Embed Size (px)
DESCRIPTION
T Test Analysis
Citation preview

t-test
Testing Inferences about Population Means
By: Agus Aan Adriansyah

Learning Objectives Menghitung dan menginterpretasi
Single sample t Independent samples t Dependent samples t
Menggunakan SPSS untuk menghitung tes yang sama dan menginterpretasi output

Review 6 Steps for Significance Testing
1. Menentukan alpha (p level).
2. Menyatakan hipotesis, null dan alternatif.
3. Menghitung statistik uji (sample value).
4. Menentukan nilai kritis statistik.
5. Menyatakan peraturan keputusan.
6. Menyatakan kesimpulan.

One Sample Exercise (1)
1. Menentukan alpha. = .052. Menyatakan hypotheses.
Null hypothesis is H0: = 1000.
Alternative hypothesis is H1: 1000.
3. Menghitung statistik uji
Menguji apakah bola lampu mempunyai umur 1000 jam

Calculating the Single Sample t800750940970790980820760
1000860
Berapa mean sampel? = 867
Berapa standar deviasi sampel bola lampu?
SD= 96.73
35.459.30
1000867
XX S
Xt
59.3010
73.96
N
SDSx
X

Determining Significance
4. Menentukan nilai kritis. Lihat pada tabel. Mencari alpha = .05, two tails dengan df = 10-1 = 9. Pada tabel 2.262.
5. Menyatakan peraturan keputusan. Jika nilai absolut dari sampel lebih besar dari nilai kritis, Null ditolak. If |-4.35| > |2.262|, H0
ditolak.

Stating the Conclusion 6. Menyatakan kesimpulan. Kami
menolak hipotesis nol bahwa lampu yang diambil dari populasi yang rata-rata berumur 1000 jam. Perbedaan antara rata-rata sampel (867) dan rata-rata populasi (1000) sangat berbeda yang tidak mungkin bahwa sampel bisa saja diambil dari populasi dengan rata-rata berumur 1000 jam.

One-Sample Statistics
10 867.0000 96.7299 30.5887BULBLIFEN Mean Std. Deviation
Std. ErrorMean
One-Sample Test
-4.348 9 .002 -133.0000 -202.1964 -63.8036BULBLIFEt df Sig. (2-tailed)
MeanDifference Lower Upper
95% ConfidenceInterval of the
Difference
Test Value = 1000
SPSS Results
Computers print p values rather than critical values. If p (Sig.) is less than .05, it’s significant.

t-tests with Two Samples
Independent Samples t-test
Dependent Samples t-test

Independent Samples t-test Digunakan ketika memiliki dua sampel
independen, mis. Kelompok perlakuan dan kelompok kontrol.
Rumus: Istilah dalam pembilang adalah mean
sampel. Istilah dalam penyebut adalah standar
eror selisih mean.
diffXX SE
XXt 21
21

Independent samples t-test
Rumus standar eror selisih mean:
2
22
1
21
N
SD
N
SDSEdiff
Misalkan kita mempelajari pengaruh kafein pada tes motorik dimana tugas ini adalah untuk menjaga mouse berpusat pada titik yang bergerak. Semua orang mendapat minuman; setengah mendapatkan kafein, setengah mendapatkan plasebo; tidak ada yang tahu siapa yang mendapat apa.
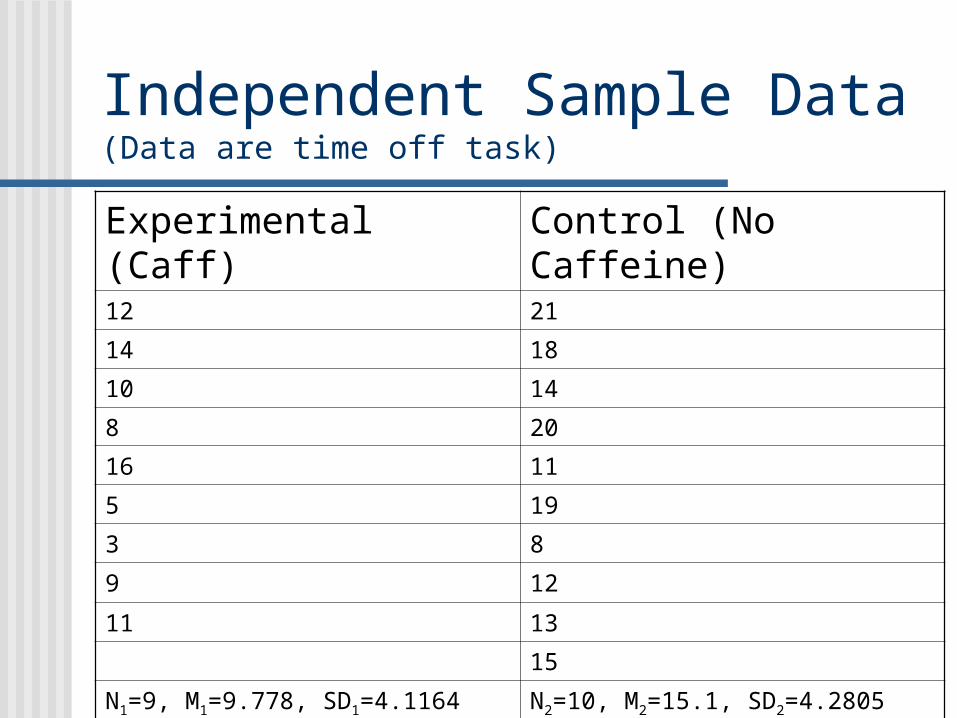
Independent Sample Data (Data are time off task)
Experimental (Caff) Control (No Caffeine)12 21
14 18
10 14
8 20
16 11
5 19
3 8
9 12
11 13
15
N1=9, M1=9.778, SD1=4.1164 N2=10, M2=15.1, SD2=4.2805

Independent Sample Steps(1)
1. Menentukan alpha. Alpha = .05
2. Menyatakan Hypotheses.
Null is H0: 1 = 2.
Alternative is H1: 1 2.

Independent Sample Steps(2)
3. Menghitung statistik uji:
93.110
)2805.4(
9
)1164.4( 22
2
22
1
21
N
SD
N
SDSEdiff
758.293.1
322.5
93.1
1.15778.921
diffSE
XXt

Independent Sample Steps (3)
4. Menentukan nilai kritis. Alpha .05, 2 tails, dan df = N1+N2-2 or 10+9-2 = 17. Hasilnya 2.11.
5. Menentukan keputusan peraturan. Jika |-2.758| > 2.11, maka null ditolak.
6. Kesimpulan: Null ditolak. Mean populasi berbeda. Kafein memiliki efek pada motorik.

Using SPSS Buka SPSS Buka file “SPSS Examples” untuk Lab 5 Go to:
“Analyze” kemudian “Compare Means” Pilih “Independent samples t-test” Masukkan IV dalam “grouping variable” dan DV
dalam kotak “test variable”. Mendefinisikan pengelompokan nomor variabel.
• Misal, experimental group sebagai “1” dalam kumpulan data dan control group sebagai “2”
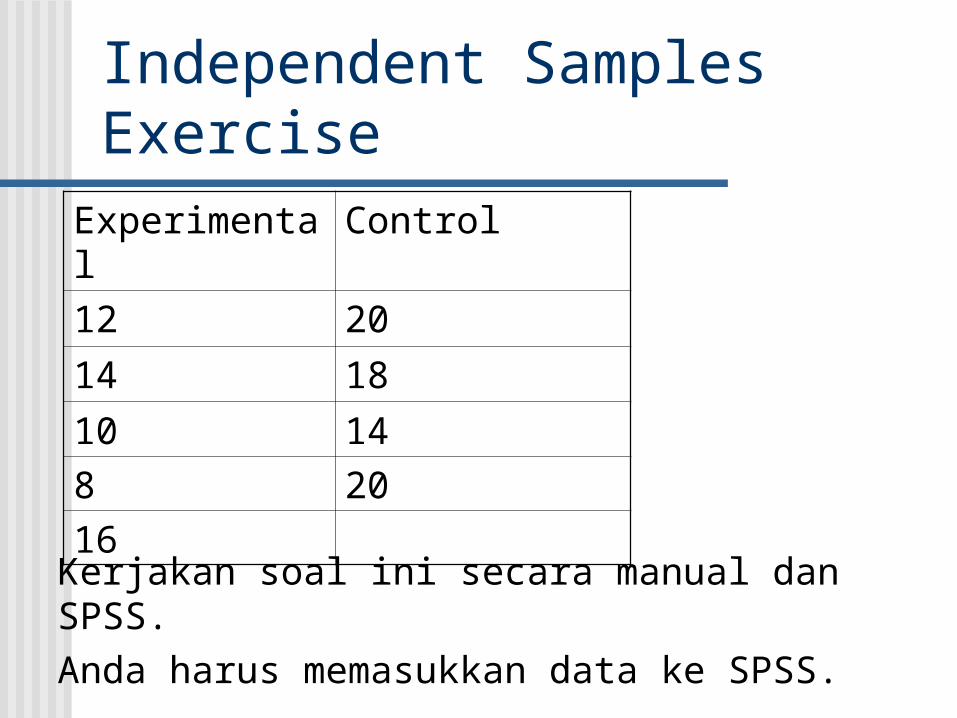
Independent Samples Exercise
Experimental Control
12 20
14 18
10 14
8 20
16
Kerjakan soal ini secara manual dan SPSS. Anda harus memasukkan data ke SPSS.
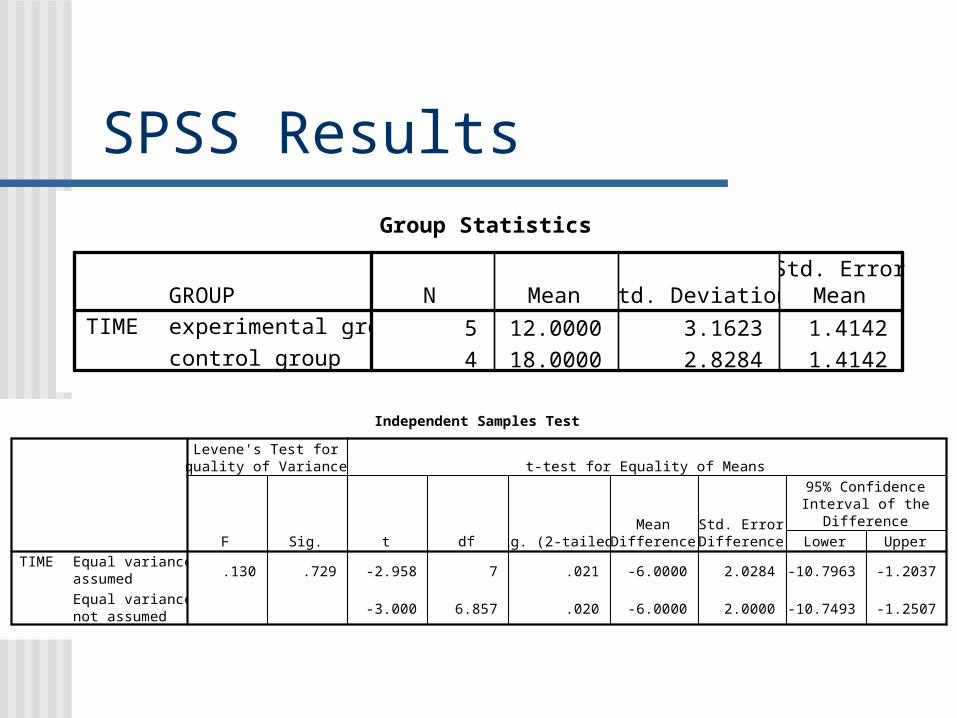
Group Statistics
5 12.0000 3.1623 1.4142
4 18.0000 2.8284 1.4142
GROUPexperimental group
control group
TIMEN Mean Std. Deviation
Std. ErrorMean
Independent Samples Test
.130 .729 -2.958 7 .021 -6.0000 2.0284 -10.7963 -1.2037
-3.000 6.857 .020 -6.0000 2.0000 -10.7493 -1.2507
Equal variancesassumed
Equal variancesnot assumed
TIMEF Sig.
Levene's Test forEquality of Variances
t df Sig. (2-tailed)Mean
DifferenceStd. ErrorDifference Lower Upper
95% ConfidenceInterval of the
Difference
t-test for Equality of Means
SPSS Results

Dependent Samples t-tests

Dependent Samples t-test Digunakan ketika memiliki sampel
dependen - matched, paired or tied pengukuran berulang Kakak & adik, suami & istri Tangan kiri, tangan kanan, dan lain-lain
Berguna untuk mengontrol perbedaan individu. Dapat menghasilkan tes yang lebih kuat daripada sampel independen t-test.

Dependent Samples tRumus:
diffX SE
Dt
D
t adalah selisih mean dan standar eror
pairs
Ddiff
n
SDSE
Standar eror ditemukan dengan mencari perbedaan antara masing-masing pasangan pengamatan. Standar deviasi perbedaan ini adalah SDD. Membagi SDD dengan sqrt (jumlah pasangan) untuk mendapatkan SEdiff.

Another way to write the formula
pairs
DX
nSD
Dt
D
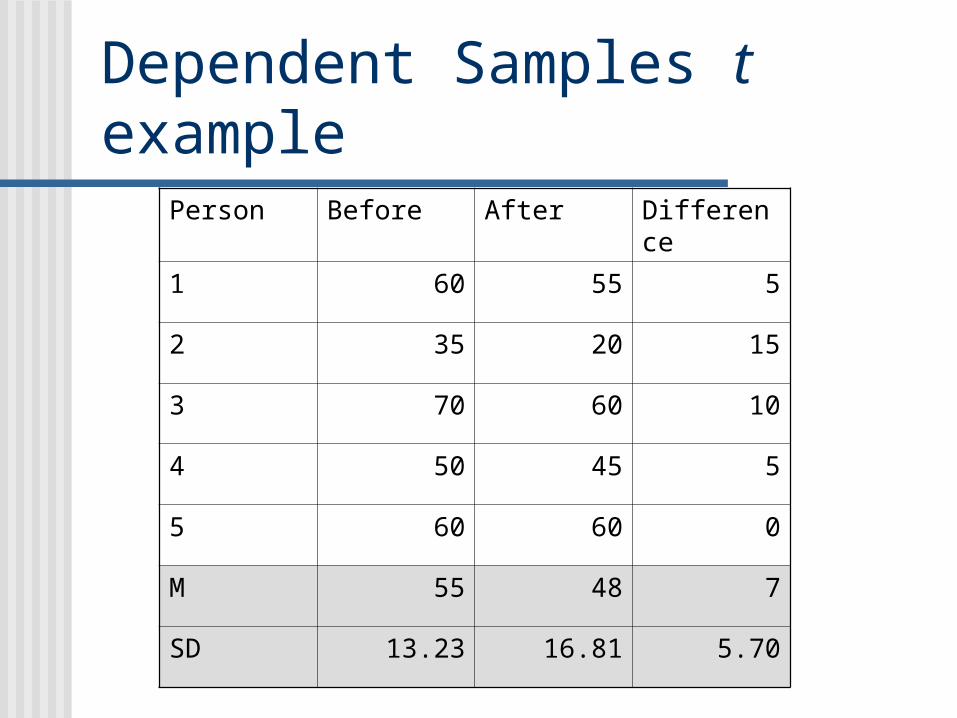
Dependent Samples t example
Person Before After Difference
1 60 55 5
2 35 20 15
3 70 60 10
4 50 45 5
5 60 60 0
M 55 48 7
SD 13.23 16.81 5.70

Dependent Samples t Example (2)
55.25
70.5
pairs
diffn
SDSE
75.255.2
7
55.2
4855
diffSE
Dt
1. Menentukan alpha = .052. Null hypothesis: H0: 1 = 2. Alternative
is H1: 1 2.
3. Menghitung statistik uji:

Dependent Samples t Example (3)
4. Menentukan nilai kritis t. Alpha =.05, tails=2 df = N(pairs)-1 =5-1=4. Nilai kritis 2.776
5. Peraturan keputusan: Apakah nilai mutlak dari nilai sampel lebih besar dari nilai kritis?
6. Kesimpulan. Tidak (terlalu) signifikan. Painfree tidak memiliki efek.

Using SPSS for dependent t-test Buka SPSS Buka file “SPSS Examples” (sama seperti
sebelumnya) Go to:
“Analyze” kemudian “Compare Means” Pilih “Paired samples t-test” Pilih dua kondisi IV yang akan
dibandingkan. Masukkan dalam “paired variables box.”

Dependent t- SPSS outputPaired Samples Statistics
55.0000 5 13.2288 5.9161
48.0000 5 16.8077 7.5166
PAINFREE
PLACEBO
Pair1
Mean N Std. DeviationStd. Error
Mean
Paired Samples Correlations
5 .956 .011PAINFREE & PLACEBOPair 1N Correlation Sig.
Paired Samples Test
7.0000 5.7009 2.5495 -7.86E-02 14.0786 2.746 4 .052PAINFREE - PLACEBOPair 1Mean Std. Deviation
Std. ErrorMean Lower Upper
95% ConfidenceInterval of the
Difference
Paired Differences
t df Sig. (2-tailed)





























