Embed Size (px)
Citation preview

Letting the Machine Code
Qualitative and Mixed
Methods Data in NVivo 10The “Autocoding by Existing Pattern” Feature
SIDLIT of C2C
July 2015
2

Presentation description
An experimental feature in NVivo 10 (circa 2013), Autocoding by Existing
Pattern, enables the application of semi-supervised machine learning to
ingested research data (in text form). This results in the extraction of
themes and other relevant insights from data—at machine speeds, based on
the classification algorithm. This presentation will introduce this feature in
NVivo 10 (available on both Windows and native Mac platforms). This will
show how the machine can achieve high inter-rater reliability (a Cohen’s
Kappa of one in many cases) on the one hand but still not achieve full human
sensibility from human cognition-based “close reading” coding on the other.
This presentation will suggest a complementary balance between machine-
and human-coding of qualitative and mixed methods data for the most
efficient application of researcher time and expertise.
3

Overview
Qualitative and mixed methods research and data; coding
A classifying of textual data by codes (a visualization)
NVivo and its main functions
Autocoding by existing pattern
Post-autocoding by existing pattern
Some challenges to autocoding by existing pattern
Other: Autocoding by style in NVivo
In perspective…
4

Overview (cont.)
Real-world affordances (of NVivo’s “autocoding by existing pattern”) for
research
Brainstorming and questions
5

Qualitative and mixed methods research
and data; coding
Qual and Mixed Methods
Data Where information comes from and what
data are
The various forms of data (structured, unstructured, and semi-structured)
A wide range of research and (in)validation methods
The critical role of the individual in research
What may be claimed from the research
The various dependencies on the data
“Coding” Extracting themes (by identifying
what is salient based on theory, based on practice, based on prior research, based on expertise, and others)
Creating categories of meaning
Identifying patterns
Organizing data (according to extant theories or in an emergent data-centric way)
…and more
6

A classifying of textual data by codes
(a visualization)
7

A wide range of data types
Exponential growth of digital data from social media, much of it accessible through application programming interfaces (APIs) and data scraping
Multidimensional and often noisy data; structured, semi-structured, and unstructured
Digital (whether born-digital or transcoded from the analog)
Multimedia inclusion enablements
Requires a text version for data processing in NVivo (treated as an abstract data type known as a “bag”); may require further processing in different nodes for different queries (such as those based on classification features, such as those for matrix queries)
No automated voice-to-text transcription, no static or dynamic computer vision capabilities
8

A wide range of data types (cont.)
“Internal” source / “external” source (as conceptualized by QSR
International)
Internal: Digital data (text, audio, video, animations, simulations, and others)
External (non-digital): Proxy data from a non-digital source, often requiring
transcoding
Run through a structured computational lens
9

A wide range of data types (cont.)
“Categorical” data analyzed through
Clustering
Similarity
Difference
Relation
Expected rates of observed occurrences given baselines
Typicality vs. anomalousness
10

NVivo and its main functions
Proper ingestion and maintenance (organization, curation) of digital data (in a
mixed-source database): Text, imagery, audio, video, datasets, and others
Data extraction from WWW and Internet and social media platforms (via
NCapture of NVivo): Twitter account Tweetstreams, Facebook messaging, web
pages, citation software programs, and others
Elicitation and recording of researcher / research team thinking: Transcription
(timed text) / notetaking / coding / memo-ing / research journaling, and
others
Data querying: Text frequency counts, text searches (for context), codebook
extractions, coding comparisons, text proximity queries, matrix queries,
queries by human demographics, and others
11

NVivo and its main functions (cont.)
Multilingual capabilities: Unicode set (UTF – 8 or Universal Coded Character
Set + Transformation Format – 8 bit), base language setting per project
Data visualization: Modeling (2D node-link diagrams, both auto-generated
and manually-drawn), word clouds, dendrograms, treemap diagrams, 2D and
3D cluster diagrams, and others (for various forms of visual analysis)
Outputs: Datasets, reports, digital visualizations, codesets, and others
Integration of team-coded projects for analysis and comparisons: Cohen’s
Kappa, coding comparison, and “interrater reliability”
Autocoding by pattern*: Emulation of human coding
Data archival: Data storage albeit in a proprietary .nvp (NVivo project on
Windows OS) format (.nvpx on Mac OS)
12
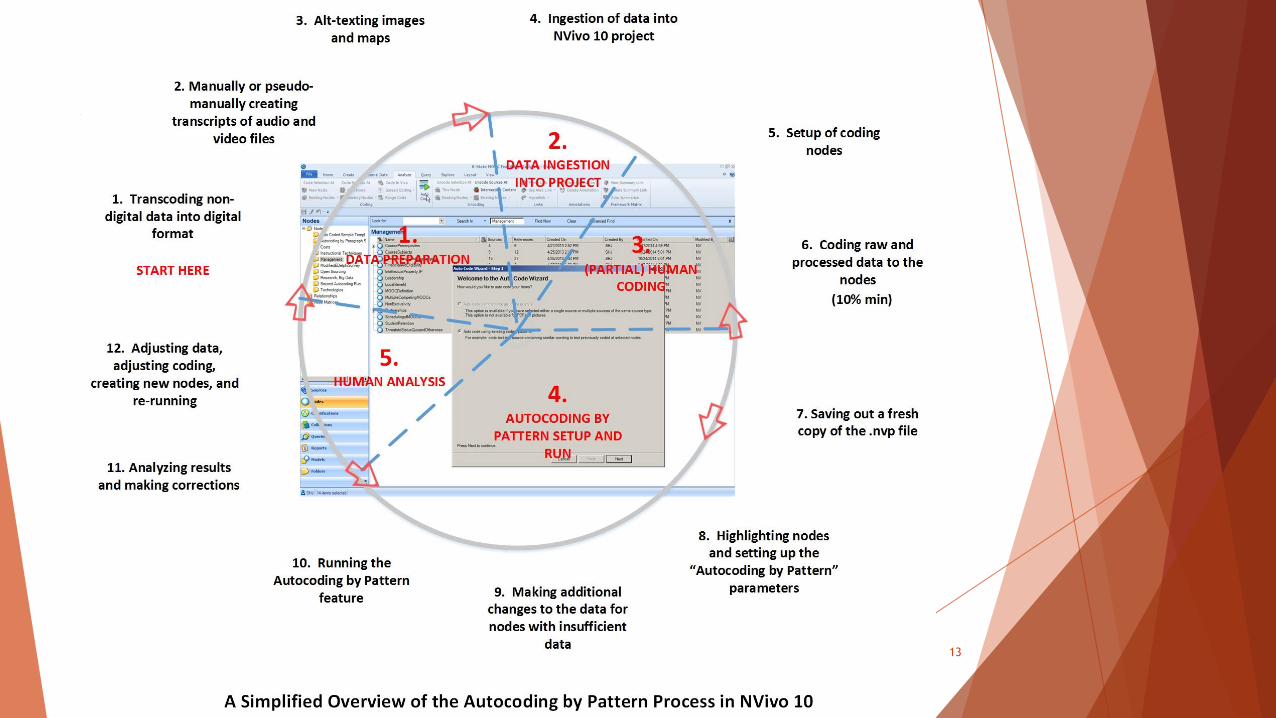
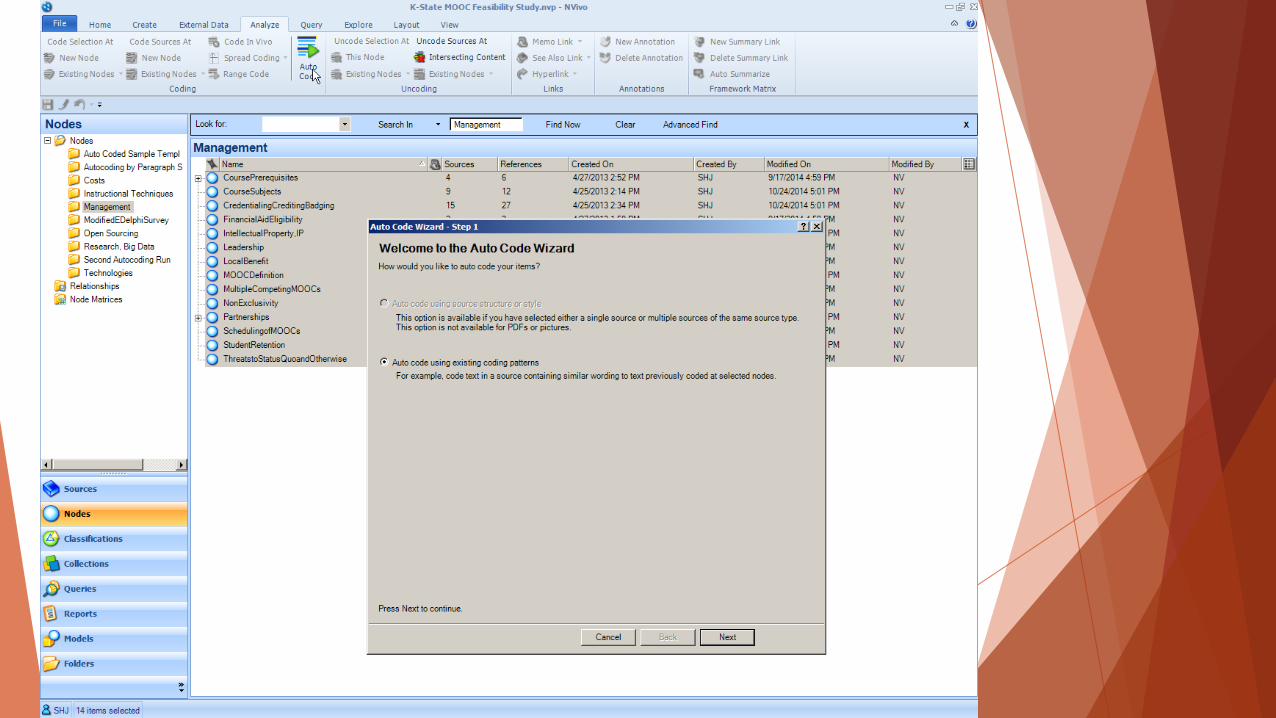
Autocoding by pattern: A sequence
(visualization)
13
A recursive process

Autocoding by existing pattern
General sequence: Save the current project under another name under which
to run the “autocoding by pattern” -> setup of all necessary nodes (like a
comprehensive taxonomic structure of the expected extractions from the
project data, with full descriptors of requirements for membership to invoke
a particular coding category—from a human perspective) by the human
researcher -> coding of examples to those nodes by the human researcher
(with a suggested minimum of 10% of the raw data) -> highlighting of nodes
and use of the “autocoding by pattern” -> selecting which nodes to use
autocoding by pattern on -> selection of “more” or “less” coding on the slider
/ selection of sentence or paragraph-level coding -> running the “autocoding
by pattern” -> human analysis of results and tweaking of “NV”-coded contents
-> running of inter-rater reliability (Cohen’s Kappa) of the NV-profile-related
codes with a coding comparison query
14

Autocoding by existing pattern (cont.)
Under the covers (an artificial intelligence or “AI” classification algorithm):
semi-supervised machine learning, classification of textual contents to
categories (nodes), based on “training set” of human-coded data apparently
Would benefit from more authoritative documentation released by QSR
International
A scour of the academic literature
Multiple direct queries to QSR International
15

Autocoding by existing pattern (cont.)
Human validation: The critical role of the human analyst
Does the machine coding make sense? Is there a correct “word sense”? Are there
certain words for which the machine is not “understanding” the relevance?
Is there over-coding with too much included? Is there under-coding, with too much
left out?
What is going on with the machine in terms of the logic?
Are there missing nodes that need to be included? If so, what are these, and why?
Would the machine coding benefit from having more sample coding (such as to 30%
or higher)? How would the researchers know which level of coding is optimal for
the particular research context and dataset?
If there will be re-runs of the autocoding by pattern, when should those be done?
16

Post-autocoding by existing pattern
May query the code (such as by text frequency counts, text searches, and
others)
May cross-analyze the code (between coders, for example; between nodes;
between categories of information, and others)
May conduct matrix coding queries on the code (and on various sources, and
folders of sources)
May create data visualizations from the results of the autocoding by pattern
17

Some challenges to autocoding by
existing pattern
Insufficient researcher understanding of what is going on with the machine-
learning classification algorithm of categorical data
Human researcher suspending their own analysis and letting the machine run
Insufficient data processing (and preparation) for machine learning analysis
Incomplete transcription of audio and video; incomplete alt texting of imagery
Incomplete node creation (the system requires the pre-making of the nodes
(classifications)
While some computer systems extract concepts automatically from text corpuses,
this is not one of them
A multi-lingual dataset (with much of the language not included in the base
language set for the project)
18

Some challenges to autocoding by
existing pattern (cont.)
A lack of iterative applications of the autocoding by pattern to the original
pristine data set based on informed adjustments
Need to add or remove coding nodes
Need to provide more human sampling of coding (a larger training set)
Need to add more research data
Need to adjust the slider to make the autocoding by pattern more or less plentiful
(less or more interpretive…aggressive)
19

Some challenges to autocoding by
existing pattern (cont.)
Poor human oversight of the resulting machine coding
Insufficient analysis (the machine only advances the research to a degree; it does
not supplant human oversight)
Insufficient knowledge of amount of confidence in the autocoding by pattern
Unclear representation of the results
20

Other: Autocoding by style in NVivo
Autocoding by Style
Differential handling of styled text
(header 1, header 2, etc.)
Ingestion of interview data
Differential handling of column
data (data fields)
Ingestion of dataset data
Why?
Enhances ways to set up later
queries
May run queries by interview
questions
May run queries by interview
subjects
May run queries by descriptive data
(such as demographic information)
about interview subjects
21

In perspective
“Autocoding by existing pattern” may be part of an iterative and recursive
process
There are ways to set up an analytical sequence (chain) that is useful for a
particular research project that maximizes what humans and computers may do (in
a complementary mutually-augmenting way)
Human oversight is critical, and the “last word” is human because of the
importance of expertise and the interpretive lens (for foregrounding and
backgrounding) albeit based on empirical observations and objective facts
Need to assess confidence in the autocoding of the textual data
The computer is following human-made rules based on coded capacities; it is not
sentient
22

In perspective (cont.)
Researchers will need to document the research / data processing / analytical
process in order to use such data in research
It is important to be clear about the requirements and limitations:
The requirement for an extant a priori human-made node structure (no automated
extraction of nodes from the text data alone)
A sufficient amount of human coding required to the respective nodes (deciding whether
to have NVivo (“NV”) code even to nodes with insufficient coding samples)
The need for human oversight of the machine findings (making sense of the machine’s
sensemaking)
QSR International labels this type of coding as “broad brush” in terms of
providing insights about the as-yet uncoded parts of the data
23

Autocoding by existing pattern or not?
Where it is suggested
Iterative research with new data
coming in at internals, to enable a
human-modeled pattern to be
applied to this data
Capturing broad overviews of
large-sets of raw data
May be used to contrast different
coder’s different approaches
Not so much… QSR International suggests that
autocoding may be useful for some issues but is insensitive to nodes that represent the following: “sentiment,” “attitudes, tones, or emotions,” “interpretation of the data,” and “the speaker in an interview transcript” (identifying speakers based on patterns of expression) (“Automatic coding using existing coding patterns,” 2015)
24

Real-world affordances for research
Extension and amplification of human expertise and sense-making through
computational affordances (for emulation, patterning, remote reading, and
engaging massive data with blistering speeds)
Capturing a researcher’s coding “fist” for posterity (for a certain type of data
in a limited domain)
Creating self awareness of human-based coding as reflected by the computer
A machine-enhanced and efficient approach to creating more insight about
the data and information
Potential cost savings (human attention is expensive and comparatively
achingly slow)
25

Real-world affordances for research (cont.)
Scalable to large sets of unstructured data (as long as each multimedia source
has a comprehensive text proxy)
Running the autocoding on different coding methods by different researchers
in order to see what different insights may be surfaced from the same data
(but different subjective and interpretive lenses)
26

Brainstorming and questions
27
How might NVivo 10’s “autocoding by existing pattern” apply to your
particular research?
(There’s virtually nothing in the research literature about this feature at this
time.)
How should you prepare data for proper NVivo handling for “autocoding by
pattern”?
Where do you think human coding and machine coding might diverge? And
why?
How would you ensure that the resulting mixed coding is accurate? Useful?
When should a more / less aggressive form of autocoding by existing pattern
be used for research? Why?

Brainstorming and questions (cont.)
How should the autocoding by existing pattern feature be described in
research articles by self-respecting (and other-respecting) researchers?
Pros and cons:
What are some upsides / downsides to the rigorous emulation mechanism of
computers for autocoding by existing pattern (probably based on “synsets” or
“synonym sets”)?
What are some upsides / downsides to human coding? To human coding alone?
What are some upsides / downsides to fully automated (unsupervised) coding of
text corpuses (machine coding alone)?
In light of the pros and cons, when should partially / fully automated
extractions of data be done from text corpuses / text datasets?
28

Contact and conclusion
Dr. Shalin Hai-Jew, Instructional Designer, iTAC, K-State
212 Hale / Farrell Library
1117 Mid-Campus Drive North, Manhattan, KS 66506-0110
785-532-5262
Additional Resource: “Using NVivo: An Unofficial and Unauthorized Primer”
29


















![A qualitative systematic review of patients’ experience … · We uploaded a full copy of all papers onto Nvivo 9 soft-ware to help organise the qualitative analysis [22]. NVivo](https://img.pdfslide.us/doc/110x75/5b647b017f8b9aec518d4e28/a-qualitative-systematic-review-of-patients-experience-we-uploaded-a-full.jpg)










