Embed Size (px)
Citation preview

Unsupervised Learning of Unsupervised Learning of Natural Language Natural Language
Morphology using MDLMorphology using MDL
John GoldsmithJohn Goldsmith
November 9, 2001November 9, 2001

Today’s presentationToday’s presentation
1.1. The task: unsupervised learningThe task: unsupervised learning2.2. Overview of program and outputOverview of program and output3.3. Overview of Minimum Description Length Overview of Minimum Description Length
frameworkframework4.4. Application of MDL to iterative search of Application of MDL to iterative search of
morphology-space, with successively morphology-space, with successively finer-grained descriptionsfiner-grained descriptions
5.5. Mathematical modelMathematical model6.6. Current capabilitiesCurrent capabilities7.7. Current challengesCurrent challenges

Today’s presentationToday’s presentation
1.1. The task: unsupervised learningThe task: unsupervised learning2.2. Overview of program and outputOverview of program and output3.3. Overview of Minimum Description Length Overview of Minimum Description Length
frameworkframework4.4. Application of MDL to iterative search of Application of MDL to iterative search of
morphology-space, with successively morphology-space, with successively finer-grained descriptionsfiner-grained descriptions
5.5. Mathematical modelMathematical model6.6. Current capabilitiesCurrent capabilities7.7. Current challengesCurrent challenges

Unsupervised learningUnsupervised learning
Input: untagged text in orthographic or Input: untagged text in orthographic or phonetic formphonetic form
with spaces (or punctuation) separating with spaces (or punctuation) separating words.words.
But no tagging or text preparation.But no tagging or text preparation.

Today’s presentationToday’s presentation
1.1. The task: unsupervised learningThe task: unsupervised learning2.2. Overview of program and outputOverview of program and output3.3. Overview of Minimum Description Length Overview of Minimum Description Length
frameworkframework4.4. Application of MDL to iterative search of Application of MDL to iterative search of
morphology-space, with successively morphology-space, with successively finer-grained descriptionsfiner-grained descriptions
5.5. Mathematical modelMathematical model6.6. Current capabilitiesCurrent capabilities7.7. Current challengesCurrent challenges

Overview of program and outputOverview of program and output
Linguistica: a C++ Windows-based Linguistica: a C++ Windows-based program available for download atprogram available for download at
http://humanities.uchicago.edu/faculty/goldsmith/Linguistica2000http://humanities.uchicago.edu/faculty/goldsmith/Linguistica2000
Technical discussion in Technical discussion in Computational Linguistics Computational Linguistics (June 2001)(June 2001) Good results with 5,000 words, very fine-Good results with 5,000 words, very fine-
grained results with 500,000 words grained results with 500,000 words (corpus length, not lexicon count).(corpus length, not lexicon count).

OutputOutput
List of stems, suffixes, and prefixesList of stems, suffixes, and prefixes List of signatures.List of signatures.
A signature: a list of all suffixes (prefixes) A signature: a list of all suffixes (prefixes) appearing in a given corpus with a given appearing in a given corpus with a given stem.stem.
Hence, a stem in a corpus has a unique Hence, a stem in a corpus has a unique signature.signature.
A A signaturesignature has a unique set of stems has a unique set of stems associated with itassociated with it
……

(example of signature in English)(example of signature in English)
NULL.ed.ing.s NULL.ed.ing.s
askask callcall pointpoint
==
askask askedasked asking asking asksasks
call call calledcalled callingcalling callscalls
pointpoint pointedpointed pointingpointing pointspoints

……outputoutput
Roots (“stems of stems”) and the inner Roots (“stems of stems”) and the inner structure of stemsstructure of stems
Regular allomorphy of stems: Regular allomorphy of stems: e.g., learn “delete stem-final –e.g., learn “delete stem-final –e e in English in English
before before –ing–ing and and –ed”–ed”


Today’s presentationToday’s presentation
1.1. The task: unsupervised learningThe task: unsupervised learning2.2. Overview of program and outputOverview of program and output3.3. Overview of Minimum Description Length Overview of Minimum Description Length
frameworkframework4.4. Application of MDL to iterative search of Application of MDL to iterative search of
morphology-space, with successively morphology-space, with successively finer-grained descriptionsfiner-grained descriptions
5.5. Mathematical modelMathematical model6.6. Current capabilitiesCurrent capabilities7.7. Current challengesCurrent challenges

Minimum Description Length (MDL)Minimum Description Length (MDL)
Jorma Rissanen: Stochastic Complexity in Jorma Rissanen: Stochastic Complexity in Statistical Inquiry (1989)Statistical Inquiry (1989)
Work by Michael Brent and Carl de Work by Michael Brent and Carl de Marcken on word-discovery using MDLMarcken on word-discovery using MDL

Essence of MDLEssence of MDL
We are We are givengiven
1.1. a corpus, anda corpus, and
2.2. a probabilistic morphology, which a probabilistic morphology, which technically means that we are given a technically means that we are given a distribution over certain strings of stems distribution over certain strings of stems and affixes.and affixes.
(“Given”? Given by who? We’ll get back to (“Given”? Given by who? We’ll get back to that.)that.)
(Remember: a (Remember: a distributiondistribution is a set of non- is a set of non-negative numbers summing to 1.0.)negative numbers summing to 1.0.)

The The higher higher the probability is that the the probability is that the morphology assigns to the (observed) morphology assigns to the (observed) corpus, the corpus, the betterbetter that morphology is as a that morphology is as a model model of of that data. that data.
Better said: Better said: -1 * log probability (corpus) is a measure of -1 * log probability (corpus) is a measure of
how well how well the morphology models the data: the morphology models the data: the the smallersmaller that number is, the better the that number is, the better the morphology models the data.morphology models the data.
This is known as the This is known as the optimal compressed optimal compressed length length of the data, given the model.of the data, given the model.
Using base 2 logs, this number is a measure Using base 2 logs, this number is a measure in information theoretic bits.in information theoretic bits.

Essence of MDL…Essence of MDL…
The goodness of the morphology is also The goodness of the morphology is also measured by how measured by how compact compact the the morphology is.morphology is.
We can measure the compactness of a We can measure the compactness of a morphology in information theoretic bits.morphology in information theoretic bits.

How can we measure the How can we measure the compactness of a morphology?compactness of a morphology?
Let’s consider a naïve version of Let’s consider a naïve version of description length: count the number of description length: count the number of letters. letters.
This naïve version is nonetheless helpful This naïve version is nonetheless helpful in seeing the intuition involved.in seeing the intuition involved.

Naive Minimum Description LengthNaive Minimum Description Length
Corpus:Corpus:
jump, jumps, jumpingjump, jumps, jumping
laugh, laughed, laugh, laughed, laughinglaughing
sing, sang, singingsing, sang, singing
the, dog, dogs the, dog, dogs
total: total: 6262 letters letters
Analysis:Analysis:
StemsStems: jump laugh sing : jump laugh sing sang dog (20 letters)sang dog (20 letters)
SuffixesSuffixes: s ing ed (6 : s ing ed (6 letters)letters)
UnanalyzedUnanalyzed: the (3 : the (3 letters)letters)
total: total: 2929 letters. letters.
Notice that the description length goes UP if we analyze sing into s+ing

Essence of MDL…Essence of MDL…
The best overall theory of a corpus is the The best overall theory of a corpus is the one for which the one for which the sumsum of of
log prob (corpus) +log prob (corpus) + length of the morphologylength of the morphology
(that’s the (that’s the description length)description length) is the is the smallestsmallest..

Essence of MDL…Essence of MDL…
0
100000
200000
300000
400000
500000
600000
700000
Best analysis Elegant theorythat works
badly
Baroque theorymodeled on
data
Length of morphology
Log prob of corpus

Overall logicOverall logic
Search through morphology space for the Search through morphology space for the morphology which provides the smallest morphology which provides the smallest description length.description length.

Today’s presentationToday’s presentation
1.1. The task: unsupervised learningThe task: unsupervised learning2.2. Overview of program and outputOverview of program and output3.3. Overview of Minimum Description Overview of Minimum Description
Length frameworkLength framework4.4. Application of MDL to iterative search Application of MDL to iterative search
of morphology-space, with of morphology-space, with successively finer-grained descriptionssuccessively finer-grained descriptions
5.5. Mathematical modelMathematical model6.6. Current capabilitiesCurrent capabilities7.7. Current challengesCurrent challenges

Corpus
Pick a large corpus from a language --5,000 to 1,000,000 words.

Corpus
Bootstrap heuristicFeed it into the “bootstrapping” heuristic...

Corpus
Out of which comes a preliminary morphology,which need not be superb.Morphology
Bootstrap heuristic
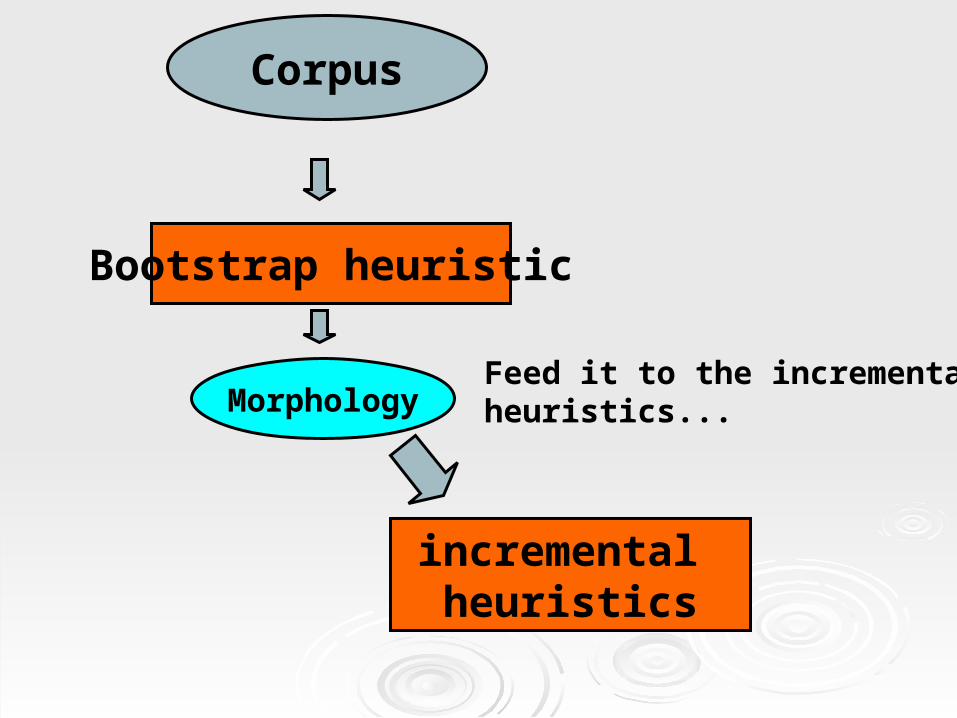
Corpus
Morphology
Bootstrap heuristic
incremental heuristics
Feed it to the incrementalheuristics...

Corpus
Morphology
Bootstrap heuristic
incremental heuristics
modified morphology
Out comes a modifiedmorphology.

Corpus
Morphology
Bootstrap heuristic
incremental heuristics
modified morphology
Is the modificationan improvement?Ask MDL!

Corpus
Morphology
Bootstrap heuristic
modified morphology
If it is an improvement,replace the morphology...
Garbage

Corpus
Bootstrap heuristic
incremental heuristics
modified morphology
Send it back to theincremental heuristics again...

Morphology
incremental heuristics
modified morphology
Continue until there are no improvementsto try.

1. Bootstrap heuristic1. Bootstrap heuristic
A function that takes words as inputs A function that takes words as inputs and gives an initial hypothesis regarding and gives an initial hypothesis regarding what are stems and what are affixes.what are stems and what are affixes.
In theory, the search space is enormous: In theory, the search space is enormous: each word w of length |w| has at least |w| each word w of length |w| has at least |w| analyses, so search space has at least analyses, so search space has at least members.members.
V
iiw
1
||

Better bootstrap heuristicsBetter bootstrap heuristics
Heuristic, not perfection! Several good Heuristic, not perfection! Several good heuristics. Best is a modification of a good heuristics. Best is a modification of a good idea of Zellig Harris (1955):idea of Zellig Harris (1955):
Current variant:Current variant:Cut words at certain Cut words at certain peakspeaks of of successor successor frequencyfrequency..
Problems: can Problems: can over-cut; over-cut; can can under-cutunder-cut; and ; and can put cuts too far to the right (“aborti-” can put cuts too far to the right (“aborti-” problem). [Not a problem!]problem). [Not a problem!]

Successor frequencySuccessor frequency
g o v e r n
Empirically, only one letter follows “gover”: “n”

Successor frequencySuccessor frequency
g o v e r n m
Empirically, 6 letters follows “govern”: “n”
i
os
e
#

Successor frequencySuccessor frequency
g o v e r n m
Empirically, 1 letter follows “governm”: “e”
e
g o v e r 1 n 6 m 1 e
peak of successor frequency

Lots of errors…Lots of errors…
c o n s e r v a t i v e s
9 18 11 6 4 1 2 1 1 2 1 1
wrong right wrong

Even so…Even so…
We set conditions:We set conditions:
Accept cuts with stems at least 5 letters in Accept cuts with stems at least 5 letters in length;length;
Demand that successor frequency be a Demand that successor frequency be a clear peak: 1… N … 1 (e.g. govern-ment)clear peak: 1… N … 1 (e.g. govern-ment)
Then for each stem, collect all of its suffixes Then for each stem, collect all of its suffixes into a signature; and accept only into a signature; and accept only signatures with at least 5 stems to it.signatures with at least 5 stems to it.

2. Incremental heuristics2. Incremental heuristics
Course-grained to fine-grainedCourse-grained to fine-grained 1. 1. Stems and suffixes Stems and suffixes to splitto split: :
Accept any analysis of a word if it consists of a known Accept any analysis of a word if it consists of a known stem and a known suffix.stem and a known suffix.
2. 2. Loose fitLoose fit: : suffixes and signatures suffixes and signatures to split: to split: Collect any string that precedes a known suffix. Collect any string that precedes a known suffix. Find all of its apparent suffixes, and use MDL to Find all of its apparent suffixes, and use MDL to
decide if it’s worth it to do the analysis. We’ll return to decide if it’s worth it to do the analysis. We’ll return to this in a moment.this in a moment.

Incremental heuristicIncremental heuristic
33.Slide stem-suffix boundary to the left.Slide stem-suffix boundary to the left: : Again, use MDL to decide.Again, use MDL to decide.
How do we use MDL to decide?How do we use MDL to decide?

Using MDL to judge Using MDL to judge a potential stema potential stem
act, acted, action, acts.act, acted, action, acts.
We have the suffixes NULL, ed, ion, and s, We have the suffixes NULL, ed, ion, and s, but no signature NULL.ed.ion.sbut no signature NULL.ed.ion.s
Let’s compute Let’s compute costcost versus versus savingssavings of of signature NULL.ed.ion.ssignature NULL.ed.ion.s
Savings: Savings:
Stem savings: Stem savings: 33 copies of the stem copies of the stem actact: : that’s 3 x 4 = 12 letters = almost 60 bits.that’s 3 x 4 = 12 letters = almost 60 bits.

Cost of NULL.ed.ing.sCost of NULL.ed.ing.s
A pointer to each A pointer to each suffix:suffix:
][log
][log
][log
][log
s
W
ing
W
ed
W
NULL
W
To give a feel for this: 5][
log ed
W
Total cost of suffix list: about 30 bits.Cost of pointer to signature: total cost is
-- all the stems using it chip in to pay for its cost, though.
bitssigthisusethatstems
W13
][#log

Cost of signature: about 45 bitsCost of signature: about 45 bits Savings: Savings: about 60 bitsabout 60 bits
so MDL says: so MDL says: Do itDo it! Analyze the words as ! Analyze the words as stem + suffix.stem + suffix.
Notice that the cost of the analysis would Notice that the cost of the analysis would have been higher if one or more of the have been higher if one or more of the suffixes had not already “existed”.suffixes had not already “existed”.

Today’s presentationToday’s presentation
1.1. The task: unsupervised learningThe task: unsupervised learning2.2. Overview of program and outputOverview of program and output3.3. Overview of Minimum Description Length Overview of Minimum Description Length
frameworkframework4.4. Application of MDL to iterative search of Application of MDL to iterative search of
morphology-space, with successively morphology-space, with successively finer-grained descriptionsfiner-grained descriptions
5.5. Mathematical modelMathematical model6.6. Current capabilitiesCurrent capabilities7.7. Current challengesCurrent challenges

ModelModel
A model to give us a probability of each A model to give us a probability of each word in the corpus (hence, its optimal word in the corpus (hence, its optimal compressed length); andcompressed length); and
A morphology whose length we can A morphology whose length we can measure.measure.

Frequency of analyzed word Frequency of analyzed word
][
][*
][
][*
][
][
)|(*)|(*)(
)(
inFT
W
FFreqTFreqFreq
FTFreq
W is analyzed as belonging to Signature stem T and suffix F.
Actually what we care about is the log of this:
Where [W] is the total number of words.
[x] means thecount of x’sin the corpus(token count)

][
][log
][
][log
)|(log)(log
)(
inFT
W
FfreqTfreq
FTwordlengthCompressed

Next, let’s see how to Next, let’s see how to measuremeasure
the length of a morphologythe length of a morphologyA morphology is a set of 3 things:A morphology is a set of 3 things: A list of stems;A list of stems; A list of suffixes;A list of suffixes; A list of signatures with the associated A list of signatures with the associated
stems.stems.
We’ll make an effort to make our grammars We’ll make an effort to make our grammars consist primarily of lists, whose length is consist primarily of lists, whose length is conceptually simple.conceptually simple.

Length of a listLength of a list
A header A header telling us how long the list is, of telling us how long the list is, of length (roughly) loglength (roughly) log22 N, where N is the N, where N is the
length.length. N entries. What’s in an entry?N entries. What’s in an entry?
Raw lists: a list of Raw lists: a list of strings of lettersstrings of letters, where the , where the length of each letter is loglength of each letter is log22 (26) – the (26) – the
information content of a letter (we can use a information content of a letter (we can use a more accurate conditional probability).more accurate conditional probability).
Pointer lists: Pointer lists:

ListsLists
Raw suffix list:Raw suffix list: eded ss inging ionion ableable ……
Signature 1:Signature 1: Suffixes:Suffixes:
• pointer to “ing”pointer to “ing”• pointer to “ed”pointer to “ed”
Signature 2:Signature 2: SuffixesSuffixes
• pointer to “ing”pointer to “ing”• pointer to “ion”pointer to “ion”
The length of each pointer is
suffixthisofoccurrence
wordssuffixed
#
#log2
-- usually cheaper than the letters themselves

The fact that a pointer to a symbol has a The fact that a pointer to a symbol has a length that is inversely proportional to its length that is inversely proportional to its frequency is the key:frequency is the key:
We want the shortest overall grammar; soWe want the shortest overall grammar; so That means maximizing the That means maximizing the re-use re-use of of
units (stems, affixes, signatures, etc.)units (stems, affixes, signatures, etc.)

Suffixesf
A
f
WflistSuffixii
][
][log||*)(
Stemst t
WtlistStemiii )
][
][log(||*:)(
Number of letters structure
+ Signatures, which we’ll get to shortly

Information contained in the Signature component
Signatures
W
][
][log list of pointers to signatures
logstems( log Signatures
suffixes
)][
][log
][
][log(
)()(
SuffixesfSigs Stemst inft
W
<X> indicates the numberof distinct elements in X

Original morphology+ Compressed data
Repair heuristics: using MDLRepair heuristics: using MDL
We We couldcould compute the entire MDL in one compute the entire MDL in one state of the morphology; make a change; state of the morphology; make a change; compute the whole MDL in the proposed compute the whole MDL in the proposed (modified) state; and compared the two (modified) state; and compared the two lengths.lengths.
Revised morphology+
compressed data
<>

But it’s better to have a more thoughtful But it’s better to have a more thoughtful approach.approach.
Let’s define Let’s define 2
1logstate
state
x
xx
Then the change of the size of the punctuation in the lists:
signaturesstemssuffixesi logloglog)(
Then the size of the punctuation for the 3 lists is:
<Suffixes> + <Stems> + <Signatures>

Size of the suffix component, Size of the suffix component, remember:remember:
Suffixesf
A
f
WflistSuffixii
][
][log||*)(
Change in its size when we consider a modification to the morphology:1. Global effects of change of number of suffixes;2. Effects on change of size of suffixes in both states;3. Suffixes present only in state 1;4. Suffixes present only in state 2;

Suffix component change:Suffix component change:
)2,1(~
)2~,1()2,1(
||*][
][log
||*][
][log*
2
1)2,1(
Suffixesf
A
Suffixesf
A
SuffixesfA
ff
W
ff
WfSuffixesW
Contribution of suffixesthat appear only in State1
Contribution of suffixesthat appear only in State 2
Global effect of change on all suffixes
Suffixes whose counts change

Digression on entropy, MDL, and Digression on entropy, MDL, and morphologymorphology
Why using MDL is closely related to Why using MDL is closely related to measuring the complexity of the space of measuring the complexity of the space of
possible vocabulariespossible vocabularies

Consider the space of all words of length L, Consider the space of all words of length L, built from an alphabet of size b.built from an alphabet of size b.
How many ways are there to build a How many ways are there to build a vocabulary of size N?Call that U(b,L,N).vocabulary of size N?Call that U(b,L,N).
Clearly, Clearly,
!)!(
!),,(
NNb
b
N
bNLbU
L
LL

Compare that with the operation Compare that with the operation (choosing a set of N words of length L, (choosing a set of N words of length L, alphabet size b) with the operation of alphabet size b) with the operation of choosing a set of T stems (of length t) choosing a set of T stems (of length t) and a set of F suffixes (of length f), and a set of F suffixes (of length f), where t + f = L.where t + f = L.
If we take the complexity of each task to If we take the complexity of each task to be measured by the log of its size, then be measured by the log of its size, then we’re asking the size of:we’re asking the size of:
F
b
T
b
N
b
FfbUTtbU
NLbUft
L
log),,(),,(
),,(log

NNbNL
StirlingNNbNL
NbN
NNb
b
NNb
b
N
b
L
L
L
L
LL
1loglog
)(loglog
!loglog
!log)!(
!log
!)!(
!loglog
is easy to approximate, however.
N
bL
log
bababa
babaaa
ba
athenbaif
1)...1)((
1)...)(1)...(1(
)!(
!remember:

NNbNL
1loglog
The number of bits neededto list all the words:
the analysis
The length of all the pointers
to all the words:
the compressed corpus
Thus the log of the number of vocabularies =description length of that vocabulary,
in the terms we’ve been using

That means that the differences in the sizes of the spacesof possible vocabularies is equal to the difference in the
description length in the two cases:hence,
Difference of complexity of “simplex word” analysisand complexity of analyzed word analysis=log U(b,L,N) – log U(b,t,T) – log U(b,f,F)
)/1log()/1log()/1log(
))((log
FFTTNN
fFtTLNb
Difference in size of morphologies
Difference in size of compressed data

But we’ve (over)simplified in this case by But we’ve (over)simplified in this case by ignoring the frequencies inherent in real ignoring the frequencies inherent in real corpora. What’s of great interest in real life corpora. What’s of great interest in real life is the fact that some suffixes are used is the fact that some suffixes are used often, others rarely, and similarly for often, others rarely, and similarly for stems.stems.

We know something about the distribution of We know something about the distribution of words, but nothing about distribution of words, but nothing about distribution of stems and especially suffixes. stems and especially suffixes.
But suppose we wanted to think about the But suppose we wanted to think about the statistics of vocabulary choice in which statistics of vocabulary choice in which words could be selected more than words could be selected more than once….once….

We want to select N words of length L, We want to select N words of length L, and the same word can be selected. and the same word can be selected. How many ways of doing this are there?How many ways of doing this are there?
You can have any number of occurrence You can have any number of occurrence of a word, and 2 sets of the same of a word, and 2 sets of the same number of them are indistinguishable. number of them are indistinguishable. How many such vocabularies are there, How many such vocabularies are there, then? then?
N
i
iZ
NL
i
b
1
)()!(
)(

N
i
iZ
NL
i
bNLbU
1
)()!(
)(),,(
where Z(i) is the number of words of frequency i.
(‘Z’ stands for “Zipf”).
We don’t know much about frequencies of suffixes,but Zipf’s law says that
i
KiZ )(
hence for a morphemeset that obeyed
the Zipf distribution:
N
i
N
i
N
i
iKbNL
iZiibNL
iiZbNLNLbU
1
1
1
loglog
)(loglog
)!log()(log),,(log
CorpusSizeK *1.0

)ln('log
lnln
loglog1
NNNKbNL
CxxxxdxSince
iKbNLN
i
End of digression

Today’s presentationToday’s presentation
1.1. The task: unsupervised learningThe task: unsupervised learning2.2. Overview of program and outputOverview of program and output3.3. Overview of Minimum Description Length Overview of Minimum Description Length
frameworkframework4.4. Application of MDL to iterative search of Application of MDL to iterative search of
morphology-space, with successively morphology-space, with successively finer-grained descriptionsfiner-grained descriptions
5.5. Mathematical modelMathematical model6.6. Current capabilitiesCurrent capabilities7.7. Current work and challengesCurrent work and challenges

Today’s presentationToday’s presentation
1.1. The task: unsupervised learningThe task: unsupervised learning2.2. Overview of program and outputOverview of program and output3.3. Overview of Minimum Description Length Overview of Minimum Description Length
frameworkframework4.4. Application of MDL to iterative search of Application of MDL to iterative search of
morphology-space, with successively morphology-space, with successively finer-grained descriptionsfiner-grained descriptions
5.5. Mathematical modelMathematical model6.6. Current capabilitiesCurrent capabilities7.7. Current work and challengesCurrent work and challenges

Current research projectsCurrent research projects
1.1. Allomorphy: Automatic discovery of Allomorphy: Automatic discovery of relationship between stems (lov~love, relationship between stems (lov~love, win~winn)win~winn)
2.2. Use of syntax (automatic learning of Use of syntax (automatic learning of syntactic categories)syntactic categories)
3.3. Rich morphology: other languages (e.g., Rich morphology: other languages (e.g., Swahili), other sub-languages (e.g., Swahili), other sub-languages (e.g., biochemistry sub-language) where the biochemistry sub-language) where the mean # morphemes/word is much highermean # morphemes/word is much higher
4.4. Ordering of morphemesOrdering of morphemes

Allomorphy: Automatic discovery of Allomorphy: Automatic discovery of relationship between stemsrelationship between stems
Currently learns (unfortunately, over-Currently learns (unfortunately, over-learns) how to delete stem-final letters in learns) how to delete stem-final letters in order to simplify signatures.order to simplify signatures. E.g., delete stem-final –e in English before E.g., delete stem-final –e in English before
suffixes –ing, -ed, -ion (etc.).suffixes –ing, -ed, -ion (etc.).

Automatic learning of syntactic Automatic learning of syntactic categoriescategories
Work in progress with Mikhail Belkin (U of Work in progress with Mikhail Belkin (U of Chicago)Chicago) Pursuing Shi and Malik’s 1997 application of Pursuing Shi and Malik’s 1997 application of
spectral graph theory (vision)spectral graph theory (vision)• Finding eigenvector decomposition of a graph that Finding eigenvector decomposition of a graph that
represents bigrams and trigramsrepresents bigrams and trigrams

Rich morphologiesRich morphologies
A practical challenge for use in data-A practical challenge for use in data-mining and information retrieval in patent mining and information retrieval in patent applications (de-oxy-ribo-nucle-ic, etc.)applications (de-oxy-ribo-nucle-ic, etc.)
Swahili, Hungarian, Turkish, etc.Swahili, Hungarian, Turkish, etc.





























