Embed Size (px)
Citation preview

Authors:
Edison Klafke Fillus
Silvia Regina Vergilio
Software Engineering Research Group
UFPR – Federal University of Paraná
LAWASP
2012

1 Introduction
2 Approach
3 Evaluation
4 Conclusions
2

3

Aims to discover potential aspect candidates inObject Oriented (OO) software.
Searches for crosscutting concern symptoms from:◦ Source code; or
◦ Run-time behavior
4

Generally use data mining and data analysis:◦ Fan-In
◦ Formal Concept Analysis
◦ Clone Detection
◦ Pattern Matching
◦ Natural Language Processing
◦ Clustering Analisys
◦ Etc.
5

Discovers potential aspect candidates fromthe searched data without requiring priorknowledge of the system characteristics.
Identifies groups of methods or statementsrelated to the crosscutting concerns.
Composed by two main parts:◦ Clustering Algorithm: Defines grouping strategy.
◦ Distance Measure: Measure the distance betweenelements based on the selected characteristics.
6

Use different distance measures based oncode scattering and tangling symptoms.
Based on a single symptom a time.
No support neither to core concerns removalnor to fast core concerns separation frompotential crosscutting concerns.
Discover advices, don’t support pointcutidentification.
7

Clustering based Approach for Aspect
Mining and Pointcut Identification.
8

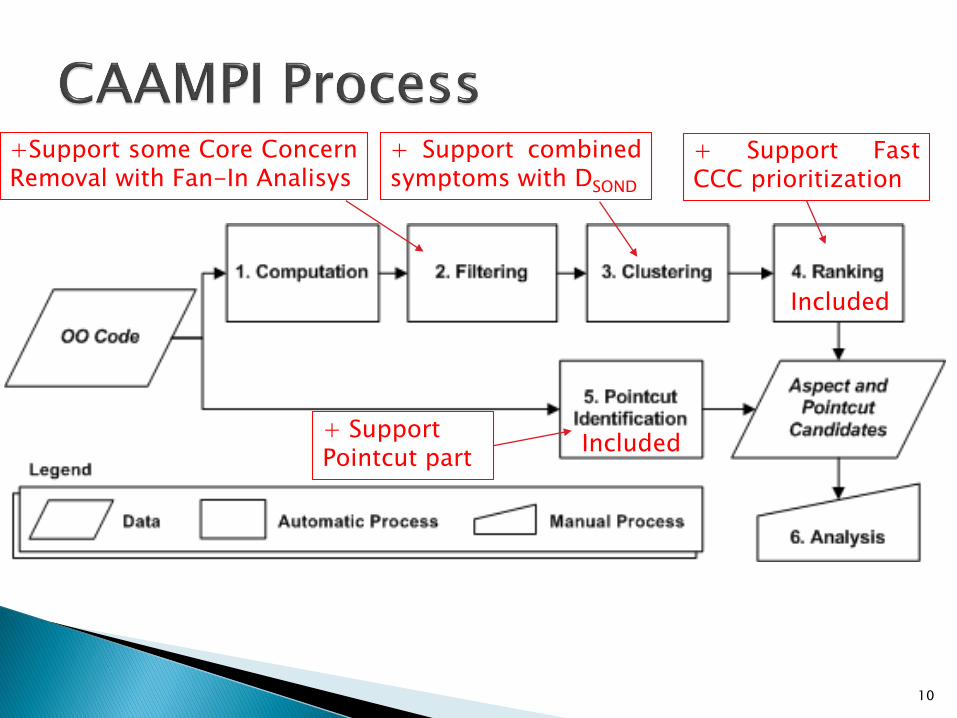
Introduces an integrated process to discoveraspect candidates and to identify pointcuts.
Input: OOP source code.
Output:◦ i) the groups obtained with clustering analysis
ranked by crosscutting concern potential, and
◦ ii) the pointcut candidates associated to eachcrosscutting concern.
9
10
+Support some Core ConcernRemoval with Fan-In Analisys
+ Support combinedsymptoms with DSOND
Included
+ SupportPointcut part
+ Support FastCCC prioritization
Included

DSOND (Combined) – It is an aggregatedfunction of three distance measures:◦ DS - Scattering
◦ DO - Operation Cloning
◦ DN - Name convention
Combines the measures by weight attributionto each symptom.
11

DS (Scattering) – Groups methods that arefrequently invoked by the same classes andmethods.
It is an enhancement of DCCC, addingpolymorphism treatment.
Polymorphism is given by treating all thepolymorphic methods as a group, counting allthe invocations to methods that overrides andrefines them.
12

DO (Operation Cloning) – Groups methods withsimilar or cloned operations.
Identifies code cloning by considering only theinvocations to methods and classes (Fan-out).
13
int i = 0;
while (i <=20)
{
i++;
(...)

DN (Name Convention) – Groups methods withsimilar name conventions.
Considers the method name, class name,parameter types and return type.
Uses the edit distance to measure the stringdistance (quantity of inserts, changes, deletes):◦ Levenstein Distance:
d(figureChanged, figureWillChange)=11/16 = 68,7%
14

Defines a score to each group found in theclustering step such that the elements ofgroups with higher score are more likely tobe crosscutting concerns than elements ofother ones with lower score.
K123 120
K232 104
K083 98
CrosscuttingPotencial

Group Scattering (GSRank): Scores based onthe number of distinct methods and classesthat invoke the methods belonging to agroup.
Group Fan-in (GFRank): Scores based on thesum of the fan-in associated to the methodsbelonging to a group.
16
m1()Fan-In: 2
m2()Fan-In: 2
GFRank = 4GSRank = 3

Interconnectivity: Computes how related themethods of the group are. If a group has lowinterconnectivity, so its score is reduced bythe factor.
GSIRank: GSRank with InterconnectivityReduction Factor.
GFIRank: GFRank with InterconnectivityReduction Factor.
17
m1()Fan-In: 2
m2()Fan-In: 2
GFIRank = 2GSIRank = 1,5
DS=0,5

Pointcut Identification Method based onAssociation Rule Mining on Source Code.◦ Item Set = Methods
◦ Transaction Set = Invocations.
The analysis is based on adjunct operationinvocations, when the consequent occursright after or right before the antecedent,considering the invocation sequence order.
18
Item Set
Transaction Set
a b c d

Before Execution
After Execution
Before Call
After Call PROCEEDEDb c
PROCEEDED ENDd
ANTECEDED STARTa
19
ANTECEDEDc b
T1 = {a,b,c,d}T2 = {a,p,b,c,q,d}
PC A Before Execution [T1,T2]
T1 = {a,b,c,d}T2 = {a,p,b,c,q,d} PC D After Execution [T1,T2]
T1 = {a,b,c,d}T2 = {a,p,b,c,q,d}T3 = {q,w,b,e}
PC B Before Call C
PC C After Call BT1 = {a,b,c,d}T2 = {a,p,b,c,q,d}T3 = {q,w,c,e}
* Rules found in format: IF Core THEN Crosscutting
20
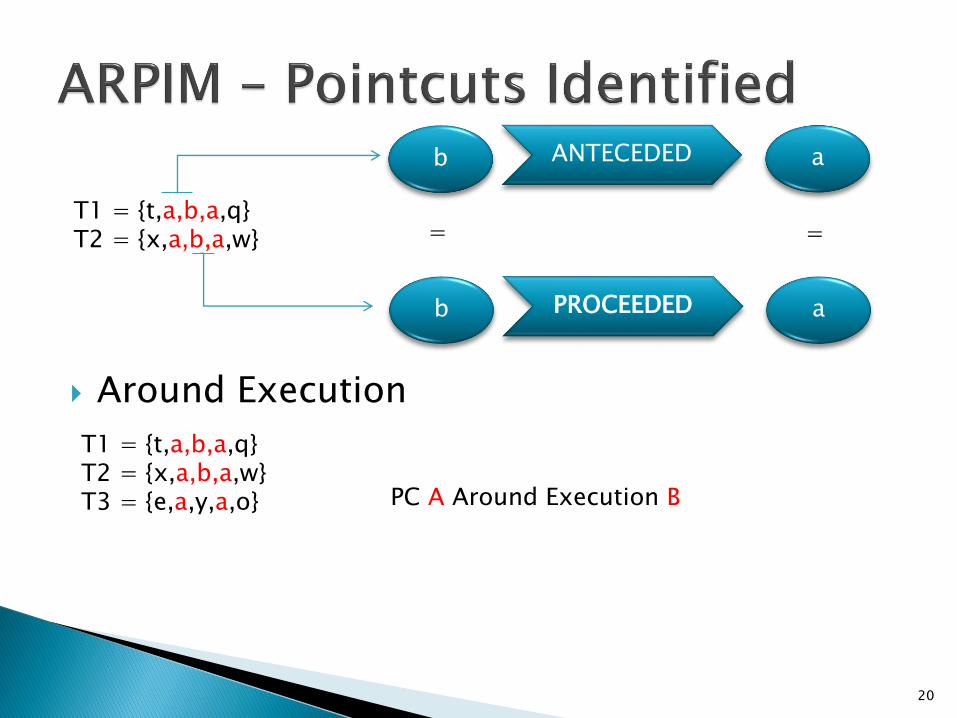
T1 = {t,a,b,a,q}T2 = {x,a,b,a,w}
PROCEEDEDb a
ANTECEDEDb a
Around Execution
T1 = {t,a,b,a,q}T2 = {x,a,b,a,w}T3 = {e,a,y,a,o} PC A Around Execution B
= =

21

22
JHotDraw v5.4b1
• Graphical Editor
HSQLDB v1.8.0.2
• Database Server
Tomcat v5.5.17
• Java Web Server

Were combined:◦ Clustering Algorithms: k-medoids, Hierarchical and
Chameleon.◦ Distance Measures: DSOND, DS, DO, DN, DCCC e DHBZH.◦ 18 instances.
Parameter calibration to each combinationalgorithm X measure X system.
Evaluation Indexes: DISP and DIV. Based onthe principle that an optimal partition is thatwhere each group represents a singlecrosscutting concern, and, each crosscuttingconcern is represented by a single group.
23
24
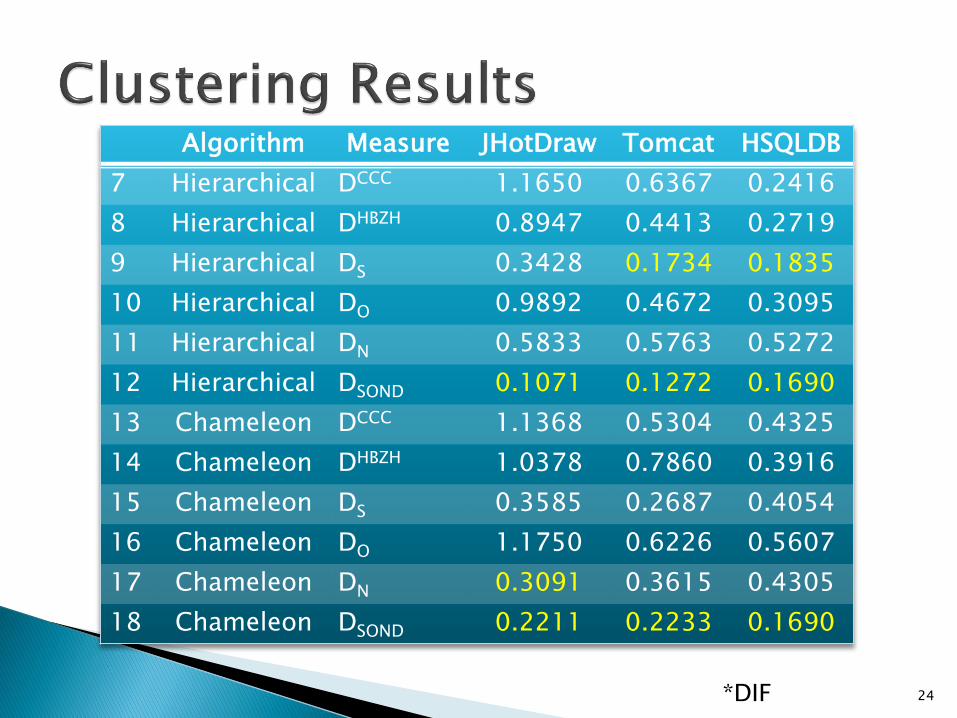
Algorithm Measure JHotDraw Tomcat HSQLDB
7 Hierarchical DCCC 1.1650 0.6367 0.2416
8 Hierarchical DHBZH 0.8947 0.4413 0.2719
9 Hierarchical DS 0.3428 0.1734 0.1835
10 Hierarchical DO 0.9892 0.4672 0.3095
11 Hierarchical DN 0.5833 0.5763 0.5272
12 Hierarchical DSOND 0.1071 0.1272 0.1690
13 Chameleon DCCC 1.1368 0.5304 0.4325
14 Chameleon DHBZH 1.0378 0.7860 0.3916
15 Chameleon DS 0.3585 0.2687 0.4054
16 Chameleon DO 1.1750 0.6226 0.5607
17 Chameleon DN 0.3091 0.3615 0.4305
18 Chameleon DSOND 0.2211 0.2233 0.1690
*DIF

The combination DSOND with the Hierarchicalalgorithm obtained the best results for allsystems. 91% efficacy.
The best results obtained by the clusteringalgorithms were with DSOND.
The best results were obtained by hierarchicalalgorithms.
Combinations Hierarchical and DS, andCHAMELEON and DN also obtained goodresults.
25

Ranking Measures:◦ GSRank◦ GSIRank◦ GFRank◦ GFIRank
Ranking applied to the best instance obtainedin clustering step in each system. (I12)
Evaluation Index: RANK - Based on theprinciple that in an optimal ranking the ngroups with higher score belongs to acrosscutting concern set composed by ninstances
26

27
Measure JHotDraw Tomcat HSQLDB
GSRank 0.9013 0.9647 0.7444
GSIRank 0.8682 0.9678 0.7457
GFRank 0.9114 0.8682 0.7299
GFIRank 0.9037 0.9517 0.7552
Any measure was absolutely better thanothers, considering the three cases.
The most notably measures are GSIRank andGFIRank, measures that use theinterconnectivity as a reduction factor.

Only ARPIM.
ARPIM applied to the best instance obtainedin clustering step in each system. (I12)
Evaluation Indexes: COV and USE - Based onthe principle that an optimal pointcutidentification occurs when at least onepointcut was identified for each crosscutting,and that each pointcut is useful on therefactoring.
28
29
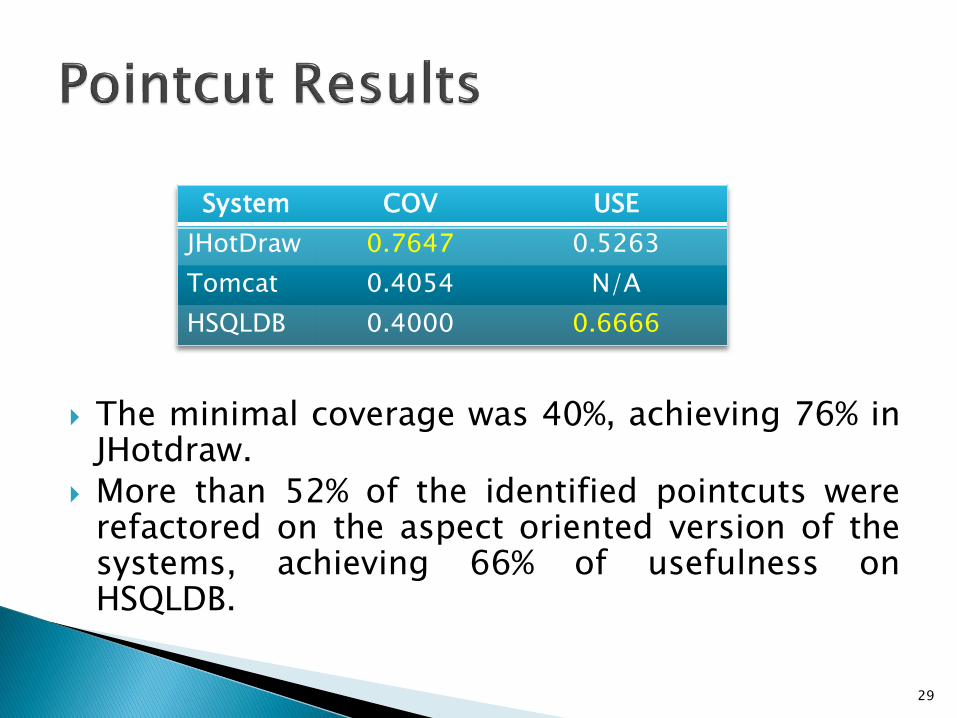
System COV USE
JHotDraw 0.7647 0.5263
Tomcat 0.4054 N/A
HSQLDB 0.4000 0.6666
The minimal coverage was 40%, achieving 76% inJHotdraw.
More than 52% of the identified pointcuts wererefactored on the aspect oriented version of thesystems, achieving 66% of usefulness onHSQLDB.

30

The CAAMPI process allows the analyst toprioritize the aspect candidates analysis byusing the ranking information, and providesthe advice and pointcut information about theaspect candidates.
Clustering: The introduced measure DSOND isthe best distance measure among theevaluated ones, independently of system andclustering algorithm, with 91% of efficacy.
Ranking: Measures proposed make feasible theaspect candidates prioritization by crosscuttingpotential.
31

Pointcut: ARPIM method enables theidentification of the pointcuts with more 40%of coverage and 52% of usefulness, whencompared with the aspectized version of thesystems.
32

Filter step can be improved, by using heuristics or patterns catalog, to automatically eliminate utility and accessor methods that do not follow the get and set conventions.
Multi-objective optimization algorithms should be explored to eliminate the weights calibration task.
To explore ways to classify the type ofcrosscutting concern represented by thecandidate, such as persistence, logging, etc.◦ Patterns recognition, natural language processing, etc.
33

Edison Klafke Fillus◦ Software Engineering Research Group◦ Informatics Department◦ UFPR - Federal University of Paraná◦ [email protected]
34





























