Embed Size (px)
Citation preview

Active learning based robust monocular vehicledetection for on-road safety systems
Sayanan Sivaraman and Mohan Manubhai TrivediLISA: Laboratory for Intelligent and Safe Automobiles
University of California, San Diego{ssivaram,mtrivedi}@ucsd.edu
Abstract—In this paper, the framework is presented for usingactive learning to train a robust monocular on-road vehicledetector for active safety, based on Adaboost classificationand Haar-like rectangular image features. An initial vehicledetector was trained using Adaboost and Haar-like rectangularimage features and was very susceptible to false positives.This detector was run on an independent highway dataset,storing true detections and false positives to obtain a selectivelysampled training set for the active learning training iteration.Various configurations of the newly trained classifier weretested, experimenting with the trade-off between detection rateand false detection rate. Experimental results show that thismethod yields a vehicle classifier with a high detection rateand low false detection rate on real data, yielding a valuableaddition to environmental awareness for intelligent active safetysystems in vehicles.
Index Terms -Active Learning, Active Safety, Vehicle Detection,Intelligent Vehicles.
I. INTRODUCTION
Auto accidents injure 10 million people each year, and twoto three million people are injured seriously on our roads. It isestimated that between 1 and 3 percent of the world’s domesticproduct is spent on the medical care, property damage, andother costs associated with auto accidents [2]. Accordingto accident statistics, the main threats to a driver are othervehicles on the road. As a result, over the years, many vehiclesafety systems have been proposed. Vehicle safety systemsfall into two classes: “passive,” and “active.” Passive safetysystems mitigate or minimize the severity of injuries causedby an accident. Examples of passive safety systems includeseat belts and shatter-resistant windshields.
Active safety systems, by contrast, work to avoid accidents.Of course avoiding an accident is preferable to simply miti-gating the severity of the injuries suffered.
The design of intelligent active safety systems presentsmany difficult challenges. In particular, it is necessary thatsuch systems accurately, reliably, and quickly identify danger-ous conditions [18].
An effective intelligent driver assistance system for activesafety should have a holistic understanding of the drivingenvironment, the vehicle, and the driver [1]. Since the late1990’s, it has been recognized that computer vision is a criticaltechnology for the development of intelligent vehicles [18].This paper focuses on using an application of computer visionto help understand the driving environment in the context of
building a holistic intelligent system for active safety. The goalis to build a surround model in an integrated scenario, and thusbuild a full panoramic awareness of the driving environment[19].
It is in this context of active safety systems that we presenta framework for iteratively training an on-board monocularvehicle detector using active learning. A robust monocularvehicle detector that achieves a high detection rate and alow false positive rate is presented. The detector has beeniteratively trained, using the active learning technique ofselective sampling [17] to train a new detector against a currentdetector’s false positive data. Using active learning to refinethe classifier yields a significant drop in false positives pervideo frame and false detection rates, while maintaining ahigh vehicle detection rate. The rest of the paper is organizedas follows. In Section III we discuss the vehicle detectionalgorithm. In Section IV we detail our application of activelearning to training. In Section V we present a quantitativeanalysis of our vehicle detector’s performance on real data ina variety of lighting conditions, and in Section VI we offersome concluding remarks and discuss future works.
II. RELATED STUDIES
In recent years, many on-road vehicle detectors have beenpresented. In [3] a good overview of current visual objectdetection techniques is presented. Recent trends in vehicledetection and tracking are also reviewed and critiqued in [2].
Wang et. al introduced a vehicle detector using PCA andICA to do classification on a statistical model, and increasedits speed by modeling the PCA and ICA vectors with aweighted Gaussian Mixture Model. This detector was capableof detecting both the front and back of a vehicle [4]. Arrospideet. al [5] performed detection and tracking that evaluatedthe quality of the tracking results, triggering new detectionsto restart the tracking process when the quality metric fellbelow a required level. The quality metric was based on thecomputation of a symmetry value over the tracked region.
In [6] a multilayer feedforward neural networks basedapproach was presented for vehicle detection, the linear outputlayer replaced by a Mahanalobis kernel. This neural networksbased approach enabled very fast detection times on grayscaleimages at 32x32 resolution. In [7], Cao et. al implementeda monocular vehicle tracker based on an optimized opticalflow, using a 3D Pulse-Coupled Neural Network. This tracker
399978-1-4244-3504-3/09/$25.00 ©2009 IEEE

performed better as the speed difference between the egovehicle and the tracked vehicle increased.
Chan et al. [8] built a detector that used vertical andhorizontal symmetry, as well as tail light cues in a statisticalmodel for detection, tracking detected vehicles on the roadusing particle filters. This detector and tracker was robust todifferent lighting conditions.
Hasselhoff et al. [11] built five vehicle detectors usingHaar-like wavelet features, learned with Adaboost, a detectionsystem first used for face detection in [12]. Hasselhoff etal. tested the performance of classifiers trained with imagesof various resolutions, from the smallest resolution of 18x18pixels to the largest of 50x50 pixels. The trade-off betweenclassifier performance and training time as a function oftraining image resolution was discussed.
Recently visual detectors have been used in fusion schemeswith radar and laser. Such schemes often use the radar orlaser to locate areas of interest in the images, and then performvision-based detection. In [9], Alessandretti et al. implementeda vehicle and guardrail detector using radar and video fusion.In [10], a fusion of laser scanning and vision-based vehicledetection was implemented. The laser scanner estimated thedistance and orientation of vehicles on the road, and dependingon this orientation, the visual detector either ran a rear/front orside vehicle detector. The performance of the fusion schemewas reported to be better than the performance of eitherdetection scheme by itself. Table 1 contains a comparison ofdifferent vehicle detection systems.
III. VEHICLE DETECTION
Robust on-board vehicle detection is a challenging computervision problem. Roads are dynamic environments, with ever-changing backgrounds and illuminations. The camera mountedin the ego vehicle and the other vehicles on the road are inmotion, so the sizes and locations of vehicles are constantlychanging. In addition, there is high variability in the shape,size, and appearance of vehicles found on a given road.
For this object detection task, we have chosen to use aboosted cascade classifiers of Haar-like rectangular features,which was introduced by Viola and Jones [12] in the context offace detection. Since then, many papers have used this objectdetection framework in on-road vehicle detection systems suchas [11],[15],[10]. The set of Haar-like features is well-suited tothe detection of the shape of vehicles, because the rectangularfeatures are sensitive to edges, bars, vertical and horizontaldetails, and symmetric structures. Figure 1 shows examples ofrectangular features.
In addition, the algorithm allows for rapid object detectionthat can be exploited in building a real-time system. Part of thisis due to the fact that feature extraction is extremely fast andefficient, due to the use of the integral image, an intermediaterepresentation for the image. Using the integral image rep-resentation, the feature extraction of a Haar-like rectangularfeature can be computed in just four array references. Theresulting extracted values are effective weak learners [12],[10],which are then classified by Adaboost.
Fig. 1. Examples of Haar-like features used in the vehicle detector
Adaboost is a discriminative learning algorithm, whichperforms classification based on a weighted majority vote ofweak learners[20] . We use Adaboost learning to construct acascade of several binary classifier stages R1...RN . The earlierstages in the cascade eliminate many non-vehicle regions withvery little processing [12]. The decision rule at each stage ismade based on a threshold of scores computed from featureextraction. Each stage of the cascade reduces the number ofvehicle candidates, and if a candidate image region survivesuntil it is output from the final stage, it is classified as apositive detection [10]. Figure 2 shows a schematic of thecascade classifier.
Fig. 2. Schematic of AdaBoost Classification Cascade. The earlier stages inthe cascade eliminate many non-vehicle regions with very little processing.
IV. ACTIVE LEARNING
A. Theoretical Justification
Conventional supervised learning of a binary classifierlearns from examples, labeled ‘positive’ and ‘negative.’ Simplylearning from examples, however, is not a universally appli-cable and effective method. In many natural and biologicalsystems, active learning is utilized to examine a problem [17].Active learning refers to a paradigm in which the learningprocess exhibits some degree of control over the training data.In the case of training a vehicle detector, our two trainingclasses are ‘vehicle,’ and ‘non-vehicle.’ Our goal in training isto build a detector than correctly classifies vehicles as vehicles,and non vehicles as non-vehicles.
However, in the feature space of vehicles and non-vehicles,there is a region of uncertainty, in which objects that are
400
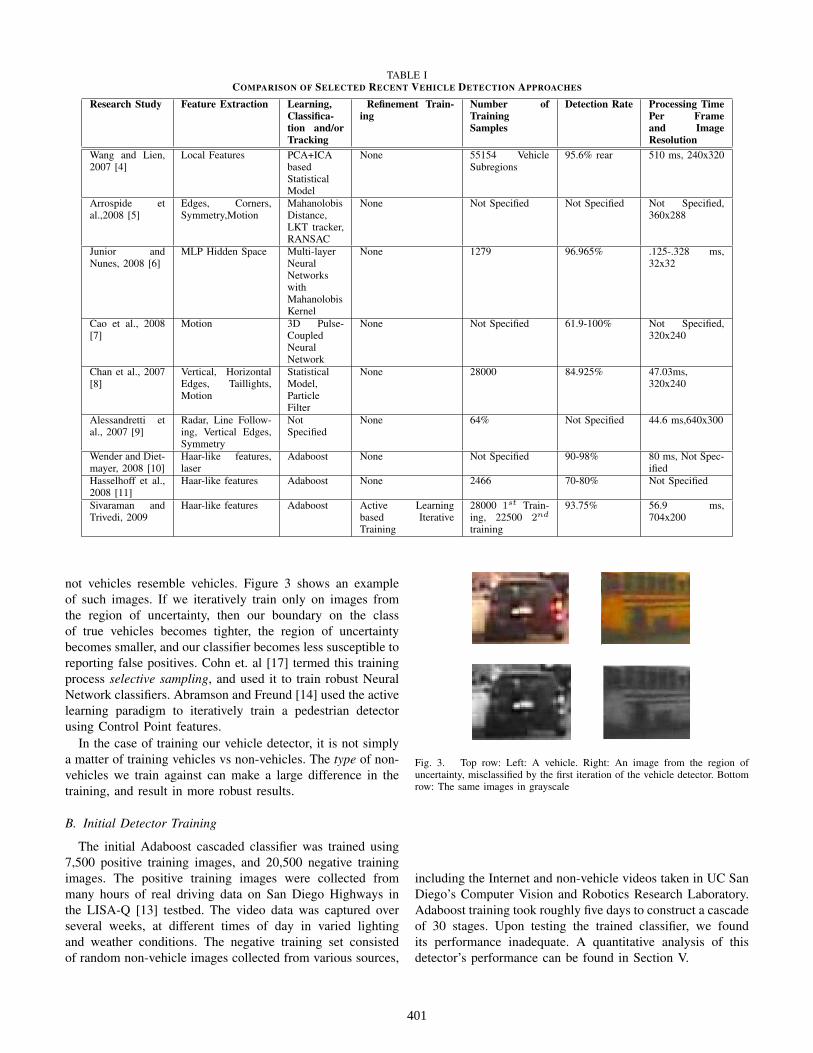
TABLE ICOMPARISON OF SELECTED RECENT VEHICLE DETECTION APPROACHES
Research Study Feature Extraction Learning,Classifica-tion and/orTracking
Refinement Train-ing
Number ofTrainingSamples
Detection Rate Processing TimePer Frameand ImageResolution
Wang and Lien,2007 [4]
Local Features PCA+ICAbasedStatisticalModel
None 55154 VehicleSubregions
95.6% rear 510 ms, 240x320
Arrospide etal.,2008 [5]
Edges, Corners,Symmetry,Motion
MahanolobisDistance,LKT tracker,RANSAC
None Not Specified Not Specified Not Specified,360x288
Junior andNunes, 2008 [6]
MLP Hidden Space Multi-layerNeuralNetworkswithMahanolobisKernel
None 1279 96.965% .125-.328 ms,32x32
Cao et al., 2008[7]
Motion 3D Pulse-CoupledNeuralNetwork
None Not Specified 61.9-100% Not Specified,320x240
Chan et al., 2007[8]
Vertical, HorizontalEdges, Taillights,Motion
StatisticalModel,ParticleFilter
None 28000 84.925% 47.03ms,320x240
Alessandretti etal., 2007 [9]
Radar, Line Follow-ing, Vertical Edges,Symmetry
NotSpecified
None 64% Not Specified 44.6 ms,640x300
Wender and Diet-mayer, 2008 [10]
Haar-like features,laser
Adaboost None Not Specified 90-98% 80 ms, Not Spec-ified
Hasselhoff et al.,2008 [11]
Haar-like features Adaboost None 2466 70-80% Not Specified
Sivaraman andTrivedi, 2009
Haar-like features Adaboost Active Learningbased IterativeTraining
28000 1st Train-ing, 22500 2nd
training
93.75% 56.9 ms,704x200
not vehicles resemble vehicles. Figure 3 shows an exampleof such images. If we iteratively train only on images fromthe region of uncertainty, then our boundary on the classof true vehicles becomes tighter, the region of uncertaintybecomes smaller, and our classifier becomes less susceptible toreporting false positives. Cohn et. al [17] termed this trainingprocess selective sampling, and used it to train robust NeuralNetwork classifiers. Abramson and Freund [14] used the activelearning paradigm to iteratively train a pedestrian detectorusing Control Point features.
In the case of training our vehicle detector, it is not simplya matter of training vehicles vs non-vehicles. The type of non-vehicles we train against can make a large difference in thetraining, and result in more robust results.
B. Initial Detector Training
The initial Adaboost cascaded classifier was trained using7,500 positive training images, and 20,500 negative trainingimages. The positive training images were collected frommany hours of real driving data on San Diego Highways inthe LISA-Q [13] testbed. The video data was captured overseveral weeks, at different times of day in varied lightingand weather conditions. The negative training set consistedof random non-vehicle images collected from various sources,
Fig. 3. Top row: Left: A vehicle. Right: An image from the region ofuncertainty, misclassified by the first iteration of the vehicle detector. Bottomrow: The same images in grayscale
including the Internet and non-vehicle videos taken in UC SanDiego’s Computer Vision and Robotics Research Laboratory.Adaboost training took roughly five days to construct a cascadeof 30 stages. Upon testing the trained classifier, we foundits performance inadequate. A quantitative analysis of thisdetector’s performance can be found in Section V.
401

Fig. 4. Screen shot of the Manual Annotation Program. True positives areboxed in green, and false detections have been marked blue.
C. Active Learning Stage
Given a detector that allows too many false positives, wewould like to retrain it such that the decision boundary is closerto the positive training examples P1...PM in the feature space.In the case of a vehicle detector, this means using negativetraining examples N1...NK that are closer to the classificationboundary. The most efficient and effective way to to collectexamples from the region of uncertainty is to run the vehicledetector on real world data, crop out the false positive regions,and save those image regions as a negative training set. Ifwe likewise save true positive detections as positive trainingexamples, collecting new training data is less labor intensive[14].
In order to amass such a set of training samples, wecollected an independent data set, also captured using theLISA-Q [13] testbed. The video data was captured on SanDiego roads and highways at various times of day, and inall had a duration of three hours, captured at 30 framesper second. We then ran our detector on the independentlycaptured data, and used a manual annotator developed usingOpenCV[16] to label the detections as true positives or falsedetections. The annotation program also allowed us to annotateany missed detections. The annotation program cropped themissed detection and positive detection regions, storing themfor a future training as the positive data set P1...PM . Italso cropped the false positive regions and stored those asthe negative training set N1...NK . Figure 4 shows a screenshot of the manual annotation program, and Figure 6 showsexamples of positive and false detections.
For the second iteration of training there were 10,000 posi-tive images, and 12,172 negative images. Using the manualannotation program it took only 10 days for one personto collect and crop all 22,172 training examples for theactive learning-based training. The negative training imagesconsisted exclusively of false detections. Adaboost trainingtook approximately 14 days to train a cascade of 20 stageson a 2.9GHz Pentium desktop computer. Figure 5 shows aflow chart of the overall training framework.
V. EXPERIMENTAL DESIGN
A. Testing
To test detector, we took another real traffic video in theLISA-Q testbed [13], and ran our detector on this independent
data set. The detectors were run on 500 frames with variousilluminations and backgrounds.
B. Performance Metrics
We have chosen three performance metrics that accuratelycharacterize the performance of an object detector. TPR isthe true positive rate, the proportion of vehicles in video thatwere detected. FDR is the false detection rate, the proportionof detections that were not true vehicles. FP/Frame isthe number of false detections per frame. We have formallydefined these metrics in equations (1)-(3) below.
(1) TPR = Number of Detected V ehiclesTotal Number of V ehicles
(2) FDR = Number of False PositivesNumber Detected+ Number of False Positives
(3) FP/Frame = Number of False PositivesTotal Number of Frames Processed
C. Quantitative Analysis
Initially, we tested the detector that had resulted from thefirst Adaboost training, and the detector that resulted fromthe second training. As Table 2 shows, the false detectionrate and the false positive per frame rate reduced drasticallyafter training. However, the detection rate also reduced. Wehad trained the second iteration classifier with 20 stages, but
7500 Manually Cropped Vehicles from Real Data
21,500 random non-vehicle images
Initial
Training
First Detector
Real on-road data
Manual Annotator
Cropped Regions
Active Learning
New Detector
Detections on
Real Data
Fig. 5. Schematic of the Framework for Training the Vehicle Detector usingActive Learning
Fig. 6. Example of true positive detection [left] and false positive [right]used in the second iteration of training
402
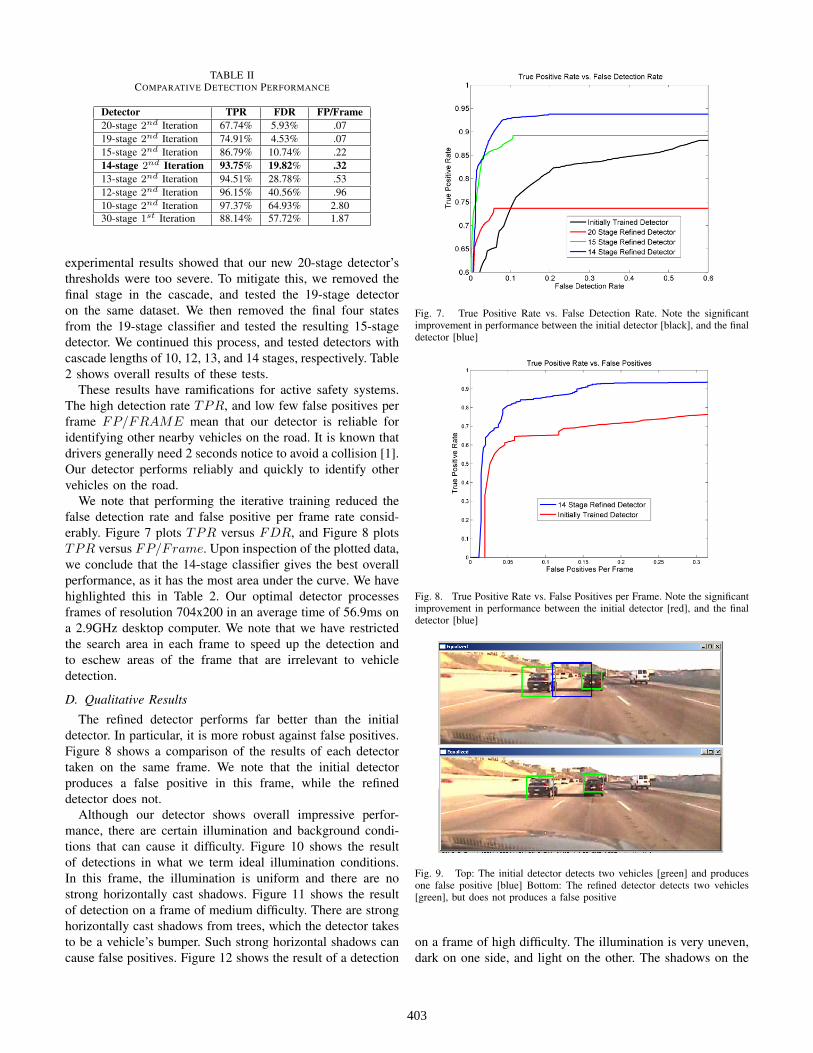
TABLE IICOMPARATIVE DETECTION PERFORMANCE
Detector TPR FDR FP/Frame20-stage 2nd Iteration 67.74% 5.93% .0719-stage 2nd Iteration 74.91% 4.53% .0715-stage 2nd Iteration 86.79% 10.74% .2214-stage 2nd Iteration 93.75% 19.82% .3213-stage 2nd Iteration 94.51% 28.78% .5312-stage 2nd Iteration 96.15% 40.56% .9610-stage 2nd Iteration 97.37% 64.93% 2.8030-stage 1st Iteration 88.14% 57.72% 1.87
experimental results showed that our new 20-stage detector’sthresholds were too severe. To mitigate this, we removed thefinal stage in the cascade, and tested the 19-stage detectoron the same dataset. We then removed the final four statesfrom the 19-stage classifier and tested the resulting 15-stagedetector. We continued this process, and tested detectors withcascade lengths of 10, 12, 13, and 14 stages, respectively. Table2 shows overall results of these tests.
These results have ramifications for active safety systems.The high detection rate TPR, and low few false positives perframe FP/FRAME mean that our detector is reliable foridentifying other nearby vehicles on the road. It is known thatdrivers generally need 2 seconds notice to avoid a collision [1].Our detector performs reliably and quickly to identify othervehicles on the road.
We note that performing the iterative training reduced thefalse detection rate and false positive per frame rate consid-erably. Figure 7 plots TPR versus FDR, and Figure 8 plotsTPR versus FP/Frame. Upon inspection of the plotted data,we conclude that the 14-stage classifier gives the best overallperformance, as it has the most area under the curve. We havehighlighted this in Table 2. Our optimal detector processesframes of resolution 704x200 in an average time of 56.9ms ona 2.9GHz desktop computer. We note that we have restrictedthe search area in each frame to speed up the detection andto eschew areas of the frame that are irrelevant to vehicledetection.
D. Qualitative Results
The refined detector performs far better than the initialdetector. In particular, it is more robust against false positives.Figure 8 shows a comparison of the results of each detectortaken on the same frame. We note that the initial detectorproduces a false positive in this frame, while the refineddetector does not.
Although our detector shows overall impressive perfor-mance, there are certain illumination and background condi-tions that can cause it difficulty. Figure 10 shows the resultof detections in what we term ideal illumination conditions.In this frame, the illumination is uniform and there are nostrong horizontally cast shadows. Figure 11 shows the resultof detection on a frame of medium difficulty. There are stronghorizontally cast shadows from trees, which the detector takesto be a vehicle’s bumper. Such strong horizontal shadows cancause false positives. Figure 12 shows the result of a detection
Fig. 7. True Positive Rate vs. False Detection Rate. Note the significantimprovement in performance between the initial detector [black], and the finaldetector [blue]
Fig. 8. True Positive Rate vs. False Positives per Frame. Note the significantimprovement in performance between the initial detector [red], and the finaldetector [blue]
Fig. 9. Top: The initial detector detects two vehicles [green] and producesone false positive [blue] Bottom: The refined detector detects two vehicles[green], but does not produces a false positive
on a frame of high difficulty. The illumination is very uneven,dark on one side, and light on the other. The shadows on the
403

left side of the frame prevent detection of the vehicle on theleft. In addition, there is a complex background of trees, whosestrong vertical edges and shadows can cause false positives.
Fig. 10. Ideal Illumination Conditions. Note the uniform illumination. Thedetector performs well here.
Fig. 11. Medium Difficulty Frame. Note the stark cast shadows, which resultin false positives
Fig. 12. Difficult Frame. Note the vehicle on the left is all but occluded byshadow. The image’s illumination is very stark and uneven. The complex treebackground results in a false positive
VI. CONCLUDING REMARKS
We have presented the framework for dramatically improv-ing the performance of an on-board vehicle detector by suc-cessfully applying active learning principles. Our detector hasdemonstrated strong performance in a variety of illuminationsand backgrounds. Our optimal vehicle detector achieved anaverage detection rate of 93.75%, a false detection rate of19.82%, and an average of .32 false positives per frame. Ourdetector can process a frame in 56.9ms on a 2.9GHz desktopcomputer. On-board vehicle detection is a difficult task, dueto variations in the appearance of vehicles, illumination, andbackgrounds. Our system performs quickly, reliably, and accu-rately in most normal driving conditions, and can be integratedas part of an overall holistic active safety system. It will be atopic of further studies to integrate this detection system withother on-board instrumentation to build a full environmentalawareness on the road.
ACKNOWLEDGMENTS
The authors would like to thank the UC Discovery Grant,Volkswagen’s ERL, fellow LISA team members BrendanMorris, Anup Doshi, Cuong Tran, Shankar Shivappa, andformer LISA team members Dr. Stephen Krotosky and Dr.Shinko Cheng for all their help and contributions.
REFERENCES
[1] M.M. Trivedi, S. Cheng, Holistic Sensing and Active Displays forIntelligent Driver Support Systems, IEEE Computer Magazine, May 2007.
[2] Z. Sun, G. Bebis, R. Miller, On-road Vehicle Detection: a Review, PatternAnalysis and Machine Intelligence, IEEE Transactions on , vol.28, no.5,pp.694-711, May 2006.
[3] A. Laika, W. Stechele, A Review of Different Object Recognition Meth-ods for the Application in Driver Assistance Systems, Image Analysis forMultimedia Interactive Services, 2007. WIAMIS ’07. Eighth InternationalWorkshop on pp. 10 - 10 ,6-8 June 2007.
[4] C. Wang; J.-J. J. Lien, Automatic Vehicle Detection Using Local Fea-tures A Statistical Approach, Intelligent Transportation Systems, IEEETransactions on , vol.9, no.1, pp.83-96, March 2008
[5] J. Arrospide, L. Salgado, M. Nieto, F. Jaureguizar, On-board RobustVehicle Detection and Tracking Using Adaptive Quality Evaluation,Image Processing, 15th IEEE International Conference on, pp.2008-2011,12-15 Oct. 2008.
[6] O.L. Junior, U. Nunes,Improving the Generalization Properties of NeuralNetworks: an Application to Vehicle Detection, Intelligent TransportationSystems, 11th International IEEE Conference on, pp.310-315, 12-15 Oct.2008.
[7] Y. Cao, A. Renfrew, P. Cook, Vehicle Motion Analysis Based on aMonocular Vision System, Road Transport Information and Control -RTIC 2008 and ITS United Kingdom Members’ Conference, pp.1-6, 20-22 May 2008.
[8] Y. Chan, S. Huang, L. Fu, P. Hsiao, Vehicle Detection under VariousLighting Conditions by Incorporating Particle Filter, Intelligent Trans-portation Systems Conference, 2007,pp.534-539, Sept. 30 2007-Oct. 32007.
[9] G. Alessandretti, A.Broggi, P. Cerri, Vehicle and Guard Rail DetectionUsing Radar and Vision Data Fusion,Intelligent Transportation Systems,IEEE Transactions on , vol.8, no.1, pp.95-105, March 2007.
[10] S. Wender, K. Dietmayer, 3D vehicle Detection Using a Laser Scannerand a Video Camera, Intelligent Transport Systems, IET , vol.2, no.2,pp.105-112, June 2008.
[11] A. Haselhoff, S. Schauland, A. Kummert, A Signal Theoretic Approachto Measure the Influence of Image Resolution for Appearance-basedVehicle Detection, Intelligent Vehicles Symposium, IEEE, pp.822-827, 4-6June 2008.
[12] P. Viola, M. Jones, Rapid Object Detection Using a Boosted Cascade ofSimple Features, Computer Vision and Pattern Recognition, Proceedingsof the 2001 IEEE Computer Society Conference on , vol.1, no., pp. I-511-I-518 vol.1, 2001.
[13] J. McCall, O. Achler, M. M. Trivedi, Design of an Instrumented VehicleTestbed for Developing Human Centered Driver Support System, In Proc.IEEE Intelligent Vehicles Symposium, Jun. 2004.
[14] Y. Abramson, Y. Freund, SEmi-automatic VIsuaL LEarning (SEVILLE):Tutorial on Active Learning for Visual Object Recognition, ComputerVision and Pattern Recognition, Proceedings of the 2005 IEEE ComputerSociety Conference on.
[15] D. Ponsa, A.Lopez, F. Lumbreras, J. Serrat, T. Graf, 3D vehiclesensor based on monocular vision, Intelligent Transportation Systems,Proceedings IEEE , pp. 1096-1101, 13-15 Sept. 2005.
[16] Open source computer vision library, c and c++ libraryhttp://www.intel.com/technology/computing/opencv.
[17] D. Cohn, L. Atlas, R. Ladner,Improving Generalization With ActiveLearning, Machine Learning. Volume 15, Number 2, pp. 201-221, May1994.
[18] M.M. Trivedi, T. Gandhi, J. McCall, Looking-In and Looking-Outof a Vehicle: Computer-Vision-Based Enhanced Vehicle Safety, IEEETransactions on Intelligent Transportation Systems, pp. 108-120, March2007.
[19] T. Gandhi, M.M. Trivedi, Vehicle Surround Capture: Survey of Tech-niques and a Novel Omni Video Based Approach for Dynamic PanoramicSurround Maps, IEEE Transactions on Intelligent Transportation Systems,Sept 2006 .
[20] Y. Freund, R. E. Schapire, A Short Introduction to Boosting,Journalof Japanese Society for Artificial Intelligence, 14(5):771-780, September,1999.
404

![EGO-SLAM: A Robust Monocular SLAM for …arXiv:1707.05564v2 [cs.CV] 17 Nov 2018 In this paper, we investigate the monocular SLAM prob-lem with a special emphasis on EGOcentric videos,](https://img.pdfslide.us/doc/110x75/5fe2bff5b533fd76167f3e75/ego-slam-a-robust-monocular-slam-for-arxiv170705564v2-cscv-17-nov-2018-in.jpg)























