Embed Size (px)
Citation preview

June 2015
OpenStack and BigData
1
Yaron Haviv - Founder & [email protected] Personal Blog: SDSBlog.com

iguazu Falls (Brazil) 1746 M3/sec flow 82m drop 2700m wide 275 discrete falls
Innovating storage and data management to address Big Data applications’ challenges

VelocityVariety
Volume
3 © 2015
Big Data is Expanding on all Three Fronts At an Increasing Rate
BatchTable
MB
GB
PeriodicDatabase
TB
NearReal-Time
Social
Web
Audio
PB
Real-Time
Photo
Video
Mobile
Unstructured

Hadoop Original Assumptions Have Changed Dramatically
• Data was uploaded/copied for batch processing, no data modification, tiering, ..
• Full data scan, not incremental processing• Sequential IO, large files – no small random
IOPs• Disks were faster than the network (1GbE)• Job scheduling assumed batch jobs• Not mission critical, can reboot if needed• Internal data, no need for security
• Data needs to be extracted/ingested from variety of sources in real time, IoT
• Processing must be incremental … you don’t go over a petabyte on every update
• Billions of data objects and many are small• Want to use clouds or containers• Data is mobile and networks are fast• Batch coupled with always-on services • High-availability and security are critical
© 20154
10 Years Ago Today
BigData and Hadoop Must Evolve To Meet The New Challenges

Big Data Deployment Architectures Have Evolved to Address the 3 V’s
In-MemoryProcessing
State Checkpoints
BatchProcessing
Data Sources
Ingestion
Raw Data• Input Datasets• Logs, Time Series• Media, Video
Aggregated Data• Files, Records, Counters• Transactional Updates
Analytics, OLTP, Users
• Durable Buffer• Inline processing
TempFiles
Data Lake

Big Data Deployment Architectures Have Evolved to Address the 3 V’s
In-MemoryProcessing
BatchProcessing
Data Sources
Ingestion
Raw Data• Input Datasets• Logs, Time Series• Media, Video
Aggregated Data• Files, Records, Counters• Transactional Updates
Analytics, OLTP, Users
• Durable Buffer• Inline processing
Complex and Immature Stack, Resource Intensive, Long Integration
State Checkpoints
TempFiles

7 © 2014
• Application Dedicated Hardware (CPU, Memory, HDDs, SSDs)• Minimum of 3 Nodes per Application, Duplicating the Same Data • Nightmare to Build, Maintain, Swap and Manage Applications
Today Big Data Applications = Tightly Coupled Silos
Application A Application B Application C

Virtualization Doesn’t Work for BigData
© 20148
BigData and Virtualization
Virtualized/Containerized Servers
Hypervisor Data ManagementHypervisor
HDFS HDFS
SAN/vSAN Storage ProtocolsStorage Device Data Management
Shared Storage
=
Hypervisor Storage Stack Redundant Layers of Storage Management- Significant overhead and latency - More replicas than needed - Break application availability and
locality assumptions - Management complexity

Hadoop & Virtualization
9
HDFS over Virtualized Hardware is 2x slower
Source: http://www.slideshare.net/yuzhidong/benchmarking-sahara-based-big-data-as-a-service-solutions

Rate of Unstructured Data Generation Grows Exponentially
10
4300% Faster Data Growth Rate by 2020
Storage must be elastic, dense, and highly efficient

How to Simplify Big Data Infrastructure ?
11
Disk
Disk
Disk
Obj
Disk
Disk
Disk
Obj
Disk
Disk
Disk
Obj
Low-costEndless Scalability and
Global Distribution
Gather Data Process Data(in VMs & Containers)
Consume Data
Shared Data Repository (Object Storage) e.g. Amazon S3, Swift
Home Grown Apps
What’s missing ?
Performance & Latency
? ? ? ? ?
Application Integration
Consistency
Security & Policies
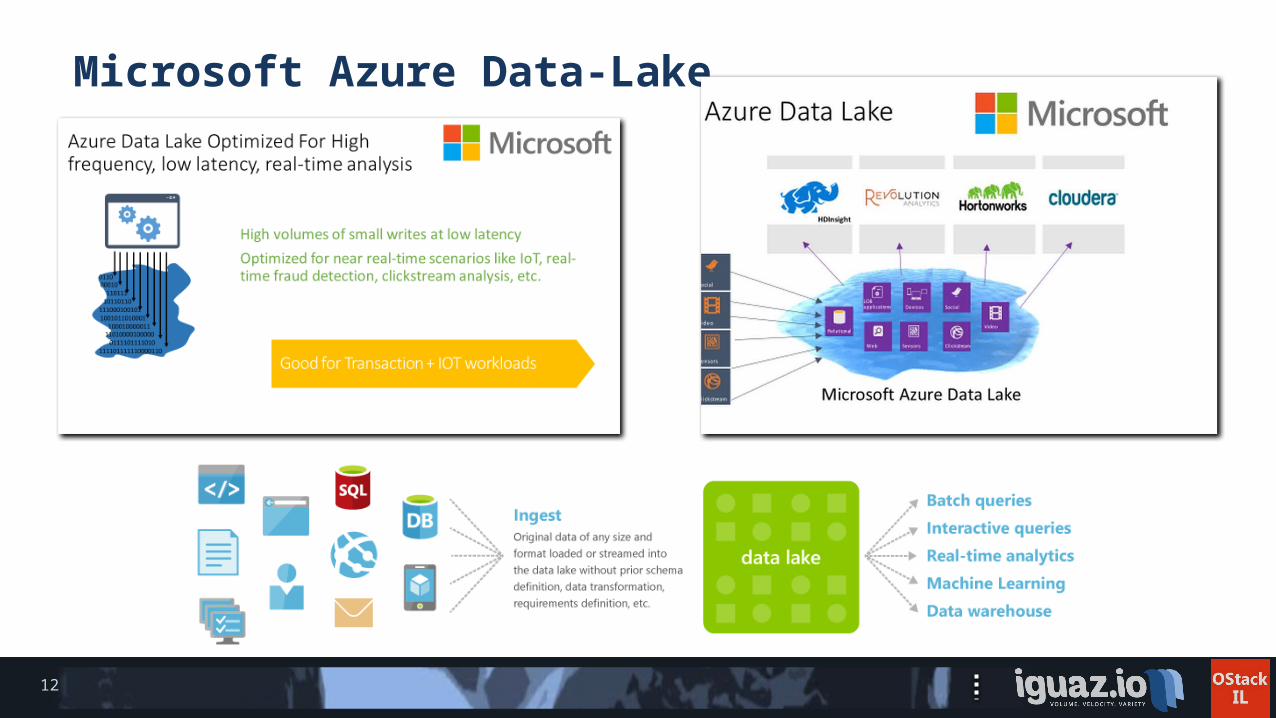
Microsoft Azure Data-Lake
12

Recommended BigData Architecture With OpenStack
10/40GbE SDN Fabric
Shared Storage
Big Data Applications Running in Servers, VMs or Containers
Ingestion
Mobile Clients
Deployment, Job Scheduling, Orchestration, Monitoring
Network segmentation and provisioning, Firewall
NovaSahara
Neutron
S3, Swift, Manila, Cinder
KVMDockers
File and Object Storage for DataBlock for KVM VM Disks

What is Manila?• Multi-tenant file
share as a service• Like Cinder for files• Integrated with Neutron • Supported Protocols– NFS, CIFS– GPFS, Ceph, Gluster– More to come
14
File Sharing with OpenStack Manila

• Automated deployment and management of Hadoop/Spark clusters
• Job Execution/tracking• In/out Data access
15
OpenStack Sahara

16

Sahara Flow
17 © 2015

Create and Launch a BigData Cluster
18

Define Data Sources & Destinations
19
Input, Output, and Intermediate data can reside on shared file/object storage
• Simple data management• Elastic Storage as a service model• Data sharing across jobs and with
external consumers/producers

Create and Run Jobs
20

• BigData Assumptions & Requirements Have Changed Dramatically– Address Volume + Velocity + Variety, and real-time/interactive response – Run over Virtualized Cloud Infrastructure – Deliver availability, security and operational efficiency
• BigData Solutions must evolve to use– Infinitely scalable and high-performance data-lakes vs directly attached storage – Dockers, Network Virtualization, Automated Deployment and operation
• BigData is one of the key application categories for OpenStack– Think twice before you lock your precious data in public clouds
21
Summary






























