Embed Size (px)
Citation preview

Proceedings of the 53rd Annual Meeting of the Association for Computational Linguisticsand the 7th International Joint Conference on Natural Language Processing, pages 239–249,
Beijing, China, July 26-31, 2015. c©2015 Association for Computational Linguistics
Learning Answer-Entailing Structures for Machine Comprehension
Mrinmaya Sachan1∗ Avinava Dubey1∗ Eric P. Xing1 Matthew Richardson2
1Carnegie Mellon University 2Microsoft Research1{mrinmays, akdubey, epxing}@cs.cmu.edu [email protected]
Abstract
Understanding open-domain text is oneof the primary challenges in NLP. Ma-chine comprehension evaluates the sys-tem’s ability to understand text througha series of question-answering tasks onshort pieces of text such that the correctanswer can be found only in the given text.For this task, we posit that there is a hid-den (latent) structure that explains the rela-tion between the question, correct answer,and text. We call this the answer-entailingstructure; given the structure, the correct-ness of the answer is evident. Since thestructure is latent, it must be inferred. Wepresent a unified max-margin frameworkthat learns to find these hidden structures(given a corpus of question-answer pairs),and uses what it learns to answer machinecomprehension questions on novel texts.We extend this framework to incorporatemulti-task learning on the different sub-tasks that are required to perform machinecomprehension. Evaluation on a publiclyavailable dataset shows that our frame-work outperforms various IR and neural-network baselines, achieving an overallaccuracy of 67.8% (vs. 59.9%, the bestpreviously-published result.)
1 Introduction
Developing an ability to understand natural lan-guage is a long-standing goal in NLP and holds thepromise of revolutionizing the way in which peo-ple interact with machines and retrieve informa-tion (e.g., for scientific endeavor). To evaluate thisability, Richardson et al. (2013) proposed the taskof machine comprehension (MCTest), along with
∗*Work started while the first two authors were interns atMicrosoft Research, Redmond.
a dataset for evaluation. Machine comprehensionevaluates a machine’s understanding by posing aseries of reading comprehension questions and as-sociated texts, where the answer to each questioncan be found only in its associated text. Solutionstypically focus on some semantic interpretation ofthe text, possibly with some form of probabilisticor logical inference, in order to answer the ques-tions. Despite significant recent interest (Burges,2013; Weston et al., 2014; Weston et al., 2015),the problem remains unsolved.
In this paper, we propose an approach for ma-chine comprehension. Our approach learns latentanswer-entailing structures that can help us an-swer questions about a text. The answer-entailingstructures in our model are closely related to theinference procedure often used in various mod-els for MT (Blunsom and Cohn, 2006), RTE(MacCartney et al., 2008), paraphrase (Yao et al.,2013b), QA (Yih et al., 2013), etc. and correspondto the best (latent) alignment between a hypoth-esis (formed from the question and a candidateanswer) with appropriate snippets in the text thatare required to answer the question. An exampleof such an answer-entailing structure is given inFigure 1. The key difference between the answer-entailing structures considered here and the align-ment structures considered in previous works isthat we can align multiple sentences in the textto the hypothesis. The sentences in the text con-sidered for alignment are not restricted to occurcontiguously in the text. To allow such a dis-contiguous alignment, we make use of the docu-ment structure; in particular, we take help fromrhetorical structure theory (Mann and Thomp-son, 1988) and event and entity coreference linksacross sentences. Modelling the inference proce-dure via answer-entailing structures is a crude yeteffective and computationally inexpensive proxyto model the semantics needed for the problem.Learning these latent structures can also be bene-
239

Figure 1: The answer-entailing structure for an example from MCTest500 dataset. The question and answer candidate arecombined to generate a hypothesis sentence. Then latent alignments are found between the hypothesis and the appropriatesnippets in the text. The solid red lines show the word alignments from the hypothesis words to the passage words, the dashedblack lines show auxiliary co-reference links in the text and the labelled dotted black arrows show the RST relation (elaboration)between the two sentences. Note that the two sentences do not have to be contiguous sentences in the text. We provide somemore examples of answer-entailing structures in the supplementary.
ficial as they can assist a human in verifying thecorrectness of the answer, eliminating the need toread a lengthy document.
The overall model is trained in a max-marginfashion using a latent structural SVM (LSSVM)where the answer-entailing structures are latent.We also extend our LSSVM to multi-task set-tings using a top-level question-type classification.Many QA systems include a question classifica-tion component (Li and Roth, 2002; Zhang andLee, 2003), which typically divides the questionsinto semantic categories based on the type of thequestion or answers expected. This helps the sys-tem impose some constraints on the plausible an-swers. Machine comprehension can benefit fromsuch a pre-classification step, not only to constrainplausible answers, but also to allow the system touse different processing strategies for each cate-gory. Recently, Weston et al. (2015) defined aset of 20 sub-tasks in the machine comprehen-sion setting, each referring to a specific aspect oflanguage understanding and reasoning required tobuild a machine comprehension system. They in-clude fact chaining, negation, temporal and spatialreasoning, simple induction, deduction and manymore. We use this set to learn to classify ques-tions into the various machine comprehension sub-tasks, and show that this task classification fur-ther improves our performance on MCTest. Byusing the multi-task setting, our learner is able toexploit the commonality among tasks where pos-sible, while having the flexibility to learn task-specific parameters where needed. To the best ofour knowledge, this is the first use of multi-tasklearning in a structured prediction model for QA.
We provide experimental validation for ourmodel on a real-world dataset (Richardson et al.,
2013) and achieve superior performance vs. anumber of IR and neural network baselines.
2 The Problem
Machine comprehension requires us to answerquestions based on unstructured text. We treat thisas selecting the best answer from a set of can-didate answers. The candidate answers may bepre-defined, as is the case in multiple-choice ques-tion answering, or may be undefined but restricted(e.g., to yes, no, or any noun phrase in the text).Machine Comprehension as Textual Entail-ment: Let for each question qi ∈ Q, ti be theunstructured text and Ai = {ai1, . . . , aim} bethe set of candidate answers to the question. Wecast the machine comprehension task as a tex-tual entailment task by converting each question-answer candidate pair (qi, ai,j) into a hypothe-sis statement hij . For example, the question“What did Alyssa eat at the restaurant?” andanswer candidate “Catfish” in Figure 1 can becombined to achieve a hypothesis “Alyssa ateCatfish at the restaurant”. We use the questionmatching/rewriting rules described in Cucerzanand Agichtein (2005) to achieve this transforma-tion. For each question qi, the machine com-prehension task reduces to picking the hypothe-sis hi that has the highest likelihood of being en-tailed by the text among the set of hypotheseshi = {hi1, . . . , him} generated for that question.Let h∗i ∈ hi be the correct hypothesis. Now let usdefine the latent answer-entailing structures.
3 Latent Answer-Entailing Structures
The latent answer-entailing structures help themodel in providing evidence for the correct hy-
240

pothesis. We consider the quality of a one-to-one word alignment from a hypothesis to snippetsin the text as a proxy for the evidence. Hypoth-esis words are aligned to a unique text word inthe text or an empty word. For example, in Fig-ure 1, all words but “at” are aligned to a wordin the text. The word “at” can be assumed to bealigned to an empty word and it has no effect onthe model. Learning these alignment edges typi-cally helps a model decompose the input and out-put structures into semantic constituents and de-termine which constituents should be compared toeach other. These alignments can then be used togenerate more effective features.
The alignment depends on two things: (a) snip-pets in the text to be aligned to the hypothesisand (b) word alignment from the hypothesis to thesnippets. We explore three variants of the snippetsin the text to be aligned to the hypothesis. Thechoice of these snippets composed with the wordalignment is the resulting hidden structure calledan answer-entailing structure.1. Sentence Alignment: The simplest variant is tofind a single sentence in the text that best aligns tothe hypothesis. This is the structure considered ina majority of previous works in RTE (MacCartneyet al., 2008) and QA (Yih et al., 2013) as they onlyreason on single sentence length texts.2. Subset Alignment: Here we find a subset of sen-tences from the text (instead of just one sentence)that best aligns with the hypothesis.3. Subset+ Alignment: This is the same as aboveexcept that the best subset is an ordered set.
4 Method
A natural solution is to treat MCTest as astructured prediction problem of ranking thehypotheses hi such that the correct hypothesisis at the top of this ranking. This induces aconstraint on the ranking structure that the correcthypothesis is ranked above the other competinghypotheses. For each text ti and hypothesesset hi, let Yi be the set of possible orderingsof the hypotheses. Let y∗i ∈ Yi be a correctranking (such that the correct hypothesis is atthe top of this ranking). Let the set of possibleanswer-entailing structures for each text hypoth-esis pair (ti,hi) be denoted by Zi. For each textti, with hypotheses set hi, an ordering of thehypotheses y ∈ Yi, and hidden structure z ∈ Zi.we define a scoring function Scorew(ti,hi, z,y)
parameterized by a weight vector w suchthat we have the prediction rule: (yi, zi) =arg maxy∈Yi,z∈Zi
Scorew(ti,hi, z,y). Thelearning task is to find w such that the predictedordering yi is close to the optimal orderingy∗i . Mathematically this can be written asminw
12‖w‖2 + C
∑i ∆(y∗i , z
∗i , yi, zi) where
z∗i = arg maxz∈Zi Scorew(ti,hi, z,y∗i ) and∆ is the loss function between the predictedand the actual ranking and latent structure.We simplify the loss function and assumeit to be independent of the hidden structure(∆(y∗i , z
∗i , yi, zi) = ∆(y∗i , yi)) and use a lin-
ear scoring function: Scorew(ti,hi, z,y) =wTφ(ti,hi, z,y) where φ is a feature mapdependent on the text ti, the hypothesis set hi, anordering of answers y and a hidden structure z.We use a convex upper bound of the loss function(Yu and Joachims, 2009) to rewrite the objective:
minw
12‖w‖2 − C
∑i
wTφ(ti,hi, z∗i ,y∗i ) (1)
+Cn∑i=1
maxy∈Yi,z∈Zi
{wTφ(ti,hi, z,y) + ∆(y∗i ,y)}
This problem can be solved using Concave-Convex Programming (Yuille and Rangarajan,2003) with the cutting plane algorithm for struc-tural SVM (Finley and Joachims, 2008). We usephi partial order (Joachims, 2006; Dubey et al.,2009) which has been used in previous structuralranking literature to incorporate ranking structurein the feature vector φ:
φ(ti,hi, z,y) =∑
j:hij 6=h∗icj(y)(ψ(ti, h∗i , z
∗i )
−ψ(ti, hij , zj)) (2)
where, cj(y) = 1 if h∗i is above hij in the rankingy else −1. We use pair preference (Chakrabarti etal., 2008) as the ranking loss ∆(y∗i ,y). Here, ψis the feature vector defined for a text, hypothesisand answer-entailing structure.Solution: We substitute the feature map definition(2) into Equation 1, leading to our LSSVM formu-lation. We consider the optimization as an alter-nating minimization problem where we alternatebetween getting the best zij and ψ for each text-hypothesis pair given w (inference) and then solv-ing for the weights w given ψ to obtain an opti-mal ordering of the hypothesis (learning). The stepfor solving for the weights is similar to rankSVM
241

(Joachims, 2002). Algorithm 1 describes our over-all procedure Here, we use beam search for infer-
Algorithm 1 Alternate Minimization for LSSVM1: Initialize w2: repeat3: zij = arg maxz wTψ(ti, hij , z) ∀i, j4: Compute ψ for each i, j5: Ci = ∅ ∀i6: repeat7: for i = 1, . . . , n do8: r(y) = wTφ(ti,hi, z,y) +
∆(y∗i ,y)−wTφ(ti,hi, z∗i ,y∗i )
9: yi = arg maxy∈Yi r(y)10: ξi = max{0,maxy∈Ui r(y)}11: if r(yi) > ξi + ε then12: Ci = Ci ∪ yi
Solve : minw,ξ
12‖w‖2 + C
∑i
ξi
∀i,∀y ∈ Ci : wTφ(ti,hi, z∗i ,y∗i )
≥ wTφ(ti,hi, z,y) + ∆(y∗i ,y)− ξi13: until no change in any Ci14: until Convergence
ring the latent structure zij in step 3. Also, notethat in step 3, when the answer-entailing structuresare “Subset” or “Subset+”, we can always get ahigher score by considering a larger subset of sen-tences. To discourage this, we add a penalty on thescore proportional to the size of the subset.Multi-task Latent Structured Learning: Ma-chine comprehension is a complex task which of-ten requires us to interpret questions, the kind ofanswers they seek as well as the kinds of inferencerequired to solve them. Many approaches in QA(Moldovan et al., 2003; Ferrucci, 2012) solve thisby having a top-level classifier that categorizes thecomplex task into a variety of sub-tasks. The sub-tasks can correspond to various categories of ques-tions that can be asked or various facets of text un-derstanding that are required to do well at machinecomprehension in its entirety.It is well known thatlearning a sub-task together with other related sub-tasks leads to a better solution for each sub-task.Hence, we consider learning classifications of thesub-tasks and then using multi-task learning.
We extend our LSSVM to multi-task settings.Let S be the number of sub-tasks. We assumethat the predictor w for each subtask s is par-
titioned into two parts: a parameter w0 that isglobally shared across each subtasks and a pa-rameter vs that is locally used to provide for thevariations within the particular subtask: w =w0 + vs. Mathematically we define the scoringfunction for text ti, hypothesis set hi of the sub-task s to be Scorew0,v,s(ti,hi, z,y) = (w0 +vs)Tφ(ti,hi, z,y). The objective in this case is
minw0,v
λ2‖w0‖2 +λ1
S
S∑s=1
‖vs‖2 (3)
S∑s=1
n∑i=1
maxy∈Yi,z∈Zi
{(w0 + vs)Tφ(ti,hi, z,y)
+ ∆(y∗i ,y)} − C∑i
(w0 + vs)Tφ(t,hi, z∗i ,y∗i )
Now, we extend a trick that Evgeniou and Pon-til (2004) used on linear SVM to reformulate thisproblem into an objective that looks like (1). Suchreformulation will help in using algorithm 1 tosolve the multi-task problem as well. Lets define anew feature map Φs, one for each sub-task s usingthe old feature map φ as:
Φs(ti,hi, z,y) = (φ(ti,hi, z,y)
µ,0, . . . ,0︸ ︷︷ ︸
s−1
,
φ(ti,hi, z,y),0, . . . ,0︸ ︷︷ ︸S−s
)
where µ = Sλ2λ1
and the 0 denotes the zerovector of the same size as φ. Also define ournew predictor as w = (
õw0,v1, . . . ,vS).
Using this formulation we can show thatwTΦs(ti,hi, z,y) = (w0 + vs)Tφ(ti,hi, z,y)and ‖w‖2 =
∑s ‖vs‖2 + µ‖w0‖2. Hence, if we
now define the objective (1) but use the new fea-ture map and w then we will get back our multi-task objective (3). Thus we can use the same setupas before for multi-task learning after appropri-ately changing the feature map. We will explorea few definitions of sub-tasks in our experiments.Features: Recall that our features had the formψ(t, h, z) where the hypothesis h was itselfformed from a question q and answer candidate a.Given an answer-entailing structure z, we inducethe following features based on word level sim-ilarity of aligned words: (a) Limited word-levelsurface-form matching and (b) Semantic wordform matching: Word similarity for synonymy us-ing SENNA word vectors (Collobert et al., 2011),
242

“Antonymy” ‘Class-Inclusion’ or ‘Is-A’ relationsusing Wordnet (Fellbaum, 1998). We compute ad-ditional features of the aforementioned kinds tomatch named entities and events. We also addfeatures for matching local neighborhood in thealigned structure: features for matching bigrams,trigrams, dependencies, semantic roles, predicate-argument structure as well as features for match-ing global structure: a tree kernel for matchingsyntactic representations of entire sentences us-ing Srivastava and Hovy (2013). The local andglobal features can use the RST and coreferencelinks enabling inference across sentences. For in-stance, in the example shown in figure 1, the coref-erence link connecting the two “restaurant” wordsbrings the snippets “Alyssa enjoyed the” and “hada special on catfish” closer making these featuresmore effective. The answer-entailing structuresshould be intuitively similar to the question butalso the answer. Hence, we add features that arethe product of features for the text-question matchand text-answer match.String edit Features: In addition to looking forfeatures on exact word/phrase match, we also addfeatures using two paraphrase databases ParaPara(Chan et al., 2011) and DIRT (Lin and Pantel,2001). The ParaPara database contains strings ofthe form string1 → string2 like “total lack of”→“lack of”, “is one of” → “among”, etc. Simi-larly, the DIRT database contains paraphrases ofthe form “If X decreases Y then X reduces Y”, “IfX causes Y then X affects Y”, etc. Whenever wehave a substring in the text can be transformed intoanother using these two databases, we keep matchfeatures for the substring with a higher score (ac-cording to w) and ignore the other substring.The sentences with discourse relations are relatedto each other by means of substitution, ellipsis,conjunction and lexical cohesion, etc (Mann andThompson, 1988) and can help us answer certainkinds of questions (Jansen et al., 2014). As an ex-ample, the “cause” relation between sentences inthe text can often give cues that can help us an-swer “why” or “how” questions. Hence, we addadditional features - conjunction of the RST labeland the question word - to our feature vector. Sim-ilarly, the entity and event co-reference relationscan allows the system to reason about repeatingentities or events through all the sentences they getmentioned in. Thus, we add additional features ofthe aforementioned types by replacing entity men-
tions with their first mentions.Subset+ Features: We add an additional set of fea-tures which match the first sentence in the orderedset to the question and the last sentence in the or-dered set to the answer. This helps in the casewhen a certain portion of the text is targeted bythe question but then it must be used in combina-tion with another sentence to answer the question.For instance, in Figure 1, sentence 2 mentions thetarget of the question but the answer can only begiven when in combination with sentence 1.Negation We empirically found that one key lim-itation in our formulation is its inability to handlenegation (both in questions and text). Negationis especially hurtful to our model as it not onlyresults in poor performance on questions that re-quire us to reason with negated facts, it providesour model with a wrong signal (facts usually alignwell with their negated versions). We use a simpleheuristic to overcome the negation problem. Wedetect negation (either in the hypothesis or a sen-tence in the text snippet aligned to it) using a smallset of manually defined rules that test for presenceof words such as “not”, “n’t”, etc. Then, we flipthe partial order - i.e. the correct hypothesis is nowranked below the other competing hypotheses. Forinference at test time, we also invert the predictionrule i.e. we predict the hypothesis (answer) thathas the least score under the model.
5 Experiments
Datasets: We use two datasets for our evaluation.(1) First is the MCTest-500 dataset 1, a freelyavailable set of 500 stories (split into 300 train,50 dev and 150 test) and associated questions(Richardson et al., 2013). The stories are fictionalso the answers can be found only in the story it-self. The stories and questions are carefully lim-ited, thereby minimizing the world knowledge re-quired for this task. Yet, the task is challenging formost modern NLP systems. Each story in MCTesthas four multiple choice questions, each with fouranswer choices. Each question has only one cor-rect answer. Furthermore, questions are also anno-tated with ‘single’ and ‘multiple’ labels. The ques-tions annotated ‘single’ only require one sentencein the story to answer them. For ‘multiple’ ques-tions it should not be possible to find the answerto the question in any individual sentence of thepassage. In a sense, the ‘multiple’ questions are
1http://research.microsoft.com/mct
243

harder than the ‘single’ questions as they typicallyrequire complex lexical analysis, some inferenceand some form of limited reasoning. Cucerzan-converted questions can also be downloaded fromthe MCTest website.
(2) The second dataset is a synthetic datasetreleased under the bAbI project2 (Weston et al.,2015). The dataset presents a set of 20 ‘tasks’,each testing a different aspect of text understand-ing and reasoning in the QA setting, and hencecan be used to test and compare capabilities oflearning models in a fine-grained manner. Foreach ‘task’, 1000 questions are used for trainingand 1000 for testing. The ‘tasks’ refer to questioncategories such as questions requiring reasoningover single/two/three supporting facts or two/threearg. relations, yes/no questions, counting ques-tions, etc. Candidate answers are not provided butthe answers are typically constrained to a smallset: either yes or no or entities already appear-ing in the text, etc. We write simple rules to con-vert the question and answer candidate pairs to hy-potheses. 3
Baselines: We have five baselines. (1) The firstthree baselines are inspired from Richardson etal. (2013). The first baseline (called SW) usesa sliding window and matches a bag of wordsconstructed from the question and hypothesizedanswer to the text. (2) Since this ignores longrange dependencies, the second baseline (calledSW+D) accounts for intra-word distances as well.As far as we know, SW+D is the best previ-ously published result on this task.4 (3) Thethird baseline (called RTE) uses textual entail-ment to answer MCTest questions. For this base-line, MCTest is again re-casted as an RTE taskby converting each question-answer pair into astatement (using Cucerzan and Agichtein (2005))and then selecting the answer whose statementhas the highest likelihood of being entailed by the
2https://research.facebook.com/researchers/15439345391893483Note that the bAbI dataset is artificial and not meant for
open-domain machine comprehension. It is a toy dataset gen-erated from a simulated world. Due to its restrictive nature,we do not use it directly in evaluating our method vs. otheropen-domain machine comprehension methods. However,it provides benefit in identifying interesting subtasks of ma-chine comprehension. As will be seen, we are able to lever-age the dataset both to improve our multi-task learning algo-rithm, as well as to analyze the strengths and weaknesses ofour model.
4We also construct two additional baselines (LSTM andQUANTA) for comparison in this paper both of which achievesuperior performance to SW+D.
story. 5 (4) The fourth baseline (called LSTM)is taken from Weston et al. (2015). The base-line uses LSTMs (Hochreiter and Schmidhuber,1997) to accomplish the task. LSTMs have re-cently achieved state-of-the-art results in a vari-ety of tasks due to their ability to model long-term context information as opposed to other neu-ral networks based techniques. (5) The fifth base-line (called QANTA)6 is taken from Iyyer et al.(2014). QANTA too uses a recursive neural net-work for question answering.Task Classification for MultiTask Learning:We consider three alternative task classificationsfor our experiments. First, we look at questionclassification. We use a simple question classi-fication based on the question word (what, why,what, etc.). We call this QClassification. Next, wealso use a question/answer classification7 from Liand Roth (2002). This classifies questions into dif-ferent semantic classes based on the possible se-mantic types of the answers sought. We call thisQAClassification. Finally, we also learn a clas-sifier for the 20 tasks in the Machine Compre-hension gamut described in Weston et al. (2015).The classification algorithm (called TaskClassifi-cation) was built on the bAbI training set. It isessentially a Naive-Bayes classifier and uses onlysimple unigram and bigram features for the ques-tion and answer. The tasks typically correspondto different strategies when looking for an answerin the machine comprehension setting. In our ex-periments we will see that learning these strategiesis better than learning the question answer classi-fication which is in turn better than learning thequestion classification.Results: We compare multiple variants of ourLSSVM8 where we consider a variety of answer-entailing structures and our modification for nega-tion and multi-task LSSVM, where we considerthree kinds of task classification strategies againstthe baselines on the MCTest dataset. We con-sider two evaluation metrics: accuracy (propor-tion of questions correctly answered) and NDCG4
5The BIUTEE system (Stern and Dagan, 2012)available under the Excitement Open Platformhttp://hltfbk.github.io/Excitement-Open-Platform/ wasused for recognizing textual entailment.
6http://cs.umd.edu/ miyyer/qblearn/7http://cogcomp.cs.illinois.edu/Data/QA/QC/8We tune the SVM regularization parameter C and the
penalty factor on the subset size on the development set. Weuse a beam of size 5 in our experiments. We use StanfordCoreNLP and the HILDA parser (Feng and Hirst, 2014) forlinguistic preprocessing.
244
69.85
59.45
61
63.24
66.15
64.83
67.65
67.99
67.83
40 50 60 70 80
Single
Multiple
All
Percentage Accuracy
0.869
0.82
0.83
0.857
0.863
0.861
0.867
0.869
0.868
0.65 0.7 0.75 0.8 0.85 0.9
Single
Multiple
All
Subset+/Negation TaskClassification
Subset+/NegationQAClassification
Subset+/NegationQClassification
Subset+/Negation
Subset+
Subset
Sentence
QANTA
LSTM
RTE
SW+D
SWNDCG
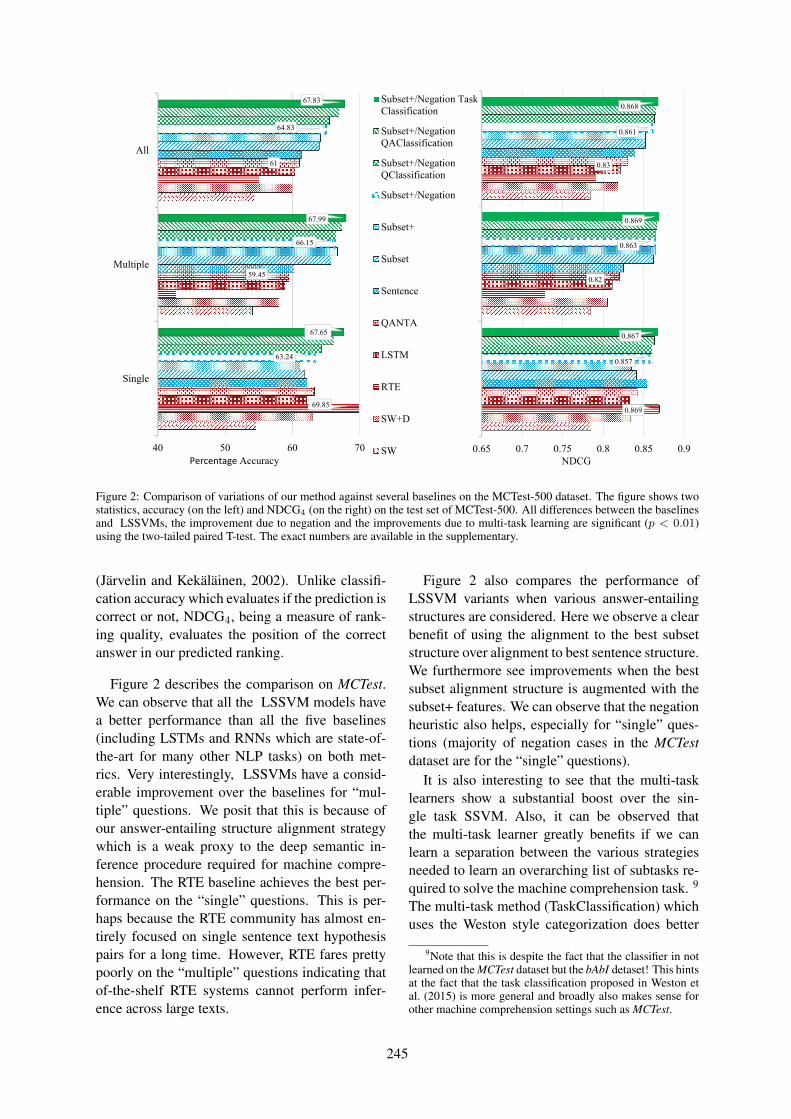
Figure 2: Comparison of variations of our method against several baselines on the MCTest-500 dataset. The figure shows twostatistics, accuracy (on the left) and NDCG4 (on the right) on the test set of MCTest-500. All differences between the baselinesand LSSVMs, the improvement due to negation and the improvements due to multi-task learning are significant (p < 0.01)using the two-tailed paired T-test. The exact numbers are available in the supplementary.
(Jarvelin and Kekalainen, 2002). Unlike classifi-cation accuracy which evaluates if the prediction iscorrect or not, NDCG4, being a measure of rank-ing quality, evaluates the position of the correctanswer in our predicted ranking.
Figure 2 describes the comparison on MCTest.We can observe that all the LSSVM models havea better performance than all the five baselines(including LSTMs and RNNs which are state-of-the-art for many other NLP tasks) on both met-rics. Very interestingly, LSSVMs have a consid-erable improvement over the baselines for “mul-tiple” questions. We posit that this is because ofour answer-entailing structure alignment strategywhich is a weak proxy to the deep semantic in-ference procedure required for machine compre-hension. The RTE baseline achieves the best per-formance on the “single” questions. This is per-haps because the RTE community has almost en-tirely focused on single sentence text hypothesispairs for a long time. However, RTE fares prettypoorly on the “multiple” questions indicating thatof-the-shelf RTE systems cannot perform infer-ence across large texts.
Figure 2 also compares the performance ofLSSVM variants when various answer-entailingstructures are considered. Here we observe a clearbenefit of using the alignment to the best subsetstructure over alignment to best sentence structure.We furthermore see improvements when the bestsubset alignment structure is augmented with thesubset+ features. We can observe that the negationheuristic also helps, especially for “single” ques-tions (majority of negation cases in the MCTestdataset are for the “single” questions).
It is also interesting to see that the multi-tasklearners show a substantial boost over the sin-gle task SSVM. Also, it can be observed thatthe multi-task learner greatly benefits if we canlearn a separation between the various strategiesneeded to learn an overarching list of subtasks re-quired to solve the machine comprehension task. 9
The multi-task method (TaskClassification) whichuses the Weston style categorization does better
9Note that this is despite the fact that the classifier in notlearned on the MCTest dataset but the bAbI detaset! This hintsat the fact that the task classification proposed in Weston etal. (2015) is more general and broadly also makes sense forother machine comprehension settings such as MCTest.
245

than the multi-task method (QAClassification) thatlearns the question answer classification. QAClas-sification in turn performs better than multi-taskmethod (QClassification) that learns the questionclassification only.
6 Strengths and Weaknesses
A good question to be asked is how good is struc-ture alignment as a proxy to the semantics of theproblem? In this section, we attempt to tease outthe strengths and limitations of such a structurealignment approach for machine comprehension.To do so, we evaluate our methods on various tasksin the bAbl dataset.For the bAbI dataset, we addadditional features inspired from the “task” dis-tinction to handle specific “tasks”.
In our experiments, we observed a similar gen-eral pattern of improvement of LSSVM over thebaselines as well as the improvement due to multi-task learning. Again task classification helpedthe multi-task learner the most and the QA clas-sification helped more than the QClassification.It is interesting here to look at the performancewithin the sub-tasks. Negation improved the per-formance for three sub-tasks, namely, the tasksof modelling “yes/no questions”, “simple nega-tions” and “indefinite knowledge” (the “IndefiniteKnowledge” sub-task tests the ability to modelstatements that describe possibilities rather thancertainties). Each of these sub-tasks contain a sig-nificant number of negation cases. Our models doespecially well on questions requiring reasoningover one and two supporting facts, two arg. rela-tions, indefinite knowledge, basic and compoundcoreference and conjunction. Our models achievelower accuracy better than the baselines on twosub-tasks, namely “path finding” and “agent mo-tivations”. Our model along with the baselinesdo not do too well on the “counting” sub-task, al-though we get slightly better scores. The “count-ing” sub-task (which asks about the number of ob-jects with a certain property) requires the inferenceto have an ability to perform simple counting op-erations. The “path finding” sub-task requires theinference to reason about the spatial path betweenlocations (e.g. Pittsburgh is located on the westof New York). The “agents motivations” sub-taskasks questions such as ‘why an agent performsa certain action’. As inference is cheaply mod-elled via alignment structure, we lack the abilityto deeply reason about facts or numbers. This is
an important challenge for future work.
7 Related Work
The field of QA is quite rich. Most QA evaluationssuch as TREC have typically focused on shortfactoid questions. The solutions proposed haveranged from various IR based approaches (Mittaland Mittal, 2011) that treat this as a problem of re-trieval from existing knowledge bases and performsome shallow inference to NLP approaches thatlearn a similarity between the question and a set ofcandidate answers (Yih et al., 2013). A majority ofthese approaches do not focus on doing any deeperinference. However, the task of machine compre-hension requires an ability to perform inferenceover paragraph length texts to seek the answer.This is challenging for most IR and NLP tech-niques. In this paper, we presented a strategy forlearning answer-entailing structures that helped usperform inference over much longer texts by treat-ing this as a structured input-output problem.
The approach of treating a problem as one ofmapping structured inputs to structured outputs iscommon across many NLP applications. Exam-ples include word or phrase alignment for bitextsin MT (Blunsom and Cohn, 2006), text-hypothesisalignment in RTE (Sammons et al., 2009; Mac-Cartney et al., 2008; Yao et al., 2013a; Sultanet al., 2014), question-answer alignment in QA(Berant et al., 2013; Yih et al., 2013; Yao andVan Durme, 2014), etc. Again all of these ap-proaches align local parts of the input to local partsof the output. In this work, we extended the wordalignment formalism to align multiple sentencesin the text to the hypothesis. We also incorpo-rated the document structure (rhetorical structures(Mann and Thompson, 1988)) and co-reference tohelp us perform inference over longer documents.
QA has had a long history of using pipelinemodels that extract a limited number of high-levelfeatures from induced representations of question-answer pairs, and then built a classifier using somelabelled corpora. On the other hand we learntthese structures and performed machine com-prehension jointly through a unified max-marginframework. We note that there exist some recentmodels such as Yih et al. (2013) that do model QAby automatically defining some kind of alignmentbetween the question and answer snippets and usea similar structured input-output model. However,they are limited to single sentence answers.
246

Another advantage of our approach is its sim-ple and elegant extension to multi-task settings.There has been a rich vein of work in multi-tasklearning for SVMs in the ML community. Evge-niou and Pontil (2004) proposed a multi-task SVMformulation assuming that the multi-task predictorw factorizes as the sum of a shared and a task-specific component. We used the same idea topropose a multi-task variant of Latent StructuredSVMs. This allows us to use the single task SVMin the multi-task setting with a different featuremapping. This is much simpler than other compet-ing approaches such as Zhu et al. (2011) proposedin the literature for multi-task LSSVM.
8 Conclusion
In this paper, we addressed the problem of ma-chine comprehension which tests language under-standing through multiple choice question answer-ing tasks. We posed the task as an extension toRTE. Then, we proposed a solution by learning la-tent alignment structures between texts and the hy-potheses in the equivalent RTE setting. The taskrequires solving a variety of sub-tasks so we ex-tended our technique to a multi-task setting. Ourtechnique showed empirical improvements overvarious IR and neural network baselines. The la-tent structures while effective are cheap proxiesto the reasoning and language understanding re-quired for this task and have their own limitations.We also discuss strengths and limitations of ourmodel in a more fine-grained analysis. In the fu-ture, we plan to use logic-like semantic represen-tations of texts, questions and answers and exploreapproaches to perform structured inference overricher semantic representations.
Acknowledgments
The authors would like to thank the anonymousreviewers, along with Sujay Jauhar and SnigdhaChaturvedi for their valuable comments and sug-gestions to improve the quality of the paper.
References[Berant et al.2013] Jonathan Berant, Andrew Chou,
Roy Frostig, and Percy Liang. 2013. Semanticparsing on freebase from question-answer pairs. InEMNLP, pages 1533–1544. ACL.
[Blunsom and Cohn2006] Phil Blunsom and TrevorCohn. 2006. Discriminative word alignment with
conditional random fields. In Proceedings of the21st International Conference on ComputationalLinguistics and the 44th annual meeting of the Asso-ciation for Computational Linguistics, pages 65–72.Association for Computational Linguistics.
[Burges2013] Christopher JC Burges. 2013. Towardsthe machine comprehension of text: An essay. Tech-nical report, Microsoft Research Technical ReportMSR-TR-2013-125, 2013, pdf.
[Chakrabarti et al.2008] Soumen Chakrabarti, RajivKhanna, Uma Sawant, and Chiru Bhattacharyya.2008. Structured learning for non-smooth rankinglosses. In Proceedings of the 14th ACM SIGKDDInternational Conference on Knowledge Discoveryand Data Mining, pages 88–96.
[Chan et al.2011] Tsz Ping Chan, Chris Callison-Burch, and Benjamin Van Durme. 2011. Rerank-ing bilingually extracted paraphrases using mono-lingual distributional similarity. In Proceedings ofthe GEMS 2011 Workshop on GEometrical Modelsof Natural Language Semantics, pages 33–42.
[Collobert et al.2011] Ronan Collobert, Jason Weston,Leon Bottou, Michael Karlen, Koray Kavukcuoglu,and Pavel Kuksa. 2011. Natural language process-ing (almost) from scratch. The Journal of MachineLearning Research, 12:2493–2537.
[Cucerzan and Agichtein2005] S. Cucerzan andE. Agichtein. 2005. Factoid question answeringover unstructured and structured content on the web.In Proceedings of TREC 2005.
[Dubey et al.2009] Avinava Dubey, Jinesh Machchhar,Chiranjib Bhattacharyya, and Soumen Chakrabarti.2009. Conditional models for non-smooth rankingloss functions. In ICDM, pages 129–138.
[Evgeniou and Pontil2004] Theodoros Evgeniou andMassimiliano Pontil. 2004. Regularized multi–tasklearning. In Proceedings of the Tenth ACM SIGKDDInternational Conference on Knowledge Discoveryand Data Mining, pages 109–117.
[Fellbaum1998] Christiane Fellbaum. 1998. WordNet:An Electronic Lexical Database. Bradford Books.
[Feng and Hirst2014] Vanessa Wei Feng and GraemeHirst. 2014. A linear-time bottom-up discourseparser with constraints and post-editing. In Proceed-ings of the 52nd Annual Meeting of the Associationfor Computational Linguistics (Volume 1: Long Pa-pers), pages 511–521.
[Ferrucci2012] David A Ferrucci. 2012. Introductionto this is watson. IBM Journal of Research and De-velopment, 56(3.4):1–1.
[Finley and Joachims2008] T. Finley and T. Joachims.2008. Training structural SVMs when exact infer-ence is intractable. In International Conference onMachine Learning (ICML), pages 304–311.
247

[Hochreiter and Schmidhuber1997] Sepp Hochreiterand Jurgen Schmidhuber. 1997. Long short-termmemory. Neural computation, 9(8):1735–1780.
[Iyyer et al.2014] Mohit Iyyer, Jordan Boyd-Graber,Leonardo Claudino, Richard Socher, and HalDaume III. 2014. A neural network for factoidquestion answering over paragraphs. In EmpiricalMethods in Natural Language Processing.
[Jansen et al.2014] Peter Jansen, Mihai Surdeanu, andPeter Clark. 2014. Discourse complements lexicalsemantics for non-factoid answer reranking. In Pro-ceedings of the 52nd Annual Meeting of the Associa-tion for Computational Linguistics (Volume 1: LongPapers), pages 977–986.
[Jarvelin and Kekalainen2002] Kalervo Jarvelin andJaana Kekalainen. 2002. Cumulated gain-basedevaluation of ir techniques. ACM Transactions onInformation Systems (TOIS), 20(4):422–446.
[Joachims2002] Thorsten Joachims. 2002. Optimizingsearch engines using clickthrough data. In Proceed-ings of the eighth ACM SIGKDD international con-ference on Knowledge discovery and data mining,pages 133–142. ACM.
[Joachims2006] T. Joachims. 2006. Training linearSVMs in linear time. In ACM SIGKDD Inter-national Conference On Knowledge Discovery andData Mining (KDD), pages 217–226.
[Li and Roth2002] Xin Li and Dan Roth. 2002. Learn-ing question classifiers. In Proceedings of the19th international conference on Computationallinguistics-Volume 1, pages 1–7.
[Lin and Pantel2001] Dekang Lin and Patrick Pantel.2001. Dirt@ sbt@ discovery of inference rules fromtext. In Proceedings of the seventh ACM SIGKDDinternational conference on Knowledge discoveryand data mining, pages 323–328.
[MacCartney et al.2008] Bill MacCartney, Michel Gal-ley, and Christopher D Manning. 2008. A phrase-based alignment model for natural language infer-ence. In Proceedings of the conference on empiricalmethods in natural language processing, pages 802–811.
[Mann and Thompson1988] William C Mann and San-dra A Thompson. 1988. {Rhetorical Struc-ture Theory: Toward a functional theory of textorganisation}. Text, 3(8):234–281.
[Mittal and Mittal2011] Sparsh Mittal and Ankush Mit-tal. 2011. Versatile question answering systems:seeing in synthesis. International Journal of Intelli-gent Information and Database Systems, 5(2):119–142.
[Moldovan et al.2003] Dan Moldovan, Marius Pasca,Sanda Harabagiu, and Mihai Surdeanu. 2003. Per-formance issues and error analysis in an open-domain question answering system. ACM Trans-
actions on Information Systems (TOIS), 21(2):133–154.
[Richardson et al.2013] Matthew Richardson,J.C. Christopher Burges, and Erin Renshaw. 2013.Mctest: A challenge dataset for the open-domainmachine comprehension of text. In Proceedingsof the 2013 Conference on Empirical Methods inNatural Language Processing, pages 193–203.
[Sammons et al.2009] M. Sammons, V. Vydiswaran,T. Vieira, N. Johri, M. Chang, D. Goldwasser,V. Srikumar, G. Kundu, Y. Tu, K. Small, J. Rule,Q. Do, and D. Roth. 2009. Relation alignment fortextual entailment recognition. In TAC.
[Srivastava and Hovy2013] Shashank Srivastava andDirk Hovy. 2013. A walk-based semantically en-riched tree kernel over distributed word representa-tions. In Empirical Methods in Natural LanguageProcessing, pages 1411–1416.
[Stern and Dagan2012] Asher Stern and Ido Dagan.2012. Biutee: A modular open-source system forrecognizing textual entailment. In Proceedings ofthe ACL 2012 System Demonstrations, pages 73–78.
[Sultan et al.2014] Arafat Md Sultan, Steven Bethard,and Tamara Sumner. 2014. Back to basics formonolingual alignment: Exploiting word similarityand contextual evidence. Transactions of the Asso-ciation of Computational Linguistics – Volume 2, Is-sue 1, pages 219–230.
[Weston et al.2014] Jason Weston, Sumit Chopra, andAntoine Bordes. 2014. Memory networks. arXivpreprint arXiv:1410.3916.
[Weston et al.2015] Jason Weston, Antoine Bordes,Sumit Chopra, and Tomas Mikolov. 2015. Towardsai-complete question answering: A set of prerequi-site toy tasks.
[Yao and Van Durme2014] Xuchen Yao and BenjaminVan Durme. 2014. Information extraction overstructured data: Question answering with freebase.In Proceedings of the 52nd Annual Meeting of theAssociation for Computational Linguistics (Volume1: Long Papers), pages 956–966. Association forComputational Linguistics.
[Yao et al.2013a] Xuchen Yao, Benjamin Van Durme,Chris Callison-Burch, and Peter Clark. 2013a.A lightweight and high performance monolingualword aligner. In ACL (2), pages 702–707.
[Yao et al.2013b] Xuchen Yao, Benjamin Van Durme,Chris Callison-Burch, and Peter Clark. 2013b.Semi-markov phrase-based monolingual alignment.In Proceedings of EMNLP.
[Yih et al.2013] Wentau Yih, Ming-Wei Chang,Christopher Meek, and Andrzej Pastusiak. 2013.Question answering using enhanced lexical se-mantic models. In Proceedings of the 51st AnnualMeeting of the Association for ComputationalLinguistics.
248

[Yu and Joachims2009] Chun-Nam Yu andT. Joachims. 2009. Learning structural svmswith latent variables. In International Conferenceon Machine Learning (ICML).
[Yuille and Rangarajan2003] A. L. Yuille and AnandRangarajan. 2003. The concave-convex procedure.Neural Comput.
[Zhang and Lee2003] Dell Zhang and Wee Sun Lee.2003. Question classification using support vectormachines. In Proceedings of the 26th annual inter-national ACM SIGIR conference on Research anddevelopment in informaion retrieval, pages 26–32.ACM.
[Zhu et al.2011] Jun Zhu, Ning Chen, and Eric P Xing.2011. Infinite latent svm for classification andmulti-task learning. In Advances in neural informa-tion processing systems, pages 1620–1628.
249





























