Embed Size (px)
Citation preview

Set Containment Joins: The Good, The Bad and The
Ugly
Karthikeyan RamasamyJointly With
Jignesh Patel, Jeffrey F. Naughton and Raghav Kaushik

Introduction
Most data mining today takes place outside of any DBMS
Unfortunate - many potential advantages arise from using a DBMS:
scalability
flexibility
consistency

Why don’t people use RDBMS?
Too slow.
Difficult to express data mining algorithms in SQL
Potential for improvement: set-valued attributes.

Relational DBMS 101
Data model:tables with rows and columns
each individual entry is an atomic element (an integer, a float, a character string.)
New extension: set-valued attributesindividual entries of tables can be sets.

Sets and Data Mining
Canonical example: customers and their transactions.
No sets: two tables,customers(cid, name, address, …)
transactions(cid, product, date,…)
Sets: one table,customers(cid, name, address, {trans}, …)

Open questions:
How do you store the sets?
How do you implement operations on these set-valued attributes?
Do they really help move data mining “into SQL”?

Set Containment Joins
Consider two relations:
Containment is defined as
Computes pair of tuples one from R and the other from S such that set from R tuple is contained or equal to the set from S tuple
}){,( baR }){,( dcS
SjoinR db }{}{)(

Set Containment Joins (Cont.)Example
STUDENT (sid, {courses-taken})COURSES (cid, {prereqs})Find the set of courses that student is eligible to take

Storage Representations
Nested internal.Grouped and stored along with the rest of the attributes in the tuple.
Unnested external.Set instances are unnested and stored in a separate relation.
Requires join to assemble elements.

Nested Internal Representation
Cardinality
Element 1
Element 2
Element N
.
.
Length
Tuple
A1 A2 A3

Unnested External - Good Old SQL
iRS. jSS.SRSS
bRS .dSS .
iRS .jSS .
SR
iRS .
SELECT RS.i, SS.j
FROM RS, SS
WHERE RS.b = SS.d
GROUP BY RS.i, SS.j
HAVING COUNT(*) = ( SELECT count(*) FROM NRS RS
WHERE NRS.i = RS.i )
}){,( baR ),( aiRB ),( biRS
}){,( dcS ),( djSS),( cjSB

SQL Approach - Pros and Cons
Pros.Easy to add to an existing DBMS.
ConsRequires extra joins for projecting other attributes
Nested query must be evaluated for each group
Number of groups is |R|*|S|

SQL Approach - Mitigation
Magic Sets RewritingCount QueryINSERT INTO T1(i,counti)
SELECT RS.i, COUNT(*)
FROM RS
GROUP BY RS.i
Candidate QueryINSERT INTO T2(i,j,countij)
SELECT RS.i, SS.j, COUNT(*)
FROM RS, SS
WHERE RS.b = SS.d
GROUP BY RS.i, SS.jVerify QuerySELECT T2.i, T2.j
FROM T2, T1
WHERE T2.i = T1.i AND
T2.countij = T1.counti

Signature Nested Loops (Sig-NL)
Applicable for Nested Internal Representation
SignaturesSignatures are bit vectors for approximating sets
Approximation leads to “false drops”
Three phases of the algorithmSignature construction phase
Comparing signature for containment
Verification of actual subsets

Signature Nested Loops (Contd)
Signature Construction Phase Take a bit vector
Apply a hash function M for each element and set the corresponding bit
Comparison Phase Necessary condition for subset satisfaction
• and)()( scrc )()()( rsssrs

Partition AlgorithmsReduce join execution time by partitioning the problem into smaller sub-problems.A partitioning function is used to partition the problem. An ideal partitioning function requires
Tuple r of R falls in one of the partitions Ri
Tuple s of S falls in one of Si
Join is accomplished by joining only Ri with Si

Partitioned Set Join Algorithm
Three phases of algorithm Partitioning Phase
Joining Phase
Verification Phase

Partition Set Join Algorithm (PSJ)
S({1,2,3,6})
R({1,2,3}) (3,0100001,OIDR)
(4,0100101,OIDS)Join

PSJ – Joining Phase
Any efficient algorithm for joining signatures can be used.
Signature based partition algorithm Partition R signatures based on randomly chosen bit that is set.
Probe each S signature multiple times for each bit set.
Outputs the result object id pairs (OIDR,OIDS).

PSJ – Pros and Cons
ProsEasy to implement – similar to hash joins
Easily parallelizable
Issues Determination of the number of partitions
Determination of the signature size

PSJ – Number of Partitions
Large number of partitions leads to large overhead
Smaller number of partitions leads to more join cost
Using a detailed analytical model
3)11(1(||||
ZFSR
PSk

PSJ – Signature Size
Inversely related to number of partitions
Cyclic dependency. Solve simultaneously and use bisection method
0))/11(1(
)1( /
PfPF
Pfe
S
RS
kkFk

Set Distributions
Many degrees of freedom
Each degree can follow a distribution of its own.
Huge distribution space!

Classifying Set Distributions
Small, Small Large, Small
Large, LargeSmall, Large
Relation Cardinality
Set
Card
inalit
y
Small Large
Sm
all
Larg
e

Performance – SettingsImplementation in research version of Paradise using extensible operator framework and Set AdtIntel Pentium 333 MHz - Solaris 2.6Main memory - 128 MBBuffer pool size - 32 MBUsed raw disks of size 4 GB and I/O bandwidth of 6 MB/secEach experiment was run against cold databaseSynthetic data set

Varying Relation Cardinality
0
5000
10000
15000
20000
25000
30000
5000 10000 25000 50000 75000 100000 125000
Relation Cardiinality
Res
pons
e T
ime
(sec
)
Sig-NL PSJ-1 PSJ SQL
Set Cardinality of 20

Cost Breakdown of Sig-NL
0
5000
10000
15000
20000
25000
30000
5000 10000 25000 50000 75000 100000 125000
Relation Cardiinality
Res
pons
e T
ime
(sec
)
Rsig-creat Ssig-creat Sig-Join Sort Verify
Set Cardinality of 20

Cost Breakdown of PSJ
0
200
400
600
800
1000
5000 10000 25000 50000 75000 100000 125000
Relation Cardiinality
Res
pons
e T
ime
(sec
)
Part-creat Spart-time Rpart-time Part-JoinPart-delete Sort Verify
Set Cardinality of 20

Effect of Signature Size
0
200
400
600
800
1000
1200
0 50 100 150 200
Signature Size (# bits)
Res
pon
se T
ime
(sec
)
Sig-NL PSJ
Relation Cardinality of 20000 and Set Cardinality of 20

Effect of Increasing Partitions
0200400600800
1000120014001600
2 4 8 16 32 64 128 256 512 1024
Partitions
Res
pons
e T
ime
(sec
)
Part-creat Spart-time Rpart-time Part-JoinPart-delete Sort Verify
Relation Cardinality of 20000 and Set Cardinality of 120
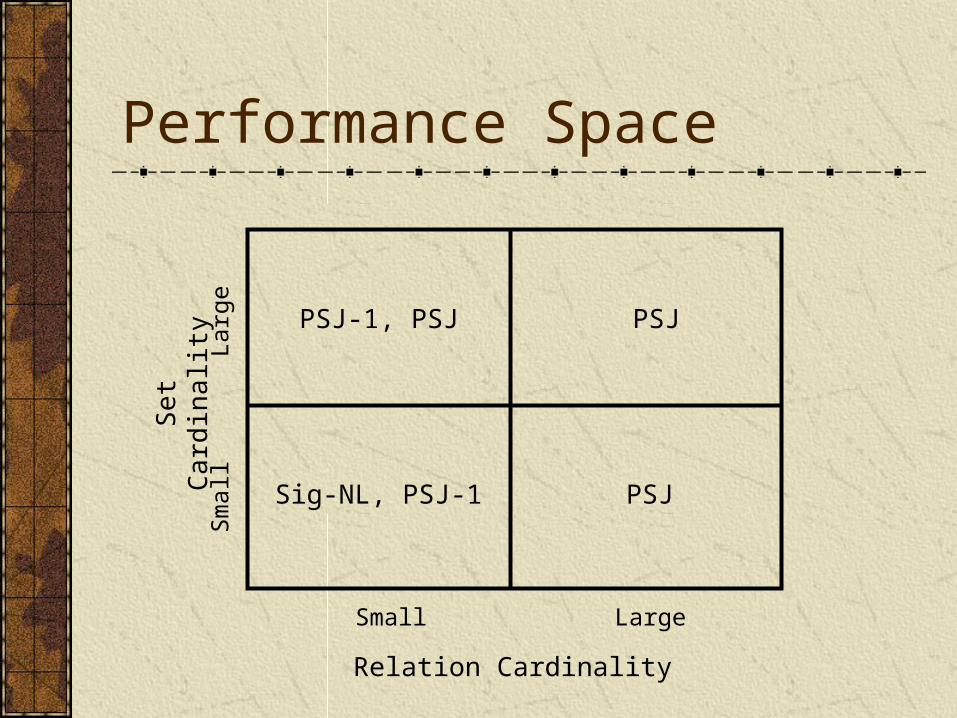
Performance Space
Sig-NL, PSJ-1 PSJ
PSJPSJ-1, PSJ
Relation Cardinality
Set
Card
inalit
y
Small Large
Sm
all
Larg
e

Conclusion
Developed a partition based algorithm for set containment joinsPerformance study shows that PSJ works well on most data setsThe advantages of PSJ are
Simple Effectiveness Easily parallelizable

Future Work
Algorithm can be easily extended for set intersection joins
Investigate the applicability of nested algorithms for unnested external representations





























