Embed Size (px)
Citation preview

A PROJECT REPORT ON
RFS FILE SYSTEM
SUBMITTED TO THE UNIVERSITY OF PUNE, PUNE IN THE PARTIAL FULFILLMENT OF THE REQUIREMENTS
FOR THE AWARD OF THE DEGREE
OF
BACHELOR OF ENGINEERING (INFORMATION TECHONOLOGY)
BY
Anish Bhatt Exam No : B2238512 Unmil Tambe Exam No : B2238600 Ravishankar Sarawadi Exam No : B2238593 Mohammad Tahir Abdulla Exam No.: B2238563
DEPARTMENT OF INFORMATION TECHONOLGY
STES’S SINHGAD COLLEGE OF ENGINEERING
VADGAON BK, OFF SINHGAD ROAD
PUNE 411041

APRIL 2006
CERTIFICATE
This is to certify that the project report entitles
“RFS FILE SYSTEM”
Submitted by
Anish Bhatt Exam No : B2238512 Unmil Tambe Exam No : B2238600 Ravishankar Sarawadi Exam No : B2238593 Mohammad Tahir Abdulla Exam No.: B2238563
is a bonafide work carried out by them under the supervision of Prof. A. W. Rohankar and it is approved for the partial fulfillment of the requirement of University of Pune,
Pune for the award of the degree of Bachelor of Engineering (Information Technology)
This project work has not been earlier submitted to any other Institute or University for the award of any degree or diploma. (Prof. A. W. Rohankar) (Prof. A. W. Rohankar) Guide Head, Department of Information Technology Department of Information
Technology
(Prof. A.S.Padalkar) Principal
Sinhgad College of Engineering
Place : Pune Date : 23rd March,2006

CONTENTS
CERTIFICATE I CERTIFICATE FROM INDUSTRY II ACKNOWLEDGEMENT III LIST OF FIGURES IV LIST OF TABLES V NOMENCLATURE VII
CHAPTER TITLE PAGE NO 1 INTRODUCTION
1.1 BACKGROUND 1.2 LITERATURE SURVEY 1.3 PROBLEM DEFINITION 1.4 SOFTWARE REQUIREMENT SPECIFICATION 1.5 PROJECT PLAN
2 PROJECT PLANNING AND MANAGEMENT
2.1 COST & EFFORT ESTIMATION 2.2 RISKS
3 PROJECT ANALYSIS
3.1 USE-CASE MODEL WITH SCENARIOS 3.2 INTERACTION DIAGRAMS
4 PROJECT DESIGN
4.1 HIGH LEVEL DESIGN 4.2 LOW LEVEL DESIGN
5 GLOSSARY 6 STUDY MATERIAL 7 PROJECT TESTING
7.1 UNIT TESTING 7.2 SYSTEM TESTING
8 CONCLUSIONS 9 APPENDIX 10 BIBLIOGRAPHY

INTRODUCTION

1.1 BACKGROUND
A portion of a disk that has bad sectors cannot be used because it is
flawed. When you format a disk, the operating system identifies any bad sectors on
the disk and marks them so they will not be used. If a sector that already contains data
becomes damaged, such data is lost. Recovery of such data is next to impossible.
Currently, such problems are solved through the use of backups or use of
high grade media, both of which are not cost effective and not suited for minimal
needs such as copying small but critical files or home use. A naïve user cannot invest
in backup software or pay for high grade media.
The project aims to solve this problem by use local replication and use of
hashing to ensure data integrity. Also by randomly spreading of chunks of data
blocks, data loss due to localization of media errors is avoided.

1.2 LITERATURE SURVEY : Our project “RFS File System (RFS)” comes under system level project
category. The project is completely based on Linux Kernel Handling & modifying
underlying structure to support functionality provided by RFS.
Since we had expertise to guide us throughout, who helped us to get basic
outline of project & directed our effort in way to complete project successfully.
Understanding Kernel functionality completely is not being easy task, we
referred many books to get in & out of it.
Few of them are viz:
1. Linux Kernel Development – Robert Love
2. Linux Device Drivers – Jonathan Cobert, Alessandro Rubini & Greg
Kroah-Hartman
3. Unix Operating System – Maurice J. Bach
4. Understanding the Linux Kernel – Daniel Bovet and Marco Cesati
5. Linux Kernel Primer
6. Linux Kernel Module Programming Guide
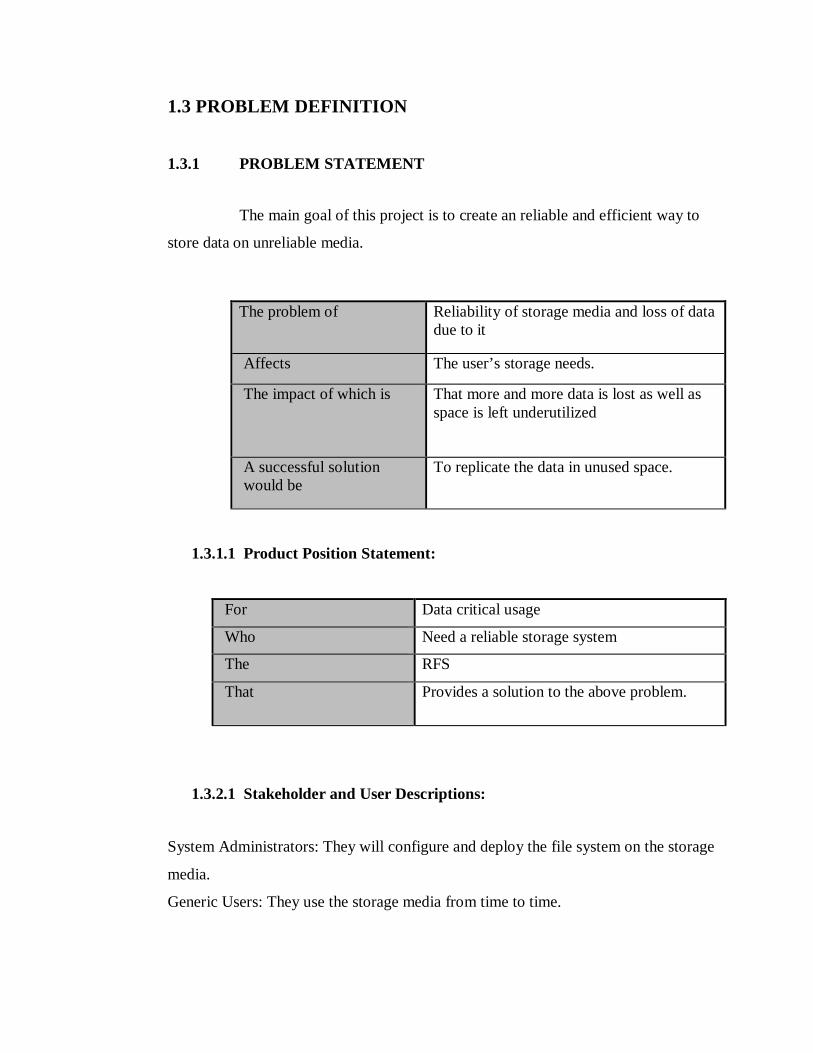
1.3 PROBLEM DEFINITION 1.3.1 PROBLEM STATEMENT
The main goal of this project is to create an reliable and efficient way to
store data on unreliable media.
1.3.1.1 Product Position Statement:
1.3.2.1 Stakeholder and User Descriptions:
System Administrators: They will configure and deploy the file system on the storage
media.
Generic Users: They use the storage media from time to time.
The problem of Reliability of storage media and loss of data due to it
Affects The user’s storage needs.
The impact of which is That more and more data is lost as well as space is left underutilized
A successful solution would be
To replicate the data in unused space.
For Data critical usage
Who Need a reliable storage system
The RFS
That Provides a solution to the above problem.
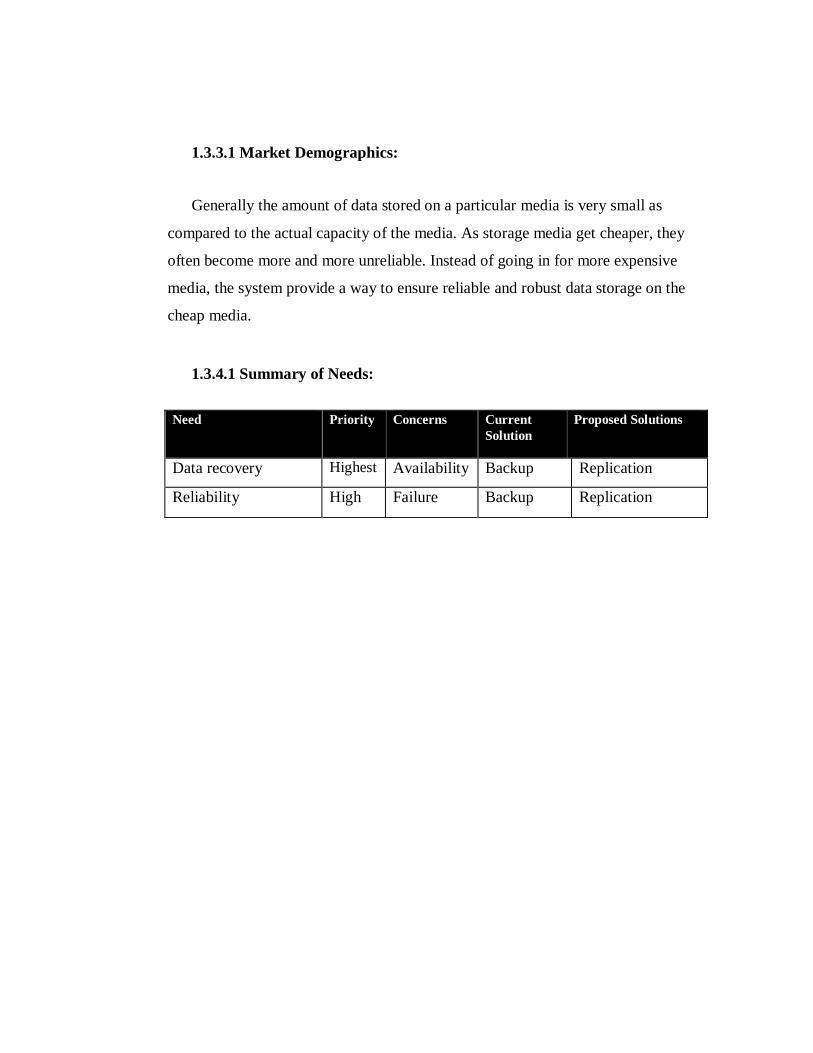
1.3.3.1 Market Demographics:
Generally the amount of data stored on a particular media is very small as
compared to the actual capacity of the media. As storage media get cheaper, they
often become more and more unreliable. Instead of going in for more expensive
media, the system provide a way to ensure reliable and robust data storage on the
cheap media.
1.3.4.1 Summary of Needs:
Need Priority Concerns Current Solution
Proposed Solutions
Data recovery Highest Availability Backup Replication
Reliability High Failure Backup Replication

SOFTWARE REQUIREMENTS SPECIFICATIONS

Introduction:
1.1 Purpose:
The purpose of this document is to formally specify requirements &
constraints required for the RFS File System. The SRS serves as architectural &
detailed design guide & also as reference for verification of RFS File System. The
intended audience for this document include any Linux user.
1.2 Project Scope: The project should perform following functions:
1. Reducing disk capacity to half.
2. Creating replica of file transparently in unused space i.e. second half. 3. Replicating metadata along with data.
4. Failsafe read & update of file. 5. Providing UNDELETE functionality.
1.3 Reference:
IEEE, “IEEE recommended Practice for Software Requirement Specification”.

Proposed System
2.1 System Perspective: The RFS File System is part of Linux operating system & it works only on
Linux Platform for linux kernel version greater than 2.6
2.2 User Characteristic: The user of this system is any general Linux operating system user being
aware of:
Storage media in use.
Basic operation of Linux OS.
2.3 Assumption & Dependencies:
Kernel source code must be compiled successfully with all
RFS modifications.
Atleast half of the contiguous blocks of the storage media re
readable.

Specific requirement:
3.1 Hardware Interface:
All processor architecture supported by Linux Kernel 2.6.
Minimum RAM required for proper functioning of LINUX OS.
Required input as well as output devices.
3.2 Software Interface:
RFS File System is totally developed in ANSI C-99
programming language.
Gnu C 2.91.66
E2fsprogs 1.19
3.3 Documentation & Training Requirement: It is core requirement of this project that RFS File System will come with
User Documentation. The documentation will be provided primarily through help
files & single hard copy will be provided which will contain installation
instruction. Apart from this a presentation of final deliverable is required which
will involve a short training run-through shoeing the functionality of RFS File
System.

PROJECT PLAN

PROJECT PLANNING AND MANAGEMENT

2.1 COST AND EFFORT ESTIMATION The Constructive Cost Model (COCOMO) is generally used for estimation
measures of cost, project duration, manpower, etc.
Like all estimation models, the COCOMO model requires sizing information. This
information can be specified in the form of
Object points
Function points (FP)
Lines of source code (KLOC)
For our project, we use the sizing information in the form of lines of source code
(KLOC).
Total lines of code for our project, KLOC=10K (approx.)
Cost of each person per month cp=Rs.6200/- (cost per person- month)
EQUATIONS:
Equation for calculation of efforts in person-months for the COCOMO model is:
Where,
a=3.0
b=1.12, for an Semi-detached project
E=Efforts in person-months
E = a * (KLOC)^b

Equation for calculation of duration of project in months for the COCOMO model
is:
Where,
c=2 .5
d=0.35 for a semi-detached project
D=Duration of project in months
Organic Project:
A project which involves data processing and tends to use Databases and focuses
on data retrieval.
Equations for calculation of number of people required for completion of the
project, using the COCOMO model is :
Where,
N=Number of people required
E=Efforts in person-months
D=Duration of project in months
Equation for calculation of Cost of project, using the COCOMO model is:
Where,
C=Cost of project
D=Duration of project in months
Cp=Cost incurred per person-month
D = c * (E)^d
N = E / D
C = D * Cp

Efforts:
E=3.0 (5) ^1.12
E=26.52 person-months
Total of 26.52 person-months are required to complete the project successfully.
Duration of project:
D=2.5* (E) ^0.35
D=7.8 months.
The approx. duration of the project is 7.8 months
Number of people required for the project:
N=26.52/7.8
N=3.4
N=4 people
Therefore 4 people are required to successfully complete the project on schedule.
Cost of project:
C=7.8 * 6200
C=48,360/-
Therefore Cost of project is Rs.48, 360/- (approx.)
2.2 RISKS
The aim to make the file system backward compatible with Ext2 and not
modifying the basic Ext2 structure is a risk as all the drawbacks of the Ext2 file system
will be reflected in this implementation too.

PROJECT ANALYSIS

3.1 USE-CASE MODEL WITH SCENARIOS
Fig 3.1 Level 0 Use Case Diagram

Fig 3.2 Level 1 Use Case Diagram
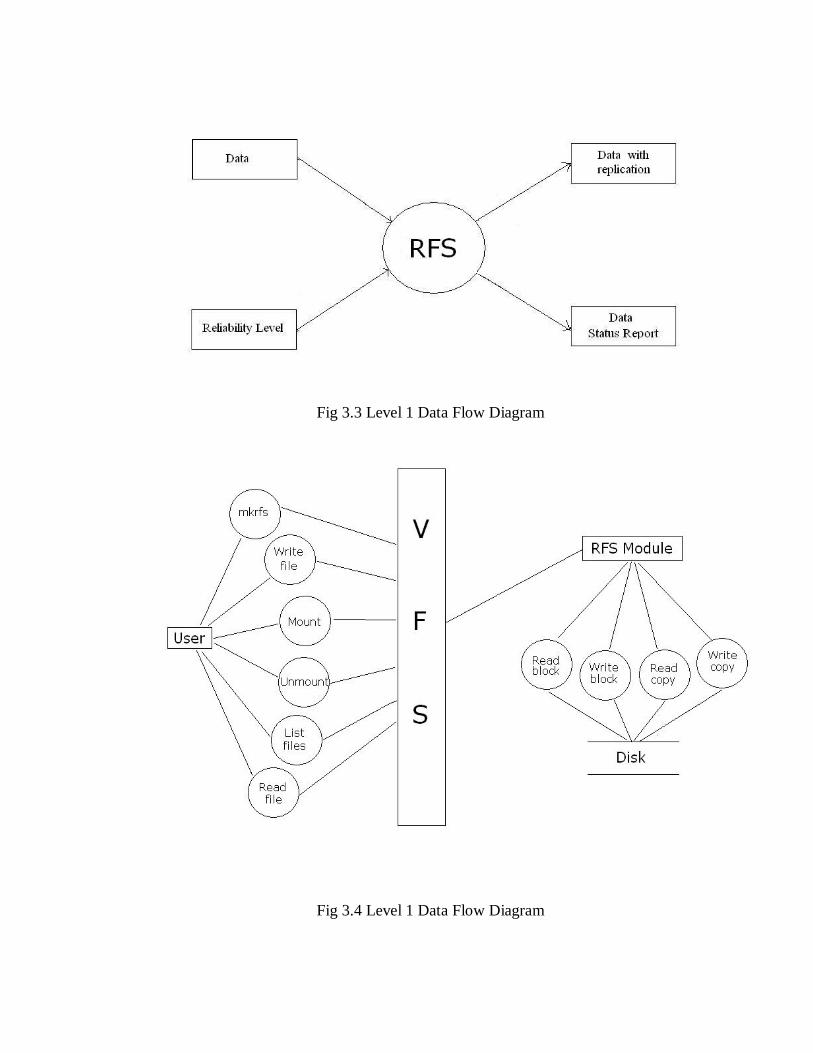
Fig 3.3 Level 1 Data Flow Diagram
Fig 3.4 Level 1 Data Flow Diagram

PROJECT DESIGN
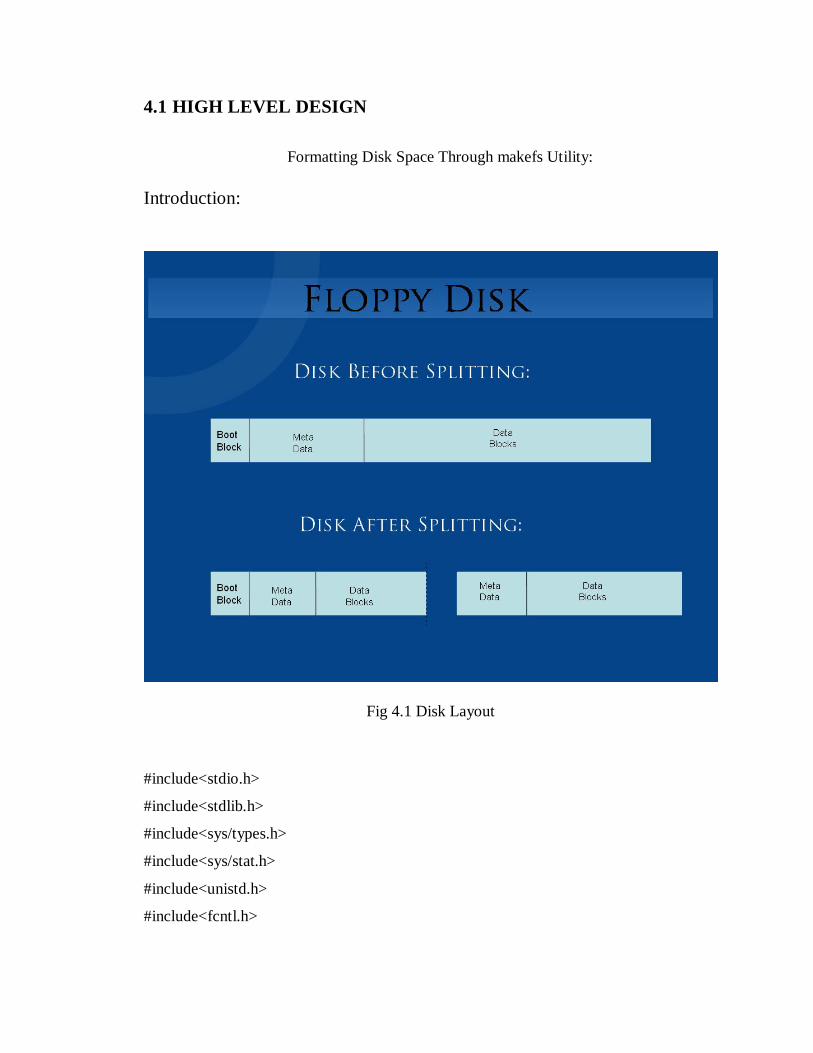
4.1 HIGH LEVEL DESIGN
Formatting Disk Space Through makefs Utility: Introduction:
Fig 4.1 Disk Layout
#include<stdio.h>
#include<stdlib.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<unistd.h>
#include<fcntl.h>

#include<linux/ext2_fs.h>
#define BOOT_BLOCK 1024
int main()
{
struct ext2_super_block *rfs_sb;
struct ext2_group_desc *rfs_bg;
struct ext2_inode *rfs_inode;
struct ext2_dir_entry_2 *rfs_dir;
int fd, block_size, inode_table, blocks, i, reclen_total=0, first_block_no, dec,
total_blocks, err, blk_bitmap_no, ino_bitmap_no;
char *buf, *buf1;
fd = open("floppy.img", O_RDWR);
if(fd==-1) return 1;
printf("\nFile opened successfully.\n");
/* Get superblock from location BOOT_BLOCK */
buf = (char *) malloc(1024);
lseek(fd, BOOT_BLOCK, SEEK_SET);
read(fd, buf, 1024);
rfs_sb = (struct ext2_super_block *) buf;
block_size = 1<<(10+rfs_sb->s_log_block_size);
printf("\nBlock size: %d\n", block_size);
printf("\nTotal blocks: %d\n", total_blocks = rfs_sb->s_blocks_count);
free(buf);

/* Modify superblock fields */
rfs_sb->s_r_blocks_count /= 2;
rfs_sb->s_free_blocks_count /= 2;
rfs_sb->s_free_inodes_count /= 2;
/*
rfs_sb->s_blocks_per_group /= 2;
rfs_sb->s_frags_per_group /= 2;
rfs_sb->s_inodes_per_group /= 2;
*/
/* Write modified sb to disk */
buf = (char *) malloc(1024);
buf = (char *) rfs_sb;
lseek(fd, BOOT_BLOCK, SEEK_SET);
write(fd, buf, 1024);
free(buf);
/* Get block group descriptor placed right after superblock, for the inode table
location */
buf = (char *) malloc(block_size);
lseek(fd, BOOT_BLOCK+block_size, SEEK_SET);
read(fd, buf, block_size);
rfs_bg = (struct ext2_group_desc *) buf;
printf("\nBlock bitmap location: %d\n", blk_bitmap_no=rfs_bg->bg_block_bitmap);
printf("\nBlock bitmap location: %d\n", ino_bitmap_no=rfs_bg->bg_inode_bitmap);
free(buf);

/* Modify block group descriptor */
rfs_bg->bg_free_blocks_count /= 2;
rfs_bg->bg_free_inodes_count /= 2;
buf = (char *) malloc(block_size);
buf = (char *) rfs_bg;
lseek(fd, BOOT_BLOCK+block_size, SEEK_SET);
write(fd, buf, block_size);
free(buf);
/* read block bitmap */
buf = (char *) malloc(block_size);
lseek(fd, block_size * rfs_bg->bg_block_bitmap, SEEK_SET);
read(fd, buf, block_size);
buf1 = buf;
/* modify it */
buf1[89]=buf1[179];
for(i=90;i<180;i++)
buf1[i]=-1;
lseek(fd, block_size * blk_bitmap_no, SEEK_SET);
err = write(fd, buf1, block_size);
printf("Bytes written = %d", err);
free(buf1);

/* read inode bitmap */
buf = (char *) malloc(block_size);
lseek(fd, block_size * ino_bitmap_no, SEEK_SET);
read(fd, buf, block_size);
buf1 = buf;
/* modify buffer */
buf1[11]=240;
for(i=12; i<23; i++)
buf1[i]=-1;
/* write it to disk */
lseek(fd, block_size * ino_bitmap_no, SEEK_SET);
err = write(fd, buf1, block_size);
printf("Bytes written = %d", err);
free(buf1);
/* copy block group*/
lseek(fd,0 , SEEK_SET);
buf = (char *) malloc(block_size*30);
read(fd, buf, block_size*30);
lseek(fd,block_size* (total_blocks/2), SEEK_SET);
err= write(fd,buf,block_size*30);
free(buf);
close(fd);
return 0;
}

4.2 LOW LEVEL DESIGN
RFS Write Operation: Introduction:
Fig 4.2 Write Operation
int rfs_commit_write(struct file *file, struct page *page,
unsigned from, unsigned to)
{
struct inode *inode = page->mapping->host;
loff_t pos = ((loff_t)page->index << PAGE_CACHE_SHIFT) + to;
__rfs_block_commit_write(inode,page,from,to);
/* No need to use i_size_read() here, the i_size cannot change under us because
we hold i_sem. */

if (pos > inode->i_size) {
i_size_write(inode, pos);
mark_inode_dirty(inode);
}
return 0;
}
int __rfs_block_commit_write(struct inode *inode, struct page *page,
unsigned from, unsigned to)
{
unsigned block_start, block_end;
int partial = 0;
unsigned blocksize;
struct buffer_head *bh, *head;
blocksize = 1 << inode->i_blkbits;
for(bh = head = page_buffers(page), block_start = 0;
bh != head || !block_start;
block_start=block_end, bh = bh->b_this_page) {
block_end = block_start + blocksize;
if (block_end <= from || block_start >= to) {
if (!buffer_uptodate(bh))
partial = 1;
} else {
set_buffer_uptodate(bh);
rfs_dup_write(bh);
mark_buffer_dirty(bh);

}
}
/*
* If this is a partial write which happened to make all buffers
* uptodate then we can optimize away a bogus readpage() for
* the next read(). Here we 'discover' whether the page went
* uptodate as a result of this (potentially partial) write.
*/
if (!partial)
SetPageUptodate(page);
return 0;
}
int rfs_dup_write(struct buffer_head *bh)
{
struct page *rfs_page;
struct buffer_head *rfs_bh;
printk("\ndup_write- bh:\tblock:%lu data:%s count:%d", bh->b_blocknr, bh-
>b_data, atomic_read(&bh->b_count));
rfs_page = alloc_page(GFP_KERNEL | __GFP_ZERO);
if(!rfs_page)
{
printk("\nNo page.\n");
}
else
{

printk("\nGot page.\n");
rfs_bh = alloc_page_buffers(rfs_page, 1024, 0);
memcpy(rfs_bh, bh, sizeof(*bh));
lock_buffer(rfs_bh);
rfs_bh->b_end_io = end_buffer_write_sync;
rfs_bh->b_private = NULL;
rfs_bh->b_blocknr = bh->b_blocknr+720;
set_buffer_mapped(rfs_bh);
set_buffer_dirty(rfs_bh);
printk("rfs_bh:\tblock:%lu data:%s count:%d", rfs_bh->b_blocknr, rfs_bh-
>b_data, atomic_read(&bh->b_count));
submit_bh(WRITE, rfs_bh);
/* Cleaning the buffer */
unlock_buffer(rfs_bh);
if (atomic_read(&rfs_bh->b_count))
{
put_bh(rfs_bh);
}
printk("\nput_bh done.");
/* Cleaning the page*/
clear_page_dirty(rfs_page);
ClearPageUptodate(rfs_page);
ClearPageMappedToDisk(rfs_page);
printk("\nTryin to free page");
page_cache_release(rfs_page);

printk("\nPage freed. Done.\n");
}
return 0;
}
Calling functions:
balloc.c:
static int group_reserve_blocks(struct ext2_sb_info *sbi, int group_no,
struct ext2_group_desc *desc, struct buffer_head *bh, int count);
static void group_release_blocks(struct super_block *sb, int group_no,
struct ext2_group_desc *desc, struct buffer_head *bh, int count);
inode.c:
static int ext2_alloc_branch(struct inode *inode,int num,unsigned long goal, int
*offsets,Indirect *branch);
static inline int ext2_splice_branch(struct inode *inode,long block,
Indirect chain[4],Indirect *where, int num);
void ext2_truncate (struct inode * inode);
super.c:
static void ext2_commit_super (struct super_block * sb,
struct ext2_super_block * es);

Fig 4.3 File Update
Fig 4.4 Disk Write

RFS Read Operation:
static int ext2_fill_super(struct super_block *sb, void *data, int silent) { struct buffer_head * bh; struct ext2_sb_info * sbi; struct ext2_super_block * es; struct inode *root; unsigned long block; unsigned long sb_block = get_sb_block(&data); unsigned long logic_sb_block; unsigned long offset = 0; unsigned long def_mount_opts; int blocksize = BLOCK_SIZE; int db_count; int i, j; __le32 features; sbi = kmalloc(sizeof(*sbi), GFP_KERNEL); if (!sbi) return -ENOMEM; sb->s_fs_info = sbi; memset(sbi, 0, sizeof(*sbi)); blocksize = sb_min_blocksize(sb, BLOCK_SIZE); if (!blocksize) { printk ("EXT2-fs: unable to set blocksize\n"); goto failed_sbi; } /* * If the superblock doesn't start on a hardware sector boundary, * calculate the offset. */ if (blocksize != BLOCK_SIZE) { logic_sb_block = (sb_block*BLOCK_SIZE) / blocksize; offset = (sb_block*BLOCK_SIZE) % blocksize; } else { logic_sb_block = sb_block; } if (!(bh = sb_bread(sb, logic_sb_block))) { printk ("EXT2-fs: unable to read superblock from block %lu\n",
logic_sb_block);

// RFS start if ((bh = sb_bread(sb, 721))) { printk("\nEXT2-fs: read secondary superblock"); } else { printk ("\nEXT2-fs: unable to read secondary superblock"); goto failed_sbi; } // RFS end }........continued
Fig 4.5 Normal File Open
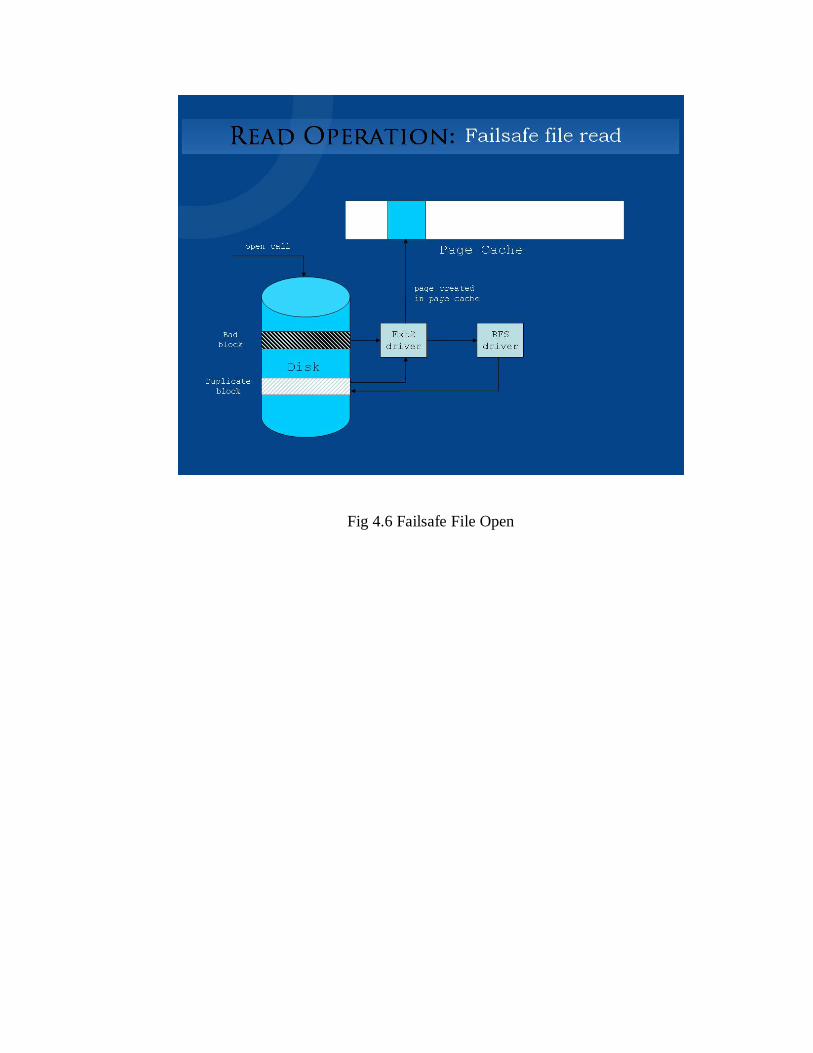
Fig 4.6 Failsafe File Open

GLOSSARY

5.1 Introduction:
5.1.1 Purpose This document sets out common technical vocabulary for this project. This
glossary will be expanded throughout the life of project.
5.1.2 Scope: This document will limit itself to describing technical terms specific to
this project. Do not use this document to define the terms generally understood
i.e. terms those are adequately defined in dictionary.
5.1.3 References: 1. Linux Kernel Development – Robert Love
2. Linux Device Drivers – Jonathan Cobert, Alessandro Rubini &
Greg Kroah-Hartman
3. Unix Operating System – Maurice J. Bach
4. Understanding the Linux Kernel –Bovet and Cesati
5. Linux Kernel Primer

5.2 Definitions:
Hard Disc/Floppy Disk: Rigid magnetic disks those are able to store data. Hard disk has much
more capacity to store data than floppy disk. Normally hard disks are fit inside PC
cabinet but floppy disks are removable. In Pc language hard disk are known by
c,d drives where as floppy disk is called by a drive. Hard disk can normally store
several hundred million bytes (or characters) of information, whereas floppy disk
can store 1.44MB data.
Kernel: The core of layered architecture that manages the most basic operations of
operating system & computer processor. The kernel schedules different blocks of
executing code, called threads, for the processor to keep it as busy as possible &
coordinates multiple processes to optimize performance. The kernel also
synchronizes activities among Executive-level sub-components, such as I/O
manager & process manager,& handles hardware exceptions & other hardware
dependent functions.
FileSystem: In an operating system, the overall structure in which files are stored,
named & organized. EXT, NTFS,FAT & FAT32 are few of filesystems used.
Device Driver: A program that allows a specific device, such as modem, network adapter,
printer to communicate with the operating system.

Root File System or rootfs: Main file system of LINUX operating system which is required for
booting.
Makefs: It is utility that creates a filesystem on disk.
Ext2 FileSystem: Extended 2 file system for Linux operating system.
VFS: The Virtual File System (also known as Virtual File system Switch) is the
software layer in kernel that provides the file system interface to user space
programs. It also provides an abstraction within the kernel which allows different
file system implementations to co-exist.
Boot Loader: Program which loads kernel in RAM & passes control; of execution to it.
Module: Modules are stored in the filesystem as ELF object files and are linked to
the kernel by executing the insmod program. For each module, the kernel
allocates a memory area containing the following data:
1. A module object
2. A null-terminated string that represents the name of the module (all modules
must have unique names).
3. The code that implements the functions of the module.
Data Structure: Programming language abstraction provided to store the data required by

program. Various kernel structures like inode, superblock etc are used to modify
functionality. Also new data structure or new fields inside structure are created for
same.
Dentry Object: The VFS often needs to perform directory specific operations, such as path
name lookups. To facilitate this the VFS employs concept of Directory Entry
(dentry). Dentry is specific component in path. E.g. in path /bin/vi the following
are dentry object /,bin,vi. First two are directories & last one is file.
Export Functions: Each source file exports functions or variables that may be accessed by
other part of program or by other modules. For simplicity, all exported functions
& variables are declared in single header file which is included by other files.
Inodes: The VFS uses index-nodes (inodes) to represent file or logical file system.
The inode data structure stores the mapping of block numbers to physical device
address.
Page: The basic unit of memory management used by kernel.also the processor’s
smallest addressable unit is usually a word, the MMU typically deal in pages. It is
represented in the kernel with data structure “struct page”.
Superblock Object: Superblock object is implemented by each file system & is used to store
information describing that filesystem. This is usually corresponds to filesystem

superblock which is stored in special sector on disk. The file system that are not
disk based (VFS) generate superblock on fly & store it in memory.

STUDY MATERIAL
Virtual Filesystem Switch (VFS):
One of Linux's keys to success is its ability to coexist comfortably with other
systems. You can transparently mount disks or partitions that host file formats used by
Windows , other Unix systems. Linux manages to support multiple filesystem types in
the same way other Unix variants do, through a concept called the Virtual Filesystem.
The idea behind the Virtual Filesystem is to put a wide range of information in the
kernel to represent many different types of filesystems ; there is a field or function to
support each operation provided by all real filesystems supported by Linux. For each
read, write, or other function called, the kernel substitutes the actual function that
supports a native Linux filesystem, the NTFS filesystem, or whatever other filesystem the
file is on.

The Role of the VFS:
The Virtual Filesystem (also known as Virtual Filesystem Switch or VFS) is a kernel
software layer that handles all system calls related to a standard Unix filesystem. Its main
strength is providing a common interface to several kinds of filesystems.
For instance, let's assume that a user issues the shell command:
$ cp /floppy/TEST /tmp/test
where /floppy is the mount point of an MS-DOS diskette and /tmp is a normal Second
Extended Filesystem (Ext2) directory. The VFS is an abstraction layer between the
application program and the filesystem implementations. Therefore, the cp program is not
required to know the filesystem types of /floppy/TEST and /tmp/test. Instead, cp interacts
with the VFS by means of generic system calls known to anyone who has done Unix
programming.
Fig 6.1 : VFS role in a simple file copy operation

Filesystems supported by the VFS may be grouped into three main classes:
Disk-based filesystems
These manage memory space available in a local disk or in some other device that
emulates a disk (such as a USB flash drive). Some of the well-known disk-based
filesystems supported by the VFS are such as the widely used Second Extended
Filesystem (Ext2), the recent Third Extended Filesystem (Ext3), and the Reiser
Filesystems (ReiserFS ).
Network filesystems
These allow easy access to files included in filesystems belonging to other
networked computers. Some well-known network filesystems supported by the
VFS are NFS , Coda , AFS (Andrew filesystem), CIFS (Common Internet File
System, used in Microsoft Windows ), and NCP (Novell's NetWare Core
Protocol).
Special filesystems
These do not manage disk space, either locally or remotely. The /proc filesystem
is a typical example of a special filesystem.
The Common File Model:
The idea behind the VFS consists of introducing a common file model capable of
representing all supported filesystems. This model strictly mirrors the file model provided
by the traditional Unix filesystem. This is not surprising, because Linux wants to run its
native filesystem with minimum overhead. However, each specific filesystem

implementation must translate its physical organization into the VFS's common file
model.
For instance, in the common file model, each directory is regarded as a file, which
contains a list of files and other directories. However, several non-Unix disk-based
filesystems use a File Allocation Table (FAT), which stores the position of each file in
the directory tree. In these filesystems, directories are not files. To stick to the VFS's
common file model, the Linux implementations of such FAT-based filesystems must be
able to construct on the fly, when needed, the files corresponding to the directories. Such
files exist only as objects in kernel memory.
More essentially, the Linux kernel cannot hardcode a particular function to handle
an operation such as read( ) or ioctl( ) . Instead, it must use a pointer for each
operation; the pointer is made to point to the proper function for the particular filesystem
being accessed
The common file model consists of the following object types:
The superblock object:
Stores information concerning a mounted filesystem. For disk-based filesystems,
this object usually corresponds to a filesystem control block stored on disk.
The inode object:
Stores general information about a specific file. For disk-based filesystems, this
object usually corresponds to a file control block stored on disk. Each inode
object is associated with an inode number, which uniquely identifies the file
within the filesystem.
The file object:

Stores information about the interaction between an open file and a process. This
information exists only in kernel memory during the period when a process has
the file open.
The dentry object:
Stores information about the linking of a directory entry (that is, a particular name
of the file) with the corresponding file. Each disk-based filesystem stores this
information in its own particular way on disk.
Figure illustrates with a simple example how processes interact with files. Three
different processes have opened the same file, two of them using the same hard link. In
this case, each of the three processes uses its own file object, while only two dentry
objects are requiredone for each hard link. Both dentry objects refer to the same inode
object, which identifies the superblock object and, together with the latter, the common
disk file.
Fig 6.2 : Interaction between processes and VFS objects

VFS Data Structures
Each VFS object is stored in a suitable data structure, which includes both the
object attributes and a pointer to a table of object methods. The kernel may dynamically
modify the methods of the object and, hence, it may install specialized behavior for the
object. The following sections explain the VFS objects and their interrelationships in
detail.
Superblock Objects
All superblock objects are linked in a circular doubly linked list. The first element
of this list is represented by the super_blocks variable, while the s_list field of
the superblock object stores the pointers to the adjacent elements in the list. The
sb_lock spin lock protects the list against concurrent accesses in multiprocessor
systems.
The s_fs_info field points to superblock information that belongs to a specific
filesystem; for instance, if the superblock object refers to an Ext2 filesystem, the field
points to an ext2_sb_info structure, which includes the disk allocation bit masks and
other data of no concern to the VFS common file model.
Inode Objects
All information needed by the filesystem to handle a file is included in a data
structure called an inode. A filename is a casually assigned label that can be changed, but
the inode is unique to the file and remains the same as long as the file exists. An inode
object in memory consists of an inode structure
Each inode object duplicates some of the data included in the disk inodefor
instance, the number of blocks allocated to the file. When the value of the i_state
field is equal to I_DIRTY_SYNC, I_DIRTY_DATASYNC, or I_DIRTY_PAGES, the

inode is dirtythat is, the corresponding disk inode must be updated. The I_DIRTY macro
can be used to check the value of these three flags at once (see later for details). Other
values of the i_state field are I_LOCK (the inode object is involved in an I/O
transfer), I_FREEING (the inode object is being freed), I_CLEAR (the inode object
contents are no longer meaningful), and I_NEW (the inode object has been allocated but
not yet filled with data read from the disk inode).
Each inode object always appears in one of the following circular doubly linked lists
(in all cases, the pointers to the adjacent elements are stored in the i_list field):
The list of valid unused inodes, typically those mirroring valid disk inodes and not
currently used by any process. These inodes are not dirty and their i_count
field is set to 0. The first and last elements of this list are referenced by the next
and prev fields, respectively, of the inode_unused variable. This list acts as a
disk cache.
The list of in-use inodes, that is, those mirroring valid disk inodes and used by
some process. These inodes are not dirty and their i_count field is positive. The
first and last elements are referenced by the inode_in_use variable.
The list of dirty inodes. The first and last elements are referenced by the
s_dirty field of the corresponding superblock object.
File Objects
A file object describes how a process interacts with a file it has opened. The
object is created when the file is opened and consists of a file structure. Notice that file
objects have no corresponding image on disk, and hence no "dirty" field is included in the
file structure to specify that the file object has been modified.
The main information stored in a file object is the file pointerthe current position
in the file from which the next operation will take place. Because several processes may

access the same file concurrently, the file pointer must be kept in the file object rather
than the inode object.
File objects are allocated through a slab cache named filp, whose descriptor
address is stored in the filp_cachep variable. Because there is a limit on the number
of file objects that can be allocated, the files_stat variable specifies in the
max_files field the maximum number of allocatable file objectsi.e., the maximum
number of files that can be accessed at the same time in the system.
dentry Objects
VFS considers each directory a file that contains a list of files and other
directories. Once a directory entry is read into memory, however, it is transformed by the
VFS into a dentry object based on the dentry structure. The kernel creates a dentry
object for every component of a pathname that a process looks up; the dentry object
associates the component to its corresponding inode. For example, when looking up the
/tmp/test pathname, the kernel creates a dentry object for the / root directory, a second
dentry object for the tmp entry of the root directory, and a third dentry object for the test
entry of the /tmp directory.
Dentry objects have no corresponding image on disk, and hence no field is
included in the dentry structure to specify that the object has been modified. Dentry
objects are stored in a slab allocator cache whose descriptor is dentry_cache; dentry
objects are thus created and destroyed by invoking kmem_cache_alloc( ) and
kmem_cache_free( ).
Filesystem Type Registration
The VFS must keep track of all filesystem types whose code is currently included in the kernel. It does this by performing filesystem type registration .
Each registered filesystem is represented as a file_system_type object whose fields are illustrated

Type Field Description const char * name Filesystem name Int fs_flags Filesystem type flags struct super_block * (*)( ) get_sb Method for reading a superblock
void (*)( ) kill_sb Method for removing a superblock
struct module * owner Pointer to the module implementing the filesystem
struct file_system_type * next Pointer to the next element in the list of
filesystem types
struct list_head fs_supers Head of a list of superblock objects having the same filesystem type
Table 6.1 : The fields of the file_system_type object
All filesystem-type objects are inserted into a singly linked list. The
file_systems variable points to the first item, while the next field of the structure
points to the next item in the list. The file_systems_lock read/write spin lock
protects the whole list against concurrent accesses.
Filesystem Handling
Like every traditional Unix system, Linux makes use of a system's root filesystem
: it is the filesystem that is directly mounted by the kernel during the booting phase and
that holds the system initialization scripts and the most essential system programs.
Other filesystems can be mountedeither by the initialization scripts or directly by
the userson directories of already mounted filesystems. Being a tree of directories, every
filesystem has its own root directory. The directory on which a filesystem is mounted is
called the mount point. A mounted filesystem is a child of the mounted filesystem to
which the mount point directory belongs. For instance, the /proc virtual filesystem is a
child of the system's root filesystem (and the system's root filesystem is the parent of

/proc). The root directory of a mounted filesystem hides the content of the mount point
directory of the parent filesystem, as well as the whole subtree of the parent filesystem
below the mount point.
Namespaces
In a traditional Unix system, there is only one tree of mounted filesystems:
starting from the system's root filesystem, each process can potentially access every file
in a mounted filesystem by specifying the proper pathname. In this respect, Linux 2.6 is
more refined: every process might have its own tree of mounted filesystemsthe so-called
namespace of the process.
Filesystem Mounting
For Linux, it is possible to mount the same filesystem several times. Of course, if
a filesystem is mounted n times, its root directory can be accessed through n mount
points, one per mount operation. Although the same filesystem can be accessed by using
different mount points, it is really unique. Thus, there is only one superblock object for
all of them, no matter of how many times it has been mounted.
Mounted filesystems form a hierarchy: the mount point of a filesystem might be a
directory of a second filesystem, which in turn is already mounted over a third filesystem,
and so on.
It is also possible to stack multiple mounts on a single mount point. Each new
mount on the same mount point hides the previously mounted filesystem, although
processes already using the files and directories under the old mount can continue to do
so. When the topmost mounting is removed, then the next lower mount is once more
made visible.

As you can imagine, keeping track of mounted filesystems can quickly become a
nightmare. For each mount operation, the kernel must save in memory the mount point
and the mount flags, as well as the relationships between the filesystem to be mounted
and the other mounted filesystems. Such information is stored in a mounted filesystem
descriptor of type vfsmount.
Mounting a Generic Filesystem
The mount( ) system call is used to mount a generic filesystem; its
sys_mount( ) service routine is used. The sys_mount( ) function copies the
value of the parameters into temporary kernel buffers, acquires the big kernel lock , and
invokes the do_mount( ) function. Once do_mount( ) returns, the service routine
releases the big kernel lock and frees the temporary kernel buffers. The do_mount (
) function takes care of the actual mount operation
The core of the mount operation is the do_kern_mount( ) function, which
checks the filesystem type flags to determine how the mount operation is to be done.
Mounting the Root Filesystem
Mounting the root filesystem is a crucial part of system initialization. It is a fairly
complex procedure, because the Linux kernel allows the root filesystem to be stored in
many different places, such as a hard disk partition, a floppy disk, a remote filesystem
shared via NFS, or even a ramdisk (a fictitious block device kept in RAM).
Mounting the root filesystem is a two-stage procedure, shown in the following list:
1. The kernel mounts the special rootfs filesystem, which simply provides an empty
directory that serves as initial mount point.
2. The kernel mounts the real root filesystem over the empty directory.
Phase 1: Mounting the rootfs filesystem

The first stage is performed by the init_rootfs( ) and
init_mount_tree( ) functions, which are executed during system initialization.
The init_rootfs( ) function registers the special filesystem type rootfs:
struct file_system_type rootfs_fs_type = {
.name = "rootfs";
.get_sb = rootfs_get_sb;
.kill_sb = kill_litter_super;
};
register_filesystem(&rootfs_fs_type);
Phase 2: Mounting the real root filesystem
The second stage of the mount operation for the root filesystem is performed by
the kernel near the end of the system initialization. There are several ways to mount the
real root filesystem, according to the options selected when the kernel has been compiled
and to the boot options passed by the kernel loader. For the sake of brevity, we consider
the case of a disk-based filesystem whose device file name has been passed to the kernel
by means of the "root" boot parameter. We also assume that no initial special filesystem
is used, except the rootfs filesystem.
Block Device Drivers
The key aspect of a block device is the disparity between the time taken by the
CPU and buses to read or write data and the speed of the disk hardware. Block devices
have very high average access times. Each operation requires several milliseconds to
complete, mainly because the disk controller must move the heads on the disk surface to

reach the exact position where the data is recorded. However, when the heads are
correctly placed, data transfer can be sustained at rates of tens of megabytes per second.
Block Devices Handling
Each operation on a block device driver involves a large number of kernel
components.
Fig 6.3 : Kernel components affected by a block device operation
There are many kernel components that are concerned with data stored in block
devices;each of them manages the disk data using chunks of different length.Even if there
are many different chunks of data, they usually share the same physical RAM cells. For
instance, Figure shows the layout of a 4,096-byte page. The upper kernel components
see the page as composed of four block buffers of 1,024 bytes each. The last three blocks
of the page are being transferred by the block device driver, thus they are inserted in a

segment covering the last 3,072 bytes of the page. The hard disk controller considers the
segment as composed of six 512-byte sectors.
Fig 6.4 : Typical layout of a page including disk data
The Page Cache
Disk caches are crucial for system performance, because repeated accesses
to the same disk data are quite common. A User Mode process that interacts with a disk is
entitled to ask repeatedly to read or write the same disk data. Moreover, different
processes may also need to address the same disk data at different times.
The page cache is the main disk cache used by the Linux kernel. In most cases,
the kernel refers to the page cache when reading from or writing to disk. New pages are
added to the page cache to satisfy User Mode processes's read requests. If the page is not
already in the cache, a new entry is added to the cache and filled with the data read from
the disk. If there is enough free memory, the page is kept in the cache for an indefinite
period of time and can then be reused by other processes without accessing the disk.

Similarly, before writing a page of data to a block device, the kernel verifies
whether the corresponding page is already included in the cache; if not, a new entry is
added to the cache and filled with the data to be written on disk. The I/O data transfer
does not start immediately: the disk update is delayed for a few seconds, thus giving a
chance to the processes to further modify the data to be written (in other words, the
kernel implements deferred write operations).
Kernel code and kernel data structures don't need to be read from or written to
disk. Thus, the pages included in the page cache can be of the following types:
Pages containing data of regular files.
Pages containing directories.
Pages containing data directly read from block device files (skipping the
filesystem layer).
Pages containing data of User Mode processes that have been swapped out on
disk.
Pages belonging to files of special filesystems, such as the shm special filesystem
used for Interprocess Communication (IPC)
The address_space Object
The core data structure of the page cache is the address_space object, a data
structure embedded in the inode object that owns the page. Many pages in the cache may
refer to the same owner, thus they may be linked to the same address_space object.
This object also establishes a link between the owner's pages and a set of methods that
operate on these pages.
Each page descriptor includes two fields called mapping and index, which link
the page to the page cache. The first field points to the address_space object of the
inode that owns the page. The second field specifies the offset in page-size units within
the owner's "address space," that is, the position of the page's data inside the owner's disk
image. These two fields are used when looking for a page in the page cache.

Block Buffers and Buffer Heads
Each block buffer has a buffer head descriptor of type buffer_head. This
descriptor contains all the information needed by the kernel to know how to handle the
block; thus, before operating on each block, the kernel checks its buffer head. The fields
of a buffer head are listed :
Type Field Description
unsigned long b_state Buffer status flags
struct
buffer_head *
b_this_page Pointer to the next element in the buffer
page's list
struct page * b_page Pointer to the descriptor of the buffer page
holding this block
Atomic_t b_count Block usage counter
U32 b_size Block size
sector_t b_blocknr Block number relative to the block device
(logical block number)
char * b_data Position of the block inside the buffer page
Struct
block_device *
b_bdev Pointer to block device descriptor
bh_end_io_t * b_end_io I/O completion method
void * b_private Pointer to data for the I/O completion method
struct list_head b_assoc_buffers Pointers for the list of indirect blocks
associated with an inode
Table 6.2 : The fields of a buffer head

Two fields of the buffer head encode the disk address of the block: the b_bdev field
identifies the block deviceusually, a disk or a partitionthat contains the block while the
b_blocknr field stores the logical block number, that is, the index of the block inside its
disk or partition.The b_data field specifies the position of the block buffer inside the
buffer page.
Managing the Buffer Heads
The buffer heads have their own slab allocator cache, whose kmem_cache_s
descriptor is stored in the bh_cachep variable. The alloc_buffer_head( ) and
free_buffer_head( ) functions are used to get and release a buffer head,
respectively.
Buffer Pages
Whenever the kernel must individually address a block, it refers to the buffer page
that holds the block buffer and checks the corresponding buffer head.
Here are two common cases in which the kernel creates buffer pages:
When reading or writing pages of a file that are not stored in contiguous disk
blocks. This happens either because the filesystem has allocated noncontiguous
blocks to the file, or because the file contains "holes"
When accessing a single disk block (for instance, when reading a superblock or an
inode block).

Fig 6.5 : A buffer page including four buffers and their buffer heads
Submitting Buffer Heads to the Generic Block Layer
A couple of functions, submit_bh( ) and ll_rw_block( ), allow the
kernel to start an I/O data transfer on one or more buffers described by their buffer heads.
The submit_bh( ) function
To transmit a single buffer head to the generic block layer, and thus to require the
transfer of a single block of data, the kernel makes use of the submit_bh( ) function.
Its parameters are the direction of data transfer (essentially READ or WRITE) and a
pointer bh to the buffer head describing the block buffer.
The submit_bh( ) function assumes that the buffer head is fully initialized; in
particular, the b_bdev, b_blocknr, and b_size fields must be properly set to
identify the block on disk containing the requested data. If the block buffer belongs to a
block device buffer page, the initialization of the buffer If the ll_rw_block( )
function passes a buffer head to the generic block layer, it leaves the buffer locked and its
reference counter increased, so that the buffer cannot be accessed and cannot be freed

until the data transfer completes. The kernel executes the b_end_io completion method
of the buffer head when the data transfer for the block terminates. Assuming that there
was no I/O error, the end_buffer_write_sync( ) and
end_buffer_read_sync( ) functions simply set the BH_Uptodate field of the
buffer head, unlock the buffer, and decrease its usage counter.
The ll_rw_block( ) function
Sometimes the kernel must trigger the data transfer of several data blocks at once,
which are not necessarily physically adjacent. The ll_rw_block( ) function receives
as its parameters the direction of data transfer (essentially READ or WRITE), the number
of blocks to be transferred, and an array of pointers to buffer heads describing the
corresponding block buffers. The function iterates over all buffer heads.
If the ll_rw_block( ) function passes a buffer head to the generic block
layer, it leaves the buffer locked and its reference counter increased, so that the buffer
cannot be accessed and cannot be freed until the data transfer completes. The kernel
executes the b_end_io completion method of the buffer head when the data transfer for
the block terminates. Assuming that there was no I/O error, the
end_buffer_write_sync( ) and end_buffer_read_sync( ) functions
simply set the BH_Uptodate field of the buffer head, unlock the buffer, and decrease
its usage counter.
The Ext2 Filesystem
The Second Extended Filesystem (Ext2) is native to Linux and is used on
virtually every Linux system. Furthermore, Ext2 illustrates a lot of good practices in its
support for modern filesystem features with fast performance.

General Characteristics of Ext2
The Second Extended Filesystem (Ext2) was introduced in 1994; besides
including several new features , it is quite efficient and robust and is, together with its
offspring Ext3, the most widely used Linux filesystem.
The following features contribute to the efficiency of Ext2:
When creating an Ext2 filesystem, the system administrator may choose the
optimal block size (from 1,024 to 4,096 bytes), depending on the expected
average file length.
When creating an Ext2 filesystem, the system administrator may choose how
many inodes to allow for a partition of a given size, depending on the expected
number of files to be stored on it. This maximizes the effectively usable disk
space.
The filesystem partitions disk blocks into groups. Each group includes data blocks
and inodes stored in adjacent tracks. Thanks to this structure, files stored in a
single block group can be accessed with a lower average disk seek time.
The filesystem preallocates disk data blocks to regular files before they are
actually used. Thus, when the file increases in size, several blocks are already
reserved at physically adjacent positions, reducing file fragmentation.
Moreover, the Second Extended Filesystem includes other features that make it both
robust and flexible
A careful implementation of file-updating that minimizes the impact of system
crashes.
Support for automatic consistency checks on the filesystem status at boot
time.
Support for immutable files (they cannot be modified, deleted, or renamed)
and for append-only files (data can be added only to the end of them).

Compatibility with both the Unix System V Release 4 and the BSD semantics
of the user group ID for a new file.
The most significant features being considered are:
Block fragmentation
Handling of transparently compressed and encrypted files
Logical deletion
Journaling
Ext2 Disk Data Structures
Fig 6.6: Layout of an Ext2 partition and of an Ext2 block group

Superblock
An Ext2 disk superblock is stored in an ext2_super_block structure, whose few
fields are listed
Type Field Description
_ _le32 s_inodes_count Total number of inodes
_ _le32 s_blocks_count Filesystem size in blocks
_ _le32 s_r_blocks_count Number of reserved blocks
_ _le32 s_free_blocks_count Free blocks counter
_ _le32 s_free_inodes_count Free inodes counter
_ _le32 s_first_data_block Number of first useful block (always 1)
_ _le32 s_log_block_size Block size
_ _le32 s_log_frag_size Fragment size
_ _le32 s_blocks_per_group Number of blocks per group
_ _le32 s_frags_per_group Number of fragments per group
_ _le32 s_inodes_per_group Number of inodes per group
... more fields…
Table 6.3 : The fields of the Ext2 superblock
The s_inodes_count field stores the number of inodes, while the
s_blocks_count field stores the number of blocks in the Ext2 filesystem.The
s_log_block_size field expresses the block size as a power of 2, using 1,024 bytes
as the unit. Thus, 0 denotes 1,024-byte blocks, 1 denotes 2,048-byte blocks, and so on.
The s_log_frag_size field is currently equal to s_log_block_size, because
block fragmentation is not yet implemented.

The s_blocks_per_group, s_frags_per_group, and
s_inodes_per_group fields store the number of blocks, fragments, and inodes in
each block group, respectively.
Group Descriptor and Bitmap
Each block group has its own group descriptor, an ext2_group_desc
structure whose fields are illustrated
Type Field Description
_ _le32 bg_block_bitmap Block number of block bitmap
_ _le32 bg_inode_bitmap Block number of inode bitmap
_ _le32 bg_inode_table Block number of first inode table block
_ _le16 bg_free_blocks_count Number of free blocks in the group
_ _le16 bg_free_inodes_count Number of free inodes in the group
_ _le16 bg_used_dirs_count Number of directories in the group
_ _le16 bg_pad Alignment to word
_ _le32 [3] bg_reserved Nulls to pad out 24 bytes
Table 6.4 : The fields of the Ext2 group descriptor
The bg_free_blocks_count, bg_free_inodes_count, and
bg_used_dirs_count fields are used when allocating new inodes and data blocks.
These fields determine the most suitable block in which to allocate each data structure.
The bitmaps are sequences of bits, where the value 0 specifies that the corresponding
inode or data block is free and the value 1 specifies that it is used. Because each bitmap
must be stored inside a single block and because the block size can be 1,024, 2,048, or
4,096 bytes, a single bitmap describes the state of 8,192, 16,384, or 32,768 blocks.

Inode Table
The inode table consists of a series of consecutive blocks, each of which contains
a predefined number of inodes. The block number of the first block of the inode table is
stored in the bg_inode_table field of the group descriptor.All inodes have the same
size: 128 bytes.
Each Ext2 inode is an ext2_inode structure whose fields are illustrated
Type Field Description
_ _le16 i_mode File type and access rights
_ _le16 i_uid Owner identifier
_ _le32 i_size File length in bytes
_ _le32 i_atime Time of last file access
_ _le32 i_ctime Time that inode last changed
_ _le32 i_mtime Time that file contents last changed
_ _le32 i_dtime Time of file deletion
_ _le16 i_gid User group identifier
_ _le16 i_links_count Hard links counter
_ _le32 i_blocks Number of data blocks of the file
_ _le32 i_flags File flags
Union osd1 Specific operating system information
__le32 [EXT2_N_BLOCKS] i_block Pointers to data blocks
... more fields…
Table 6.5 : The fields of the Ext2 inode

In particular, the i_size field stores the effective length of the file in bytes, while
the i_blocks field stores the number of data blocks (in units of 512 bytes) that have been
allocated to the file.
The i_block field is an array of EXT2_N_BLOCKS (usually 15) pointers to
blocks used to identify the data blocks allocated to the file.





























