Embed Size (px)
Citation preview

Research Division, India Research Lab
December 2005
Indian Institute of Technology, Bombay
and
Graphical models for part of speech tagging

IIT Bombay and IBM India Research Lab
December 2005
Different Models for POS tagging
HMM Maximum Entropy Markov Models Conditional Random Fields

IIT Bombay and IBM India Research Lab
December 2005
POS tagging: A Sequence Labeling Problem
Input and Output– Input sequence x xxxn
– Output sequence y yyym
Labels of the input sequenceSemantic representation of the input
Other Applications– Automatic speech recognition
– Text processing, e.g., tagging, name entity recognition, summarization by exploiting layout structure of text, etc.

IIT Bombay and IBM India Research Lab
December 2005
Hidden Markov Models Doubly stochastic models
Efficient dynamic programming algorithms exist for– Finding Pr(S)
– The highest probability path P that maximizes Pr(S,P) (Viterbi)
Training the model– (Baum-Welch algorithm)
S2
S4
S10.9
0.5
0.5
0.8
0.2
0.1
S3
A
C
0.6
0.4
A
C
0.3
0.7
A
C
0.5
0.5
A
C
0.9
0.1
IIT Bombay and IBM India Research Lab
December 2005
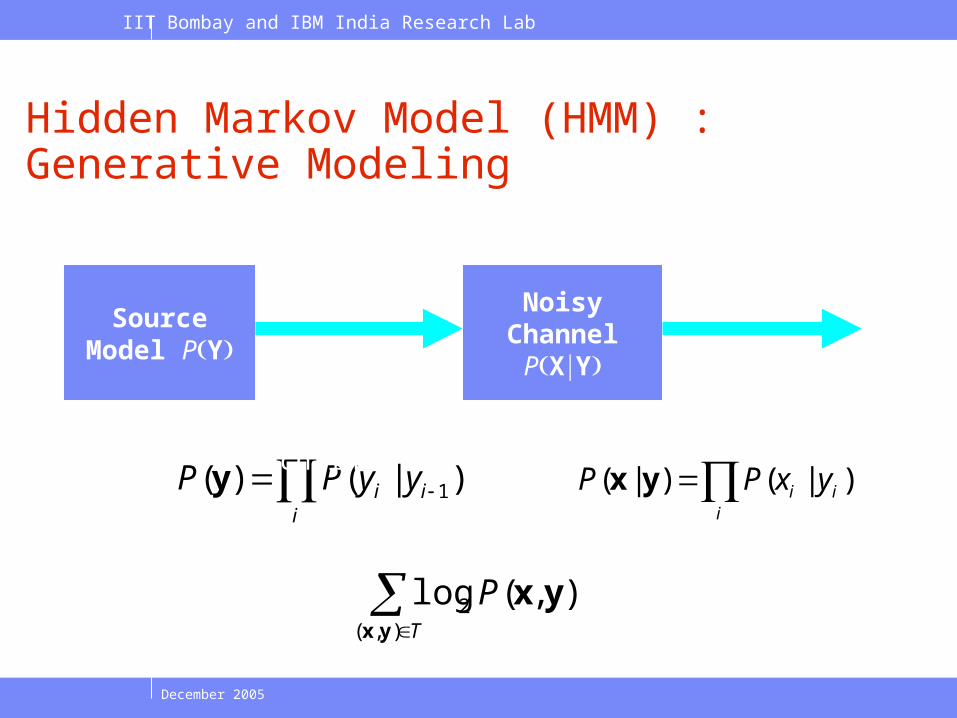
Hidden Markov Model (HMM) : Generative Modeling
Source Model PY
Noisy Channel PXY
y x
i
ii yyPP )|()( 1y i
ii yxPP )|()|( yx
e.g., 1st order Markov chain
Parameter estimation:
maximize the joint likelihood of training examples
T
P),(
2 ),(logyx
yx
IIT Bombay and IBM India Research Lab
December 2005
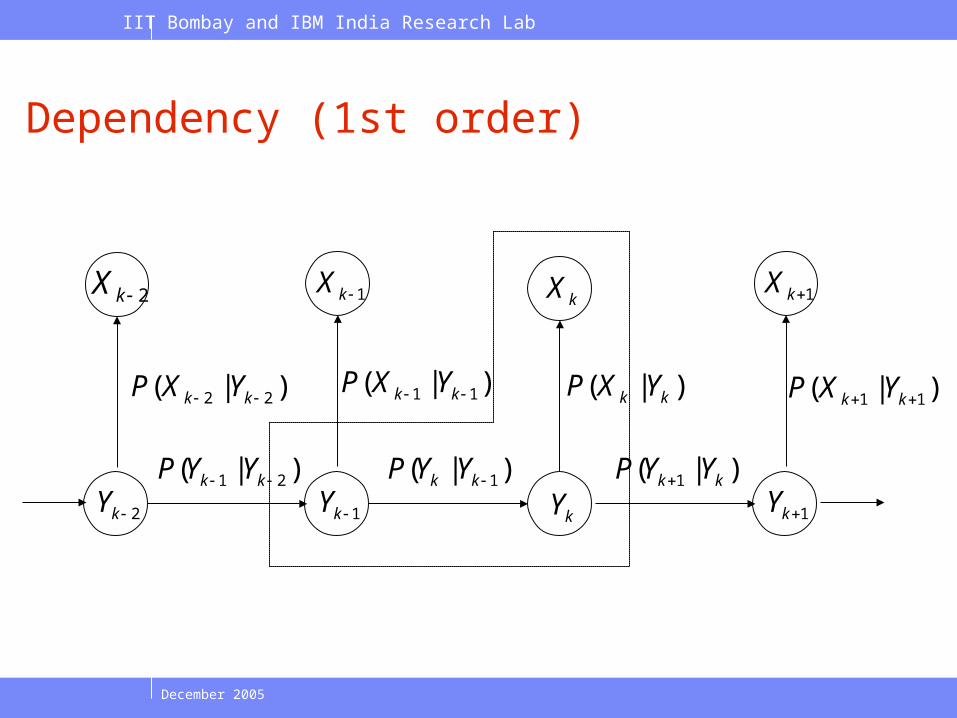
Dependency (1st order)
kY1kY
kX
)|( kk YXP
)|( 1kk YYP
1kX
)|( 11 kk YXP
2kX
)|( 22 kk YXP
2kY)|( 21 kk YYP
1kY
1kX
)|( 1 kk YYP
)|( 11 kk YXP

IIT Bombay and IBM India Research Lab
December 2005
Different Models for POS tagging
HMM Maximum Entropy Markov Models Conditional Random Fields

IIT Bombay and IBM India Research Lab
December 2005
Disadvantage of HMMs (1) No Rich Feature Information
– Rich information are required
When xk is complexWhen data of xk is sparse
Example: POS Tagging– How to evaluate Pwk|tk for unknown words wk ?
– Useful featuresSuffix, e.g., -ed, -tion, -ing, etc.Capitalization

IIT Bombay and IBM India Research Lab
December 2005
Disadvantage of HMMs (2)
Generative Model– Parameter estimation: maximize the joint
likelihood of training examples
T
P),(
2 ),(logyx
yYxX
Better Approach Discriminative model which models Py|x directly Maximize the conditional likelihood of training
examples
T
P),(
2 )|(logyx
xXyY

IIT Bombay and IBM India Research Lab
December 2005
Maximum Entropy Markov Model
Discriminative Sub Models– Unify two parameters in generative model
into one conditional model
Two parameters in generative model, parameter in source model
and parameter in noisy channelUnified conditional model
– Employ maximum entropy principle
)|( 1kk yyP
)|( kk yxP
),|( 1kkk yxyP
i
iii xyyPP ),|()|( 1xy
Maximum Entropy Markov Model

IIT Bombay and IBM India Research Lab
December 2005
General Maximum Entropy Model
Model– Model distribution PY|X with a set of features
fffl defined on X and Y
Idea– Collect information of features from training data
– Assume nothing on distribution PY|X other than the collected information
Maximize the entropy as a criterion

IIT Bombay and IBM India Research Lab
December 2005
Features
Features– 0-1 indicator functions
1 if x y satisfies a predefined condition
0 if not Example: POS Tagging
otherwise
NN is and tion- with ends if
,0
,1),(1
yxyxf
otherwise
NNP is and tionCaptializa with start if
,0
,1),(2
yxyxf

IIT Bombay and IBM India Research Lab
December 2005
Constraints
Empirical Information– Statistics from training data T
Tyx
ii yxfT
fP),(
),(||
1)(ˆ
Constraints)()(ˆ
ii fPfP
Tyx YDy
ii yxfxXyYPT
fP),( )(
),()|(||
1)(
Expected Value From the distribution PY|X we want to model

IIT Bombay and IBM India Research Lab
December 2005
Maximum Entropy: Objective
Entropy
x y
Tyx
xXyYPxXyYPxP
xXyYPxXyYPT
I
)|(log)|()(ˆ
)|(log)|(||
1
2
),(2
)()(ˆ s.t.
max)|(
fPfP
IXYP
Maximization Problem

IIT Bombay and IBM India Research Lab
December 2005
Dual Problem
Dual Problem – Conditional model
– Maximum likelihood of conditional data
)),(exp()|(1
l
iii yxfxXyYP
Solution Improved iterative scaling (IIS) (Berger et al. 1996) Generalized iterative scaling (GIS) (McCallum et al.
2000)
Tyx
xXyYPl ),(
2,,
)|(logmax1

IIT Bombay and IBM India Research Lab
December 2005
Maximum Entropy Markov Model
Use Maximum Entropy Approach to Model– 1st order
),|( 11 kkkkkk yYxXyYP
Features Basic features (like parameters in HMM)
Bigram (1st order) or trigram (2nd order) in source model
State-output pair feature Xkxk Yk yk Advantage: incorporate other advanced
features on xk yk
IIT Bombay and IBM India Research Lab
December 2005
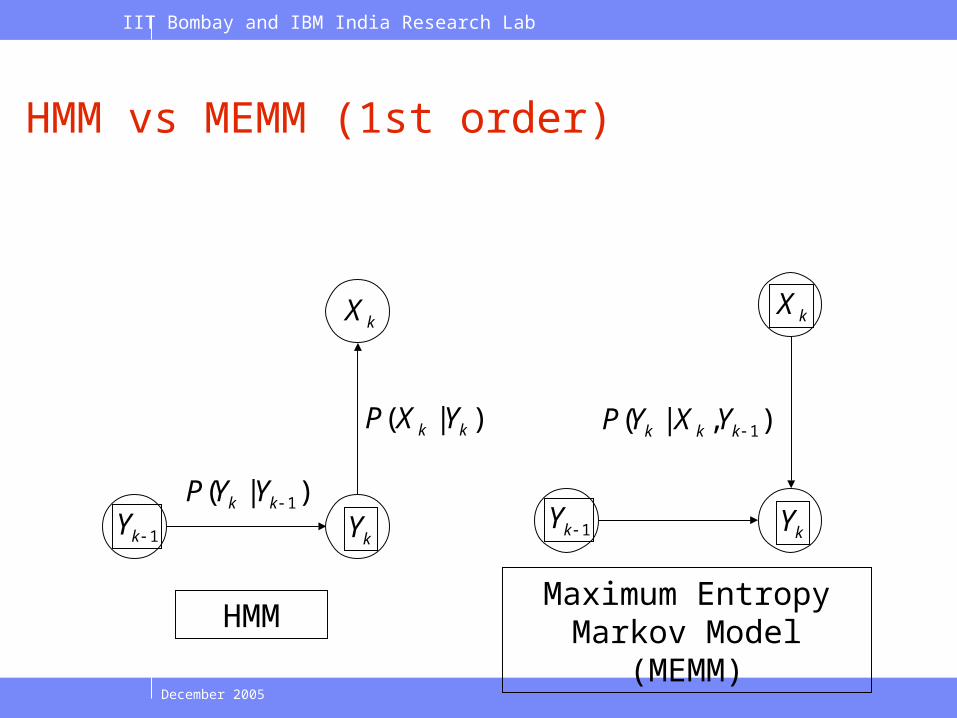
HMM vs MEMM (1st order)
kY1kY
kX
)|( 1kk YYP
)|( kk YXP
HMMMaximum Entropy
Markov Model (MEMM)
kY1kY
kX
),|( 1kkk YXYP

IIT Bombay and IBM India Research Lab
December 2005
Performance in POS Tagging
POS Tagging– Data set: WSJ
– Features:HMM features, spelling features (like –ed, -tion, -
s, -ing, etc.) Results (Lafferty et al. 2001)
– 1st order HMM94.31% accuracy, 54.01% OOV accuracy
– 1st order MEMM95.19% accuracy, 73.01% OOV accuracy
IIT Bombay and IBM India Research Lab
December 2005
Different Models for POS tagging
HMM Maximum Entropy Markov Models Conditional Random Fields

IIT Bombay and IBM India Research Lab
December 2005
Disadvantage of MEMMs (1)
Complex Algorithm of Maximum Entropy Solution– Both IIS and GIS are difficult to implement
– Require many tricks in implementation Slow in Training
– Time consuming when data set is large
Especially for MEMM

IIT Bombay and IBM India Research Lab
December 2005
Disadvantage of MEMMs (2)
Maximum Entropy Markov Model– Maximum entropy model as a sub model
– Optimization of entropy on sub models, not on global model
Label Bias Problem– Conditional models with per-state
normalization
– Effects of observations are weakened for states with fewer outgoing transitions

IIT Bombay and IBM India Research Lab
December 2005
Label Bias Problem
Training Data
X:Y
rib:123
rib:123
rib:123
rob:456
rob:456
1 2 3
r i b
4 5 6
r o b
Model
4.0114.0
)5,|6()4,|5()|4()|456(
6.0116.0
)2,|3()1,|2()|1()|123(
borrob
borrob
PPPP
PPPP
Parameters
1)5,|6()2,|3(
,1)4,|5()4,|5(
,1)1,|2()1,|2(
,6.0)|4(,4.0)|1(
bb
oi
oi
rr
PP
PP
PP
PP
New input: rob

IIT Bombay and IBM India Research Lab
December 2005
Solution
Global Optimization– Optimize parameters in a global model
simultaneously, not in sub models separately
Alternatives– Conditional random fields
– Application of perceptron algorithm

IIT Bombay and IBM India Research Lab
December 2005
Conditional Random Field (CRF) (1)
Let – be a graph such that Y is indexed
by the vertices
),( EVG
Then XY is a conditional random field if
Conditioned globally on X
VvvY )(Y
)),(,,|(),,|( EvwYYPvwYYP wvwv XX

IIT Bombay and IBM India Research Lab
December 2005
Conditional Random Field (CRF) (2)
Exponential Model– : a tree (or more specifically, a
chain) with cliques as edges and vertices),( EVG
Parameter Estimation Maximize the conditional likelihood of training
examples
IIS or GIS
kVv
vkkkEe
ekk vgefP,,
)|,()|,(exp()|( xyxyxXyY
T
P),(
2 )|(logyx
xXyY
State determined
Determined by State Transitions

IIT Bombay and IBM India Research Lab
December 2005
MEMM vs CRF
Similarities– Both employ maximum entropy principle
– Both incorporate rich feature information Differences
– Conditional random fields are always globally conditioned on X, resulting in a global optimized model

IIT Bombay and IBM India Research Lab
December 2005
Performance in POS Tagging
POS Tagging– Data set: WSJ
– Features:HMM features, spelling features (like –ed, -tion,
-s, -ing, etc.) Results (Lafferty et al. 2001)
– 1st order MEMM95.19% accuracy, 73.01% OOV accuracy
– Conditional random fields95.73% accuracy, 76.24% OOV accuracy

IIT Bombay and IBM India Research Lab
December 2005
Comparison of the three approaches to POS Tagging
Results (Lafferty et al. 2001)– 1st order HMM
94.31% accuracy, 54.01% OOV accuracy
– 1st order MEMM
95.19% accuracy, 73.01% OOV accuracy
– Conditional random fields
95.73% accuracy, 76.24% OOV accuracy

IIT Bombay and IBM India Research Lab
December 2005
References
A. Berger, S. Della Pietra, and V. Della Pietra (1996). A Maximum Entropy Approach to Natural Language Processing. Computational Linguistics, 22(1), 39-71.
J. Lafferty, A. McCallumn, and F. Pereira (2001). Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data. In Proc. ICML-2001, 282-289.





























