Modification of Genes and Proteins. By Paul Southard, Joshua Pikovsky , and Jake Secor. Transcript Processing Protein Folding RNAi Gene Repair. Transcript Processing. Introduction to Transcript Processing. Transcription factor recognizes TATA Box and binds to DNA - PowerPoint PPT Presentation
Modification of Genes and Proteins
Modification of Genes and ProteinsBy Paul Southard, Joshua
Pikovsky, and Jake SecorTranscript ProcessingProtein
FoldingRNAiGene Repair
Genes and proteins are modified by transcript processing,
protein folding, RNA interference, and gene repair.2Transcript
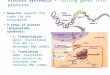
ProcessingIntroduction to Transcript ProcessingTranscription factor
recognizes TATA Box and binds to DNARNA polymerase bonds to DNARNA
polymerase separates strands and strings together complementary
nucleotides (using U instead of T)Primary transcript has been
created when terminator region is reached
In transcript processinga transcription factorrecognizes aTATA
Box(nucleotide sequence with sequential TATA) and binds to the DNA.
The TATA Box is generally a few dozen nucleotides upstream from the
starting point of the transcription region. The TATA box and
subsequent nucleotides until the start point is known as
thePromoter Region.Once transcription factors are bound,RNA
Polymerasecan bond to the DNA. The combination of the two is called
theTranscription Initiation Complex. The RNA Polymerase separates
the strands and strings together nucleotides that are complementary
to the DNA template strand. The only difference between these and
the non-template strand is that, in RNA, U nucleotides are used
instead of T nucleotides. The RNA Polymerase moves down the
template strand, unwinding the double helix and continuing to
string together nucleotides until it reaches the terminator region.
By the end of this process, the cell has created the primary
transcript.4Introduction to Transcript Processing
Transcription:Creates molecule to carry protein instructions
from DNACreates exact replica complementary to DNA
Transcription is a process intended to create a molecule that
can carry the exact message of DNA to the parts of the cell where
proteins are made. It occurs in the nucleus and its end product is
theprimary transcript. It creates an exact replica by using many
proteins to string together a single strand of nucleotides
complementing those of the DNA. Here is an animation describing how
mRNA is processed.5Transcript ProcessingAlteration of ends of
transcript:5 end capped with modified guanineKeeps RNA from
degrading in the cytoplasmCleavage factors and stabilizing factors
bind to 3 endPoly A polymerase binds and cleaves 3 end and adds
poly A tail made of adenine
When the transcript is altered, the 5' end gets capped with
amodified guanine nucleotide. This happens as soon as transcription
starts. This cap keeps the RNA from degrading in the cytoplasm and
helps the ribosome know where to start. Once transcription ends,
twoCleavage Factorsbind to the 3' end along with twostabilizing
factors, at which pointpoly A polymerasebinds and cleaves the end.
Poly A Polymerase then puts apoly (A) tailon the 3' end. This
consists of 50-250 adenine nucleotides. This serves the same
function as the 5' end. The poly (A) tail may also make it move
more easily.6Transcript ProcessingRNA splicing:Nucleotides
removedIntrons = non-coding regionsExons = coding regions to be
expressedSmall nuclear ribonucleoproteins (snRNPs) = proteins that
detect adenine at branching siteSpliceosomes remove the intron and
bind the two exons
A lot of nucleotides are removed from the transcript in the
process ofRNA splicing.The majority of the RNA is noncoding, and
must be removed. Noncoding regions are calledintrons, coding
regions that will be expressed are called exons. Ends of introns
are marked by nucleotide sequences. There is a GU at the5' splice
siteand an AG at the3' splice site.There is also aBranch sitein the
middle that consists of one adenine. These can be detected by
proteins calledsmall nuclear ribonucleoproteins(snRNPs). snRNP
contains asmall nuclear RNA(snRNA). The snRNPs are parts of
largerspliceosomesthat act on the splice sites. They cuts these
sites, remove the intron and bind the two exons together where the
splice sites were. In one specific example, a U1 snRNP binds to the
5' site, a U2 binds to the Branch site and the U3, U4 and U5 bind
to the rest of the intron, comprising one spliceosome. First, the
5' end is cut, which curls up and connects to the adenine of the
branch site. After that the 3' end is cut, and the snRNP's
dissociate.7
Protein FoldingIntroduction to Protein FoldingThe sequence of
amino acids defines a proteins primary structure.
A protein is made up of a collection of amino acids. A proteins
structure is defined by its amino acid sequence. Because the amino
acid sequence also determines a proteins function, structure is
crucial to function and vice versa.10Introduction to Protein
FoldingBlueprint for each amino acid is characterized by base
tripletsFound in the coding region of genesRibosomes recognize
triplets and create proteins
Base triplets are sets of three letters that characterize each
amino acid. They are found in the coding regions of genes. Triplets
are recognized by ribosomes which create proteins. In its primary
structure, a protein is in the form of a linear amino acid
sequence. After its primary structure, a protein takes on its
secondary structure, usually a pleated sheet and alpha helix. The
protein only becomes functional when it is folded into its
three-dimensional, tertiary structure. A proteins tertiary
structure cannot be determined just from its gene sequence.11
These diagrams demonstrate how an amino acid chain folds to form
its tertiary structure. It is not known how an amino acid chain
folds into its tertiary structure in fractions of a second.
Folding, along with intramolecular bonds created by the initial
amino acid sequence, determines the proteins tertiary 3D structure.
When a protein folds it tests multiple conformations and shapes
before reaching its unique and compact final form.12Protein
FoldingCovalent bonds between amino acids help stabilize the
proteinShape and stability also maintained by chemical forces
Proteins that are folded are kept stable by thousands of
noncovalent bonds between the amino acids. Chemical forces between
a protein and its environment also contribute to the shape and
stability. For example, proteins that are dissolved in the
cytoplasm have hydrophilic chemical groups on their surfaces, while
hydrophobic elements are tucked inside.13Protein FoldingChaperone
proteins:Prevent nearby proteins from inappropriately associating
and interfering with proper foldingSurround protein in protective
chamber during foldingEx) bacteria: GroEL and GroESUse ATPAlso
assist in refolding proteins
Due to the crowded nature of cytoplasm, cells rely on chaperone
proteins to prevent nearby proteins from inappropriately
associating and interfering with proper folding. Chaperone proteins
surround a protein during the folding process. For example, in
bacteria, many chaperone GroEL form a hollow chamber over proteins
while they are folding. Molecules of a second chaperone, GroES,
form a lid over the hollow chamber. Chaperones are common in cells
and use ATP to bind and release polypeptides as they fold.
Chaperones also help refolding proteins, for folded proteins are
surprisingly fragile and can easily denature, or unfold, due to
subtle increases in temperature or changes in environmental
conditions. Refolding proteins is important because it is much more
efficient to fix an unfolded protein than to synthesize an entire
new protein.14Protein Folding
Chaperone proteins protecting folding proteins
Some protein folding occurs during translation, but most occurs
in the endoplasmic reticulum. Protein molecules fold spontaneously
during or after synthesis, and while it is a mostly independent
process, it relies on the solvent (water or lipid bilayer), salt
concentration, temperature and availability of chaperone
proteins.15Protein FoldingModels of protein folding:Diffusion
Collision Model:Nucleus is formedSecondary structures collide and
pack togetherNuclear Condensation Model:Secondary and tertiary
structures are made simultaneously
There are two models of protein folding. The Diffusion Collision
Model states that a nucleus is formed, then secondary structures
collide and pack together. The Nuclear Condensation Model involves
secondary and tertiary structures that are made
simultaneously.16RNAiIntroduction to RNAiRNAi = RNA
InterferenceRNAi is used to:Silence specific genesFix gene
expression problems in mammals
Also known as:CosuppressionPost Transcriptional Gene
SilencingQuelling
RNA interference, or RNAi, is the process used by cells to turn
off certain genes. RNAi is the fastest known way to silence
specific genes, and also fixes gene expression problems in
mammals.18Introduction to RNAiTypes of small silencing RNA:Small
interfering RNA (siRNA)Endogeneous: derived from cellExogeneous:
delivered by humansMicro RNAs (miRNA)PIWI-interacting RNAs
(piRNA)RNAi breaks up mRNA before it is synthesized.
There are three types of small silencing RNA. Small interfering
RNA, or siRNA, is derived from double stranded RNAs either
endogeneously or exogeneously, as shown in the picture below, which
will reappear shortly. SiRNA regulates gene expression. Micro RNA,
or miRNA, comes from RNA transcribed in the nucleus. In order to
effectively stop proteins from being synthesized, RNAi molecules
must break up mRNA before it is synthesized.19Introduction to
RNAi
The pictures below show how the cell cleaves and degrades the
mRNA selected by the RNAi.20Introduction to RNAi
This video gives a simplified explanation of how RNAi
functions.21Implications of RNAiAllows singling out of genes to
determine function.
When an individual gene is turned off through RNA interference,
phenotypic observations can be made to determine what function that
specific gene has. For example, if a purple flower turns white when
gene one is turned off, then gene one relates to color. If petals
stop growing when gene two is turned off, then gene two controls
petal production.22Implications of RNAiCould halt progression
of:CancerHIVArthritisAll other diseases
Because RNAi stops production of proteins, harmful diseases like
Cancer, which currently have painful, life-consuming effects and
treatments, can be defeated.23Implications of RNAi
If RNA, modified to be identified as a disease and coded for the
production of cancerous proteins, is added to a cell that is
already producing those proteins, then the RNAi in the cell will
kill not only the added cancer RNA, but all other RNA signaling the
production of cancer proteins. Production of these proteins would
be completely stopped; effectively halting cancer in the
cell.24Jean RepairIntroduction to Jean Repair
Gene RepairIntroduction to Gene RepairDNA can be damaged
by:Radiation (gamma, x-ray, and ultraviolet)Oxygen radicals from
cellular respirationEnvironmental chemicals (hydrocarbons)Chemicals
used in chemotherapy
There are a variety of external and internal factors that can
damage DNA. Radiation is harmful, especially among gamma, x-ray and
ultraviolent wavelengths. Some oxygen byproducts from cellular
respiration are dangerous as they are highly reactive. Various
environmental chemicals, particularly hydrocarbons (found in
cigarette smoke) can be harmful as they cause serious mutations in
DNA. Chemicals used in chemotherapy are also capable of damaging
DNA.28Introduction to Gene RepairFour major types of DNA
damage:Deamination: amino acid group lostMismatched baseBackbone
breakCovalent cross-linkage between bases
Deamination in DNA
There are four major types of possible DNA damage. The first is
deamination, which is essentially when an amino group is lost. This
can be responsible for converting a C base to a U. The second is
the mismatch of a base as a result of a proofreading failure during
DNA replication. One of the more common examples of this is the
incorporation of U instead of T. Next is the backbone break, which
can be limited to one of the two strands of DNA or both strands.
The most common cause of this is ionizing radiation. The fourth and
last major type of DNA damage is the covalent cross-linkage between
bases. This can occur on the same DNA strand (intrastrand) or on
opposite strands (interstrand).29Gene RepairRepairing damaged
bases:Direct chemical reversalExcision repair mechanisms:Base
excision repair (BER)Nucleotide excision repair (NER)Mismatch
repair (MMR)
There are four primary mechanisms for repairing damage to DNA.
The first is direct chemical reversal, often through enzymes.
Direct chemical reversal deals with specific problems. More general
repairs are done by excision repair mechanisms. These repairs are
classified under base excision repair (BER), nucleotide excision
repair (NER), and mismatch repair (MMR).30Gene RepairChemical
ReversalEx) glycosylase enzymes remove mismatched T and restore
correct C
One of the most frequent causes of point mutations is a
spontaneous bonding of a methyl group to a cytocine base after it
is removed from a T. These are easy to repair, as glycosylase
enzymes remove the mismatched T and restore the correct C. While
this does solve the problem, it isn't efficient because each of the
various problems requires a specific mechanism to be fixed.31Gene
RepairExcision repair mechanisms:Base excision repair:DNA
glycosylases identify damaged basesDNA glycosylases remove damaged
basesDeoxyribose phosphate backbone component removed, creating
gapGap filled with correct nucleotideBreak in strand ligated
The first of the excision repair mechanisms is base excision
repair. Base excision repair has a few steps. First, DNA
glycosylases identify and remove damaged bases. Next, the
deoxyribose phosphate backbone component is removed, creating a
gap. Then, it is replaced with the correct nucleotide, relying on
DNA polymerase beta, one of more than 11 DNA polymerases encoded by
our genes. Finally, the break in the strand is ligated, or bound,
requiring two ATP reliant enzymes.32Gene RepairExcision repair
mechanisms:Nucleotide excision repair:Protein factors identify
damageDNA is unwoundFaulty area is cut out and the bases are
removedDNA is synthesized to match that of the opposite, correct
strandDNA ligase adds synthesized DNA
The next method of excision repair is nucleotide excision
repair. Nucleotide excision repair uses different enzymes, and
instead of removing just one incorrect base, it takes a whole patch
of adjacent bases. First the damage is identified by protein
factors. The DNA is unwound, creating a bubble like shape using an
enzyme system (Transcription factors IIH, TFIIH). Cuts are then
made on both sides of the faulty area, and the bases are removed.
DNA synthesis using the opposite, correct strand fills in
nucleotides. Finally, DNA ligase covalently adds the correct part
into the DNA backbone. This can also be coupled with transcription,
for it occurs most quickly in cells whose genes are being actively
transcribed, or on a DNA strand that is a template for
transcription.33Gene RepairExcision repair mechanisms:Mismatch
repairCorrects mismatches of normal bases (A&T, C&G)
by:Identifying mismatched basesCutting mismatched bases
The third mechanism for excision repair is mismatch repair.
Mismatch repair corrects mismatches of normal bases (A&T,
C&G). This involves two major steps: theidentificationof a
mismatch and the cutting of the mismatch.34
This diagram shows what types of gene damage are repaired by
each gene repair method.35Any Questions?