Embed Size (px)
Citation preview

1
Latency considerations of depth-first GPU ray tracing
Michael Guthe
University BayreuthVisual Computing
2
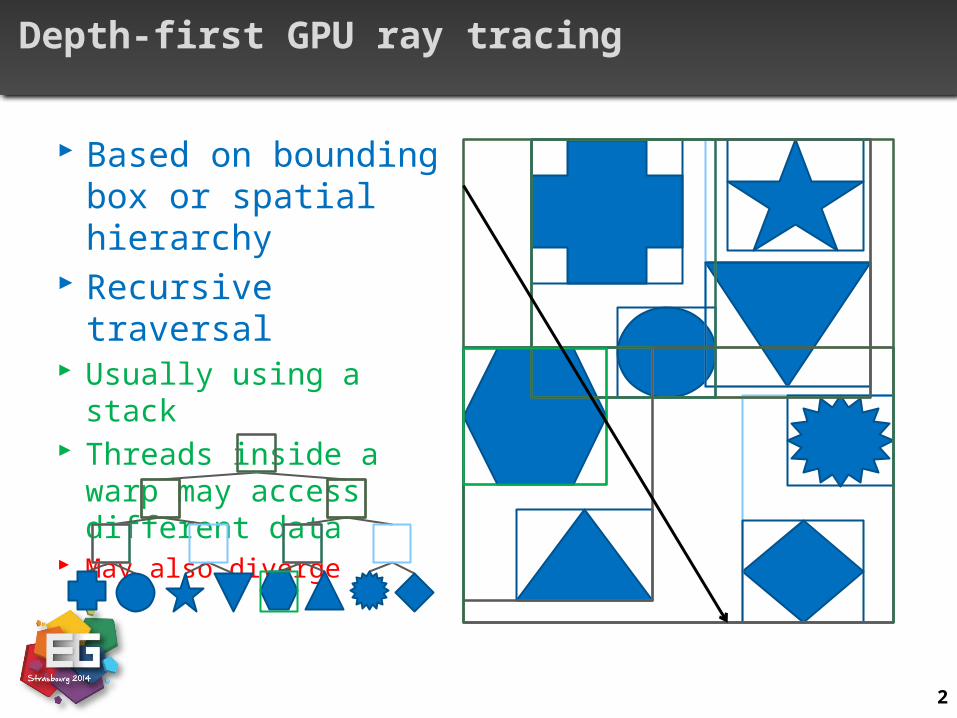
Depth-first GPU ray tracing
Based on bounding box or spatial hierarchy
Recursive traversal Usually using a stack Threads inside a warp may
access different data May also diverge
3
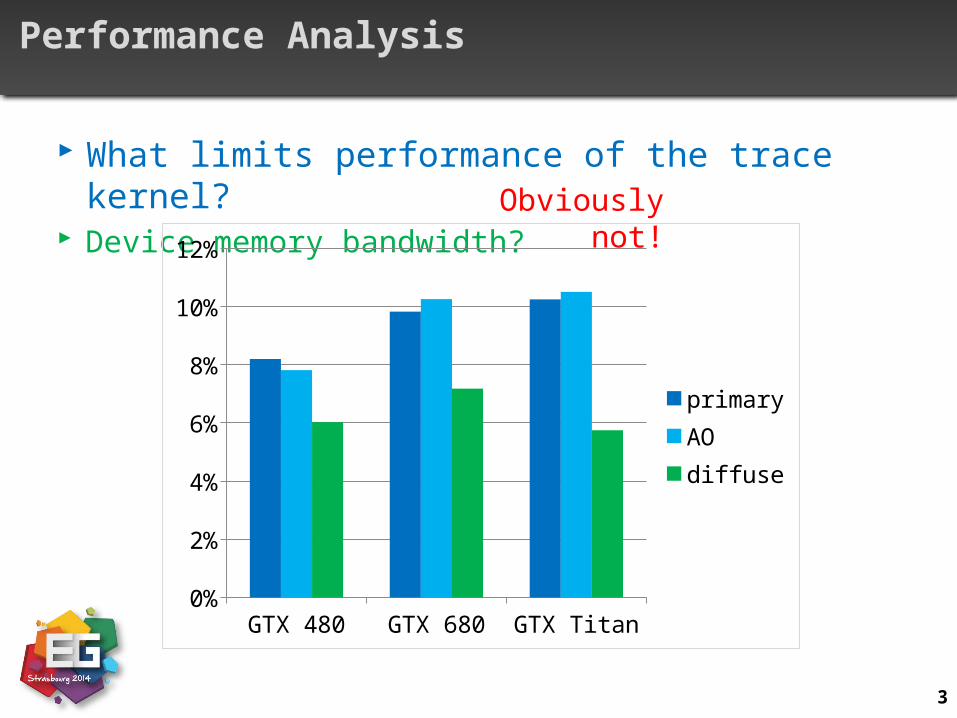
Performance Analysis
What limits performance of the trace kernel? Device memory bandwidth?
GTX 480 GTX 680 GTX Titan0%
2%
4%
6%
8%
10%
12%
primaryAOdiffuse
Obviously not!
4
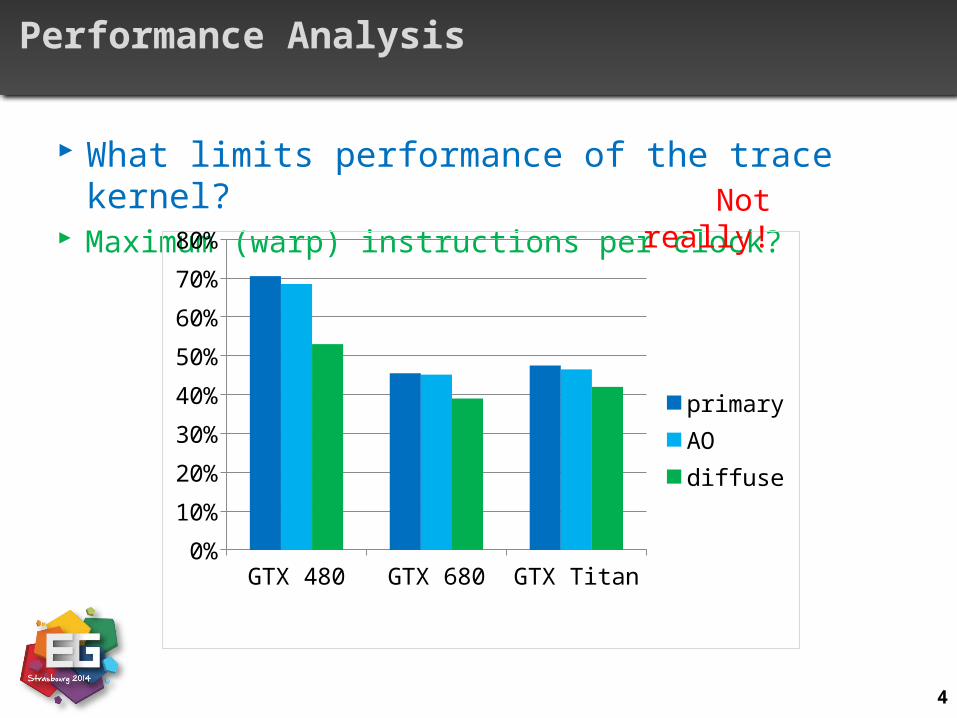
Performance Analysis
What limits performance of the trace kernel? Maximum (warp) instructions per clock?
GTX 480 GTX 680 GTX Titan0%
10%
20%
30%
40%
50%
60%
70%
80%
primaryAOdiffuse
Not really!

5
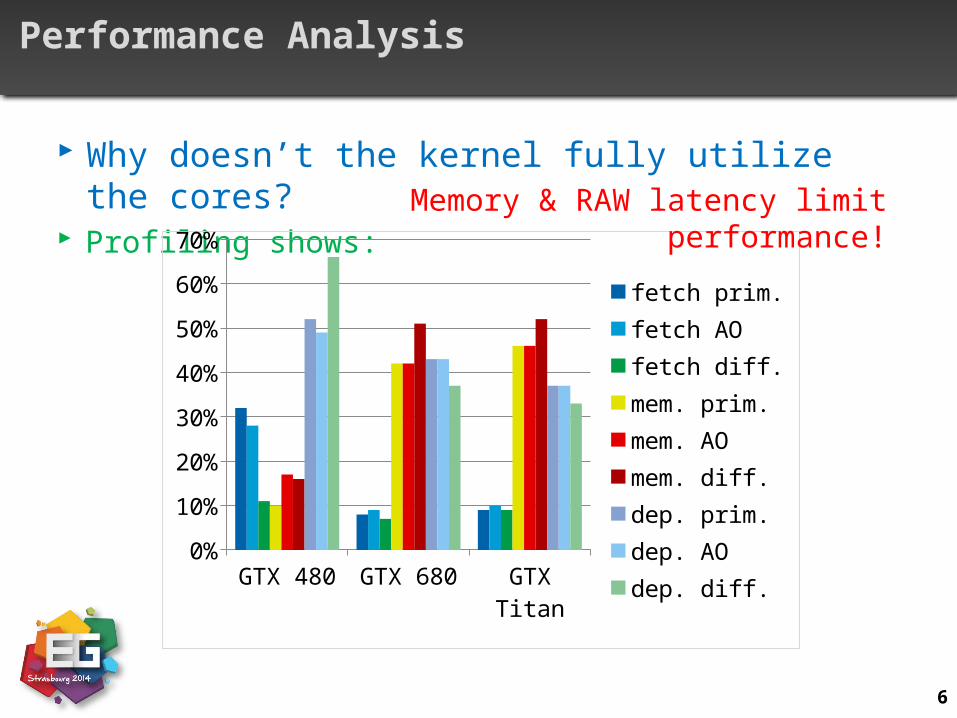
Performance Analysis
Why doesn’t the kernel fully utilize the cores?
Three possible reasons: Instruction fetch e.g. due to branches Memory latency a.k.a. data request mainly due to random access Read after write latency a.k.a. execution dependency It takes 22 clock cycles (Kepler) until the result is written to a register
6
Performance Analysis
Why doesn’t the kernel fully utilize the cores? Profiling shows:
GTX 480 GTX 680 GTX Titan0%
10%
20%
30%
40%
50%
60%
70%
fetch prim.fetch AOfetch diff.mem. prim.mem. AOmem. diff.dep. prim.dep. AOdep. diff.
Memory & RAW latency limit performance!

7
Reducing Latency
Standard solution for latency: Increase occupancy No option due to register pressure
Relocate memory access Automatically performed by compiler But not between iterations of a while loop Loop unrolling for triangle test

8
Reducing Latency
Instruction level parallelism Not directly supported by GPU Increases number of eligible warps Same effect as higher occupancy We might even spend some more registers
Wider trees 4-ary tree means 4 independent instructions paths Almost doubles the number of eligible warps during node tests Higher width increase number of node tests, 4 is optimum
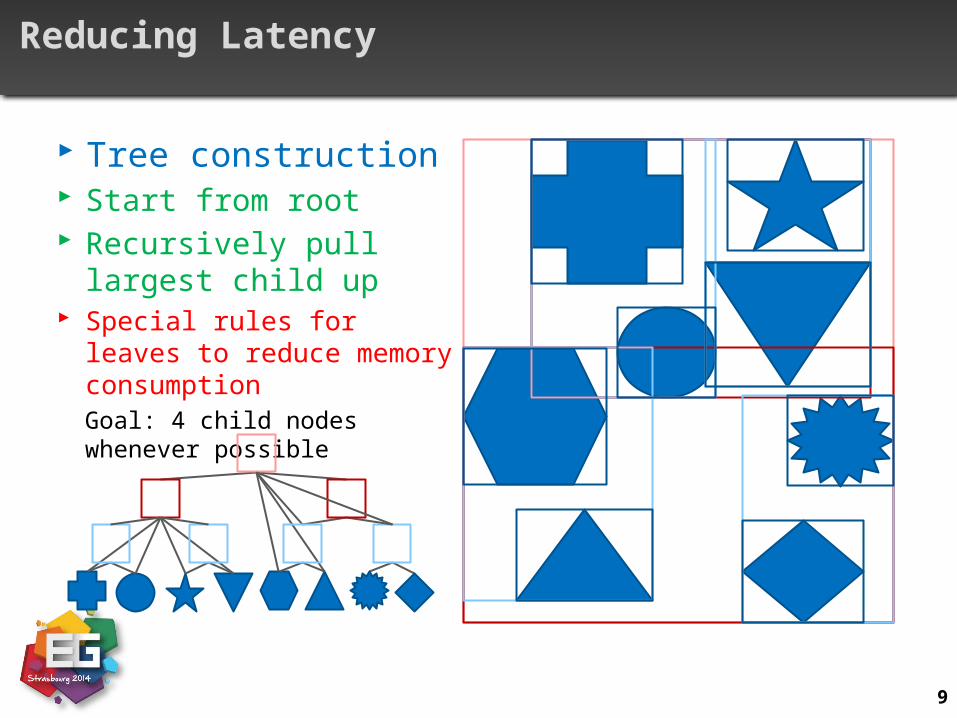
9
Reducing Latency
Tree construction Start from root Recursively pull largest
child up Special rules for leaves to
reduce memory consumptionGoal: 4 child nodes whenever possible
10
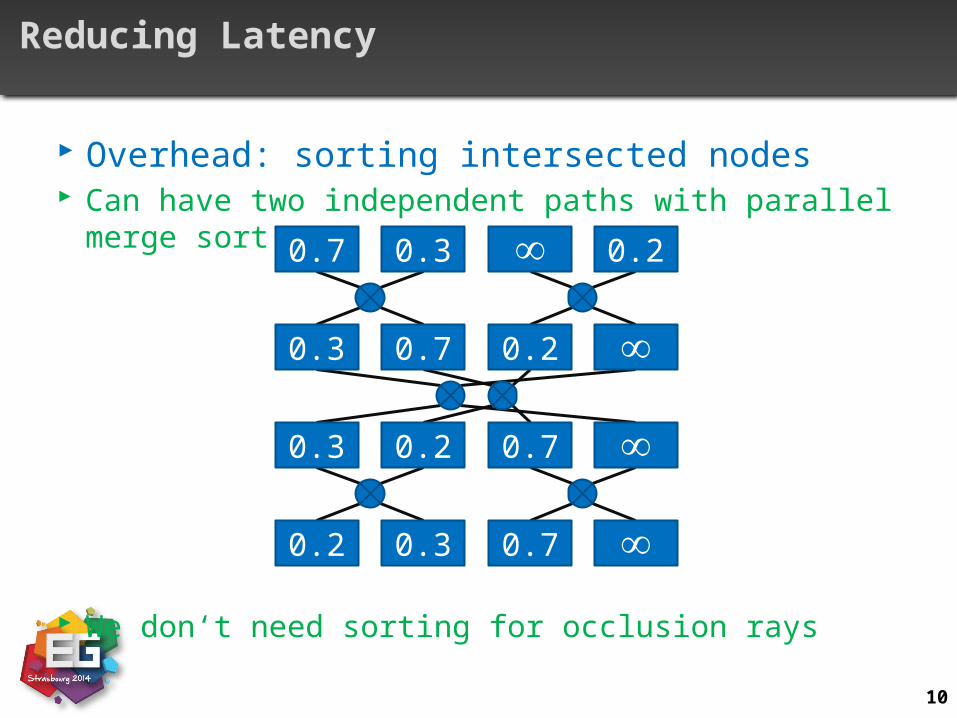
Reducing Latency
Overhead: sorting intersected nodes Can have two independent paths with parallel merge sort
We don‘t need sorting for occlusion rays
0.2 0.3 0.7
0.3 0.2 0.7
0.3 0.7 0.2
0.7 0.3 0.2

11
Results
Improved instructions per clock Doesn’t directly translate to speedup
GTX 480 GTX 680 GTX Titan0%
10%
20%
30%
40%
50%
60%
70%
80%
primaryAOdiffuse
GTX 480 GTX 680 GTX Titan0%
10%
20%
30%
40%
50%
60%
70%
80%
primaryAOdiffuse
12
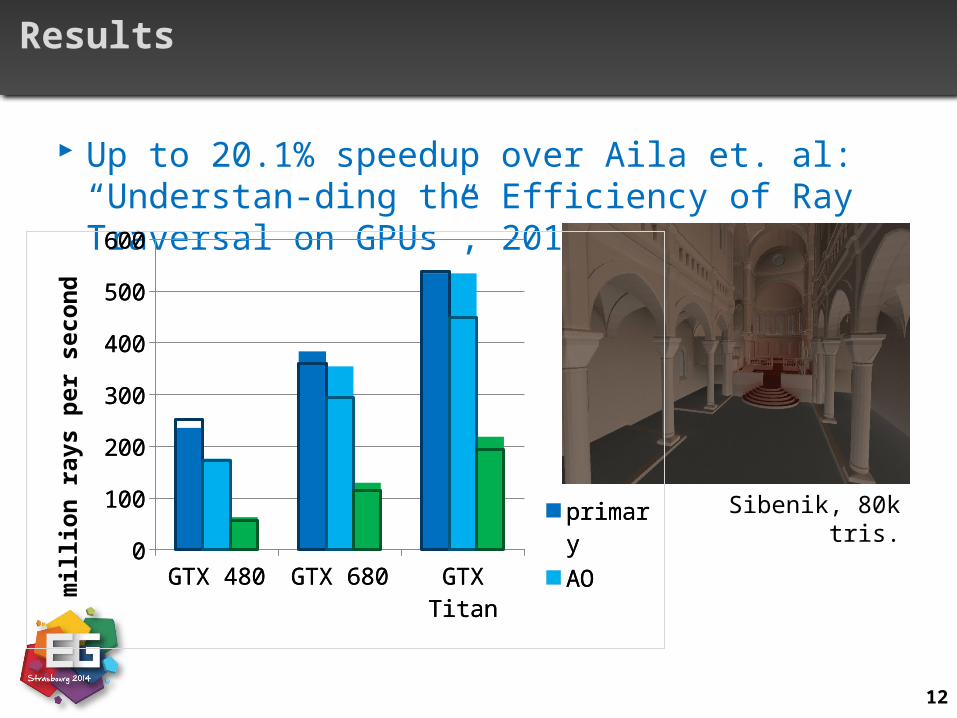
Results
Up to 20.1% speedup over Aila et. al: “Understan-ding the Efficiency of Ray Traversal on GPUs”, 2012
GTX 480 GTX 680 GTX Titan0
100
200
300
400
500
600
pri-mary
AO
GTX 480 GTX 680 GTX Titan0
100
200
300
400
500
600
pri-mary
AOmillion
rays p
er
secon
d
Sibenik, 80k tris.
13
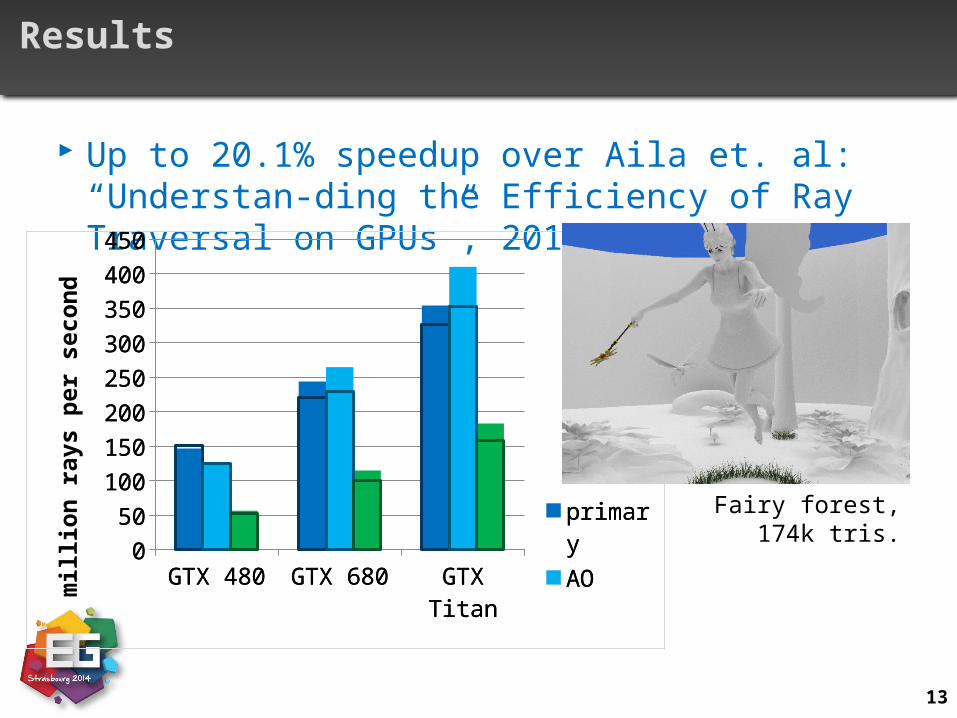
Results
Up to 20.1% speedup over Aila et. al: “Understan-ding the Efficiency of Ray Traversal on GPUs”, 2012
GTX 480 GTX 680 GTX Titan0
50
100
150
200
250
300
350
400
450
pri-mary
AO
GTX 480 GTX 680 GTX Titan0
50
100
150
200
250
300
350
400
450
pri-mary
AOmillion
rays p
er
secon
d
Fairy forest, 174k tris.
14
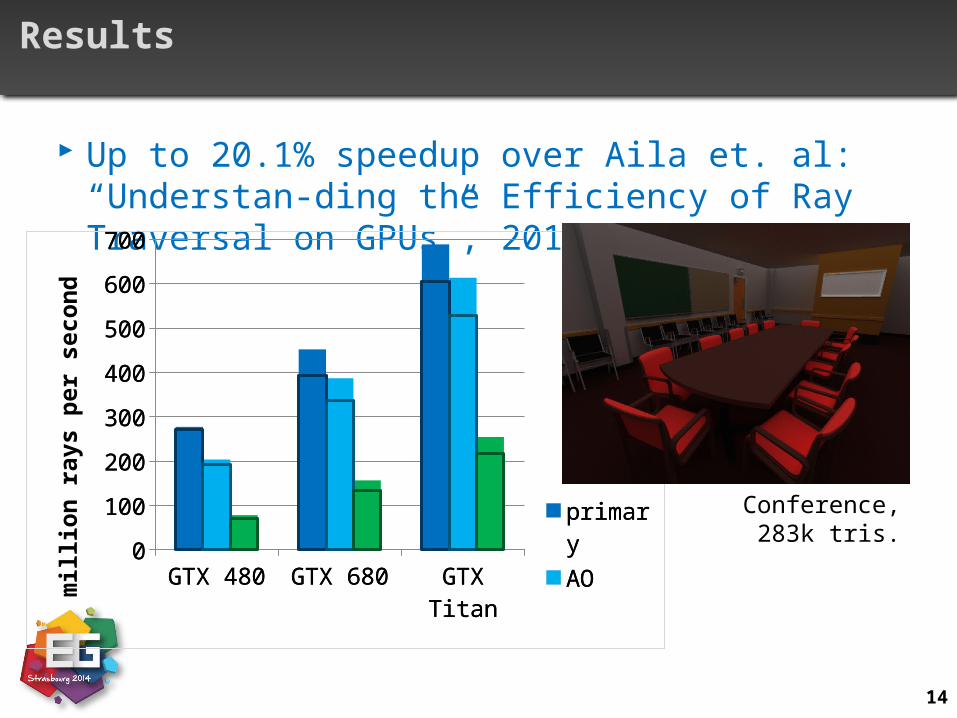
Results
Up to 20.1% speedup over Aila et. al: “Understan-ding the Efficiency of Ray Traversal on GPUs”, 2012
GTX 480 GTX 680 GTX Titan0
100
200
300
400
500
600
700
pri-mary
AO
GTX 480 GTX 680 GTX Titan0
100
200
300
400
500
600
700
pri-mary
AOmillion
rays p
er
secon
d
Conference, 283k tris.
15
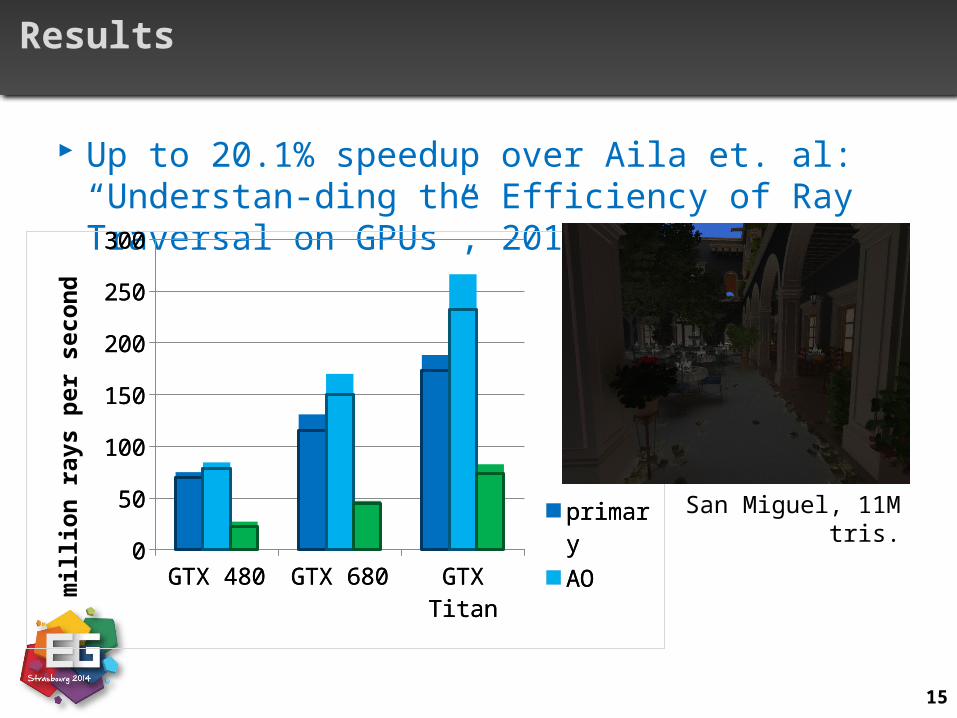
Results
Up to 20.1% speedup over Aila et. al: “Understan-ding the Efficiency of Ray Traversal on GPUs”, 2012
GTX 480 GTX 680 GTX Titan0
50
100
150
200
250
300
pri-mary
AO
GTX 480 GTX 680 GTX Titan0
50
100
150
200
250
300
pri-mary
AOmillion
rays p
er
secon
d
San Miguel, 11M tris.
16
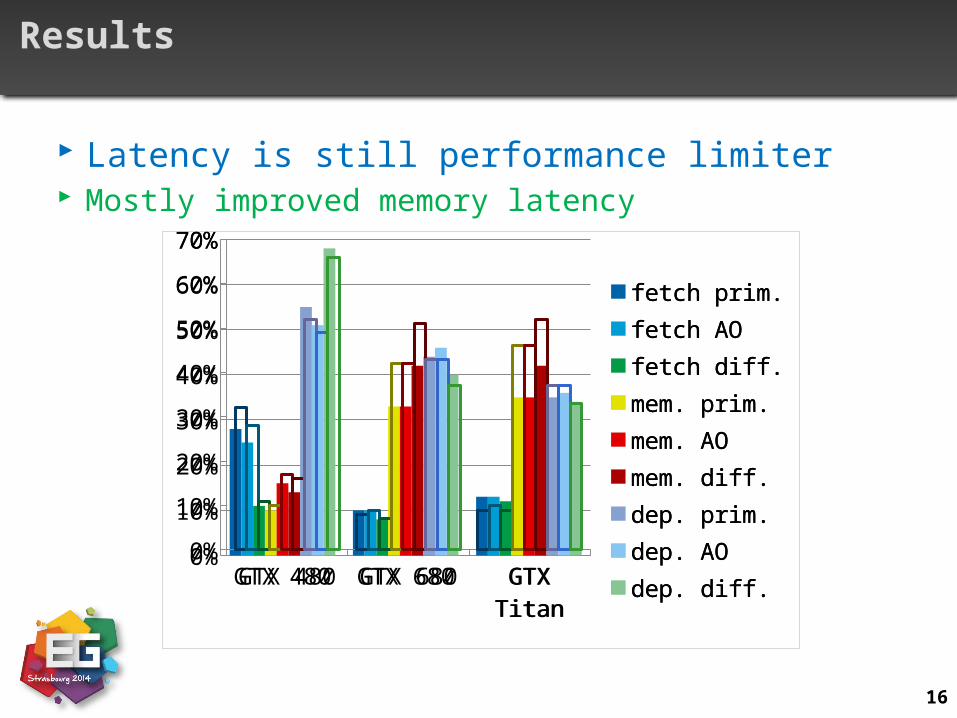
Results
Latency is still performance limiter Mostly improved memory latency
GTX 480 GTX 680 GTX Titan0%
10%
20%
30%
40%
50%
60%
70%
fetch prim.fetch AOfetch diff.mem. prim.mem. AOmem. diff.dep. prim.dep. AOdep. diff.
GTX 480 GTX 680 GTX Titan0%
10%
20%
30%
40%
50%
60%
70%
fetch prim.fetch AOfetch diff.mem. prim.mem. AOmem. diff.dep. prim.dep. AOdep. diff.





























