Embed Size (px)
Citation preview

FSE 2013
Near Collision Attack on the Grain v1 Stream Cipher
Bin Zhang∗ and Zhenqi Li†
∗Institute of Information Engineering,Chinese Academy of Sciences, Beijing, 100093, China.
†Institute of Software,Chinese Academy of Sciences, Beijing, 100190, China.
zhangbin, [email protected]
March 13, 2013
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 1 / 29

Outline
Introduction
Description of Grain v1
Main idea& some key observations
The general attack model: NCA-1.0
NCA-2.0& NCA-3.0
Simulations
Conclusions
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 2 / 29

Introduction
Grain v1, designed by Martin Hell, Thomas Johansson and Willi Meier, is astream cipher for restricted hardware environments. It wasselected into the finalportfolio by the eSTREAM project.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 3 / 29

Introduction
Grain v1, designed by Martin Hell, Thomas Johansson and Willi Meier, is astream cipher for restricted hardware environments. It wasselected into the finalportfolio by the eSTREAM project.
Grain v1 is immune to thecorrelationanddistinguishingattacks thatsuccessfully broke the former version Grain v0.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 3 / 29

Introduction
Grain v1, designed by Martin Hell, Thomas Johansson and Willi Meier, is astream cipher for restricted hardware environments. It wasselected into the finalportfolio by the eSTREAM project.
Grain v1 is immune to thecorrelationanddistinguishingattacks thatsuccessfully broke the former version Grain v0.
De Canniere. C.et al.discovered aslide propertyin the initialization phase ofGrain v1, reduce half of the cost of exhaustive key search fora fixed IV.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 3 / 29

Introduction
Grain v1, designed by Martin Hell, Thomas Johansson and Willi Meier, is astream cipher for restricted hardware environments. It wasselected into the finalportfolio by the eSTREAM project.
Grain v1 is immune to thecorrelationanddistinguishingattacks thatsuccessfully broke the former version Grain v0.
De Canniere. C.et al.discovered aslide propertyin the initialization phase ofGrain v1, reduce half of the cost of exhaustive key search fora fixed IV.
A related-key chosen IVattack has also been proposed by Lee, Yet al.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 3 / 29

Introduction
Grain v1, designed by Martin Hell, Thomas Johansson and Willi Meier, is astream cipher for restricted hardware environments. It wasselected into the finalportfolio by the eSTREAM project.
Grain v1 is immune to thecorrelationanddistinguishingattacks thatsuccessfully broke the former version Grain v0.
De Canniere. C.et al.discovered aslide propertyin the initialization phase ofGrain v1, reduce half of the cost of exhaustive key search fora fixed IV.
A related-key chosen IVattack has also been proposed by Lee, Yet al.
The companion cipher, Grain-128 is designed in a similar waywith low algrbraicdegree feedback function, resulting in adynamic cube attackon the fullinitialization rounds by Dinuret al.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 3 / 29

Introduction
Grain v1, designed by Martin Hell, Thomas Johansson and Willi Meier, is astream cipher for restricted hardware environments. It wasselected into the finalportfolio by the eSTREAM project.
Grain v1 is immune to thecorrelationanddistinguishingattacks thatsuccessfully broke the former version Grain v0.
De Canniere. C.et al.discovered aslide propertyin the initialization phase ofGrain v1, reduce half of the cost of exhaustive key search fora fixed IV.
A related-key chosen IVattack has also been proposed by Lee, Yet al.
The companion cipher, Grain-128 is designed in a similar waywith low algrbraicdegree feedback function, resulting in adynamic cube attackon the fullinitialization rounds by Dinuret al.
A new variant, Grain-128a withoptional authenticationwas proposed byAgrenet al.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 3 / 29

Outline
Introduction
Description of Grain v1
Main idea& some key observations
The general attack model: NCA-1.0
NCA-2.0& NCA-3.0
Simulations
Conclusions
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 4 / 29
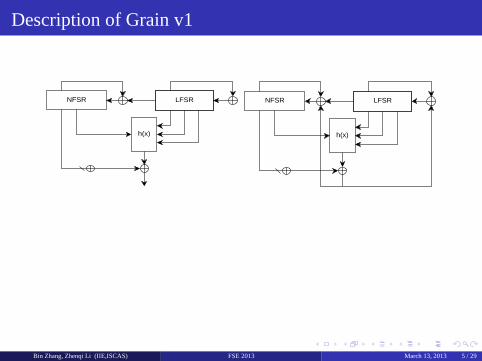
Description of Grain v1
h(x)
NFSR LFSR
h(x)
NFSR LFSR
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 5 / 29
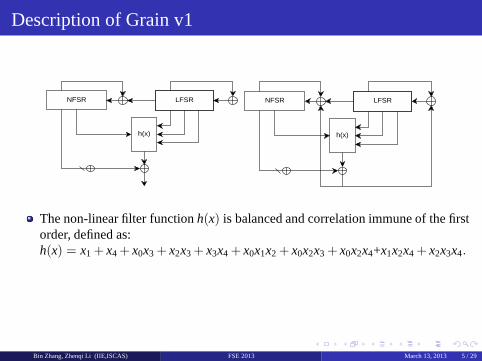
Description of Grain v1
h(x)
NFSR LFSR
h(x)
NFSR LFSR
The non-linear filter functionh(x) is balanced and correlation immune of the firstorder, defined as:h(x) = x1 + x4+ x0x3 + x2x3+ x3x4 + x0x1x2 + x0x2x3 + x0x2x4+x1x2x4 + x2x3x4.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 5 / 29
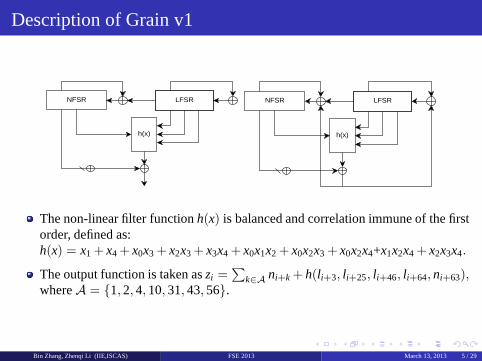
Description of Grain v1
h(x)
NFSR LFSR
h(x)
NFSR LFSR
The non-linear filter functionh(x) is balanced and correlation immune of the firstorder, defined as:h(x) = x1 + x4+ x0x3 + x2x3+ x3x4 + x0x1x2 + x0x2x3 + x0x2x4+x1x2x4 + x2x3x4.
The output function is taken aszi =∑
k∈A ni+k + h(l i+3, l i+25, l i+46, l i+64, ni+63),whereA = 1, 2, 4, 10, 31, 43, 56.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 5 / 29

Outline
Introduction
Description of Grain v1
Main idea& some key observations
The general attack model: NCA-1.0
NCA-2.0& NCA-3.0
Simulations
Conclusions
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 6 / 29

Main idea
In this paper, a new key recovery attack, called near collision attack is proposed,utilizing the compact NFSR-LFSR combined structure of Grain v1.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 7 / 29

Main idea
In this paper, a new key recovery attack, called near collision attack is proposed,utilizing the compact NFSR-LFSR combined structure of Grain v1.
It is observed that the NFSR and LFSR are of length exactly 80-bit (with noredundance) and theLFSR updates independentlyin the keystream generationphase.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 7 / 29

Main idea
In this paper, a new key recovery attack, called near collision attack is proposed,utilizing the compact NFSR-LFSR combined structure of Grain v1.
It is observed that the NFSR and LFSR are of length exactly 80-bit (with noredundance) and theLFSR updates independentlyin the keystream generationphase.
It is observed that the LFSR state bits can be easily recovered, given the internalstate difference at two different time instants.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 7 / 29

Main idea
In this paper, a new key recovery attack, called near collision attack is proposed,utilizing the compact NFSR-LFSR combined structure of Grain v1.
It is observed that the NFSR and LFSR are of length exactly 80-bit (with noredundance) and theLFSR updates independentlyin the keystream generationphase.
It is observed that the LFSR state bits can be easily recovered, given the internalstate difference at two different time instants.
It is observed that the distribution of the keystream segment differences isnon-uniform, given a low Hamming weight internal state difference.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 7 / 29

Main idea
In this paper, a new key recovery attack, called near collision attack is proposed,utilizing the compact NFSR-LFSR combined structure of Grain v1.
It is observed that the NFSR and LFSR are of length exactly 80-bit (with noredundance) and theLFSR updates independentlyin the keystream generationphase.
It is observed that the LFSR state bits can be easily recovered, given the internalstate difference at two different time instants.
It is observed that the distribution of the keystream segment differences isnon-uniform, given a low Hamming weight internal state difference.
Three attacks has been proposed: NCA-1.0, NCA-2.0 combinedwith BSWsampling, NCA-3.0 utilizing the non-uniform distributionof the internal statedifferences for a fixed keystream difference.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 7 / 29

Preliminaries
DefinitionTwo n-bit strings s, s′ are d-near-collision, if wH(s⊕ s′) ≤ d.
Similar to the birthday paradox, which states that two random subsets of a space with2n elements are expected to intersect when the product of theirsizes exceeds 2n, wepresent the followinglemma ofd-near-collision.
LemmaGiven two random subsets A, B of a space with2n elements, then there exists a pair(a, b) with a∈ A and b∈ B that is an d-near-collision if
|A| · |B| ≥2n
V(n, d)(1)
holds, where|A| and|B| are the size of A and B respectively.
V(n, d) =∑d
i=0
(ni
)
.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 8 / 29

Observation I-State recovery with known state difference
Denote the LFSR state asLt1 = (lt10 , lt11 , ..., l
t179) at timet1 andLt2 = (lt20 , l
t21 , ..., l
t279)
at timet2 (0 ≤ t1 < t2). Then, we can derive
lt20 = c00lt10 + c0
1lt11 + ...+ c079l
t179
lt21 = c10lt10 + c1
1lt11 + ...+ c179l
t179
...lt279 = c79
0 lt10 + c791 lt11 + ...+ c79
79lt179,
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 9 / 29

Observation I-State recovery with known state difference
Denote the LFSR state asLt1 = (lt10 , lt11 , ..., l
t179) at timet1 andLt2 = (lt20 , l
t21 , ..., l
t279)
at timet2 (0 ≤ t1 < t2). Then, we can derive
lt20 = c00lt10 + c0
1lt11 + ...+ c079l
t179
lt21 = c10lt10 + c1
1lt11 + ...+ c179l
t179
...lt279 = c79
0 lt10 + c791 lt11 + ...+ c79
79lt179,
Suppose that we know the difference∆L = (lt10 ⊕ lt20 , ..., lt179 ⊕ lt279) = (∆l0,∆l1,
...,∆l79) with the time interval∆t = t2 − t1. Then,
∆l0 = lt20 ⊕ lt10 = (c00 + 1)lt10 + xc0
1lt11 + ...+ c079l
t179
∆l1 = lt21 ⊕ lt11 = c10lt10 + (c1
1 + 1)lt11 + ...+ c179l
t179
...∆l79 = lt279 ⊕ lt179 = c79
0 lt10 + c791 lt11 + ...+ (c79
79 + 1)lt179.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 9 / 29

Observation I-State recovery with known state difference
Denote the LFSR state asLt1 = (lt10 , lt11 , ..., l
t179) at timet1 andLt2 = (lt20 , l
t21 , ..., l
t279)
at timet2 (0 ≤ t1 < t2). Then, we can derive
lt20 = c00lt10 + c0
1lt11 + ...+ c079l
t179
lt21 = c10lt10 + c1
1lt11 + ...+ c179l
t179
...lt279 = c79
0 lt10 + c791 lt11 + ...+ c79
79lt179,
Suppose that we know the difference∆L = (lt10 ⊕ lt20 , ..., lt179 ⊕ lt279) = (∆l0,∆l1,
...,∆l79) with the time interval∆t = t2 − t1. Then,
∆l0 = lt20 ⊕ lt10 = (c00 + 1)lt10 + xc0
1lt11 + ...+ c079l
t179
∆l1 = lt21 ⊕ lt11 = c10lt10 + (c1
1 + 1)lt11 + ...+ c179l
t179
...∆l79 = lt279 ⊕ lt179 = c79
0 lt10 + c791 lt11 + ...+ (c79
79 + 1)lt179.
The next step is to recover the NFSR state att1 andt2, the time complexity isbounded by 220.3 cipher ticks.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 9 / 29

Observation II-the Distribution of the KSD
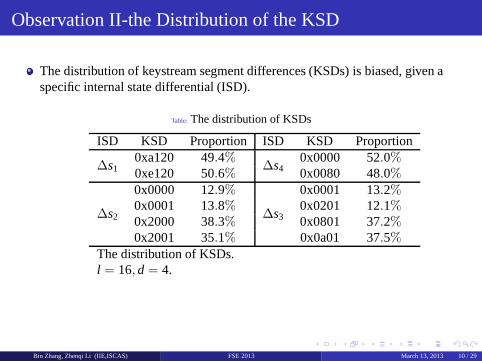
The distribution of keystream segment differences (KSDs) is biased, given aspecific internal state differential (ISD).
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 10 / 29
Observation II-the Distribution of the KSD
The distribution of keystream segment differences (KSDs) is biased, given aspecific internal state differential (ISD).
Table: The distribution of KSDs
ISD KSD Proportion ISD KSD Proportion
∆s10xa120 49.4%
∆s40x0000 52.0%
0xe120 50.6% 0x0080 48.0%
∆s2
0x0000 12.9%
∆s3
0x0001 13.2%0x0001 13.8% 0x0201 12.1%0x2000 38.3% 0x0801 37.2%0x2001 35.1% 0x0a01 37.5%
The distribution of KSDs.l = 16, d = 4.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 10 / 29
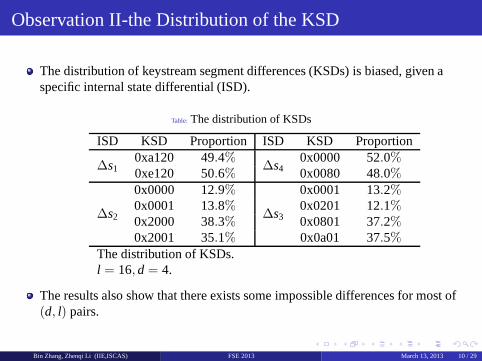
Observation II-the Distribution of the KSD
The distribution of keystream segment differences (KSDs) is biased, given aspecific internal state differential (ISD).
Table: The distribution of KSDs
ISD KSD Proportion ISD KSD Proportion
∆s10xa120 49.4%
∆s40x0000 52.0%
0xe120 50.6% 0x0080 48.0%
∆s2
0x0000 12.9%
∆s3
0x0001 13.2%0x0001 13.8% 0x0201 12.1%0x2000 38.3% 0x0801 37.2%0x2001 35.1% 0x0a01 37.5%
The distribution of KSDs.l = 16, d = 4.
The results also show that there exists some impossible differences for most of(d, l) pairs.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 10 / 29

Observation III-Complexity of the brute force attack
The complexity of the brute force attack ishigher than 280 ticksand such anattack can only be mounted for each fixed IV.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 11 / 29

Observation III-Complexity of the brute force attack
The complexity of the brute force attack ishigher than 280 ticksand such anattack can only be mounted for each fixed IV.
For each enumeratedki , 1 ≤ i ≤ 280 − 1, the attacker first needs to proceed theinitialization phase which needs 160 ticks.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 11 / 29

Observation III-Complexity of the brute force attack
The complexity of the brute force attack ishigher than 280 ticksand such anattack can only be mounted for each fixed IV.
For each enumeratedki , 1 ≤ i ≤ 280 − 1, the attacker first needs to proceed theinitialization phase which needs 160 ticks.
If each keystream bit is treated as a random variable, then for eachki , theprobability that the attacker need to generatel (1 ≤ l ≤ 80) bits keystream is 1for l = 1 and 2−(l−1) for l > 1
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 11 / 29

Observation III-Complexity of the brute force attack
The complexity of the brute force attack ishigher than 280 ticksand such anattack can only be mounted for each fixed IV.
For each enumeratedki , 1 ≤ i ≤ 280 − 1, the attacker first needs to proceed theinitialization phase which needs 160 ticks.
If each keystream bit is treated as a random variable, then for eachki , theprobability that the attacker need to generatel (1 ≤ l ≤ 80) bits keystream is 1for l = 1 and 2−(l−1) for l > 1
Let Nw be the expected number of bits needed to generate for each enumeratedkey, which isNw =
∑80l=1 l · Pl =
∑80l=1 l · 2−(l−1) ≈ 4. Then, the total time
complexity is(280 − 1) · (160+ 4) ≈ 287.4 cipher ticks.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 11 / 29

Outline
Introduction
Description of Grain v1
Main idea& some key observations
The general attack model: NCA-1.0
NCA-2.0& NCA-3.0
Simulations
Conclusions
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 12 / 29

The General Attack Model
Main concern:Identify the correctd-near-collision ISD.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 13 / 29

The General Attack Model
Main concern:Identify the correctd-near-collision ISD.
Off-line stage:some well structured differential tables are pre-computed. Thetable structure can be illustrated as follows.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 13 / 29

The General Attack Model
Main concern:Identify the correctd-near-collision ISD.
Off-line stage:some well structured differential tables are pre-computed. Thetable structure can be illustrated as follows.
table-0x0000
∆s4 52.0%∆s2 12.9%
...
table-0x0001
∆s2 13.8%∆s3 13.2%
...
...
table-0x0080
∆s4 48.0%...
...
The total number of tables isQ(n, d, l) and the average number of rows in eachtable isR(n, d, l).
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 13 / 29

The General Attack Model
Main concern:Identify the correctd-near-collision ISD.
Off-line stage:some well structured differential tables are pre-computed. Thetable structure can be illustrated as follows.
table-0x0000
∆s4 52.0%∆s2 12.9%
...
table-0x0001
∆s2 13.8%∆s3 13.2%
...
...
table-0x0080
∆s4 48.0%...
...
The total number of tables isQ(n, d, l) and the average number of rows in eachtable isR(n, d, l).
Due to the non-uniform distribution of the KSDs for a fixed ISD, we onlyconsider at most 100 KSDs whose proportions are the first 100 largest among allthe KSDs. HenceR(n, d, l) is upper bounded by 100· V(n, d)/Q(n, d, l).
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 13 / 29

The General Attack Model
Main concern:Identify the correctd-near-collision ISD.
Off-line stage:some well structured differential tables are pre-computed. Thetable structure can be illustrated as follows.
table-0x0000
∆s4 52.0%∆s2 12.9%
...
table-0x0001
∆s2 13.8%∆s3 13.2%
...
...
table-0x0080
∆s4 48.0%...
...
The total number of tables isQ(n, d, l) and the average number of rows in eachtable isR(n, d, l).
Due to the non-uniform distribution of the KSDs for a fixed ISD, we onlyconsider at most 100 KSDs whose proportions are the first 100 largest among allthe KSDs. HenceR(n, d, l) is upper bounded by 100· V(n, d)/Q(n, d, l).
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 13 / 29

On-line Stage
Now we discuss how to obtain the ISD by utilizing the pre-computed tables andthe truncated keystreams.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 14 / 29

On-line Stage
Now we discuss how to obtain the ISD by utilizing the pre-computed tables andthe truncated keystreams.
1 Randomly collect two keystream segments setsA andB, satisfying|A| · |B| ≥ 2n/V(n, d).
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 14 / 29

On-line Stage
Now we discuss how to obtain the ISD by utilizing the pre-computed tables andthe truncated keystreams.
1 Randomly collect two keystream segments setsA andB, satisfying|A| · |B| ≥ 2n/V(n, d).
2 SortA andB with respect to the value of the firstl bits. Divide them intomdifferentgroupsGA
1 ,GA2, ..., GA
m andGB1,G
B2, ...,G
Bm respectively.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 14 / 29

On-line Stage
Now we discuss how to obtain the ISD by utilizing the pre-computed tables andthe truncated keystreams.
1 Randomly collect two keystream segments setsA andB, satisfying|A| · |B| ≥ 2n/V(n, d).
2 SortA andB with respect to the value of the firstl bits. Divide them intomdifferentgroupsGA
1 ,GA2, ..., GA
m andGB1,G
B2, ...,G
Bm respectively.
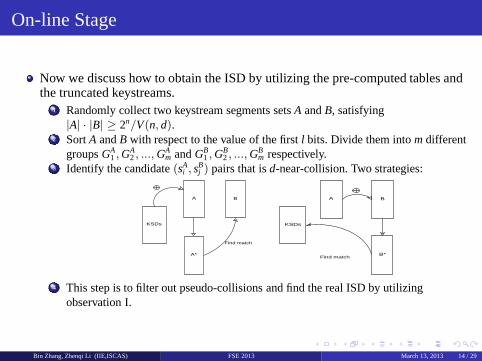
3 Identify the candidate(sAi , s
Bj ) pairs that isd-near-collision. Two strategies:
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 14 / 29
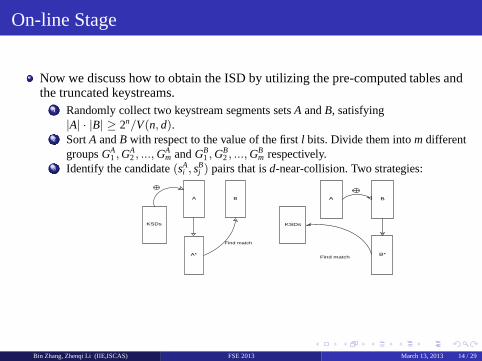
On-line Stage
Now we discuss how to obtain the ISD by utilizing the pre-computed tables andthe truncated keystreams.
1 Randomly collect two keystream segments setsA andB, satisfying|A| · |B| ≥ 2n/V(n, d).
2 SortA andB with respect to the value of the firstl bits. Divide them intomdifferentgroupsGA
1 ,GA2, ..., GA
m andGB1,G
B2, ...,G
Bm respectively.
3 Identify the candidate(sAi , s
Bj ) pairs that isd-near-collision. Two strategies:
KSDs
A
A*
B
Find match
KSDs
A
B*
B
Find match
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 14 / 29
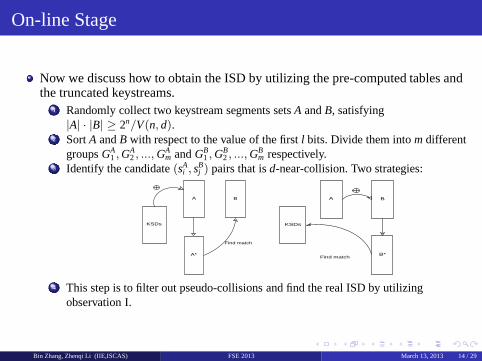
On-line Stage
Now we discuss how to obtain the ISD by utilizing the pre-computed tables andthe truncated keystreams.
1 Randomly collect two keystream segments setsA andB, satisfying|A| · |B| ≥ 2n/V(n, d).
2 SortA andB with respect to the value of the firstl bits. Divide them intomdifferentgroupsGA
1 ,GA2, ..., GA
m andGB1,G
B2, ...,G
Bm respectively.
3 Identify the candidate(sAi , s
Bj ) pairs that isd-near-collision. Two strategies:
KSDs
A
A*
B
Find match
KSDs
A
B*
B
Find match
4 This step is to filter out pseudo-collisions and find the real ISD by utilizingobservation I.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 14 / 29
On-line Stage
Now we discuss how to obtain the ISD by utilizing the pre-computed tables andthe truncated keystreams.
1 Randomly collect two keystream segments setsA andB, satisfying|A| · |B| ≥ 2n/V(n, d).
2 SortA andB with respect to the value of the firstl bits. Divide them intomdifferentgroupsGA
1 ,GA2, ..., GA
m andGB1,G
B2, ...,G
Bm respectively.
3 Identify the candidate(sAi , s
Bj ) pairs that isd-near-collision. Two strategies:
KSDs
A
A*
B
Find match
KSDs
A
B*
B
Find match
4 This step is to filter out pseudo-collisions and find the real ISD by utilizingobservation I.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 14 / 29

Complexity Analysis of NCA-1.0
Pre-computation time:P = 2 · N · V(n, d) · l. The data complexity isD = |A|+ |B| l-bit keystream segments and the memory requirement isM = M1 + M2 = V(n, d) · 26.6 + |A|+ |B| entries.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 15 / 29

Complexity Analysis of NCA-1.0
Pre-computation time:P = 2 · N · V(n, d) · l. The data complexity isD = |A|+ |B| l-bit keystream segments and the memory requirement isM = M1 + M2 = V(n, d) · 26.6 + |A|+ |B| entries.
Step 2:T1 = (|A| · log |A|+ |B| · log |B|)/Ω cipher ticks.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 15 / 29

Complexity Analysis of NCA-1.0
Pre-computation time:P = 2 · N · V(n, d) · l. The data complexity isD = |A|+ |B| l-bit keystream segments and the memory requirement isM = M1 + M2 = V(n, d) · 26.6 + |A|+ |B| entries.
Step 2:T1 = (|A| · log |A|+ |B| · log |B|)/Ω cipher ticks.
Step 3:T2 = minQ(n, d, l) · m · logm/Ω, m2 · logQ(n, d, l)/Ω ticks.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 15 / 29

Complexity Analysis of NCA-1.0
Pre-computation time:P = 2 · N · V(n, d) · l. The data complexity isD = |A|+ |B| l-bit keystream segments and the memory requirement isM = M1 + M2 = V(n, d) · 26.6 + |A|+ |B| entries.
Step 2:T1 = (|A| · log |A|+ |B| · log |B|)/Ω cipher ticks.
Step 3:T2 = minQ(n, d, l) · m · logm/Ω, m2 · logQ(n, d, l)/Ω ticks.
Step 4:T3 = |A| · |B| · V(n, d) · 26.6 · TK/Q(n, d, l).
Table: The attack complexity with variousl
l P T1 T2 T3 T102 295.7 240.9 285.8 286.4 286.4
104 295.7 240.9 285.9 284.4 285.9
106 295.7 240.9 285.9 272.4 285.9
n = 160, d = 16, D = 245.8, M = 278.6
Strategy II is chosen in Step 3.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 15 / 29

Complexity Analysis of NCA-1.0
Pre-computation time:P = 2 · N · V(n, d) · l. The data complexity isD = |A|+ |B| l-bit keystream segments and the memory requirement isM = M1 + M2 = V(n, d) · 26.6 + |A|+ |B| entries.
Step 2:T1 = (|A| · log |A|+ |B| · log |B|)/Ω cipher ticks.
Step 3:T2 = minQ(n, d, l) · m · logm/Ω, m2 · logQ(n, d, l)/Ω ticks.
Step 4:T3 = |A| · |B| · V(n, d) · 26.6 · TK/Q(n, d, l).
Table: The attack complexity with variousl
l P T1 T2 T3 T102 295.7 240.9 285.8 286.4 286.4
104 295.7 240.9 285.9 284.4 285.9
106 295.7 240.9 285.9 272.4 285.9
n = 160, d = 16, D = 245.8, M = 278.6
Strategy II is chosen in Step 3.
We name this basic attack as NCA-1.0. The pre-computation complexityP = 295.7 exceeds the brute force attack complexity of 287.4.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 15 / 29

Outline
Introduction
Description of Grain v1
Main idea& some key observations
The general attack model: NCA-1.0
NCA-2.0& NCA-3.0
Simulations
Conclusions
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 16 / 29

NCA-2.0
The first improvement is designated by combining thesampling resistanceproperty of Grainwith NCA-1.0.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 17 / 29

NCA-2.0
The first improvement is designated by combining thesampling resistanceproperty of Grainwith NCA-1.0.
LemmaGiven the value of139particular state bits of Grain and the first21keystream bitsproduced from that state, another21 internal state bits can be deduced directly.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 17 / 29

NCA-2.0
The first improvement is designated by combining thesampling resistanceproperty of Grainwith NCA-1.0.
LemmaGiven the value of139particular state bits of Grain and the first21keystream bitsproduced from that state, another21 internal state bits can be deduced directly.
The sampling resistance of Grain isR= 2−21. Thus we definea restrictedone-way functionτ : 0, 1139 → 0, 1139 by choosing a prefix of 021.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 17 / 29

NCA-2.0
The first improvement is designated by combining thesampling resistanceproperty of Grainwith NCA-1.0.
LemmaGiven the value of139particular state bits of Grain and the first21keystream bitsproduced from that state, another21 internal state bits can be deduced directly.
The sampling resistance of Grain isR= 2−21. Thus we definea restrictedone-way functionτ : 0, 1139 → 0, 1139 by choosing a prefix of 021.
1. For each 139-bit input valuex, the remaining 21-bit internal state can be determinedby Lemma 2 and the prefix of 021.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 17 / 29

NCA-2.0
The first improvement is designated by combining thesampling resistanceproperty of Grainwith NCA-1.0.
LemmaGiven the value of139particular state bits of Grain and the first21keystream bitsproduced from that state, another21 internal state bits can be deduced directly.
The sampling resistance of Grain isR= 2−21. Thus we definea restrictedone-way functionτ : 0, 1139 → 0, 1139 by choosing a prefix of 021.
1. For each 139-bit input valuex, the remaining 21-bit internal state can be determinedby Lemma 2 and the prefix of 021.
2. Run the cipher forward for 160 ticks, generate an 160-bit segment 021||y, outputy.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 17 / 29

NCA-2.0
The first improvement is designated by combining thesampling resistanceproperty of Grainwith NCA-1.0.
LemmaGiven the value of139particular state bits of Grain and the first21keystream bitsproduced from that state, another21 internal state bits can be deduced directly.
The sampling resistance of Grain isR= 2−21. Thus we definea restrictedone-way functionτ : 0, 1139 → 0, 1139 by choosing a prefix of 021.
1. For each 139-bit input valuex, the remaining 21-bit internal state can be determinedby Lemma 2 and the prefix of 021.
2. Run the cipher forward for 160 ticks, generate an 160-bit segment 021||y, outputy.
Now, the searching space is reduced to a special subset of theinternal states.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 17 / 29

Complexity Analysis of NCA-2.0
Now, the goal is torecover then∗ = 139 bits ISDwhich contains 60 NFSR statebits and 79 LFSR state bits, instead of then = 160 bits ISD.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 18 / 29

Complexity Analysis of NCA-2.0
Now, the goal is torecover then∗ = 139 bits ISDwhich contains 60 NFSR statebits and 79 LFSR state bits, instead of then = 160 bits ISD.
We need to collect those keystream segments with the prefix pattern 021, the datacomplexity isD = (|A|+ |B|) · 221.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 18 / 29

Complexity Analysis of NCA-2.0
Now, the goal is torecover then∗ = 139 bits ISDwhich contains 60 NFSR statebits and 79 LFSR state bits, instead of then = 160 bits ISD.
We need to collect those keystream segments with the prefix pattern 021, the datacomplexity isD = (|A|+ |B|) · 221.
Table: The attack complexities with variousl based on sampling resistance
l P∗ T1 T2 T3 T92 283.4 235.9 276.1 275.4 276.1
94 283.4 235.9 276.2 273.4 276.2
96 283.4 235.9 276.2 271.4 276.2
n∗ = 139, d = 13, D = 262, M = 265.9.Strategy II is chosen in Step 3.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 18 / 29

Complexity Analysis of NCA-2.0
Now, the goal is torecover then∗ = 139 bits ISDwhich contains 60 NFSR statebits and 79 LFSR state bits, instead of then = 160 bits ISD.
We need to collect those keystream segments with the prefix pattern 021, the datacomplexity isD = (|A|+ |B|) · 221.
Table: The attack complexities with variousl based on sampling resistance
l P∗ T1 T2 T3 T92 283.4 235.9 276.1 275.4 276.1
94 283.4 235.9 276.2 273.4 276.2
96 283.4 235.9 276.2 271.4 276.2
n∗ = 139, d = 13, D = 262, M = 265.9.Strategy II is chosen in Step 3.
Compared to NCA-1.0, our improved attack reducesP by a factor of 212.3 and itsaves 10-bit storage for each entry inA andB.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 18 / 29

Complexity Analysis of NCA-2.0
Now, the goal is torecover then∗ = 139 bits ISDwhich contains 60 NFSR statebits and 79 LFSR state bits, instead of then = 160 bits ISD.
We need to collect those keystream segments with the prefix pattern 021, the datacomplexity isD = (|A|+ |B|) · 221.
Table: The attack complexities with variousl based on sampling resistance
l P∗ T1 T2 T3 T92 283.4 235.9 276.1 275.4 276.1
94 283.4 235.9 276.2 273.4 276.2
96 283.4 235.9 276.2 271.4 276.2
n∗ = 139, d = 13, D = 262, M = 265.9.Strategy II is chosen in Step 3.
Compared to NCA-1.0, our improved attack reducesP by a factor of 212.3 and itsaves 10-bit storage for each entry inA andB.
All the complexities are under the brute force attack complexity of 287.4. Wename this combined attack as NCA-2.0.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 18 / 29

NCA-3.0
The second improvement is based on NCA-2.0 byutilizing the non-uniformdistribution of KSDsamong all the tables. Some observations (Example inSection 3.2):
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 19 / 29

NCA-3.0
The second improvement is based on NCA-2.0 byutilizing the non-uniformdistribution of KSDsamong all the tables. Some observations (Example inSection 3.2):
1. Some tables like table-0x0000, table-0x0008, table-0x0004 contains more rows thanthose like table-0x0012 and table-0x0048.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 19 / 29

NCA-3.0
The second improvement is based on NCA-2.0 byutilizing the non-uniformdistribution of KSDsamong all the tables. Some observations (Example inSection 3.2):
1. Some tables like table-0x0000, table-0x0008, table-0x0004 contains more rows thanthose like table-0x0012 and table-0x0048.
2. Table-0x0000 contains the most rows among all the tables.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 19 / 29

NCA-3.0
The second improvement is based on NCA-2.0 byutilizing the non-uniformdistribution of KSDsamong all the tables. Some observations (Example inSection 3.2):
1. Some tables like table-0x0000, table-0x0008, table-0x0004 contains more rows thanthose like table-0x0012 and table-0x0048.
2. Table-0x0000 contains the most rows among all the tables.3. Most tables like table-0xfe00, table-0xfd68 and table-0xfad1 only contain a single
row.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 19 / 29

NCA-3.0
The second improvement is based on NCA-2.0 byutilizing the non-uniformdistribution of KSDsamong all the tables. Some observations (Example inSection 3.2):
1. Some tables like table-0x0000, table-0x0008, table-0x0004 contains more rows thanthose like table-0x0012 and table-0x0048.
2. Table-0x0000 contains the most rows among all the tables.3. Most tables like table-0xfe00, table-0xfd68 and table-0xfad1 only contain a single
row.4. The tables with low Hamming weight indexes satisfyingwH(KSD) ≤ 3 (special
tables) contain about 80% of all theV(n, d) different ISDs.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 19 / 29

NCA-3.0
The second improvement is based on NCA-2.0 byutilizing the non-uniformdistribution of KSDsamong all the tables. Some observations (Example inSection 3.2):
1. Some tables like table-0x0000, table-0x0008, table-0x0004 contains more rows thanthose like table-0x0012 and table-0x0048.
2. Table-0x0000 contains the most rows among all the tables.3. Most tables like table-0xfe00, table-0xfd68 and table-0xfad1 only contain a single
row.4. The tables with low Hamming weight indexes satisfyingwH(KSD) ≤ 3 (special
tables) contain about 80% of all theV(n, d) different ISDs.
AssumptionOn average, the special tables can cover50% of all the V(n∗, d) different ISDs, whend and l becomes larger.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 19 / 29

NCA-3.0
The second improvement is based on NCA-2.0 byutilizing the non-uniformdistribution of KSDsamong all the tables. Some observations (Example inSection 3.2):
1. Some tables like table-0x0000, table-0x0008, table-0x0004 contains more rows thanthose like table-0x0012 and table-0x0048.
2. Table-0x0000 contains the most rows among all the tables.3. Most tables like table-0xfe00, table-0xfd68 and table-0xfad1 only contain a single
row.4. The tables with low Hamming weight indexes satisfyingwH(KSD) ≤ 3 (special
tables) contain about 80% of all theV(n, d) different ISDs.
AssumptionOn average, the special tables can cover50% of all the V(n∗, d) different ISDs, whend and l becomes larger.
The assumption indicates that in the off-line stage, we onlyneed to constructthose special tables.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 19 / 29

Complexity Analysis of NCA-3.0
All the complexities remain unchanged exceptT2 = minl3 · m · logm, m2 · log l3.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 20 / 29

Complexity Analysis of NCA-3.0
All the complexities remain unchanged exceptT2 = minl3 · m · logm, m2 · log l3.
Table: The attack complexity on Grain with variousl based on special tables
l P∗ T1 T2 T3 T92 273.1 241.9 260.5 275.4 275.4
94 273.1 241.9 260.6 273.4 273.4
96 273.1 241.9 260.7 271.4 271.4
n∗ = 139, d = 10, M = 262.8 bits,D = 267.8 bits keystream.Strategy I is chosen in Step 3.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 20 / 29

Complexity Analysis of NCA-3.0
All the complexities remain unchanged exceptT2 = minl3 · m · logm, m2 · log l3.
Table: The attack complexity on Grain with variousl based on special tables
l P∗ T1 T2 T3 T92 273.1 241.9 260.5 275.4 275.4
94 273.1 241.9 260.6 273.4 273.4
96 273.1 241.9 260.7 271.4 271.4
n∗ = 139, d = 10, M = 262.8 bits,D = 267.8 bits keystream.Strategy I is chosen in Step 3.
We can obtain an attack ofT = 271.4, M = 262.8 andD = 267.8 with thepre-computation complexityP = 273.1. We name this enhanced attack asNCA-3.0.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 20 / 29

Outline
Introduction
Description of Grain v1
Main idea& some key observations
The general attack model: NCA-1.0
NCA-2.0& NCA-3.0
Simulations
Conclusions
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 21 / 29

Simulation and Results-Reduced Version
The reduced version of Grain v1 cipher consists of an LFSR of 32 bits and anNFSR of 32 bits. The update functions of LFSR and NFSR are designed in asimilar way as full version.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 22 / 29

Simulation and Results-Reduced Version
The reduced version of Grain v1 cipher consists of an LFSR of 32 bits and anNFSR of 32 bits. The update functions of LFSR and NFSR are designed in asimilar way as full version.
LFSR update function:l′i+32 = l′i+30 + l′i+25 + l′i+16 + l′i . NFSR update function:
n′i+32 = l′i + n′i+25 + n′i+23 + n′i+15 + n′i+8 + n′i + n′i+25n′i+23 + n′i+15n
′i+8
+ n′i+25n′i+23n
′i+15 + n′i+23n
′i+15n
′i+8 + n′i+25n
′i+23n
′i+15n
′i+8.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 22 / 29

Simulation and Results-Reduced Version
The reduced version of Grain v1 cipher consists of an LFSR of 32 bits and anNFSR of 32 bits. The update functions of LFSR and NFSR are designed in asimilar way as full version.
LFSR update function:l′i+32 = l′i+30 + l′i+25 + l′i+16 + l′i . NFSR update function:
n′i+32 = l′i + n′i+25 + n′i+23 + n′i+15 + n′i+8 + n′i + n′i+25n′i+23 + n′i+15n
′i+8
+ n′i+25n′i+23n
′i+15 + n′i+23n
′i+15n
′i+8 + n′i+25n
′i+23n
′i+15n
′i+8.
The output function asz′i =∑
k∈A′ n′i+k + h(l′i+3, l′i+11, l
′i+21, l
′i+25, n
′i+24), where
A = 1, 4, 10, 21.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 22 / 29

Simulation and Results-Reduced Version
The reduced version of Grain v1 cipher consists of an LFSR of 32 bits and anNFSR of 32 bits. The update functions of LFSR and NFSR are designed in asimilar way as full version.
LFSR update function:l′i+32 = l′i+30 + l′i+25 + l′i+16 + l′i . NFSR update function:
n′i+32 = l′i + n′i+25 + n′i+23 + n′i+15 + n′i+8 + n′i + n′i+25n′i+23 + n′i+15n
′i+8
+ n′i+25n′i+23n
′i+15 + n′i+23n
′i+15n
′i+8 + n′i+25n
′i+23n
′i+15n
′i+8.
The output function asz′i =∑
k∈A′ n′i+k + h(l′i+3, l′i+11, l
′i+21, l
′i+25, n
′i+24), where
A = 1, 4, 10, 21.
Given the value of 53 particular state bits (including 32 bits LFSR and 21 bitsNFSR) and the first 11 keystream bits, another 11 internal state bits can bededuced directly. Thenthe sampling resistance isR′ = 2−11.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 22 / 29

Verification of Assumption 1
We randomly chose 104 ISDs with Hamming weightd ≤ 4 and generate theircorresponding KSDs with the proportions. For each ISD,N random internalstates were generated to determine the projection from ISD to KSD.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 23 / 29

Verification of Assumption 1
We randomly chose 104 ISDs with Hamming weightd ≤ 4 and generate theircorresponding KSDs with the proportions. For each ISD,N random internalstates were generated to determine the projection from ISD to KSD.
Only those KSDs satisfyingwH(KSD) ≤ 3 will be recorded and theircorresponding ISDs will be stored in a text file named with KSD.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 23 / 29

Verification of Assumption 1
We randomly chose 104 ISDs with Hamming weightd ≤ 4 and generate theircorresponding KSDs with the proportions. For each ISD,N random internalstates were generated to determine the projection from ISD to KSD.
Only those KSDs satisfyingwH(KSD) ≤ 3 will be recorded and theircorresponding ISDs will be stored in a text file named with KSD.
Similar to the process of the off-line stage, we only consider at mostη KSDswhose proportions are the firstη largest among all the KSDs. Finally, we countthe number of different ISDs in these special tables.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 23 / 29

Verification of Assumption 1
We randomly chose 104 ISDs with Hamming weightd ≤ 4 and generate theircorresponding KSDs with the proportions. For each ISD,N random internalstates were generated to determine the projection from ISD to KSD.
Only those KSDs satisfyingwH(KSD) ≤ 3 will be recorded and theircorresponding ISDs will be stored in a text file named with KSD.
Similar to the process of the off-line stage, we only consider at mostη KSDswhose proportions are the firstη largest among all the KSDs. Finally, we countthe number of different ISDs in these special tables.
Table: Verification of Assumption 1
η l No. of ISDs Proportion50 24 9842 98.4%
1000 24 9851 98.5%50 32 9202 92.0%
1000 32 9153 91.5%n = 53, d = 4.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 23 / 29

Verification of Assumption 1
We randomly chose 104 ISDs with Hamming weightd ≤ 4 and generate theircorresponding KSDs with the proportions. For each ISD,N random internalstates were generated to determine the projection from ISD to KSD.
Only those KSDs satisfyingwH(KSD) ≤ 3 will be recorded and theircorresponding ISDs will be stored in a text file named with KSD.
Similar to the process of the off-line stage, we only consider at mostη KSDswhose proportions are the firstη largest among all the KSDs. Finally, we countthe number of different ISDs in these special tables.
Table: Verification of Assumption 1
η l No. of ISDs Proportion50 24 9842 98.4%
1000 24 9851 98.5%50 32 9202 92.0%
1000 32 9153 91.5%n = 53, d = 4.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 23 / 29

Simulations
In the off-line stage, we setη = 50,N = 212 andd = 4.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 24 / 29
Simulations
In the off-line stage, we setη = 50,N = 212 andd = 4.
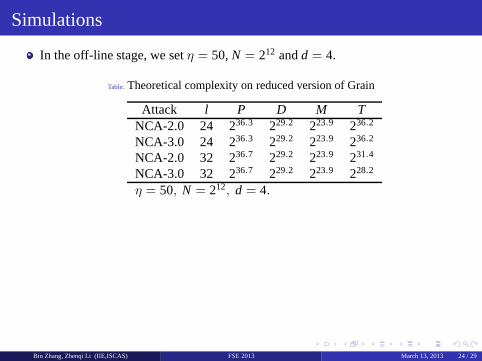
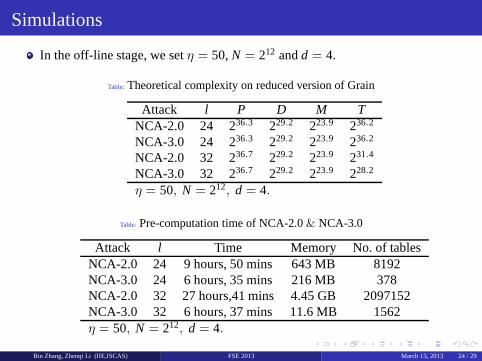
Table: Theoretical complexity on reduced version of Grain
Attack l P D M TNCA-2.0 24 236.3 229.2 223.9 236.2
NCA-3.0 24 236.3 229.2 223.9 236.2
NCA-2.0 32 236.7 229.2 223.9 231.4
NCA-3.0 32 236.7 229.2 223.9 228.2
η = 50, N = 212, d = 4.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 24 / 29
Simulations
In the off-line stage, we setη = 50,N = 212 andd = 4.
Table: Theoretical complexity on reduced version of Grain
Attack l P D M TNCA-2.0 24 236.3 229.2 223.9 236.2
NCA-3.0 24 236.3 229.2 223.9 236.2
NCA-2.0 32 236.7 229.2 223.9 231.4
NCA-3.0 32 236.7 229.2 223.9 228.2
η = 50, N = 212, d = 4.
Table: Pre-computation time of NCA-2.0& NCA-3.0
Attack l Time Memory No. of tablesNCA-2.0 24 9 hours, 50 mins 643 MB 8192NCA-3.0 24 6 hours, 35 mins 216 MB 378NCA-2.0 32 27 hours,41 mins 4.45 GB 2097152NCA-3.0 32 6 hours, 37 mins 11.6 MB 1562η = 50, N = 212, d = 4.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 24 / 29

Simulations
We apply NCA-2.0 and NCA-3.0 to the reduced version of Grain respectively for140 randomly generated (K,IV) pairs.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 25 / 29

Simulations
We apply NCA-2.0 and NCA-3.0 to the reduced version of Grain respectively for140 randomly generated (K,IV) pairs.
Table: The simulation results on reduced version of Grain
Attack l Average Attack SuccessTimea Probability
NCA-2.0 24 1 hours, 53 mins 9%NCA-3.0 24 1 hours, 31 mins 7%NCA-2.0 32 2 hours, 12 mins 6%NCA-3.0 32 41 mins 4%aThis is the average time for each on-line attack.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 25 / 29

Simulations
We apply NCA-2.0 and NCA-3.0 to the reduced version of Grain respectively for140 randomly generated (K,IV) pairs.
Table: The simulation results on reduced version of Grain
Attack l Average Attack SuccessTimea Probability
NCA-2.0 24 1 hours, 53 mins 9%NCA-3.0 24 1 hours, 31 mins 7%NCA-2.0 32 2 hours, 12 mins 6%NCA-3.0 32 41 mins 4%aThis is the average time for each on-line attack.
The experimental time is based on running an non-optimized C++ program on a1.83 GHz CPU with 2GB RAM and 1TB harddisk.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 25 / 29

Simulations
We apply NCA-2.0 and NCA-3.0 to the reduced version of Grain respectively for140 randomly generated (K,IV) pairs.
Table: The simulation results on reduced version of Grain
Attack l Average Attack SuccessTimea Probability
NCA-2.0 24 1 hours, 53 mins 9%NCA-3.0 24 1 hours, 31 mins 7%NCA-2.0 32 2 hours, 12 mins 6%NCA-3.0 32 41 mins 4%aThis is the average time for each on-line attack.
The experimental time is based on running an non-optimized C++ program on a1.83 GHz CPU with 2GB RAM and 1TB harddisk.
The success probability is the proportion of the number of the correct internalstate difference stored in the KSD tables.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 25 / 29

Simulations
We apply NCA-2.0 and NCA-3.0 to the reduced version of Grain respectively for140 randomly generated (K,IV) pairs.
Table: The simulation results on reduced version of Grain
Attack l Average Attack SuccessTimea Probability
NCA-2.0 24 1 hours, 53 mins 9%NCA-3.0 24 1 hours, 31 mins 7%NCA-2.0 32 2 hours, 12 mins 6%NCA-3.0 32 41 mins 4%aThis is the average time for each on-line attack.
The experimental time is based on running an non-optimized C++ program on a1.83 GHz CPU with 2GB RAM and 1TB harddisk.
The success probability is the proportion of the number of the correct internalstate difference stored in the KSD tables.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 25 / 29

Further Discussion
The success probability needs to be stabilized.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 26 / 29

Further Discussion
The success probability needs to be stabilized.
Our attack need to be refined further and we indeed get some improvements byreducing the complexity of recovering the NFSR given the LFSR and the statedifference. We will provide the details in the upcoming papers.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 26 / 29

Further Discussion
The success probability needs to be stabilized.
Our attack need to be refined further and we indeed get some improvements byreducing the complexity of recovering the NFSR given the LFSR and the statedifference. We will provide the details in the upcoming papers.
We can also see that the experimental success probability ofNCA-2.0 is lowerthan estimated in theory. The reason is that we choose a restricted value ofη andN. These two parameters directly influence the size and the number of thepre-computed tables, hence affect the success probability.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 26 / 29

Further Discussion
The success probability needs to be stabilized.
Our attack need to be refined further and we indeed get some improvements byreducing the complexity of recovering the NFSR given the LFSR and the statedifference. We will provide the details in the upcoming papers.
We can also see that the experimental success probability ofNCA-2.0 is lowerthan estimated in theory. The reason is that we choose a restricted value ofη andN. These two parameters directly influence the size and the number of thepre-computed tables, hence affect the success probability.
How to theoretically derive the relationship between the success probability andthese two parameters is our future work.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 26 / 29

Outline
Introduction
Description of Grain v1
Main idea& some key observations
The general attack model: NCA-1.0
NCA-2.0& NCA-3.0
Simulations
Conclusions
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 27 / 29

Conclusions
In this paper, we have proposed a key recovery attack, callednear collisionattack on Grain v1.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 28 / 29

Conclusions
In this paper, we have proposed a key recovery attack, callednear collisionattack on Grain v1.
Based on some key observations, we have presented the basic attack calledNCA-1.0 and further enhance it to NCA-2.0 and NCA-3.0 by combining thesampling resistance of Grain v1 and the non-uniform distribution of the KSDtable size respectively.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 28 / 29

Conclusions
In this paper, we have proposed a key recovery attack, callednear collisionattack on Grain v1.
Based on some key observations, we have presented the basic attack calledNCA-1.0 and further enhance it to NCA-2.0 and NCA-3.0 by combining thesampling resistance of Grain v1 and the non-uniform distribution of the KSDtable size respectively.
Our attack has been verified on a reduced version of Grain v1 and anextrapolation of the results indicates an attack on the original Grain v1.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 28 / 29

Conclusions
In this paper, we have proposed a key recovery attack, callednear collisionattack on Grain v1.
Based on some key observations, we have presented the basic attack calledNCA-1.0 and further enhance it to NCA-2.0 and NCA-3.0 by combining thesampling resistance of Grain v1 and the non-uniform distribution of the KSDtable size respectively.
Our attack has been verified on a reduced version of Grain v1 and anextrapolation of the results indicates an attack on the original Grain v1.
Our attack is just a starting point for further analysis of Grain-like stream ciphersand hopefully it provides some new insights on the design of such compactstream ciphers.
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 28 / 29

Thanks for your attention!
Bin Zhang, Zhenqi Li (IIE,ISCAS) FSE 2013 March 13, 2013 29 / 29