Embed Size (px)
Citation preview

Crowdsourcing Europe
Laurence LIVERMORE1 , John TWEDDLE1
& Rob CUBEY2
1 Natural History Museum, London; 2 Royal Botanic Garden Edinburgh
NBN Crowdsourcing Data Capture Summit
25 September 2015
Improving access, usability and enriching data on 385 million natural history specimens

Crowdsourcing Europe - Overview
• Intro– SYNTHESYS Project– Crowdsourcing research & key findings– Why build a new platform?
• Platform functionality – What will it do?
• Strategy & relevance to other organisations
• Future & concluding remarks

What is SYNTHESYS?
• EU FP7 framework project• 18 Partners• 3 core strands of work:
Transnational Access improves accessibility of natural history collections through funded physical access to collections / expertise and facilities.
Joint Research Activities improve access to data stored digitally within NH collections by extracting and enhancing
data from digitised collections
Network Activities deliver collection management policies, best practice models, unified standards and protocols for new and emerging collections.
Overall aim: “to create an integrated European infrastructure for researchers in the natural sciences”

SYNTHESYS Joint Research Activities
• Automated data collection from digital images
• New methods for 3D digitisation of NH collections
• Access and management of an integrated European digital collection (with NA2)
• Crowdsourcing metadata enrichment of digital images
• Led by: RBGE (lead), NHM, MfN
DNA sequencing viability
Quantitative colour analysis

Crowdsourcing metadata enrichment of digital images = label transcription (for now)
• Applied human intelligence is still required for label transcription
• Some of the issues that are very challenging to solve computationally are:– Diversity and irregularity of labels e.g. shape, size, contents– Recognising and mapping of label data to atomised fields is
complex– Label data can be duplicated– Label data can be irrelevant or contradictory– Mixture of handwritten and printed text

Crowdsourcing Landscape c. 2014
• Crowdsourcing landscape changed since planning (2011-2012)
• Many platforms (recently) launched!
• SYNTHESYS partners developing/using platforms
• Growing understanding of best practices (Ellwood et al, 2015)
Ellwood et al 2015. doi: 10.1093/biosci/biv005

Research & Requirements Gathering
• General research report (sent to all survey participants)– Platform comparisons– Case studies– Motivation, participation– Organisational investment
• Functional requirement survey & platform assessments
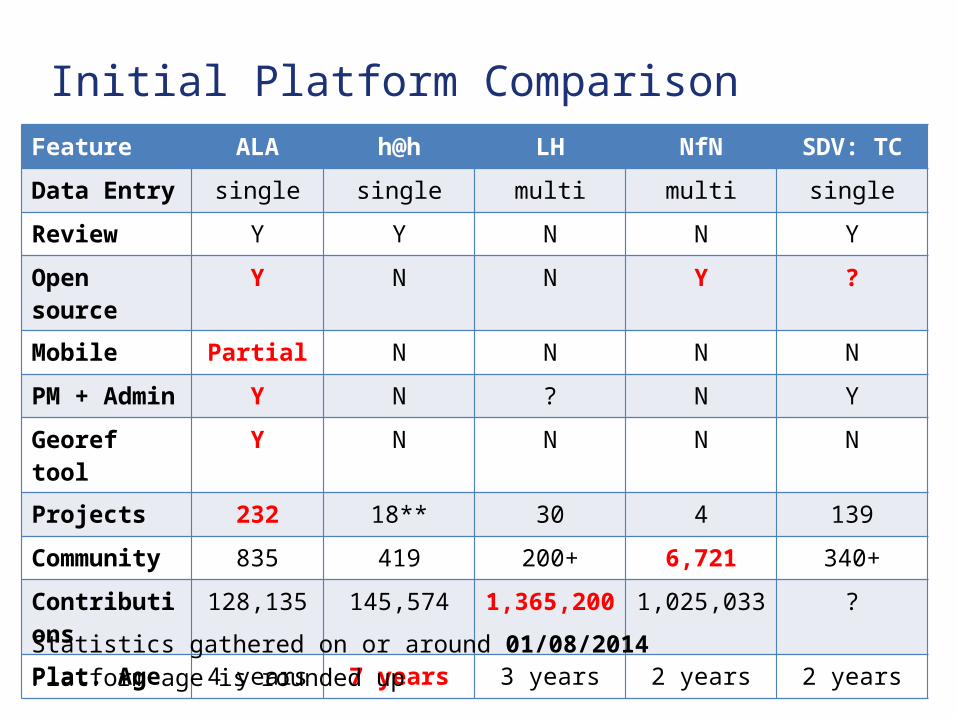
Initial Platform ComparisonFeature ALA h@h LH NfN SDV: TC
Data Entry single single multi multi single
Review Y Y N N Y
Open source Y N N Y ?
Mobile Partial N N N N
PM + Admin Y N ? N Y
Georef tool Y N N N N
Projects 232 18** 30 4 139
Community 835 419 200+ 6,721 340+
Contributions 128,135 145,574 1,365,200 1,025,033 ?
Plat. Age 4 years 7 years 3 years 2 years 2 years
Statistics gathered on or around 01/08/2014
Platform age is rounded up

NHM Case Study: Notes from Nature
• Led by Tim Conyers and Robert Prys-Jones
• Bird register project – initial test project for NfN
• 2,950 pages
• 315,785 transcriptions
• 75% of transcriptions by 1 volunteer!
• Project page: http://www.notesfromnature.org/#/archives/ornithological• Contributor stats:
http://data.nhm.ac.uk/dataset/notes-from-nature/resource/7f8fc5f5-90ae-4959-b286-9cb7951f2875?view_id=ce329dfd-99cb-4223-b615-ce95d6c707c7

RBG Kew Case Study: herbaria@home
• Led by Sarah Phillips
• British herbarium sheet transcription
• 13,000 transcriptions (2012-2014)
• Established community generated high quality data – even from handwriting interpretation

NHM Case Study:• Led by John Tweddle & Mark
Spencer (+ AMC Team)
• Combing contemporary recording with historical datasets
• 1,000 participants, 30,000 classifications, 1,800 field records
• 200 new orchid locations (incl. for threatened spp.)
• New recorders, new activity for existing enthusiasts
• Preliminary analysis already found flowering data are 10 days earlier for 2 orchid species
www.orchidobservers.org
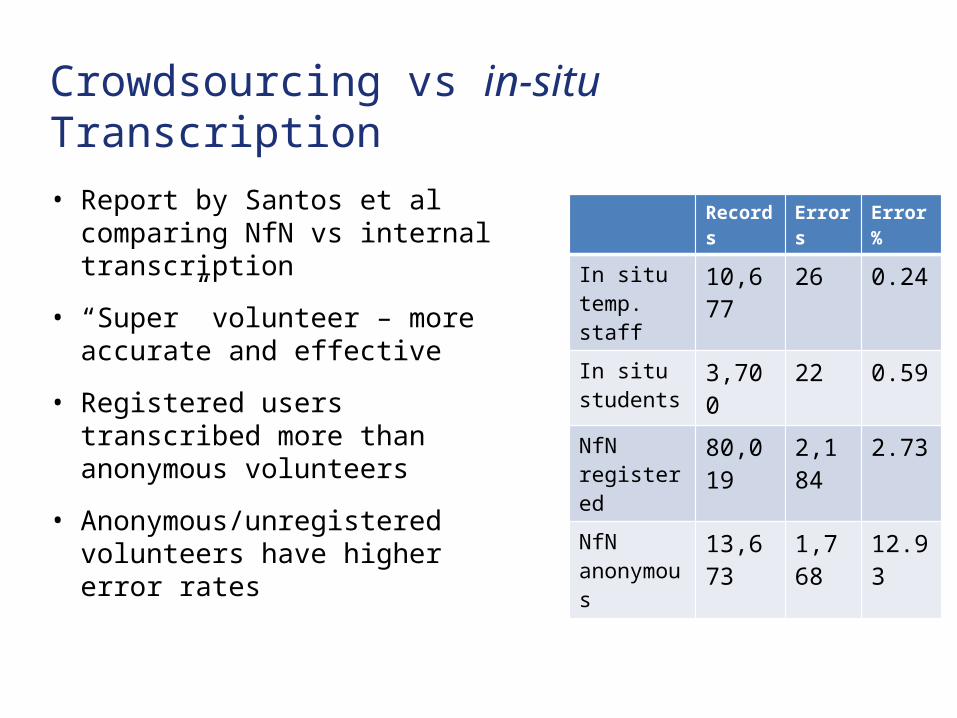
Crowdsourcing vs in-situ Transcription
• Report by Santos et al comparing NfN vs internal transcription
• “Super” volunteer – more accurate and effective
• Registered users transcribed more than anonymous volunteers
• Anonymous/unregistered volunteers have higher error rates
Records Errors Error %
In situ temp. staff
10,677 26 0.24
In situ students
3,700 22 0.59
NfN registered
80,019 2,184 2.73
NfN anonymous
13,673 1,768 12.93

Crowdsourcing vs in-situ Transcription - Recommendations
• Strongly recommend review-based transcription & multi-stage QC
• Need to offer better training to volunteers (but when?)
• Mechanisms to review incomplete submissions (either human or technical error)
• Highlighted benefits of analysing data – some errors and platform issues could have been fixed earlier…

Participant motivation - why does it matter?
CS isn’t free and participation isn’t a given!
• Understanding why volunteers participate in crowdsourcing endeavours and how to support, maintain and reward their involvement is central to success
• Narrative, tasks, supporting resources & feedback all affect participation
• Social aspects of crowdsourcing are critical and should not be ignored
• Motivations of participants vary and can be hard to determine
• Increasing number of studies, but biased coverage

Initial decision to participate
• Enthusiasm and interest in project topic
• Desire to record, find and discover
• Learning and development of new skills
• Contribution to the greater good (society/science)
• Sense of purpose and belonging to a community (social)
On-going support & reward – what works?
• On-going, rapid feedback and thanks
• Evidence that the data are being used
• Social interaction and community
• Personal learning and progression
• Recognition and reputational gain (incl. super-contributors)
• Awards, games, badges, leaderboard (work for some people, not others)
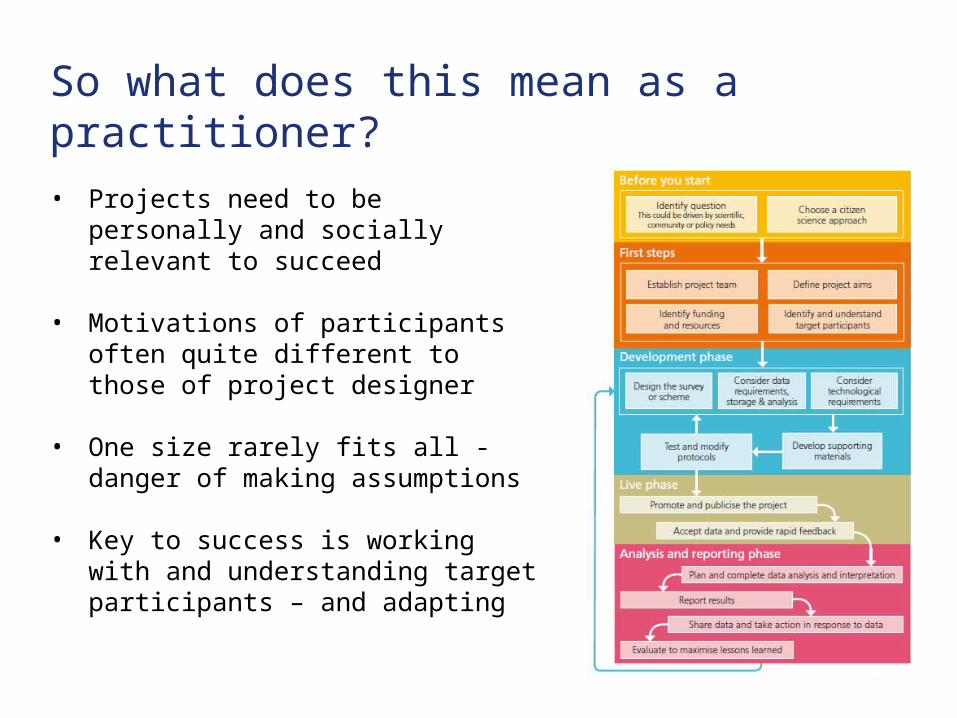
So what does this mean as a practitioner?
• Projects need to be personally and socially relevant to succeed
• Motivations of participants often quite different to those of project designer
• One size rarely fits all - danger of making assumptions
• Key to success is working with and understanding target participants – and adapting

Report conclusions: project choice and design
• Clear project rationale with both cultural and scientific benefits
• Projects should be actively promoted and monitored
• Scientists should be visible and engaged with volunteers
• Develop best practice for motivating and retaining volunteers (self-establishing community structure and forum, good science, tasks of interest, different rewards etc)
• Platform should use existing data standards – reduce bottle neck for collections management ingestion
• Resulting data should be freely available – projects do not end when all tasks are complete!

Areas of Organisational Investment
• Communication, outreach and support (e.g. dedicated staff time to develop and provide feedback to an external community, internal project manager and scientists)
• Strategic project selection (e.g. strong narrative, potential scientific outputs, public appeal, well-structured tasks of known complexity)
• Preparation of underlying data (e.g. data for autocomplete fields such as collector names or localities)
• Post-processing of data and subsequent import into institutional collections management system
• (?) Technical infrastructure (e.g. software, hardware and developers)

Functional requirements
• Surveyed 14 EU partners
• Captured functional requirements
• Prioritised using MoSCoW method
• Requirements written up as user stories after identifying key user roles
Must Have
Should Have
Could Have
Won’t Have
MoSCoW Method
“As a Community Manager I want to be able to queue projects so when one project gets completed a new one goes live so Volunteers always have content”

Platform Requirements
• Platform as a service• Strong management functionality• Organisational control• API (micro services) to allow embedding in mobile and
institutional websites• Key functionality (for example)
– Review-based transcription– Full task archiving– Multilingual support– Georeferencing & mapping support

Platform Choice
• Smithsonian Institution’s Transcription Centre– Strong collaboration potential/expertise– Met many functional requirements – Open source & Drupal-based – Highly customisable (in-house and externally)– Significant NHM developer experience

But not restrictive…
• Still encourage partners to use other systems
– ALA, Les Herbonautes, Panoptes
– Differing functionality & specialisms
– NHM still intends to work with Zooniverse

What are our plans?
• Technical analysis of major platforms• Functional requirements document• Finalise technical specification • Hire developer(s)…• Joint development and design work (NHM, Smithsonian,
Simbiotica)• User acceptance testing• Launch in August 2016!
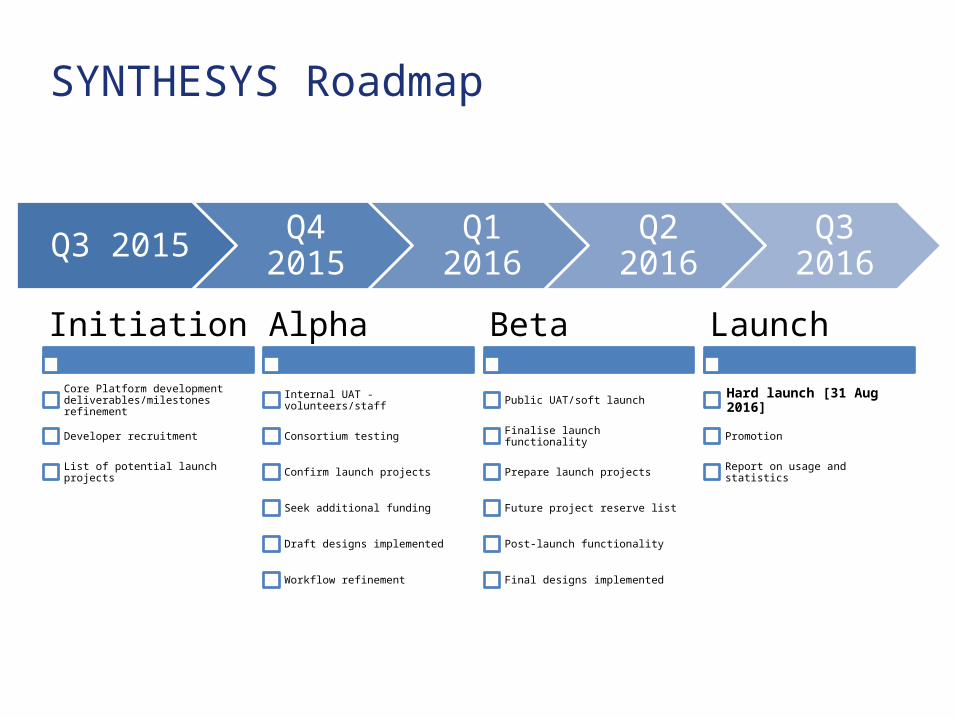
SYNTHESYS Roadmap
Initiation
Core Platform development deliverables/milestones refinement
Developer recruitment
List of potential launch projects
Alpha
Internal UAT - volunteers/staff
Consortium testing
Confirm launch projects
Seek additional funding
Draft designs implemented
Workflow refinement
Beta
Public UAT/soft launch
Finalise launch functionality
Prepare launch projects
Future project reserve list
Post-launch functionality
Final designs implemented
Launch
Hard launch [31 Aug 2016]
Promotion
Report on usage and statistics
Q3 2015 Q4 2015 Q1 2016 Q2 2016 Q3 2016

Risks
• Developer recruitment
• Challenging financial climate
• Multiple partners/stakeholders
• CMS integration – currently a
massive bottleneck for all our
digital projects

Why should you be interested in crowdsourcing?
• A stronger online presence/brand
• Increased rate of collections digitisation (100k+/day?), hence access to data
• Higher scientific output
• An effective way of engaging (dispersed) members of the public
• Deeper and more meaningful engagement with our collections

Why should you be interested in the SYNTHESYS platform?
• Platform model would work for institutes of all sizes
• Established scalable platform model
• Reduces technical overheads
• Modular structure allows customisation
• Open international collaboration (e.g. iDigBio/Smithsonian)
• Resulting data will be available for research (Data Portal)

Future
• Directly doing research through crowdsourcing
• Deeper engagement with volunteers (visiteering)
• Tracking our data, benefits, impact and repatriation
• Dual approach for transcription – combine with OCR and intelligent sorting
• Beyond transcription…

Closing Remarks
• We need more data to do better crowdsourcing:– Raw (unreviewed) transcription data– Volunteer demographics– Motivation for initial and sustained user engagement – Experimental data on optimal UI configurations
• Produce more education and outreach materials to complement public engagement
• Recruiting & keeping developers is a challenge!
• Collaboration & partnerships are good but often result in compromises! (open source + modular helps but is £££)
• “Free” platforms still require community management to get best results

If you have any relevant information please share!
Anecdotal information, raw or processed transcription data welcome

Acknowledgements
• SYNTHESYS: JRA Objective 3 & NA3 Groups
• Smithsonian Institution: Meghan Ferriter & Michael Schall
• Other Contributors: Simon Chagnoux, Libby Ellwood, Paul Flemons, Tom Humphrey and Deborah Paul
• NHM: Celena Bretton, Tim Conyers, Lucy Robinson , Ben Scott, Vince Smith, Ali Thomas


References
• Ellwood, E.R., B. Dunckel, P. Flemons, R. Guralnick, G. Nelson, G. Newman, S. Newman, D. Paul, G. Riccardi, N. Rios, K. C. Seltmann and A. R. Mast. (2015). Accelerating digitization of biodiversity research specimens through online public participation. BioScience. doi: 10.1093/biosci/biv005

Developing Specifications
• It’s a support tool but also a service• Some of the existing platforms with undoubtedly work for you• We will have a developer in post sometime in October• High level ideas for the NHM• Other museums are not just about Natural History- we have
other needs sogood to get feedback• Project jhas a look of stackholders in SYNTHESYS but we are
also aiming at other institutions in the UK and Europe• Want to develop our role as a virtual hub for Citizen Science• Want to use this sesison partial for requirements gathering
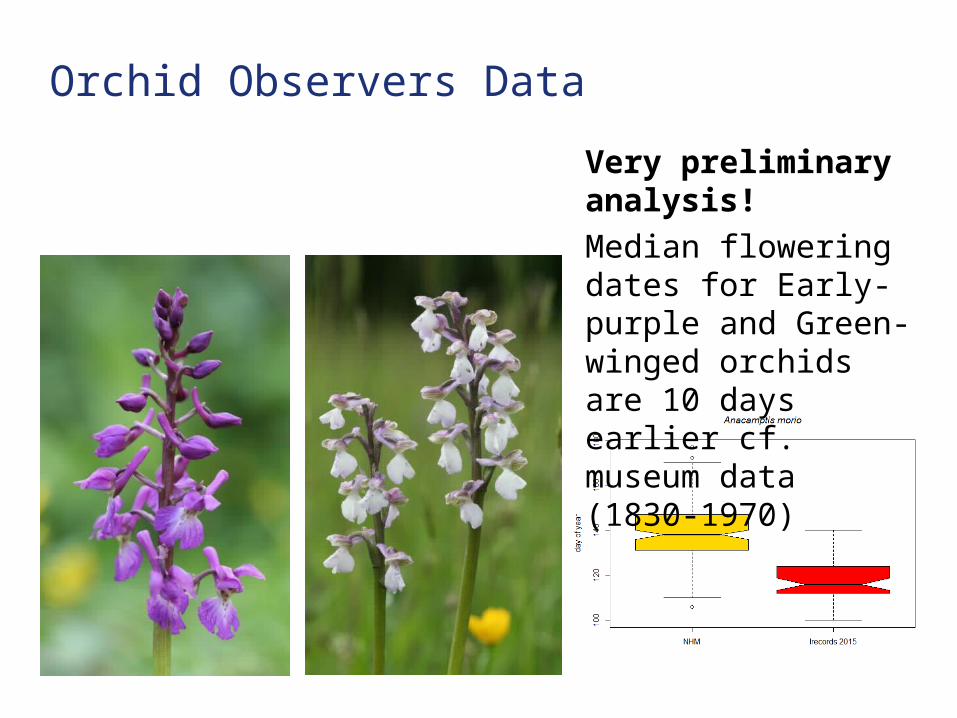
Orchid Observers Data
Very preliminary analysis!Median flowering dates for Early-purple and Green-winged orchids are 10 days earlier cf. museum data (1830-1970)
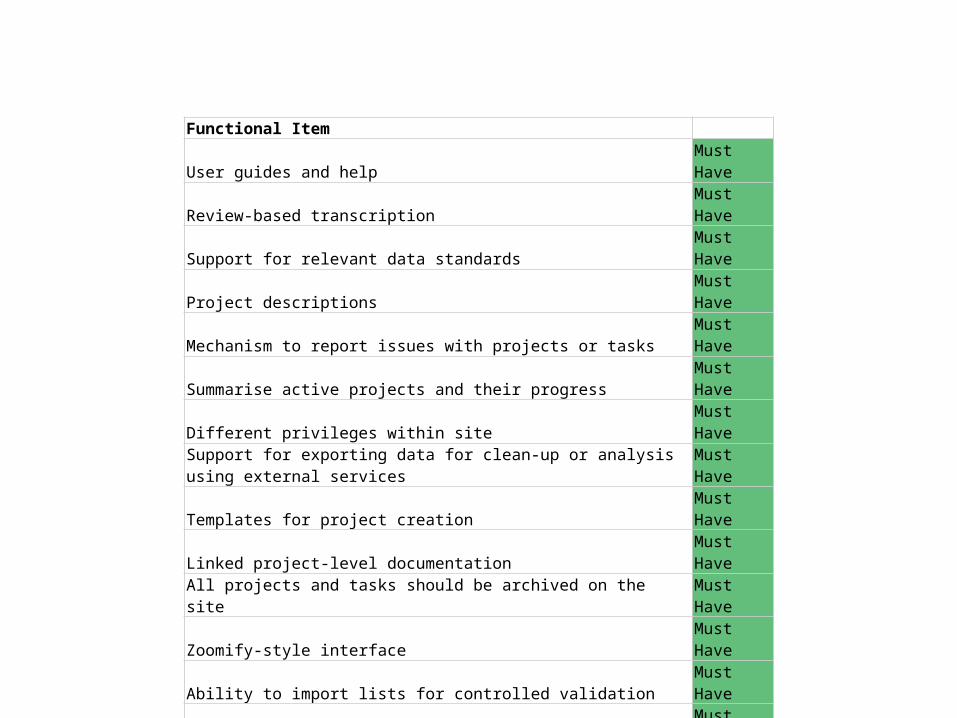
Functional ItemUser guides and help Must HaveReview-based transcription Must HaveSupport for relevant data standards Must HaveProject descriptions Must HaveMechanism to report issues with projects or tasks Must HaveSummarise active projects and their progress Must HaveDifferent privileges within site Must HaveSupport for exporting data for clean-up or analysis using external services Must HaveTemplates for project creation Must HaveLinked project-level documentation Must HaveAll projects and tasks should be archived on the site Must HaveZoomify-style interface Must HaveAbility to import lists for controlled validation Must HaveAbility to map and export data in different formats Must HaveHover-over help Must HaveTools for analysing and assessing the quality of user contributions Must HaveInteractive examples/tutorials Must HaveAbility to edit "live" projects Must HaveAbility to create custom data export templates Must HaveStandard field types and basic validation Must HavePermission-based administration Must HaveProject progress bars Must HaveTop users Must HaveSupport for maps to display georeferenced data Must Have

Custom fields for data entry Should HaveAbility for users to filter projects and tasks within projects based on their areas of interest Should HaveA georeferencing tool that allows users to generate coordinates from locality information Should HaveAn annotation tool that includes determinations to capture data from more expert users Should HaveNew/featured project section Should HaveAbility for users to ask general questions about projects Should HaveUser notifications Should HaveAbility for users to request help from a dedicated community member or project experts Should HaveDynamic lists Should HaveAbility to host and run multiple crowdsourcing projects at one time Should HaveLinks to content and project outputs Should HaveControl hub for users Should HaveMultikeying/multi-pass transcription Should HaveNews feed to display updates Should HaveReporting tools Should HaveLocalisation support Should HaveAbility to contact all project volunteers Should HaveAbility for users to submit or query records for discussion Should HaveSimple content management Should HaveLinks to information to help with tasks (e.g. BHL, taxonomic catalogues, community created content) Should HavePotential to develop mobile/tablet based apps using API Should HaveFlexible theming Should HaveA modular structure to support different task types Should HaveSupport for organisations/institutes to use single sign on technology for internal users Should HaveBuilt-in read/write API that is used by platform as primary means for delivering and creating content (e.g. dogfooding paradigm) Should HaveSupport for Google Analytics Should HaveSupport for public/community responses to tasks and discussions Should HaveSimple site-wide user statistics Should Have
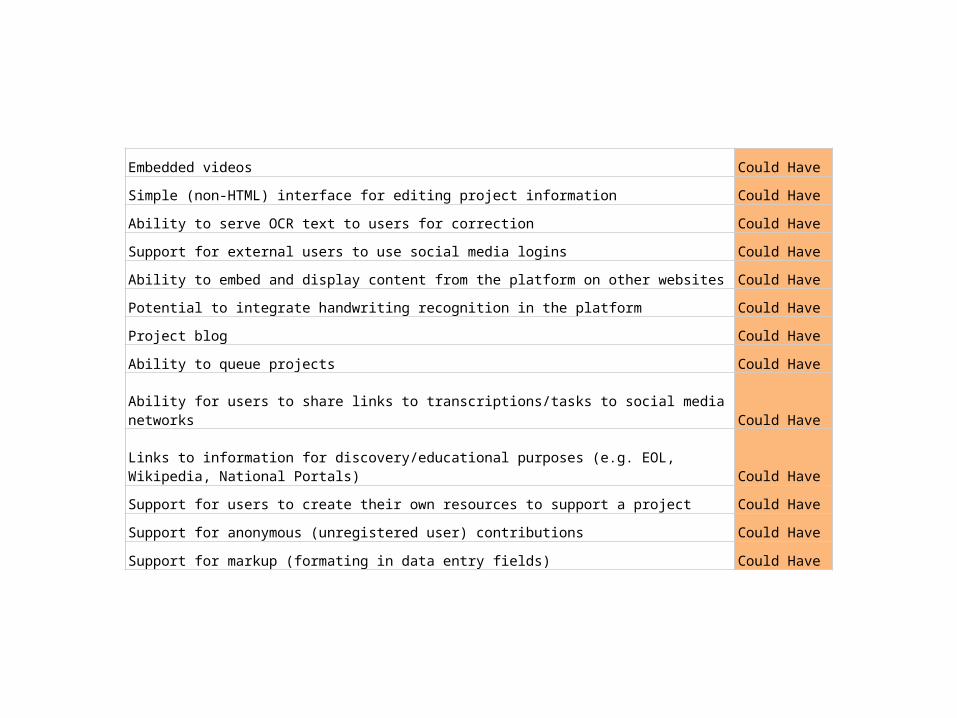
Embedded videos Could Have
Simple (non-HTML) interface for editing project information Could Have
Ability to serve OCR text to users for correction Could Have
Support for external users to use social media logins Could Have
Ability to embed and display content from the platform on other websites Could Have
Potential to integrate handwriting recognition in the platform Could Have
Project blog Could Have
Ability to queue projects Could Have
Ability for users to share links to transcriptions/tasks to social media networks Could Have
Links to information for discovery/educational purposes (e.g. EOL, Wikipedia, National Portals) Could Have
Support for users to create their own resources to support a project Could Have
Support for anonymous (unregistered user) contributions Could Have
Support for markup (formating in data entry fields) Could Have





























