Embed Size (px)
Citation preview

Analysis of sentiment Analysis of sentiment syntagma using syntagma using
dependency tree dependency tree
Serge B. PotemkinMoscow State University

TermsTerms
Sentiment◦A thought, view, or attitude, especially one based mainly on emotion instead of reason
Sentiment Analysis (opinion mining)◦ use of natural language processing (NLP) and computational techniques for extraction or classification of sentiment from (unstructured) text

What for?What for?
Consumer information◦ Product reviews◦ Consumer attitudes◦ Trends
Politics◦ Politicians want to know voters’ views◦ Voters want to know policitians’ intentions and who else
supports themSocial
Find like-minded individuals or communitiesFinancial
Predict market trends given the current opinions

Features Features
Which features to use?◦Words (unigrams)◦Phrases/n-grams ◦Sentences
How to interpret features for sentiment detection?◦Bag of words ◦ Annotated lexicons (WordNet, SentiWordNet)◦Syntactic patterns◦Paragraph structure

ChallengesChallenges
Harder than topical classification, with which bag of words features perform well
Must consider other features due to…◦Ambiguity of sentiment expression
irony expression of sentiment using neutral words … many others
◦Domain/context dependence words/phrases can mean different things in
different contexts and domains◦Effect of syntax on semantics

Formal descriptionFormal description
Semantic orientation of a sentence expressed by a ternary predicate:
O(subject, object, sentiment) sentiment = {bad, neutral, good}
◦i.e.,◦ the subject of assessment considers the object of assessment to be good or bad (or neutral = not a sentiment)

Sentiment expression in NLSentiment expression in NL
Predicate O may be expressed explicitly: (Vania likes Masha) -
only the surface syntactic analysis is needed:
Vania (subj) likes (sentiment) Masha (obj)to determine its semantic orientation (SO).The common case is quite different:
(Vania suffers from Masha’s absence) – both suffer and absence are negative but the sense is equivalent.

Bag of words vs. syntagma an.Bag of words vs. syntagma an.
Bag of words (number of positive and negative words) gives good results for large texts
Syntagma = a phrase forming a syntactic unit, say modifier (X) + keyword (Y)i.e. adjective+noun or adverb+verb
Signature of syntagma SO = sgn(X,Y,neg/0/pos).

SO Calculus SO Calculus
X,Y.[sgn(X,Y,pos) dep(mod,X,Y),sgn(X,pos),sgn(Y,pos)].(a)
i.e. if X,Y positive then X+Y positive X,Y,Z.[sgn(X,Y,Z)
dep(mod,X,Y),sgn(X,0),sgn(Y,Z)]. (b)i.e. if X pos., Y neut. then X+Y pos. X,Y,Z.[sgn(X,Y,Z)
dep(mod,X,Y),sgn(X,Z),sgn(Y,0)]. (c)

Different orientation of syntagma Different orientation of syntagma constituent wordsconstituent words
sgn(безумная,радость,pos)=sgn(mad,happyness,pos), sgn(бешеный,успех,pos)=sgn(furious,success,pos),
sgn(солидный,ущерб,neg)=sgn(considerable,damage,neg), sgn(хороший,нагоняй,neg)=sgn(good,scolding,neg).
[Kustova, 1]

Ambigoues cases Ambigoues cases
sgn(худой,мир,?), sgn(добрая,война,?) sgn (bad,peace,?), sgn (good,war,?) The expression "a bad peace is better
than a good war," establishes an order relation "better" among its member attributive constructions, but one can assume that both are bad, i.e., sgn sgn(bad,peace,neg), sgn(good,war,neg). In some other context, "good war" could be perceived as a positive phenomenon.

Double negative Double negative
Logical rule of double negation : * X,Y,Z.[sgn(X,Y,pos)
dep(mod,X,Y),sgn(X,neg),sgn(Y,neg)].fails in NL: weak opponent, impotent aggressor,
toothless criticism (neut.)orbitter sorrow, blatant outrage, brutal torture
(neg.)

Syntagma evaluationSyntagma evaluation
Methods:expert evaluations performed by several
independent experts [Osgood,2], who are asked to mark up SO of isolated words and syntagma, assigning them a label {pos/0/neg}
corpus techniques, performed on an sentiment-annotated corpus [Zagibalov,3],
SentiWordNet

SentiWordNetSentiWordNet
Based on WordNet “synsets”◦http://wordnet.princeton.edu/
Ternary classifier◦Positive, negative, and neutral scores for each
synsetProvides means of gauging sentiment for
a text

SentiWordNet: ConstructionSentiWordNet: Construction
Created training sets of synsets, Lp and Ln◦Start with small number of synsets with
fundamentally positive or negative semantics, e.g., “nice” and “nasty”
◦Use WordNet relations, e.g., direct antonymy, similarity, derived-from, to expand Lp and Ln over K iterations
◦Lo (objective) is set of synsets not in Lp or LnTrained classifiers on training set
◦Rocchio and SVM◦Use four values of K to create eight classifiers
with different precision/recall characteristics◦As K increases, P decreases and R increases

SentiWordNet: ResultsSentiWordNet: Results
24.6% synsets with Objective<1.0 ◦Many terms are classified with some degree of
subjectivity10.45% with Objective<=0.50.56% with Objective<=0.125
◦Only a few terms are classified as definitively subjective
Difficult (if not impossible) to accurately assess performance

Corpus-based methodCorpus-based method
Sentiment annotated corpora (English and Russian) of approx. 1500 short utterances concerning popular books. Each utterance contains from 1 to 15 sentences and was marked with a label {neg / pos}.

Corpus processingCorpus processing
- Stemming and determination of morphological characters of each word (without morphology disambiguation);
- Parse with obtaining the dependency tree for each sentence [Potemkin, 4];
- Joining the particle "no/not" to the associated word (not understand => not_understand)
- Selection of constructions modifier+key word (adjective+noun, adverb+verb);
- Counting the number of occurrences for each key word = nverb,

Corpus processing (continued)Corpus processing (continued)
- Counting the number of occurrences in the positive-marked utterances = nvp and negatively labeled utterances = nvn
- Calculation of the normalized assessment factor for each key word kv = (nvp-nvn) / nverb;
- The same calculations for each modifier to give the normalized assessment factor kd, and for each syntagma in the corpus - the normalized assessment factor ks.

Assessment thresholds Assessment thresholds
Assessment factors ks [-1,1], ks [-1, -0.6) = neg;
ks [-0.6, 0.6] = 0; ks (0.6, 1] = pos

Table of syntagma signaturesTable of syntagma signatures
neg -key 0 -key pos -key
neg -mod neg not_palatable demagogypos –defeated enemy
neg uninteresting book pos forgotten kingdoms
neg banal action-filmpos secondery pleasure
0 -mod neg star fever;pos imminent defeat;
neg unexpected level.pos only book.
neg. late successpos continues growth
pos -mod neg happy endpos fine rubbish
neg good intentionspos pleasant book
neg sweet honeypos best masterpiece
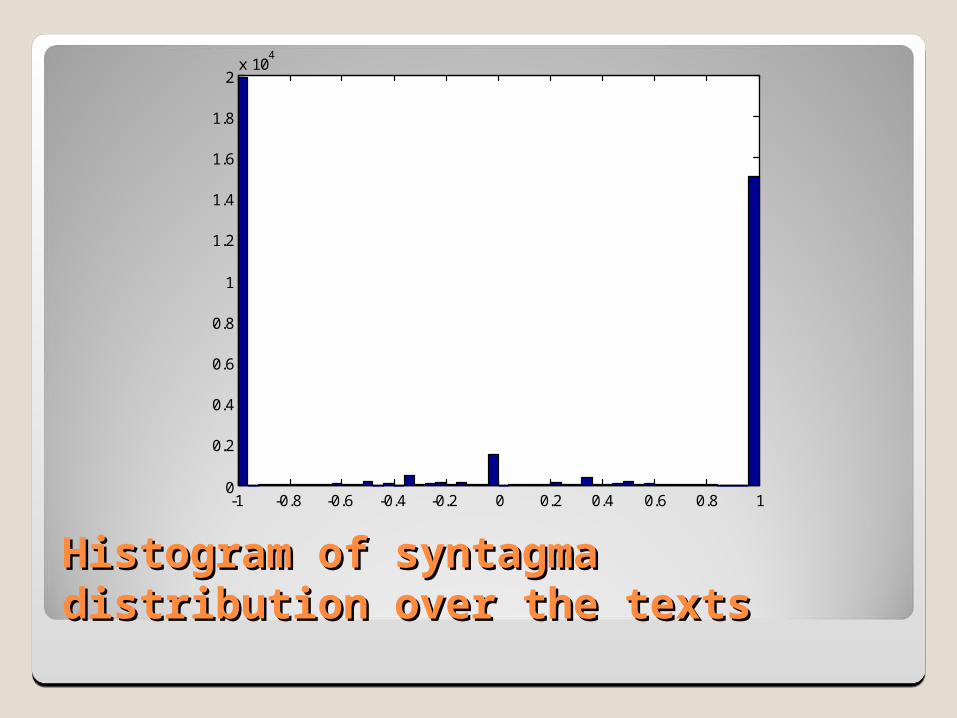
Histogram of syntagma Histogram of syntagma distribution over the texts distribution over the texts
-1 -0.8 -0.6 -0.4 -0.2 0 0.2 0.4 0.6 0.8 10
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2x 10
4

Histogram of the 1Histogram of the 1stst word of word of syntagma distribution syntagma distribution
-1 -0.8 -0.6 -0.4 -0.2 0 0.2 0.4 0.6 0.8 10
1000
2000
3000
4000
5000
6000
7000
8000
9000
10000

Histogram of the 2Histogram of the 2ndnd word of word of syntagma distribution syntagma distribution
-1 -0.8 -0.6 -0.4 -0.2 0 0.2 0.4 0.6 0.8 10
1000
2000
3000
4000
5000
6000

ConclusionConclusion
The report presents considerations for determining the sentiment of syntagma on the basis of evaluation of the signature of its constituent words for structures such as adjective+noun, verb+adverb.
Logical formulas specifying the calculation of semantic orientations are listed.
An experiment over the semantically annotated sentences was performed.
The further research concerning predictive syntagma of type subject + verb + object will be undertaken.
ReferencesReferences
http://dict.ruslang.ru/magn.phpCharles E. Osgood, George Suci, & Percy
Tannenbaum, The Measurement of Meaning. University of Illinois Press, 1957.
http://www.informatics.sussex.ac.uk/users/tz21/http://sunsite.informatik.rwth-aachen.de/Publicati
ons/CEUR-WS/Vol-476/paper6.pdf





























