Embed Size (px)
Citation preview

© 2015 IBM Corporation
Tutorial: Programação paralela híbrida com MPI e
OpenMPuma abordagem prática
Tutorial: Programação paralela híbrida com MPI e
OpenMPuma abordagem prática
Eduardo [email protected]
3°. Workshop de High Performance Computing – Convênio: USP – Rice University

IBM Research
IBM Research
Brazil Lab research areasIndustrial Technology and ScienceSystems of Engagement and InsightSocial Data AnalyticsNatural Resource Solutions
https://jobs3.netmedia1.com/cp/faces/job_summary?job_id=RES-0689175 https://jobs3.netmedia1.com/cp/faces/job_search

IBM Research
Legal stuff
● This presentation represents the views of the author and does not necessarily represent the views of IBM.
● Company, product and service names may be trademarks or service marks of others.

IBM Research
Agenda
● MPI and OpenMP– Motivation
– Basic functions / directives
– Hybrid usage
– Performance examples
● AMPI – load balancing

IBM Research
Parallel Programming Modelsfork-join Message passing
Power8https://en.wikipedia.org/wiki/Computer_cluster#/media/File:Beowulf.jpg

IBM Research
Motivation
shared memory
fast network interconnection
Hybrid-model
Why MPI / OpenMP?They are open standard.
Current HPC architectures

IBM Research
MPI 101
● Message Passing Interface – share nothing model;
● The most basic functions:
– MPI_Init, MPI_Finalize, MPI_Comm_rank, MPI_Comm_size, MPI_Send, MPI_Recv
#include <mpi.h>#include <stdio.h>
int main(int argc, char** argv) { int rank, size; int rbuff, sbuff; MPI_Status status;
MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &rank); MPI_Comm_size(MPI_COMM_WORLD, &size);
sbuff = rank;
MPI_Send(&sbuff, 1, MPI_INT, (rank+1) % size, 1, MPI_COMM_WORLD); MPI_Recv(&rbuff, 1, MPI_INT, (rank+size-1) % size, 1, MPI_COMM_WORLD, &status);
printf("rank %d - rbuff %d\n", rank, rbuff);
MPI_Finalize(); return 0;}
$ mpirun -np 4 ./a.out rank 0 - rbuff 3rank 2 - rbuff 1rank 1 - rbuff 0rank 3 - rbuff 2
Output:
● Over 500 functions, but why?

IBM Research
Send/Recv flavors (1)● MPI_Send, MPI_Recv
● MPI_Isend, MPI_Irecv
● MPI_Bsend
● MPI_Ssend
● MPI_Rsend

IBM Research
Send/Recv flavors (2)● MPI_Send - Basic blocking send operation. Routine returns only after the application
buffer in the sending task is free for reuse.● MPI_Recv - Receive a message and block until the requested data is available in the
application buffer in the receiving task.● MPI_Ssend - Synchronous blocking send: Send a message and block until the
application buffer in the sending task is free for reuse and the destination process has started to receive the message.
● MPI_Bsend - Buffered blocking send: permits the programmer to allocate the required amount of buffer space into which data can be copied until it is delivered. Insulates against the problems associated with insufficient system buffer space.
● MPI_Rsend - Blocking ready send. Should only be used if the programmer is certain that the matching receive has already been posted.
● MPI_Isend, MPI_Irecv - nonblocking send / recv
● MPI_Wait● MPI_Probe

IBM Research
Collective communication

IBM Research
Collective communicationhow MPI_Bast works

IBM Research
Collective communicationhow MPI_All_Reduce
Peter Pacheco, Introduction to Parallel Programming

IBM Research
(Some) New features
● Process creation (MPI_Comm_spawn);● MPI I/O (HDF5);● Non-blocking collectives;● One-sided communication

IBM Research
One-sided communicationActive target
MPI_Alloc_mem(sizeof(int)*size, MPI_INFO_NULL, &a); MPI_Alloc_mem(sizeof(int)*size, MPI_INFO_NULL, &b);
MPI_Win_create(a, size, sizeof(int), MPI_INFO_NULL, MPI_COMM_WORLD, &win);
for (i = 0; i < size; i++) a[i] = rank * 100 + i;
printf("Process %d has the following:", rank);
for (i = 0; i < size; i++) printf(" %d", a[i]); printf("\n");
MPI_Win_fence((MPI_MODE_NOPUT | MPI_MODE_NOPRECEDE), win);
for (i = 0; i < size; i++) MPI_Get(&b[i], 1, MPI_INT, i, rank, 1, MPI_INT, win);
MPI_Win_fence(MPI_MODE_NOSUCCEED, win);
printf("Process %d obtained the following:", rank); for (i = 0; i < size; i++) printf(" %d", b[i]); printf("\n");
MPI_Win_free(&win);

IBM Research
Level of Thread Support
● MPI_THREAD_SINGLE - Level 0: Only one thread will execute.● MPI_THREAD_FUNNELED - Level 1: The process may be multi-threaded, but only
the main thread will make MPI calls - all MPI calls are funneled to the main thread.● MPI_THREAD_SERIALIZED - Level 2: The process may be multi-threaded, and
multiple threads may make MPI calls, but only one at a time. That is, calls are not made concurrently from two distinct threads as all MPI calls are serialized.
● MPI_THREAD_MULTIPLE - Level 3: Multiple threads may call MPI with no restrictions.
int MPI_Init_thread(int *argc, char *((*argv)[]),
int required, int *provided)
IBM Research
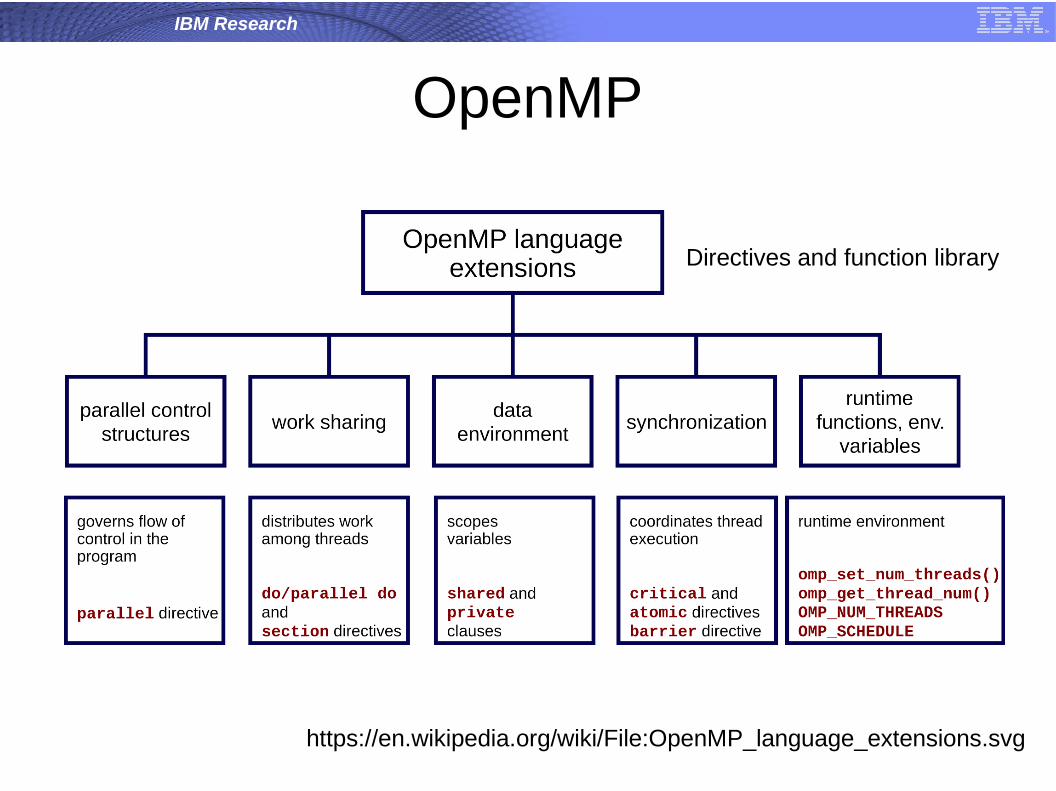
OpenMP
https://en.wikipedia.org/wiki/File:OpenMP_language_extensions.svg
Directives and function library

IBM Research
OpenMP 101#include <omp.h>#include <stdio.h>
int main() { printf("sequential A\n"); #pragma omp parallel num_threads(3) { int id = omp_get_thread_num(); printf("parallel %d\n", id); } printf("sequential B\n");}
Points to keep in mind:- OpenMP uses shared memory for communication (and synchronization);
- race condition may occur – the user is responsible to synchronize access and avoid data conflicts;
- synchronization is expensive and should be avoided;
LOCAL

IBM Research
OpenMP internals
#include <omp.h>#include <stdio.h>
int main() { printf("sequential A\n"); #pragma omp parallel num_threads(3) { int id = omp_get_thread_num(); printf("parallel %d\n", id); } printf("sequential B\n");}
.LC0: .string "sequential A" .align 3.LC1: .string "sequential B
(...) addis 3,2,.LC0@toc@ha addi 3,3,.LC0@toc@l bl puts nop addis 3,2,main._omp_fn.0@toc@ha addi 3,3,main._omp_fn.0@toc@l li 4,0 li 5,5 bl GOMP_parallel_start nop li 3,0 bl main._omp_fn.0 bl GOMP_parallel_end nop addis 3,2,.LC1@toc@ha addi 3,3,.LC1@toc@l bl puts
(...)
main._omp_fn.0:(…)
bl printf(...)
libgomp

IBM Research
OpenMP Internals
Tim Mattson, Intel

IBM Research
OpenMP 101
● Parallel loops● Data environment● Synchronization● Reductions
#include <omp.h>#include <stdio.h>
#define SX 4#define SY 4
int main() { int mat[SX][SY]; omp_set_nested(1); printf(">>> %d\n", omp_get_nested()); #pragma omp parallel for num_threads(2) for (int i = 0; i < SX; i++) { int outerId = omp_get_thread_num(); #pragma omp parallel for num_threads(2) for (int j = 0; j < SY; j++) { int innerId = omp_get_thread_num(); mat[i][j] = (outerId+1)*100 + innerId; } } for (int i = 0; i < SX; i++) { for (int j = 0; j < SX; j++) { printf("%d ", mat[i][j]); } printf("\n"); }}

IBM Research
Power8
IBM Journal of Research and Development,Issue 1 • Date Jan.-Feb. 2015
IBM Research
Power8

IBM Research
Powe8 performance evaluation

IBM Research
Performance examples: a word of caution
● Hybrid programming not always good;● Some examples:
– NAS-NBP;
– Ocean-Land-Atmosphere Model (OLAM);
– Weather Research and Forecasting Model (WRF);

IBM Research
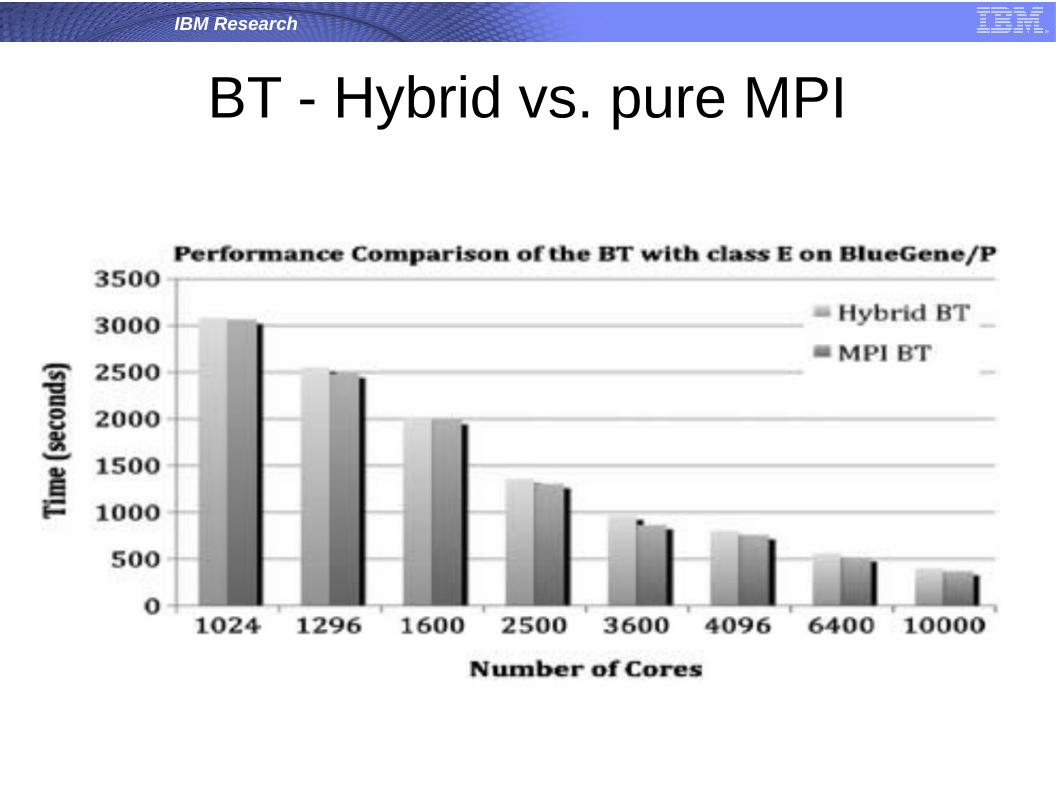
NAS-NPB
● Scalar Pentadiagonal (SP) and Block Tridiagonal (BT) benchmarks
● Intrepid (BlueGene/P) at Argonne National Laboratory
Xingfu Wu, Valerie Taylor, Performance Characteristics of HybridMPI/OpenMP Implementations of NAS Parallel Benchmarks SP and BT on Large-Scale Multicore Clusters, The Computer Journal, 2012.

IBM Research
SP - Hybrid vs. pure MPI
IBM Research
BT - Hybrid vs. pure MPI

IBM Research
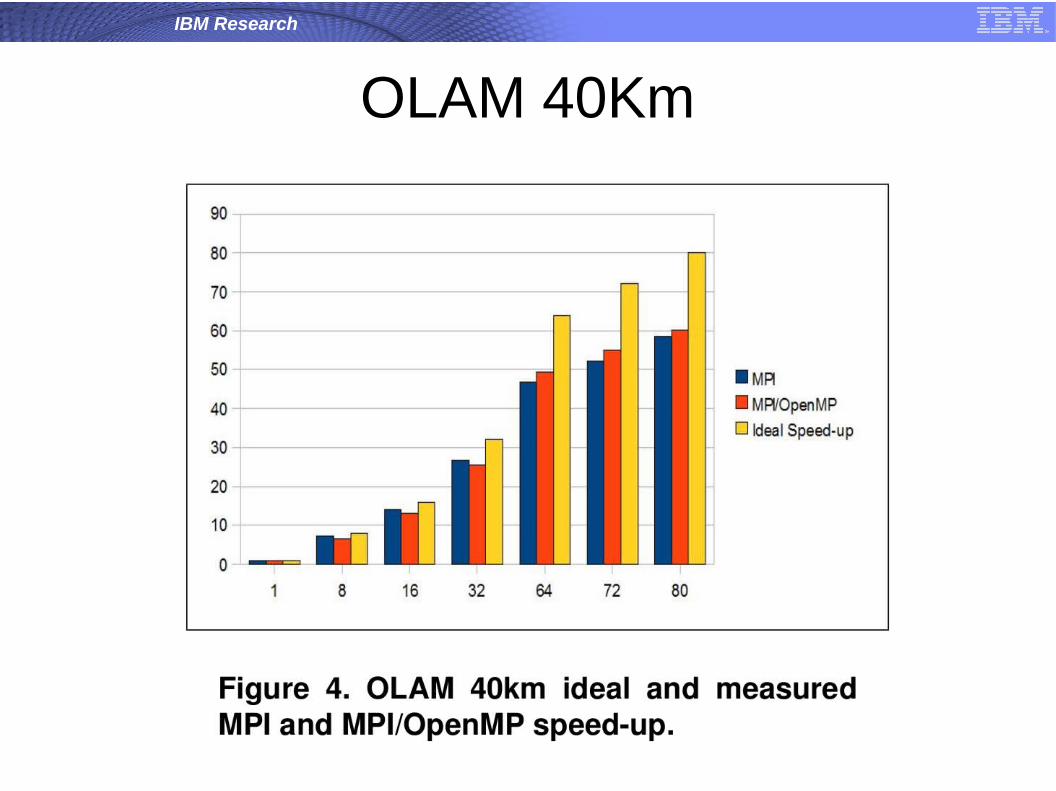
OLAM
● Global grid that can be locally refined;
● This feature allows simultaneous representation (and forecasting) of both the global scale and the local scale phenomena, as well as bi-directional interactions between scales
Carla Osthoff et al, Improving Performance on Atmospheric Models through a Hybrid OpenMP/MPI Implementation, 9th IEEE International Symposium on Parallel and Distributed Processing with Applications, 2011.

IBM Research
OLAM 200Km
IBM Research
OLAM 40Km

IBM Research
OLAM 40Km with Physics

IBM Research
WRF
Don Morton, et al, Pushing WRF To Its Computational Limits, Presentation at Alaska Weather Symposium, 2010.

IBM Research
WRF

IBM Research
WRF

IBM Research
Motivação para o AMPI
● MPI é um padrão de fato para programação paralela● Porém, aplicações modernas podem ter:
– distribuição de carga pelos processadores variável ao longo da simulação;
– refinamentos adaptativos de grades;– múltiplos módulos relativos a diferentes componentes físicos
combinados na mesma simulação;– exigências do algoritmo quanto ao número de
processadores a serem utilizados.
● Várias destas características nao combinam bem com implementações convencionais de MPI

IBM Research
Alternativa: Adaptive MPI
● Adaptive MPI (AMPI) é uma implementação do padrão
MPI baseada em Charm++● Com AMPI, é possível utilizar aplicações MPI
jáexistentes, através de poucas modificações no código original
● AMPI está disponível e é portável para diversas arquiteturas.

IBM Research
Adaptive MPI: Princípios Gerais
● Em AMPI, cada tarefa MPI é embutida em um objeto (elemento de vetor, ou thread de usuário) Charm++
● Como todo objeto Charm++, as tarefas AMPI (threads) são migráveis entre processadores

IBM Research
Adaptive MPI e Virtualização
● Benefícios da virtualização:
– Sobreposição automática entre computação e comunicação
– Melhor uso de cache
– Flexibilidade para se fazer balanceamento de carga

IBM Research
Exemplo

IBM Research
Balanceadores Disponíveis no Charm++
IBM Research
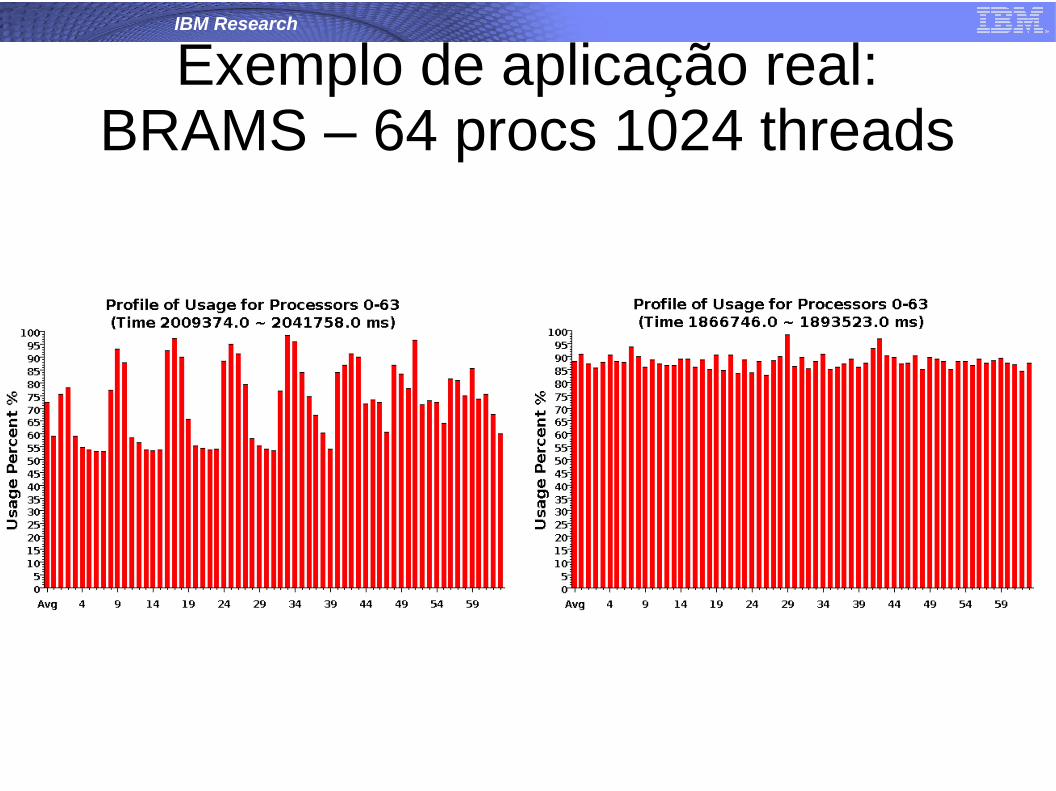
Exemplo de aplicação real:BRAMS – 64 procs 1024 threads

IBM Research
Final remarks
● MPI / OpenMP hybrid– Probably the most popular hybrid programming
technologies/standard;
– Suitable for current architectures;
– May not produce the best performance though;
● OpenPower– Lots of cores and even more threads (lots of fun :-)
● Load balancing may be an issue,– AMPI is an adaptive alternative for the vanilla MPI





























