Embed Size (px)
Citation preview

C O M P U T E | S T O R E | A N A L Y Z E
Apache Jena Elephas and Friends
RDF and the Hadoop Ecosystem
Rob Vesse
Twitter: @RobVesse
Email: [email protected]

C O M P U T E | S T O R E | A N A L Y Z E
About Me
● Software Engineer at Cray Inc● Working on:
● RDF and SPARQL
● Big Data Analytics
● Active open source contributor● Apache Jena
● dotNetRDF
● Minor contributions to other Apache projects
● Assorted other bits and pieces on my GitHub and BitBucket
● Primarily interested in intersection of RDF/SPARQL world with rest of Big Data world

C O M P U T E | S T O R E | A N A L Y Z E
Talk Overview
● What's missing in the Hadoop ecosystem?
● What's already available?● Apache Jena Elephas
● Intel Graph Builder
● Other interesting projects
● Getting Involved
● Questions

C O M P U T E | S T O R E | A N A L Y Z E
What's missing in the Hadoop ecosystem?

Apache, the projects and their logo shown here are registered trademarks or trademarks of The Apache Software Foundation in the U.S. and/or other countries

C O M P U T E | S T O R E | A N A L Y Z E
Where's RDF?
● No first class projects
● Some very limited support in other projects● Giraph can support RDF by bridging through the Tinkerpop 2
stack
● Few existing projects● Mostly academic proofs of concept (POC)
● Some open source efforts but often task specific● e.g. Infovore targeted at creating curated Freebase and DBPedia
datasets

C O M P U T E | S T O R E | A N A L Y Z E
What's needed for RDF?
● Minimum Viable Product● Standard Writable implementations for primitives
● Input and Output support
● Would be nice to have:● Tools for translating data to and from RDF
● Integration with the common analytic frameworks● e.g. Spark, Giraph, Hive, Pig

C O M P U T E | S T O R E | A N A L Y Z E
What's already available?

C O M P U T E | S T O R E | A N A L Y Z E
Apache Jena Elephas - Background
● Started as a POC at Cray
● Donated to the Apache Jena project 1st April 2014● JENA-666
● Originally known as Hadoop RDF Tools
● Renamed to Elephas in December 2014● Name was suggested by
Claude Warren

C O M P U T E | S T O R E | A N A L Y Z E
Apache Jena Elephas - What is it?
● Set of modules part of the Apache Jena project
● Currently only developer SNAPSHOT builds available● Will be included as part of upcoming Jena 2.13.0 release
● Aims to fulfill all the basic requirements for enabling RDF on Hadoop
● Built against Hadoop 2.x APIs

C O M P U T E | S T O R E | A N A L Y Z E
Apache Jena Elephas - How do I use it?
● Read the documentation● http://jena.apache.org/documentation/hadoop/
● Add appropriate Maven dependencies to your code● http://jena.apache.org/documentation/hadoop/artifacts.html
● Will also need to declare relevant Hadoop dependencies as "provided"
● Use the APIs as-is for basic tasks or use as starting point for more complex applications

C O M P U T E | S T O R E | A N A L Y Z E
Apache Jena Elephas - Common API
● Provides Writable types for the RDF primitives● NodeWritable● TripleWritable● QuadWritable● NodeTupleWritable
● An arbitrarily sized tuples of RDF terms
● Backed by RDF Thrift● A compact binary serialization for RDF using Apache Thrift
● See http://afs.github.io/rdf-thrift/
● Extremely efficient to serialize and de-serialize
● Allows for efficient WritableComparator implementations that perform comparisons directly on the binary forms

C O M P U T E | S T O R E | A N A L Y Z E
Apache Jena Elephas - IO API
● Provides Hadoop InputFormat and OutputFormatimplementations for RDF● Covers all RDF serializations Jena supports
● Easily extended with custom formats
● Splits and parallelizes processing of input where the RDF serialization allows it● Blank Nodes can be awkward
● Transparently handles compressed IO
C O M P U T E | S T O R E | A N A L Y Z E
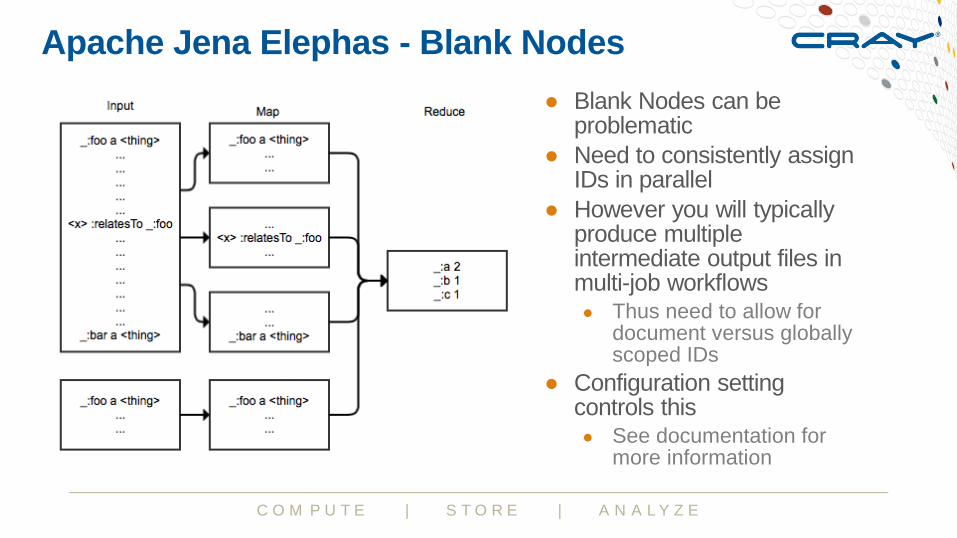
Apache Jena Elephas - Blank Nodes
● Blank Nodes can be problematic
● Need to consistently assign IDs in parallel
● However you will typically produce multiple intermediate output files in multi-job workflows● Thus need to allow for
document versus globally scoped IDs
● Configuration setting controls this● See documentation for
more information

C O M P U T E | S T O R E | A N A L Y Z E
Apache Jena Elephas - Map/Reduce API
● Various reusable basic Mapper and Reducer implementations
● Covers common tasks:● Counting
● Filtering
● Grouping
● Splitting
● Transformation
● Mostly intended for use as a starting point
● Some of these are bundled into a RDF stats demo application

C O M P U T E | S T O R E | A N A L Y Z E
Apache Jena Elephas - Example Job
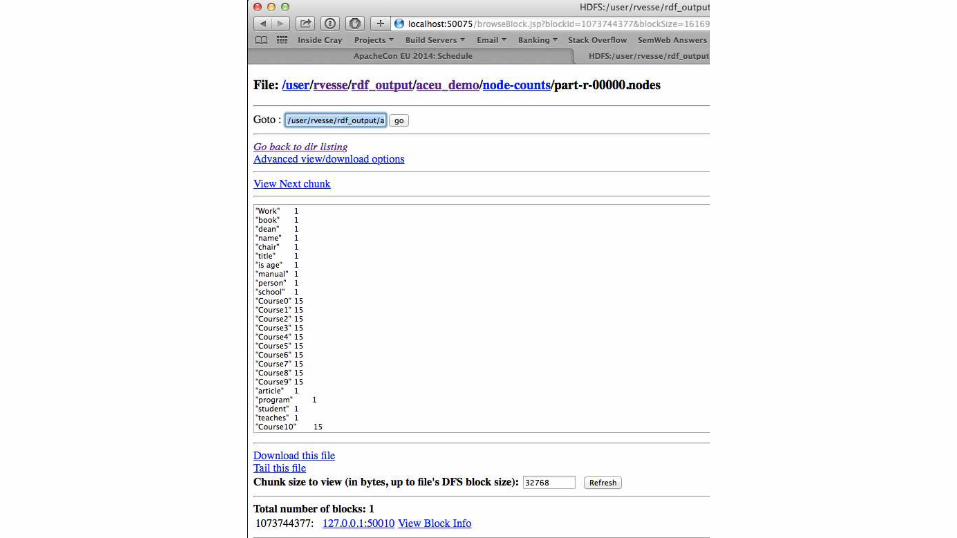
● Node Count (aka word count for RDF)
● All the classes referenced (bar Example.class) are provided by Elephas
Job job = Job.getInstance(config);job.setJarByClass(Example.class);job.setJobName("RDF Triples Node Usage Count");
// Map/Reduce classesjob.setMapperClass(TripleNodeCountMapper.class);job.setMapOutputKeyClass(NodeWritable.class);job.setMapOutputValueClass(LongWritable.class);job.setReducerClass(NodeCountReducer.class);
// Input and Outputjob.setInputFormatClass(NTriplesInputFormat.class);job.setOutputFormatClass(NTriplesNodeOutputFormat.class);FileInputFormat.setInputPath(job, new Path("/inputs/rdf"));FileOutputFormat.setOutputPath(job, new Path("/outputs/rdf"));

C O M P U T E | S T O R E | A N A L Y Z E
Apache Jena Elephas - Node Count Demo
See end of slide deck for steps to run the demo and screenshots

C O M P U T E | S T O R E | A N A L Y Z E
Apache Jena Elephas - Performance Notes
● For NTriples inputs we compared performance of a Text based node count versus RDF based node count
● Performance typically as good (within 10%) and sometimes significantly better● Heavily dataset dependent
● Varies considerably with cluster setup
● Also depends on how the input is processed
● Be aware YMMV!

C O M P U T E | S T O R E | A N A L Y Z E
Intel Graph Builder - What is it?
● Tools for transforming/creating large graphs
● Developed by Intel● Cray has some proposed improvements that are awaiting
merging at time of writing
● Open source under Apache License● https://github.com/01org/graphbuilder/tree/2.0.alpha
● 2.0.alpha is the preferred branch
● See https://github.com/cray/graphbuilder for the version discussed here
● Allows graphs to be created/transformed from arbitrary data sources using Apache Pig

C O M P U T E | S T O R E | A N A L Y Z E
Intel Graph Builder - How do I use it?
● REGISTER the Graph Builder JAR in your Pig script● May optionally want to IMPORT the pig/graphbuilder.pig
script which aliases some of the provided UDFs
● LOAD your data
● Use the provided UDFs to generate a graph● Can create both property graphs and RDF
● Currently data must be mapped to a property graph and then into RDF
● STORE the resulting graph

C O M P U T E | S T O R E | A N A L Y Z E
Intel Graph Builder - How it works?
● Uses a declarative mapping based on Pig primitives
● Has to be explicitly joined to the data● Limitation of Pig UDFs
● RDF mappings operate on property graphs● Must map data to a property graph first
● Direct mapping to RDF is a possible future enhancement

C O M P U T E | S T O R E | A N A L Y Z E
Intel Graph Builder - Pig Script Example
https://github.com/Cray/graphbuilder/blob/2.0.alpha/examples/property_graphs_and_rdf_example.pig
-- Rest of script omitted for brevity
-- Declare our mappingspropertyGraphWithMappings = FOREACH propertyGraph GENERATE (*, [ 'idBase' # 'http://example.org/instances/', 'base' # 'http://example.org/ontology/', 'namespaces' # [ 'foaf' # 'http://xmlns.com/foaf/0.1/' ],'propertyMap' # [ 'type' # 'a',
'name' # 'foaf:name', 'age' # 'foaf:age' ],
'uriProperties' # ( 'type' ),'idProperty' # 'id' ]);
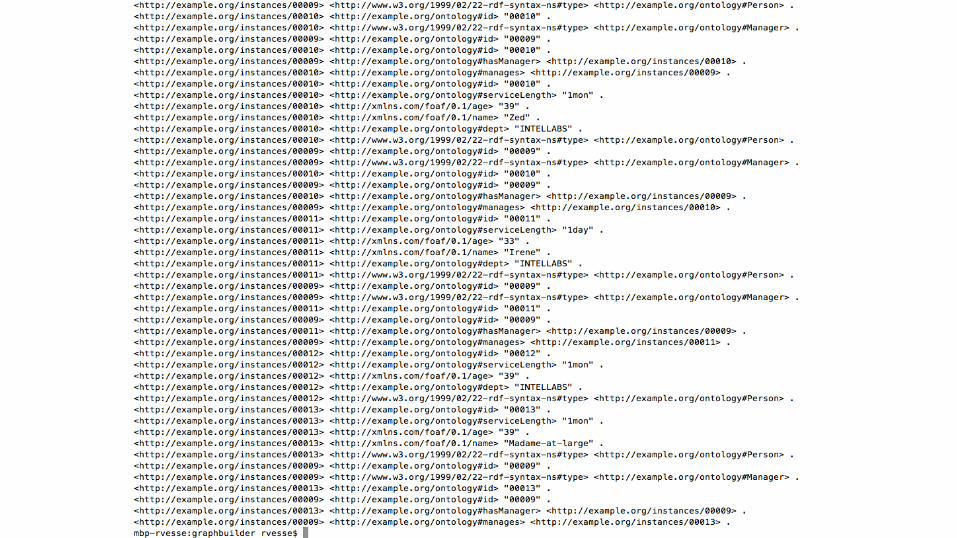
-- Convert to NTriplesrdf_triples = FOREACH propertyGraphWithMappings GENERATE FLATTEN(RDF(*));
-- Write out NTriplesSTORE rdf_triples INTO '/tmp/rdf_triples' USING PigStorage();

C O M P U T E | S T O R E | A N A L Y Z E
Intel Graph Builder - RDF Generation Demo
See end of slide deck for steps to run the demo and screenshots

C O M P U T E | S T O R E | A N A L Y Z E
Other Projects - Infovore
● Framework developed by Paul Houle
● Open source on GitHub● https://github.com/paulhoule/infovore/wiki
● Apache License 2.0
● Produces a cleaned and curated Freebase dataset using Hadoop for the processing● Designed to be easily self-deployed on Amazon EC2
● Also some related projects for working with Wikipedia● https://github.com/paulhoule/telepath
● Currently unclear what direction these projects will take after the Freebase shutdown at end of March this year

C O M P U T E | S T O R E | A N A L Y Z E
Other Projects - CumulusRDF
● Academic project from Institute of Applied Informatics and Formal Description Methods● https://code.google.com/p/cumulusrdf/
● RDF store backed by Apache Cassandra● Reasonable performance compared to native RDF stores
● See NoSQL Databases for RDF: An Empirical Evaluation● Philippe Cudre-Mauroux et al
● http://exascale.info/sites/default/files/nosqlrdf.pdf
● Reasonably active development

C O M P U T E | S T O R E | A N A L Y Z E
Getting Involved

C O M P U T E | S T O R E | A N A L Y Z E
How to contribute
● Please download and try out these projects
● Interact with the communities and developers involved● What works?
● What is broken?
● What is missing?
● How could the documentation be better?
● Contribute● Open source ultimately lives or dies with community
participation
● If there's a missing feature then suggest it
● Or better still contribute it yourself!

C O M P U T E | S T O R E | A N A L Y Z E
Questions?
Personal Email: [email protected]
Apache Jena User List: [email protected]
These slides will be posted to my SlideShare:
http://www.slideshare.net/RobVesse

C O M P U T E | S T O R E | A N A L Y Z E
Apache Jena Elephas - Node Count Demo

C O M P U T E | S T O R E | A N A L Y Z E
Environment Pre-requisites
● Hadoop 2.x cluster● Assumes hadoop command is on your PATH
● Download the latest JAR file● Or build youself from source
● jena-hadoop-rdf-stats-VERSION-hadoop-job.jar
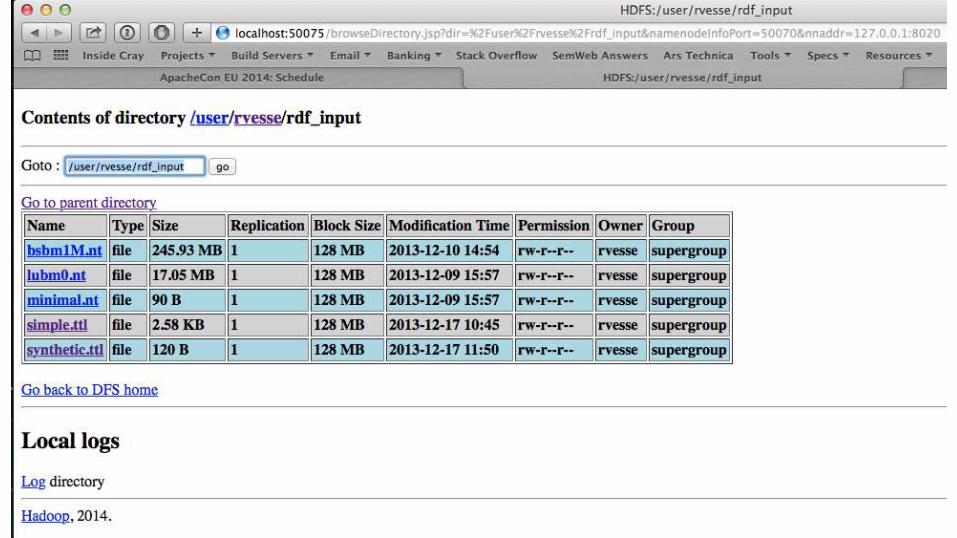
● Upload some RDF data to a HDFS folder

C O M P U T E | S T O R E | A N A L Y Z E
Run the Demo
● --node-count requests the Node Count statistics be calculated
● Assumes mixed quads and triples input if no --input-type specified
● Using this for triples only data can skew statistics
● e.g. can result in high node counts for default graph node
● Hence we explicitly specify input as triples
> hadoop jar jena-hadoop-rdf-stats-0.9.0-SNAPSHOT-hadoop-job.jar org.apache.jena.hadoop.rdf.stats.RdfStats --node-count --output /user/output --input-type triples /user/input

C O M P U T E | S T O R E | A N A L Y Z E
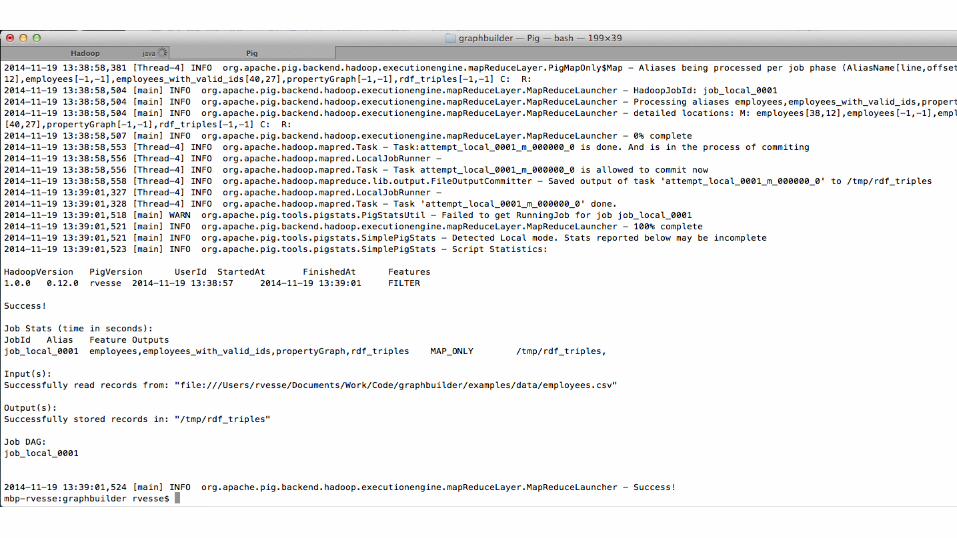
Intel Graph Builder - RDF Generation Demo

C O M P U T E | S T O R E | A N A L Y Z E
Environment Pre-requisites
● Pig 0.12● Should work with higher but not tested
● Assumes pig command is on your PATH
● Clone the Cray version of the Graph Builder code● https://github.com/cray/graphbuilder

C O M P U T E | S T O R E | A N A L Y Z E
Run the Demo
● Running Pig in local mode for simplicity
● Output goes to /tmp/rdf_triples/
> pig -x local examples/property_graphs_and_rdf.pig
> cat /tmp/rdf_triples/part-m-00000