Embed Size (px)
Citation preview

Vigneshvar.A.SDEPUTY MANAGER CLOUDRELIANCE JIO INFOCOMM
BANGALORE
Nova Scheduler

Contents
• An introduction to nova scheduler
• Various Scheduling Options
• How does instance gets scheduled
• Filters and Weights
• Host Aggregates
• Scheduler performance on Scale
• How do we solve it
• Big Boom – The Gantt
Nova SchedulerAn Introduction
The nova-scheduler process is
“conceptually” the simplest
piece of code in Nova.
It simply takes a virtual
machine instance request from
the queue and determines
where it should run it.
Various Scheduling options in Nova
Simple Random
Zone

So how exactly instance gets scheduled ?

On Compute Node
● There is a periodic task (Resource Tracker), which collects
host information.
● This information is then stored to DB
On Controller Node
● Request from nova API reaches conductor
● Conductor interacts with the scheduler.
● Scheduler uses filters to identify the best node from the
information stored in DB
● Selected host information is sent back to conductor.
● Now conductor uses the compute queue and directs it to
the selected host
● The compute node then launches the instance
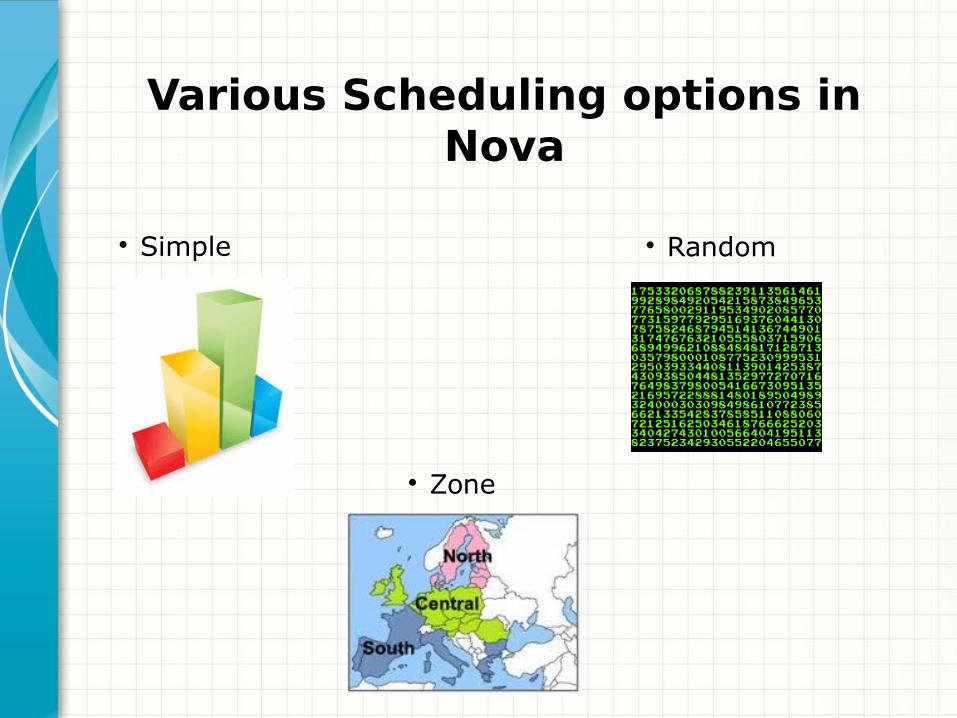
Filters and Weights
DB

Filters and WeightsSome common filters are,
AvailabilityZoneFilter:
Return hosts where node_availability_zone name is the
same as the one requested.
RamFilter:
Return hosts where (free ram * ram_allocation_ratio) is
greater than requested ram.
ComputeFilter:
Return hosts where asked instance_type (with extra_specs)
match capabilities
DiskFilter:
Returns hosts with sufficient disk space available for root
and ephemeral storage.
RetryFilter:
Filters out hosts that have already been attempted for
scheduling purposes. If the scheduler selects a host to
respond to a service request, and the host fails to respond
to the request, this filter prevents the scheduler from
retrying that host for the service request.
This filter is only useful if the scheduler_max_attempts
configuration option is set to a value greater than zero.

Filters and Weights
DiskFilter:
Returns hosts with sufficient disk space available for root
and ephemeral storage.
RetryFilter:
Filters out hosts that have already been attempted for
scheduling purposes.

Filters and Weights
Weights:
Scheduler applies cost function on each host and
calcaulates the weight.
Some of cost functions could be
● Considering Free RAM among filtered hosts. Highest free
RAM wins
● Considering least workload (io ops) among filtered hosts.
● Can consider any specific metric we want to consider in a
similar fashion. Can be enabled from configuration file

Host Aggregates
● Helps us to partition availability zones
● We can aggregate nodes of some specific property
together, so that we can always direct instances which
needs that property into that group of nodes.
● Eg: Nodes with SSD disk
Nodes with GPU cards

Host AggregatesHow to aggregate hosts
$ nova aggregate-create fast-io nova
+----+---------+-------------------+-------+----------+
| Id | Name | Availability Zone | Hosts | Metadata |
+----+---------+-------------------+-------+----------+
| 1 | fast-io | nova | | |
+----+---------+-------------------+-------+----------+
$ nova aggregate-set-metadata 1 ssd=true
+----+---------+-------------------+-------+-------------------+
| Id | Name | Availability Zone | Hosts | Metadata |
+----+---------+-------------------+-------+-------------------+
| 1 | fast-io | nova | [] | {u'ssd': u'true'} |
+----+---------+-------------------+-------+-------------------+

Host Aggregates$ nova aggregate-add-host 1 node1
+----+---------+-------------------+-----------+-------------------+
| Id | Name | Availability Zone | Hosts | Metadata |
+----+---------+-------------------+------------+-------------------+
| 1 | fast-io | nova | [u'node1'] | {u'ssd': u'true'} |
+----+---------+-------------------+------------+-------------------+
$ nova aggregate-add-host 1 node2
+----+---------+-------------------+---------------------+-------------------+
| Id | Name | Availability Zone | Hosts | Metadata |
+----+---------+-------------------+----------------------+-------------------+
| 1 | fast-io | nova | [u'node1', u'node2'] | {u'ssd': u'true'} |
+----+---------+-------------------+----------------------+-------------------+

Host Aggregates$ nova flavor-create ssd.large 6 8192 80 4
+----+-----------+-----------+------+-----------+------+-------+-------------
+-----------+-------------+
| ID | Name | Memory_MB | Disk | Ephemeral | Swap | VCPUs | RXTX_Factor |
Is_Public | extra_specs |
+----+-----------+-----------+------+-----------+------+-------+-------------
+-----------+-------------+
| 6 | ssd.large | 8192 | 80 | 0 | | 4 | 1 | True | {} |
+----+-----------+-----------+------+-----------+------+-------+-------------
+-----------+-------------+
$ nova flavor-key ssd.large set ssd=true
We can use this specific flavor to launch instances requiring
ssd disk on this flavor.

Scheduler performance on ScaleThe whole scheduler looks prety good when the nodes are
less. Lets identify the problems we may face when the
cloud grows.
● Host capacity is recalculated only on regular intervals.
Node may not be in same state before instance reaches it.
Could initiate a retry.
● Influence of Database – Collects all nodes info before
filters are applied.
● The larger the list to filter, more time it takes.

How we solve it ... ?

Horizontally Scalable SchedulerWe came up with a very simple idea of bypassing
scheduler and handle scheduling just with flavor based
queues.
We allow the nodes to have their logic to either subscribe
or un-subscribe to a flavor based queue.
Compute node 1N-CPUNova API
Nova Conductor
RabbitMQ
Compute node 2N-CPU
m1.nano
m1.small
m1.small
m1.large
m1.xlarge

Logic● Compute nodes themself decide what they are capable of
in real time.
● No centralized scheduler components which does decision
making.
● No data access from DB
● Taking advantage of queues
● Can be enabled if required as an option
● New nodes takes immediate effect.

The Blue Printhttps://blueprints.launchpad.net/nova/+spec/horizontally-
scalable-scheduling
Specification Document
https://review.openstack.org/#/c/99006/
Code
https://review.openstack.org/#/c/74423/
https://github.com/JioCloud/nova/tree/scalable-scheduler

The GanttOpenStack related Scheduler-as-a-Service project
This project would be give a generic scheduler for every
other component requiring scheduler.
Plan
● Each resource sends updates to scheduler.
● Scheduler that took this update, sends it to common key-
value in memory storage (between all scheduler service)
● Cleanup: All calls to db.api
● Follow the existing scheduling model in an isolated
fashion.

Mail : [email protected] NickName: vigneshvarChannle: #openstack-dev