Embed Size (px)
Citation preview

LEPOR: An Augmented Machine Translation Evaluation Metric
Master thesis defense, 2014.07
(Aaron) Li-Feng Han (韓利峰), MB-154887 Supervisors: Dr. Derek F. Wong & Dr. Lidia S. Chao
NLP2CT, University of Macau

Content
• MT evaluation (MTE) introduction – MTE background – Existing methods – Weaknesses analysis
• Designed model – Designed factors – LEPOR metric
• Experiments and results – Evaluation criteria – Corpora – Results analysis
• Enhanced models – Variants of LEPOR – Performances in shared task
• Conclusion and future work • Selected publications
2

MTE - background
• MT began as early as 1950s (Weaver, 1955) • Rapid development since 1990s (two reasons)
– Computer technology – Enlarged bilingual corpora (Mariño et al., 2006)
• Several promotion events for MT: – NIST Open MT Evaluation series (OpenMT)
• 2001-2009 (Li, 2005) • By National Institute of Standards and Technology, US • Corpora: Arabic-English, Chinese-English, etc.
– International Workshop on Statistical Machine Translation (WMT) • from 2006 (Koehn and Monz, 2006; Callison-Burch et al., 2007 to 2012; Bojar et al., 2013) • Annually by SIGMT of ACL • Corpora: English to French/German/Spanish/Czech/Hungarian/Haitian Creole/Russian &
inverse direction
– International Workshop of Spoken Language Processing (IWSLT) • from 2004 (Eck and Hori, 2005; Paul, 2009; Paul, et al., 2010; Federico et al., 2011) • English & Asian language (Chinese, Japanese, Korean)
3

• With the rapid development of MT, how to evaluate the MT model? – Whether the newly designed algorithm/feature
enhance the existing MT system, or not? – Which MT system yields the best output for specified
language pair, or generally across languages?
• Difficulties in MT evaluation: – language variability results in no single correct
translation – natural languages are highly ambiguous and different
languages do not always express the same content in the same way (Arnold, 2003)
4

Existing MTE methods
• Manual MTE methods:
• Traditional Manual judgment – Intelligibility: how understandable the sentence is
– Fidelity: how much information the translated sentence retains as compared to the original • by the Automatic Language Processing Advisory Committee
(ALPAC) around 1966 (Carroll, 1966)
– Adequacy (similar as fidelity)
– Fluency: whether the sentence is well-formed and fluent
– Comprehension (improved intelligibility) • by Defense Advanced Research Projects Agency (DARPA) of US
(Church et al., 1991; White et al., 1994)
5

• Advanced manual judgment: – Task oriented method (White and Taylor, 1998)
• In light of the tasks for which the output might by used
– Further developed criteria • Bangalore et al. (2000): simple string accuracy/ generation string
accuracy/ two corresponding tree-based accuracies. • LDC (Linguistics Data Consortium): 5-point scales fluency & adequacy • Specia et al. (2011): design 4-level adequacy, highly adequacy/fairly
adequacy /poorly adequacy/completely inadequate
– Segment ranking (WMT 2011~2013) • Judges are asked to provide a complete ranking over all the candidate
translations of the same source segment (Callison-Burch et al., 2011, 2012)
• 5 systems are randomly selected for the judges (Bojar et al., 2013)
6

• Problems in Manual MTE – Time consuming
• How about a document contain 3,000 sentences or more
– Expensive • Professional translators? or other people?
– Unrepeatable • Precious human labor can not be simply re-run
– Low agreement, sometimes (Callison-Burch et al., 2011) • E.g. in WMT 2011 English-Czech task, multi-annotator agreement
kappa value is very low
• Even the same strings produced by two systems are ranked differently each time by the same annotator
7

• How to address the problems? – Automatic MT evaluation!
• What do we expect? (as compared with manual judgments) – Repeatable
• Can be re-used whenever we make some change of the MT system, and plan to have a check of the translation quality
– Fast • several minutes or seconds for evaluating 3,000 sentences • V.s. hours of human labor
– Cheap • We do not need expensive manual judgments
– High agreement • Each time of running, result in same scores for un-changed outputs
– Reliable • Give a higher score for better translation output • Measured by correlation with human judgments
8

Automatic MTE methods
• BLEU (Papineni et al., 2002)
– Proposed by IBM – First automatic MTE method – based on the degree of n-gram overlapping between the strings of words produced by the machine and the
human translation references – corpus level evaluation
• 𝐵𝐿𝐸𝑈 = 𝐵𝑟𝑒𝑣𝑖𝑡𝑦𝑝𝑒𝑛𝑎𝑙𝑡𝑦 × 𝑒𝑥𝑝 𝜆𝑛𝑙𝑜𝑔𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛𝑛𝑁𝑛=1
– 𝐵𝑟𝑒𝑣𝑖𝑡𝑦𝑝𝑒𝑛𝑎𝑙𝑡𝑦 = 1 𝑖𝑓 𝑐 > 𝑟
𝑒(1−𝑟
𝑐) 𝑖𝑓 𝑐 ≤ 𝑟
– 𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 =#𝑐𝑜𝑟𝑟𝑒𝑐𝑡
#𝑜𝑢𝑡𝑝𝑢𝑡, 𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛𝑛 =
#𝑛𝑔𝑟𝑎𝑚 𝑐𝑜𝑟𝑟𝑒𝑐𝑡
#𝑛𝑔𝑟𝑎𝑚 𝑜𝑢𝑡𝑝𝑢𝑡
• 𝑐 is the total length of candidate translation corpus (the sum of sentences’ length) • 𝑟 refers to the sum of effective reference sentence length in the corpus
– if there are multi-references for each candidate sentence, then the nearest length as compared to the candidate sentence is selected as the effective one
Papineni et al. 2002. BLEU: A Method for Automatic Evaluation of Machine Translation. Proc. of ACL.
9

• METEOR (Banerjee and Lavie, 2005) – Proposed by CMU – To address weaknesses in BLEU, e.g. lack of recall, lack of explicit word matching – Based on general concept of flexible unigram matching – Surface form, stemmed form and meanings
• 𝑀𝐸𝑇𝐸𝑂𝑅 =10𝑃𝑅
𝑅+9𝑃× (1 − 𝑃𝑒𝑛𝑎𝑙𝑡𝑦)
– 𝑃𝑒𝑛𝑎𝑙𝑡𝑦 = 0.5 ×#𝑐ℎ𝑢𝑛𝑘𝑠
#𝑢𝑛𝑖𝑔𝑟𝑎𝑚𝑠_𝑚𝑎𝑡ℎ𝑒𝑑
3
– 𝑅𝑒𝑐𝑎𝑙𝑙 =#𝑐𝑜𝑟𝑟𝑒𝑐𝑡
#𝑟𝑒𝑓𝑒𝑟𝑒𝑛𝑐𝑒
• Unigram strings matches between MT and references, the match of words – simple morphological variants of each other – by the identical stem – synonyms of each other
• Metric score is combination of factors – unigram-precision, unigram-recall – a measure of fragmentation , to capture how well-ordered the matched words in the machine translation
are in relation to the reference – Penalty increases as the number of chunks increases
Banerjee, Satanjeev and Alon Lavie. 2005. METEOR: An Automatic Metric for MT Evaluation with Improved
Correlation with Human Judgments. In proc. of ACL. 10
Reference: He is a clever boy in the class
Output: he is an clever boy in class
#𝑐ℎ𝑢𝑛𝑘𝑠=2
#𝑢𝑛𝑖𝑔𝑟𝑎𝑚𝑠_𝑚𝑎𝑡ℎ𝑒𝑑=6

• WER (Su et al., 1992) • TER/HTER (Snover et al., 2006)
– by University of Maryland & BBN Technologies
• HyTER (Dreyer and Marcu, 2012)
• 𝑊𝐸𝑅 =𝑠𝑢𝑏𝑠𝑡𝑖𝑡𝑢𝑡𝑖𝑜𝑛+𝑖𝑛𝑠𝑒𝑟𝑡𝑖𝑜𝑛+𝑑𝑒𝑙𝑒𝑡𝑖𝑜𝑛
𝑟𝑒𝑓𝑒𝑟𝑒𝑛𝑐𝑒𝑙𝑒𝑛𝑔𝑡ℎ
• WER is Based on Levenshtein distance – the minimum number of editing steps needed to match two sequences
• WER does not take word ordering into account appropriately – The WER scores very low when the word order of system output translation is “wrong” according to the reference. – In the Levenshtein distance, the mismatches in word order require the deletion and re-insertion of the misplaced words. – However, due to the diversity of language expression, some so-called “wrong” order sentences by WER also prove to be good
translations.
• TER adds a novel editing step: blocking movement – allow the movement of word sequences from one part of the output to another – Block movement is considered as one edit step with same cost of other edits
• HyTER develops an annotation tool that is used to create meaning-equivalent networks of translations for a given sentence – Based on the large reference networks
Snover et al. 2006. A Study of Translation Edit Rate with Targeted Human Annotation. In proc. of AMTA. Dreyer, Markus and Daniel Marcu. 2012. HyTER: Meaning-Equivalent Semantics for Translation Evaluation. In proc. of NAACL.
11

Weaknesses of MTE methods
• Good performance on certain language pairs – Perform lower with language pairs when English as source compared
with English as target – E.g. TER (Snover et al., 2006) achieved 0.83 (Czech-English) vs 0.50
(English-Czech) correlation score with human judgments on WMT-2011 shared tasks
• rely on many linguistic features for good performance – E.g. METEOR rely on both stemming, and synonyms, etc.
• Employ incomprehensive factors
– E.g. BLEU (Papineni et al., 2002) based on n-gram precision score – higher BLEU score is not necessarily indicative of better translation
(Callison-Burch et al., 2006)
12

Content
• MT evaluation (MTE) introduction – MTE background – Existing methods – Weaknesses analysis
• Designed model – Designed factors – LEPOR metric
• Experiments and results – Evaluation criteria – Corpora – Results analysis
• Enhanced models – Variants of LEPOR – Performances in shared task
• Conclusion and future work • Selected publications
13

Designed factors
• How to solve the mentioned problems?
• Our designed methods – to make a comprehensive judgments:
Enhanced/Augmented factors – to deal with language bias (perform differently across
languages) problem: Tunable parameters
• Try to make a contribution on some existing weak points – evaluation with English as the source language – some low-resource language pairs, e.g. Czech-English
14

Factor-1: enhanced length penalty
• BLEU (Papineni et al., 2002) only utilizes a brevity penalty for shorter sentence • the redundant/longer sentences are not penalized properly
• to enhance the length penalty factor, we design a new version of penalty
• 𝐿𝑃 =
exp 1 −𝑟
𝑐: 𝑐 < 𝑟
1 ∶ 𝑐 = 𝑟
exp 1 −𝑐
𝑟: 𝑐 > 𝑟
• 𝑟: length of reference sentence • 𝑐: length of candidate (system-output) sentence
– A penalty score for both longer and shorter sentences as compared with reference one
• Our length penalty is designed first by sentence-level while BLEU is corpus level
15

Factor-2: n-gram position difference penalty (𝑁𝑃𝑜𝑠𝑃𝑒𝑛𝑎𝑙)
• Word order information is introduced in ATEC (Wong and Kit, 2008) – However, they utilize the traditional nearest matching strategy – Without giving a clear formulized measuring steps
• We design the n-gram based position difference factor and formulized steps
• To calculate 𝑁𝑃𝑜𝑠𝑃𝑒𝑛𝑎𝑙 score: several steps – N-gram word alignment, n is the number of considered neighbors – labeling each word a sequence number – Measure the position difference score of each word ( 𝑃𝐷𝑖 ) – Measure the sentence-level position difference score (𝑁𝑃𝐷, and
𝑁𝑃𝑜𝑠𝑃𝑒𝑛𝑎𝑙)
16

• Step 1: N-gram word alignment (single reference)
• N-gram word alignment – Alignment direction fixed: from hypothesis (output) to
reference – Considering word neighbors, higher priority shall be
given for the candidate matching with neighbor information • As compared with the traditional nearest matching strategy,
without consider the neighbors
– If both the candidates have neighbors, we select nearest matching as backup choice
17

Fig. N-gram word alignment algorithm 18
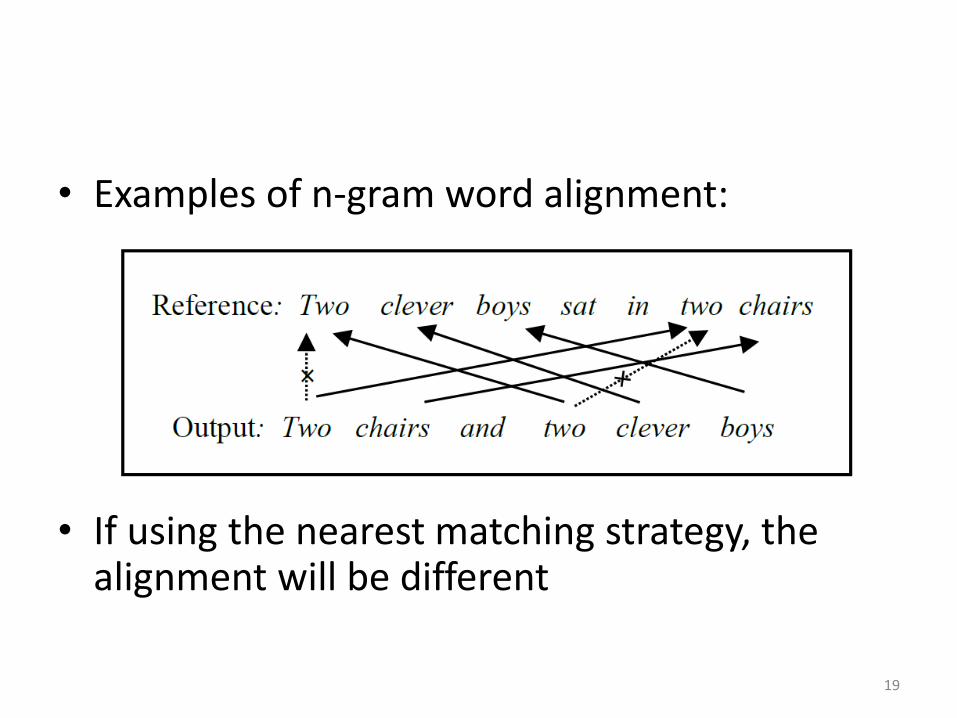
• Examples of n-gram word alignment:
• If using the nearest matching strategy, the alignment will be different
19

• Step 2: NPD calculation for each sentence
• Labeling the token units: • 𝑀𝑎𝑡𝑐ℎ𝑁𝑜𝑢𝑡𝑝𝑢𝑡: position of matched token in output sentence
• 𝑀𝑎𝑡𝑐ℎ𝑁𝑟𝑒𝑓: position of matched token in reference sentence
• Measure the scores: • Each token: 𝑃𝐷𝑖 = |𝑀𝑎𝑡𝑐ℎ𝑁𝑜𝑢𝑡𝑝𝑢𝑡 −𝑀𝑎𝑡𝑐ℎ𝑁𝑟𝑒𝑓|
• Whole sentence: 𝑁𝑃𝐷 =1
𝐿𝑒𝑛𝑔𝑡ℎ𝑜𝑢𝑡𝑝𝑢𝑡 |𝑃𝐷𝑖|𝐿𝑒𝑛𝑔𝑡ℎ𝑜𝑢𝑡𝑝𝑢𝑡𝑖=1
• N-gram Position difference score: 𝑁𝑃𝑜𝑠𝑃𝑒𝑛𝑎𝑙 = exp −𝑁𝑃𝐷
20

• Examples of NPD score with single reference:
– N-gram position difference penalty score of each word: 𝑃𝐷𝑖 – Normalize the penalty score for each sentence: 𝑁𝑃𝐷
– This example: 𝑁𝑃𝑜𝑠𝑃𝑒𝑛𝑎𝑙 = exp −𝑁𝑃𝐷 = 𝑒−1
2
21

multi-reference solution
• Design the n-gram word alignment for multi-reference situation
• N-gram alignment for multi-reference: – The same direction, output to references – Higher priority also for candidate with neighbor
information – Adding principle:
• If the matching candidates from different references all have neighbors, we select the one leading to a smaller NPD value (backup choice for nearest matching)
22

• N-gram alignment examples of multi-references:
• For the word “on”:
– Reference one: PDi = PD3 =3
6−
4
8
– Reference two: PDi = PD3 =3
6−
4
7
–3
6−
4
8 <
3
6−
4
7, the “on” in reference-1 is selected by leading to a smaller NPD value
• Other two words “a” and “bird” are aligned using the same principle
23

Factor-3: weighted Harmonic mean of precision and recall
• METEOR (Banerjee and Lavie, 2005) puts a fixed higher weight on recall value as compared with precision – For different language pairs, the importance of precision and recall differ
• To make a generalized factor for wide spread language pairs • We design the tunable parameters for precision and recall
• 𝐻𝑎𝑟𝑚𝑜𝑛𝑖𝑐 𝛼𝑅, 𝛽𝑃 = (𝛼 + 𝛽)/(𝛼
𝑅+
𝛽
𝑃)
• 𝑃 =𝑐𝑜𝑚𝑚𝑜𝑛_𝑛𝑢𝑚
𝑠𝑦𝑠𝑡𝑒𝑚_𝑙𝑒𝑛𝑔𝑡ℎ
• 𝑅 =𝑐𝑜𝑚𝑚𝑜𝑛_𝑛𝑢𝑚
𝑟𝑒𝑓𝑒𝑟𝑒𝑛𝑐𝑒_𝑙𝑒𝑛𝑔𝑡ℎ
• 𝛼 and 𝛽 are two parameters to adjust the weight of 𝑅 (recall) and 𝑃 (precision) • 𝑐𝑜𝑚𝑚𝑜𝑛_𝑛𝑢𝑚 represents the number of aligned (matching) words and marks appearing both in
automatic translations and references • 𝑠𝑦𝑠𝑡𝑒𝑚_𝑙𝑒𝑛𝑔𝑡ℎ and 𝑟𝑒𝑓𝑒𝑟𝑒𝑛𝑐𝑒_𝑙𝑒𝑛𝑔𝑡ℎ specify the sentence length of system output and
reference respectively
24

LEPOR metric
• LEPOR: automatic machine translation evaluation metric considering the enhanced Length Penalty, Precision, n-gram Position difference Penalty and Recall.
• Initial version: The product value of the factors • Sentence-level score:
– 𝐿𝐸𝑃𝑂𝑅 = 𝐿𝑃 × 𝑁𝑃𝑜𝑠𝑃𝑒𝑛𝑎𝑙 × 𝐻𝑎𝑟𝑚𝑜𝑛𝑖𝑐(𝛼𝑅, 𝛽𝑃)
• System-level score:
– 𝐿𝐸𝑃𝑂𝑅𝐴 =1
𝑆𝑒𝑛𝑡𝑁𝑢𝑚 𝐿𝐸𝑃𝑂𝑅𝑖𝑡ℎ𝑆𝑒𝑛𝑡𝑆𝑒𝑛𝑡𝑁𝑢𝑚𝑖=1
– 𝐿𝐸𝑃𝑂𝑅𝐵 = 𝐹𝑎𝑐𝑡𝑜𝑟𝑖𝑛𝑖=1
– 𝐹𝑎𝑐𝑡𝑜𝑟𝑖=1
𝑆𝑒𝑛𝑡𝑁𝑢𝑚 𝐹𝑎𝑐𝑡𝑜𝑟𝑖𝑡ℎ𝑆𝑒𝑛𝑡𝑆𝑒𝑛𝑡𝑁𝑢𝑚𝑖=1
25

Content
• MT evaluation (MTE) introduction – MTE background – Existing methods – Weaknesses analysis
• Designed model – Designed factors – LEPOR metric
• Experiments and results – Evaluation criteria – Corpora and compared existing methods – Results analysis
• Enhanced models – Variants of LEPOR – Performances in shared task
• Conclusion and future work • Selected publications
26

Evaluation criteria
• Evaluation criteria: – Human judgments are assumed as the golden ones – Measure the correlation score between automatic evaluation and
human judgments
• System-level correlation (one commonly used correlation criterion) – Spearman rank correlation coefficient (Callison-Burch et al., 2011):
– 𝜌 𝑋𝑌 = 1 −6 𝑑𝑖
2𝑛𝑖=1
𝑛(𝑛2−1)
– 𝑋 = 𝑥1, … , 𝑥𝑛 , 𝑌 = {𝑦1, … , 𝑦𝑛} – 𝑑𝑖 = (𝑥𝑖 − 𝑦𝑖) is the difference value of two corresponding ranked
variants
27

Corpora and compared methods
• Corpora: – Development data for tuning of parameters – WMT2008 (http://www.statmt.org/wmt08/) – EN: English, ES: Spanish, DE: German, FR: French and CZ: Czech – Two directions: EN-other and other-EN
– Testing data – WMT2011 (http://www.statmt.org/wmt11/)
– The numbers of participated automatic MT systems in WMT 2011 – 10, 22, 15 and 17 respectively for English-to-CZ/DE/ES/FR – 8, 20, 15 and 18 respectively for CZ/DE/ES/FR-to-EN – The gold standard reference data consists of 3,003 sentences
28

• Comparisons (3 gold standard BLEU/TER/METEOR & 2 latest metrics):
– BLEU (Papineni et al., 2002), precision based metric – TER (Snover et al., 2006), edit distance based metric – METEOR (version 1.3) (Denkowski and Lavie, 2011), precision and recall, using
synonym, stemming, and paraphrasing as external resources – AMBER (Chen and Kuhn, 2011), a modified version of BLEU, attaching more
kinds of penalty coefficients, combining the n-gram precision and recall – MP4IMB1 (Popovic et al., 2011), based on morphemes, POS (4-grams) and
lexicon probabilities, etc.
• Ours, initial version of LEPOR (𝐿𝐸𝑃𝑂𝑅𝐴 & 𝐿𝐸𝑃𝑂𝑅𝐵)
– Simple product value of the factors – Without using linguistic feature – Based on augmented factors
29
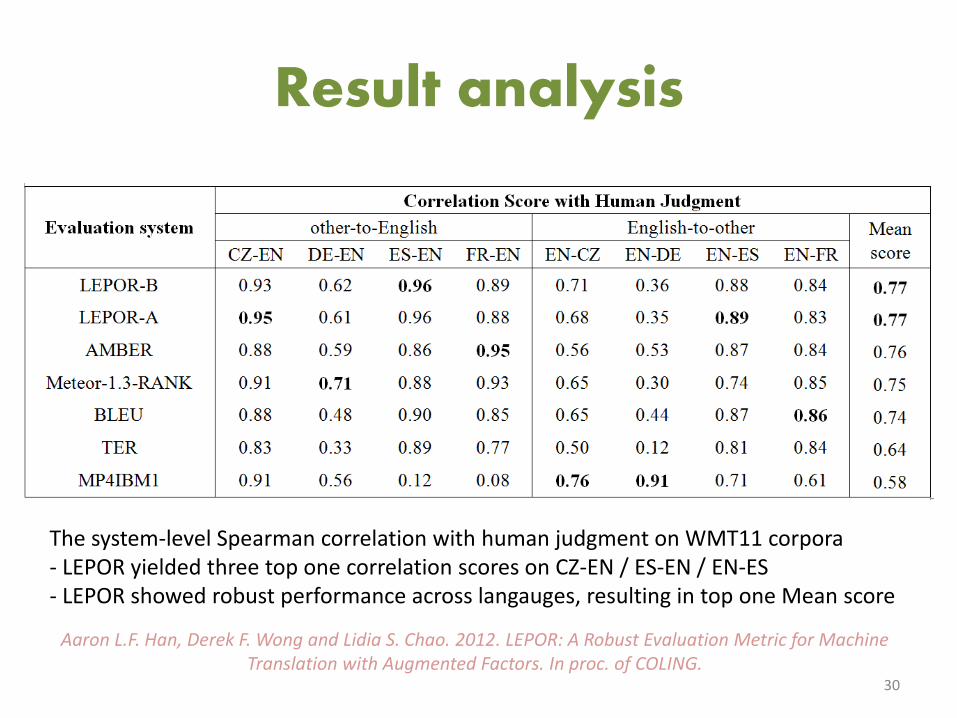
Result analysis
The system-level Spearman correlation with human judgment on WMT11 corpora - LEPOR yielded three top one correlation scores on CZ-EN / ES-EN / EN-ES - LEPOR showed robust performance across langauges, resulting in top one Mean score
Aaron L.F. Han, Derek F. Wong and Lidia S. Chao. 2012. LEPOR: A Robust Evaluation Metric for Machine Translation with Augmented Factors. In proc. of COLING.
30

Content
• MT evaluation (MTE) introduction – MTE background – Existing methods – Weaknesses analysis
• Designed model – Designed factors – LEPOR metric
• Experiments and results – Evaluation criteria – Corpora – Results analysis
• Enhanced models – Variants of LEPOR – Performances in shared task
• Conclusion and future work • Selected publications
31

Variant of LEPOR
• New factor: to consider the content information – Design n-gram precision and n-gram recall – Harmonic mean of n-gram sub-factors – Also measured on sentence-level vs BLEU (corpus-level)
• N is the number of words in the block matching
• 𝑃𝑛 =#𝑛𝑔𝑟𝑎𝑚𝑚𝑎𝑡𝑐ℎ𝑒𝑑
#𝑛𝑔𝑟𝑎𝑚 𝑐ℎ𝑢𝑛𝑘𝑠 𝑖𝑛 𝑠𝑦𝑠𝑡𝑒𝑚 𝑜𝑢𝑡𝑝𝑢𝑡
• 𝑅𝑛 =#𝑛𝑔𝑟𝑎𝑚𝑚𝑎𝑡𝑐ℎ𝑒𝑑
#𝑛𝑔𝑟𝑎𝑚 𝑐ℎ𝑢𝑛𝑘𝑠 𝑖𝑛 𝑟𝑒𝑓𝑒𝑟𝑒𝑛𝑐𝑒
• 𝐻𝑃𝑅 = 𝐻𝑎𝑟𝑚𝑜𝑛𝑖𝑐 𝛼𝑅𝑛, 𝛽𝑃𝑛 =𝛼+𝛽𝛼
𝑅𝑛+
𝛽
𝑃𝑛
32
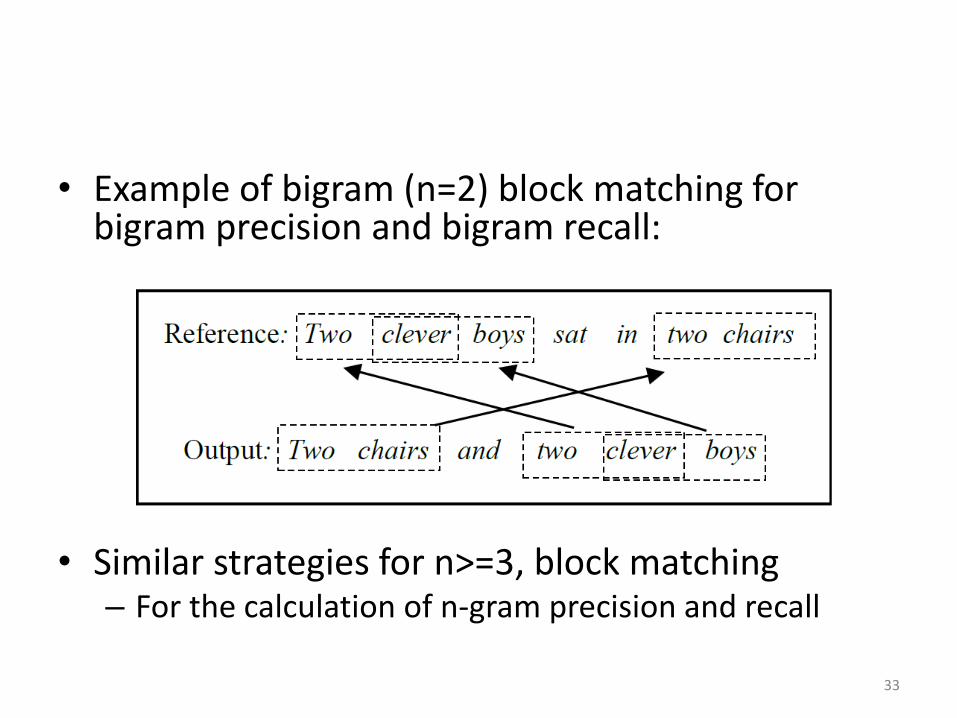
• Example of bigram (n=2) block matching for bigram precision and bigram recall:
• Similar strategies for n>=3, block matching – For the calculation of n-gram precision and recall
33

Variant-1: ℎ𝐿𝐸𝑃𝑂𝑅
• To achieve higher correlation with human judgments for focused language pair – Design tunable parameters at factors level – Weighted harmonic mean of the factors:
– ℎ𝐿𝐸𝑃𝑂𝑅 = 𝐻𝑎𝑟𝑚𝑜𝑛𝑖𝑐 𝑤𝐿𝑃𝐿𝑃, 𝑤𝑁𝑃𝑜𝑠𝑃𝑒𝑛𝑎𝑙𝑁𝑃𝑜𝑠𝑃𝑒𝑛𝑎𝑙, 𝑤𝐻𝑃𝑅𝐻𝑃𝑅
= 𝑤𝑖𝑛𝑖=1
𝑤𝑖
𝐹𝑎𝑐𝑡𝑜𝑟𝑖
𝑛𝑖=1
=𝑤𝐿𝑃+𝑤𝑁𝑃𝑜𝑠𝑃𝑒𝑛𝑎𝑙+𝑤𝐻𝑃𝑅𝑤𝐿𝑃𝐿𝑃
+𝑤𝑁𝑃𝑜𝑠𝑃𝑒𝑛𝑎𝑙𝑁𝑃𝑜𝑠𝑃𝑒𝑛𝑎𝑙
+𝑤𝐻𝑃𝑅𝐻𝑃𝑅
– ℎ𝐿𝐸𝑃𝑂𝑅𝐴 =1
𝑆𝑒𝑛𝑡𝑁𝑢𝑚 ℎ𝐿𝐸𝑃𝑂𝑅𝑖𝑡ℎ𝑆𝑒𝑛𝑡𝑆𝑒𝑛𝑡𝑁𝑢𝑚𝑖=1
– ℎ𝐿𝐸𝑃𝑂𝑅𝐵 = 𝐻𝑎𝑟𝑚𝑜𝑛𝑖𝑐(𝑤𝐿𝑃𝐿𝑃,𝑤𝑁𝑃𝑜𝑠𝑃𝑒𝑛𝑎𝑙𝑁𝑃𝑜𝑠𝑃𝑒𝑛𝑎𝑙, 𝑤𝐻𝑃𝑅𝐻𝑃𝑅)
• In this way, it has more parameters to tune for the focused language pair – To seize the characteristics of focused language pair – Especially for distant language pairs
34

Variant-2: 𝑛𝐿𝐸𝑃𝑂𝑅
• For the languages that request high fluency – We design the n-gram based metric – N-gram based product of the factors:
– 𝑛𝐿𝐸𝑃𝑂𝑅 = 𝐿𝑃 × 𝑁𝑃𝑜𝑠𝑃𝑒𝑛𝑎𝑙 × 𝑒𝑥𝑝 ( 𝑤𝑛𝑙𝑜𝑔𝐻𝑃𝑅𝑁𝑛=1 )
– 𝐻𝑃𝑅 = 𝐻𝑎𝑟𝑚𝑜𝑛𝑖𝑐 𝛼𝑅𝑛, 𝛽𝑃𝑛 =𝛼+𝛽𝛼
𝑅𝑛+
𝛽
𝑃𝑛
– 𝑛𝐿𝐸𝑃𝑂𝑅𝐴 =1
𝑆𝑒𝑛𝑡𝑁𝑢𝑚 𝑛𝐿𝐸𝑃𝑂𝑅𝑖𝑡ℎ𝑆𝑒𝑛𝑡𝑆𝑒𝑛𝑡𝑁𝑢𝑚𝑖=1
– 𝑛𝐿𝐸𝑃𝑂𝑅𝐵 = 𝐿𝑃 × 𝑃𝑜𝑠𝑃𝑒𝑛𝑎𝑙𝑡𝑦 × 𝑒𝑥𝑝( 𝑤𝑛𝑙𝑜𝑔𝐻𝑃𝑅𝑁𝑛=1 )
• In this way, the n-gram information is considered for the measuring of precision and recall – To consider more about content information
35

Linguistic feature
• Enhance the metric with concise linguistic feature:
• Example of Part-of-speech (POS) utilization – Sometimes perform as synonym information – E.g. the “say” and “claim” in the example translation
36

• Scores with linguistic features: • Sentence-level score:
• 𝐿𝐸𝑃𝑂𝑅𝑓𝑖𝑛𝑎𝑙 =1
𝑤ℎ𝑤+𝑤ℎ𝑝(𝑤ℎ𝑤𝐿𝐸𝑃𝑂𝑅𝑤𝑜𝑟𝑑 +𝑤ℎ𝑝𝐿𝐸𝑃𝑂𝑅𝑃𝑂𝑆)
• 𝐿𝐸𝑃𝑂𝑅𝑃𝑂𝑆 and 𝐿𝐸𝑃𝑂𝑅𝑤𝑜𝑟𝑑 are measured using the same algorithm on POS sequence and word sequence respectively
• System-level score:
• 𝐿𝐸𝑃𝑂𝑅𝑓𝑖𝑛𝑎𝑙 =1
𝑤ℎ𝑤+𝑤ℎ𝑝(𝑤ℎ𝑤𝐿𝐸𝑃𝑂𝑅𝑤𝑜𝑟𝑑 +𝑤ℎ𝑝𝐿𝐸𝑃𝑂𝑅𝑃𝑂𝑆)
Aaron L.F. Han, Derek F. Wong Lidia S. Chao, et al. 2013. Language-independent Model for Machine
Translation Evaluation with Reinforced Factors. In proc. of MT Summit. 37

• Experiments of enhanced metric • Corpora setting
– The same corpora utilization with last experiments – WMT08 for development and WMT11 for testing
• Variant of LEPOR model – Harmonic mean to combine the main factors – More parameters to tune – Utilizing concise linguistic features (POS) as external resource
– ℎ𝐿𝐸𝑃𝑂𝑅 =1
𝑛𝑢𝑚𝑠𝑒𝑛𝑡 |ℎ𝐿𝐸𝑃𝑂𝑅𝑖|𝑛𝑢𝑚𝑠𝑒𝑛𝑡𝑖=1
– ℎ𝐿𝐸𝑃𝑂𝑅𝐸 =1
𝑤ℎ𝑤+𝑤ℎ𝑝(𝑤ℎ𝑤ℎ𝐿𝐸𝑃𝑂𝑅𝑤𝑜𝑟𝑑 + 𝑤ℎ𝑝ℎ𝐿𝐸𝑃𝑂𝑅𝑃𝑂𝑆)
38

• Comparison (Metrics) with related works:
– In addition to the state-of-the-art metrics METEOR / BLEU / TER
– Compare with ROSE (Song and Cohn, 2011) and MPF (Popovic, 2011)
– ROSE and MPF metrics both utilize the POS as external information
39
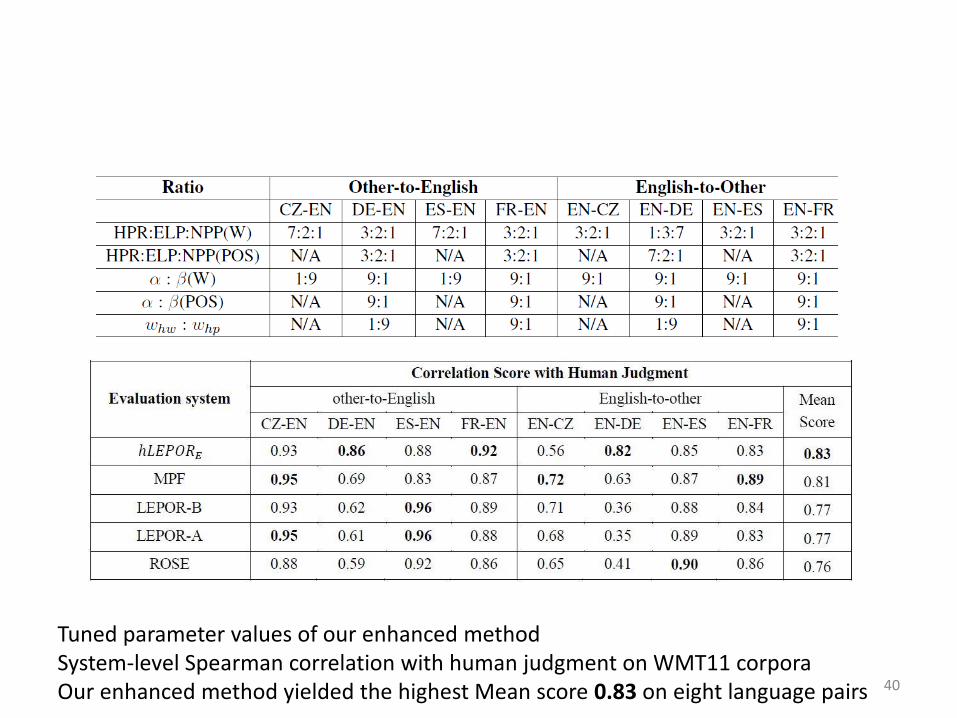
Tuned parameter values of our enhanced method System-level Spearman correlation with human judgment on WMT11 corpora Our enhanced method yielded the highest Mean score 0.83 on eight language pairs 40

Performance in WMT task
• Performances on MT evaluation shared tasks in ACL-WMT 2013
– The eighth international workshop of statistical machine translation, accompanied with ACL-2013
• Corpora:
– English, Spanish, German, French, Czech, and Russian (new)
41

• Submitted methods: – hLEPOR (LEPOR_v3.1): with linguistic feature & tunable
parameters
– ℎ𝐿𝐸𝑃𝑂𝑅 =1
𝑛𝑢𝑚𝑠𝑒𝑛𝑡 |ℎ𝐿𝐸𝑃𝑂𝑅𝑖|𝑛𝑢𝑚𝑠𝑒𝑛𝑡𝑖=1
– ℎ𝐿𝐸𝑃𝑂𝑅𝑓𝑖𝑛𝑎𝑙 =1
𝑤ℎ𝑤+𝑤ℎ𝑝(𝑤ℎ𝑤ℎ𝐿𝐸𝑃𝑂𝑅𝑤𝑜𝑟𝑑 +𝑤ℎ𝑝ℎ𝐿𝐸𝑃𝑂𝑅𝑃𝑂𝑆)
– nLEPOR_baseline: without using external resource, default weights
– 𝑛𝐿𝐸𝑃𝑂𝑅 = 𝐿𝑃 × 𝑁𝑃𝑜𝑠𝑃𝑒𝑛𝑎𝑙 × exp ( 𝑤𝑛𝑙𝑜𝑔𝐻𝑃𝑅𝑁𝑛=1 )
42

Metric evaluations
• Evaluation criteria: – Human judgments are assumed the golden ones – Measure the correlation score between automatic evaluation and
human judgments
• System-level correlation (two commonly used correlations) – Spearman rank correlation coefficient:
– 𝜌 𝑋𝑌 = 1 −6 𝑑𝑖
2𝑛𝑖=1
𝑛(𝑛2−1)
– 𝑋 = 𝑥1, … , 𝑥𝑛 , 𝑌 = {𝑦1, … , 𝑦𝑛}
– Pearson correlation coefficient:
– 𝜌 𝑋𝑌 = (𝑥𝑖−𝜇𝑥)(𝑦𝑖−𝜇𝑦)𝑛𝑖=1
𝑥𝑖−𝜇𝑥2𝑛
𝑖=1 𝑦𝑖−𝜇𝑦2𝑛
𝑖=1
, 𝜇𝑦 =1
𝑛 𝑦𝑖, 𝜇𝑥 =
1
𝑛 𝑥𝑖
43
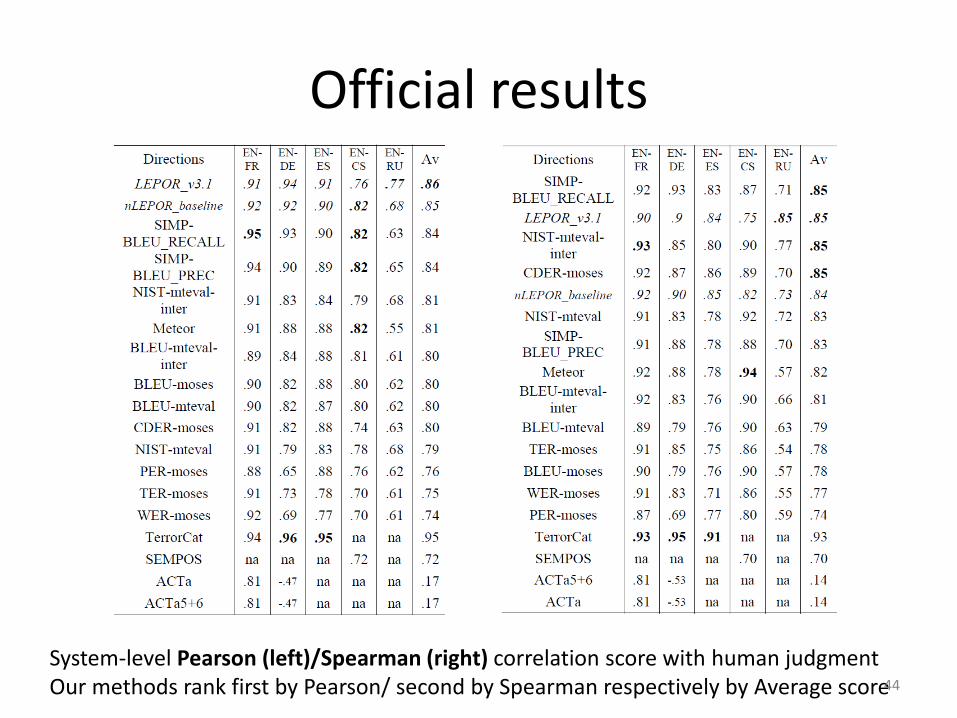
Official results
System-level Pearson (left)/Spearman (right) correlation score with human judgment Our methods rank first by Pearson/ second by Spearman respectively by Average score 44

• From the shared task results
– Practical performance: LEPOR methods are effective yielding generally higher across language pairs
– Robustness: LEPOR methods achieved the first highest score on the new language pair English-Russian
– Contribution for the existing weak point: MT evaluation with English as the source language
45
Aaron L.F. Han, Derek F. Wong and Lidia S. Chao et al. 2013. A Description of Tunable Machine Translation Evaluation Systems in WMT13 Metrics Task. In proc. of ACL workshop of 8th WMT.

Content
• MT evaluation (MTE) introduction – MTE background – Existing methods – Weaknesses analysis
• Designed model – Designed factors – LEPOR metric
• Experiments and results – Evaluation criteria – Corpora – Results analysis
• Enhanced models – Variants of LEPOR – Performances in shared task
• Conclusion and future work • Selected publications
46

• The methods and contributions – Designed and trained for system-level MTE – Using reference translations
• For future work: – Tune MT system using designed MTE methods – Design model for Segment-level MTE – MTE without using reference translation – Investigate more linguistic features (e.g. text
entailment, paraphrasing, and synonym) for MTE with English as target language
47

Content
• MT evaluation (MTE) introduction – MTE background – Existing methods – Weaknesses analysis
• Designed model – Designed factors – LEPOR metric
• Experiments and results – Evaluation criteria – Corpora – Results analysis
• Enhanced models – Variants of LEPOR – Performances in shared task
• Conclusion and future work • Selected publications
48

Selected publications Aaron Li-Feng Han, Derek F. Wong, Lidia S. Chao, Liangye He and Yi Lu. Unsupervised Quality Estimation Model for English to German Translation and Its Application in Extensive
Supervised Evaluation. The Scientific World Journal, Issue: Recent Advances in Information Technology. Page 1-12, April 2014. Hindawi Publishing Corporation. ISSN:1537-744X. http://www.hindawi.com/journals/tswj/aip/760301/
Aaron Li-Feng Han, Derek F. Wong, Lidia S. Chao, Liangye He, Yi Lu, Junwen Xing and Xiaodong Zeng. Language-independent Model for Machine Translation Evaluation with Reinforced Factors. Proceedings of the 14th International Conference of Machine Translation Summit (MT Summit), pp. 215-222. Nice, France. 2 - 6 September 2013. International Association for Machine Translation. http://www.mt-archive.info/10/MTS-2013-Han.pdf
Aaron Li-Feng Han, Derek Wong, Lidia S. Chao, Yi Lu, Liangye He, Yiming Wang, Jiaji Zhou. A Description of Tunable Machine Translation Evaluation Systems in WMT13 Metrics Task. Proceedings of the ACL 2013 EIGHTH WORKSHOP ON STATISTICAL MACHINE TRANSLATION (ACL-WMT), pp. 414-421, 8-9 August 2013. Sofia, Bulgaria. Association for Computational Linguistics. http://www.aclweb.org/anthology/W13-2253
Aaron Li-Feng Han, Yi Lu, Derek F. Wong, Lidia S. Chao, Liangye He, Junwen Xing. Quality Estimation for Machine Translation Using the Joint Method of Evaluation Criteria and Statistical Modeling. Proceedings of the ACL 2013 EIGHTH WORKSHOP ON STATISTICAL MACHINE TRANSLATION (ACL-WMT), pp. 365-372. 8-9 August 2013. Sofia, Bulgaria. Association for Computational Linguistics. http://www.aclweb.org/anthology/W13-2245
Aaron Li-Feng Han, Derek F. Wong, Lidia S. Chao, Liangye He, Shuo Li and Ling Zhu. Phrase Tagset Mapping for French and English Treebanks and Its Application in Machine Translation Evaluation. Language Processing and Knowledge in the Web. Lecture Notes in Computer Science Volume 8105, 2013, pp 119-131. Volume Editors: Iryna Gurevych, Chris Biemann and Torsten Zesch. Springer-Verlag Berlin Heidelberg. http://dx.doi.org/10.1007/978-3-642-40722-2_13
Aaron Li-Feng Han, Derek F. Wong, Lidia S. Chao, Liangye He, Ling Zhu and Shuo Li. A Study of Chinese Word Segmentation Based on the Characteristics of Chinese. Language Processing and Knowledge in the Web. Lecture Notes in Computer Science Volume 8105, 2013, pp 111-118. Volume Editors: Iryna Gurevych, Chris Biemann and Torsten Zesch. Springer-Verlag Berlin Heidelberg. http://dx.doi.org/10.1007/978-3-642-40722-2_12
Aaron Li-Feng Han, Derek F. Wong, Lidia S. Chao, Liangye He. Automatic Machine Translation Evaluation with Part-of-Speech Information. Text, Speech, and Dialogue. Lecture Notes in Computer Science Volume 8082, 2013, pp 121-128. Volume Editors: I. Habernal and V. Matousek. Springer-Verlag Berlin Heidelberg. http://dx.doi.org/10.1007/978-3-642-40585-3_16
Aaron Li-Feng Han, Derek Fai Wong and Lidia Sam Chao. Chinese Named Entity Recognition with Conditional Random Fields in the Light of Chinese Characteristics. Language Processing and Intelligent Information Systems. Lecture Notes in Computer Science Volume 7912, 2013, pp 57-68. M.A. Klopotek et al. (Eds.): IIS 2013. Springer-Verlag Berlin Heidelberg. http://dx.doi.org/10.1007/978-3-642-38634-3_8
Aaron Li-Feng Han, Derek F. Wong and Lidia S. Chao. LEPOR: A Robust Evaluation Metric for Machine Translation with Augmented Factors. Proceedings of the 24th International Conference on Computational Linguistics (COLING): Posters, pages 441–450, Mumbai, December 2012. Association for Computational Linguistics. http://aclweb.org/anthology//C/C12/C12-2044.pdf
49

Warm pictures from NLP2CT
50

Thanks for your attention!
(Aaron) Li-Feng Han (韓利峰), MB-154887 Supervisors: Dr. Derek F. Wong & Dr. Lidia S. Chao
NLP2CT, University of Macau