Embed Size (px)
Citation preview

Developing a CAT

What is CAT?
CAT is an algorithmWe need to break down and specify all aspectsChoice of major algorithmsSubalgorithmsInput parametersItem bank needs

CAT Components
1. Calibrated item bank2. Starting rule3. Item selection rule4. Scoring rule5. Stopping rule
We must provide validity documentation on each
Algorithms inside your testing engine
Test development side

Background
CAT remains underutilized. What are the barriers?What do you think?CostComplexityFew guidelines on how to develop one

Background
We have approximately 4 decades of technical research on CAT
Numerous books and other resources (Rudner’s tutorial) on what CAT is and how it works
Discussions of issues (Wise & Kingsbury, 2000)
Very few resources on how to develop a CAT

Background
Best existing resource: descriptions of current CAT programsSands, Waters, & McBride (1997): ASVABElements of Adaptive Testing: Part 2 = 5 examples
JATT issue on CAT

Background
Framework, not complete recipeIdentify choices for your org and best way to investigate/decide
Leads to better quality in the endAlso the foundation for validity arguments
Why did you choose certain things?

Seq. Stage Primary work1 Feasibility, applicability, and
planning studiesMonte carlo simulation; business case evaluation
2 Develop item bank content or utilize existing bank
Item writing and review
3 Pretest and calibrate item bank
Pretesting; item analysis
4 Determine specifications for final CAT
Post-hoc or hybrid simulations
5 Publish live CAT Publishing and distribution; software development
The 5 step model

1. Feasibility, applicability, planning
Big question: is CAT worth the investment?
If so, how can we develop a project plan and timeline?

1. Feasibility, applicability, planning
Answer: simulationsSimulate how a CAT would operate under specified conditions IVs Item bank size Item quality Desired precision
DVs Average test length Accuracy: CAT θ vs. true θ (or full bank)

1. Feasibility, applicability, planning
For those newer to CAT…Three types of simulations
Monte CarloPost hoc (real data)Hybrid

1. Feasibility, applicability, planning
At this point, real data not likely, so Monte Carlo
Generate plausible situations Item bank: 100, 200, 300… Item quality: a = 0.7, 0.8…; spread of bDesired precision: SEM = 0.2, 0.3, 0.4…
Compare results to each other and fixed formsBase values on reality (e.g., mean a)
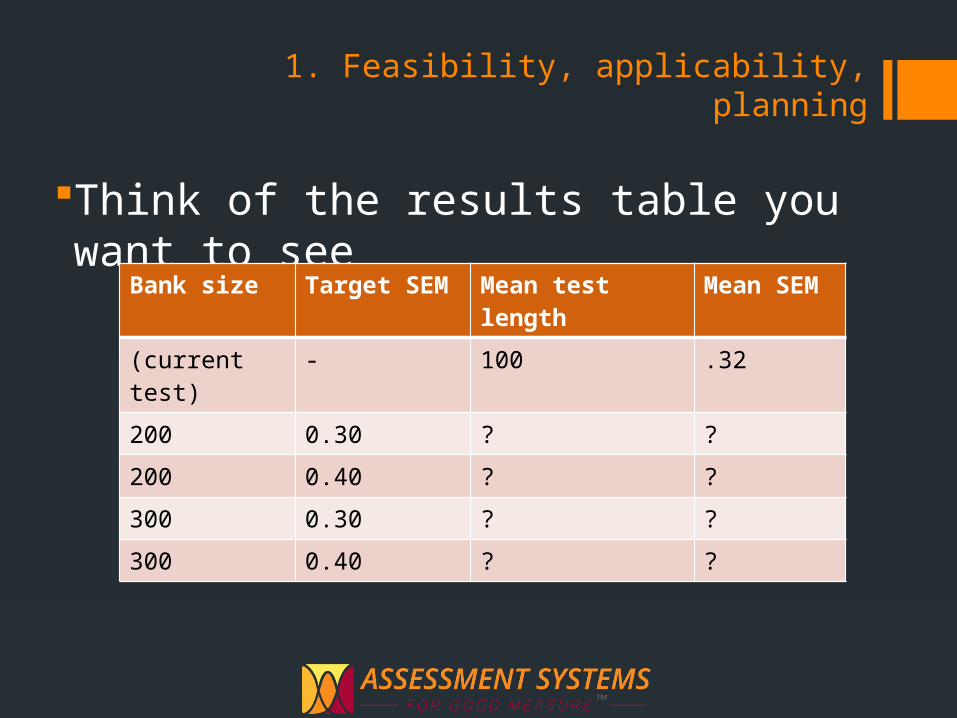
1. Feasibility, applicability, planning
Think of the results table you want to see
Bank size Target SEM Mean test length Mean SEM(current test) - 100 .32
200 0.30 ? ?
200 0.40 ? ?
300 0.30 ? ?
300 0.40 ? ?

1. Feasibility, applicability, planning
Software will do this for you, allowing you to simulate CATs for thousands of examinees in secondsCATSim (ASC)WinGen (Han)FireStar (Choi)
You can then easily set up an experiment with a wide range of conditions, and run a simulation for each
Workshop by Cito on this
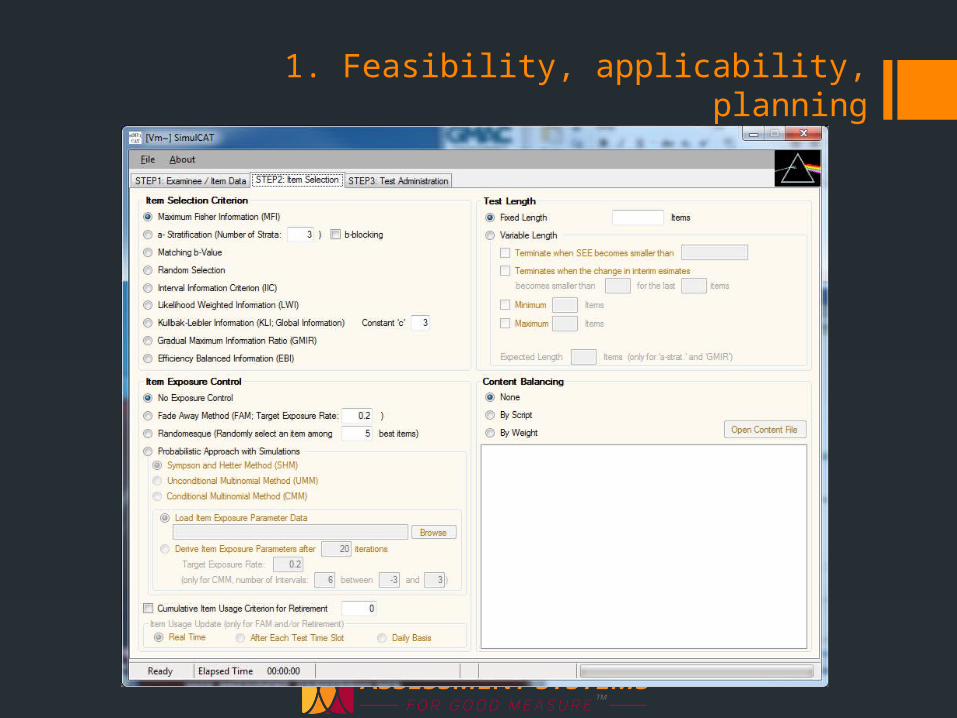
1. Feasibility, applicability, planning

1. Feasibility, applicability, planning
Example takeaway:CAT with bank of 300 items and SEM=0.25 has average of 53 items
Current fixed test has 100 items, SEM=0.23 in middle and 0.35+ beyond θ of ±1.5
CAT will make test more accurate for extreme examinees, about same accuracy for middle, but with 50% reduction

1. Feasibility, applicability, planning
Another question: Business Case EvaluationExample:
You deliver 100,000 tests per yearYou estimate $20/hour seat timeReducing a test from 2 hours to 1 hour then saves $2
million
More difficult to estimate for K-12 – cost is not seat time but time away from instruction

2. Develop item bank
Now that we have an idea what we need, we need to build it
CAT-based considerations:Difficulty spreadAnticipated exposure/security issuesTIF adequacy
Normal considerationsContent blueprintsCognitive level

3. Pretesting and analysis
Must pretest items to obtain bank calibration
Two situationsNew test, new scale: present large amounts of items to examinees
Existing test, old scale: seed itemsObviously will take longer time to pilotRequires a linking study

3. Pretesting and analysis
Then calibrate, usually IRTAlso perform other due diligence
Dimensionality DIF Model fitDistractor analysisRemove/revise items based on stats?Etc.

4. Determine final specifications
To publish a CAT, we need to specify algorithmsStarting pointItem selectionScoringTermination criterion
Also subalgorithms, such as item exposure, content, test length constraints

4. Determine final specifications
But we must have a reason for selecting specificationsValidity documentationDefensibility
Again, we turn to simulation studiesDefine competing conditions
Big difference now: we have real data!Post Hoc or Hybrid simulations
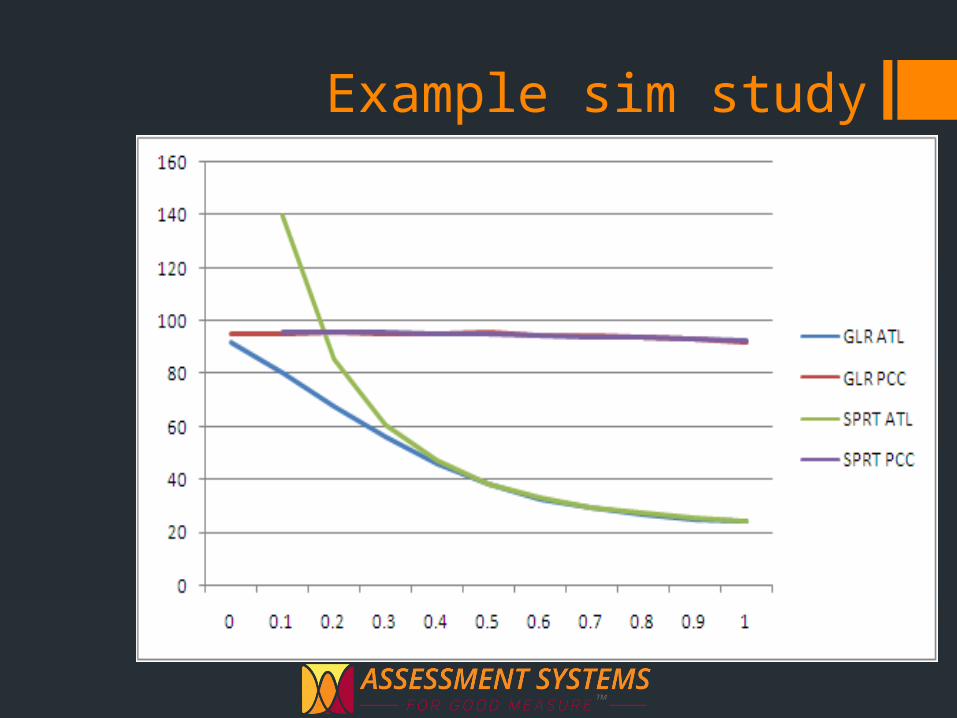
Example sim study

4. Determine final specifications
After determining psychometric specifications, evaluate more practical issues
For example, time limits; can’t really set until you know how many itemsCAT-ASVAB approach: set limits for 90-95% of population

5. Publish live CAT
Once you have finalized your item bank and CAT design, time to publish
Need to put everything into item banker and CAT engine
First: obtain the item banker and CAT engine If developing your own, this can be the biggest
step If purchasing, this is the easiest step

Epilogue: Maintaining CATLike fixed form testing, maintenance is usually necessary
Check that performing as expectedIs termination criterion being satisfied?Examinees hitting test length or other constraints?
Average test length what you expected?Exposure or security issues?






























