
Conference title 1
Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU G. Bernabé†, J. Cuenca† , Luis P. García* and D. Giménez‡
† Computer Engineering Department, University of Murcia * Technical Research Service, Technical University of Cartagena
‡ Computer Science and Systems Department, University of Murcia
3-7 July, 2014
14th International Conference on Computational and Mathematical Methods
in Science and Engineering (CMMSE 2014)

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
2
Outline
Introduction and Motivation
An enhanced autotuning engine for the 3D-FWT
Experimental Results
Conclusions and Future work

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
3
Outline
Introduction and Motivation
An enhanced autotuning engine for the 3D-FWT
Experimental Results
Conclusions and Future work

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
4
•Cluster of nodes
Introduction

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
5
•Cluster of nodes
Introduction
To solve scientific problems like 3D-FWT

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
6
Introduction
• The development and optimization of
parallel code is a complex task
– Deep knowledge of the different components
exploit the computing capacity
– Programming and combining efficiently the
different paradigms (message passing, shared
memory and SIMD GPU)

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
7
Introduction
• The development and optimization of
parallel code is a complex task
– Deep knowledge of the different components
exploit the computing capacity
– Programming and combining efficiently the
different paradigms (message passing, shared
memory and SIMD GPU)

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
8
Introduction
• The development and optimization of
parallel code is a complex task
– Deep knowledge of the different components
exploit the computing capacity
– Programming and combining efficiently the
different paradigms (message passing, shared
memory and SIMD GPU)

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
9
Introduction
• The development and optimization of
parallel code is a complex task
– Deep knowledge of the different components
exploit the computing capacity
– Programming and combining efficiently the
different paradigms (message passing, shared
memory and SIMD GPU)
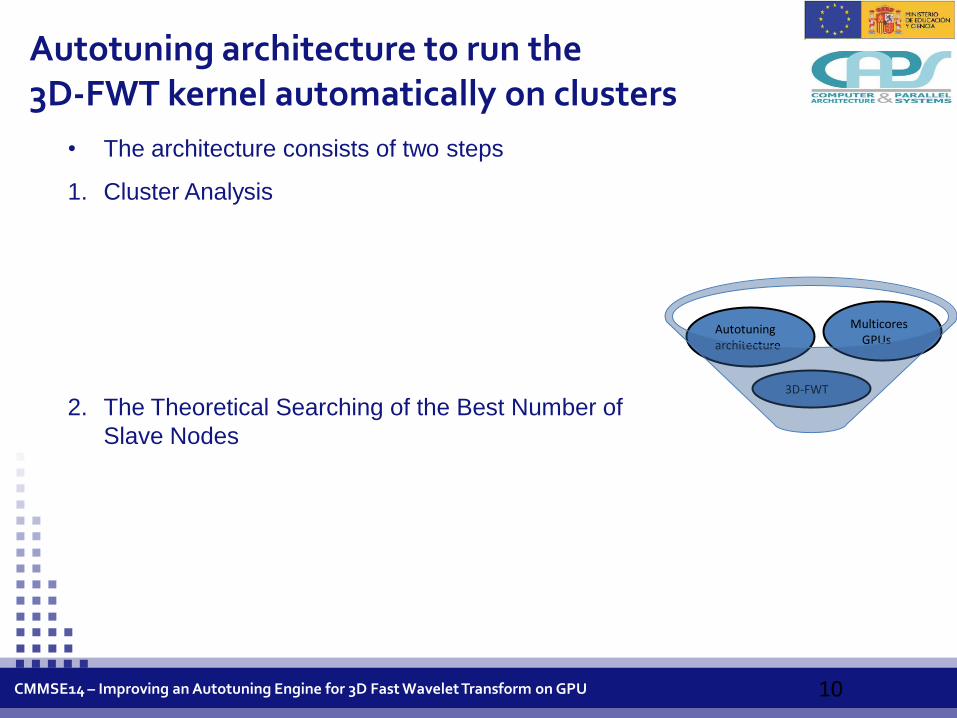
Autotuning architecture to run the 3D-FWT kernel automatically on clusters of multicore+GPUs [6]
[6] G. Bernabé, J. Cuenca y D. Giménez. “Optimizing a
3D-FWT code in heterogeneous cluster of multicore
CPUs and manycore GPUs”. SBAC-PAD 2013
Autotuning architecture
3D-FWT
Multicores GPUs
CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
10
Autotuning architecture to run the 3D-FWT kernel automatically on clusters
• The architecture consists of two steps
1. Cluster Analysis
2. The Theoretical Searching of the Best Number of
Slave Nodes
Autotuning architecture
3D-FWT
Multicores GPUs

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
11
Autotuning architecture to run the 3D-FWT kernel automatically on clusters
• The architecture consists of two steps
1. Cluster Analysis
• Detects the number and type of CPUs and
GPUs
• The 3D-FWT computer performance
• The bandwidth of the interconnection network
2. The Theoretical Searching of the Best Number of
Slave Nodes
Autotuning architecture
3D-FWT
Multicores GPUs
Cluster Analysis

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
12
Autotuning architecture to run the 3D-FWT kernel automatically on clusters
• The architecture consists of two steps
1. Cluster Analysis
• Detects the number and type of CPUs and GPUs
• The 3D-FWT computer performance
• The bandwidth of the interconnection network
2. The Theoretical Searching of the Best Number of Slave
Nodes
• Automatically computes the proportions at which
the different sequences of video are divided among
the nodes in the cluster
• Searchs the possible Temporal distribution
schemes for 1 to n slaves nodes working jointly to
a master node
• Chooses the number of slave nodes which gives
the lowest execution time
Autotuning architecture
3D-FWT
Multicores GPUs
Cluster Analysis
Theoretical Searching of the Best Number
of Slave Nodes

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
15
Autotuning architecture to run the 3D-FWT kernel automatically on clusters
Cluster Analysis
Cluster Performance
Map
Theoretical Searching of the Best Number
of Slave Nodes
Best Number of Slave Nodes
• The first stage is the Cluster Analysis
1. Detects automatically the available GPUs and
CPUs in each node
2. For each platform in each node (GPU or CPU) do
• If GPU Nvidia: CUDA 3D-FWT calculates
automatically block size
• If GPU ATI: OpenCL 3D-FWT computes
automatically work-group size
• If CPU: Tiling and pthreads fast analysis to
obtain the best n threads
• Send one sequence Computer
performance of the 3D-FWT kernel
3. Measures the performance of the interconnection
network among the nodes

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
16
An enhanced autotuning engine for the 3D-FWT
• The first stage is the Cluster Analysis
1. Detects automatically the available GPUs and
CPUs in each node
2. For each platform in each node (GPU or CPU) do
• If GPU Nvidia: CUDA 3D-FWT calculates
automatically block size
• If GPU ATI: OpenCL 3D-FWT computes
automatically work-group size
• If CPU: Tiling and pthreads fast analysis to
obtain the best n threads
• Send one sequence Computer
performance of the 3D-FWT kernel
3. Measures the performance of the interconnection
network among the nodes
Cluster Analysis
Cluster Performance
Map
Theoretical Searching of the Best Number
of Slave Nodes
Best Number of Slave Nodes

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
17
An enhanced autotuning engine for the 3D-FWT
• The first stage is the Cluster Analysis
1. Detects automatically the available GPUs and
CPUs in each node
2. For each platform in each node (GPU or CPU) do
• If GPU Nvidia: CUDA 3D-FWT calculates
automatically block size and the number of
streams
• If GPU ATI: OpenCL 3D-FWT computes
automatically work-group size
• If CPU: Tiling and pthreads fast analysis to
obtain the best n threads
• Send one sequence Computer
performance of the 3D-FWT kernel
3. Measures the performance of the interconnection
network among the nodes
Cluster Analysis
Cluster Performance
Map
Theoretical Searching of the Best Number
of Slave Nodes
Best Number of Slave Nodes

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
18
Motivation
Why the number of streams is so important?

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
19
Motivation
• Nvidia Fermi GPU and Kepler GPU
crucial for the incorporation of streams
as a key factor in codes
• One most difficult challenges for the
GPU architecture optimal scheduler
to manage the workload composed of
different streams in a GPU

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
20
Motivation
• Nvidia Fermi GPU and Kepler GPU
crucial for the incorporation of streams
as a key factor in codes
• One most difficult challenges for the
GPU architecture optimal scheduler
to manage the workload composed of
different streams in a GPU

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
21
Motivation
• The Fermi GPU architecture allows a concurrency execution of up to 16
streams, but there is a single hardware queue and the streams must be
multiplexed and serialized

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
22
Motivation
• The Kepler GPU architecture introduces Hyper-Q, which enables up to 32
hardware queues allowing great flexibility to improve the performance
without modifications to the source codes

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
23
Motivation
• A slight difference among execution times is observed for different block sizes in both GPUs. In
fact, the maximum difference is about 16% in Fermi GPU and 6% in Kepler GPU
• Speedups when using several streams with respect to the execution with a single stream is in the
range of 1.31 to 1.68 for the Fermi GPU and 1.28 to 1.56 for the Kepler GPU

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
25
Outline
Introduction and Motivation
An enhanced autotuning engine for the 3D-FWT
Experimental Results
Conclusions and Future work

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
26
Outline
Introduction and Motivation
An enhanced autotuning engine for the 3D-FWT
Experimental Results
Conclusions and Future work

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
27
An enhanced autotuning engine for the 3D-FWT
• The first stage is the Cluster Analysis
1. Detects automatically the available GPUs and
CPUs in each node
2. For each platform in each node (GPU or CPU) do
• If GPU Nvidia: CUDA 3D-FWT calculates
automatically block size
• If GPU ATI: OpenCL 3D-FWT computes
automatically work-group size
• If CPU: Tiling and pthreads fast analysis to
obtain the best n threads
• Send one sequence Computer
performance of the 3D-FWT kernel
3. Measures the performance of the interconnection
network among the nodes
Cluster Analysis
Cluster Performance
Map
Theoretical Searching of the Best Number
of Slave Nodes
Best Number of Slave Nodes

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
28
An enhanced autotuning engine for the 3D-FWT
• The first stage is the Cluster Analysis
1. Detects automatically the available GPUs and
CPUs in each node
2. For each platform in each node (GPU or CPU) do
• If GPU Nvidia: CUDA 3D-FWT calculates
automatically block size and the number of
streams
• If GPU ATI: OpenCL 3D-FWT computes
automatically work-group size
• If CPU: Tiling and pthreads fast analysis to
obtain the best n threads
• Send one sequence Computer
performance of the 3D-FWT kernel
3. Measures the performance of the interconnection
network among the nodes
Cluster Analysis
Cluster Performance
Map
Theoretical Searching of the Best Number
of Slave Nodes
Best Number of Slave Nodes

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
30
An enhanced autotuning engine for the 3D-FWT
• function f(block, stream)

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
31
An enhanced autotuning engine for the 3D-FWT
• function f(block, stream)

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
32
An enhanced autotuning engine for the 3D-FWT
• function f(block, stream)
Set of block sizes

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
33
An enhanced autotuning engine for the 3D-FWT
• function f(block, stream)
Set of block sizes
Set of number of
streams

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
34
An enhanced autotuning engine for the 3D-FWT
• function f(block, stream)
Set of block sizes
Set of number of
streams
The minimum execution
time

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
35
An enhanced autotuning engine for the 3D-FWT
• function f(block, stream)
Reducing the number of possible evaluations
Set of block sizes
Set of number of
streams
The minimum execution
time

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
36
An enhanced autotuning engine for the 3D-FWT
• function f(block, stream)
1. Occupancy of each multiprocessor for a set of block sizes select all the
block sizes that reach at least 60% occupancy of each multiprocessor
2. Selects a first block size and obtains execution times for several number of
streams. The minimum ET is selected (best time).
3. If ET(streams) is > the best time plus a threshold the number of streams
is not considered for the next evaluation of block size
4. For the next block sizes, the analysis is only done for the number of streams
selected in the previous step
5. The output is the minimum execution time (block, stream)

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
37
Outline
Introduction and Motivation
An enhanced autotuning engine for the 3D-FWT
Experimental Results
Conclusions and Future work

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
38
Outline
Introduction and Motivation
An enhanced autotuning engine for the 3D-FWT
Experimental Results
Conclusions and Future work

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
39
Experimental Results For an NVIDIA Tesla K20 GPU with 2496 cores f(block, stream) is executed
Sequence 256 frames 1024 x 1024 pixels
Installation_block_sizes_Set 128, 192, 256, 320, 384, 448, 512
streams_Set 1, 2, 4, 8, 16, 32, 64
Threshold 10%

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
40
Experimental Results For an NVIDIA Tesla K20 GPU with 2496 cores f(block, stream) is executed - 1st Iteration
Sequence 256 frames 1024 x 1024 pixels
Installation_block_sizes_Set 128, 192, 256, 320, 384, 448, 512
streams_Set 1, 2, 4, 8, 16, 32, 64
Threshold 10%
Block size / streams
1 2 4 8 16 32 64 Best_time + 10%
128 568.69 501.68 466.32 467.52 451.67 438.49 414.73 456.20

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
41
Experimental Results For an NVIDIA Tesla K20 GPU with 2496 cores f(block, stream) is executed - 1st Iteration
Sequence 256 frames 1024 x 1024 pixels
Installation_block_sizes_Set 128, 192, 256, 320, 384, 448, 512
streams_Set 1, 2, 4, 8, 16, 32, 64
Threshold 10%
Block size / streams
1 2 4 8 16 32 64 Best_time + 10%
128 568.69 501.68 466.32 467.52 451.67 438.49 414.73 456.20
X

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
42
Experimental Results For an NVIDIA Tesla K20 GPU with 2496 cores f(block, stream) is executed - 1st Iteration
Sequence 256 frames 1024 x 1024 pixels
Installation_block_sizes_Set 128, 192, 256, 320, 384, 448, 512
streams_Set 1, 2, 4, 8, 16, 32, 64
Threshold 10%
Block size / streams
1 2 4 8 16 32 64 Best_time + 10%
128 568.69 501.68 466.32 467.52 451.67 438.49 414.73 456.20
X X

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
43
Experimental Results For an NVIDIA Tesla K20 GPU with 2496 cores f(block, stream) is executed - 1st Iteration
Sequence 256 frames 1024 x 1024 pixels
Installation_block_sizes_Set 128, 192, 256, 320, 384, 448, 512
streams_Set 1, 2, 4, 8, 16, 32, 64
Threshold 10%
Block size / streams
1 2 4 8 16 32 64 Best_time + 10%
128 568.69 501.68 466.32 467.52 451.67 438.49 414.73 456.20
X X X

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
44
Experimental Results For an NVIDIA Tesla K20 GPU with 2496 cores f(block, stream) is executed - 1st Iteration
Sequence 256 frames 1024 x 1024 pixels
Installation_block_sizes_Set 128, 192, 256, 320, 384, 448, 512
streams_Set 1, 2, 4, 8, 16, 32, 64
Threshold 10%
Block size / streams
1 2 4 8 16 32 64 Best_time + 10%
128 568.69 501.68 466.32 467.52 451.67 438.49 414.73 456.20
X X X X

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
45
Experimental Results For an NVIDIA Tesla K20 GPU with 2496 cores f(block, stream) is executed – 2nd Iteration
Sequence 256 frames 1024 x 1024 pixels
Installation_block_sizes_Set 128, 192, 256, 320, 384, 448, 512
streams_Set 16, 32, 64
Threshold 10%
Block size / streams
1 2 4 8 16 32 64 Best_time + 10%
128 568.69 501.68 466.32 467.52 451.67 438.49 414.73 456.20
192 447.05 433.93 410.18 451.20

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
46
Experimental Results For an NVIDIA Tesla K20 GPU with 2496 cores f(block, stream) is executed – 3rd – 6th Iteration
Sequence 256 frames 1024 x 1024 pixels
streams_Set 16, 32, 64
Block size / streams
1 2 4 8 16 32 64 Best_time + 10%
128 568.69 501.68 466.32 467.52 451.67 438.49 414.73 456.20
192 447.05 433.93 410.18 451.20
256 434.33 439.08 415.91 457.50
320 444.47 431.28 409.68 450.65
384 442.41 428.84 405.37 445.91
448 448.94 435.84 414.54 445.91

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
47
Experimental Results For an NVIDIA Tesla K20 GPU with 2496 cores f(block, stream) is executed – 3rd – 6th Iteration
Sequence 256 frames 1024 x 1024 pixels
streams_Set 16, 32, 64
Block size / streams
1 2 4 8 16 32 64 Best_time + 10%
128 568.69 501.68 466.32 467.52 451.67 438.49 414.73 456.20
192 447.05 433.93 410.18 451.20
256 434.33 439.08 415.91 457.50
320 444.47 431.28 409.68 450.65
384 442.41 428.84 405.37 445.91
448 448.94 435.84 414.54 445.91
X

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
48
Experimental Results For an NVIDIA Tesla K20 GPU with 2496 cores f(block, stream) is executed – 7th Iteration
Sequence 256 frames 1024 x 1024 pixels
streams_Set 32, 64
Block size / streams
1 2 4 8 16 32 64 Best_time + 10%
128 568.69 501.68 466.32 467.52 451.67 438.49 414.73 456.20
192 447.05 433.93 410.18 451.20
256 434.33 439.08 415.91 457.50
320 444.47 431.28 409.68 450.65
384 442.41 428.84 405.37 445.91
448 448.94 435.84 414.54 445.91
512 438.99 416.87 445.91

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
49
Experimental Results For an NVIDIA Tesla K20 GPU with 2496 cores f(block, stream) is executed
Block size / streams
1 2 4 8 16 32 64 Best_time + 10%
128 568.69 501.68 466.32 467.52 451.67 438.49 414.73 456.20
192 447.05 433.93 410.18 451.20
256 434.33 439.08 415.91 457.50
320 444.47 431.28 409.68 450.65
384 442.41 428.84 405.37 445.91
448 448.94 435.84 414.54 445.91
512 438.99 416.87 445.91
• The autotuning engine obtains the minimum execution time, reducing the
number of executed evaluations from the 56 total possible to 24
• Our enhanced automatical method achieves the optimal configuration with a
block size of 384 and 64 streams in 10.61 secs.

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
50
Experimental Results For a sequence of video of 10 hours with 25 frames per second, split in group of 256 frames
Execution times (seconds) – 900,000 frames 1024 x 1024
Autotuning engine (block size=384, streams=64) 23.75 minutes
Non-expert user (block size=64, streams=1) 34.38 minutes
Expert user (block size=optimal, streams=32) 25.13 minutes
• Non-expert user has not knowledge to properly select the block size and
the number of streams (selecting 64 as the block size and 1 as the
number of streams)
• Expert user, who selects the optimal block size and establishes the
number of streams to 32 (which is the number of hardware queues in a
Tesla K20 GPU)
• Speedups of 1.45 and 1.06 with regard to non-expert user, expert user
CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
51
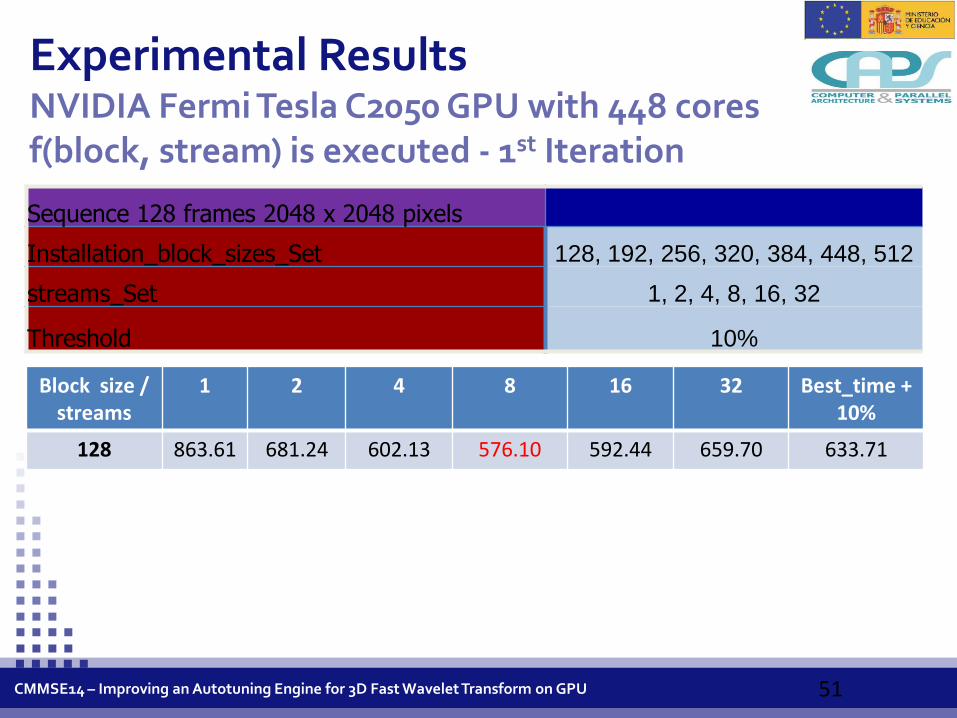
Experimental Results NVIDIA Fermi Tesla C2050 GPU with 448 cores f(block, stream) is executed - 1st Iteration
Sequence 128 frames 2048 x 2048 pixels
Installation_block_sizes_Set 128, 192, 256, 320, 384, 448, 512
streams_Set 1, 2, 4, 8, 16, 32
Threshold 10%
Block size / streams
1 2 4 8 16 32 Best_time + 10%
128 863.61 681.24 602.13 576.10 592.44 659.70 633.71

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
52
Experimental Results NVIDIA Fermi Tesla C2050 GPU with 448 cores f(block, stream) is executed - 1st Iteration
Sequence 128 frames 2048 x 2048 pixels
Installation_block_sizes_Set 128, 192, 256, 320, 384, 448, 512
streams_Set 1, 2, 4, 8, 16, 32
Threshold 10%
Block size / streams
1 2 4 8 16 32 Best_time + 10%
128 863.61 681.24 602.13 576.10 592.44 659.70 633.71
X

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
53
Experimental Results NVIDIA Fermi Tesla C2050 GPU with 448 cores f(block, stream) is executed - 1st Iteration
Sequence 128 frames 2048 x 2048 pixels
Installation_block_sizes_Set 128, 192, 256, 320, 384, 448, 512
streams_Set 1, 2, 4, 8, 16, 32
Threshold 10%
Block size / streams
1 2 4 8 16 32 Best_time + 10%
128 863.61 681.24 602.13 576.10 592.44 659.70 633.71
X X

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
54
Experimental Results NVIDIA Fermi Tesla C2050 GPU with 448 cores f(block, stream) is executed - 1st Iteration
Sequence 128 frames 2048 x 2048 pixels
Installation_block_sizes_Set 128, 192, 256, 320, 384, 448, 512
streams_Set 1, 2, 4, 8, 16, 32
Threshold 10%
Block size / streams
1 2 4 8 16 32 Best_time + 10%
128 863.61 681.24 602.13 576.10 592.44 659.70 633.71
X X X

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
55
Experimental Results NVIDIA Fermi Tesla C2050 GPU with 448 cores f(block, stream) is executed – 2nd Iteration
Sequence 128 frames 2048 x 2048 pixels
Installation_block_sizes_Set 128, 192, 256, 320, 384, 448, 512
streams_Set 4, 8, 16
Threshold 10%
Block size / streams
1 2 4 8 16 32 Best_time + 10%
128 863.61 681.24 602.13 576.10 592.44 659.70 633.71
192 583,30 557,59 574,58 613,35

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
56
Experimental Results NVIDIA Fermi Tesla C2050 GPU with 448 cores f(block, stream) is executed – 3rd - 7th Iteration
Sequence 128 frames 2048 x 2048 pixels
streams_Set 4, 8, 16
Block size / streams
1 2 4 8 16 32 Best_time + 10%
128 863.61 681.24 602.13 576.10 592.44 659.70 633.71
192 583.30 557.59 574.58 613.35
256 589,62 564,49 581,43 620,94
320 590,83 566,25 583,10 622,88
384 576,60 551,35 567,44 606,49
448 581,87 557,56 574,57 606,49
512 594,44 569,55 586,08 606,49

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
57
Experimental Results NVIDIA Fermi Tesla C2050 GPU with 448 cores f(block, stream) is executed Block size /
streams 1 2 4 8 16 32 Best_time +
10%
128 863.61 681.24 602.13 576.10 592.44 659.70 633.71
192 583.30 557.59 574.58 613.35
256 589,62 564,49 581,43 620,94
320 590,83 566,25 583,10 622,88
384 576,60 551,35 567,44 606,49
448 581,87 557,56 574,57 606,49
512 594,44 569,55 586,08 606,49
• The optimization engine obtains the minimum execution time, executing 50%
of the total evaluations in 14.33 secs.
• The best time is 551.35 msecs. achieved by 384 block size and 8 streams

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
58
Experimental Results For a sequence of video of 10 hours with 25 frames per second, split in group of 128 frames
Execution times (seconds) – 900,000 frames 2048 x 2048
Autotuning engine (block size=384, streams=64) 64.61 minutes
Non-expert user (block size=64, streams=1) 107.73 minutes
Expert user (block size=optimal, streams=1) 97.48 minutes
Expert user (block size=optimal, streams=16) 66.50 minutes
• Non-expert user has not knowledge to properly select the block size and
the number of streams
• Expert user, who selects the optimal block size and establishes the
number of streams to 1 or 16 (which are the number of theoretical
streams allowed in concurrency and the hardware queues in a Fermi
Tesla C2050 GPU)
• Speedups of 1.45 and 1.06 with regard to non-expert user, expert user

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
59
Experimental Results For a sequence of video of 10 hours with 25 frames per second, split in group of 128 frames
Execution times (seconds) – 900,000 frames 2048 x 2048
Autotuning engine (block size=384, streams=64) 64.61 minutes
Non-expert user (block size=64, streams=1) 107.73 minutes
Expert user (block size=optimal, streams=1) 97.48 minutes
Expert user (block size=optimal, streams=16) 66.50 minutes
• Speedups of 1.67 with regard to a non-expert user
• Speedups of 1.51 and 1.02 depending of the selection of 1 or 16 streams
by an expert user

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
60
Outline
Introduction and Motivation
Autotuning architecture to run the 3D-FWT kernel automatically on clusters
Experimental Results
Conclusions and Future work

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
61
Outline
Introduction and Motivation
Autotuning architecture to run the 3D-FWT kernel automatically on clusters
Experimental Results
Conclusions and Future work

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
63
Conclusions
• An extension of a previously proposed optimization engine to run the
3D-FWT kernel automatically on integrated systems with different
platforms such as multicore CPU and manycore GPUs
• The autotuning method
Reducing the number of possible evaluations
• Speedups of up to 1.45x for the NVIDIA Tesla K20 and 1.67 for the
Fermi Tesla C2050 with respect to a user with no knowledge in
selecting the optimal block size and the number of streams
• For expert users, who select the optimal block size and know the
architecture of the GPUs, the autotuning engine achieves speedups up
to 1.51x
Set of block sizes
Set of number of
streams
The minimum
execution time

CMMSE14 – Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU
64
Future work
• The methodology applied to propose the
optimization engine should be applicable to other
complex compute applications
• Our work is part of the development of an image
processing library oriented to biomedical
applications, allowing users the efficient executions
of different routines automatically

Conference title 65
Improving an Autotuning Engine for 3D Fast Wavelet Transform on GPU G. Bernabé†, J. Cuenca† , Luis P. García* and D. Giménez‡
† Computer Engineering Department, University of Murcia * Technical Research Service, Technical University of Cartagena ‡ Computer Science and Systems Department, University of Murcia 3-7 July, 2014
14th International Conference on Computational and Mathematical Methods
in Science and Engineering (CMMSE 2014)
Recommended

















