Embed Size (px)
Citation preview

Warp Processing – Towards FPGA Ubiquity
Frank Vahid Professor
Department of Computer Science and EngineeringUniversity of California, Riverside
Associate Director, Center for Embedded Computer Systems, UC Irvine
Work supported by the National Science Foundation, the Semiconductor Research Corporation, Xilinx, Intel, and Freescale
Contributing Students: Roman Lysecky (PhD 2005, now asst. prof. at U. Arizona), Greg Stitt (PhD 2006), Kris Miller (MS 2007), David Sheldon (3rd yr PhD), Ryan Mannion (2nd yr PhD), Scott Sirowy (1st
yr PhD)

Frank Vahid, UC Rivers
ide
2/39
Outline FPGAs
Why they’re great Why they’re not ubiquitous yet
Hiding FPGAs from programmers Warp processing
Binary decompilation Just-in-time FPGA compilation
Directions

Frank Vahid, UC Rivers
ide
3/39
FPGAs
FPGA -- Field-Programmable Gate Array Implement circuit by downloading bits
N-address memory (“LUT”) implements N-input combinational logic Register-controlled switch matrix (SM) connects LUTs FPGA fabric
Thousands of LUTs and SMs, increasingly additional hard core components like multipliers, RAM, etc.
CAD tools automatically map desired circuit onto FPGA fabric
a ba1
a0
4x2 Memory
ab
1010
1110
d1 d0
F G
00011011
Implement circuit by downloading particular
bits
LUTF G
2x2 switch matrix
x
y
01
01
1 0a
b
FPGASM
SM
SM
SM
SM
SM
SM
LUT
SM
SM
SM
SM
SM
LUT
01
11
11 01
001111...
10 11
000101...
Frank Vahid, UC Rivers
ide
4/39
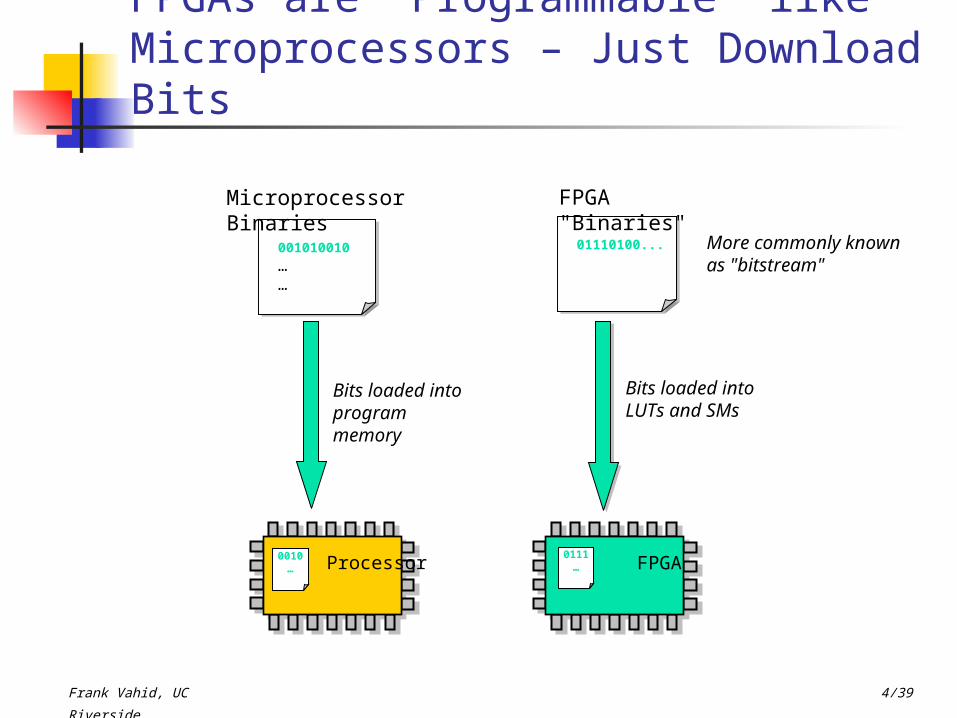
FPGAs are "Programmable" like Microprocessors – Just Download Bits
Processor Processor
001010010……
001010010……
0010…
Bits loaded into program memory
Microprocessor Binaries
001010010……
01110100...
Bits loaded into LUTs and SMs
FPGA "Binaries"
Processor FPGA0111
…
More commonly known as "bitstream"
Frank Vahid, UC Rivers
ide
5/39
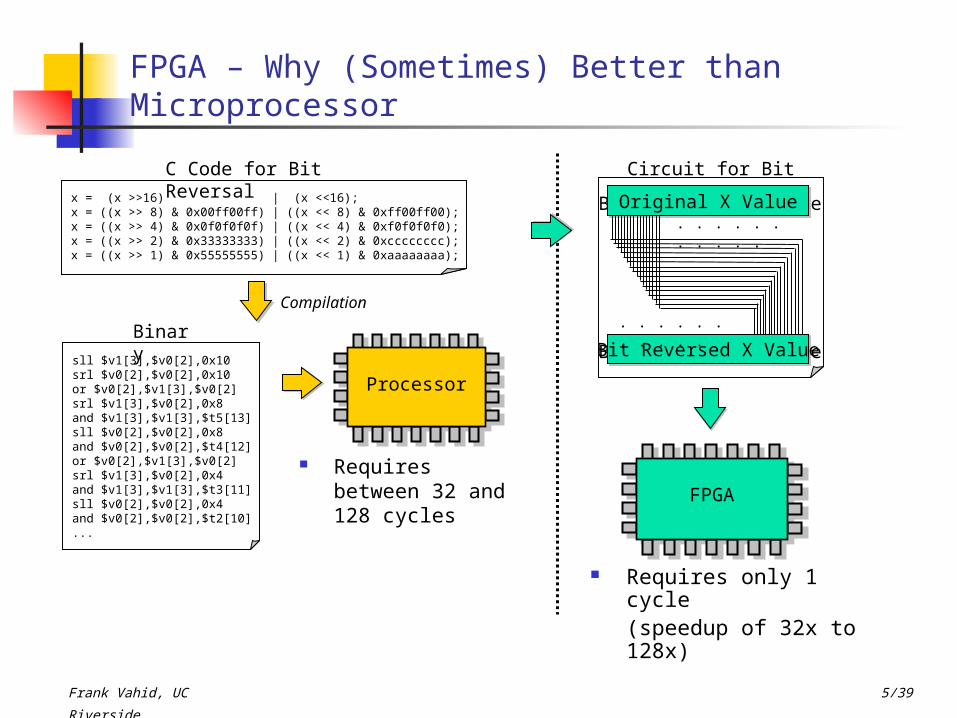
FPGA – Why (Sometimes) Better than Microprocessor
x = (x >>16) | (x <<16);x = ((x >> 8) & 0x00ff00ff) | ((x << 8) & 0xff00ff00);x = ((x >> 4) & 0x0f0f0f0f) | ((x << 4) & 0xf0f0f0f0);x = ((x >> 2) & 0x33333333) | ((x << 2) & 0xcccccccc);x = ((x >> 1) & 0x55555555) | ((x << 1) & 0xaaaaaaaa);
C Code for Bit Reversal
sll $v1[3],$v0[2],0x10srl $v0[2],$v0[2],0x10or $v0[2],$v1[3],$v0[2]srl $v1[3],$v0[2],0x8and $v1[3],$v1[3],$t5[13]sll $v0[2],$v0[2],0x8and $v0[2],$v0[2],$t4[12]or $v0[2],$v1[3],$v0[2]srl $v1[3],$v0[2],0x4and $v1[3],$v1[3],$t3[11]sll $v0[2],$v0[2],0x4and $v0[2],$v0[2],$t2[10]...
Binary
Compilation
ProcessorProcessor
Requires between 32 and 128 cycles
Circuit for Bit Reversal
Bit Reversed X Value
Bit Reversed X ValueBit Reversed X Value
. . . . . . . . . . .
. . . . . . . . . . .
Original X Value
ProcessorFPGA
Requires only 1 cycle (speedup of 32x to 128x)
Frank Vahid, UC Rivers
ide
6/39
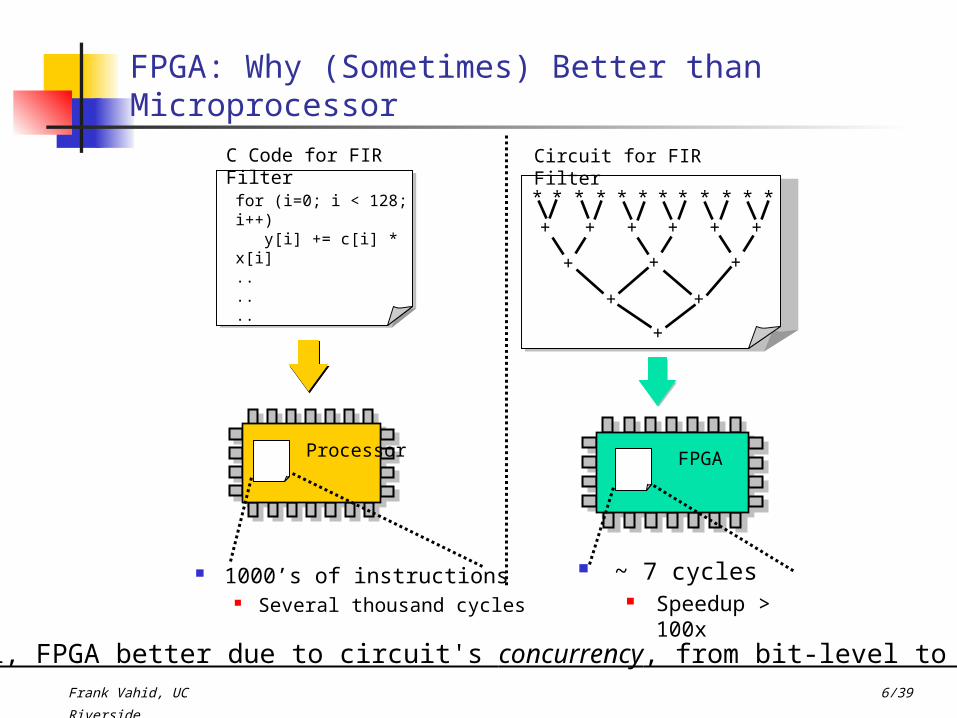
for (i=0; i < 128; i++) y[i] += c[i] * x[i]......
FPGA: Why (Sometimes) Better than Microprocessor
for (i=0; i < 128; i++) y[i] += c[i] * x[i]......
* * * * * * * * * * * *
+ + + + + +
+ + +
+ +
+
C Code for FIR Filter
Processor Processor
1000’s of instructions Several thousand cycles
Circuit for FIR Filter
Processor FPGA
~ 7 cycles Speedup >
100xIn general, FPGA better due to circuit's concurrency, from bit-level to task level
Frank Vahid, UC Rivers
ide
7/39
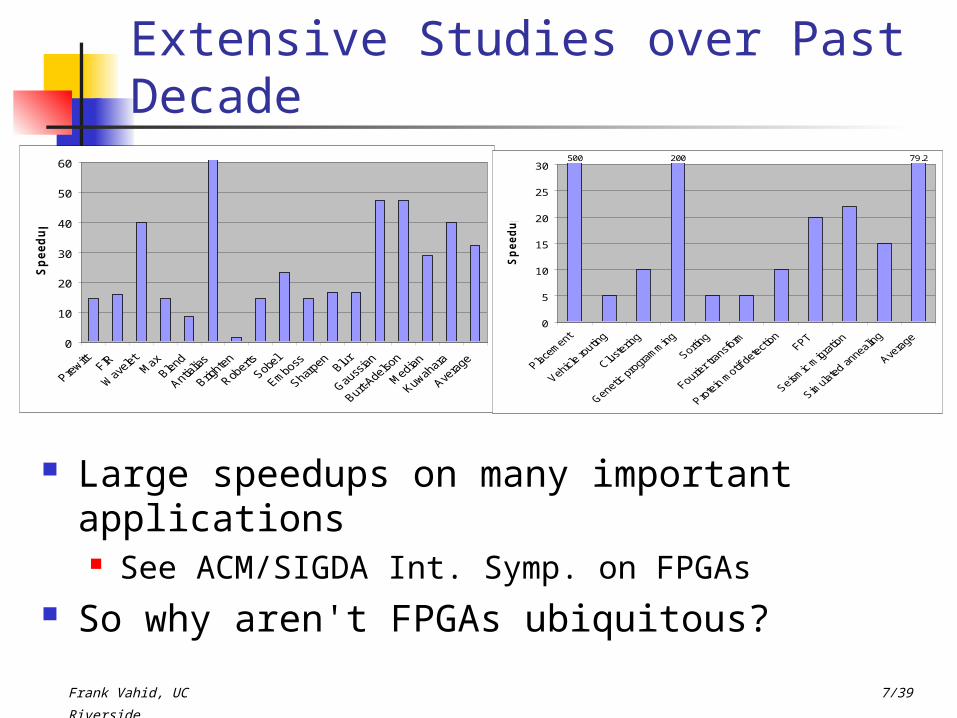
Extensive Studies over Past Decade
Large speedups on many important applications See ACM/SIGDA Int. Symp. on FPGAs
So why aren't FPGAs ubiquitous?
0
10
20
30
40
50
60
Sp
ee
du
p
79.2200500
0
5
10
15
20
25
30
Sp
ee
du
p
Frank Vahid, UC Rivers
ide
8/39
Why FPGAs aren’t Mainstream
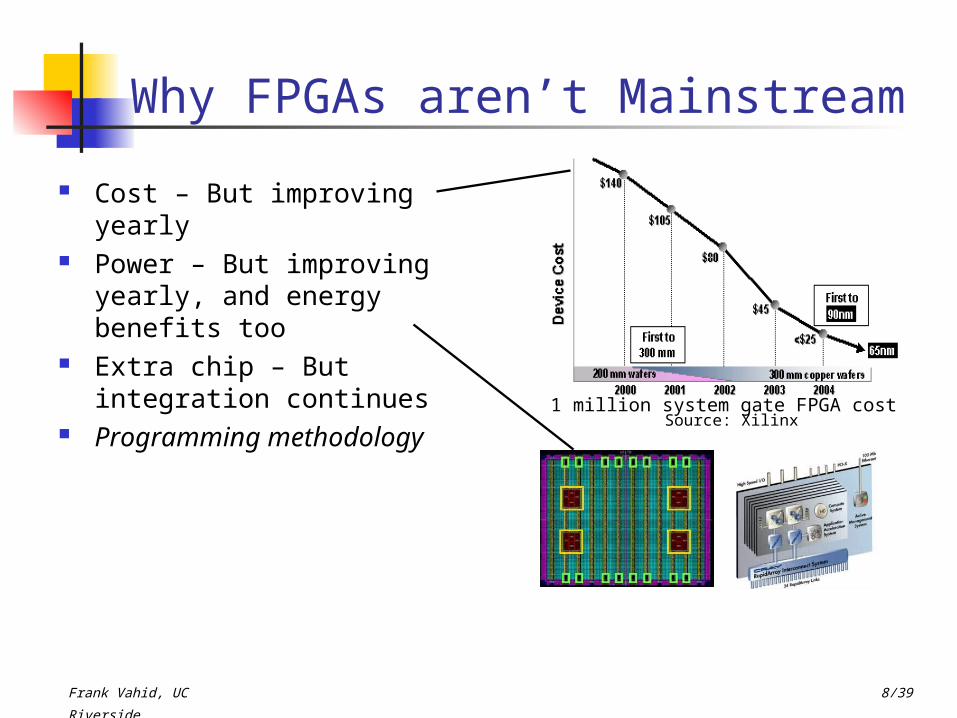
Cost – But improving yearly Power – But improving
yearly, and energy benefits too
Extra chip – But integration continues
Programming methodologySource: Xilinx
1 million system gate FPGA cost

Frank Vahid, UC Rivers
ide
9/39
Why FPGAs aren’t Mainstream Cost Power Extra chip Programming methodology
Though tremendous progress in past decade
Implementation
Assembly code
Microprocessor binary FPGA binary
Logic equations / FSMs
Register transfersCompilation (1960s, 1970s)
Assembling, linking (1950s, 1960s)
Behavioral synthesis(1990s)
RT synthesis(1980s, 1990s)
Logic synthesis, physical design(1970s, 1980s)
Microprocessors FPGA circuits
Automated hardware/software partitioning
C/C++/Java C/C++/Java/VHDL/Verilog/SystemC/Handel-C/Streams-C...
Application (C/C++/Java/SystemC/Handel-C/Streams-C/…)
Downloading Downloading
Frank Vahid, UC Rivers
ide
10/39
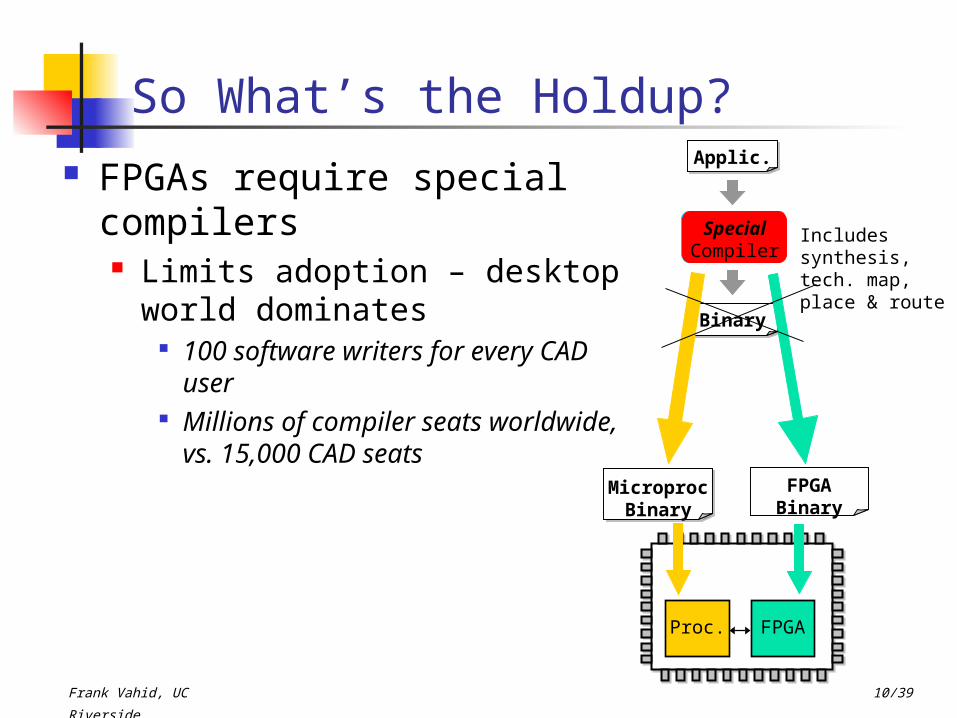
So What’s the Holdup? FPGAs require special
compilers Limits adoption – desktop
world dominates 100 software writers for every
CAD user Millions of compiler seats
worldwide, vs. 15,000 CAD seats
BinaryApplic.
StandardCompiler
BinaryBinary
FPGA Binary
Microproc Binary
FPGAProc.
Includessynthesis, tech. map,place & route
Special Compiler

Frank Vahid, UC Rivers
ide
11/39
Outline FPGAs
Why they’re great Why they’re not ubiquitous yet
Hiding FPGAs from programmers Warp processing
Binary decompilation Just-in-time FPGA compilation
Directions

Frank Vahid, UC Rivers
ide
12/39
Can we Hide FPGAs from Programmers and Standard Tools?
Example Radically different x86
architectures hidden from programmers and tools
All execute standard x86 binaries On-chip tools dynamically
translate binary to particular architecture
Idea: Hide FPGA from programmers and tools
Download standard binary Have on-chip tools dynamically
translate binary (portions) to FPGA
We call this Warp Processing
BinarySW
ProfilingStandard Compiler
BinaryBinary
Traditionalpartitioningdone here
RISC architecture
Translator
VLIWarchitecture
Translator
FPGAProc.
Translator
Frank Vahid, UC Rivers
ide
13/39
µP
FPGAOn-chip CAD
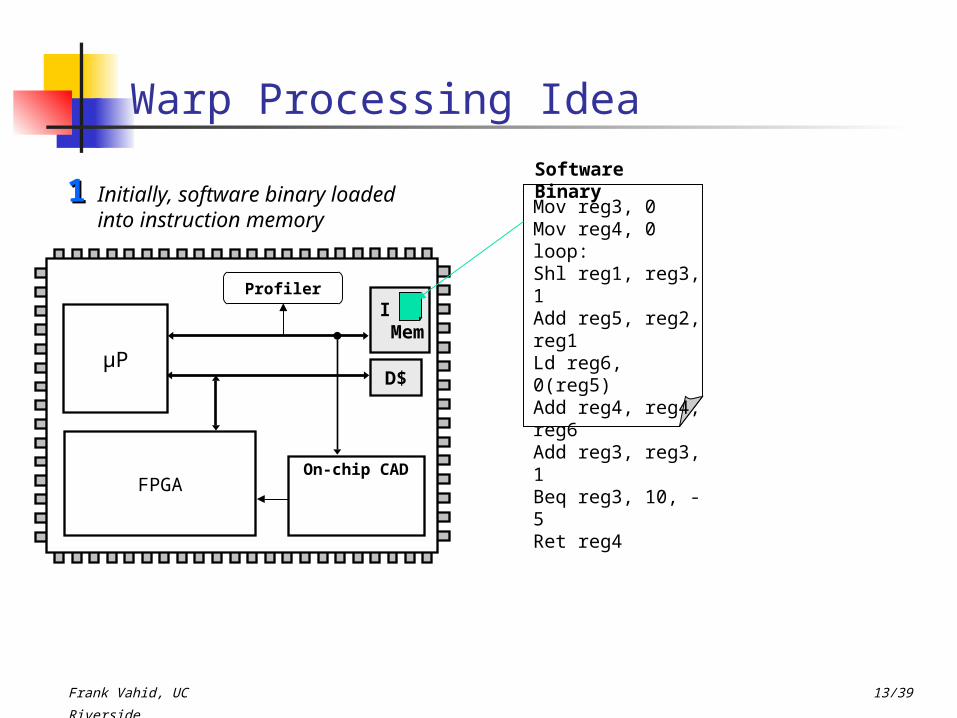
Warp Processing Idea
Profiler
Initially, software binary loaded into instruction memory
11
I Mem
D$
Mov reg3, 0Mov reg4, 0loop:Shl reg1, reg3, 1Add reg5, reg2, reg1Ld reg6, 0(reg5)Add reg4, reg4, reg6Add reg3, reg3, 1Beq reg3, 10, -5Ret reg4
Software Binary
Frank Vahid, UC Rivers
ide
14/39
µP
FPGAOn-chip CAD
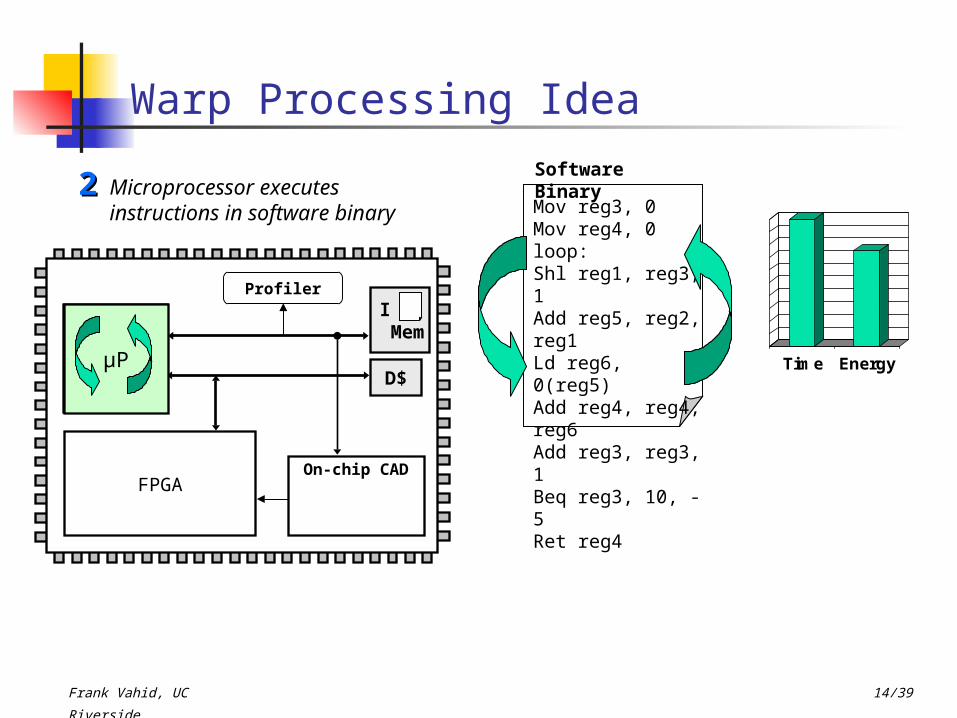
Warp Processing Idea
ProfilerI Mem
D$
Mov reg3, 0Mov reg4, 0loop:Shl reg1, reg3, 1Add reg5, reg2, reg1Ld reg6, 0(reg5)Add reg4, reg4, reg6Add reg3, reg3, 1Beq reg3, 10, -5Ret reg4
Software BinaryMicroprocessor executes
instructions in software binary
22
Time EnergyµP

Frank Vahid, UC Rivers
ide
15/39
µP
FPGAOn-chip CAD
Warp Processing Idea
Profiler
µP
I Mem
D$
Mov reg3, 0Mov reg4, 0loop:Shl reg1, reg3, 1Add reg5, reg2, reg1Ld reg6, 0(reg5)Add reg4, reg4, reg6Add reg3, reg3, 1Beq reg3, 10, -5Ret reg4
Software BinaryProfiler monitors instructions
and detects critical regions in binary
33
Time Energy
Profiler
add
add
add
add
add
add
add
add
add
add
beq
beq
beq
beq
beq
beq
beq
beq
beq
beq
Critical Loop Detected
Frank Vahid, UC Rivers
ide
16/39
µP
FPGAOn-chip CAD
Warp Processing Idea
Profiler
µP
I Mem
D$
Mov reg3, 0Mov reg4, 0loop:Shl reg1, reg3, 1Add reg5, reg2, reg1Ld reg6, 0(reg5)Add reg4, reg4, reg6Add reg3, reg3, 1Beq reg3, 10, -5Ret reg4
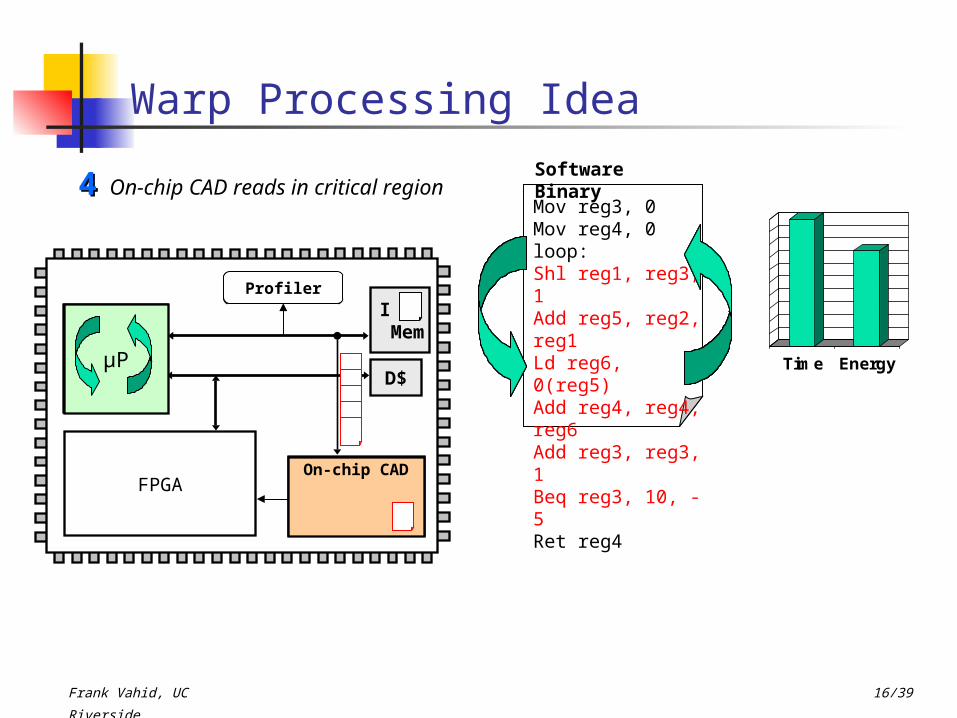
Software BinaryOn-chip CAD reads in critical
region44
Time Energy
Profiler
On-chip CAD
Frank Vahid, UC Rivers
ide
17/39
µP
FPGADynamic Part. Module (DPM)
Warp Processing Idea
Profiler
µP
I Mem
D$
Mov reg3, 0Mov reg4, 0loop:Shl reg1, reg3, 1Add reg5, reg2, reg1Ld reg6, 0(reg5)Add reg4, reg4, reg6Add reg3, reg3, 1Beq reg3, 10, -5Ret reg4
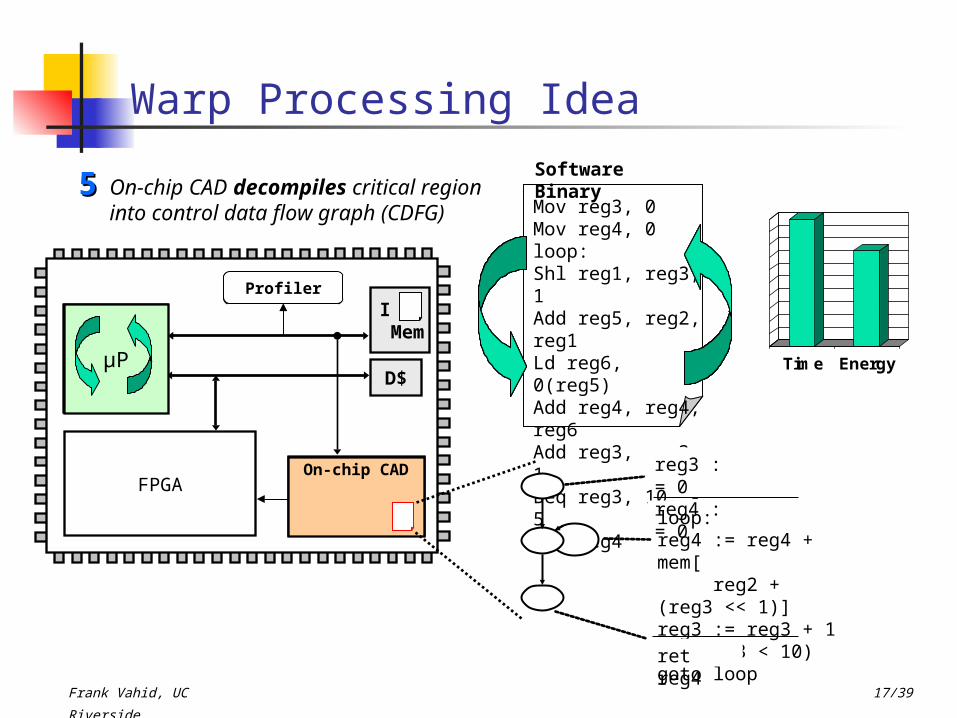
Software BinaryOn-chip CAD decompiles critical
region into control data flow graph (CDFG)
55
Time Energy
Profiler
On-chip CAD
loop:reg4 := reg4 + mem[ reg2 + (reg3 << 1)]reg3 := reg3 + 1if (reg3 < 10) goto loop
ret reg4
reg3 := 0reg4 := 0
Frank Vahid, UC Rivers
ide
18/39
µP
FPGADynamic Part. Module (DPM)
Warp Processing Idea
Profiler
µP
I Mem
D$
Mov reg3, 0Mov reg4, 0loop:Shl reg1, reg3, 1Add reg5, reg2, reg1Ld reg6, 0(reg5)Add reg4, reg4, reg6Add reg3, reg3, 1Beq reg3, 10, -5Ret reg4
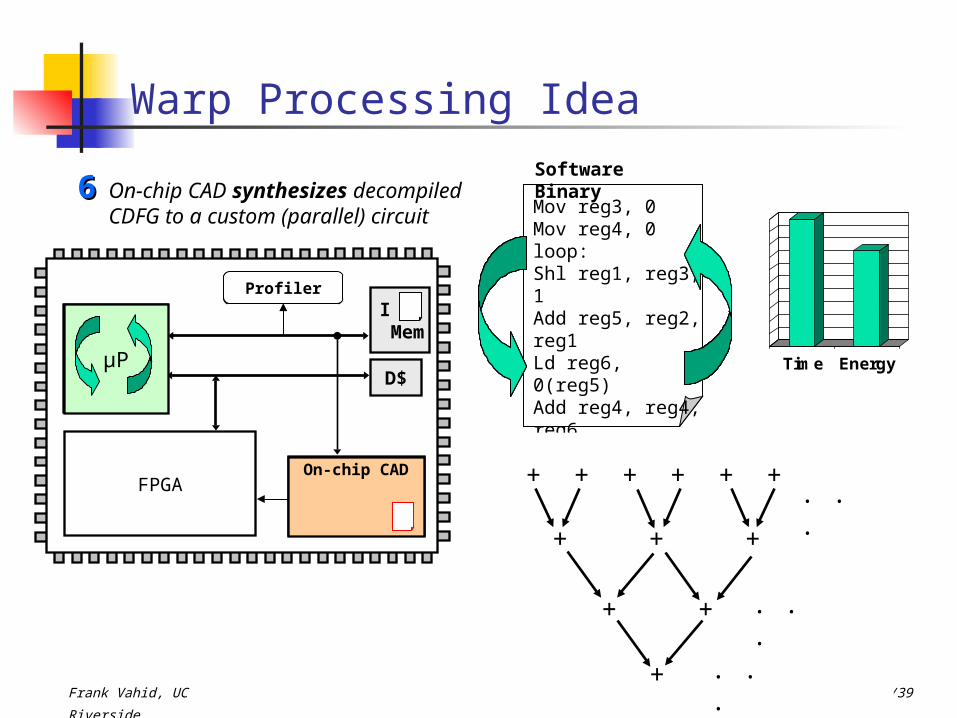
Software BinaryOn-chip CAD synthesizes
decompiled CDFG to a custom (parallel) circuit
66
Time Energy
Profiler
On-chip CAD
loop:reg4 := reg4 + mem[ reg2 + (reg3 << 1)]reg3 := reg3 + 1if (reg3 < 10) goto loop
ret reg4
reg3 := 0reg4 := 0+ + ++ ++
+ ++
+
+
+
. . .
. . .
. . .
Frank Vahid, UC Rivers
ide
19/39
µP
FPGADynamic Part. Module (DPM)
Warp Processing Idea
Profiler
µP
I Mem
D$
Mov reg3, 0Mov reg4, 0loop:Shl reg1, reg3, 1Add reg5, reg2, reg1Ld reg6, 0(reg5)Add reg4, reg4, reg6Add reg3, reg3, 1Beq reg3, 10, -5Ret reg4
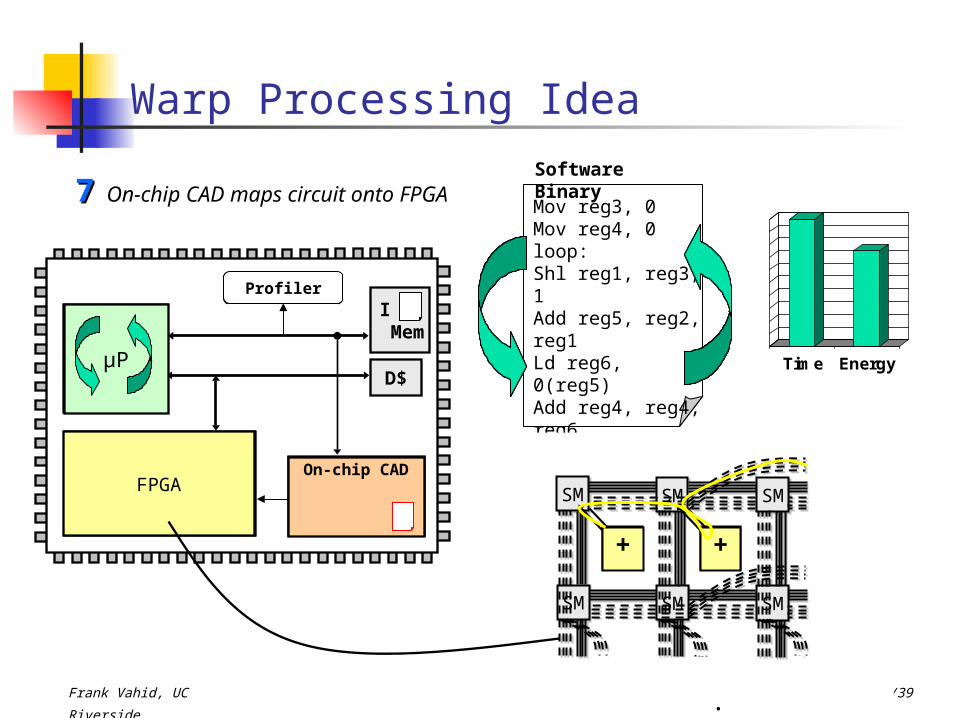
Software BinaryOn-chip CAD maps circuit onto
FPGA77
Time Energy
Profiler
On-chip CAD
loop:reg4 := reg4 + mem[ reg2 + (reg3 << 1)]reg3 := reg3 + 1if (reg3 < 10) goto loop
ret reg4
reg3 := 0reg4 := 0+ + ++ ++
+ ++
+
+
+
. . .
. . .
. . .
FPGA
CLB
CLB
SM
SM
SM
SM
SM
SM
SM
SM
SM
SM
SM
SM
++

Frank Vahid, UC Rivers
ide
20/39
µP
FPGADynamic Part. Module (DPM)
Warp Processing Idea
Profiler
µP
I Mem
D$
Mov reg3, 0Mov reg4, 0loop:Shl reg1, reg3, 1Add reg5, reg2, reg1Ld reg6, 0(reg5)Add reg4, reg4, reg6Add reg3, reg3, 1Beq reg3, 10, -5Ret reg4
Software Binary88
Time Energy
Profiler
On-chip CAD
loop:reg4 := reg4 + mem[ reg2 + (reg3 << 1)]reg3 := reg3 + 1if (reg3 < 10) goto loop
ret reg4
reg3 := 0reg4 := 0
+ + ++ ++
+ ++
+
+
+
. . .
. . .
. . .
CLB
CLB
SM
SM
SM
SM
SM
SM
SM
SM
SM
SM
SM
SM
++
FPGA
On-chip CAD replaces instructions in binary to use hardware, causing performance and energy to “warp” by an order of magnitude or more
Mov reg3, 0Mov reg4, 0loop:// instructions that interact with FPGA
Ret reg4
FPGA
Time Energy
Software-only“Warped”
Frank Vahid, UC Rivers
ide
21/39
µP
FPGAOn-chip CAD
Warp Processing Idea
ProfilerI Mem
D$µP
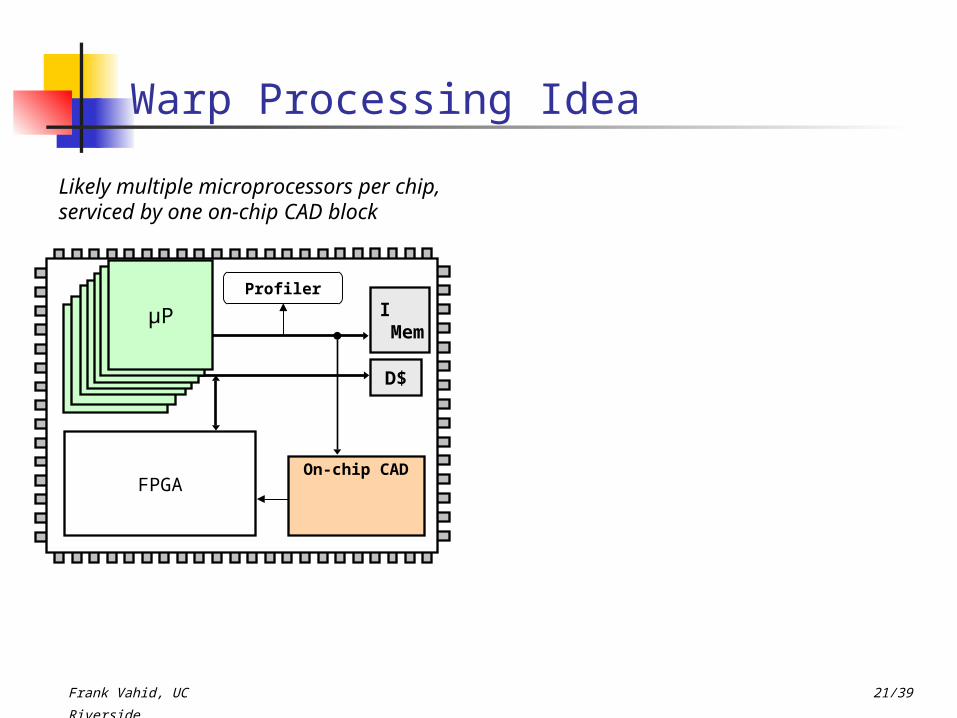
Likely multiple microprocessors per chip, serviced by one on-chip CAD block
µPµPµPµPµP
Frank Vahid, UC Rivers
ide
22/39
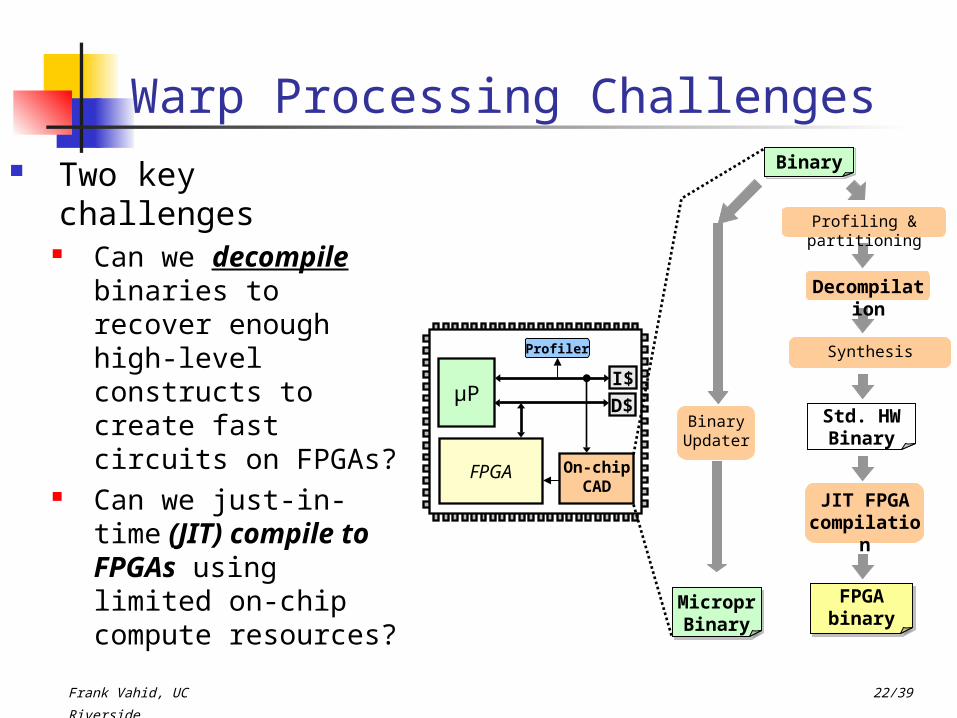
Warp Processing Challenges Two key challenges
Can we decompile binaries to recover enough high-level constructs to create fast circuits on FPGAs?
Can we just-in-time (JIT) compile to FPGAs using limited on-chip compute resources?
µPI$
D$
FPGA
Profiler
On-chip CAD
BinaryBinary
Decompilation
BinaryFPGA binary
Synthesis
Profiling & partitioning
Binary Updater
BinaryMicropr Binary
Std. HW Binary
JIT FPGA compilation
Frank Vahid, UC Rivers
ide
23/39
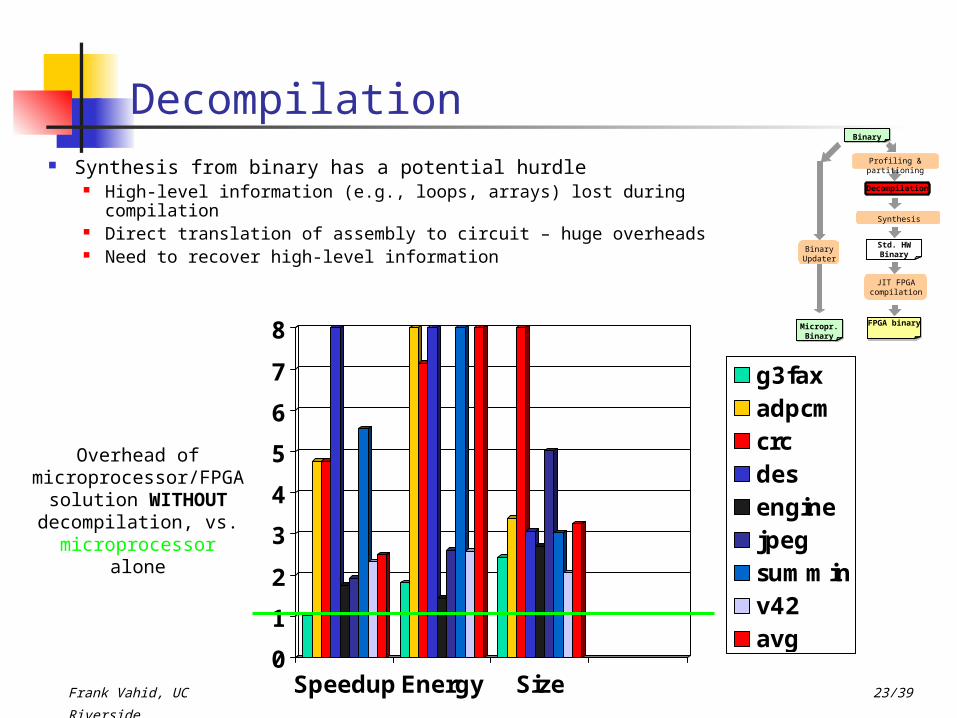
Decompilation Synthesis from binary has a potential hurdle
High-level information (e.g., loops, arrays) lost during compilation Direct translation of assembly to circuit – huge overheads Need to recover high-level information
BinaryBinary
Decompilation
BinaryFPGA binary
Synthesis
Profiling & partitioning
Binary Updater
BinaryMicropr. Binary
Std. HW Binary
JIT FPGA compilation
0
1
2
3
4
5
6
7
8
SpeedupEnergy Size
g3faxadpcmcrcdesenginejpegsumminv42avg
Overhead of microprocessor/FPGA solution WITHOUT decompilation, vs.
microprocessor alone

Frank Vahid, UC Rivers
ide
24/39
Decompilation Solution – Recover high-level information from binary:
decompilation Adapted extensive previous work (for different purposes) Developed new decompilation methods also Ph.D. work of Greg Stitt (Ph.D. UCR 2006) Numerous publications: http://www.cs.ucr.edu/~vahid/pubs
Mov reg3, 0Mov reg4, 0loop:Shl reg1, reg3, 1Add reg5, reg2, reg1Ld reg6, 0(reg5)Add reg4, reg4, reg6Add reg3, reg3, 1Beq reg3, 10, -5Ret reg4
long f( short a[10] ) { long accum; for (int i=0; i < 10; i++) { accum += a[i]; } return accum;}
loop:reg1 := reg3 << 1reg5 := reg2 + reg1reg6 := mem[reg5 + 0]reg4 := reg4 + reg6reg3 := reg3 + 1if (reg3 < 10) goto loop
ret reg4
reg3 := 0reg4 := 0
Control/Data Flow Graph CreationOriginal C Code
Corresponding Assembly
loop:reg4 := reg4 + mem[ reg2 + (reg3 << 1)]reg3 := reg3 + 1if (reg3 < 10) goto loop
ret reg4
reg3 := 0reg4 := 0
Data Flow Analysis
long f( long reg2 ) { int reg3 = 0; int reg4 = 0; loop: reg4 = reg4 + mem[reg2 + reg3 << 1)]; reg3 = reg3 + 1; if (reg3 < 10) goto loop; return reg4;}
Function Recovery
long f( long reg2 ) { long reg4 = 0; for (long reg3 = 0; reg3 < 10; reg3++) { reg4 += mem[reg2 + (reg3 << 1)]; } return reg4;}
Control Structure Recovery
long f( short array[10] ) { long reg4 = 0; for (long reg3 = 0; reg3 < 10; reg3++) { reg4 += array[reg3]; } return reg4; }
Array Recovery
Almost Identical Representations
BinaryBinary
Decompilation
BinaryFPGA binary
Synthesis
Profiling & partitioning
Binary Updater
BinaryMicropr. Binary
Std. HW Binary
JIT FPGA compilation
Frank Vahid, UC Rivers
ide
25/39
Decompilation Results vs. C
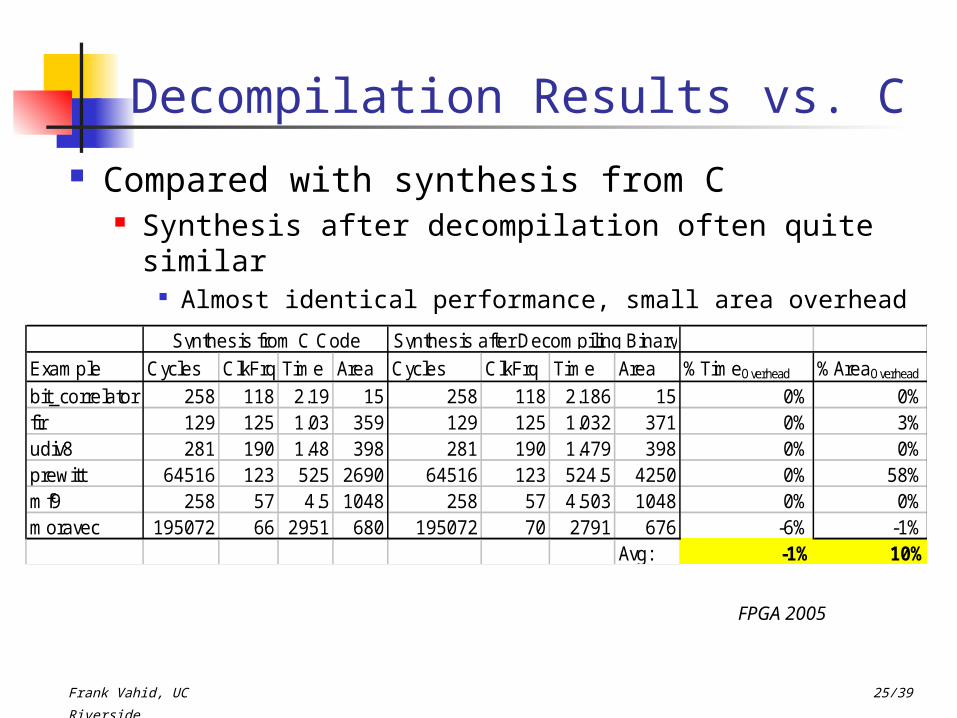
Compared with synthesis from C Synthesis after decompilation often quite
similar Almost identical performance, small area overhead
Example Cycles ClkFrq Time Area Cycles ClkFrq Time Area %TimeOverhead %AreaOverhead
bit_correlator 258 118 2.19 15 258 118 2.186 15 0% 0%fir 129 125 1.03 359 129 125 1.032 371 0% 3%udiv8 281 190 1.48 398 281 190 1.479 398 0% 0%prewitt 64516 123 525 2690 64516 123 524.5 4250 0% 58%mf9 258 57 4.5 1048 258 57 4.503 1048 0% 0%moravec 195072 66 2951 680 195072 70 2791 676 -6% -1%
Avg: -1% 10%
Synthesis from C Code Synthesis after Decompiling Binary
FPGA 2005
Frank Vahid, UC Rivers
ide
26/39
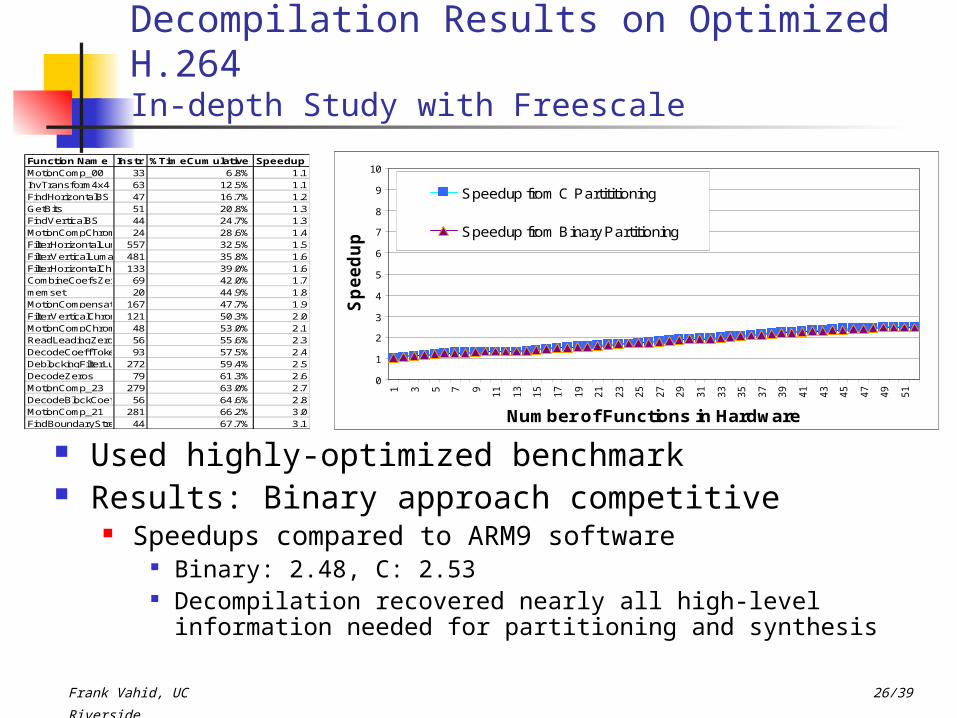
Decompilation Results on Optimized H.264In-depth Study with Freescale
Used highly-optimized benchmark Results: Binary approach competitive
Speedups compared to ARM9 software Binary: 2.48, C: 2.53 Decompilation recovered nearly all high-level information
needed for partitioning and synthesis
Speedup from C Partititioning
0
1
2
3
4
5
6
7
8
9
10
1 3 5 7 9 11
13
15
17
19
21
23
25
27
29
31
33
35
37
39
41
43
45
47
49
51
Number of Functions in Hardware
Sp
ee
du
p
Speedup from C Partititioning
0
1
2
3
4
5
6
7
8
9
10
1 3 5 7 9 11
13
15
17
19
21
23
25
27
29
31
33
35
37
39
41
43
45
47
49
51
Number of Functions in Hardware
Sp
ee
du
p
Speedup from C Partititioning
Speedup from Binary Partitioning
Function Name Instr %TimeCumulative SpeedupMotionComp_00 33 6.8% 1.1InvTransform4x4 63 12.5% 1.1FindHorizontalBS 47 16.7% 1.2GetBits 51 20.8% 1.3FindVerticalBS 44 24.7% 1.3MotionCompChromaFullXFullY24 28.6% 1.4FilterHorizontalLuma 557 32.5% 1.5FilterVerticalLuma 481 35.8% 1.6FilterHorizontalChroma133 39.0% 1.6CombineCoefsZerosInvQuantScan69 42.0% 1.7memset 20 44.9% 1.8MotionCompensate 167 47.7% 1.9FilterVerticalChroma 121 50.3% 2.0MotionCompChromaFracXFracY48 53.0% 2.1ReadLeadingZerosAndOne56 55.6% 2.3DecodeCoeffTokenNormal93 57.5% 2.4DeblockingFilterLumaRow272 59.4% 2.5DecodeZeros 79 61.3% 2.6MotionComp_23 279 63.0% 2.7DecodeBlockCoefLevels56 64.6% 2.8MotionComp_21 281 66.2% 3.0FindBoundaryStrengthPMB44 67.7% 3.1

Frank Vahid, UC Rivers
ide
27/39
Simple Coding Guidelines Bring Speedups Closer to Ideal
Interesting discovery during H264 study – C style limited speedup Orthogonal to binary vs. C issue – coding style hurt both Developed simple coding guidelines Rewritten software: 20 minutes, and only ~3% slower than original New speedups: Binary: 6.55, C: 6.56
Binary still competitive with C Following guidelines not required, but helps any approach targeting FPGAs
0
1
2
3
4
5
6
7
8
9
101 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41 43 45 47 49 51
Number of Functions in Hardware
Sp
eed
up
Ideal Speedup (Zero-time Hw Execution)
Speedup from C Partititioning
Speedup from Binary Partitioning
0
1
2
3
4
5
6
7
8
9
101 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41 43 45 47 49 51
Number of Functions in Hardware
Sp
eed
up
Ideal Speedup (Zero-time Hw Execution)Speedup After Rewrite (C Partitioning)Speedup After Rewrite (Binary Partitioning)Speedup from C PartititioningSpeedup from Binary Partitioning
Frank Vahid, UC Rivers
ide
28/39
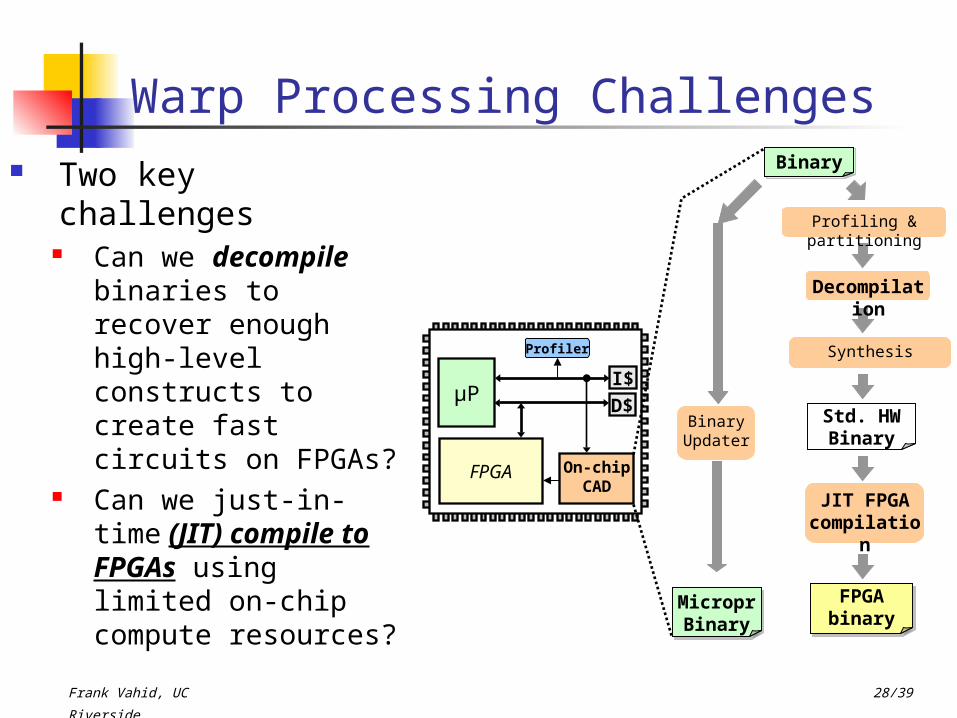
Warp Processing Challenges Two key challenges
Can we decompile binaries to recover enough high-level constructs to create fast circuits on FPGAs?
Can we just-in-time (JIT) compile to FPGAs using limited on-chip compute resources?
µPI$
D$
FPGA
Profiler
On-chip CAD
BinaryBinary
Decompilation
BinaryFPGA binary
Synthesis
Profiling & partitioning
Binary Updater
BinaryMicropr Binary
Std. HW Binary
JIT FPGA compilation

Frank Vahid, UC Rivers
ide
29/39
Developed ultra-lean CAD heuristics for synthesis, placement, routing, and technology mapping; simultaneously developed CAD-oriented FPGA
e.g., Our router (ROCR) 10x faster and 20x less memory than popular VPR tool, at cost of 30% longer critical path. Similar results for synth & placement
Ph.D. work of Roman Lysecky (Ph.D. UCR 2005, now Asst. Prof. at Univ. of Arizona) Numerous publications: http://www.cs.ucr.edu/~vahid/pubs
JIT FPGA Compilation
DAC’04
0
10000
20000
30000
40000
50000
60000
70000
Benchmark
Me
mo
ry
Us
ag
e (
KB
)
VPR (RD) VPR (TD) ROCR
0
10
20
30
40
50
60
Benchmark
Ex
ec
uti
on
Tim
e (
s)
VPR (TD) ROCR
BinaryBinary
Decompilation
BinaryFPGA binary
Synthesis
Profiling & partitioning
Binary Updater
BinaryMicropr. Binary
Std. HW Binary
JIT FPGA compilation

Frank Vahid, UC Rivers
ide
30/39
JIT FPGA Compilation
60 MB
9.1 s
Xilinx ISE
3.6MB1.4s
Riverside JIT FPGA tools on a 75MHz ARM7
3.6MB0.2 s
Riverside JIT FPGA tools
Frank Vahid, UC Rivers
ide
31/39
191 113 130
0
10
20
30
40
50
60
70
80
Spee
dup
Warp Proc.
Xilinx Virtex-E
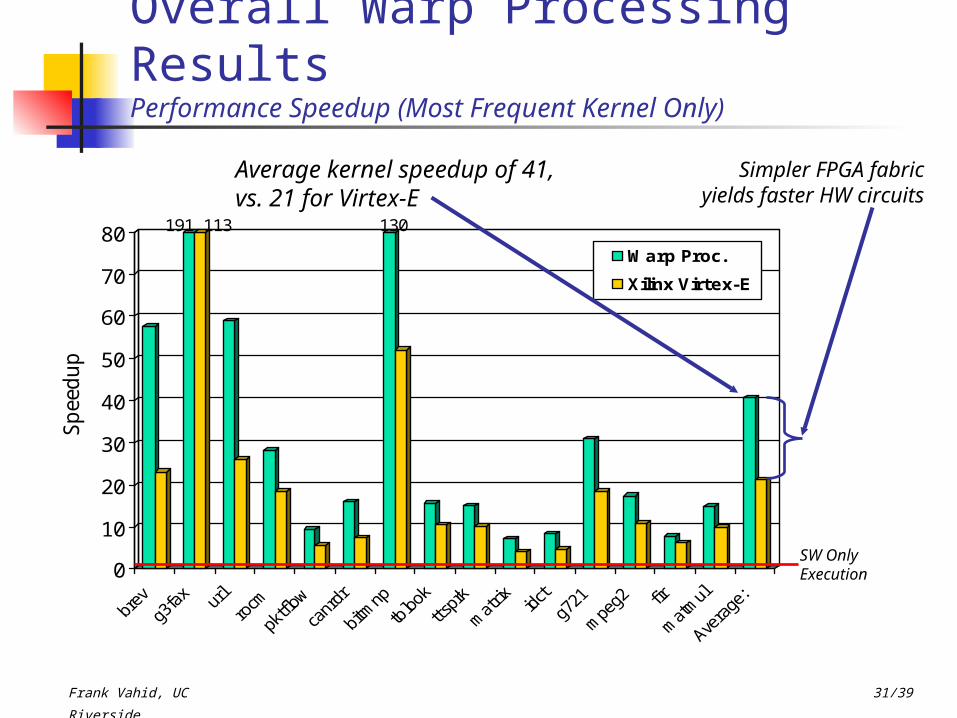
Overall Warp Processing ResultsPerformance Speedup (Most Frequent Kernel Only)
Average kernel speedup of 41, vs. 21 for Virtex-E
SW Only Execution
Simpler FPGA fabric yields faster HW
circuits
Frank Vahid, UC Rivers
ide
32/39
0
2
4
6
8
10
12
14
16
18
Spee
dup
Warp Proc.
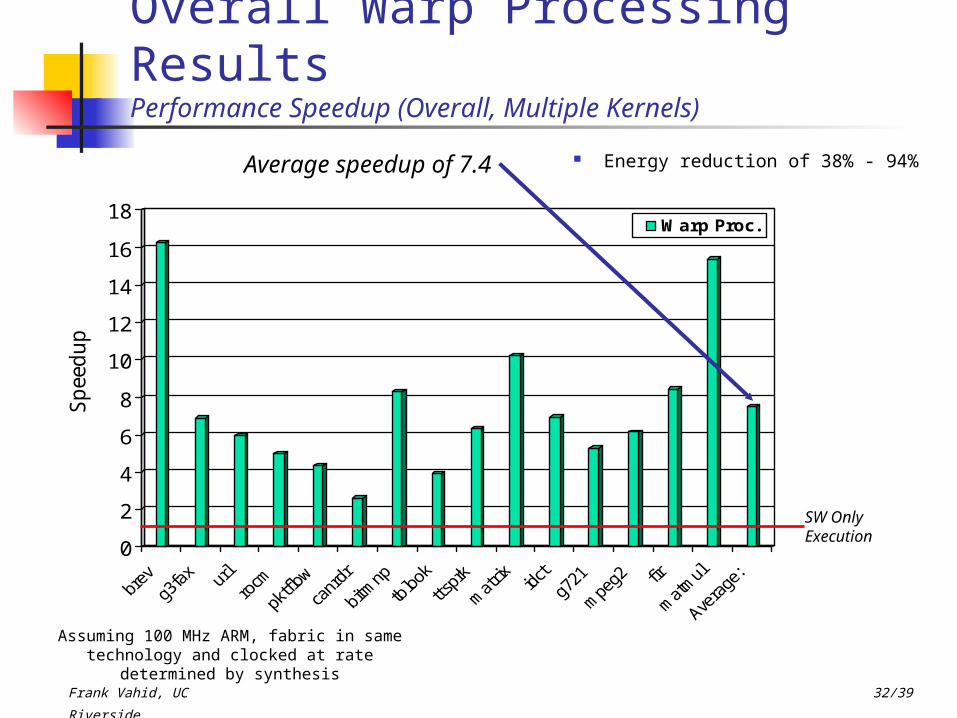
Overall Warp Processing ResultsPerformance Speedup (Overall, Multiple Kernels)
Average speedup of 7.4 Energy reduction of 38% - 94%
SW Only Execution
Assuming 100 MHz ARM, fabric in same technology and clocked at rate determined by
synthesis
Frank Vahid, UC Rivers
ide
33/39
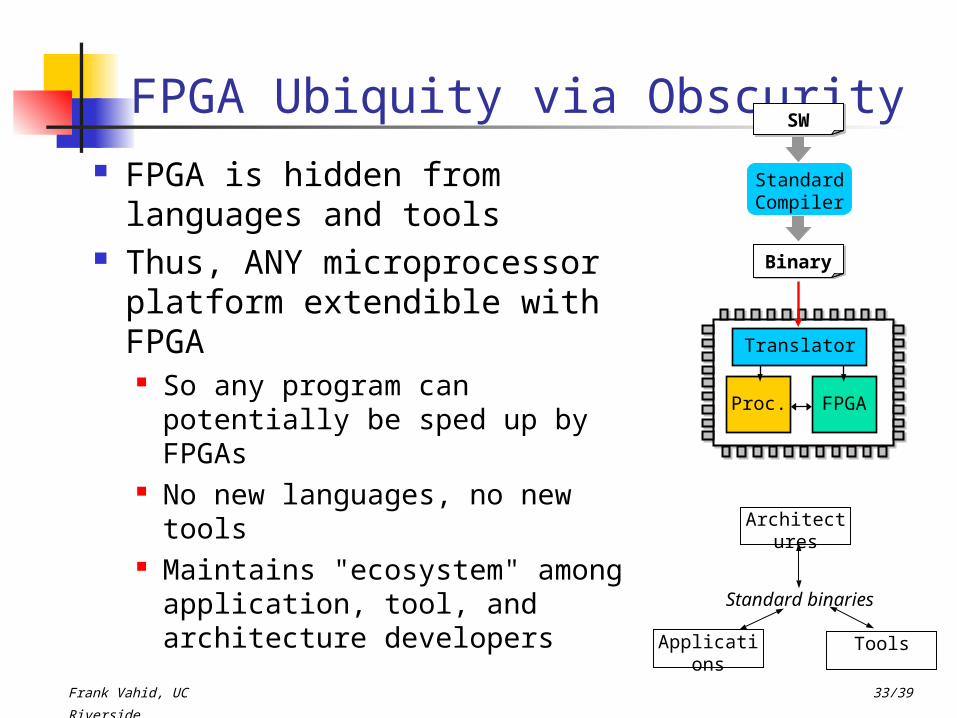
FPGA Ubiquity via Obscurity FPGA is hidden from
languages and tools Thus, ANY microprocessor
platform extendible with FPGA So any program can potentially
be sped up by FPGAs No new languages, no new
tools Maintains "ecosystem" among
application, tool, and architecture developers
FPGAProc.
Translator
BinarySW
ProfilingStandard Compiler
BinaryBinary
Architectures
Applications Tools
Standard binaries

Frank Vahid, UC Rivers
ide
34/39
Outline FPGAs
Why they’re great Why they’re not ubiquitous yet
Hiding FPGAs from programmers Warp processing
Binary decompilation Just-in-time FPGA compilation
Directions
Frank Vahid, UC Rivers
ide
35/39
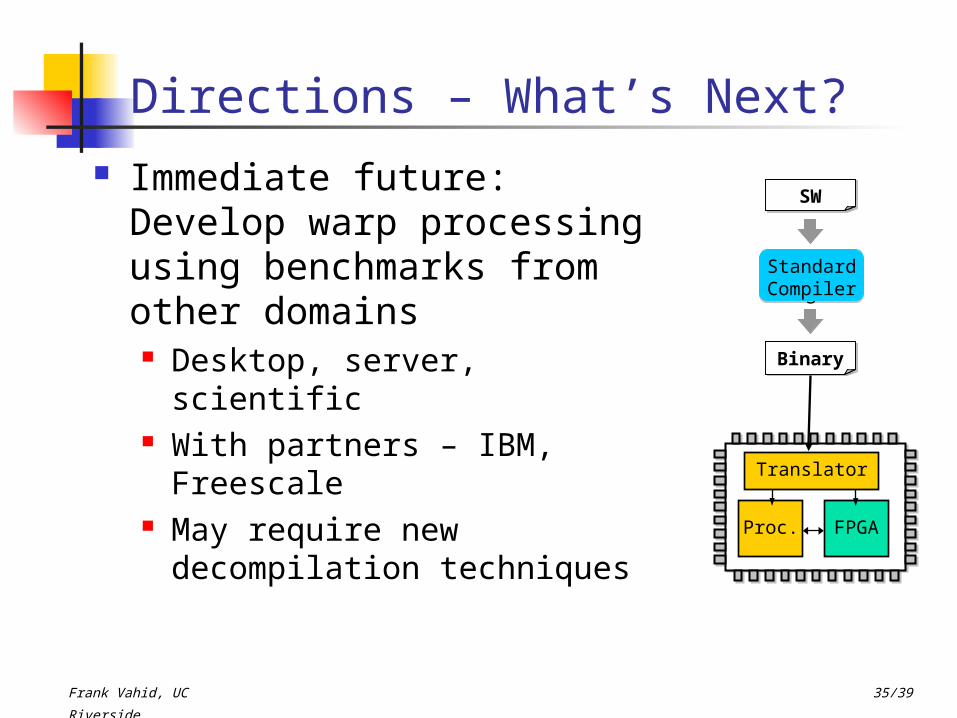
Directions – What’s Next? Immediate future: Develop
warp processing using benchmarks from other domains Desktop, server, scientific With partners – IBM, Freescale May require new decompilation
techniques
BinarySW
ProfilingStandard Compiler
BinaryBinary
FPGAProc.
Translator
Frank Vahid, UC Rivers
ide
36/39
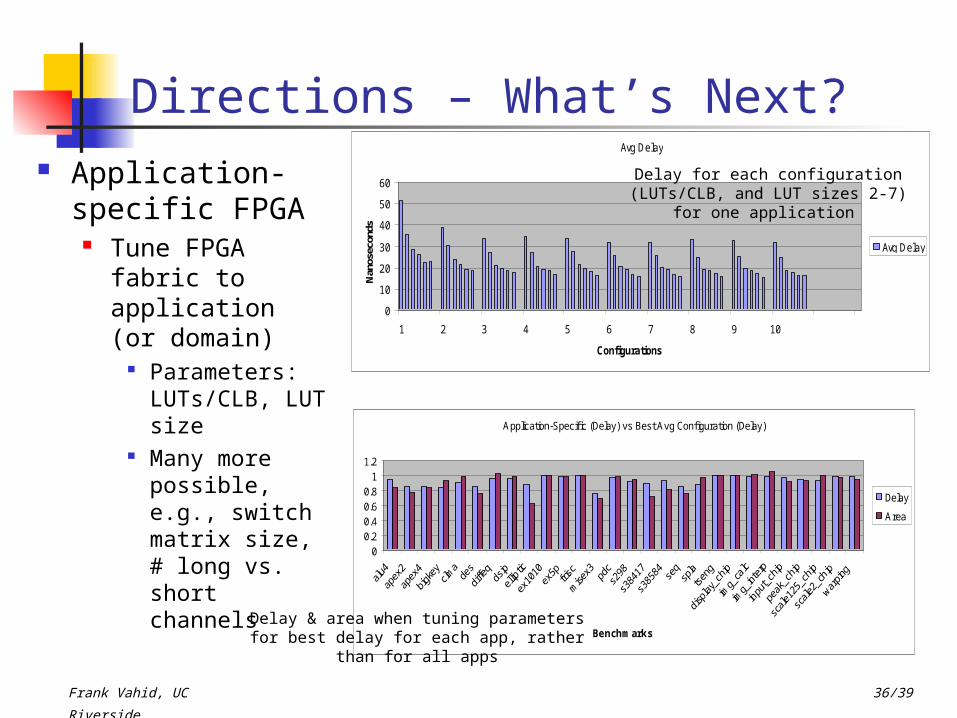
Directions – What’s Next? Application-
specific FPGA Tune FPGA
fabric to application (or domain)
Parameters: LUTs/CLB, LUT size
Many more possible, e.g., switch matrix size, # long vs. short channels
Avg Delay
0
10
20
30
40
50
60
1 2 3 4 5 6 7 8 9 10
Configurations
Nan
osec
onds
Avg Delay
Application-Specif ic (Delay) vs Best Avg Configuration (Delay)
00.20.40.60.8
11.2
Benchmarks
Delay
Area
Delay for each configuration (LUTs/CLB, and LUT sizes 2-7) for one
application
Delay & area when tuning parameters for best delay for each app, rather than for all
apps
Frank Vahid, UC Rivers
ide
37/39
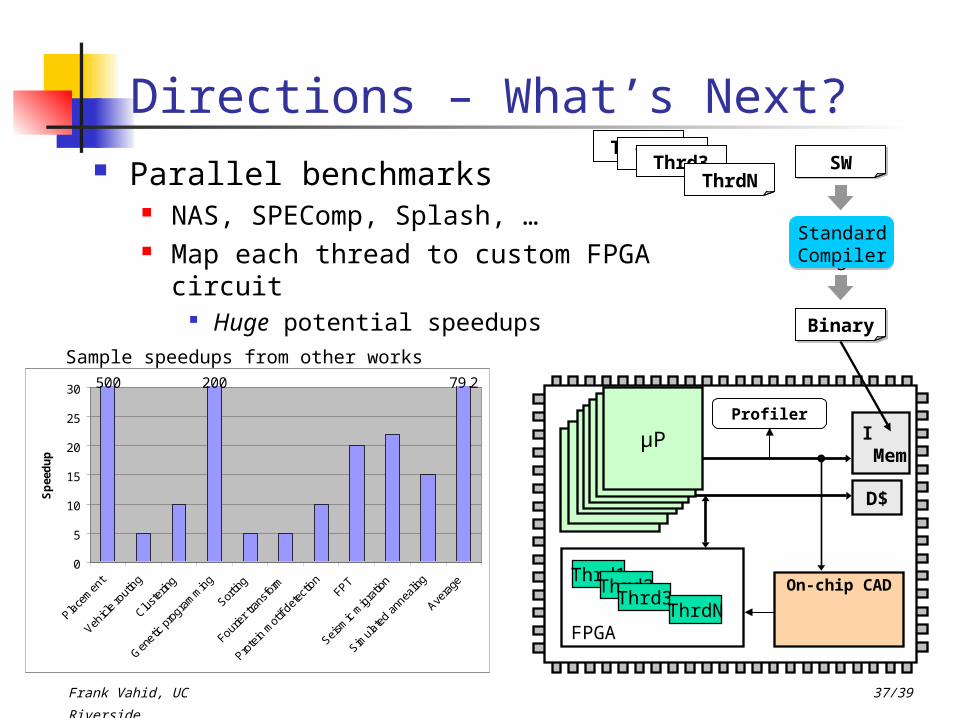
Directions – What’s Next? Parallel benchmarks
NAS, SPEComp, Splash, … Map each thread to custom FPGA
circuit Huge potential speedups
BinarySW
ProfilingStandard Compiler
BinaryBinary
µP
FPGA
On-chip CAD
ProfilerI Mem
D$µPµPµPµPµPµP
Thrd1Thrd2
Thrd3ThrdN
Thrd1Thrd2Thrd3ThrdN
79.2200500
0
5
10
15
20
25
30
Place
men
t
Vehicl
e ro
utin
g
Cluste
ring
Gen
etic p
rogra
mm
ing
Sortin
g
Fourier
tran
sfor
m
Prote
in m
otif d
etec
tion
FPT
Seism
ic m
igra
tion
Simula
ted a
nnea
ling
Avera
ge
Sp
eed
up
Sample speedups from other works

Frank Vahid, UC Rivers
ide
38/39
Directions – What’s Next?
With JIT FPGA compiler, what else is possible?
Implications for existing applications? Image processing, neural networks, ...
Add FPGA hardware to improve performance, like expandable memory?
Standard binaries for FPGAs? Rather than extracting circuit from
sequential code, distribute circuit binary itself, use JIT FPGA compiler to best map to FPGA resources
BinaryBinary
FPGAProc.
Translator
FPGA
* * * * * * * * * * * *
+ + + + + +
+ + +
+ +
+
BinaryBinary
Translator
FPGA
Translator
FPGA

Frank Vahid, UC Rivers
ide
39/39
Summary FPGA future looks bright Hiding FPGA via warp processing is feasible
Decompilation can recover high-level constructs to yield speedups competitive with source-level
JIT FPGA compilation can be made sufficiently lean Many possible directions exist that may use
FPGAs to gain ultra-high performance without ultra-high engineering or hardware costs
Publications can be found at: http://www.cs.ucr.edu/~vahid/pubs


















![[IJCT-V1I2P2] Author :Vahid Ghoreish](https://img.pdfslide.us/doc/110x75/577cc1761a28aba7119326b7/ijct-v1i2p2-author-vahid-ghoreish.jpg)










