Embed Size (px)
Citation preview

Tag Me a Label with Multi-arm: Active Learning for Telugu
Sentiment Analysis
by
Muku Sandeep, Subba Reddy Oota, Radhika Mamidi
in
19th International Conference on Big Data Analytics and Knowledge Discovery(DaWaK-2017)
: 355-367
Lyon, France
Report No: IIIT/TR/2017/-1
Centre for Language Technologies Research CentreInternational Institute of Information Technology
Hyderabad - 500 032, INDIAAugust 2017

Tag Me a Label with Multi-arm: ActiveLearning for Telugu Sentiment Analysis
Sandeep Sricharan Mukku1(B), Subba Reddy Oota2(B), and Radhika Mamidi1
1 LTRC, KCIS, IIIT Hyderabad, Hyderabad, [email protected], [email protected]
2 Teradata, Hyderabad, [email protected]
Abstract. Sentiment Analysis is one of the most active research areas innatural language processing and an extensively studied problem in datamining, web mining and text mining for English language. With the pro-liferation of social media these days, data is widely increasing in regionallanguages along with English. Telugu is one such regional language withabundant data available in social media, but it’s hard to find a labeledtraining set as human annotation is time-consuming and cost-ineffective.To address this issue, in this paper the practicality of active learning forTelugu sentiment analysis is investigated. We built a hybrid approach bycombining different query selection strategy frameworks to increase moreaccurate training data instances with limited labeled data. Using a setof classifiers like SVM, XGBoost, and Gradient Boosted Trees (GBT),we achieved promising results with minimal error rate.
Keywords: Active learning · SVM · XGBoost · Sentiment analysis ·GBT
1 Introduction
Currently, people are commonly found writing comments, reviews, blog posts insocial media about trending activities in their regional languages. Unlike English,many regional languages lack resources to analyze these activities. Moreover,English has many datasets available, however, it is not the same with Telugu.
Telugu is a Dravidian language, native to India. It ranks third by the numberof native speakers in India and fifteenth in the Ethnologue list1 of the mostspoken languages world-wide2. Over the last decade, there has been an incrementin movie review sites, newspaper websites, tweets, comments and other blog-posts, etc., written in Telugu. Labeling these reviews with their sentiments wouldprovide a brief summary to the readers.
In this paper, we attempted to perform sentiment analysis in Telugu andclassify a sentence with positive or negative polarity. With the dearth of suffi-cient annotated sentiment data in Telugu language, we needed to increase the1 https://www.ethnologue.com/statistics/size.2 https://en.wikipedia.org/wiki/Telugu language.
c© Springer International Publishing AG 2017L. Bellatreche and S. Chakravarthy (Eds.): DaWaK 2017, LNCS 10440, pp. 355–367, 2017.DOI: 10.1007/978-3-319-64283-3 26

356 S.S. Mukku et al.
existing available labeled datasets. However, annotating abundant unlabeleddata manually is very time-consuming, cost-ineffective and resource-intensive.To address this problem, one possible solution is to employ active learning [1].Active learning algorithms are used in many natural language processing taskssuch as sentiment analysis, text categorization etc., where only limited numberof instances are actively selected as training data so as to reduce the annotationeffort substantially.
In active learning, there are different query selection strategies such as uncer-tainty sampling [2], random sampling [3], Querying Informative and Representa-tive Examples (QUIRE) [4], Density Weighted Uncertainty Sampling (DWUS)[5] and Query by Committee (QBC) [6]. One may use any of these strategies,however, we observed that using a hybrid of these strategies gives a better perfor-mance when compared with individual strategies. In this paper, through activelearning, we developed a sentiment analysis model for Telugu language by exper-imenting with three different classifiers viz., support vector machines (SVM) [7],extreme gradient boosting (XGBoost) [8], gradient boosted trees (GBT) [9]. Ourexperiments achieved encouraging outputs with minimal error rates.
The contributions of our work are four-fold:
1. We created a word embedding model for Telugu language and examined dif-ferent regions of the embedding space
2. We proposed a hybrid approach of query selection strategies in active learning3. We adopted this approach for Telugu language and labeled many unlabeled
data instances4. We built a classification model for Telugu sentiment analysis
This paper is organized as follows: Sect. 2 explains the state-of-the-art sys-tems related to this problem. Section 3 covers dataset generation and featuregeneration. In Sect. 4, we covered the system architecture, approach and the algo-rithm. Experimental details and results are covered in Sect. 5. Section 6 brieflydiscusses future work and finally concludes the paper.
2 Related Work
In this section, we give an overview of related work which is focused on: (i) Analy-sis of resource poor languages and their labeling techniques, (ii) Active learningand different query selection strategies, (iii) Sentiment analysis for regional lan-guages.
There are many popular approaches like named entity recognition (NER),word sense disambiguation, part-of-speech tagging developed for resource poorlanguages. [10] developed a part-of speech tagger for Sindhi language. [11] devel-oped a NER system for Arabic language. [12] provided a way of expandingthe lexicon for a resource-poor language using a morphological analyzer and aweb crawler for small sentences. [13] developed a dialogue system for Telugu, aresource-poor language.

Active Learning for Telugu Sentiment Analysis 357
There are many scenarios of active learning algorithms described in the liter-ature: pool-based, stream-based, query synthesis, active class selection and manymore discussed in [14]. Two of the most common active learning scenarios arepool- and stream-based active learning.
Fig. 1. Word embedding visualization
In stream-based active learning [15–17], the learner is provided with a streamof unlabeled points. On each iteration, learner must decide whether or not torequest a label for a new unlabeled point. In our work, we have mainly focusedon the pool-based active learning [1], where the learner is presented with botha labeled pool, an unlabeled pool in the beginning, and allowed to access apool of (unlabeled) instances repeatedly. In pool-based active learning, threeindependent working groups [18–20] have proposed a similar querying functionbased on support vector machines.
The most popular existing work on pool-based active learning primarilyfocused on a reasonable approach for selecting which instance to label. Uncer-tainty sampling [2] is one such popular approach, which queries the instance thatis most uncertain to the classifier. [21,22] studied the combinations of uncertaintysampling. [23] identified issues in uncertainty sampling and proposed a proba-bilistic approach (PAL) that combines different types of information. Anotherpopular approach is QUIRE [4], which measures the representativeness and infor-mativeness by estimating the possible label-assignments for unlabeled instances.In QBC [6,15], a query sample is chosen according to the principle of maximaldisagreement of different classifiers. In DWUS [5,24], the informative instancesshould not only be those which are uncertain, but also those which are “rep-resentative” of the underlying distribution. In Random sampling used by [3], aquery sample is chosen randomly from the underlying distribution.
[25] deals with semi-supervised sentiment classification using active deeplearning. [26] focused on imbalanced class distribution situations for sentiment

358 S.S. Mukku et al.
analysis and proposed a novel active learning approach. [27] dealt with machinelearning experiments with regard to sentiment analysis in blog, review and forumtexts and also investigated the role of active learning techniques for reducing thenumber of examples to be manually annotated. [28] deals with sentiment clas-sification of Telugu text using machine learning techniques with limited labeleddata instances. [29] is a shared task on sentiment analysis on three Indian lan-guage tweets namely Hindi, Bengali and Tamil and the participants achievedlow accuracies due to lack of resources and tools for these regional languages.
Fig. 2. Adjectives Fig. 3. Inflected verbs Fig. 4. Pronouns
3 Dataset Generation
Unlike English, Telugu has neither a large annotated dataset and tools nor anypre-trained models. Telugu data requires indispensable preprocessing to create aword embedding model, and for information extraction and sentiment extraction.For this, we used the wikipedia Telugu dump which is available in Unicode(UTF) format. This data is transliterated [30] to WX notation3 for the ease ofimplementing and experimentation, which is then used as raw dataset. See theexample given below showing same sentence both in UTF and WX notations:
To generate the annotated dataset, we crawled Telugu news websites andcollected the data, cleaned and preprocessed. We have given a set of rules tonative Telugu speakers and had the data annotated by them. We cross checkedthe data by using kappa coefficient and obtained an annotation co-efficiency of0.89. There are a total of around 1000 sentences annotated into positive andnegative polarities. Similar to the raw dataset, we transliterated the annotateddataset by using UTF-WX converter [30].
3 https://en.wikipedia.org/wiki/WX notation.

Active Learning for Telugu Sentiment Analysis 359
In our case, we took the annotated data (D) of around 1000 sentences. Ini-tially, we set the test data (DT ) as 200 sentences and in the remaining 800sentences, we set 10 sentences as labeled data instances (DL) and 790 sentencesas unlabeled data instances (DU ).
3.1 Word Embeddings Generation
We used the word2vec [31] approach for generating the word embedding model.Word vectors are used to contribute to a prediction task about the next wordin the sentence [32]. Initially we used Telugu raw dataset (in WX notation) asan input to word2vec for generating the word embedding model. To validate thegenerated word embeddings, we checked and visualized the nearness of seman-tically similar words using t-sne [33] shown in Fig. 1.
Using the word embedding model, we generated a 100 dimension featurevector for each sentence of annotated data (D).
Table 1. Adjectives
WX UTF English
wakkuva loweVkkuva highcAla many
koVMwa some
Table 2. Inflected verbs
WX UTF English
cesAdu he didceswAru they doceyadaM to doceswU doing
Table 3. Pronouns
WX UTF English
AmeVku to herAyanaku to himimeV sheiwanu he
Figures 2, 3 and 4 show how word2vec clustered adjectives, verbs and pro-nouns on Telugu language data. From Fig. 2, we can observe that all adjecti-vals are grouped together (examples are shown in Table 1). From Fig. 3, all theinflected forms of the verbs (examples are shown in Table 2), as well as derivedwords are grouped together. Similarly, pronouns are clustered together depend-ing on their case markers (examples are shown in Table 3). The clustering reflectsthe morphology of Telugu as shown in the paradigm of nouns, verbs, pronouns,adjectives etc., discussed in [34,35].
3.2 Feature Engineering
For generating features of annotated sentences, we used sentence2vec [36] app-roach. The input to the sentence2vec is a vocabulary of word vectors generated inthe word2vec approach. The average of all the word vectors of the words presentin the sentence is calculated. This average vector represents the sentence vector.
4 The Proposed Approach
Our proposed approach is a novel approach called Hybrid query selection app-roach. The approach solves the task of selecting from a candidate set of algo-rithms adaptively based on their contributions to the learning performance ona given data set.

360 S.S. Mukku et al.
4.1 Active Learning
Consider we have a limited number of labeled samples (DL), abundant unlabeledsamples (DU ) and an oracle. In an active learning setting, an active learner maypose queries from unlabeled data instances (DU ) to be labeled by an oracle andthen added to labeled data instances (DL).
4.2 Input to the System
The sentence vectors (D) generated in Sect. 3.1 are given as input to the system.Each sentence vector has a length of 100 dimensions. In the initial setup, we splitthe entire data (D) into three parts which are unlabeled data instances (DU ),labeled data instances (DL) and test data (DT ).
4.3 Query Selection Strategies
In active learning, to get the informative samples from unlabeled data instances,there are different query selection strategies proposed in the literature. In uncer-tainty sampling, an active learner queries the instances which are most uncer-tain or least confident. We used least confident method in uncertainty sampling,where it queries the instance whose posterior probability of being positive isnearest to 0.5 (for binary classification). In random sampling, an active learnerqueries the instances randomly. QUIRE provides an organized way of combiningboth informative and representative sample instances emanating from min-maxview of active learning. In DWUS, combining uncertainty with the density of theunderlying data helps in reducing the error quickly. We used k-means clusteringas a method for underlying data for building a initial training set.
Hybrid Query Selection Approach. Hybrid query selection approachemanated from the multi-arm bandit problem [37]. Multi-arm bandit problemdeals with rewarding the arm(s) based on observed feedback. At iteration n,choose an arm an, observe the feedback on(an), and obtain the reward rn(an).In our approach, each arm ai represents a query selection strategy. If an arm ai
is selected at iteration n, then arm ai is rewarded or not rewarded based on theprevious observed feedback on−1(ai) and then the observed feedback on(ai) andreward rn(ai) are updated.
As shown in Fig. 5, hybrid query selection approach takes both unlabeled datainstances (DU ) and labeled data instances (DL) as an input. A decision makingmodel is built along with this approach to predict the posterior probability foreach instance of DU . After calculating the sampling query distribution φ(D(n)),based on multi-arm bandit approach a best sample instance xi ∈ D is selectedfor querying. If xi ∈ DU , then this selected sample instance (xi) is labeled withan oracle/labeler as yi and added to DL. Now the classifier (Cn) is trained onthe updated DL. This process is repeated until DU becomes empty. The reward(rn(ai)) and observation(on(ai)) is updated by comparing the label yi given bythe oracle/labeler with the classifier (Cn(xi)).

Active Learning for Telugu Sentiment Analysis 361
Fig. 5. System architecture
Algorithm 1. Active Learning using Hybrid Query Selection1: INPUT D = {Labeled Data: DL; Unlabeled Data: DU}; QS = {qs1, qs2, ..., qsK}:
query selection strategies; T: Number of queries to label2: Initialize pmin = 1/len(QS): minimum probability to select qsi from QS; n = 1;
Train a classifier C0 on DL
3: while i = 1 → T do4: Step 1:Using Multi-arm bandit problem, adopt a weight vector W(n) which5: is scaled to probability vector P(n) ∈ [pmin, 1]6: Step 2:Using Multi-arm bandit problem, select qsi randomly based on P(n)7: Step 3:For all the samples xi ∈ D, calculate qi(n)=
∑Kl=1 pl(n) ∗ φl(xi)
8: Step 4:Choose a sample instance xi based on qi(n) and record it’s weight9: Wn=1/qi(n)
10: if xi ∈ DU then (i.e., from unlabeled data)11: a:label the xi as yi and move (xi, yi) from DU → DL
12: b:Train the classifier Cn on updated DL
13: c:i → i + 1
14: end if15: Step 5:Caluculate the reward r = Wn * (Cn(xi) == yi) and add r to all16: query selection strategies which suggest xi
17: Step 6:n → n + 1
18: end while

362 S.S. Mukku et al.
Algorithm 1 describes a hybrid approach for annotating the unlabeled sam-ples. This algorithm takes data D = (DU ,DL), query selection strategies QS ={qs1, qs2, ..., qsK} and number of queries to label (T) as an input. We initializethe minimum probability for random selection of query strategy qsi from QSas pmin = 1/len(QS), iteration (n) = 1, weight vector W(n) = {w1, w2, ..., wK}where wi = 1; 1 <= i <= K and a classifier (Cn).
There are 5 major steps in our algorithm. In Step 1 (Line 4), we used multi-arm bandit problem to make a choice to select a qsi with the probability vectorP(n) = {p1, p2, ..., pK} ∈ [pmin, 1] where pmin > 0 scaled from weight vectorW(n). In Step 2 (Line 5) using multi-arm bandit problem, select qsi randomlybased on P(n). In Step 3 (Line 6) for all xi ∈ D, form a probability distributionφi using qsi ∈ QS and find the query vector qi using Eq. 1.
qi =K∑
l=1
pl(n) ∗ φl(xi) (1)
In Step 4 (Line 7), select a sample instance xi based on qi and record it’sweight. Lines 8–11 deal with the cases when sample instance xi ∈ DU i.e. nolabel exists for xi. Now using oracle/labeler assign a label for the instance xi asyi and move (xi,yi) from DU → DL. Using the newly updated DL, a classifieris trained to build a model. In Step 5, the reward is fed by comparing predictedlabel (Cn(xi)) and yi. In Step 6, the iteration number (n) is incremented. Thisprocess (i.e., Steps 1–6) is repeated until T.
4.4 Classification Model for Telugu Sentiment Analysis
From the Sect. 4.3, the updated labeled data set (DL) is used for training theclassification model for sentiment analysis. We built the hybrid query selectionapproach with three models viz., SVM [7], GBT, and XGBoost [8] and pickedthe best underlying model which gives the lowest error rate on test data (DT ).Using the trained model, we predicted the labels (as positive or negative) fortest data (DT ) and found the error rate by comparing true labels with predictedlabels. Later using this model, we annotated around 50,000 Telugu sentencesand made the sentiment analysis for Telugu facile.
5 Experiments and Results
In order to observe the behavior of error rate with respect to number of queries,we have conducted experiments using uncertainty sampling, random sampling,QUIRE, QBC, DWUS, and Hybrid approach for each classifier namely SVM[7], XGBoost [8], and GBT. Parameters are set for each classifier using crossvalidation. Since initially there are few test data instances for tuning parametersusing cross validation, we used the same hyper parameters obtained based ontraining and validation dataset samples as shown in Table 4.
Figures 6 show mean error rate over 20 iterations with respect to numberof queries and Figs. 7 show median error rate over 20 iterations with respect to

Active Learning for Telugu Sentiment Analysis 363
Table 4. Parameters used for each classifier
Classifier Parameters used
XGB N estimators = 100, Learning rate = 1.0, Max depth = 3
SVM Kernel = Linear, Regularization, -Parameter(C) = 10
GBT N estimators = 100, Learning rate = 1.0, Max depth = 3
number of queries. From Figs. 6a and 7a, we can observe that for the underlyingclassifier XGBoost [8], hybrid query selection and uncertainty sampling methodsshows a constant error decrease rate as the number of queries are increasing, onthe other hand we can observe from the same image that the query selectioncriteria: DWUS and random sampling are not maintaining a proper reduction inthe error rate. Although QUIRE and QBC are showing slight decrement in theerror rate on the whole but they are fluctuating too often. However for the SVMclassifier as shown in Figs. 6b and 7b, uncertainty sampling and DWUS per-formed well and shows constant error reduction. The reason is that at each stepSVM improves their estimation of uncertainty over a certain training instancechanges. The other classifier we used GBT as shown in Figs. 6c and 7c, Hybridquery selection performs well with low error rate.
Fig. 6. Number of queries vs. mean error rate

364 S.S. Mukku et al.
It can be observed from the Figs. 6 and 7 that each query selection strategyperforms strongly with some classifier but performs badly on the others. Out ofall classifiers, XGBoost shows better learning by maintaining reasonable decre-ment in the error rate. We also observed that XGBoost classifier in combinationwith Hybrid query selection approach is performing relatively better comparedto other query selection approaches. Thus, for the purpose of testing, we usedthe model obtained from XGBoost in combination with Hybrid query selectionapproach.
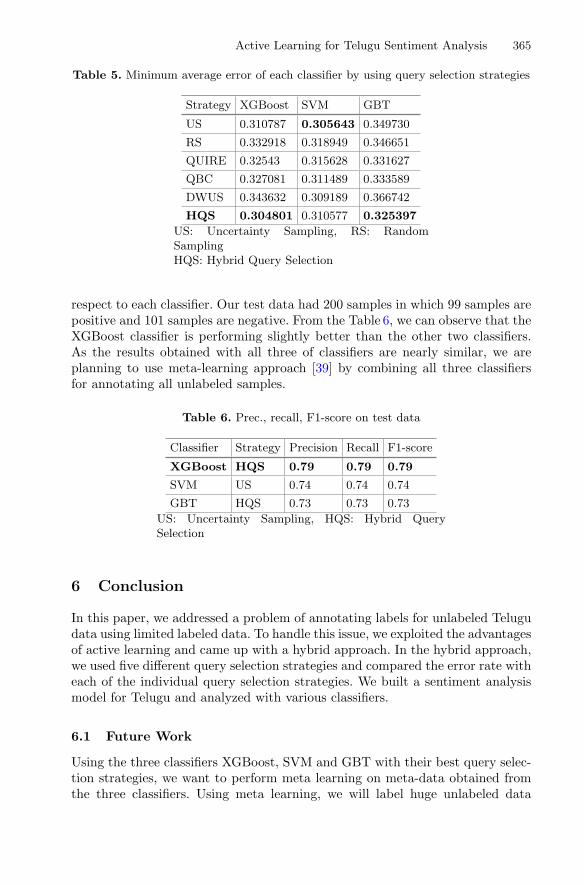
Table 5 shows the average error behavior of each query selection strategywith respect to the classifier. From the Table 5, we observed that the proposedhybrid query selection method’s ability of learning semantics of the sentences andaccurate prediction producing lower error rate with the two classifiers used beingXGBoost and GBT. However, a classifier like SVM produces a lower error ratewith both uncertainty and DWUS methods but not with hybrid query selection.We can also observe that, since random and QUIRE query selection methodslack the certainty of selecting queries, their error rate is not a monotonicallydecreasing graph.
Table 6 shows the precision, recall and F1-scores [38] of test data samplesby applying best query selection strategies obtained in the training phase with
Fig. 7. Number of queries vs. median error rate
Active Learning for Telugu Sentiment Analysis 365
Table 5. Minimum average error of each classifier by using query selection strategies
Strategy XGBoost SVM GBT
US 0.310787 0.305643 0.349730
RS 0.332918 0.318949 0.346651
QUIRE 0.32543 0.315628 0.331627
QBC 0.327081 0.311489 0.333589
DWUS 0.343632 0.309189 0.366742
HQS 0.304801 0.310577 0.325397
US: Uncertainty Sampling, RS: RandomSamplingHQS: Hybrid Query Selection
respect to each classifier. Our test data had 200 samples in which 99 samples arepositive and 101 samples are negative. From the Table 6, we can observe that theXGBoost classifier is performing slightly better than the other two classifiers.As the results obtained with all three of classifiers are nearly similar, we areplanning to use meta-learning approach [39] by combining all three classifiersfor annotating all unlabeled samples.
Table 6. Prec., recall, F1-score on test data
Classifier Strategy Precision Recall F1-score
XGBoost HQS 0.79 0.79 0.79
SVM US 0.74 0.74 0.74
GBT HQS 0.73 0.73 0.73
US: Uncertainty Sampling, HQS: Hybrid QuerySelection
6 Conclusion
In this paper, we addressed a problem of annotating labels for unlabeled Telugudata using limited labeled data. To handle this issue, we exploited the advantagesof active learning and came up with a hybrid approach. In the hybrid approach,we used five different query selection strategies and compared the error rate witheach of the individual query selection strategies. We built a sentiment analysismodel for Telugu and analyzed with various classifiers.
6.1 Future Work
Using the three classifiers XGBoost, SVM and GBT with their best query selec-tion strategies, we want to perform meta learning on meta-data obtained fromthe three classifiers. Using meta learning, we will label huge unlabeled data

366 S.S. Mukku et al.
instances and later perform sentiment analysis task using deep learning tech-niques. We would also like to extend this problem to multi-class classification.We also look to address this for other Dravidian languages as well.
References
1. Settles, B.: Active learning literature survey. Technical report (2010)2. Lewis, D.D.: A sequential algorithm for training text classifiers: corrigendum and
additional data, pp. 13–19 (1995)3. Kolar Rajagopal, A., Subramanian, R., Ricci, E., Vieriu, R.L., Lanz, O., Kalpathi,
R., Sebe, N.: Exploring transfer learning approaches for head pose classificationfrom multi-view surveillance images. Int. J. Comput. Vision 109, 146–167 (2014)
4. Huang, S.J., Jin, R., Zhou, Z.H.: Active learning by querying informative andrepresentative examples. In: Proceedings of the 23rd International Conference onNeural Information Processing Systems, pp. 892–900 (2010)
5. Settles, B., Craven, M.: An analysis of active learning strategies for sequence label-ing tasks. In: EMNLP 2008, pp. 1070–1079. Association for Computational Lin-guistics (2008)
6. Seung, H.S., Opper, M., Sompolinsky, H.: Query by committee. In: Proceedingsof the Fifth Annual Workshop on Computational Learning Theory, pp. 287–294(1992)
7. Cortes, C., Vapnik, V.: Support-vector networks. Mach. Learn. 20, 273–297 (1995)8. Chen, T., Guestrin, C.: XGBoost: a scalable tree boosting system. In: Proceedings
of the 22nd ACM SIGKDD International Conference on Knowledge Discovery andData Mining, pp. 785–794. ACM (2016)
9. Ganjisaffar, Y., Caruana, R., Lopes, C.V.: Bagging gradient-boosted trees for highprecision, low variance ranking models. In: Proceedings of the 34th InternationalACM SIGIR Conference on Research and Development in Information Retrieval,pp. 85–94. ACM (2011)
10. Motlani, R., Lalwani, H., Shrivastava, M., Sharma, D.M.: Developing part-of-speech tagger for a resource poor language: Sindhi
11. Gad-Elrab, M.H., Yosef, M.A., Weikum, G.: Named entity disambiguation forresource-poor languages. In: Proceedings of the Eighth Workshop on ExploitingSemantic Annotations in Information Retrieval, ESAIR 2015, pp. 29–34 (2015)
12. Gasser, M.: Expanding the lexicon for a resource-poor language using a morpholog-ical analyzer and a web crawler. In: Proceedings of the International Conference onLanguage Resources and Evaluation, LREC 2010, Valletta, Malta, 17–23 May 2010
13. Sravanthi, M.C., Prathyusha, K., Mamidi, R.: A Dialogue System for Telugu, aResource-Poor Language, pp. 364–374 (2015)
14. Settles, B.: Active learning. Synth. Lect. Artif. Intell. Mach. Learn. 6(1), 1–114(2012)
15. Freund, Y., Seung, H.S., Shamir, E., Tishby, N.: Selective sampling using the queryby committee algorithm. Mach. Learn. 28, 133–168 (1997)
16. Cohn, D., Atlas, L., Ladner, R.: Improving generalization with active learning.Mach. Learn. 15, 201–221 (1994)
17. Chu, W., Zinkevich, M., Li, L., Thomas, A., Tseng, B.: Unbiased online activelearning in data streams. In: Proceedings of the 17th ACM SIGKDD InternationalConference on Knowledge Discovery and Data Mining, pp. 195–203 (2011)

Active Learning for Telugu Sentiment Analysis 367
18. Tong, S., Koller, D.: Support vector machine active learning with applications totext classification. J. Mach. Learn. Res. 2, 45–66 (2001)
19. Campbell, C., Cristianini, N., Smola, A., et al.: Query learning with large marginclassifiers. In: ICML, pp. 111–118 (2000)
20. Kremer, J., Steenstrup Pedersen, K., Igel, C.: Active learning with support vectormachines. Wiley Interdiscip. Rev. Data Min. Knowl. Disc. 4(4), 313–326 (2014)
21. Fu, Y., Zhu, X., Li, B.: A survey on instance selection for active learning (2012)22. Reitmaier, T., Sick, B.: Let us know your decision: pool-based active training of a
generative classifier with the selection strategy 4DS. Inf. Sci. 230, 106–131 (2013)23. Kottke, D., Krempl, G., Spiliopoulou, M.: Probabilistic active learning in datas-
treams. In: Fromont, E., Bie, T., Leeuwen, M. (eds.) IDA 2015. LNCS, vol. 9385,pp. 145–157. Springer, Cham (2015). doi:10.1007/978-3-319-24465-5 13
24. Settles, B.: Curious machines: active learning with structured instances. ProQuest(2008)
25. Zhou, S., Chen, Q., Wang, X.: Active deep learning method for semi-supervisedsentiment classification. Neurocomputing 120, 536–546 (2013)
26. Li, S., Ju, S., Zhou, G., Li, X.: Active learning for imbalanced sentiment classifica-tion. In: Proceedings of the 2012 Joint Conference on Empirical Methods in NaturalLanguage Processing and Computational Natural Language Learning, Associationfor Computational Linguistics, pp. 139–148 (2012)
27. Boiy, E., Moens, M.F.: A machine learning approach to sentiment analysis in mul-tilingual web texts. Inf. Retrieval 12(5), 526–558 (2009)
28. Mukku, S.S., Choudhary, N., Mamidi, R.: Enhanced sentiment classification ofTelugu text using ML techniques. In: Proceedings of 25th International Joint Con-ference on Artificial Intelligence, p. 29 (2016)
29. Patra, B.G., Das, D., Das, A., Prasath, R.: Shared task on sentiment analysisin Indian languages (SAIL) tweets - an overview. In: Prasath, R., Vuppala, A.K.,Kathirvalavakumar, T. (eds.) MIKE 2015. LNCS, vol. 9468, pp. 650–655. Springer,Cham (2015). doi:10.1007/978-3-319-26832-3 61
30. Gupta, R., Goyal, P., Diwakar, S.: Transliteration among Indian languages usingWX notation. In: KONVENS, pp. 147–150 (2010)
31. Mikolov, T., Sutskever, I., Chen, K., Corrado, G.S., Dean, J.: Distributed repre-sentations of words and phrases and their compositionality. In: Advances in NeuralInformation Processing Systems, pp. 3111–3119 (2013)
32. Mikolov, T., Chen, K., Corrado, G., Dean, J.: Efficient estimation of word repre-sentations in vector space. arXiv preprint arXiv:1301.3781 (2013)
33. van der Maaten, L., Hinton, G.: Visualizing data using t-SNE. J. Mach. Learn.Res. 9, 2579–2605 (2008)
34. Krishnamurti, B., Gwynn, J.P.L.: A Grammar of Modern Telugu. OxfordUniversity Press, New York (1985)
35. Krishnamurthi, B.: Telugu verbal bases: a comparative and descriptive study(1961)
36. Le, Q.V., Mikolov, T.: Distributed representations of sentences and documents37. Mahajan, A., Teneketzis, D.: Multi-armed bandit problems. In: Hero, A.O.,
Castanon, D.A., Cochran, D., Kastella, K. (eds.) Foundations and Applicationsof Sensor Management, pp. 121–151. Springer, Boston (2008)
38. Davis, J., Goadrich, M.: The relationship between precision-recall and roc curves.In: Proceedings of the 23rd International Conference on Machine Learning, ICML2006, pp. 233–240 (2006)
39. Seewald, A.K.: Meta-learning for stacked classification. Audiology 24(226), 69





























