Embed Size (px)
Citation preview

Stuttgart October 2001
From an informal textual lexicon
to a well-structured lexical database:
An experiment in data reverse engineering
WCRE 2001,WCRE 2001,
Stuttgart, October 2001Stuttgart, October 2001
GérardGérard Huet Huet
INRIAINRIA

Stuttgart October 2001
Introduction
We report on some experiments in data reverse engineering applied to computational linguistics resources.
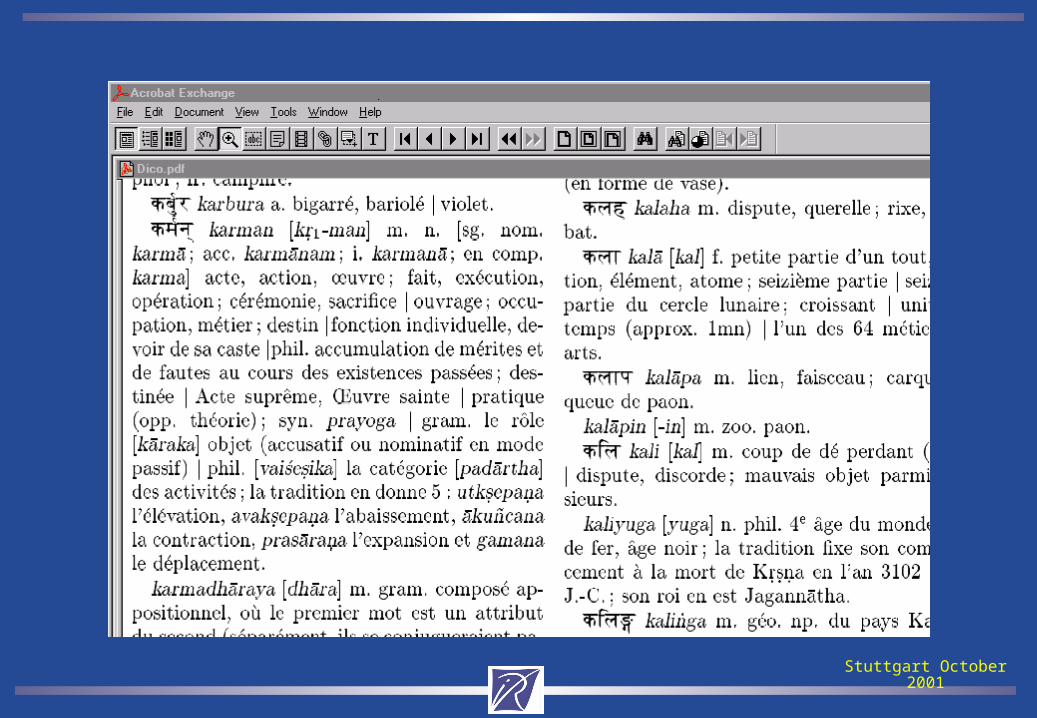
We started from a sanskrit-to-french dictionary in TeX input format.

Stuttgart October 2001
History
• 1994 - non-structured lexicon in TeX
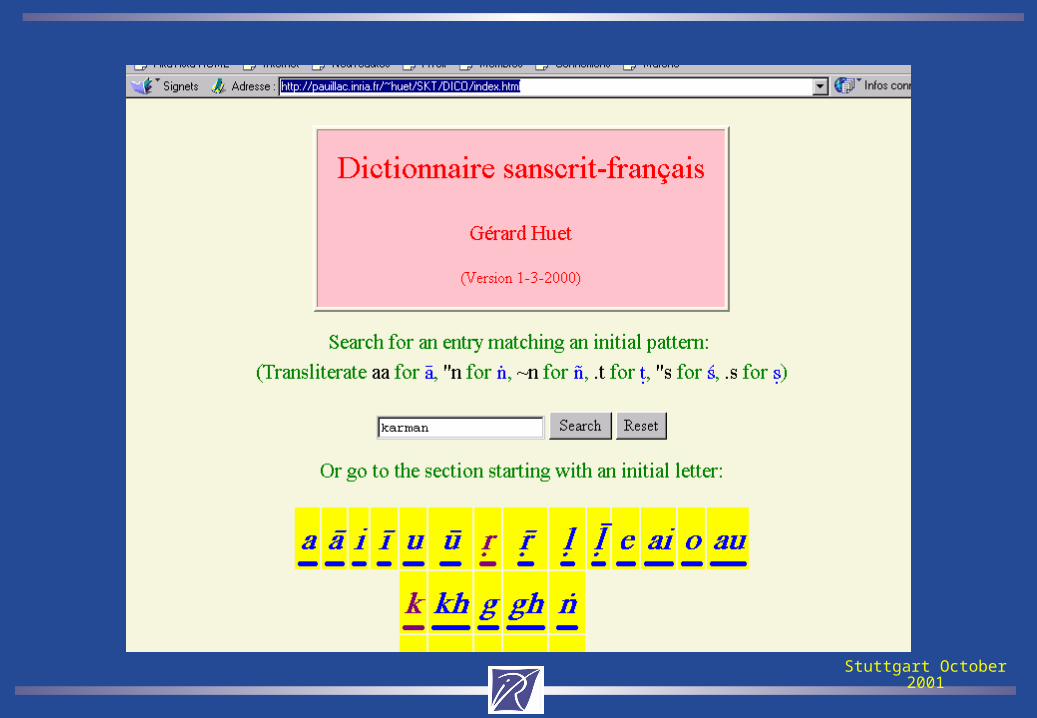
• 1996 - available on Internet
• 1998 - 10000 entries - invariants design
• 1999 - reverse engineering
• 2000 - Hypertext version on the Web, euphony processor, grammatical engine
Stuttgart October 2001

Stuttgart October 2001
Initial semi-structured format
\word{$kumAra$}{kum\=ara} m.
gar{\c c}on, jeune homme
| prince; page; cavalier
| myth. np. de Kum\=ara ``Prince'',
\'epith. de Skanda % Renou 241
-- n. or pur
-- \fem{kum\=ar{\=\i}\/} adolescente, jeune
fille, vierge.

Stuttgart October 2001
Systematic Structuring with macros
\word{$kumAra$}{kum\=ara}
\sm \sem{garçon, jeune homme}
\or \sem{prince; page; cavalier}
\or \myth{np. de Kum\=ara ``Prince'',
épith. de Skanda} % Renou 241
\role \sn \sem{or pur}
\role \fem{kum\=ar{\=\i}\/} \sem{adolescente,
jeune fille, vierge}
\fin

Stuttgart October 2001
Uniform cross-referencing
\word{kumaara}
\sm
\sem{garçon, jeune homme}
\or \sem{prince; page; cavalier}
\or \myth{np. de \npd{Kumaara} "Prince",
épith. de \np{Skanda}} % Renou 241
\role \sn \sem{or pur}
\role \fem{kumaarii} \sem{adolescente,
jeune fille, vierge}
\fin

Stuttgart October 2001
Structured Computations
Grinding : the data is parsed, compiled into typed abstract syntax, and a processor is applied to each entry in order to realise some uniform computation. This processor is a parameter to the grinding functor.
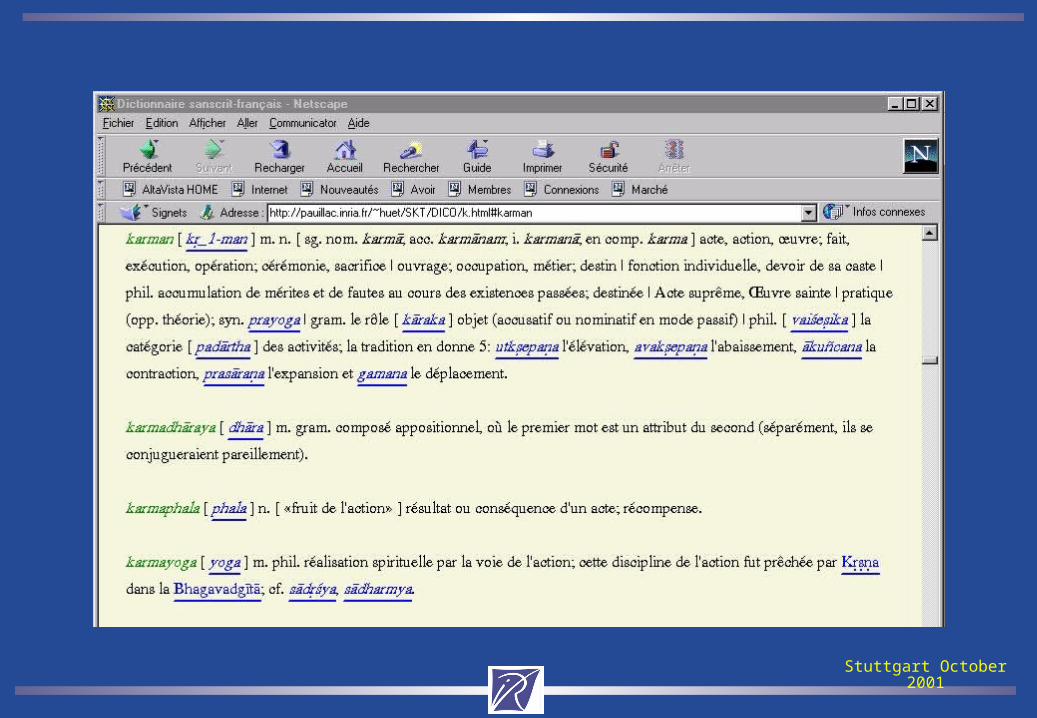
For instance, a printing process may compile into a backend generator in some rendering format. It may be itself parametric as a virtual typesetter. Thus the original TeX format may be restored, but an HTML processor is easily derived as well.
Other processes may for instance call a grammatical processor in order to generate a full lexicon of flexed forms. This lexicon of flexed forms is itself the basis of further computational linguistics tools (segmenter, tagger, syntax analyser, corpus editors, etc).
Stuttgart October 2001
Stuttgart October 2001
Stuttgart October 2001
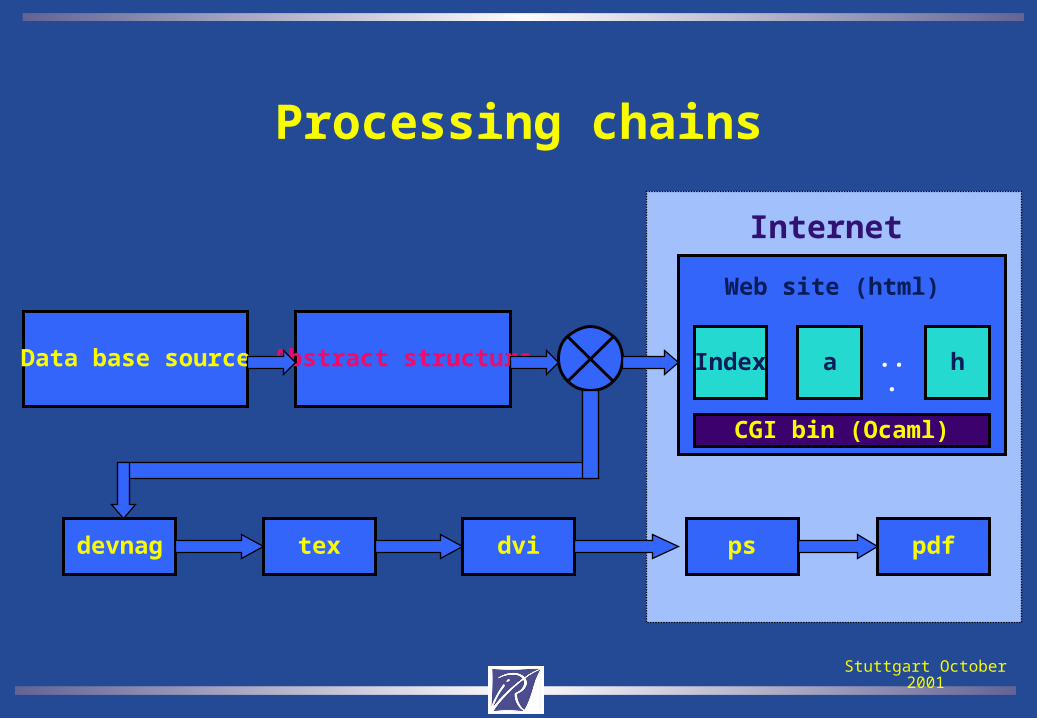
Processing chains
Data base source Abstract structure
devnag tex dvi ps pdf
Internet
Index a h...
Web site (html)
CGI bin (Ocaml)
Stuttgart October 2001
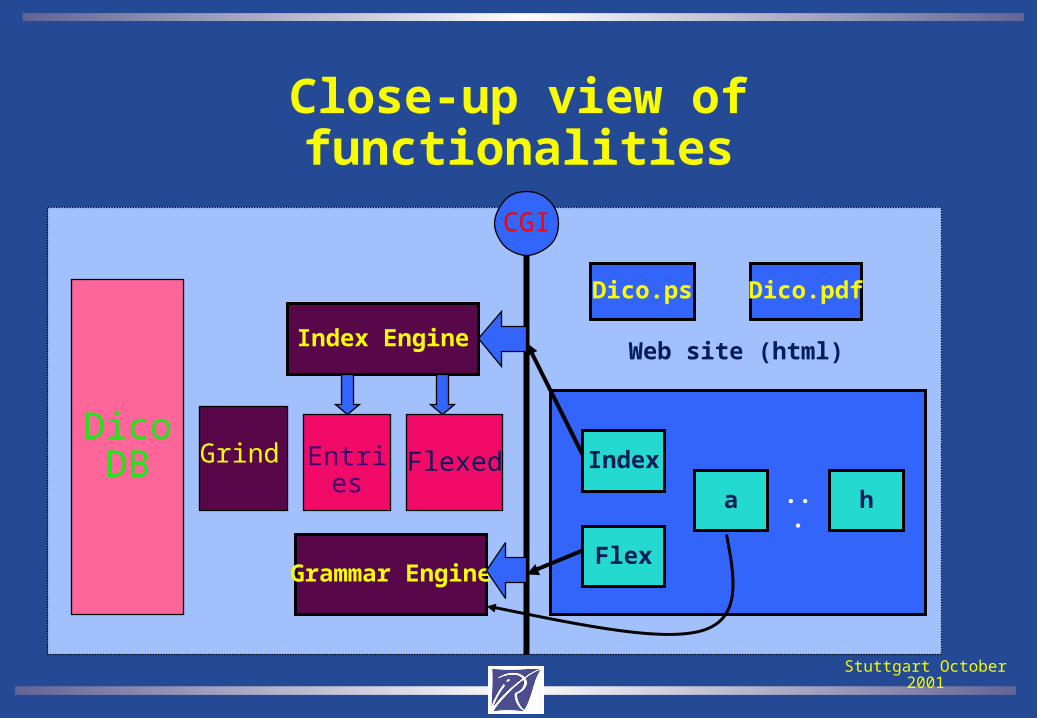
Close-up view of functionalities
Index Engine
Grammar Engine
Dico.ps Dico.pdf
Web site (html)
Index
a h...
Flex
DicoDB Grind FlexedEntries
CGI

Stuttgart October 2001
Tools used
Printable document
• Knuth TeX, Metafont, LaTeX2e
• Velthuis devnag font & ligature comp
• Adobe Postscript, Pdf, Acrobat
Hypertext document
• W3C HTTP, HTML, CSS
• Unicode UTF-8
• Chris Fynn Indic Times Font
Processing & Search
• INRIA Objective Caml

Stuttgart October 2001
Requirements, comments
• The Abstract syntax ought to accommodate the freedom of style of the concrete syntax input with the minimum changes needed to avoid ambiguities
• This resulted in 3 mutually recursive parsers (generic dictionary, sanskrit, french) with resp. (253, 14, 54) productions. Such a structure, implicit from the data, would have been hard to design
• The typed nature of the abstract syntax (~DTD) enforced on the other hand a much stricter discipline than what TeX allowed, leading to much improvement in catching input mistakes
• Total processing of the source document (~2Mb of TEXT) takes only 30 seconds on a current PC
Stuttgart October 2001
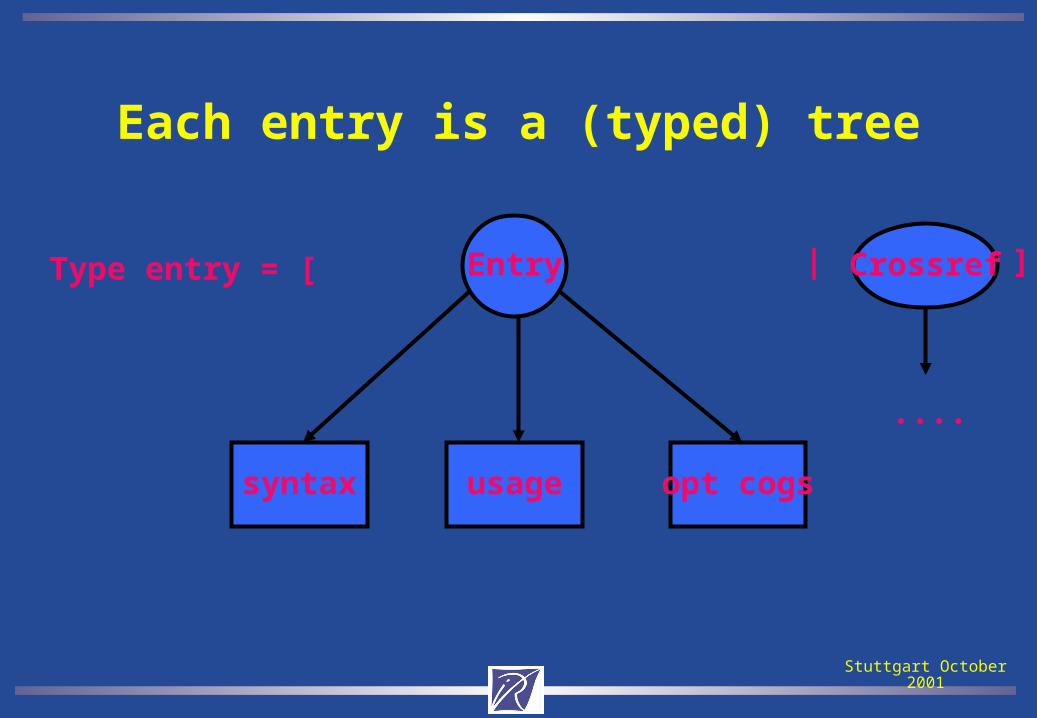
Each entry is a (typed) tree
Entry
syntax usage opt cogs
Type entry = [ | Crossref ]
....

Stuttgart October 2001
Grammatical information
type gender = [ Mas | Neu | Fem | Any ];
type number = [ Singular | Dual | Plural ];
type case = [ Nom | Acc | Ins | Dat | Abl | Gen | Loc | Voc ];

Stuttgart October 2001
The verb system
type voice = [ Active | Reflexive ]
and mode = [ Indicative | Imperative | Causative | Intensive | Desiderative ]
and tense = [ Present of mode | Perfect | Imperfect | Aorist | Future ]
and nominal = [ Pp | Ppr of voice | Ppft | Ger | Infi | Peri ]
and verbal = [ Conjug of (tense * voice)
| Passive | Absolutive | Conditional | Precative
| Optative of voice
| Nominal of nominal
| Derived of (verbal * verbal) ];

Stuttgart October 2001
Key points
• Each entry is a structured piece of data on which one may compute
• Consistency and completeness checks : • every reference is well defined once, there is no dangling reference
• etymological origins, when known, are systematically listed
• lexicographic ordering at every level is mechanically enforced
• Specialised views are easily extracted
• Search engines are easily programmable
• Maintenance and transfer to new technologies is ensured
• Independence from input format, diacritics conventions, etc.
• The technology is scalable to much bigger corpus

Stuttgart October 2001
Interactions lexicon-grammar
• The index engine, when given a string which is not a stem defined in one of the entries of the lexicon, attempts to find it within the flexed forms persistent database, and if found there will propose the corresponding lexicon entry or entries
• From within the lexicon, the grammatical engine may be called online as a cgi which lists the declensions of a given stem. It is directly accessible from the gender declarations, because of an important scoping invariant:
• every substantive stem is within the scope of one or more genders
• every gender declaration is within the scope of a unique substantive stem

Stuttgart October 2001
The segmenter/tagger
• Word segmentation done by euphony defined as a reversible rational relation, analysed by non-deterministic transducer compiled from the flexed forms trie
• Each segment may be decorated by the set of stems/cases leading to the corresponding flexed form
• This yields an interactive tagger which may be used for corpus analysis
• Towards a full computational linguistics platform

Stuttgart October 2001
Reverse engineering strategies
• In the standard methodology, some unstructured text or low-level document is converted once and for all into a high-level structured document on which future processing is applied.
• Here we convert a semi-structured text document into a more structured document, in a closely resembling surface form which may be parsed into an abstract structure on which further processing applies.The surface form is kept with minimal disturbance, and the refinement process may be iterated, so that more structure may percolate with time in a continuous life cycle of the data. E.g. valency, quotations, sources references.

Stuttgart October 2001
Advantages of the refined scheme
• Comments are kept within the data in their original form, and may progressively participate to the structuring process
• The data acquisition/revision processes are not disturbed
• Data revision/accretion may thus proceed asynchronously with respect to the processing agents own life cycle
• The data is kept in transparent text form, as opposed to being
buried in data base or other proprietary formats, with risks of long
term obsolescence or vendor dependency.

Stuttgart October 2001
Computational linguistics as an
important application area for
reverse engineering
• Computational resources data (lexicons, corpuses, etc) live over very long periods, and they keep evolving
• Multi-layer paradigms and interconnection of platforms for different languages make it a necessity to reprocess this data
• Computational linguistics is coming of age for large scale applications, for instance in information retrieval and in speech recognition interfaces

Stuttgart October 2001
Ocaml as a reverse engineering workhorse
• From LISP to Scheme to ML to Haskell
• Caml mixes imperative and applicative paradigms
• Ocaml has a small efficient runtime
• Ocaml has both bytecode and native code compilers
• Ocaml creates small stand-alone applications on current platforms
• Ocaml can call C code and conversely with marshalling processes
• Ocaml has a powerful module system with functors
• Ocaml has a object-oriented layer without extra penalty
• Camlp4 provides powerful meta-programming (macros, parsers)
• Ocaml has an active users/contributors community (Consortium)





























