Embed Size (px)
Citation preview

Strategic Decisions Using Dynamic Programming
Nikolaos E. Pratikakis, Matthew Realff and Jay H. Lee

Agenda Motivation
Exemplary Manufacturing Job Shop Under Uncertain Demand and Product Yield
Understanding Dynamic Programming (DP) via Chess
Curse of Dimensionality (COD)
A new proposed Approach based on Real Time DP (RTDP)
Results
Conclusions and Future Work
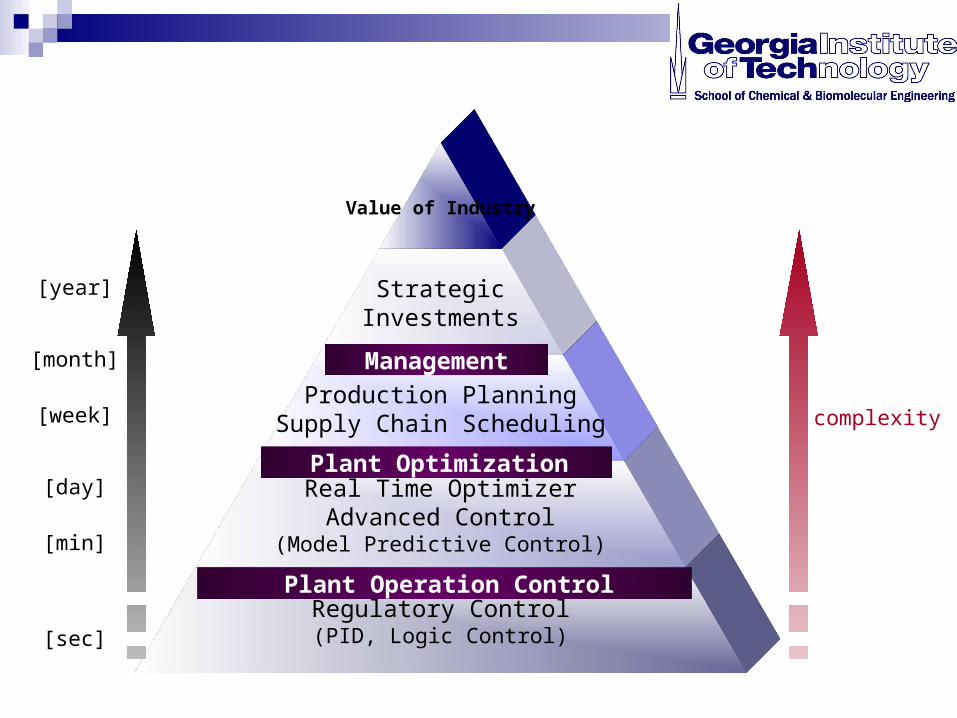
Regulatory Control(PID, Logic Control)
Real Time OptimizerAdvanced Control
(Model Predictive Control)
Production PlanningSupply Chain Scheduling
StrategicInvestments
Value of Industry
Plant Optimization
Plant Operation Control
Management
[year]
[month]
[week]
[day]
[min]
[sec]
complexity
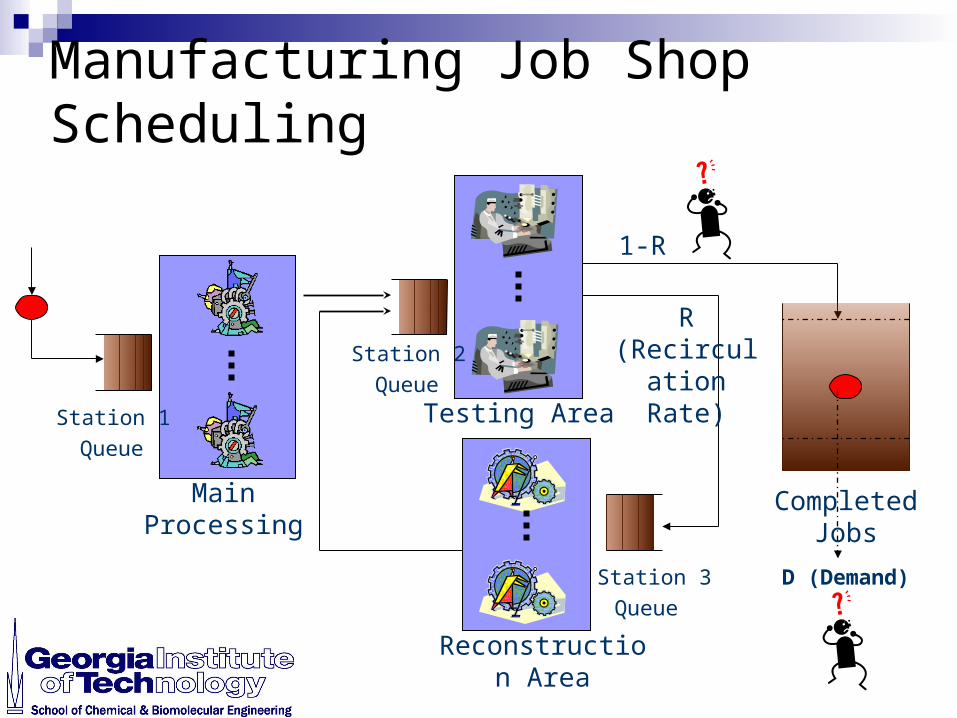
Manufacturing Job Shop Scheduling
Main Processing
Station 1
Queue
Completed Jobs
Reconstruction Area
D (Demand)
R(Recirculation
Rate)
1-R
Testing Area
Station 2
Queue
Station 3
Queue

An Analogy…
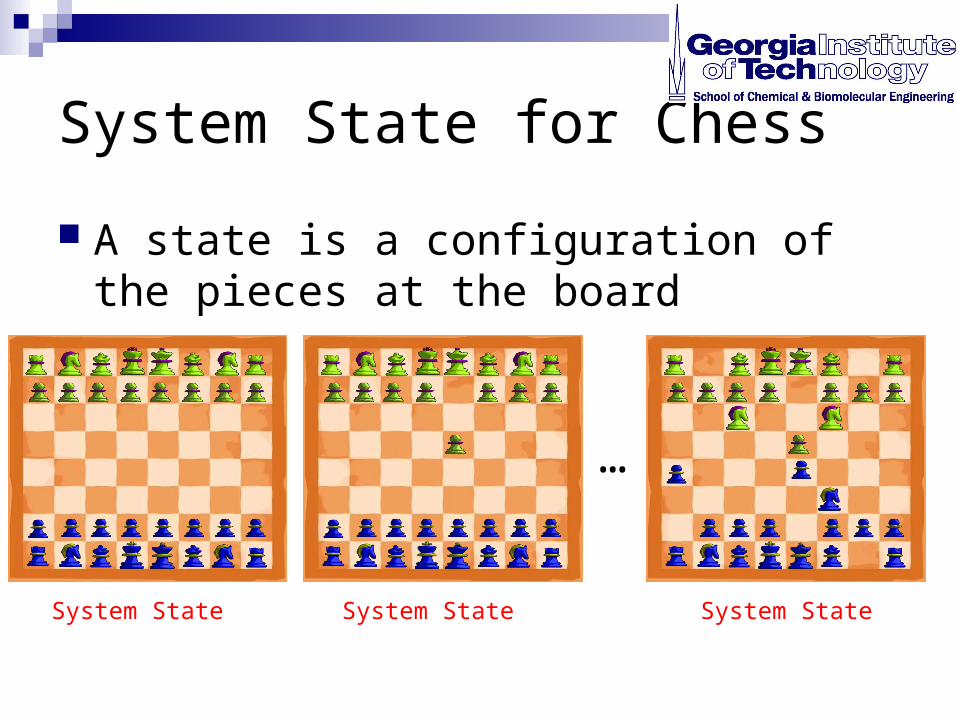
System State for Chess
A state is a configuration of the pieces at the board
System State System State System State
…
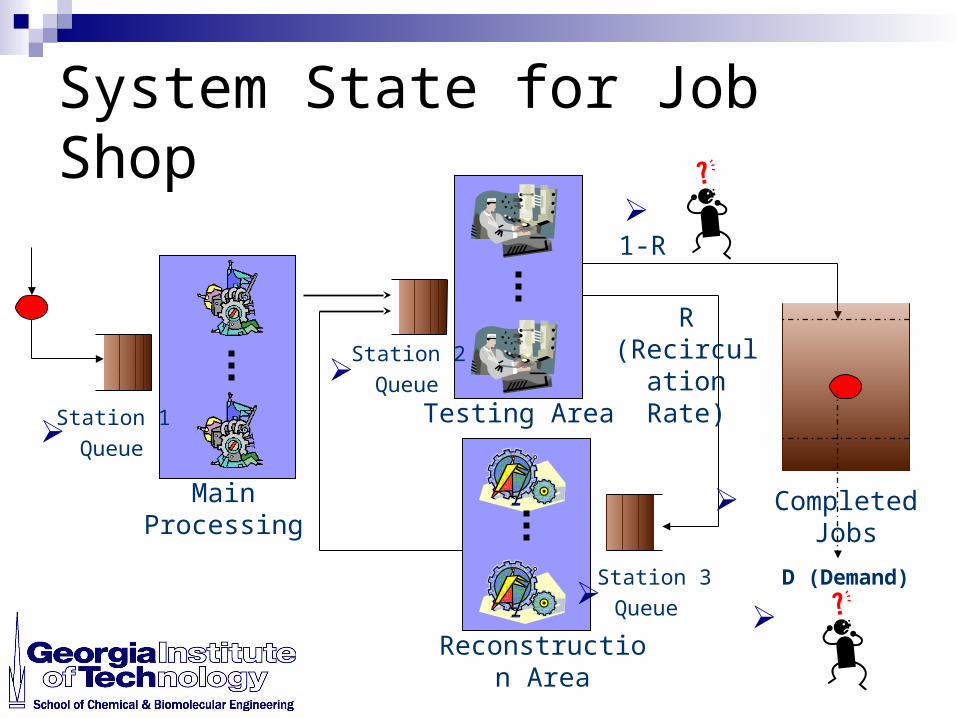
System State for Job Shop
Main Processing
Station 1
Queue
Completed Jobs
Reconstruction Area
D (Demand)
R(Recirculation
Rate)
1-R
Testing Area
Station 2
Queue
Station 3
Queue

Control in DP Terms (2)
Which Control or Action will maximize my future position?
Action 1 ? Action 2 ? Expert to help you decide!
System State
How ???By scoring the successor configurations of the table

“Curse of Dimensionality”
Curse of Dimensionality (COD) Size of S (storage issue)
For complex applications the S is countable infinite
Large number of controls per system state
The research branch that focuses on alleviating the COD is termed as Approximate DP

Formal Definition of Value Function
Value Functions are the solution of the optimality equations.
Optimal action can easily be computed from optimal value function
Given a policy the value function for state is the expected reward
Optimal value function corresponds to
)}(),|(),({maxarg
)}(),|(),({max)(
**
**
jSx
ijiAa
jSx
ijiAa
i
sJassPasra
sJassPasrsJ
j
j
is
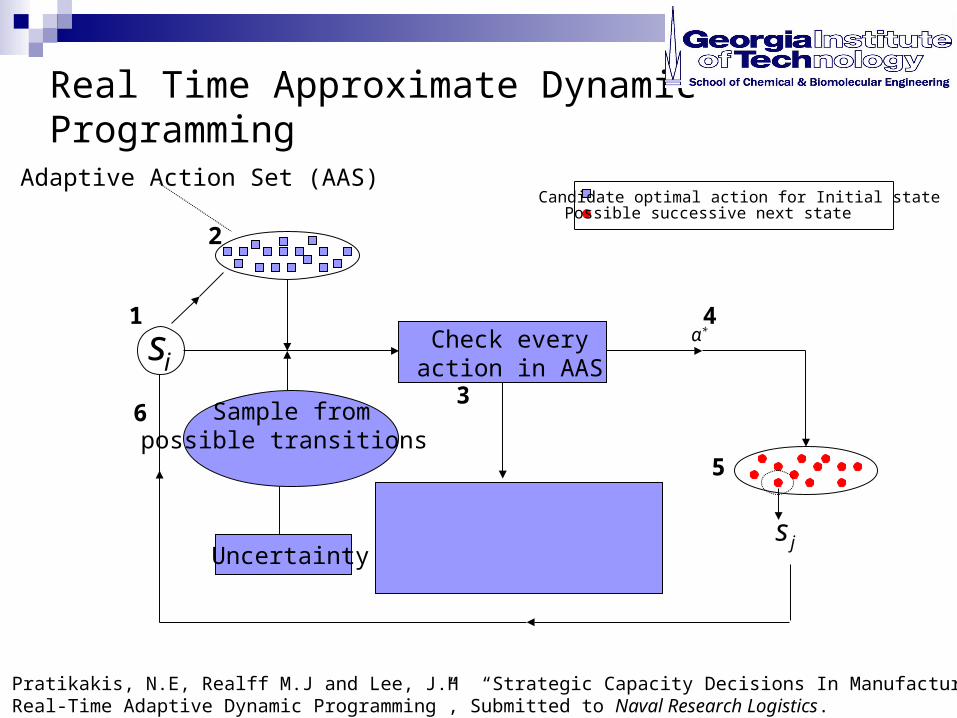
Uncertainty
Sample frompossible transitions
Check every action in AAS
α*
js
Adaptive Action Set (AAS)
1
2
3
4
Real Time Approximate Dynamic Programming
5
6
Possible successive next stateCandidate optimal action for Initial state
Pratikakis, N.E, Realff M.J and Lee, J.H “Strategic Capacity Decisions In Manufacturing Using Real-Time Adaptive Dynamic Programming”, Submitted to Naval Research Logistics.
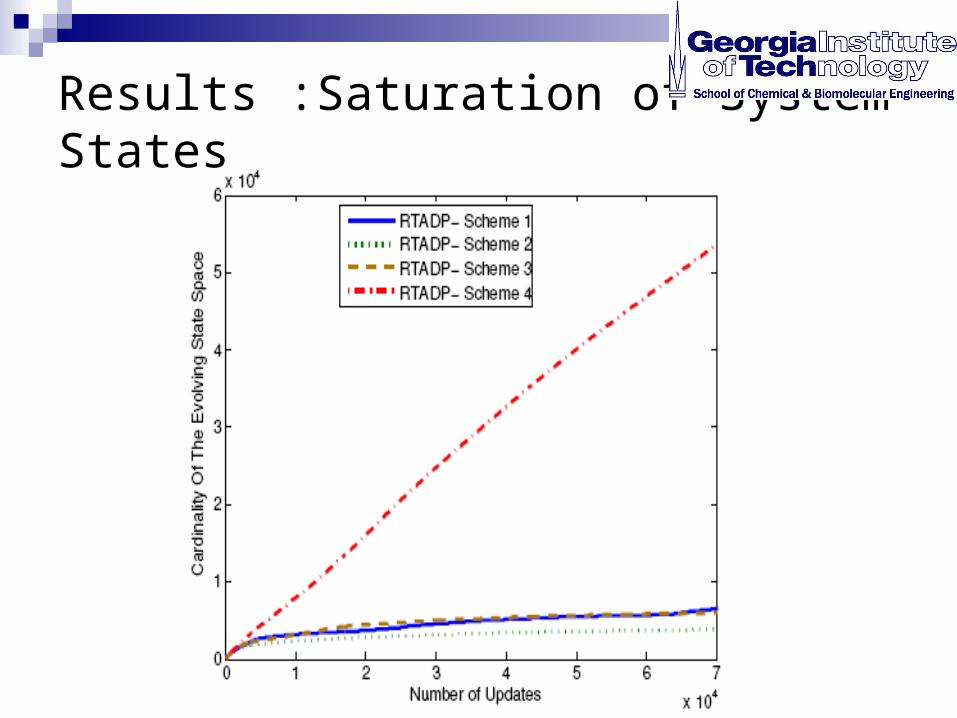
Results :Saturation of System States
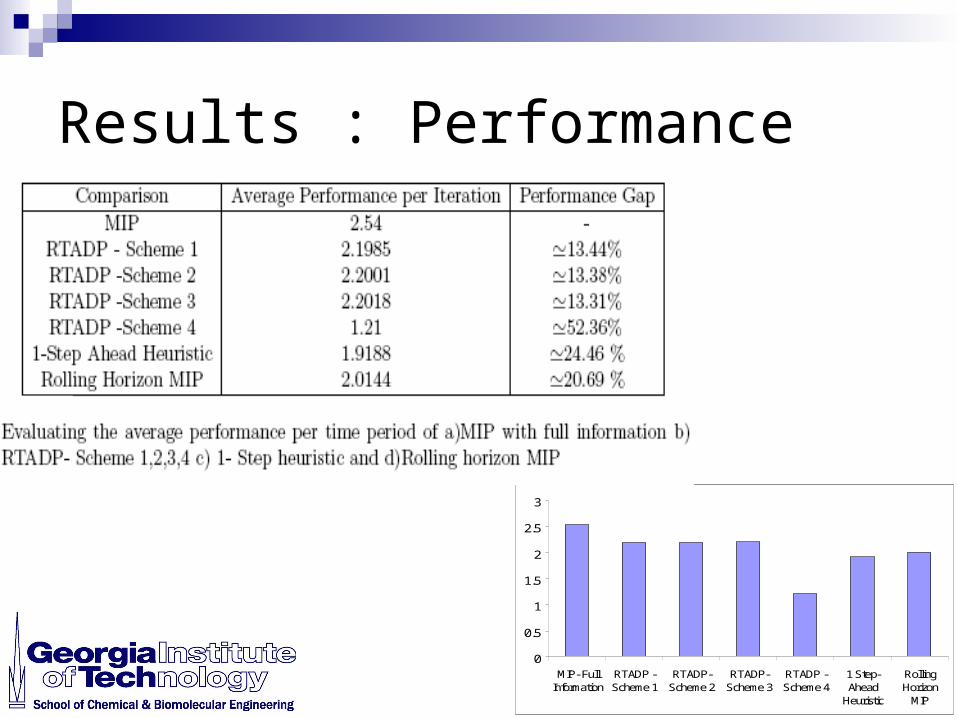
Results : Performance
0
0.5
1
1.5
2
2.5
3
MIP- FullInformation
RTADP -Scheme 1
RTADP-Scheme 2
RTADP-Scheme 3
RTADP -Scheme 4
1 Step-Ahead
Heuristic
RollingHorizon
MIP
.

Conclusions & Future Directions
RTADP computationally amenable way to create a high quality policy for any given system.
Quality of solution exceeds traditional deterministic approaches
Extend current framework and incorporate risk issues (Risk Measure - CVaR).
Risk RTADP framework promises to generate multiple strategies accounting risk.

Questions …?


Approximate Dynamic Programming
Sampling of the “relevant” state space through simulation (with known suboptimal policies)
Fit a function approximator to the value function data for interpolation
Global1,2 vs local approximators3
Barto et al4 introduced the real time DP
1. Bertsekas, D. P.. Encyclopedia of Optimization, Kluwer, 2001.2. Thrun, S. and Schwartz, A. Proceedings of the Fourth Connectionist Models Summer School (Hillsdale, NJ)
Lawrence Erlbaum,1993.3. Lee, J. M. and Lee, J. H.,, International Journal of Control Automation and Systems, vol. 2, no. 3, pp. 263-278,
2004.4. Barto, A., Bradtke, S., and Singh, S. Artificial Intelligence, vol. 72, pp. 81-138, 1995.

Overview of RTDP Algorithm
The controller always follows a policy that is greedy with respect to the most recent estimate of J.
Simulate the dynamics of the system
Update J according to :
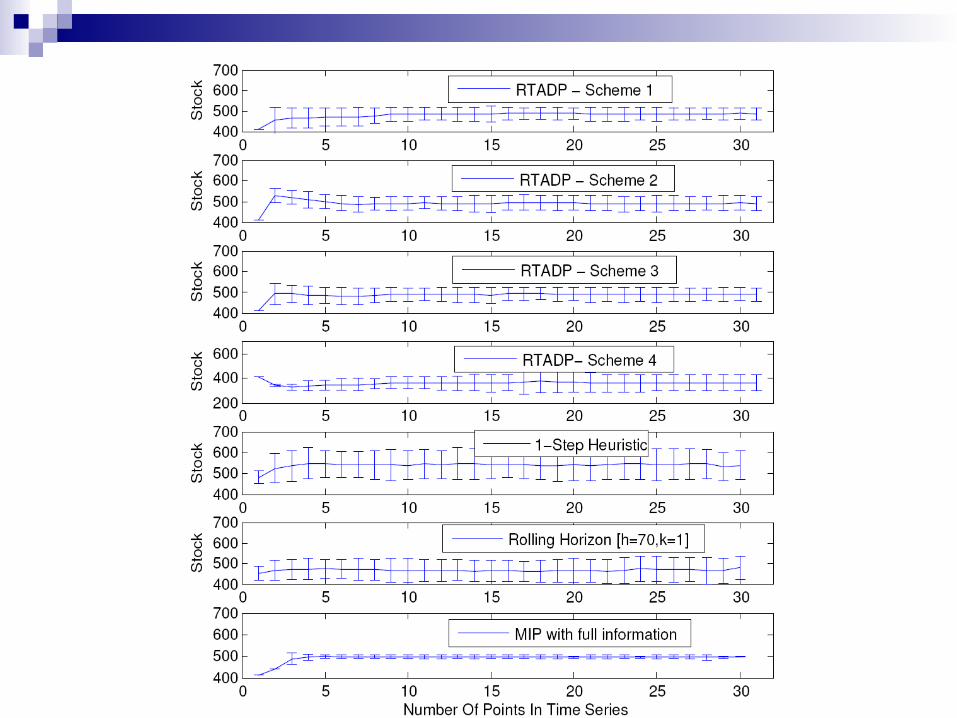

Future Directions



























![Realff wires-ict2013-final [modalità compatibilità]](https://img.pdfslide.us/doc/110x75/5583f4ddd8b42a33318b4e73/realff-wires-ict2013-final-modalita-compatibilita.jpg)
