Embed Size (px)
Citation preview

SIMULATION - SYSTÈMES DE PRODUCTION
RÉSEAUX DE PETRI - ARENA
“All models are wrong but some are useful” Georges E.P. Box, statisticien 1919-2013
Si le problème que vous rencontrez à une solution, il ne sert à rien de s’inquiéter. Mais s’il n’en a pas, alors s’inquiéter ne change rien.
Adage tibétain
Jean-Louis Boimond
Table des matières
I INTRODUCTION À LA SIMULATION ........................................................................................................... 4
I.1 L’ÉTAPE DE MODÉLISATION ............................................................................................................. 5 I.2 LES LIMITES DE LA SIMULATION .................................................................................................... 6 I.3 LES SYSTÈMES À ÉVÉNEMENTS DISCRETS ................................................................................... 6 I.4 LA SIMULATION DES SYSTÈMES DE PRODUCTION .................................................................... 7 I.5 UTILISATION DE L’INFORMATIQUE ................................................................................................ 8
II RAPPELS DE PROBABILITÉS ET STATISTIQUES ..................................................................................... 8
II.1 VARIABLES ALÉATOIRES CONTINUES ........................................................................................ 10 II.2 LOIS DE DISTRIBUTION STANDARD ............................................................................................. 11 II.3 VARIABLES ALÉATOIRES DISCRÈTES ......................................................................................... 13
III DONNÉES D'ENTRÉE DU SYSTÈME ........................................................................................................ 15
III.1 CONNAISSANCE PARTIELLE DES DONNÉES ............................................................................ 15 III.2 DONNÉES EXISTANTES (accessibles à la mesure) ......................................................................... 16
IV VÉRIFICATION ET VALIDATION DES MODÈLES ................................................................................. 17
IV.1 VÉRIFICATION ................................................................................................................................... 17 IV.2 VALIDATION ....................................................................................................................................... 18
V INTERPRÉTATION DES RÉSULTATS ........................................................................................................ 19
V.1 ANALYSE DES SYSTÈMES FINIS ..................................................................................................... 21 V.2 ANALYSE DES SYSTÈMES QUI NE SE TERMINENT PAS .......................................................... 22
VI NOTIONS ELÉMENTAIRES SUR LES RÉSEAUX DE PETRI ................................................................. 23
VI.1 GÉNÉRALITÉS .................................................................................................................................... 23 VI.2 GRAPHES D'ÉVÉNEMENTS ............................................................................................................. 25 VI.3 EXEMPLES ........................................................................................................................................... 25 VI.4 AUTRES CLASSES DE RÉSEAUX DE PETRI ................................................................................ 27
VII LE LANGAGE DE SIMULATION ARENA ............................................................................................... 28
VII.1 NOTIONS DE BASE ........................................................................................................................... 28 VII.2 BLOCS PERMETTANT LA CONSTRUCTION D’UN MODÈLE ................................................ 31 VII.3 BLOCS PERMETTANT L’ANALYSE D’UN MODÈLE ................................................................ 43 VII.4 ANIMATION GRAPHIQUE .............................................................................................................. 47 VII.5 DONNÉES D'ENTRÉES ..................................................................................................................... 50 VII.6 ANALYSE DES RÉSULTATS ........................................................................................................... 51

2
Bibliographie
▪ Discrete Event Systems - Modeling and Performance Analysis, Christos G. Cassandras, Aksen Associates
Incorporated Publishers, ISBN 0-256-11212-6.
▪ Handbook of Simulation: Principles, Methodology, Advances, Applications, and Practice, J. Bank, Wiley
Interscience, 1998.
▪ Introduction to Simulation Using SIMAN. Second Edition, C. Dennis Pegden, R.E. Shannon, R.P. Sadowski,
Ed. Mc Graw-Hill.
▪ Simulation Modeling and Analysis with ARENA. T. Altiok, B. Melamed, Elsevier, 2007.
▪ Optimisation des flux de production : Méthodes et simulation, A. Ait Hssain, Ed. Dunod, 2000.
▪ Du Grafcet aux réseaux de Petri. R. David, H. Alla, Hermès, 1989.
▪ Cours de « Simulation informatique des systèmes de production », P. Castagna, A. L'Anton, N. Mebarki,
97/98 - IUT OGP Nantes.
▪ Cours de « Réseaux de files d'attente et simulation », J. P. Chemla, 96/97 - Université de Tours.
▪ Probabilités et statistiques. 3ème édition, A. Ruegg, Presses Polytechniques Romandes.

3
Arena : blocs, lois de probabilité, variables
bloc ASSIGN ........................................................................................................................................................ 36
bloc BATCH ........................................................................................................................................................ 40
bloc CREATE ...................................................................................................................................................... 31
bloc DECIDE ....................................................................................................................................................... 37
bloc DELAY ........................................................................................................................................................ 33
bloc DISPOSE ..................................................................................................................................................... 32
bloc MATCH ....................................................................................................................................................... 39
bloc PROCESS .................................................................................................................................................... 41
bloc QUEUE ...................................................................................................................................................34, 39
bloc RECORD ..................................................................................................................................................... 43
bloc RELEASE .................................................................................................................................................... 35
bloc RESOURCE ................................................................................................................................................ 35
bloc SEIZE ........................................................................................................................................................... 33
bloc SEPARATE ................................................................................................................................................. 41
bloc STATION .................................................................................................................................................... 48
bloc STATISTIC ................................................................................................................................................. 45
bloc VARIABLE ................................................................................................................................................. 37
loi DISCrete ......................................................................................................................................................... 14
loi EXPOnential .................................................................................................................................................. 12
loi NORMal .......................................................................................................................................................... 13
loi TRIAngular .................................................................................................................................................... 11
loi UNIFform ....................................................................................................................................................... 10
variable NQ .......................................................................................................................................................... 45
variable NR .......................................................................................................................................................... 45

4
I INTRODUCTION À LA SIMULATION
La simulation est un processus qui consiste à :
- Concevoir un modèle du système (réel) étudié,
- Mener des expérimentations sur ce modèle (et non pas des calculs),
- Interpréter les observations fournies par le déroulement du modèle et formuler des
décisions relatives au système.
Le but peut être de comprendre le comportement dynamique du système, de comparer des
configurations, d’évaluer différentes stratégies de pilotage, d’évaluer et d’optimiser des
performances.
La simulation est une technique permettant d'étudier le comportement d'un système dynamique
en construisant un modèle logiciel de celui-ci.
Les domaines d'application sont divers. Sont listés ci-dessous quelques classes d’applications
et quelques exemples de problèmes typiques rattachés à ces classes :
▪ Systèmes de flux de production
- équilibrage de lignes d’assemblage,
- conception de systèmes de transfert entre des postes,
- dimensionnement des stocks d’un atelier,
- comparaison de pilotage de lignes de production.
▪ Flux logistiques et systèmes de transport
- conception et dimensionnement d’entrepôts,
- dimensionnement d’une flotte de camions,
- étude de procédures de contrôle des flux de véhicules en circulation.
▪ Production des services
- étude de transactions bancaires,
- gestion de cantines, de restaurants,
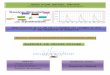
Calendrier SCHEDULES
CREATE
Operateur SEIZE
10 DELAY
DISPOSE
Date de sortie VARIABLES
Date de sortie ASSIGN
NR(Machine) NR(Operateur)
DSTATS
Operateur RELEASE
1
DELAY
1
DELAY
Modélisation Analyse des
résultats

5
- comparaisons de politiques de maintenance des avions.
▪ Systèmes informatiques et télécommunications
- étude de la file d’attente mémoire d’un serveur,
- étude des comportements des utilisateurs,
- conception et dimensionnement de hubs.
▪ Autres classes d’applications
- domaine militaire (support logistique, coordination des opérations, …),
- gestion d’hôpitaux (personnel, lits, service d’urgence, …),
- le nucléaire, la météo, les jeux, ...
➢ Méthodologie générale
Quatre phases sont classiquement considérées durant le processus de simulation : La
modélisation (représenter le comportement du système), la programmation, l'expérimentation
et l'interprétation des résultats (accompagnée d’actions).
(a) Expérimentation : Il s'agit de construire des théories, d’émettre des hypothèses, qui
prennent en compte le comportement observé.
Dans ce cours, les modèles conceptuels seront représentés par des réseaux de Petri, cf. chp. VI ;
les programmes/modèles de simulation, ainsi que les expérimentations à même d’extraire des
résultats, se feront dans le cadre du logiciel Arena, cf. chp. VII.
I.1 L’ÉTAPE DE MODÉLISATION
L’étape de modélisation est une phase essentielle à la simulation au sens où la qualité des
résultats fournis à l’issue des expérimentations est principalement liée à la qualité de la
modélisation.
Différents points doivent être abordés :
• Définir l'objectif de la modélisation (lié au cahier des charges) : Pourquoi modélise-t-on ?
Qu'étudie-t-on ? Que veut-on faire ou améliorer ?
Figure 1 : Méthodologie d'une simulation.
Résultats
Modèle conceptuel
(conditionné par l’objectif de l’étude)
Programme de simulation
Analyse & Modélisation
Interprétation
& Action
Correction
Correction
Vérification
Programmation
Expérimentation(a)
Validation Système (réel)

6
• Définir les limites du système (les entrées, les sorties) et les éléments (via la réalisation d'une
fonction, ou d'un processus) qui le composent.
• Définir les interactions entre ces éléments (hiérarchie).
I.2 LES LIMITES DE LA SIMULATION
La simulation n'est pas une technique d'optimisation au sens propre. Elle ne peut qu'établir les
performances d'une solution conçue et imaginée par l'utilisateur. C'est une technique itérative
qui ne propose pas de solution finale mais qui permet seulement à l'utilisateur d'envisager des
choix possibles. En tout état de cause, c'est lui qui devra décider de ce qui répond le mieux aux
problèmes posés.
Les résultats de simulation sont souvent complexes à interpréter. On étudie des phénomènes
aléatoires et les techniques d'analyse demandent de la rigueur ; il est souvent difficile de faire
la part du crucial et de l'anecdotique (le modèle doit être ni trop grossier, ni trop précis), ceci
dans un temps de réalisation souvent contraint.
I.3 LES SYSTÈMES À ÉVÉNEMENTS DISCRETS
Les systèmes que nous allons considérer, notamment les systèmes de production, sont dits à
événements discrets. Un tel système est représenté par un modèle à événements discrets.
L’espace d'état est régi par des événements discrets au sens où les transitions entre états sont
associées à l'occurrence d'événements discrets asynchrones. Les changements d’état de tels
systèmes s’opèrent instantanément, à des moments discrets dans le temps. Par exemple, si une
variable représente le nombre de pièces présentes dans un stock alors ses valeurs varient
seulement aux instants où des pièces entrent, ou sortent, du stock.
Les systèmes de trafic (aérien, ferroviaire, naval, …), les systèmes de communication, les
systèmes informatiques sont d'autres exemples de systèmes dynamiques dont l'activité est due
à des événements discrets, dont certains sont provoqués (départ d’un train, appui sur une touche
d'un clavier) et d'autres pas (panne d'un équipement).
Le modèle reproduit l'évolution au cours du temps de l'état1 du système sous l'effet des activités
qui y sont réalisées. L’évolution d'une simulation événementielle se fait à travers la gestion
d’un échéancier : Le modèle du système passe au cours du temps d'un état à un autre état suite
au déclenchement d'un événement. A chaque événement est associée une fonction à exécuter
laquelle peut modifier l'état du système à travers le déclenchement d'un, ou de plusieurs
événements.
1 L’évolution de l’état est régie par des événements discrets contrairement aux systèmes continus (régis par des
équations différentielles) où l’état évolue continûment au cours du temps.

7
I.4 LA SIMULATION DES SYSTÈMES DE PRODUCTION
Un système de production est constitué d'un système opérant (physique), d'un système de
conduite (partie commande) et d'un système d'informations reliant ces deux derniers. Il est
traversé par un flux d'informations (présence d'une pièce, état d'une machine) et un flux physique
(matière première, pièces). Le système à simuler peut être existant, à modifier ou non encore
construit.
Les systèmes automatisés de production - à l'initiative de l'Homme - sont caractérisés par une
forte complexité et flexibilité. La simulation de ces systèmes nécessite souvent d’avoir une
approche globale prenant en compte, à la fois, les aspects techniques (caractéristiques des
ressources de production, des capacités de stockage, géométrie du réseau de transport, ...) et
humains (contraintes sociales, travail en équipe, heures supplémentaires, ...).
Le modèle décrit le fonctionnement du système (sa structure et son comportement dynamique)
avec le degré de détail nécessaire à la résolution du problème posé. C'est une représentation de
la circulation des flux de produits :
- Le flux est ralenti par des activités qui mobilisent des ressources (après avoir attendu
leur disponibilité) pendant un certain temps (durées opératoires, temps de transfert, ...),
- Le flux est contraint par des règles opératoires (gammes, contraintes technologiques),
- Le flux est dirigé par les règles de conduite (système de contrôle).
L'historique et les statistiques portent sur les déplacements (temps de séjour des pièces, temps
de transports des pièces d'un lieu à un autre, ...), les taux d'engagements des ressources, les
longueurs des files d'attente, ...
Historique, statistiques
Evaluation de performances
Système de production
Modèle
Programme
Événement X
Événement C
Événement B
Événement A
Événements
datables
Échéancier
Moteur : Exécution de
l’événement dont
la date
d’occurrence est la
plus proche du
temps courant de
la simulation

8
L'évaluation de performances2, en termes de circulation de produits, exploite ces données pour :
- Déterminer des performances absolues (volume de production, temps de cycle
maximum),
- Prédire des performances dans certaines conditions (présence de pannes),
- Faire une analyse de sensibilité (parmi des choix semblables),
- Comparer des alternatives (parmi des choix possibles).
Ces indicateurs de performances sont ensuite agrégés pour des prises de décisions relatives à
l'aide à la conception, à la conduite, ...
I.5 UTILISATION DE L’INFORMATIQUE
Trois approches sont habituellement utilisées pour réaliser une simulation : 1. Ecrire le programme correspondant au problème et au système donnés. Les moyens
informatiques sont les langages de programmation généraux (C, Fortran, Pascal, ...). La mise
en œuvre peut être longue, par contre on dispose d’une grande flexibilité. 2. Le développement d'un modèle de simulation est réalisé au travers d'un programme écrit par
l'utilisateur à partir de primitives de modélisation offertes par le langage (les langages de
simulation). Ce type de logiciel offre une grande flexibilité mais avec des coûts de
développement parfois importants. Certains langages, comme ARENA (un des principaux
logiciels standards de simulation en France), proposent des primitives de modélisation
particulièrement adaptées aux systèmes de production (primitives de modélisation des
ressources et fonction de transport). 3. Utiliser un logiciel, appelé simulateur, dédié à un type de systèmes et un type de problème.
Le modèle est donné et il suffit de le paramétrer pour l'adapter au cas étudié. Cette alternative
présente l’avantage de ne pas programmer (seules des données sont à entrer), par contre il
n’est pas toujours simple de trouver le logiciel dédié adapté au système et au problème
concernés.
II RAPPELS DE PROBABILITÉS ET STATISTIQUES
Sachant qu'il est impossible – quelle que soit la puissance des ordinateurs - de simuler toutes
les déviations possibles d'un système, l'outil statistique est une alternative pour prendre en
compte, étudier et maîtriser les conséquences des variations aléatoires des systèmes.
La théorie des probabilités, branche des mathématiques, permet de modéliser et d'étudier des
phénomènes aléatoires. On parle alors d'événements aléatoires, de lois de probabilité, de
variables aléatoires, ...
Dans un système de production, de nombreux phénomènes ont un caractère aléatoire, par
exemple :
- La durée opératoire d'une opération manuelle,
2 L’évaluation de performances se base souvent sur le taux de production (nombre moyen de pièces par unité de
temps), le WIP (Work In Process, nombre total de pièces dans le système à chaque instant), le makespan (intervalle
de temps entre le début et la fin de la production des pièces).

9
- La durée de vie d'un outil,
- L'absentéisme des opérateurs,
- La période d'arrivée des ordres de fabrication déclenchant une production.
La statistique repose sur l'observation de phénomènes concrets. Le but est de recueillir des
données d'observation, de les traiter et de les interpréter. On parle alors de population
d'individus, de variables caractéristiques, d'échantillons, de moyennes, ...
Les modèles probabilistes permettent de représenter approximativement les données observées
(imprécision, erreurs, répartition dans la population) comme des variables aléatoires suivant
une certaine loi de probabilité → modèles simplificateurs.
L'échantillon étant tiré au hasard, les caractéristiques des données à traiter sont des variables
aléatoires → application de théorèmes de probabilités (par exemple, le théorème central
limite3).
La simulation utilise les résultats des probabilités-statistiques essentiellement pour :
- Approcher des données empiriques par des distributions de probabilités
→ des fonctions intégrées dans le modèle de simulation (lois de distributions),
- Interpréter statistiquement les données générées par le modèle
→ moyennes, intervalles de confiance, ...
Définition de la probabilité
On considère l'ensemble Ω des éventualités possibles résultant d'une épreuve (expérience,
observation ou simulation), chacune de ces éventualités étant appelée événement élémentaire.
Un événement quelconque est défini comme un sous-ensemble 𝐴 de Ω contenant tous les
événements élémentaires de Ω composant l'événement 𝐴. La probabilité attachée à un
événement 𝐴 est un nombre 𝑃(𝐴) compris entre 0 et 1, obéissant à certaines règles
axiomatiques, en particulier :
- L'événement de l'ensemble vide a une probabilité nulle.
- L'événement Ω a une probabilité égale à 1.
- ∀ 𝐴 ⊆ , on a 0 ≤ 𝑃(𝐴) ≤ 1.
- ∀ 𝐴, 𝐵 ⊆ , on a 𝑃(𝐴 ∪ 𝐵) = 𝑃(𝐴) + 𝑃(𝐵) si 𝐴 ∩ 𝐵 = ∅.
Le problème de l'attribution de probabilités à un ensemble d'événements peut être résolu dans
un certain nombre de cas de la façon suivante :
- Si les événements élémentaires sont en nombre fini, on peut procéder à une série de
répétitions de l'épreuve : La fréquence d'apparition de chaque événement permet de
disposer d'une estimation de sa probabilité.
- Si les événements sont en nombre infini, on peut définir sur cet ensemble une densité
de répartition de probabilité.
3 La moyenne d'un échantillon de taille 𝑛 extrait d'une population quelconque de moyenne 𝜇 et d'écart type 𝜎 est
distribuée selon une loi pratiquement normale de moyenne 𝜇 et d'écart type 𝜎
√𝑛 quand la taille de l'échantillon est
suffisamment grande. Pour une population de départ de distribution normale, le théorème centrale limite est valable
pour tout 𝑛. Pour les distributions rencontrées dans la pratique courante, plus la taille de l'échantillon est grande,
plus la loi se rapproche de la loi normale. On peut considérer qu'à partir de 𝑛 égale à 30, la moyenne d'un
échantillon est distribuée de façon sensiblement normale.

10
II.1 VARIABLES ALÉATOIRES CONTINUES
Une variable aléatoire continue 𝑋 est une fonction à valeurs réelles définie sur un ensemble Ω
(ensemble des événements possibles) telle que l'ensemble des valeurs prises par 𝑋, noté 𝑋(Ω), est un intervalle fini ou infini. Soit par exemple Ω un intervalle [𝑎, 𝑏] représentant l’ensemble
des valeurs possibles du diamètre des pièces en sortie d’un tour d’usinage.
Exemple de la loi uniforme (UNIF) continue : Soit 𝑋 une variable aléatoire susceptible de
prendre toutes les valeurs d'un intervalle fini [𝑎, 𝑏], sans privilégier aucune région de [𝑎, 𝑏] (on
parle d'événements équiprobables). Aussi, la probabilité que 𝑋 prenne une valeur appartenant
à l'intervalle [𝑢, 𝑣] (⊂ [𝑎, 𝑏]) est proportionnelle à la longueur de [𝑢, 𝑣], d'où
𝑃(𝑢 ≤ 𝑋 ≤ 𝑣) = (𝑣 − 𝑢)/(𝑏 − 𝑎),
soit 𝑃(𝑢 ≤ 𝑋 ≤ 𝑣) = ∫ 𝑓𝑋(𝑥)𝑑𝑥 𝑣
𝑢 où 𝑓𝑋(𝑥) = {
1/(𝑏 − 𝑎) si 𝑎 ≤ 𝑥 ≤ 𝑏0 sinon
.
La fonction 𝑓𝑋(𝑥), appelée densité de probabilité, définit le comportement aléatoire
(stochastique) de la variable aléatoire 𝑋 et permet ainsi de caractériser sa loi de probabilité
(distribution).
La loi uniforme (distribution of maximum ignorance) est utilisée lorsque l'on a aucune
information exceptée la connaissance du domaine [𝑎, 𝑏].
𝑓𝑋(𝑥) est une densité de probabilité de la variable aléatoire 𝑋 si, et seulement si,
∀ 𝑎, 𝑏 ∈ 𝑅2, 𝑃(𝑎 ≤ 𝑋 ≤ 𝑏) = ∫ 𝑓𝑋(𝑥)𝑑𝑥. 𝑏
𝑎
Remarque : Pour une variable aléatoire continue, considérer un événement du type « 𝑋 = 𝑥 »
n'a pas de sens (en effet, on a : 𝑃(𝑥 ≤ 𝑋 ≤ 𝑥) = 0).
La densité de probabilité 𝑓𝑋(𝑥) est telle que :
{𝑓𝑋(𝑥) ≥ 0, ∀ 𝑥 ∈ 𝑅,
∫ 𝑓𝑋(𝑥) 𝑑𝑥+∞
−∞= 1 (correspondant à la probabiité de l'événement certain = 1).
Remarque : 𝑓𝑋(𝑥) est continue sur 𝑅 sauf (éventuellement) en un nombre fini de points (par
exemple, la densité de la loi uniforme est continue, exceptée en 2 points).
On définit la moyenne 𝑀, aussi appelée espérance mathématique 𝐸(𝑋), par :
𝑀 = ∫ 𝑥 𝑓𝑋(𝑥) 𝑑𝑥 +∞
−∞.
On définit la variance 𝜎2 (𝜎2 ≥ 0), aussi notée 𝑉𝑎𝑟(𝑋), par :
𝜎2 = (∫ 𝑥2𝑓𝑋(𝑥) 𝑑𝑥 +∞
−∞) − 𝑀2, encore égale à ∫ (𝑥 − 𝑀)2𝑓𝑋(𝑥) 𝑑𝑥
+∞
−∞.
1
𝑏 − 𝑎
𝑓𝑋(𝑥)
0 a u v b x
aire =𝑃(𝑢 ≤ 𝑋 ≤ 𝑣)

11
Rappel (Moyenne, variance) : La moyenne constitue un paramètre de position qui renseigne
sur l'ordre de grandeur des valeurs prises par la variable aléatoire 𝑋. La variance est une mesure
de la dispersion de ces valeurs autour de leur moyenne. Plus la variance est faible (≥ 0), plus
les valeurs prises par 𝑋 sont concentrées autour de la moyenne.
Exemple : Dans le cas de la loi uniforme précédente, on a :
𝑀 = ∫ 𝑥
𝑏−𝑎 𝑑𝑥 =
𝑎+𝑏
2
𝑏
𝑎 et 𝜎2 = ∫
𝑥2
𝑏−𝑎
𝑏
𝑎 𝑑𝑥 − (
𝑎+𝑏
2)2
=(𝑏−𝑎)2
12.
On définit l'écart type (standard deviation) par 𝜎=√𝜎2.
La plus grande partie des phénomènes aléatoires rencontrés dans la pratique peut être étudiée
via un nombre restreint de lois de distribution. Nous allons à présent voir les principales lois de
distributions.
II.2 LOIS DE DISTRIBUTION STANDARD
a) LOI TRIANGULAIRE (TRIA)
{
𝑓𝑋(𝑥) =
2(𝑥−𝑎)
(𝑚−𝑎)(𝑏−𝑎) si 𝑎 ≤ 𝑥 ≤ 𝑚,
𝑓𝑋(𝑥) =2(𝑏−𝑥)
(𝑏−𝑚)(𝑏−𝑎) si 𝑚 ≤ 𝑥 ≤ 𝑏,
𝑓𝑋(𝑥) = 0 sinon.
𝐷 = [𝑎, 𝑏] ; 𝑀 =𝑎+𝑚+𝑏
3 ; 𝜎2 =
𝑎2+𝑚2+𝑏2−𝑎𝑚−𝑎𝑏−𝑚𝑏
18.
Application : On utilise cette loi lorsqu'on dispose d'une estimation du minimum, du maximum
et de la valeur la plus probable.
Exercice : Soient 𝑎 = 0,𝑚 = 2, 𝑏 = 3, calculer 𝑃(1 ≤ 𝑋 ≤ 2,5).
2
𝑏 − 𝑎
a m b x
𝑓𝑋(𝑥)
aire = 1

12
b) LOI EXPONENTIELLE (EXPO)
{𝑓𝑋(𝑥) =
1
𝛽𝑒−𝑥/𝛽 si 𝑥 > 0 (𝛽 > 0),
𝑓𝑋(𝑥) = 0 sinon.
𝐷 = [0, + ∞ [ ; 𝑀 = 𝛽 ; 𝜎2 = 𝛽2.
Application : Cette loi est souvent utilisée en pratique. Par exemple, dans le cas de temps
séparant les arrivées de 2 « clients » successifs dans l'étude d'un phénomène d'attente, ou dans
le cas d'une durée de bon fonctionnement d'un équipement technique.
La loi exponentielle est la seule loi continue à permettre la prise en compte de phénomènes sans
mémoire ou sans vieillissement ou sans usure. En effet, la probabilité que 𝑋 soit supérieure, ou
égale, à 𝑥 + 𝑥0, sachant que 𝑋 est supérieure, ou égale, à 𝑥0, dépend de la valeur de 𝑥, et est
indépendante de la valeur de 𝑥0, soit : 𝑃(𝑋 ≥ 𝑥 + 𝑥0 | 𝑋 ≥ 𝑥0) = 𝑃(𝑋 ≥ 𝑥). Par exemple, il est souvent admis que la durée de vie 𝑇 d'un dispositif électronique obéit à une
loi exponentielle. Aussi la probabilité de bon fonctionnement du dispositif dans un intervalle
de temps [Δ0, Δ0 + Δ], c'est-à-dire, 𝑃(𝑇 ≥ Δ + Δ0| 𝑇 ≥ Δ0), dépend uniquement de la
longueur de cet intervalle, et non de sa position par rapport à l'axe des temps, soit :
𝑃(𝑇 ≥ Δ + Δ0 | 𝑇 ≥ Δ0) = 𝑃(𝑇 ≥ Δ)).
Démonstration : Soient l'événement 𝐴 correspondant au fait que 𝑋 ≥ 𝑥0 et l'événement 𝐵
correspondant au fait que 𝑋 ≥ 𝑥0 + 𝑥. On a 𝑃(𝑋 ≥ 𝑥0) = ∫ 𝑓𝑋(𝑥) 𝑑𝑥 +∞
𝑥0 et 𝑃(𝑋 ≥ 𝑥0 + 𝑥) =
∫ 𝑓𝑋(𝑥) 𝑑𝑥 +∞
𝑥0+𝑥. Aussi 𝑃(𝐵 | 𝐴) équivaut à 𝑃(𝑋 ≥ 𝑥0 + 𝑥 | 𝑋 ≥ 𝑥0).
Sachant que : 𝑃(𝐴 ∩ 𝐵) = 𝑃(𝐴) × 𝑃(𝐵 | 𝐴) = 𝑃(𝐵) × 𝑃(𝐴 | 𝐵) (probabilité conditionnelle),
on a 𝑃(𝐵 | 𝐴) =𝑃(𝐵)×𝑃(𝐴 | 𝐵)
𝑃(𝐴).
Sachant que 𝑃(𝐴 | 𝐵) équivaut à 𝑃(𝑋 ≥ 𝑥0 | 𝑋 ≥ 𝑥0 + 𝑥) = 1, on a 𝑃(𝐵 | 𝐴) =𝑃(𝐵)
𝑃(𝐴).
Ainsi 𝑃(𝐵 | 𝐴) =𝑃(𝐵)
𝑃(𝐴)=
𝑃(𝑋≥𝑥0+𝑥)
𝑃(𝑋≥𝑥0)=
∫1
𝛽 𝑒− 𝑢𝛽 𝑑𝑢
+ ∞ 𝑥0+𝑥
∫1
𝛽 𝑒− 𝑢𝛽 𝑑𝑢
+ ∞ 𝑥0
=
− [𝑒− 𝑢𝛽] 𝑥0+𝑥
+ ∞
− [𝑒− 𝑢𝛽] 𝑥0
+ ∞ =𝑒− (𝑥0+𝑥)𝛽
𝑒− 𝑥0𝛽
= 𝑒− 𝑥
𝛽 qui est
fonction de 𝑥 uniquement (indépendant de 𝑥0).
𝑓𝑋(𝑥)
0 x
1
𝛽

13
c) LOI NORMALE (NORM)
𝐷 = ]−∞, +∞[ ; moyenne = 𝑀 ; variance = 𝜎2.
Application : Cette loi s'applique dans le cas de processus dont la distribution est symétrique et
pour lesquels la moyenne et l'écart type sont estimés. Exemple : Variations de la longueur de
pièces fabriquées en série.
Cette loi permet de modéliser une donnée qui est la somme d'un grand nombre de données
aléatoires (théorème central limite).
Rappel : A la place de la densité de probabilité 𝑓𝑋(𝑥), on peut utiliser la fonction de répartition
𝐹𝑋(𝑥) pour caractériser la distribution d'une variable aléatoire 𝑋.
On a : 𝐹𝑋(𝑥) = 𝑃(𝑋 ≤ 𝑥) = ∫ 𝑓𝑋(𝑢) 𝑑𝑢 𝑥
− ∞ pour −∞ < 𝑥 < +∞.
𝐹𝑋(𝑥) est une fonction continue, monotone croissante, telle que 𝐹𝑋(− ∞) = 0 et 𝐹𝑋(+ ∞) = 1,
𝐹𝑋′ (𝑥) = 𝑓𝑋(𝑥). Elle permet de calculer des probabilités de la forme 𝑃(𝑎 < 𝑋 ≤ 𝑏) sans
effectuer une intégration (ce qui est le cas en utilisant 𝑓𝑋(𝑥)) ; en effet 𝑃(𝑎 < 𝑋 ≤ 𝑏) =𝐹𝑋(𝑏) − 𝐹𝑋(𝑎).
II.3 VARIABLES ALÉATOIRES DISCRÈTES
Une variable aléatoire est discrète si elle ne peut prendre qu'un nombre fini de valeurs (par
exemple : Ω ={pile, face} dans le cas du lancer d'une pièce de monnaie). Pour chaque valeur
𝑥𝑖, on associe la probabilité 𝑝(𝑥𝑖) d'apparition de cette valeur.
Pour 𝑁 valeurs, l'ensemble des probabilités associées est tel que :
∑ 𝑝(𝑥𝑖) 𝑁𝑖=1 = 1 si 𝑁 couvre l'ensemble des valeurs.
Exemple : On définit un système capable de produire quatre types de produits notés 1, 2, 3, 4.
Lors de l'arrivée des ordres de fabrication, on sait que la probabilité d'avoir un produit 1 est
égale à 1 6⁄ , celle d'avoir un produit 2 est égale à 1 3⁄ , celle d'avoir un produit 3 est égale à 1 3⁄
et celle d'avoir un produit 4 est égale à 1 6⁄ .
𝑓𝑋(𝑥)=1
𝜎√2𝜋 𝑒− (𝑥−𝑀)
2/2𝜎2
points d'inflexion
1
𝜎√2𝜋
𝑓𝑋(𝑥)
0 𝑥 𝑀 − 𝜎 𝑀 𝑀 + 𝜎
𝑀 𝑥
𝑓𝑋(𝑥)
68% des valeurs
𝜎2 petit
𝜎2 grand

14
La loi est représentée soit par le diagramme en bâtons suivant indiquant 𝑝(𝑥𝑖) en fonction de
𝑥𝑖 :
soit par un histogramme4 :
Définitions
La moyenne (arithmétique) 𝑀 est égale à ∑ 𝑥𝑖𝑝(𝑥𝑖)𝑁𝑖=1 .
Exercice : Calculer la moyenne considérée dans l'exemple précédent.
La variance 𝜎2 est égale à (∑ 𝑥𝑖2𝑝(𝑥𝑖)) − 𝑀
2𝑁𝑖=1 .
On définit la probabilité cumulée (notion utilisée dans le logiciel ARENA) par
𝑝𝑐(𝑥𝑖) = ∑ 𝑝(𝑥𝑙)𝑖𝑙=1 .
Dans l'exemple précédent, on a : 𝑝𝑐(𝑥1) =1
6, 𝑝𝑐(𝑥2) =
1
2, 𝑝𝑐(𝑥3) =
5
6, 𝑝𝑐(𝑥4) = 1.
Soit 𝑥1, ⋯ , 𝑥𝑛 un ensemble de 𝑛 valeurs discrètes possibles, la distribution empirique discrète
DISC(𝑝𝑐(𝑥1), 𝑥1, ⋯ , 𝑝𝑐(𝑥𝑖), 𝑥𝑖 , ⋯ , 𝑝𝑐(𝑥𝑛), 𝑥𝑛) est telle qu’elle retourne la valeur 𝑥𝑖 avec une
probabilité cumulée égale à 𝑝𝑐(𝑥𝑖)5. Par exemple, la loi DISC(0.3,1, 0.4,2, 1,4) retourne : la
valeur 1 avec une probabilité égale à 0.3 ; la valeur 2 avec une probabilité égale à 0.1(= 0.4 −0.3) ; la valeur 4 avec une probabilité égale à 0.6(= 1 − 0.4).
4 Ensemble de rectangles de même largeur dont les surfaces sont proportionnelles aux probabilités 𝑝(𝑥𝑖). 5 Par construction, on a : 𝑝𝑐(𝑥1) = 𝑝(𝑥1) et 𝑝𝑐(𝑥𝑛) = 1.
𝑝(𝑥𝑖)
1/3
1/6
𝑥𝑖 0 1 2 3 4
1/3
1/6
1 2 3 4 0
𝑝(𝑥𝑖)
𝑥𝑖

15
Application : Les variables aléatoires discrètes s'appliquent dans le cas d'injection directe de
données empiriques dans le modèle. Exemples : Types de pièces, taille des lots.
III DONNÉES D'ENTRÉE DU SYSTÈME
La qualité des données est aussi importante que la qualité du modèle (garbage in - garbage
out) ; ceci concerne, par exemple dans le cas d'un système de production, les temps opératoires,
les temps de bon fonctionnement, les taux de rebut, ...
Deux problèmes se posent principalement :
P1) Collecte des données
→ lesquelles ? disponibles ? pertinentes ? comment les collecter ?
P2) Systèmes stochastiques
→ lecture directe des données empiriques ou tirage à partir d'une distribution
théorique associée ?
Les sources possibles de données sont de nature différente :
- Enregistrement du passé → bases de données à interroger (problèmes de mise à jour).
- Observation du système → ressources humaines (erreurs, négligence des extrêmes et
oubli du passé).
- Systèmes similaires → attention aux inférences.
- Affirmation des fournisseurs de matériel (souvent optimistes).
- Estimation des concepteurs (à vérifier).
Deux cas sont à considérer : les données du système (moyenne, minimum, maximum, ...) sont
disponibles ou partiellement connues.
III.1 CONNAISSANCE PARTIELLE DES DONNÉES
C'est le cas des systèmes qui n'existent pas encore, ou pour lesquels il est impossible de disposer
des données désirées (temps, ressources). On doit se baser sur l'estimation des opérateurs, des
concepteurs, des fournisseurs de matériel, ...
Trois cas se présentent souvent : On dispose seulement de la moyenne, on dispose seulement
du minimum et du maximum, ou on dispose seulement du minimum, de la valeur la plus
probable ( de la moyenne, voir la loi triangulaire) et du maximum.
1. Seule la moyenne 𝑴 est disponible
On peut alors utiliser (si cela est justifié) :
- Directement 𝑀 comme valeur constante de la variable si la dispersion (écart type) est petite,
- Une distribution exponentielle (grande dispersion : forte variabilité) de paramètre 𝑀 si la
nature du phénomène le justifie.
2. 𝑴𝒊𝒏 et 𝑴𝒂𝒙 sont disponibles
On peut alors utiliser (si cela est justifié) :
- Une distribution uniforme de paramètres 𝑀𝑖𝑛 et 𝑀𝑎𝑥, c'est la distribution de l'ignorance
(il n'y a pas de raison de penser que les probabilités ne sont pas équiprobables),

16
- Si les données sont centrées autour de la moyenne 𝑀 = (𝑀𝑖𝑛 + 𝑀𝑎𝑥) 2⁄ , on peut appliquer
une distribution normale centrée autour de 𝑀 ; à partir de l'étendue des données
(𝐸𝑡𝑒𝑛𝑑𝑢𝑒 = 𝑀𝑎𝑥 −𝑀𝑖𝑛), on peut calculer l'écart type : Si les données sont nombreuses,
𝜎 = 𝐸𝑡𝑒𝑛𝑑𝑢𝑒/6, sinon 𝜎 = 𝐸𝑡𝑒𝑛𝑑𝑢𝑒/4.
3. 𝑴𝒊𝒏, 𝑴𝒂𝒙 et la valeur la plus probable 𝒎 sont disponibles
On peut alors utiliser (si cela est justifié) une distribution triangulaire de paramètres
𝑀𝑖𝑛,𝑚,𝑀𝑎𝑥.
III.2 DONNÉES EXISTANTES (accessibles à la mesure)
Le problème P2 n'ayant pas de réponse claire, les logiciels de simulation proposent souvent les
deux possibilités.
Il est souvent intéressant, pour des raisons théoriques et pratiques, de pouvoir décrire une loi de
probabilité par une distribution théorique. Ceci revient à exprimer sous forme analytique les
probabilités 𝑝(𝑥𝑘) en fonction de l'indice 𝑘. On peut alors appliquer au calcul des probabilités
des méthodes bien connues d'analyse mathématique, évitant ainsi des calculs numériques
fastidieux.
- Si les données empiriques sont directement utilisées, elles sont entrées sous forme de
distributions empiriques cumulatives (histogramme des fréquences : regroupement des
observations en classes, nombres de classes = (O√𝑛𝑏𝑟𝑒 𝑑′𝑜𝑏𝑠𝑒𝑟𝑣𝑎𝑡𝑖𝑜𝑛𝑠)). - Si on veut faire des tirages à partir des distributions théoriques, il faut :
a) Choisir une distribution en fonction de sa forme (et celle de l'histogramme des données),
b) Estimer ses paramètres,
c) Tester l'hypothèse (la distribution correspond-elle bien aux données ?).
L'étape a) est effectuée, connaissant les caractéristiques des distributions courantes et en
comparant visuellement la distribution théorique et la distribution empirique (histogramme des
fréquences).
L'étape b) implique l'utilisation des estimateurs classiques.
L'étape c) peut s'effectuer visuellement, ou en utilisant des tests statistiques d'hypothèses (Khi-
deux, Kolmogorov-Smirnov).

17
Exemple : On s'intéresse au temps de traitement d'une machine. On dispose d'un ensemble de
500 valeurs représentant l'intervalle de temps (obtenu à l'aide d'un chronomètre) entre chaque
apparition d'une pièce en sortie de la machine. L'entrée de la machine est toujours
approvisionnée. On considère 21 classes pour construire l'histogramme des fréquences.
REAL data Data pts =500 intervals = 21 Range : -1 to 12
Mean = 5,02 StdDev = 1,88 Min = -0,4531 Max = 11,3
NORMAL DISTRIBUTION : NORM.(5,02 ; 1,88)
Sq Error = 0,0008231
(*) Hypothèse : Valeurs 𝑀𝑖𝑛 et 𝑀𝑎𝑥 finies.
Une valeur 𝑥 ∈ 𝐶𝑙𝑎𝑠𝑠𝑒 𝑛 (1 ≤ 𝑛 ≤ 21) ⟺ 𝑀𝑖𝑛 + (𝑛 − 1)𝑀𝑎𝑥−𝑀𝑖𝑛
21≤ 𝑥 ≤ 𝑀𝑖𝑛 + 𝑛
𝑀𝑎𝑥−𝑀𝑖𝑛
21.
Si la valeur 𝑀𝑖𝑛 (respectivement 𝑀𝑎𝑥) = −∞ (respectivement +∞), on considère une classe [−∞, valeur réelle] (respectivement [valeur réelle, +∞]).
IV VÉRIFICATION ET VALIDATION DES MODÈLES
Les programmes de simulation se caractérisent par une évolution constante (tests de scénarii,
que se passe-t-il si ?, ...). La difficulté majeure est de savoir :
• Comment avoir confiance dans le modèle ?
• Comment le transmettre à l'utilisateur ?
Avant de tirer des inférences des résultats statistiques d'un modèle/programme de simulation,
il faut s'assurer qu'il représente bien le système. Ceci passe habituellement par deux étapes : la
vérification et la validation.
IV.1 VÉRIFICATION
La vérification consiste à s'assurer que le modèle fonctionne comme le souhaite le concepteur
(sans erreur de logique), ce qui nécessite de pouvoir isoler les erreurs (étape la plus difficile)
afin de les corriger. La vérification est rendue plus facile si on commence par un modèle simple
Nbre de valeurs
appartenant à la
classe
n°1, n°2, ... (*)
𝑀𝑖𝑛
Cl. 1 …. Cl. 21
𝑀𝑎𝑥

18
qu'on améliore (enrichi) progressivement. Les techniques (ou comportement à avoir) suivantes
permettent l'isolation des erreurs :
1. Considérer toujours que le modèle contient des erreurs et les chercher (approche destructive,
plutôt que constructive).
2. Impliquer des personnes non concernées par la conception et l'implémentation.
3. Réviser le modèle et les données avec l'aide d'au moins un client et un connaisseur du langage
(en plus du développeur).
4. Effectuer des tests :
- Remplacer des temps aléatoires par des constantes,
- Tester seulement une partie du modèle,
- Tester le modèle dans des conditions limites. Pour cela :
- Augmenter le taux d'arrivée et/ou diminuer le taux de service pour créer des
congestions, ou des phénomènes de « famines » de machines,
- Réduire la taille des stocks pour créer des blocages,
- Modifier la distribution des types de pièces (job mix) pour augmenter l'arrivée des
pièces de types moins fréquents,
- Augmenter le taux d'occurrence des événements moins fréquents (par exemple
une panne).
5. Générer et analyser la trace du modèle pour vérifier le cheminement des pièces, les
changements d'état à l'issue d'une attente (au niveau d'une file, par une activité, ...).
6. Utiliser l'animation (technique puissante).
7. Corriger les erreurs en identifiant les vraies causes et ne pas traiter seulement les symptômes
(le raisonnement logique reste la meilleure approche).
8. Eviter des erreurs classiques, notamment vis-à-vis :
- De la saisie des données d'entrée,
- De la phase d'initialisation (unités de mesures),
- Du contrôle du flux,
- De l'existence de blocages,
- Des erreurs arithmétiques (parenthèses, conversion de types, ...),
- Des erreurs d'enregistrement (temps d'arrivée des pièces, compteurs, ...),
- D'une mauvaise utilisation des primitives ou fonctions du langage.
IV.2 VALIDATION
Trois questions doivent être posées :
• Le modèle représente-t-il correctement le système réel (validité conceptuelle) ?
• Les données sur le comportement générées par le modèle sont-elles caractéristiques
de celles du système réel (validité opérationnelle) ?
• L'utilisateur a-t-il confiance dans les résultats du modèle (confiance) ?
Trois points de vue sont à prendre en compte :
- Celui du développeur,

19
- Celui d'une personne évaluant le modèle (superviseur, client),
- Celui de l'utilisateur final (décideur).
Trois types de tests :
1. Le comportement est-il raisonnable ?
- Continuité : Petits changements dans les paramètres d'entrée
→ petits changements dans les variables de sortie et les variables d'état.
- Consistance : Exécutions presque identiques
→ résultats presque identiques (exemple : Générateur aléatoire changé).
- Dégénérescence : Suppression d'une composante (d'un « mode ») du modèle
→ effets sur les résultats (exemple : Une machine supprimée).
- Conditions absurdes : Paramètres d'entrées absurdes
→ résultats absurdes (exemple : Porter le budget de la publicité à l'infini ne doit
pas entraîner des ventes infinies).
2. Test des données et de la structure du modèle
Les théories et les hypothèses doivent être correctes et la représentation du modèle doit être en
adéquation par rapport à l'utilisation désirée.
→ Validité de « façade » : Le comportement semble correct pour des personnes familières avec
le système réel (logique, entrées-sorties).
→ Vérification de la structure et des limites : Correspondance entre le modèle conceptuel et le
système de référence.
3. Test du comportement du modèle
Il consiste à étudier le comportement du modèle en relation avec le système de référence.
→ Comparaison de comportements : Tests statistiques pour comparer les résultats (Khi-deux,
Kolmogorov-Smirnov, ...).
→ Générer des symptômes :
- Le modèle génère des difficultés déjà connues dans le système ?
- Le modèle produit des résultats connus pour des entrées données ?
→ Anomalie de comportement : Une anomalie dans le modèle peut amener à découvrir
l'anomalie équivalente dans le système réel ?
→ Prédiction de comportement : Prédiction du modèle contre des tests sur le terrain.
V INTERPRÉTATION DES RÉSULTATS
Selon le logiciel utilisé, l'exécution d'un programme de simulation peut générer :

20
- Un rapport de simulation comprenant les moyennes, les écarts types, les minimums et
maximums des variables observées, ...
- Un historique de l'évolution de ces variables au cours de la simulation.
La qualité de la moyenne (arithmétique) comme estimateur de la vraie moyenne dépend, entre
autres, du nombre des observations. De même, l'écart type est biaisé pour un petit nombre
d'observations. On peut utiliser son rapport à la moyenne pour mesurer la dispersion des valeurs
(en plus du minimum et du maximum).
Un tel rapport de simulation ne suffit pas pour tirer des conclusions crédibles sur les
performances du système. Il suffit de changer le générateur de nombres aléatoires pour que le
même modèle génère des résultats différents. L'animation graphique n'est pas suffisante non
plus. En fait, on a souvent tendance à se contenter du rapport de simulation et/ou de l'animation,
surtout quand le projet est en retard.
Les résultats générés par un modèle jouent le rôle de mesures sur un échantillon. Il faut donc
les exploiter pour effectuer des procédures statistiques. A chaque variable (inconnue), il faut
associer un intervalle de confiance.
Rappel (Intervalle de confiance) : L'intervalle de confiance [𝑐1, 𝑐2] du paramètre inconnu 𝜆
est défini à l'aide de 2 grandeurs statistiques 𝐶1, 𝐶2 de telle sorte qu'il recouvre, avec une
probabilité donnée 1 − 𝛼, la (vraie) valeur inconnue de 𝜆, soit :
𝑝(𝐶1 ≤ 𝜆 ≤ 𝐶2) = 1 − 𝛼.
La probabilité 1 − 𝛼, associée à cette estimation par intervalle, est appelée niveau de confiance
ou seuil de confiance. Les valeurs les plus souvent utilisées pour 1 − 𝛼 sont : 0,90 ; 0,95 ; 0,99
et 0,999.
Chaque réalisation des deux statistiques 𝐶1, 𝐶2 donne lieu à un intervalle de confiance
numérique [𝑐1, 𝑐2]. La notion de niveau de confiance est alors à interpréter dans le sens suivant.
Si l'on effectue un grand nombre de réalisations des deux statistiques (𝐶1, 𝐶2), alors la valeur
inconnue du paramètre 𝜆 sera recouverte par environ 100(1 − 𝛼) % des intervalles [𝑐1, 𝑐2] ainsi obtenus.
La longueur d'un intervalle de confiance diminue :
• En augmentant la taille 𝑛 de l'échantillon,
• En diminuant la dispersion de la variable aléatoire 𝜆 étudiée,
• En choisissant un seuil de confiance moins élevé par exemple en prenant 0,90 au lieu
de 0,95. Dans Arena (lorsque le nombre de réplication est supérieur à 1), la demi-largeur
(half width) se rapporte à un intervalle de confiance dont le seuil est égal à 95%.
Il existe deux types de systèmes : Les systèmes finis – c'est-à-dire, ayant un événement de fin
qui détermine la fin de la simulation - et les systèmes qui ne se terminent pas - c'est-à-dire,
n'ayant pas d'événement de fin de simulation. Par exemple, un commerce qui ouvre et qui ferme
à intervalles réguliers est un système fini ; par contre, un hôpital où il y a toujours au moins un
patient est un système qui n'est pas fini.

21
V.1 ANALYSE DES SYSTÈMES FINIS
Ils sont plus faciles à analyser que les systèmes qui ne se terminent pas. On ne peut contrôler
que le nombre des répétitions des expériences. A chaque répétition, on peut utiliser un autre
générateur des nombres aléatoires.
Deux sources de données d'observation :
a) Observations individuelles dans chaque répétition/expérience (par exemple, le temps de
traitement de chaque pièce),
b) Moyennes, écarts-types, maximums, minimums des observations dans chaque répétition
(par exemple, le temps de traitement moyen des pièces).
Si l’on change le générateur des nombres aléatoires d'une répétition à l'autre, on peut considérer
que les observations de type b) d'un ensemble de répétitions sont telles que :
- Elles sont indépendantes,
- Les moyennes sont normalement distribuées.
Cette dernière propriété est due au fait qu'elles sont sommes, ou moyennes, d'observations
individuelles (théorème central limite).
Les procédures classiques de statistiques peuvent alors s'appliquer pour les moyennes. Pour les
minimums et maximums, certaines procédures de statistiques s'appliquent encore.
A partir des observations de type b), on peut calculer en particulier :
- Des intervalles de confiance autour de la moyenne, du maximum et du minimum,
- Des intervalles de confiance autour de la différence entre les moyennes, les maximums et
les minimums de deux systèmes différents.
Cette comparaison de deux systèmes est utile pour évaluer par exemple la différence entre deux
dimensionnements, deux règles d'ordonnancement, ... (si l'intervalle de confiance ne contient
pas 0, on peut en déduire que les deux systèmes sont différents).
Procédure générale :
- Simuler un grand nombre d'expériences/répétitions (minimum 20) et récupérer chaque fois les
observations souhaitées (moyennes, maximum, minimum, ...) ;
- Analyser le comportement du système en se basant sur la valeur moyenne pour chaque
expérience :
- Utilisation de l'histogramme,
- Calcul de l'intervalle de confiance.
- Déterminer le nombre d’expériences à l'aide de l'analyse des résultats en fonction des
précisions souhaitées pour l'intervalle de confiance. Utiliser la formule 𝑛2 = 𝑛1 (ℎ1/ℎ2)2 où
𝑛1 est le nombre d’expériences déjà réalisées,
𝑛2 est le nombre total d’expériences,
ℎ1 est la moitié de l'intervalle de confiance déjà obtenu,
ℎ2 est la moitié de l'intervalle de confiance souhaité.
- Simuler encore : Soit tout recommencer, soit rajouter les résultats des nouvelles simulations à
ceux des premières ;
- Analyser : Intervalle de confiance, histogramme.

22
V.2 ANALYSE DES SYSTÈMES QUI NE SE TERMINENT PAS
On s’intéresse à l'étude des performances stationnaires d’un système du fait d’un régime
transitoire souvent favorable aux performances du système ; ce peut être, par exemple, le cas
d’un atelier vide au début de la simulation. L'état stable du système correspond à son
comportement après un certain temps et est indépendant de l'état de départ.
Le but est de calculer un intervalle de confiance autour de la moyenne. Deux problèmes peuvent
se poser :
- Pas de point de passage précis entre le régime transitoire et le régime stationnaire,
- Corrélation entre les observations.
Problème du régime transitoire
Il existe trois méthodes pour traiter le problème du régime transitoire :
- Choisir des conditions de départ qui ressemblent aux conditions de régime permanent
(par exemple : Charger les machines, mettre les pièces dans les files d'attente).
- Faire des simulations assez longues pour rendre le régime transitoire insignifiant.
- Ecarter les valeurs enregistrées pendant le régime transitoire. Pour cela, on peut
éventuellement utiliser le filtre de la moyenne glissante (moyenne arithmétique des k
observations récentes) pour réduire la variabilité de la variable.
C'est cette dernière méthode qui est couramment utilisée. Il existe certaines règles pour
sélectionner la partie à tronquer, mais il n'y a aucune méthode complètement satisfaisante. La
plus utilisée est d'évaluer (visuellement) la période transitoire à l'aide des graphes (courbes,
histogrammes, moyennes mobiles).
Intervalles de confiance
Deux méthodes sont couramment utilisées :
- Répétition d'expériences indépendantes comme pour les systèmes finis (problème du
régime transitoire à chaque fois),
- Longue simulation et décompositions des données générées en sous-ensembles (batchs).
Cette dernière méthode consiste à :
- Ecarter le régime transitoire,
- Décomposer les observations restantes en 𝑛 batchs de taille 𝑚 et sans chevauchement,
- Remplacer chaque batch 𝐵𝑗 (𝑗 = 1, 2,⋯ , 𝑛) par 𝑋𝑗, moyenne des 𝑚 observations dans
𝐵𝑗 ,
- Calculer l'intervalle de confiance à partir des observations 𝑋𝑗, 𝑗 = 1, 2,⋯ , 𝑛.
Ici encore, les conditions du théorème central limite sont considérées vraies et le calcul de
l'intervalle de confiance justifié (indépendance et normalité des observations 𝑋𝑗).
Indications : 𝑛 = 10 𝑙𝑎𝑔∗, 𝑚 de 10 à 20.
Corrélogramme → 𝑙𝑎𝑔∗ : Le plus grand nombre d'observations pour lequel la
corrélation est encore significative.
Cette méthode (présentée pour des variables ne dépendant pas du temps comme le nombre de
pièces finies) est évidemment applicable pour les variables persistantes (dépendant du temps)
comme les tailles des files d'attente. Il suffit de définir les batchs par des intervalles de temps
réguliers au lieu d'un nombre fixé de données.

23
VI NOTIONS ELÉMENTAIRES SUR LES RÉSEAUX DE PETRI
VI.1 GÉNÉRALITÉS
Définition (Réseau de Petri)
Un réseau de Petri (RdP) est un graphe constitué de 2 sortes de nœuds : Les places (représentées
par des ronds) et les transitions (représentées par des barres). Le graphe est orienté : Des arcs
vont d'une sorte de nœuds à l'autre (jamais de places à places, ou de transitions à transitions
directement). Voir exemple dans la figure suivante.
De façon plus formelle, un RdP peut-être défini par un 4-uplet < 𝑃, 𝑇, 𝑃𝑟é, 𝑃𝑜𝑠𝑡 > tel que :
𝑃 = {𝑃1, 𝑃2, ⋯ , 𝑃𝑛} est un ensemble fini et non vide de places ;
𝑇 = {𝑇1, 𝑇2, ⋯ , 𝑇𝑚} est un ensemble fini et non vide de transitions ;
𝑃𝑟é: 𝑃 × 𝑇 → {0, 1} est l'application d'incidence avant ;
𝑃𝑜𝑠𝑡: 𝑃 × 𝑇 → {0, 1} est l'application d'incidence arrière.
𝑃𝑟é(𝑃𝑖, 𝑇𝑗) est le poids de l'arc (orienté) reliant la place 𝑃𝑖 à la transition 𝑇𝑗 ; ce poids vaut 1 si
l'arc existe et 0 sinon.
𝑃𝑜𝑠𝑡(𝑃𝑖 , 𝑇𝑗) est le poids de l'arc (orienté) reliant la transition 𝑇𝑗 à la place 𝑃𝑖.
Marquage des places
Les places sont marquées par des jetons (points noirs). Les jetons vont circuler dans les places
du fait du franchissement de transitions en suivant certaines règles définies ci-dessous. L'état
du réseau à un instant 𝑡 est défini par le nombre de jetons contenus dans chaque place à l’instant
𝑡. La circulation des jetons représente l'évolution dynamique de l’état du réseau. Le marquage
initial correspond à celui indiqué sur le dessin et donne la position initiale des jetons.
Règles de fonctionnement et circulation des jetons
Pour qu'une transition puisse être activée, la présence d'un jeton au moins est requise dans
chaque place située en amont de la transition. L'activation (le tir) de la transition a pour effet
de prélever ces jetons des places amont et de rajouter dans chaque place aval un nouveau jeton.
De façon plus formelle, le franchissement (tir) d'une transition 𝑇𝑗 ne peut s'effectuer que si le
marquage de chacune des places 𝑃𝑖 directement en amont de cette transition est tel que :
𝑚(𝑃𝑖) ≥ 𝑃𝑟é(𝑃𝑖, 𝑇𝑗) (condition nécessaire).
Le franchissement (tir) de 𝑇𝑗 consiste à retirer 𝑃𝑟é(𝑃𝑖 , 𝑇𝑗) jetons dans chacune des places
directement en amont de 𝑇𝑗 et à ajouter 𝑃𝑜𝑠𝑡(𝑃𝑘, 𝑇𝑗) jetons dans chacune des places 𝑃𝑘
directement en aval de 𝑇𝑗.
𝑃6
𝑃7
𝑃5
𝑃4
𝑃3
𝑇2
𝑇3
𝑇4
𝑇6
𝑇5
𝑇1
𝑃1
𝑃2

24
Exercice : Exprimer sous une forme matricielle les applications 𝑃𝑟é et 𝑃𝑜𝑠𝑡 relatives au RdP
précédent. Valider à travers quelques exemples le bon fonctionnement de l’équation
d’évolution du marquage : 𝑀𝑘 = 𝑀𝑙 + (𝑃𝑜𝑠𝑡 − 𝑃𝑟é) 𝑇𝑘 𝑙, où 𝑇𝑘 𝑙 est le vecteur de tirs permettant une évolution du vecteur de marquage, de 𝑀𝑙 vers 𝑀𝑘.
Modélisation de la concurrence (ou logique) et de la synchronisation (et logique)
- Concurrence à la fourniture de jetons dans une place : C'est la convergence d'arcs sur
une place (voir figure a suivante).
- Concurrence à la consommation des jetons d'une place : C'est la divergence d'arcs à
partir d'une place (voir figure b suivante). Ce conflit structurel doit être arbitré par une
règle de priorité quelconque lorsque le conflit est effectif (c'est-à-dire lorsque les
transitions aval en compétition pourraient effectivement être activées). Ne pas arbitrer
un conflit effectif fait que le comportement du système n'est pas entièrement spécifié.
- Synchronisation dans la consommation de jetons de plusieurs places : C'est la
convergence de plusieurs arcs sur une transition (voir figure c suivante).
- Synchronisation dans la fourniture de jetons à plusieurs places : C'est la divergence
d'arcs à partir d'une transition (voir figure d suivante).
Temporisation des places et/ou des transitions
A priori, on peut penser à l'activation d'une transition comme au déroulement d'une tâche : Il
faudrait alors mettre une temporisation sur les transitions. Par ailleurs, si on pense à une place
comme un endroit où une ressource séjourne en attendant de poursuivre son parcours, il peut y
avoir une durée minimale de séjour à respecter : Penser par exemple au séjour d'une pièce dans
un four pour atteindre une température souhaitée.
On est donc tenté de mettre à la fois :
- Une durée d'activation pour les transitions : Durée pendant laquelle un jeton situé dans
chaque place amont de la transition activée est « réservé » pour cette transition (avant
de disparaître), et au-delà de laquelle un jeton apparaît dans chacune des places aval ;
- Une durée minimale de séjour dans les places : Durée pendant laquelle tout jeton qui
vient d'être produit dans une place ne peut pas encore servir à l'activation de transitions
aval.
En fait, il n'y a aucune perte de généralité à ne mettre de temporisations que sur les transitions,
ou que sur les places. La figure suivante montre la transformation d'une transition de durée Δ
en 2 transitions instantanées (le début et la fin) séparées par une place de temporisation Δ.
a b c d
Δ Δ

25
VI.2 GRAPHES D'ÉVÉNEMENTS
Restrictions et capacités de modélisation
Les graphes d'événements sont une sous-classe de RdP pour lesquels toute place a exactement
une transition amont et une transition aval (les situations représentées dans les figures a et b
précédentes sont interdites). Aussi, les graphes d'événements peuvent modéliser des
phénomènes de synchronisation, mais pas de concurrence.
A l'opposé, les graphes d'état refusent les configurations représentées dans les figures c et d
précédentes pour ne retenir que celles représentées dans les figures a et b. Aussi, les graphes
d'état, tels que toute transition a exactement une place d'entrée et une place de sortie, permettent
de visualiser des phénomènes de concurrence (décision), mais pas de synchronisation.
Une propriété fondamentale des graphes d'événements
Le nombre total de jetons le long de tout circuit d'un graphe d'événements reste constant. Ceci
n'est généralement pas vérifié dans le cas d'un RdP (le nombre de jetons total d'un RdP ne reste
pas nécessairement constant au cours de l'évolution du marquage du réseau).
VI.3 EXEMPLES
Soit une machine représentée dans la figure suivante. Chaque pièce qui arrive est, soit traitée
immédiatement par la ressource machine, soit mise en attente dans le stock (à capacité infinie)
jusqu'à ce que la ressource machine soit disponible. Le temps de traitement de la ressource
machine est de 3 unités de temps. Après traitement, chaque pièce sort.
Le RdP suivant modélise ce système.
arrivée
pièce
stock ressource
machine
sortie
pièce
3 stock
ressource machine libre
ressource machine occupée
Arrivée
pièce Sortie
pièce
Démarrage

26
Modifications
a) Le modèle RdP suivant indique une capacité de stockage limitée à 5 pièces.
b) Le stock en amont de la ressource machine est remplacé par un convoyeur correspondant à
une file composée de 5 compartiments (gestion First-In, First-Out du convoyeur). Le temps
de déplacement du convoyeur est de 6 unités de temps. Le système est représenté par le
modèle RdP suivant.
c) La machine a une capacité de traitement de 2 : Elle est capable de traiter 2 pièces
simultanément. Le système est représenté par le modèle RdP suivant.
d) La machine a un temps de setup de 1,5 unités de temps. Le système est représenté par le
modèle RdP suivant.
3 stock
ressource machine libre
ressource machine occupée
Arrivée
pièce Sortie
pièce
5
Démarrage Arrivée
pièce …
6/5 6/5 6/5
3
ressources machine libres
ressources machine occupées
Sortie
pièce
Démarrage
2
3
ressources machine libres
ressources machine occupées
Sortie
pièce
Démarrage
2
1,5

27
VI.4 AUTRES CLASSES DE RÉSEAUX DE PETRI
Réseau de Petri temporel
Ces réseaux permettent l’analyse de systèmes à contraintes de temps. Un intervalle, et non plus
une simple valeur scalaire, est associé aux places et/ou aux transitions. Le fait d’associer un
intervalle [𝑎, 𝑏] à une place fait qu’un jeton présent dans cette place devra séjourner au moins
𝑎 unités de temps. Il pourra contribuer à la validation d’une transition située en aval si son
temps de séjour est inférieur à 𝑏 unités de temps, au-delà le jeton meurt et de ce fait ne
contribuera plus à la validation d’une transition située en aval.
Réseau de Petri synchronisé
Un ensemble d'événements externes est associé au RdP ; ces événements permettent le
franchissement de certaines transitions. Un tel RdP est dit synchronisé.
Considérons le RdP modélisant la machine décrite dans VI.3. On associe à ce RdP l'ensemble
d'événements {𝐴, 𝐷, 𝑆} où 𝐴 désigne l'événement « Arrivée pièce », 𝐷 l'événement
« Démarrage service », 𝑆 l'événement « Sortie pièce ». La figure suivante représente le système
modélisé par un RdP synchronisé.
Le tir de la transition 𝑇1 est lié à l'occurrence de l'événement 𝐴.
Le tir de la transition 𝑇2 est lié :
- A la validation de la transition, matérialisée par la présence d'au moins un jeton dans la
place « stock » et d'un jeton dans la place « ressource machine libre » ;
- Au démarrage effectif du service (occurrence de l'événement 𝐷).
Le tir de la transition 𝑇3 est lié à l'occurrence de l'événement 𝑆.
Réseau de Petri généralisé
Un RdP généralisé est un RdP dans lequel les poids associés aux arcs sont des nombres entiers
strictement positifs. Ces poids peuvent être différents de 0 ou 1.
Tous les arcs, dont le poids n'est pas explicitement spécifié, ont un poids de 1.
Soit un arc reliant une place 𝑃𝑖 à une transition 𝑇𝑗 ayant un poids égal à 𝑝, alors la transition 𝑇𝑗
ne sera validée que si la place 𝑃𝑖 contient au moins 𝑝 jetons. Lors du franchissement de cette
transition, 𝑝 jetons seront retirés de la place 𝑃𝑖. Le fait qu'un arc relie une transition 𝑇𝑗 à une place 𝑃𝑖 avec un poids égal à 𝑝, signifie que lors
du franchissement de cette transition, 𝑝 jetons seront ajoutés à la place 𝑃𝑖.
3 stock
ressource machine libre
ressource machine
occupée
Arrivée
pièce Sortie
pièce
𝑨 𝑫 S
𝑇1
𝑇2
𝑇3 Démarrage
Assemblage
2

28
VII LE LANGAGE DE SIMULATION ARENA
Le logiciel SIMAN-ARENA6 a été conçu en 1982 par C.D. Pedgen de System Modeling
Corporation, ARENA représentant la version « graphique » de SIMAN. La description du
modèle (logiciel) du système simulé se fait à l'aide d'un assemblage constitué de mise en série,
en parallèle ou en feedback de différents blocs fonctionnels, issus de bibliothèques (templates)
d’ARENA. Une telle approche de modélisation permet d'obtenir une structure du modèle
(logiciel) proche de celle du système (réel) à simuler.
VII.1 NOTIONS DE BASE
Entité : Une entité est un objet qui évolue dans les différents blocs fonctionnels constituant le
modèle du système. Elle correspond en général à un objet concret, par exemple, une
personne ou une pièce dans un atelier. Le déplacement des entités au sein des différents
blocs - par exemple le déplacement de pièces dans un atelier - provoque un changement
d'état du modèle de simulation, ce qui est analogue aux déplacements des jetons dans
un modèle RdP.
Attribut : Un attribut est une variable associée individuellement aux entités (la variable est
locale) pour représenter leurs états ou des paramètres qui leur sont propres. Par
exemple, chaque entité, représentant une pièce circulant dans un atelier, peut avoir les
attributs suivants :
- Type_de_piece afin de désigner le type d'une pièce (par exemple, Type_de_piece =
A ou B) ;
- Indice_de_priorite afin de désigner l'indice de priorité d'une pièce (par exemple,
Indice_de_priorite = faible ou importante) ;
- Date_arrivee_ds_le_modele (par exemple, Date_arrivee_ds_le_modele = TNOW).
Variable globale : Une variable globale concerne l'ensemble du modèle. Par exemple, la
variable TNOW (variable prédéfinie dans ARENA) désigne la date à laquelle se trouve
la simulation, c'est le temps courant - mis à jour à chaque avancée dans l'échéancier des
événements – s’écoulant durant une simulation du modèle.
Le principe de fonctionnement du logiciel ARENA est de permettre l’évolution de chacune des
entités d'un bloc fonctionnel vers un autre, de sa création dans le modèle à sa destruction.
L’ordonnancement dans le temps des différents événements rattachés à l'évolution des entités
dans les blocs constituant le modèle se fait au travers d’un échéancier.
Quand une entité rentre dans un bloc fonctionnel, elle déclenche/active le « service » qui lui est
associé, ce qui provoque une modification de l'état du modèle. Un « service » peut agir :
- sur l'entité au travers de la valeur de ses attributs. Par exemple, à travers un bloc Assign,
on peut affecter à l'attribut indice_de_priorite d'une entité représentant une pièce, présente
dans le bloc, la valeur importante ;
- sur les variables globales du modèle logiciel. Par exemple, le passage d’une entité dans un
bloc Delay provoque un retard pur, ce qui aura une conséquence sur la variable TNOW.
6 Une documentation électronique est fournie avec le logiciel ARENA à travers différents fichiers
(ArenaBEUsersGuide.pdf, ArenaVariablesGuide.pdf, ArenaSEUsersGuide.pdf) accessibles dans le répertoire
\Rockwell Software\Arena\.

29
Un programme (ou modèle logiciel) élaboré avec ARENA est sauvegardé dans un fichier ayant
pour extension .doe et est constitué :
- d'une partie modèle, qui représente l'algorithme décrivant les caractéristiques statiques et
dynamiques des différents blocs fonctionnels composant le modèle ;
- du cadre expérimental, qui regroupe les données précisant les paramètres spécifiques à une
simulation donnée (conditions initiales, durée de la simulation, …).
En fait, les entités traversent uniquement les blocs fonctionnels de la partie modèle.
Considérons un simple tapis roulant, ayant un temps de transport de 3 unités de temps,
représenté par le modèle logiciel décrit comme suit :
Le bloc Create, issu du template Basic Process, est tel qu'une entité est créée à partir de l’instant
0, ceci toute les 2 unités de temps.
Le bloc Delay, issu du template Advanced Process, force une entité à séjourner 3 unités de
temps dans le bloc.
Le bloc Dispose, issu du template Basic Process, détruit toute entité entrant dans le bloc.
A travers le menu Run/Setup/Replication Parameters, on peut notamment fixer :
- le nombre de réplications (champ Number of Replications),
- le temps où se termine une réplication (champ Replication Length).
A travers le menu Run/Setup/Project Parameters, on peut notamment donner :
- un titre au projet (champ Project Title),
- le nom du programmeur (champ Analyst Name),

30
- un commentaire (champ Project Description).
Les 2 fichiers générés par ARENA (au format txt) sont accessibles via le menu
Run/SIMAN/View (voir ci-dessous un listage partiel de ces fichiers).
• fichier Exemple.mod : (partie modèle)
; Model statements for module: Create
2$ CREATE, 1,HoursToBaseTime(0.0),Entity 1:HoursToBaseTime(2):NEXT(0$);
;
; Model statements for module: Delay
0$ DELAY: 3,,Other:NEXT(1$);
;
; Model statements for module: Dispose
1$ DISPOSE: Yes;
0$, 1$, 2$ sont des étiquettes.
• fichier Exemple.exp : (cadre expérimental)
PROJECT,"Premier exemple","ISTIA",,,No,Yes,Yes,Yes,No,No,No,No,No,No;
REPLICATE, 1,,HoursToBaseTime(10),Yes,Yes,,,,24,Hours,No,No,,,Yes;

31
Le modèle RdP correspondant à la partie modèle du modèle logiciel précédent est décrit dans
la figure suivante :
ARENA permet de construire un modèle en proposant des primitives de représentation
(appelées par la suite, blocs ou modules) plus ou moins détaillées. Il permet également de créer
des animations graphiques pour visualiser le comportement du modèle durant la simulation.
Les blocs sont regroupés dans différentes bibliothèques (templates).
Des liens sont utilisés pour permettre les assemblages en série, en parallèle, en feedback, entre
les blocs, voir une illustration de tels assemblages dans le RdP qui suit.
VII.2 BLOCS PERMETTANT LA CONSTRUCTION D’UN MODÈLE
a) Create (issu du template Basic Process) : Un bloc Create permet de créer des entités. Celui
représenté dans la figure suivante est intitulé Create 1 (champ Name = Create 1).
Sont indiqués :
- dans le cadre Time Between Arrivals, le temps entre deux créations de lots d’entités. Par
exemple un temps égale à 2 lorsque : champ Type = Constant et champ Value = 2, ou un
temps régit par une loi exponentielle de moyenne 1 lorsque : champ Type = Expression et
champ Value = EXPO(1),
- la taille des lots (champ Entities per Arrival = 1),
- le nombre total de lots à créer (champ Max Arrivals = Infinite),
- la date de création du premier lot (champ First Creation = 0).
3
2

32
Les valeurs considérées sont telles qu'1 entité est créée toute les 2 unités de temps à partir de
l’instant 0, ceci une infinité de fois.
Le RdP suivant permet de décrire le bloc Create 1.
Le nombre de tirs de la transition de sortie de ce RdP à un instant t correspond au nombre
d’entités sorties du bloc Create au même instant t. Notons que le bloc Create n’a pas d’entrée.
b) Dispose (issu du template Basic Process) : Un bloc Dispose permet de détruire des entités.
Celui représenté dans la figure suivante est intitulé Dispose 1 (champ Name = Dispose 1), une
entité entrant dans ce bloc est immédiatement détruite.
En termes de RdP, ce bloc, qui n’a pas de sortie, équivaut à une transition puit, c'est-à-dire, une
transition sans place située en aval.
Type (Constant), Value (2)
Max
Arrivals
(∞)
Entities per
Arrival (1) First
Creation
(0)
P
Sortie de
l’entité du
bloc Create

33
c) Delay (issu du template Advanced Process) : Un bloc Delay permet de retarder le passage
d'entités. Celui représenté dans la figure suivante est intitulé Delay 1 (champ Name = Delay 1),
quand une entité entre dans ce bloc, elle y reste inconditionnellement pendant la durée (aléatoire
ou non) indiquée dans le champ Delay Time.
Le RdP suivant permet de décrire un bloc Delay.
Le nombre de jetons présents dans la place correspond au nombre d'entités présentes dans le
bloc Delay.
d) Seize (issus du template Advanced Process) : Une entité présente dans un bloc Seize ne peut
sortir de ce bloc que s’il existe un nombre suffisant de ressources disponibles (le nombre et le
type de ressources étant spécifiés dans le bloc) ; en attendant l’entité est stockée (« patiente »)
dans une file d’attente interne au bloc Seize. Le fait qu'une entité sorte du bloc indique que les
ressources, disponibles en nombre suffisant, sont « saisies » (et donc plus disponibles).
Le bloc représenté dans la figure suivante est intitulé Seize 1 (champ Name = Seize 1). Pour
simplifier la compréhension, considérons que seulement un type de ressource est concerné
(dans l’exemple, Resource 1), alors :
- le nom de la ressource est spécifié dans le champ Resource Name, soit Resource Name =
Resource 1 (l’ajout d’un autre type de ressource donnerait lieu à une ligne supplémentaire
dans la liste Resources),
- le nombre (minimum) de ressources (de type Resource 1) disponibles est spécifié dans le
champ Units to Seize, par exemple Units to Seize = 1.
Sachant qu'une ressource peut ne pas être disponible, les entités, en attente d'un nombre
suffisant de ressources disponibles, sont stockées dans une file d'attente, intégrée (en amont) au
bloc Seize, et dont le nom est indiqué dans le champ Queue Name (soit Queue Name = Seize
1.Queue).
Delay Time
Entrée d'une entité
dans le bloc Delay
Sortie de l'entité
du bloc Delay

34
Le RdP suivant permet de décrire un bloc Seize dans le cas où un seul type de ressource (dans
l’exemple, Resource 1) est requis.
La transition T pour être activée doit :
- contenir (au moins) un jeton dans la place P1, ce qui correspond à la présence dans la file
d’attente d'au moins une entité dans le bloc Seize.
- contenir (au moins) Units to Seize jetons dans la place P2, ce qui signifie qu’au moins Units
to Seize ressources Resource Name sont disponibles.
Le fait de franchir la transition T a pour effet d'ôter 1 jeton dans la place P1 et d’ôter Units to
Seize jetons dans la place P2, ce qui représente la sortie d’une entité du bloc Seize et la « saisie »
de Units to Seize ressources Resource Name.
Le nombre de jetons présents dans la place P1 correspond au nombre d'entités présentes (en
attente) dans le bloc Seize.
▪ Une file d’attente est caractérisée (configurée) par le bloc Queue (issu du template Basic
Process, appartenant au cadre expérimental et donc non traversé par une entité), voir la figure
suivante :
- le champ Name permet de déclarer une file d’attente, par exemple Seize 1.Queue,
File d’attente
(Seize 1.Queue)
T P1
P2
Units to
Seize
Entrée d'une entité
dans le bloc Seize
Sortie de l'entité
du bloc Seize
Saisie de (Units to Seize = 1) ressources
(Resource Name = Resource 1)
ressources
disponibles

35
- le champ Type permet d’indiquer le mode de gestion de la file d’attente. Par défaut, le
mode de gestion est de type First In, First Out (FIFO). D’autres modes sont possibles :
Last In, First Out (LIFO), Lowest Attribute Value (LAV), Highest Attribute Value (HAV).
Ces deux derniers modes permettent de prioriser les entités présentes dans la file d’attente
ayant la plus petite (Lowest), ou la grande (Highest), valeur de l’attribut (défini dans le
champ Attribute Name) rattaché au mode de gestion utilisé.
Le bloc Queue permet de définir plusieurs files d'attente dans un même modèle.
▪ Les types de ressource, ainsi que le nombre pour chaque type de ressources, sont indiqués
dans le bloc Resource (issu du template Basic Process, appartenant au cadre expérimental
et donc non traversé par une entité), voir la figure suivante :
- le champ Name permet de déclarer une ressource, par exemple Resource 1,
- le champ Capacity permet de définir le nombre d’unité de la ressource, par exemple 1.
Le bloc Resource permet de définir plusieurs types de ressources dans un même modèle.
e) Release (issu du template Advanced Process) : Un bloc Release permet de « relâcher » des
ressources. Celui représenté dans la figure suivante est intitulé Release 1 (champ Name =
Release 1). Quand une entité entre dans ce bloc, elle libère (relâche) la, ou les ressources dont
le nom est spécifié dans le champ Resource Name, par exemple Resource 1, le nombre de
ressources libérées est spécifié dans le champ Units to Release, par exemple 1. On peut noter
que l’exécution de cette tâche est instantanée, autrement dit le temps de passage d’une entité
dans un bloc Release est nul. Pour simplifier, seul un type de ressource est concerné (dans
l’exemple, Resource 1), l’ajout d’un autre type de ressource donnerait lieu à une ligne
supplémentaire dans la liste Resources.

36
Le RdP suivant permet de décrire un bloc Release dans le cas où un seul type de ressource (dans
l’exemple, Resource 1) est libéré.
Le fait de franchir la transition T' provoque l'apparition de Units to Release jetons dans la place
P1, ce qui représente la sortie d’une entité du bloc Release et la mise en disponibilité (le
« relâchement ») de Units to Release ressources Resource Name.
f) Assign (issu du template Basic Process) : Un bloc Assign permet d’assigner une valeur,
notamment, à un attribut, une variable (éventuellement propre à ARENA, par exemple relative
à l’état d’une ressource), durant l’exécution d’une simulation. Quand une entité entre dans un
bloc Assign, l’expression - logique ou mathématique - spécifiée dans le champ New Value est
évaluée et assignée, selon le contenu du champ Type (Attribute, Variable, …), à un attribut
(rattaché à l’entité « activant » le bloc) ou une variable. Dans la figure suivante, le bloc intitulé
Assign 1 (champ Name = Assign 1) permet de déclarer :
- une variable Variable 1 à 1 ;
- un attribut Attribute 1 à TNOW ;
- une variable Variable 2 à STATE(resource 1). La variable STATE(resource 1) restitue
l’état courant de la ressource resource 1 (les valeurs possibles sont : -1=Idle ; -2=Busy ;
-3=Inactive ; -4=Failed) ;
- une Variable 3 à Attribute 1.
Cet exemple est proposé dans \Exemples\Assign\Assign.doe.
T'
P1
Units to
Release
Entrée d'une entité
dans le bloc Release
Sortie de l'entité
du bloc Release
ressources
disponibles

37
Le RdP suivant permet de décrire le bloc Assign 1.
Le bloc Variable (issu du template Basic Process, appartenant au cadre expérimental et donc
non traversé par une entité) permet de déclarer des variables.
g) Decide (issu du template Basic Process) : Un bloc Decide permet d’aiguiller un flux d’entités
vers différents blocs de destination, il comporte une entrée et plusieurs sorties. L’aiguillage est
réalisé, selon le contenu du champ Type, d’après un critère de type condition, ou probabilité.
Variable 1 := 1
Attribute 1 := TNOW
Variable 2 := STATE(resource 1)
Variable 3 := Attribute 1
Entrée d'une entité
dans le bloc Assign
Sortie de l'entité
du bloc Assign

38
Les conditions sont par exemple basées sur des valeurs d’attributs, de variables, une expression.
Le routage se fait via un ensemble de branches.
Quand une entité entre dans un bloc Decide, chaque condition de branchement est testée de
manière séquentielle (i.e., dans l’ordre de leurs déclarations dans le bloc). La branche
sélectionnée par une entité est la première branche pour laquelle la condition de branchement
est satisfaite ; l’entité est alors aiguillée vers le bloc correspondant. Si aucune branche n’est
satisfaite, l’entité est détruite. Un bloc Decide, intitulé Decide 1 (champ Name = Decide 1), est
décrit dans la figure suivante. Le critère d’aiguillage vers les 2 sorties possibles est réalisé à
partir de la condition If Variable 1 >= 1 (avec un résultat True ou False).
Le critère utilisé par le bloc Decide 2 est de type probabilité (2 sorties, ayant chacune une
probabilité égale à 0.5, sont possibles).

39
Le RdP suivant permet de décrire un bloc Decide.
Notons que toutes les sorties d’un bloc Decide doivent être connectées à un bloc
(éventuellement un bloc Dispose si la sortie n’est pas « utile »).
h) Match (issu du template Advanced Process) : Un bloc Match permet de synchroniser la
progression de deux, voire de plusieurs, entités situées dans différentes files d’attentes. Quand
toutes les files d’attentes, associées au bloc Match, ont une, voire plusieurs entités, ces entités
sont libérées, de façon synchrone, vers les sorties correspondantes. Dans la figure qui suit, le
bloc Match 1 (champ Name = Match 1) effectue une synchronisation entre deux entrées. Une
synchronisation se produit lorsqu’au moins une entité est présente dans chacune des deux files
d’attente, à savoir Match 1.Queue1 et Match 1.Queue2. Les entités à l’origine de la
synchronisation sont ensuite dirigées vers les sorties correspondantes. Le fait d’avoir le champ
Type = Any Entities (et non Based on Attribute) fait que la synchronisation ne s’effectue pas en
fonction de la valeur d’un éventuel attribut (rattaché aux entités).
Le bloc Queue (issu du template Basic Process) décrit ci-dessous indique la définition des files
d’attente Match 1.Queue1 et Match 1.Queue2.
Entrée d'une entité
dans le bloc Decide
.
.
.
Sorties du bloc
Decide
critère
de type
condition ou
probabilité
Match 1
Match 1.Queue1
Match 1.Queue2

40
Voir une description du bloc Match 1 à l'aide du RdP suivant.
Notons que toutes les sorties d’un bloc Match doivent être connectées à un bloc (éventuellement
un bloc Dispose si la sortie n’est pas « utile »).
i) Batch (issu du template Basic Process) : Un bloc Batch permet de regrouper des entités entre-
elles. Les entités une fois regroupées génèrent la sortie d’une entité (notons que cette entité peut
avoir un nouveau Type d’entité, ce qui peut être indiqué dans le champ Representative Entity
Type). Le groupement peut être réversible (ou non) selon que le champ Type = Temporary (ou
Permanent) : un regroupement réversible (Temporary) permet – en utilisant un bloc Separate -
de dégrouper par la suite les entités. Le nombre nécessaire d’entités pour former un groupe est
indiqué dans le champ Batch Size. Une entité arrivant dans un bloc Batch est placée dans la file
d’attente associée au bloc, ceci tant que le nombre d’entités accumulées dans la file d’attente
n’est pas suffisant pour effectuer un regroupement. Le champ Rule assigné à la valeur By
Attribute permet d’effectuer le regroupement d’entités en fonction d’un attribut, dans le cas
contraire (cas par défaut) le champ Rule est assigné à la valeur Any Entity.
Un exemple est décrit dans la figure suivante :
Match 1.Queue1
Match 1.Queue2
Sorties du
bloc Match Entrées du
bloc Match
synchronisation

41
Le RdP suivant décrit le comportement du bloc Batch 1.
j) Separate (issu du template Basic Process) : Un bloc Separate permet de dupliquer des entités
lorsque le champ Type = Duplicate Original. Le nombre de duplication créée est spécifié dans
le champ # of Duplicates. Lorsqu’une entité entre dans ce bloc et comporte des attributs, les
attributs de toutes les entités dupliquées sont identiques aux valeurs courantes des attributs de
l’entité à dupliquer. L'entité originale sort par la sortie Original, les # of Duplicates entités
(celles dupliquées) sortent par la sortie Duplicate. Un bloc Separate, intitulé Separate 1 (champ
Name = Separate 1), est décrit dans la figure suivante. Un exemple est donné dans
\Exemples\Separate\Separate.doe.
Le RdP qui suit permet de décrire un bloc Separate.
k) Process (issu du template Basic Process) : Un bloc Process permet de simuler le
comportement, par exemple, d’une machine ou d’un guichet de banque, sachant que différents
Separate Entrée
de
l'entité
Original (sortie de l'entité originale)
Duplicate (sortie de (# of
Duplicates) entités dupliquées
Entrée du
bloc Batch Sortie du
bloc Batch
Batch Size
(2)
Entrée de
l‘entité Sortie de l’entité
originale
Sortie de
(# of Duplicates)
entités dupliquées
# of
Duplicates

42
modes de fonctionnement sont autorisés selon le contenu du champ Action (situé dans le cadre
Logic lorsque le champ Type = Standard).
Un bloc Process, intitulé Process 1 (champ Name = Process 1), est décrit dans la figure
suivante.
Lorsque le champ Action contient la valeur :
i) Delay, le bloc Process se ramène à un simple bloc Delay, ce qui permet de simuler un
temps de traitement (voir le cadre Delay Type pour assigner un temps de traitement) et le
fait qu’il n’y a pas de contrainte vis-à-vis de la ressource de la machine.
2i) Seize Delay, le bloc Process se ramène à la mise en série des blocs Seize et Delay. Il
permet de simuler un process (machine, guichet de banque) nécessitant une, voire plusieurs
ressources (voir le cadre Resources pour assigner le type, ainsi que le nombre, de ressources
concernées) durant un temps (relatif au temps de traitement) minimum indiqué dans le cadre
Delay (le relâchement de la/les ressource(s) est supposé réalisé en aval).
3i) Seize Delay Release, le bloc Process se ramène à la mise en série des blocs Seize, Delay
et Release. Il permet de simuler un process (machine, guichet de banque) nécessitant une,
voire plusieurs ressources (voir le cadre Resources pour assigner le type, ainsi que le
nombre, de ressources concernées) durant un temps (relatif au temps de traitement)
minimum indiqué dans le cadre Delay, temps au-delà duquel la, voire les ressources
« saisies » sont relâchées (opération réalisée dans le bloc Release).
4i) Delay Release, le bloc Process se ramène à la mise en série des blocs Delay et Release.
Son comportement correspond au cas 3i) sans la gestion de l’allocation de la/les
ressource(s) nécessaire(s) au traitement (cette gestion est supposée réalisée en amont du
bloc).
Le RdP correspondant au cas i) est décrit au VII.2.c. Les RdP correspondant au cas 2i, 3i, 4i
sont issus de concaténation des RdP décrits au VII.2.c,d,e.

43
VII.3 BLOCS PERMETTANT L’ANALYSE D’UN MODÈLE
Les blocs décrits au VII.2 permettent de modéliser un système physique, sans pour autant
fournir d’informations (exceptées celles données par défaut dans le rapport final). La collecte
d’informations spécifiques se fait en utilisant des blocs supplémentaires. Quelques-uns de ces
blocs sont décrits ci-dessous. Un exemple est donné dans le fichier
\Exemples\Record_Statistic\Stat_File.doe.
1) Le bloc Record (issu du template Basic Process) permet, selon le contenu du champ Type,
de :
- compter le nombre d'entités traversant le bloc (Type = Count) (voir 1.a)) ;
- recueillir les temps de passage successif de 2 entités (Type = Time Between) (voir 1.b)) ;
- recueillir les temps mis par les entités traversant une partie (ou l'ensemble) d'un modèle
(Type = Time Interval) (voir 1.c)).
1.a) Lorsque le champ Type = Count, le bloc Record permet de compter le nombre d'entités qui
transitent par ce bloc. Le compteur s'incrémente d'une valeur (Value, par défaut égale à 1) à
chaque passage d'une entité. Le nom du compteur est spécifié dans le champ Counter Name.
Voir le bloc Statistic (voir 2.b) pour effectuer un enregistrement des données.
1.b) Lorsque le champ Type = Time Between, le bloc Record permet de recueillir les temps de
passage entre 2 entités successives. Le nom du tally7 est spécifié dans le champ Tally Name.
Voir le bloc Statistic (voir 2.b) pour effectuer un enregistrement des données.
7 "To keep a tally of …" signifie "tenir le compte de …".
compteur = + 1
transition

44
1.c) Lorsque le champ Type = Time Interval, le bloc Record permet de recueillir les temps mis
par les entités traversant une partie (ou l'ensemble) d'un modèle. Le nom du tally est spécifié
dans le champ Tally Name.
Par exemple, on souhaite pour chaque entité recueillir la différence entre le temps de sortie du
bloc M et le temps de sortie du bloc N. Soient )(),( itit MN les temps de sortie de l'entité n° i des
blocs N et M respectivement (cf. schéma suivant).
Pour réaliser cela, on dispose :
- Un bloc Assign (cf. VII.2.f) placé juste après le bloc N afin d'assigner le temps de passage,
à savoir TNOW, de chaque entité dans un attribut, noté par exemple Attribute 1 (un attribut
est une variable associée individuellement aux entités).
- Un bloc Record 1 (avec Type = Time Interval) placé juste après le bloc M afin de disposer
des temps de parcours de la sortie du bloc N au bloc M. Le lien avec l'attribut Attribute 1
se fait via le champ Attribute Name.
Voir le schéma suivant pour avoir une vue schématique des blocs N, Assign, M, Record et la
figure suivante où est décrit un bloc Record de Type Time Interval.
Bloc N Bloc M
tN (i) tM (i)
Bloc N Bloc M
tN (1),
tN (2),
.
.
tM (1),
tM (2),
.
.
Assign
(Attribute 1
= TNOW)
Record 1
(Attribute
Name =
Attribute 1)
tM (1) - tN (1),
tM (2) - tN (2),
.
.
transition
X X(k + 1) - X(k)
X(k) : tps de
franchissement
de l’entité n° k

45
2) Le bloc Statistic (issu du template Advanced Process, appartenant au cadre expérimental et
donc non traversé par une entité) permet de collecter des statistiques issues d’un bloc Record
ou de variables ARENA (mise à jour automatiquement par ARENA), telles que le nombre
d’entités contenues dans une file d'attente ou le taux d’occupation d’une ressource.
La variable NQ (abréviation de Number in Queue), permet de disposer du nombre d’entités
contenues dans une file d'attente. Par exemple, la variable NQ(Process 1.Queue) permet de
connaître le nombre d’entités présentes dans la file d’attente Process 1.Queue.
La variable NR (abréviation de Number of busy Resource units), permet de disposer du taux
d’occupation d’une ressource. Soit une machine constituée de n ressources, ce qui permet le
traitement en parallèle de n pièces, une ressource peut être occupée (busy) ou disponible (idle).
Par exemple, considérons une machine, représentée par un bloc Process 1, utilisant une
ressource Resource 1 de capacité égale à 3 (donnée déclarée dans un bloc Resource), alors la
variable NR(Resource 1) permet de connaître le nombre de ressources Resource 1 occupées (ce
nombre pouvant être égal à 0, 1, 2 ou 3).
a) On accède à différents types de données statistiques selon la configuration du bloc Statistic :
i) A travers une statistique, notée Statistic 1, on peut disposer de la moyenne, du minimum, du
maximum du nombre d’entités présentes dans la file d’attente, par exemple,
Process 1.Queue. Pour cela, prendre la configuration suivante :
champ Name = Statistic 1, champ Type = Time-Persistent, champ Expression =
NQ(Process 1.Queue) (voir figure ci-dessous).
2i) A travers une statistique, notée Statistic 2, on peut disposer de la moyenne, du minimum, du
maximum du nombre de ressources, par exemple, Resource 1, occupées. Pour cela, prendre la
configuration suivante :
champ Name = Statistic 2, champ Type = Time-Persistent, champ Expression =
NR(Resource 1) (voir figure ci-dessous).
3i) A travers une statistique, notée Statistic 3, on peut disposer de données statistiques de la file
d'attente, par exemple, Process 1.Queue, classées par catégorie, avec pour chacune des
catégories, son nombre d'occurrences, le temps moyen de chaque occurrence et le pourcentage
des temps d'occurrences par catégorie. Considérons, par exemple, les 3 catégories suivantes :
- Vide lorsque la file d'attente ne contient pas d'entité ;
- Moitie chargee lorsque la file d'attente contient entre 1 et 10 entités ;

46
- Chargee au-delà de 10 entités.
Pour cela, prendre la configuration suivante :
champ Name = Statistic 3, champ Type = Frequency, champ Frequency Type =
Value, champ Expression = NQ(Process 1.Queue), 3 lignes à définir dans le champ
Categories, à savoir :
Constant or Range Value High
Value Category Name Category Option
1 Constant 0
Vide Include
2 Range 0 10 Moitie chargee Include
3 Range 10 1000 Chargee Include
voir figure ci-dessous.
Remarque : La valeur 1000, contenue dans le tableau, correspond à une borne supérieure du
nombre d'entités dans la file d'attente.
4i) A travers une statistique, notée Statistic 4, on peut disposer de données statistiques de la
ressource, par exemple Resource 1, classées par catégorie, avec pour chacune des catégories,
son nombre d'occurrences, le temps moyen de chaque occurrence, et le pourcentage des temps
d'occurrences par catégorie. Considérons, par exemple, les 4 catégories suivantes :
- Zero lorsque la ressource est libre ;
- Une lorsqu'une (seule) ressource est occupée ;
- Deux lorsque 2 ressources sont occupées ;
- Trois lorsque toutes les ressources (c'est-à-dire, 3) sont occupées.
Pour cela, prendre la configuration suivante :
champ Name = Statistic 4, champ Type = Frequency, champ Frequency Type =
Value, champ Expression = NR(Resource 1), 4 lignes à definer dans le champ
Categories, à savoir :
Constant or Range Value Category Name Category Option
1 Constant 0 Zero Include
2 Constant 1 Une Include
3 Constant 2 Deux Include
4 Constant 3 Trois Include
voir figure ci-dessous.
b) Le bloc Statistic permet également de sauvegarder les données d’observations individuelles,
acquises tout au long de la simulation, par exemple, issues d’un bloc Record (relatif à un
compteur ou un tally), ou d’une variable ARENA (le nombre d’entités contenues à chaque
instant dans une file d'attente, le taux d’occupation à chaque instant d’une ressource). Pour cela,
il suffit de compléter le bloc Statistic en indiquant dans le champ Counter Output File ou Tally

47
Output File (selon que le bloc Record est relatif à un compteur ou un tally) ou Output File (pour
une variable ARENA), le nom du fichier - ainsi que son répertoire si celui-ci est différent du
répertoire contenant l’application.
Afin de disposer des données au format csv (abréviation de comma-separated-value, « comma »
signifiant virgule), reconnu notamment par MatLab (via la commande CSVREAD) et Excel, il
suffit de mettre l’extension .csv au fichier de sauvegarde et d’indiquer que le fichier de
sauvegarde est au format texte en cochant la case Write Statistics Output Files as Text accessible
via le menu Run/Setup/Run Control/Advanced.
Par exemple, la statistique, notée Statistic 5, permet via le compteur Record 1 défini dans le
bloc Record 1 de disposer dans le fichier Compteur.csv du nombre d’entités qui ont transité à
tout instant dans ce bloc.
VII.4 ANIMATION GRAPHIQUE
L'animation permet de décrire graphiquement l'évolution dynamique de l'état du système
simulé, notamment à travers une visualisation :
▪ du flux des entités (par exemple, des pièces circulant le long d'une ligne de production),
▪ de l'état des ressources (par exemple, l'état libre (idle), occupée (busy) ou inactive
(inactive) d'une machine, d'un robot),
▪ de l'évolution des variables, des attributs (par exemple, le contenu d'une variable
indiquant le temps de traitement d'une machine, l'état d'un stock).
L'animation est un moyen très efficace de communication. D'un abord facile, notamment pour
les décideurs non nécessairement initiés aux aspects techniques, elle permet - sous réserve bien
sûr que les conditions de simulation soient crédibles - de mettre en avant les phénomènes
étudiés. Elle permet également lors de la conception du modèle de simulation de vérifier son
bon fonctionnement à travers une visualisation étape par étape (voir commande Step ►| ) du
cheminement des entités dans le modèle de simulation.
Un exemple est donné dans le fichier \Exemples\Animation_Un_exemple\Animation.Doe.
➢ Animation des entités
Une animation, rattachée aux connecteurs, est proposée par défaut (voir option Animate
Connectors dans le menu Object). Elle permet de visualiser le flux des entités le long des
connecteurs, i.e., les liens reliant les modules entre eux :
Create
Process 0
0
connecteur

48
Notons que le mouvement des entités le long des connecteurs n'a pas d'impact sur le temps de
simulation (TNOW).
La simulation de temps de transport nécessite l'utilisation du bloc STATION du template
Advanced Transfer.
L'image initiale utilisée pour représenter un type d'entité donné est définie dans le bloc Entity
(issu du template Basic Process, appartenant au cadre expérimental et donc non traversé par
une entité). L'image est par défaut celle notée Picture.Report et est indiquée dans le champ
Initial Picture du module Entity. Le changement de l'image associée à une entité se fait via son
passage dans un bloc Assign en assignant une nouvelle image à l'attribut Entity Picture (par
exemple, Type : Entity Picture, Entity Picture : Picture.Truck).
Le menu Edit/Entity Picture permet d'accéder à d'autres images (contenues dans des fichiers
.plb). Le bouton Open permet d’ouvrir un fichier .plb particulier, lequel contient des images.
Par exemple, le fichier machine.plb met à disposition des images relatives à des machines.
Il est également possible de créer ses propres images, lesquelles seront sauvegardées dans un
fichier .plb. Pour créer une image, cliquez sur le bouton Add de droite, ce qui fait apparaître une
case grise. Le fait de double cliquer dans cette case permet d’ouvrir une fenêtre (Picture Editor)
où il est possible de concevoir une image. Fermer la fenêtre une fois l’image conçue ; elle
apparaîtra alors à la place de la case grise. Le bouton Save permet de sauvegarder dans un fichier
.plb de votre choix la, voire les, image(s) créée(s).
➢ La barre d'outils Animation (Animate)
Cette barre d'outils fournit une interface avec les objets de base de l'animation (cocher la case
Animate de la fenêtre issue du menu View/Toolbars… pour faire apparaître – si nécessaire –
cette barre d'outils).
Ces objets sont décrits ci-dessous :
- Affichage d'état :
- Clock permet d'afficher le temps de simulation en heures, minutes et secondes,
- Date permet d'afficher le temps de simulation en jours, mois et années,
- Variable permet d'afficher la valeur numérique d'une expression mathématique ou
logique,
- Level affiche la valeur d'une expression relative à des valeurs minimum et maximum
spécifiées,
- Histogram permet d'afficher la distribution de la valeur d'une expression dans une plage
spécifiée,
Affichage d'état : Clock Date Variable Level Histogram Plot
Zone d'attente : Queue Image : Resource Global

49
- Plot permet d'afficher les valeurs passées d'une expression sur une plage de temps
spécifiée.
- Zone d'attente :
- Queue permet d'afficher les entités en attente d'un événement spécifié (par exemple, la
disponibilité d'une ressource).
- Image :
- Resource permet de disposer d'un objet (par exemple, une machine) à capacité limitée
pouvant être alloué à des entités. Une ressource peut être dans l'état idle, busy ou
inactive. Durant la simulation, l'image d'une ressource change en fonction de son état.
- Global permet d'associer des images à une expression (variable, attribut). Durant la
simulation, l'image de l'expression change en fonction sa valeur par rapport à une valeur
spécifiée.
➢ La barre d'outils Dessin (Drawing)
Les objets de cette barre d'outils permettent l'ajout de dessins statiques, ou de texte :
Line Polyline Arc Bezier curve Box Polygon Ellipse Text Couleur

50
VII.5 DONNÉES D'ENTRÉES
Le module Input Analyser d'ARENA permet l'exploitation de données d'entrées en déterminant
automatiquement la loi de probabilité la plus adaptée de la distribution empirique obtenue à
partir des données d'entrée (regroupées dans un fichier).
Les données d’entrées sont contenues dans un fichier au format .dst où une ligne contient un
nombre (réel). En fait, ce fichier est de type texte et donc lisible, par exemple, via le WordPad.
Voir, à titre d’exemple, le fichier test1.dst, ou test2.dst, dans le répertoire
\Exemples\Distribution. Pour analyser un fichier de données (.dst), faire : Rockwell
Software/Arena/Input Analyzer afin d’ouvrir l’application Input Analyzer. Une fois dans cette
application, faire : File/New afin d’ouvrir une fenêtre Input1. Après avoir cliqué dans la fenêtre
grisée, faire File/Data File/Use Existing…8, ce qui permet de récupérer le fichier (.dst)
contenant les données à convertir en une loi de distribution : il en résulte l’affichage d’un
histogramme des données.
Dans la fenêtre grisée, sont décrites des informations relatives aux données (le nombre de
données, les valeurs minimale et maximale, la moyenne, l’écart type) et à l’histogramme (la
portée (la plus petite valeur et la plus grande valeur considérées dans l’histogramme), le nombre
d’intervalles (en )( ptsdenbreO et compris entre 5 et 40)).
8 A ce niveau, vous pourriez créer un fichier de données (.dst) correspondant à une certaine
distribution en sélectionnant Generate New….

51
Pour modifier les paramètres de l’histogramme des données, à savoir le nombre d’intervalles,
la borne inférieure (les données ayant des valeurs inférieures étant ignorées) et la borne
supérieure (les données ayant des valeurs supérieures étant ignorées), faire :
Options/Parameters/Histogram….
Pour trouver la meilleure distribution correspondant à cet histogramme, faire : Fit/Fit All9.
VII.6 ANALYSE DES RÉSULTATS
Le module Output Analyser d'ARENA permet, à l'issue d'une simulation, le calcul de résultats
statistiques tels que la moyenne, l'écart type, la valeur minimum, la valeur maximum. Il est
également possible de récupérer l'historique complet des valeurs récoltées au cours de la
simulation dans des fichiers (exploitables par exemple via le logiciel Excel).
Outre les tracés de courbes et d'histogrammes, ce module intègre différentes fonctions
statistiques, telles que le calcul d'intervalles de confiance, la construction de corrélogrammes,
la comparaison et l'analyse de moyennes, l'analyse de variances, le test d'hypothèses, …
9 « To fit » signifie « ajuster ».