Embed Size (px)
Citation preview

Sequential PAttern Mining using A Bitmap Representation
Jay Ayres, Johannes Gehrke, Tomi Yiu and Jason Flannick
Dept. of Computer Science
Cornell University
Presenter0259636 林哲存0259639 林庭宇0159638 徐敏容

Outline
• Introduction• The SPAM Algorithm
– Lexicographic Tree for Sequences– Depth First Tree Traversal – Pruning
• Data Representation– Data Structure – Candidate Generation
• Experimental Evaluation– Synthetic data generation – Comparison With SPADE and PrefixSpan – Consideration of space requirements
• Conclusion

Introduction
• I = {i1,i2,...,in} be a set of items
• a subset X ⊆ I an itemset
• |X| is the size of X
• A sequence s = (s1, s2, . . . , sm) is an ordered list of itemsets, where si ⊆ I, i {1,...,∈ m}
• The length l of a sequence s = (s1, s2, . . . , sm) is defined as

Introduction
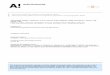
• Sa : A Sequence. Example : ({a}, {b,c})
• sup D(Sa) : The support of Sa in database D.Example : Sa = ({a},{b, c}), we know sup D(Sa) = 2
• Given a support threshold minSup, a Sequence Sa is called a frequent sequential pattern on D if sup D(Sa) >=minSup.
Introduction
• Consider the sequence of customer 2– the size of this sequence is 2.– the length of this sequence is 4.
• the support of Sa is 2, or 0.67. • If the minSup is < 0.67, then Sa is deemed frequent.
({a, b}, {b, c, d})3
({b}, {a, b, c})2
({a, b, d}, {b, c, d}, {b, c, d})1
SequenceCID
{b, c, d}73
{a, b}53
{a, b, c}42
{b}22
{b, c, d}61
{b, c, d}31
{a, b, d}11
ItemsetTIDCID
Table 1 Table 2
Sa : ({a}, {b,c})

Introduction
Contributions of SPAM• Novel depth-first search strategy that integrates a
depth-first traversal of the search space with effective pruning mechanisms.
• Vertical bitmap representation of the database with efficient support counting.
• SPAM outperforms previous work by up to an order of magnitude.
The SPAM Algorithm
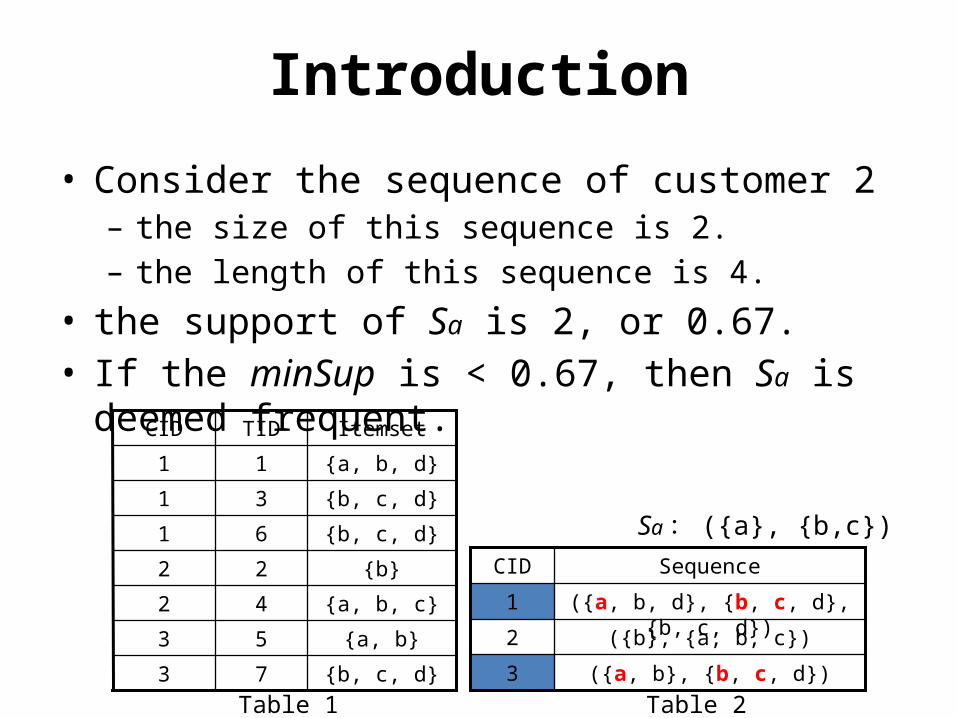
Consider all sequences arranged in a sequence tree with the following structure : • The root of the tree is labeled with null I={a, b}
The Lexicographic Sequence Tree

The SPAM Algorithm
• Each sequence in the sequence tree can be considered as either a sequence-extended sequence or an itemset-extended sequence.
(a, b)
{}
a
a, a a, b
a, a, a a, a, b a, (a, b) = S-Step = I-Step
The Lexicographic Sequence Tree

The SPAM Algorithm
For example: Sa= ({a, b, c}, {a, b})
• sequence-extended sequence of Sa
• itemset-extended sequence of Sa
= S-Step = I-Step
The Lexicographic Sequence Tree
({a, b, c}, {a, b})
({a, b, c}, {a, b}, {d})………
S-Step
({a, b, c}, {a, b})
({a, b, c}, {a, b, d})
I-Step

The SPAM AlgorithmDepth First Tree Traversal
• A standard depth-first manner.• sup D (S) minSup, store S and repeat DFS.• sup D (S) < minSup, not need to repeat DFS.
(a, b)
{}
a
a, a a, b
a, a, a a, a, b a, (a, b)
• A huge search space.

The SPAM AlgorithmPruning
• S-step Pruning – Suppose we are at node ({a}) in the tree and suppose that
S({a}) = {a, b, c, d}, I({a}) = {b, c, d}.
– Suppose that ({a}, {c}) and ({a}, {d}) are not frequent.
• By Apriori principle– ({a},{a},{c}) ({a},{b},{c}) ({a},{a,c}) ({a},{b,c})({a},
{a},{d}) ({a},{b},{d}) ({a},{a,d}) ({a},{b,d})are not frequent Hence, when we are at node ({a}, {a}) or ({a}, {b}), we do not have to perform I-step or S-step using items c and d,
– i.e. S({a},{a}) = S({a},{b}) = {a, b}
I({a},{a}) = {b}, and I({a}, {b}) = null .

• I-step Pruning – Let us consider the same node ({a}) described in
the previous section. The possible itemset-extended sequences are ({a, b}), ({a, c}), and ({a, d}). If ({a, c}) is not frequent, then ({a, b, c}) must also not be frequent by the Apriori principle. Hence, I({a, b}) = {d}, S({a,b}) = {a, b}, and S({a, d}) = {a, b}.
The SPAM AlgorithmPruning

Pseudocode for DFS with pruning

Data Representation
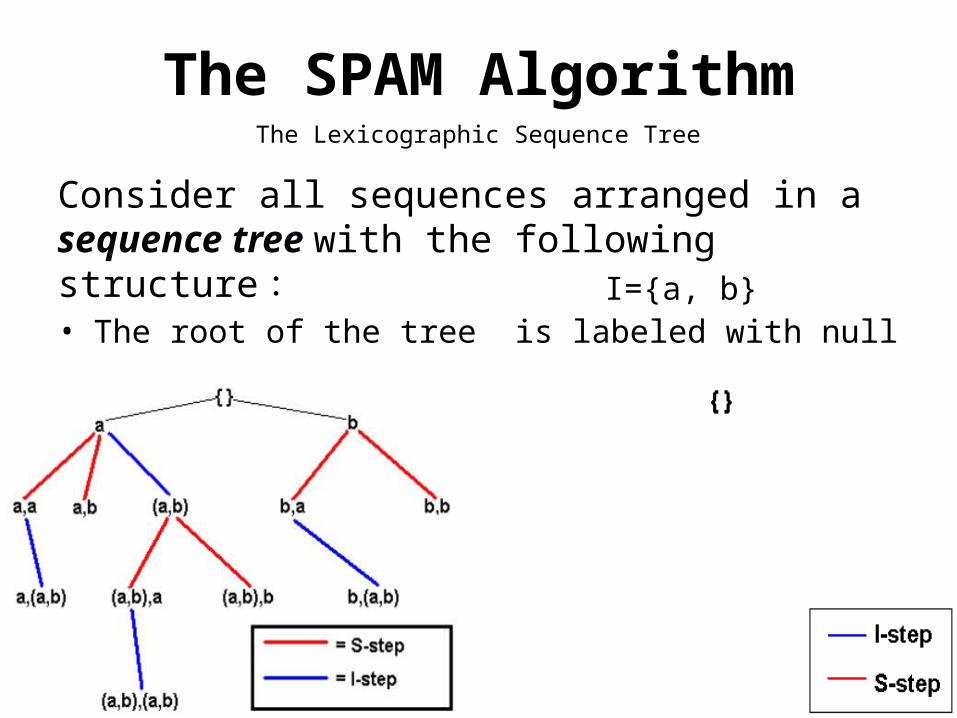
• Our algorithm uses a vertical bitmap representation of the data.
• A vertical bitmap is created for each item in the dataset, and each bitmap has a bit corresponding to each transaction in the dataset.
• A bit is set to 1 if the transaction it represents contains the last itemset in the sequence, and previous transactions contain all previous itemsets in the sequence – (i.e. the customer contains the sequence of itemsets)
Data Structure

• If item i appears in transaction j, then the bit corresponding to transaction j of the bitmap for item i is set to one; otherwise, the bit is set to zero.
• If the size of a sequence is between 2k + 1 and 2k+1, we consider it as a 2K+1-bit sequence. – (the size of a sequence =3), k=1, 21+1-bit=4-bit
Data Representation
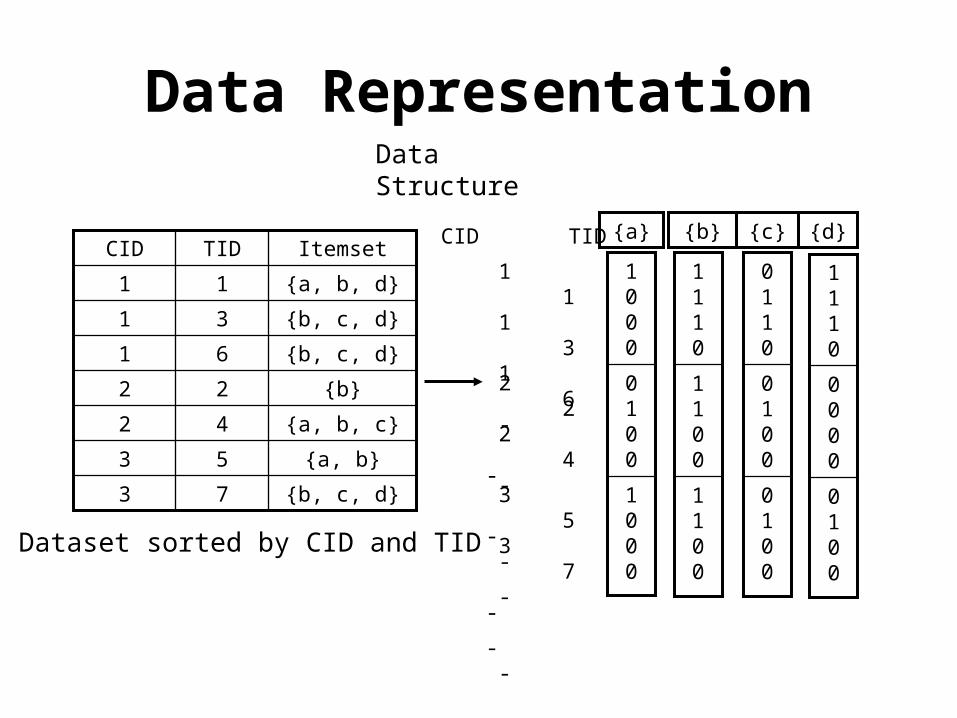
{b, c, d}73
{a, b}53
{a, b, c}42
{b}22
{b, c, d}61
{b, c, d}31
{a, b, d}11
ItemsetTIDCID
Dataset sorted by CID and TID
1000
0100
1000
1100
1100
1110
0100
0100
0110
0100
0000
1110
{b}{a} {c} {d}CID TID
1 1 1 3 1 6 - -
2 2 2 4 - - - -
3 5 3 7 - - - -
Data Structure

Data Representation
• S-step requires that we set the first 1 in the current sequence’s bit slice to 0, and all bits afterward to 1, to indicate that the new item can only come in a transaction after the last transaction in the current sequence.
• I-step, only the AND is necessary, since the item on the end occurs within the same transaction as the last itemset in the current sequence:
(Candidate Generation) Process
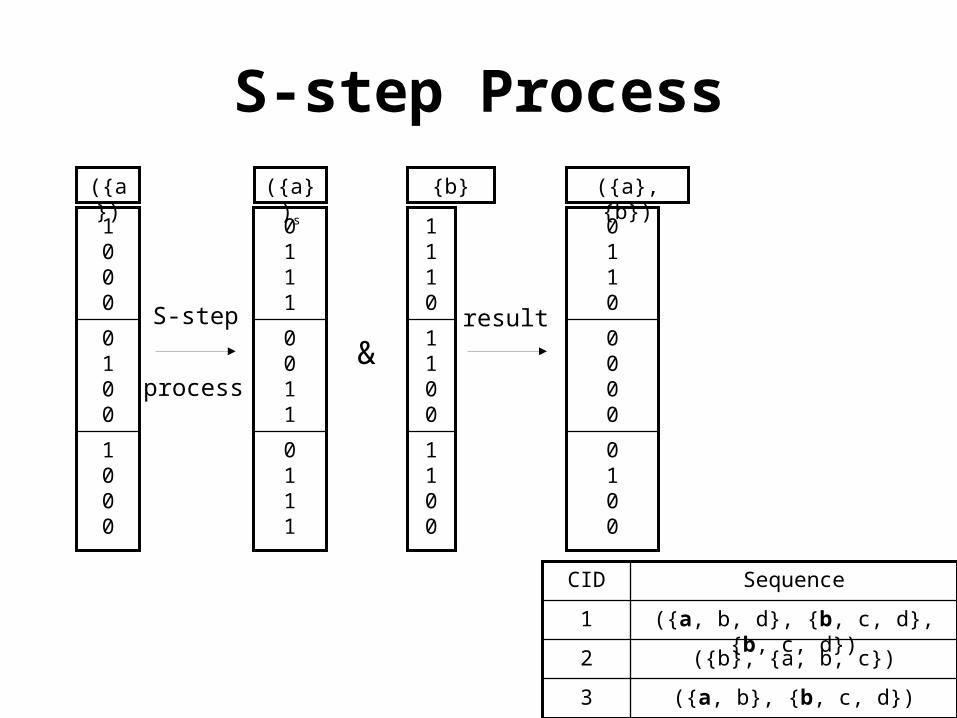
S-step Process
1000
0100
1000
0111
0011
0111
1100
1100
1110
0100
0000
0110
({a})s({a}) {b} ({a},{b})
S-step
process&
result
({a, b}, {b, c, d})3
({b}, {a, b, c})2
({a, b, d}, {b, c, d}, {b, c, d})1
SequenceCID
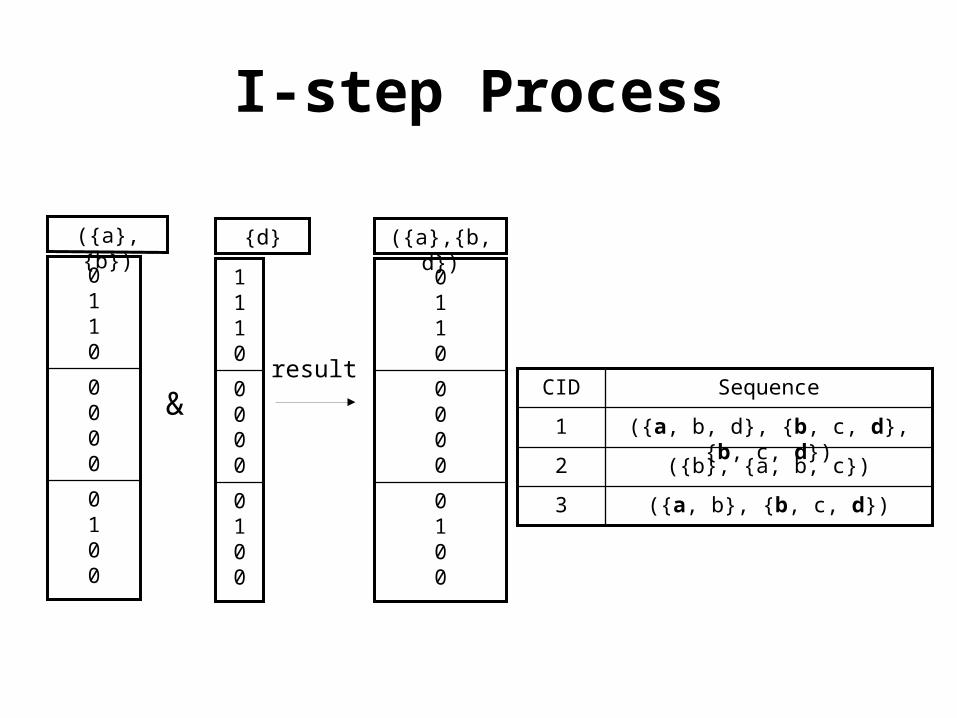
I-step Process
0100
0000
1110
0100
0000
0110
{d} ({a},{b, d})
&result
0100
0000
0110
({a},{b})
({a, b}, {b, c, d})3
({b}, {a, b, c})2
({a, b, d}, {b, c, d}, {b, c, d})1
SequenceCID

Experimental Evaluation
• Using the 「 IBM AssocGen program 」 to generate dataset.
• We also compared the performance of the
algorithms as the minimum support was varied for several datasets of different sizes.
Synthetic data generation

Experimental Evaluation
• We compared the three algorithms on several small, medium, and large datasets for various minimum support values.
• This set of tests shows that SPAM outperforms SPADE by about a factor of 2.5 on small datasets and better than an order of magnitude for reasonably large datasets.
• PrefixSpan outperforms SPAM slightly on very small datasets, but on large datasets SPAM outperforms PrefixSpan by over an order of magnitude.
Comparison With SPADE and PrefixSpan
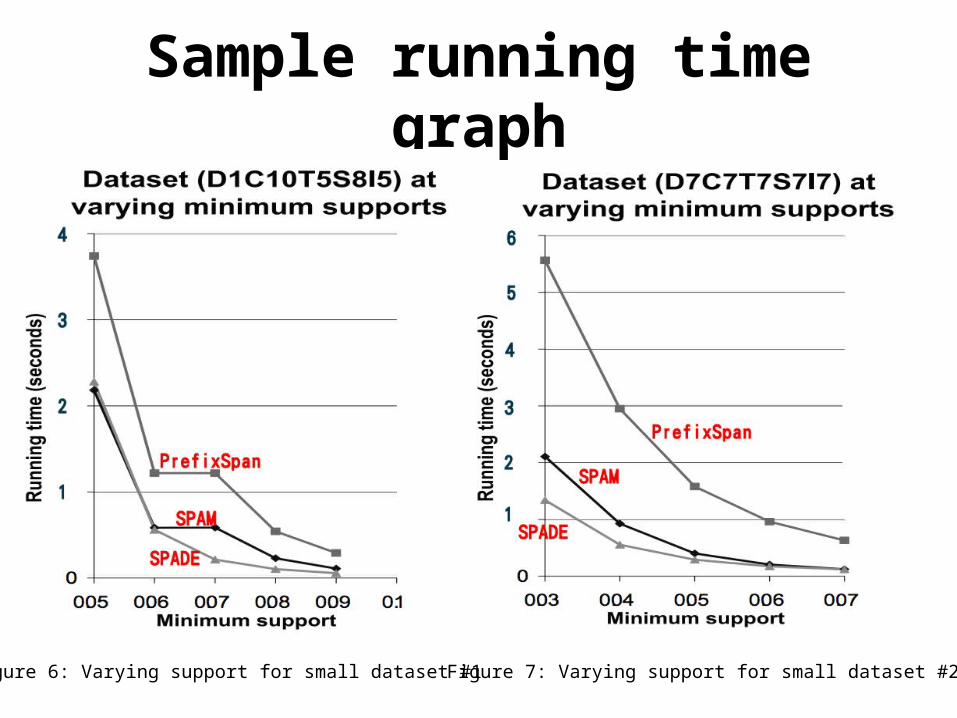
Sample running time graph
Figure 6: Varying support for small dataset #1 Figure 7: Varying support for small dataset #2
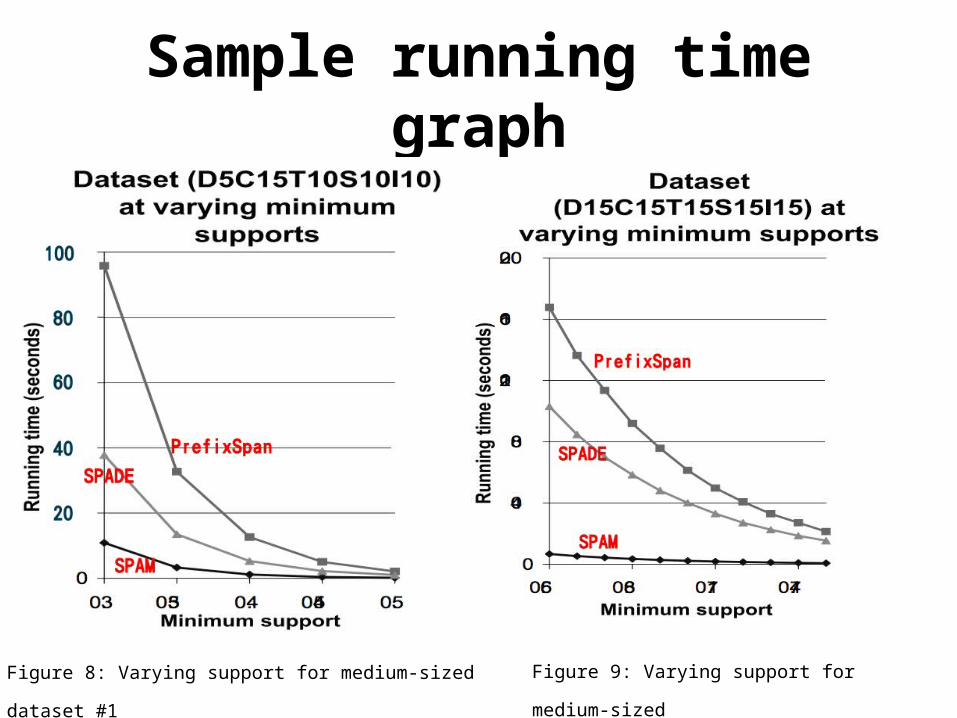
Sample running time graph
Figure 8: Varying support for medium-sized
dataset #1
Figure 9: Varying support for medium-sized
dataset #2
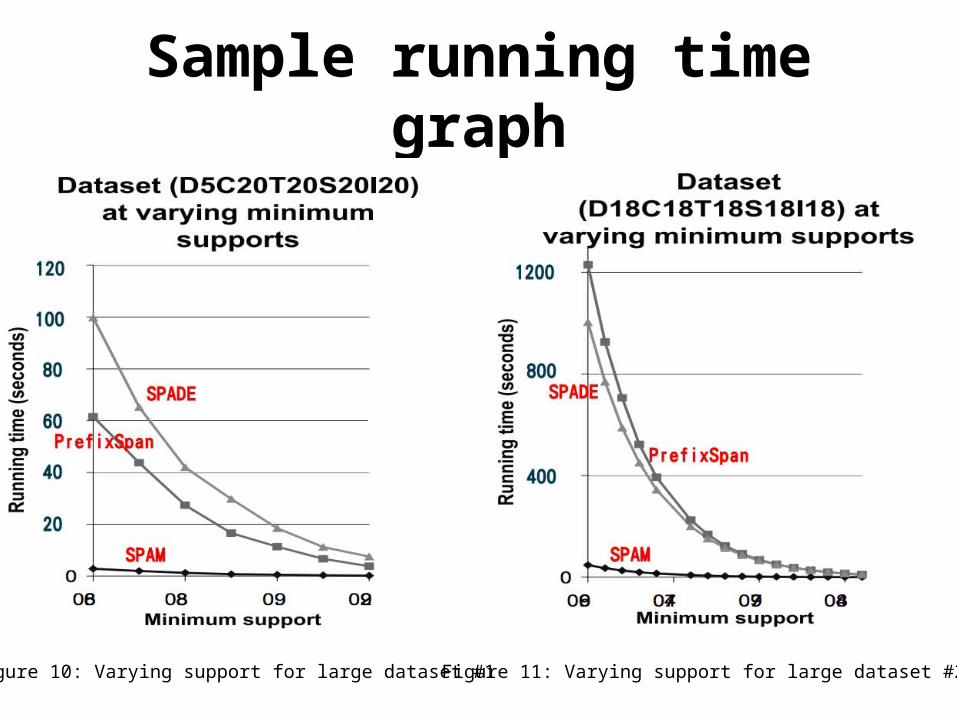
Sample running time graph
Figure 10: Varying support for large dataset #1 Figure 11: Varying support for large dataset #2

• SPAM performs so well for large datasets.• PrefixSpan runs slightly faster for small
datasets.• The SPAM excels at finding the frequent
sequences for many different types of large datasets.
Comparison With SPADE and PrefixSpan Experimental Evaluation
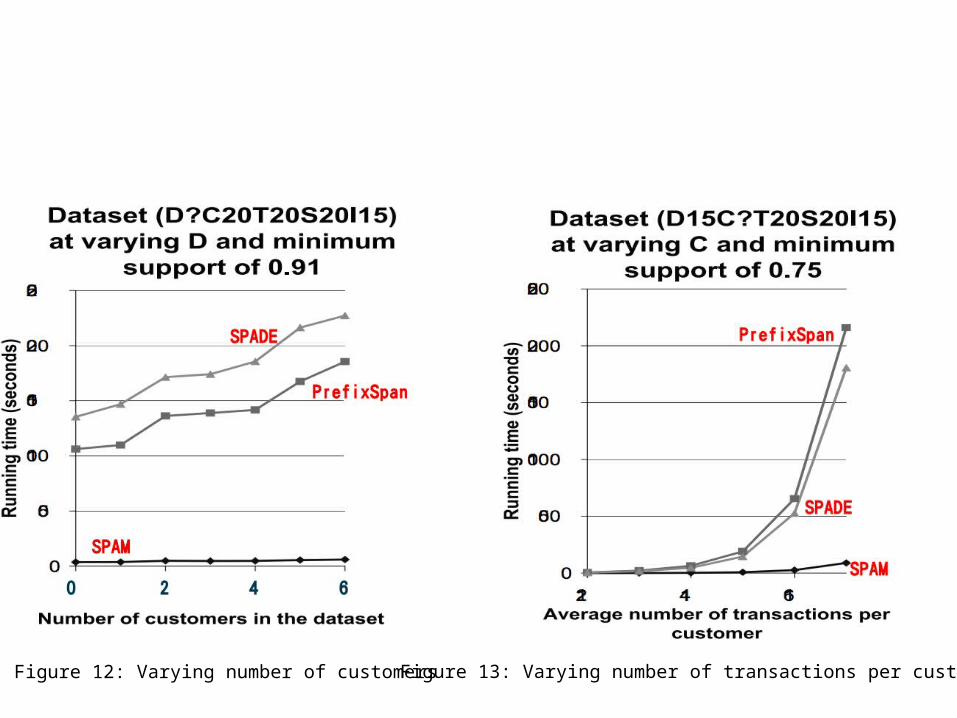
Figure 12: Varying number of customers Figure 13: Varying number of transactions per customer
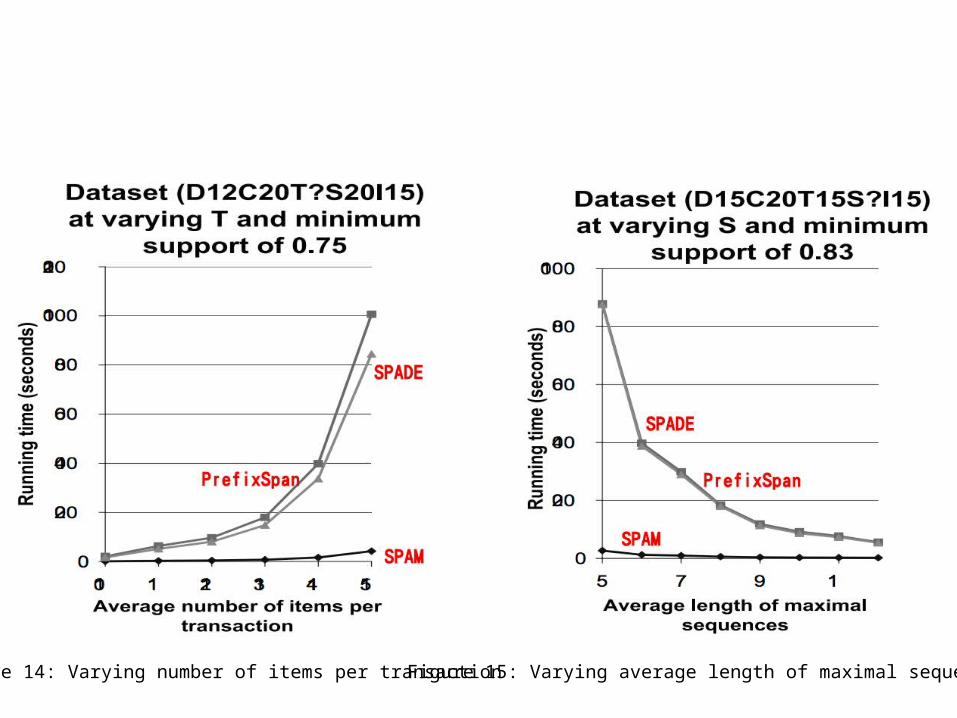
Figure 14: Varying number of items per transaction Figure 15: Varying average length of maximal sequences
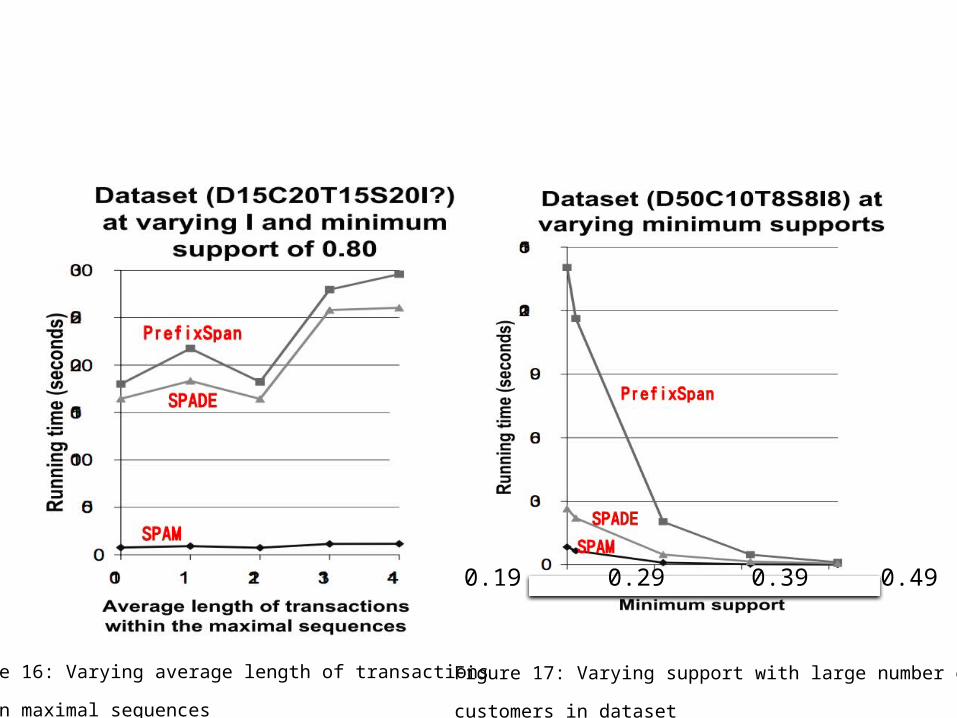
Figure 16: Varying average length of transactions
within maximal sequences
Figure 17: Varying support with large number of
customers in dataset
0.19 0.29 0.39 0.49

Experimental Evaluation
• Uses a depth-first traversal of the search space, it is quite space-inefficient in comparison to SPADE.
• Using the vertical bitmap representation to store transactional data is inefficient – when an item is not present in a transaction, storing a zero to
represent that fact.
• The representation of the data that SPADE uses is more efficient.
Consideration of space requirements

Experimental Evaluation
• SPAM is less space-efficient then SPADE as long as 16T < N(the total number of items across all of the transactions).
• Thus the choice between SPADE and SPAM is clearly a space-time trade off.
Consideration of space requirements

Conclusion
• We presented an algorithm to quickly find all frequent sequences in a list of transactions.
• The algorithm utilizes a depth-first traversal of the search space combined with a vertical bitmap representation to store each sequence.
• Experimental results demonstrated that our algorithm outperforms SPADE and PrefixSpan on large datasets.
Consideration of space requirements

Discussion
• Strongest part of this paper• SPAM outperforms other algorithms on large dataset.
• Weak points of this paper• Space utility may not good.• Need to load all data into main memory.
• Possible improvement• Using linking list to improve the vertical bitmap space
utility.• Possible extension & applications• To forecast in the stock market or financial investment.

Q&A
Sequential PAttern Mining using A Bitmap Representation
Presenter0259636 林哲存0259639 林庭宇0159638 徐敏容

![TOMI TRILAR [10061] nas/slike zaposlenih/Bib-TOMI-TRILA… · 14. KALAN, Katja, KOSTANJŠEK, Rok, MERDIĆ, Enrich, TRILAR, Tomi. A survey of Aedes albopictus (Diptera: Culicidae)](https://img.pdfslide.us/doc/110x75/60ae56009640d207fa3289ed/tomi-trilar-10061-nasslike-zaposlenihbib-tomi-trila-14-kalan-katja-kostanjek.jpg)