Embed Size (px)
DESCRIPTION
September, 13th gR2002, Vienna PAOLO GIUDICI Faculty of Economics, University of Pavia. ASSOCIATION MODELS FOR WEB MINING. Research carried out within the laboratory: Statistical models for data mining (SMDM). A small sample of web clickstream data (from a logfile). - PowerPoint PPT Presentation
Citation preview

September, 13th gR2002, Vienna
PAOLO GIUDICIFaculty of Economics, University of Pavia
Research carried out within the laboratory: Statistical models for data mining (SMDM)

A small sample of web clickstream data
(from a logfile)
C, “10908”, 10908V, 1108V, 1017C, “10909”, 10909V, 1113V, 1009V, 1034C, “10910”, 10910V, 1026V, 1017

Analysis of web clickstream data
1. In data matrix form (Giudici and Castelo, 2001; Blanc and Giudici, 2001):
- Association measures
- Association models (graphical association models)
2. In transactional data form (in this talk)
- Association and sequence rules
- Statistical models for sequences

Association measures and models
Based on data arranged in contingency table form
FOR INSTANCE:
Odds ratios
Graphical loglinear models
Recursive logistic regression models
For a review, see Giudici, Applied data mining, Wiley, 2003

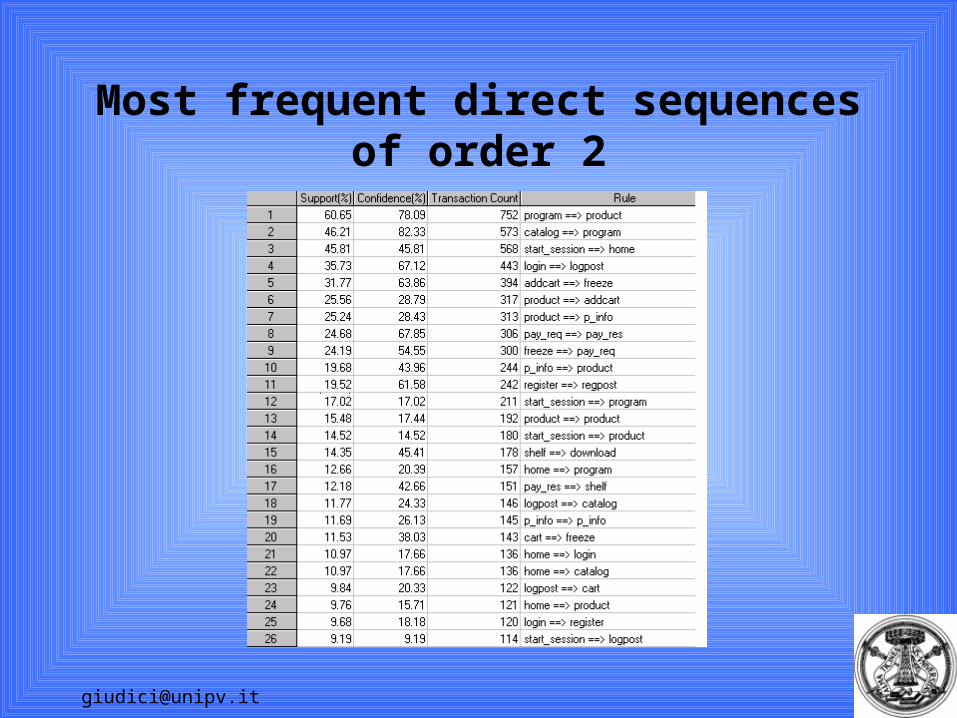
Association and sequence rules
Implemented in main Data Mining softwares
Based on transactional databases
Such databases arise for instance in - Market basket analysis (order does not matter)- Web clickstream analysis (order matters)
Aim: search for itemsets (groups of events) that occurr simultaneously with a high frequency

• A1, .., Ap: p binary random variables. Itemset: logical
expression such as A = (Aj1 = 1 ,...,.Ajk =1), k< p.
Association rule: logical relationship between two itemsets: e.g. if A, then B
Example:A= (Milk, Coffee) B=(Bread, Biscuits)
Sequence rule: the relationship is determined by a temporal order.
Example: A= (Home, Register) B=(P_info)
Formally:
BA

Interestingness of a rule
• Support =
• Confidence = =
• Lift =Confidence / Support (B)
A priori search algorithm (Agrawal et al., 1995):
based on the support.
BA
BA
N
N BA
A
BA
N
N
A
BA
support
support
BA BA
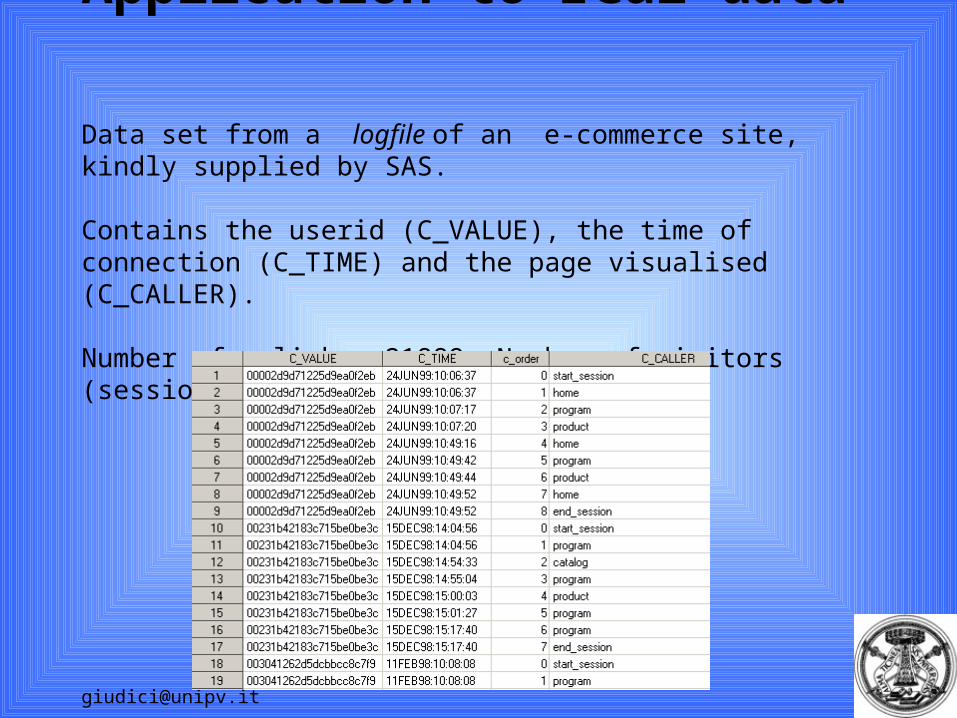
Application to real data Data set from a logfile of an e-commerce site, kindly supplied by SAS.
Contains the userid (C_VALUE), the time of connection (C_TIME) and the page visualised (C_CALLER).
Number of clicks: 21889; Number of visitors (sessions): 1240.

Exploratory step (data selected from a cluster of visitors, N. 3)
Cluster N.obs Variables
Cluster mean
Overall mean
1 8802 CLICKSLENGTHstart%PURCH
86 minh. 180.034
1010 min
14 h0.072
2 2859 CLICKSLENGTHstart%PURCH
2217 minh. 150.241
3 1240 CLICKSLENGTHstart%PURCH
1859minh. 130.194
4 9251 CLICKSLENGTHstart%PURCH
86 minh. 100.039
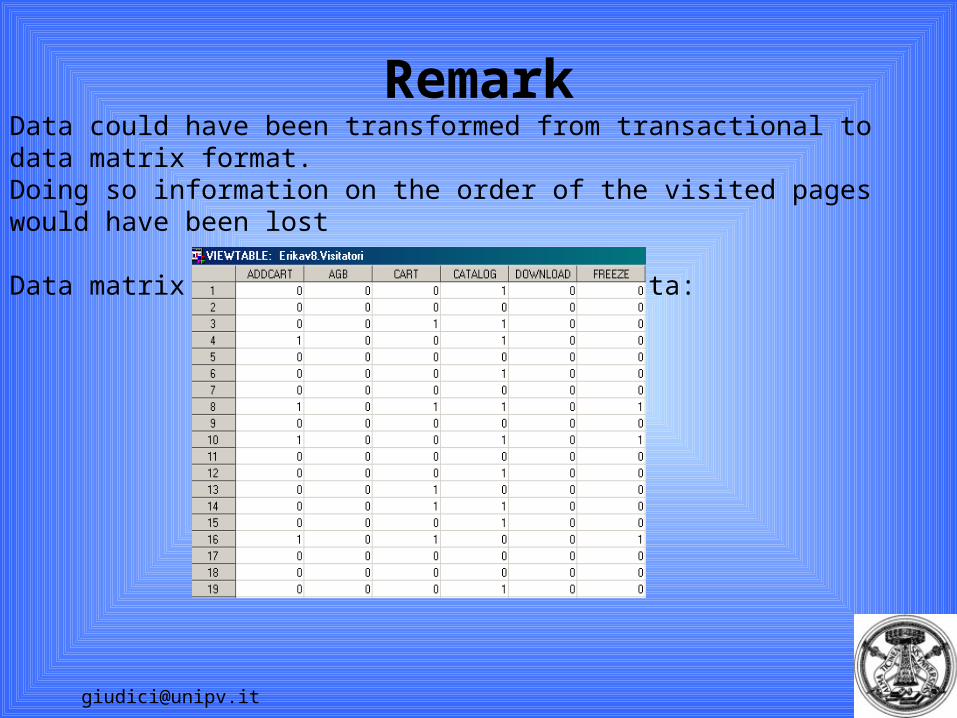
RemarkData could have been transformed from transactional to data matrix format. Doing so information on the order of the visited pages would have been lost
Data matrix format for the considered data:

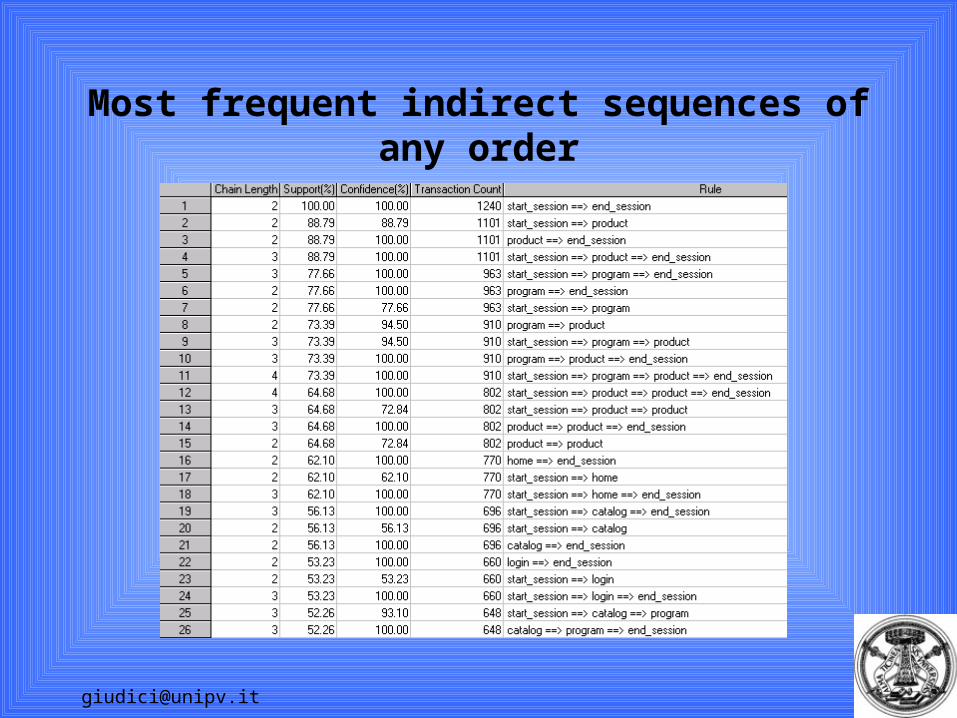
Proposal: direct sequences
• Only “subsequent” visits are being considered• We have inserted two fictitious (deterministic) pages:
(start_session; end_session)

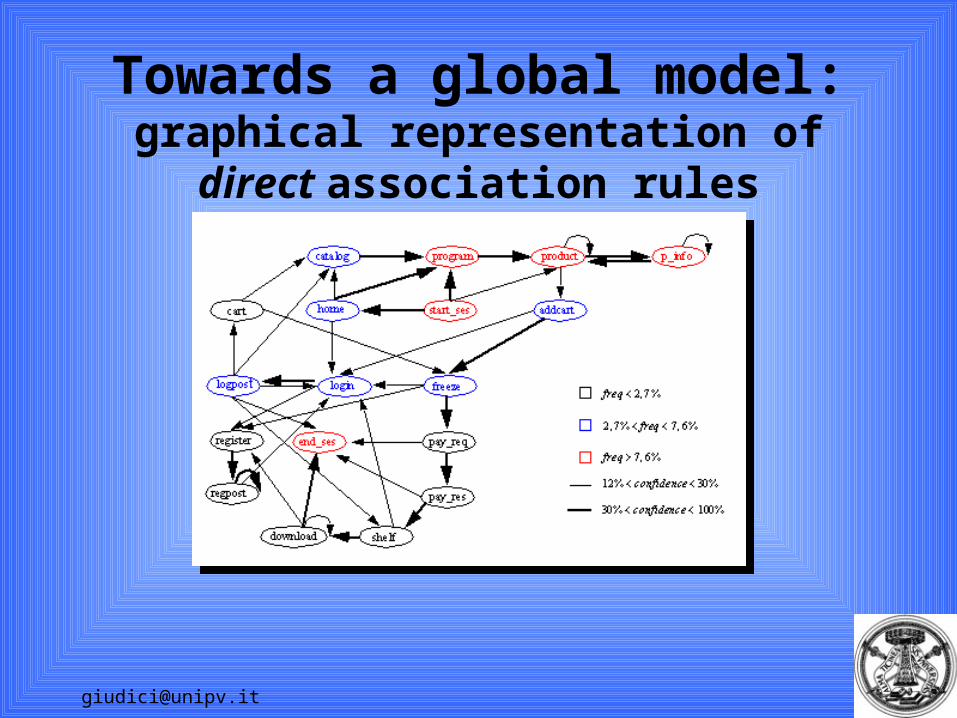
Global models for web miningSequence rules are an instance of a local model (or pattern, see Hand et al, 2001) of data mining.
A local model draws statistical conclusions on parts of the dataset, rather than on the whole.
Link analysis is an example of a global descriptive model.
We have considered two global inferential models:
- probabilistic expert systems- Markov chains

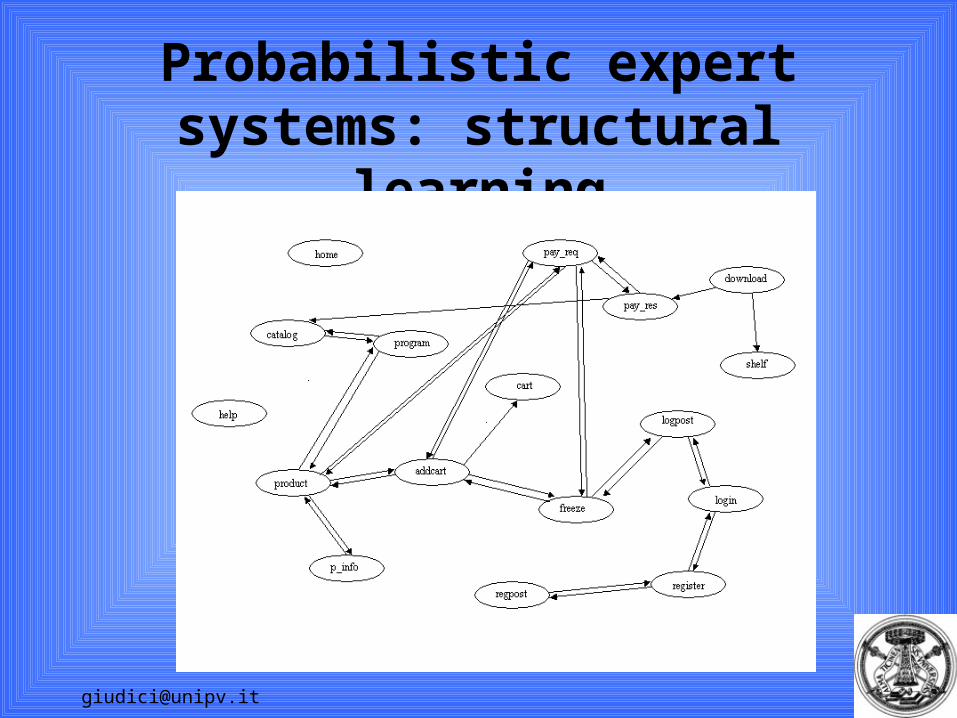
Probabilistic expert systems
Graphical models that allow to describe (recursive) dependencies between (binary) random variables
Can be described by a directed conditional independence graph, that specifies the factorisation of the joint probability distribution.
They ARE NOT directly comparable with sequence rules, that are local indexes to study dependencies between events (itemsets)
They are built from contingency table data, thus DO NOT model order of visit to pages.

Markov Chains for web mining
Ideal to model dependencies between events. Order of the chain parallels order of a sequence rule.
Data have been structured in the following form:

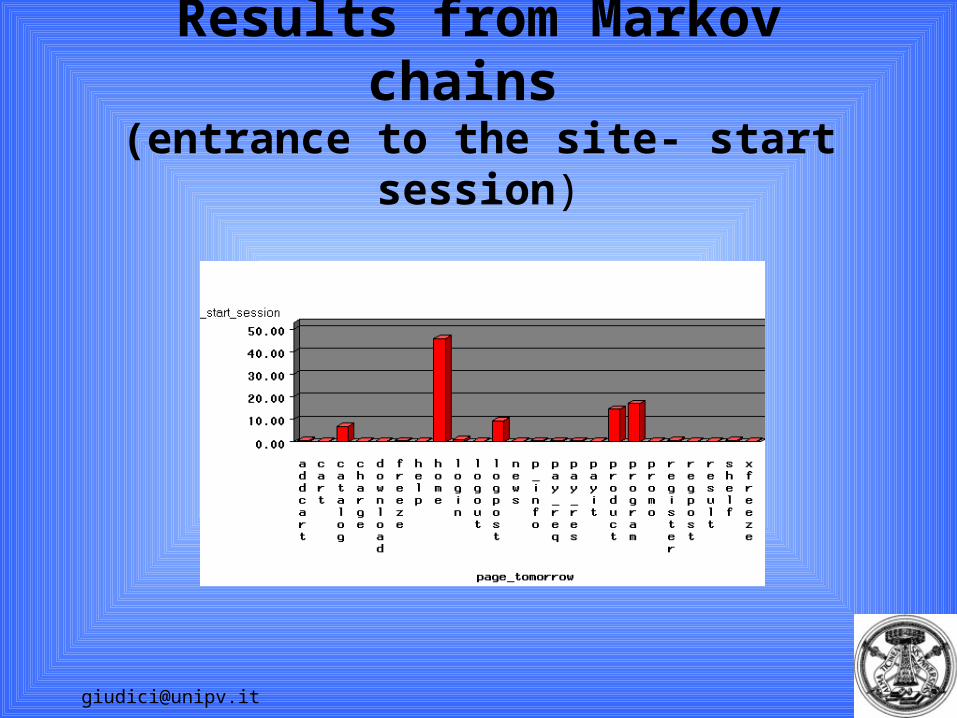
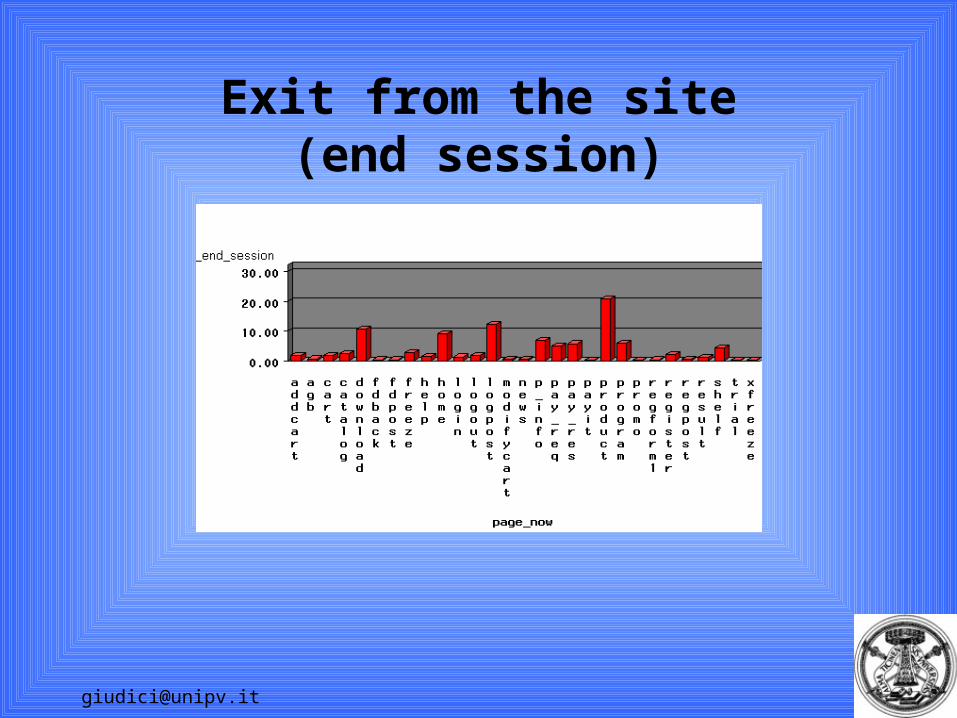
Most likely paths
Program
HomeStart_session
P_info
45,81% 17,80%Product
70,18%
26,73%
Markov chains ARE DIRECTLY comparable with direct sequence rules.
E.g. for the most likely path:from start_session, the highest confidence is with home (45,81%), then program (20.39,), product ( 78,09% ) and addcart (28,79%).
There are small differences, due to the fact that apriori algorithm considers only rules with support higher than a fixed threshold (e.g. 5%).

Essential referencesAgrawal, R., Manilla, H., Srikant, R., Toivonen, H. and Verkamo, A.I. (1995) Fast discovery of association rules, in: Advances in knowledge discovery and data mining, AAAI/MIT Press, Cambridge.
Giudici, P. (2003) Applied Data mining. Wiley, London.
Giudici, P. and Castelo, R. (2001) Association models for web mining. Journal of Knowledge discovery and data mining, 5, pp. 183-196.
Trevor Hastie, Robert Tibshirani and Jerome Friedman (2001).The elements of statistical learning: data mining, inference and prediction. Springer-Verlag.
Hand, D.J., Mannilla, H. and Smyth, P (2001) Principles of Data Mining, MIT Press, New York.