Embed Size (px)
Citation preview

Capítulo
5Roteamento por Segmentos:Conceitos, Desafios e Aplicações Práticas
Antonio José Silvério (UFRJ/Embratel), Miguel Elias M. Campista (UFRJ)e Luís Henrique M. K. Costa (UFRJ)
Abstract
Currently, among the main problems of telecom operators are the huge number of statesin the routers, manual configuration of traffic engineering and restoration paths in thenetwork core. In this direction, the Segment Routing is an emerging proposal to simplifythe routing and configuration of these networks. In Segment Routing, the flow states arekept only on the network edge nodes and configuration of the IP/MPLS core network,commonly used by operators, can be automated. To do this, Segment Routing uses theprogramming benefits of software defined network, by control plane centralization. Thecentralized controller view allows the dynamic calculation of the segments and the routeconstruction between the edge nodes. Among the challenges to be explored in the shortcourse are the problems faced by current operators and its solution through the SegmentRouting.
Resumo
Atualmente, dentre os principais problemas das operadoras de telecomunicações estãoo enorme número de estados nos roteadores, configurações manuais de engenharia detráfego e restauração de caminhos no núcleo da rede. Nessa direção, o Roteamento porSegmentos é uma proposta emergente para simplificação do roteamento e da configu-ração dessas redes. No Roteamento por Segmentos, os estados por fluxo são mantidosapenas nos nós de borda da rede e a configuração das redes de núcleo IP/MPLS, comu-mente utilizadas pelas operadoras, pode ser automatizada. Para tal, o Roteamento porSegmentos utiliza os benefícios da programação das redes definidas por software atravésda centralização do plano de controle. A visão centralizada do controlador permite ocálculo dinâmico dos segmentos e a construção de rotas entre os nós de borda. Den-tre os desafios a serem explorados no minicurso estão os problemas enfrentados pelasoperadoras atuais e a solução através do Roteamento por Segmento.

5.1. IntroduçãoNesta seção introduzimos os principais tópicos deste minicurso, destacando o ro-
teamento IP/MPLS e a engenharia de tráfego em redes de roteadores de núcleo de ope-radoras de núcleo e suas limitações tais como configurações manuais, manutenção deestados nos roteadores intermediários, ineficiência na ocupação de banda dos enlaces narestauração de falhas na rede. Estas limitações são mitigadas através das tecnologias deroteamento por segmentos e de redes definidas por software [Kreutz et al., 2015].
Na arquitetura TCP/IP com roteamento tradicional, o encaminhamento dos paco-tes é feito salto a salto, não orientado à conexão, sendo que os campos do cabeçalho IPsão analisados consultando-se a tabela de roteamento que contém os prefixos que identifi-cam a rede, para então, encaminhar adequadamente o pacote. Dependendo da extensão eda conectividade de rede a busca na tabela de roteamento pode exigir um grande proces-samento de dados no roteador, ocasionando perda de eficiência do roteador, aumentandoconsequentemente a latência e jitter da rede [De Ghein, 2007].
Com o crescimento mundial da Internet, e o aumento expressivo do número derotas manipuladas pelos roteadores de núcleo, surgiu em 2001 a proposta da tecnologiaMPLS (Multi Protocol Label Switiching) definida na RFC 3031, com rótulos (labels) detamanho fixo, possibilitando uma comutação rápida e eficiente dos pacotes [Santos, 2007].Os roteadores de núcleo encaminham e comutam os pacotes baseados em rótulos e nãomais em prefixos IP diminuindo o processamento destes roteadores e aumentando suaeficiência.
A rede de roteadores de núcleo da operadora de telecomunicações é constituídapor uma arquitetura roteadores IP/MPLS em malha total ou parcialmente interligada fi-sicamente por fibras ópticas, provendo enlaces de alta capacidade, atualmente da ordemde n x 100 Gbit/s. A tecnologia IP/MPLS provê um encaminhamento orientado à cone-xão através de circuitos virtuais denominados LSP (Label Switch Path), que são circuitosunidirecionais.
A inserção e remoção dos rótulos são realizadas pelo roteador de núcleo de bordaconforme mostrado na Figura (Figure 5.1). Cada roteador de borda relaciona para cadarótulo prefixos de redes IP previamente configurados.
Figura 5.1. Exemplo de rede IP/MPLS de núcleo das operadoras.

As rotas calculadas pelo IGP (Interior Gateway Protocol) são insuficientes paraprevenir situações de congestionamento ou evitar enlaces extensos, de maior latência narede, mesmo que tenham o menor número de saltos.
A Engenharia de Tráfego é o processo de arranjar como os fluxos de dados fluematravés da rede para que congestionamentos causados pela utilização desigual da redepossam ser evitados. Um objetivo central da Engenharia de Tráfego é facilitar a operaçãoda rede, otimizando sua capacidade e desempenho [Sadok D.; Kamienski, 2000].
A Engenharia de tráfego permite alterar o fluxo de dados, forçando uma rota, vi-sando atender requisitos de QoS (Quality of Service) de determinados fluxos de dados, ouainda na otimização de recursos de rede impedindo que enlaces da rede tornem-se conges-tionados enquanto outros permaneçam com recursos ociosos. A aplicação da engenhariade tráfego em MPLS é designada como MPLS-TE (MPLS Traffic Engineering), criandotúneis na rede IP/MPLS. [Cisco, 2001].
O MPLS-TE (MPLS Traffic Engineering) permite a construção manual ou dinâ-mica de LSPs sendo esta última através de extensões do protocolo OSPF e IS-IS, e atravésde sinalização do protocolo RSVP (Resource Reservation Protocol) para reserva dos re-cursos da rede. O túnel é identificado por um rótulo por onde passam os fluxos de dados.As operadoras de telecomunicações utilizam túneis para balanceamento de tráfego e paraproteção de determinados fluxos com túneis primários (Primary Tunnels) e de proteção(Backup tunnels).
A Figura (Figure 5.2) mostra o balanceamento de tráfego utilizando MPLS-TE,bem como o desacoplamento das informações de enlaces físicos com a camada IP/MPLS,necessitando de uma planejada e demorada configuração manual de túneis. Outra limi-tação é quando ocorrem falhas nos enlaces físicos por longos períodos, necessitando dereconfigurações nos túneis.
Figura 5.2. Configuração manual de túneis MPLS-TE.
A engenharia de tráfego em redes de núcleo de operadoras de telecomunicaçõesé uma das funções de rede que se beneficiam do paradigma das redes definidas por soft-ware.Em redes definidas por software ou SDN (Software Defined Networks), com a cen-tralização do controle, é possível programar o roteamento da rede IP/MPLS por fluxobaseado nos objetivos de engenharia de tráfego. Nesse caso, a programação dos cami-nhos dos fluxos da rede pode ser realizada considerando inclusive mais de um parâmetrode configuração, como banda disponível, latência e grupos de risco compartilhado de en-

laces físicos de fibras ópticas. Os roteadores de núcleo passam a ser switches “programá-veis“ e toda lógica de programação reside em um controlador SDN em servidores de usocomum COTS (Commercial off the shelf) e não mais em hardware proprietários de altocusto [Kreutz et al., 2015]. As interfaces northbound comunicam com o gerenciamentoda rede através de APIs (Application Interfaces) abertas ou proprietárias, bem como assouthbound interfaces. Esta simplificação permite resolver as limitações da configuraçãode túneis TE mencionadas anteriormente.
O roteamento por segmentos é uma proposta emergente para simplificação doroteamento e configuração, mantendo os estados por fluxo apenas nos nós de borda darede, utilizando-se dos benefícios da programação de Redes Definidas por Software. Oroteamento por segmentos é um roteamento pela fonte (source routing), onde uma listaordenada de segmentos define um caminho na rede conhecida pela fonte. O cálculo docaminho é feito pelo SDN PCE (SDN Path Computation Element) que determina o ca-minho baseado em um amplo rol de objetivos de engenharia de tráfego. Em uma redede roteadores de núcleo IP/MPLS, os segmentos são rótulos MPLS, que são adensadosnos roteadores de núcleo de borda informam o caminho até o seu destino para um deter-minado fluxo de dados, assim apenas os roteadores de borda contém a informação dosrótulos, não sendo necessário mantê-los em tabelas de rótulos nos roteadores intermediá-rios, reduzindo ainda mais a complexidade do plano de controle dos roteadores de núcleo.
Figura 5.3. Roteamento por segmentos em uma rede IP/MPLS.
5.2. Limitações das Tecnologias das Redes de Núcleo (6 páginas)5.2.1. Fundamentos e Arquitetura de Redes IP/MPLS
As limitações da comutação de pacotes IP exigiram da indústria o desenvolvi-mento de tecnologias que trouxessem desempenho às redes de roteadores. As soluçõespropostas utilizavam basicamente a inteligência dos protocolos de roteamento da rede IPpara switches ATM e o desenvolvimento de um hardware (Application Specific Integra-tion Circuit - ASIC) que ampliasse a capacidade de comutação, separando os protocolosde controle da comutação de pacotes, sendo esta última, o embrião do surgimento doMPLS. A tecnologia MPLS, definida na RFC 3031 [Rose, 2014] surgiu como uma pro-posta de evolução de redes públicas de comutação e encaminhamento de pacotes, moti-vada pela convergência da comunicação digital (voz, dados e vídeo) em uma infraestruturacomum, integrando-se com redes IP e Ethernet, e outros tipos de redes legadas como oFrame Relay e ATM [El-Sayed e Jaffe, 2002].
A rede IP/MPLS tem planos de controle e de encaminhamento de dados imple-

mentados em cada nó da rede. O plano de controle é mantido através de protocolos comoo LDP (Label Distribution Protocol) para distribuição dos rótulos e um protocolo IGP(Interior Gateway Protocol), como por exemplo o OSPF, para descoberta dos caminhosdenominados LSP (Label Switched Path). O IGP, como por exemplo o OSPF, escolhe ocaminho mais curto (/it Shortest Path First - SPF). No caso de falha da rede o protocoloOSPF /it (Open Shortest Path First) encontra um novo caminho, desviando o tráfego dosenlaces anteriores para novos enlaces [De Ghein, 2007].
Figura 5.4. Representação de um roteador IP/MPLS.
Em uma rede MPLS o pacote IP, recebe uma informação adicional que é um rótulo(label). O rótulo é um novo cabeçalho que é inserido entre o cabeçalho IP e o cabeçalhoda camada 2, neste caso ele é chamado de rótulo de enchimento (shim label). Um rótuloMPLS possui 32 bits onde os primeiros 20 bits são o valor do rótulo, permitindo endereçar220, ou seja 1.048.575 diferentes rótulos. Os rótulos de 0 a 16 são de uso reservado.
Os 3 próximos bits são os bits experimentais (EXP bits) usado para marcação declasses de serviço (Quality of Service - QoS), 1 bit S (Bottom of Stack) cujo valor é 0 seo rótulo é o inferior da pilha de rótulos. A pilha pode ser constituída de um único rótulo,ou por mais rótulos, sem uma limitação definida. Os 8 últimos bits são usados para otempo de vida do pacote (Time to Live - TTL), cuja função é similar ao campo TTL docabeçalho IP [Marzo et al., 2003].
Figura 5.5. Estrutura do rótulo MPLS (Label).
Os roteadores de núcleo MPLS são capazes de processar mais que um rótulo no

pacote a ser roteado pela rede MPLS. Isto é realizado pelo empacotamento de rótulosem uma pilha sendo o primeiro rótulo denominado de rótulo externo ou superior (top la-bel) e o último rótulo de rótulo interno ou inferior (bottom label). Algumas aplicaçõescomo redes privativas virtuais (Vitual Private Networks - VPN), linhas alugadas virtuais( Virtual Leased Lines - VLL ou Virtual Private LAN Service - VPLS) e transporte deoutras tecnologias sobre MPLS (AToM - Any Transport Over MPLS). Esta importante ca-racterística da tecnologia MPLS será a base de informações no roteamento por segmentos[Guichard, 2003, Asati, 2012].
Figura 5.6. Empilhamento de rótulos MPLS (Label Stack).
A tecnologia MPLS introduziu mecanismos como qualidade de serviço, Engenha-ria de Tráfego (Traffic Engineering - TE, bem como novos serviços do tipo VPN (VirtualPrivate Network) na rede de núcleo das operadoras de telecomunicações. Os serviços deVPNs podem se de 2 tipos principais : VPN L2 (VPN Layer 2) Redes Privativas camada2, ou seja, redes que emulam redes de camada 2 em algum protocolo como Ethernet,Frame Relay ou SDN e VPN L3 (VPN Layer 3): Redes Privativas Layer 3, ou seja, redesque emulam redes de camada 3 em IP. A rede IP/MPLS é muitas vezes considerada comouma rede multiserviço conforme mostrado na Figura 5.7.
Figura 5.7. Rede IP/MPLS como Rede Multiserviço.
A arquitetura de rede MPLS é composta de roteadores de borda denominadoscomo PE (Provider Edge) ou LER (Label Edge Router) que insere (push) e retira (pop)rótulos do pacote MPLS. Os roteadores intermediários denominados P (Provider) ou LSR(Label Switch Router) realizam a comutação (swap) de rótulos, enviando o pacote paraum determinado enlace de dados. O CE (Customer Edge) representa o roteador baseado

no protocolo IP, que pertence a um determinado sistema autônomo [De Ghein, 2007]. Asequência de rótulos que forma o circuto virtual é denominado LSP (Label Switch Path)sendo este circuito unidirecional ilustrado na Figura 5.8) .
Figura 5.8. Arquitetura de Rede IP/MPLS.
A tecnologia MPLS ao separar o plano de controle do plano de encaminhamentode pacotes permitiu flexibilizar novas facilidades no plano de controle, sem a necessidadede criar um novo plano de encaminhamento, sendo a base para as aplicações como a pró-pria engenharia de tráfego da rede, com um único encaminhamento baseado em rótulos.Esta operação denomina-se imposição de rótulo (label imposition ou Push). A tabelaFEC (Fowarding Equivalence Class) associa o endereço IP de destino com o rótulo deentrada na rede MPLS. Os roteadores de núcleo de borda (LER) recebem os pacotes IPprovenientes do roteador cliente (CE) de origem, inserindo um rótulo adequado ao seuIP de destino. No interior da rede MPLS o pacote é comutado nos roteadores de núcleointermediários (LSR) apenas com base na informação dos rótulos, sendo esta operaçãodenominada de comutação de rótulos (Swap). No interior da rede MPLS não se mantémos mesmos rótulos, tendo significado local e não necessitam ser um único endereço comoem redes IP. A informação de rótulos está contida em uma base de instâncias de rótulosde encaminhamento (LFIB-Label Fowarding Instance Base) em cada um dos roteadoresde núcleo intermediários. Na outra extremidade, o roteador de núcleo de borda (LER) faza operação inversa, retirando o rótulo (Pop), entregando o pacote para a rede do roteadorde cliente de destino. O processo de comutação de rótulos é mostrado no diagrama da Fi-gura 5.9. O protocolo LDP (Label Distribution Protocol) é responsável por associar umaFEC a um rótulo, sendo esta operação denominada associação de rótulo (label binding).Outra importante função do protocolo LDP é a distribuição de rótulos, trocando informa-ções da FEC e rótulos associados dos roteadores de núcleo de borda e intermediários, deforma que se forme um circuito virtual (LSP) coerente com os prefixos IP dos pacotes aserem encaminhados [Rose, 2014].
As tabelas de roteamento são preenchidas por algum protocolo de roteamento

Figura 5.9. Comutação MPLS.
(OSPF, BGP-Border Gateway Protocol) entre o CE de origem e o de destino. O protocoloLDP identifica seus vizinhos através de mensagens (Hello messages). Para cada entradada tabela de roteamento é criada uma entrada na FEC, associando um rótulo de entrada.Os roteadores de núcleo (LERs e LSRs) anunciam as seus vizinhos a dupla FEC/Rótulode Entrada, sendo esta operação denominada distribuição de rótulos (label distribution).Cada roteador de núcleo monta uma tabela completa com FEC/Rótulo de Entrada/Rótulode Saída/Porta. Dessa forma o plano de encaminhamento, é responsável pela comutaçãodos pacotes baseado apenas nos seus rótulos envolvendo as operações de comutação, in-serção e retirada de rótulos. No plano de controle, o protocolo LDP traduz as tabelas derótulos em informações da tabela de roteamento. Ainda no plano de controle o cálculo decaminhos na rede MPLS é feita por um IGP (Interior Gateway Protocol) dos roteadoresde núcleo, a partir de interfaces locais (loopbacks) dos roteadores.
5.2.2. Serviços de Rede IP/MPLS
O principal serviço em redes IP/MPLS é o serviço de rede virtual privada (VPN-Virtual Private Network). O serviço de VPN definida na RFC2547 pode ser configu-rado em topologias do tipo malha (full-mesh) ou matriz-filial (hub and spoke). O MPLSpermite basicamente dois tipos de categoria de serviços VPN segundo sua operação nomodelo de camadas OSI: VPNs de camada 3 (VPN L3) e VPNs de camada 2 (VPNL2) [Guichard, 2003, Asati, 2012].
As L3 VPNs permitem a troca de protocolos de roteamento “peering” entre os ro-teadores cliente (CE Edge) e os roteadores de núcleo de borda (LER). As portas do LERsão associadas a uma VPN através de uma instância de roteamento denominada VRF (Vir-tual routing e fowarding tables). As VRFs serão utilizadas para definir os caminhos derótulos (LSP). Como cada VPN utiliza sua própria VRF, os roteadores de cliente (CEs)

de diferentes VPNs podem ter o mesmo endereço. Os roteadores de cliente (CEs) utili-zam protocolos de roteamento tradicionais como OSPF, RIP e BGP com os roteadores denúcleo de borda (LER) aos quais estão diretamente conectados. Os roteadores de núcleode borda (LER) trocam informações aprendidas pelos roteadores de cliente (CEs) direta-mente ligados a este através do protocolo MP-BGP (Multiprotocol BGP). Na percepçãodo roteador do cliente, a rede IP/MPLS funciona como uma rede IP dedicada. O processode encaminhamento das VPNs utiliza dois rótulos, ou seja, o roteador de núcleo de bordainsere dois rótulos MPLS entre o cabeçalho de camada 2 e o cabeçalho IP, utilizando-seda característica de empilhamento de rótulos (label stack). O rótulo mais externo refere-seao roteador de núcleo (LER) de destino, enquanto o rótulo mais interno refere-se à VPN.A Figura5.10 ilustra o funcionamento de uma L3 VPN.
As L2 VPNs são redes privativas virtuais que trocam com os roteadores de núcleoapenas informações de camada 2, e as informações de camada 3 estabelecidas apenasentre os roteadores clientes (CE). As L2 VPNs podem ser entendidas como um “pseu-dowire“, que pode ser ponto a ponto (no caso do VLL-Virtual Leased Line) e ponto-multiponto (no caso do VPLS-Virtual Private LAN service). Para transportar quadros L2sobre MPLS a RFC4905, introduziu o conceito de VC (Virtual Circuit) em MPLS. UmLSP age como um túnel que permite carregar múltiplos VCs, enquanto o VC permitetransporte de quadros L2. O VC é implementando utilizando-se um empilhamento derótulos definidos nas RFCs 4385 e 5287 [documents, 2001]. A (Figure 5.11) mostra umaL2 VPN ponto a ponto um LSP conectando o roteador de núcleo de borda A e B respecti-vamente, existindo um rótulo do LSP. O roteador de núcleo de borda A informa ao B queo roteador A receberá pela porta 1 os quadros L2 com outro rótulo, enviando os quadroscom dois rótulos, fazendo com que chegue ao seu destino na porta correta.
Figura 5.10. Serviço de rede privativa L3 VPN.
5.2.3. Qualidade de Serviço (QoS), Engenharia de Tráfego e restauração Rede IP/MPLS
A qualidade de serviço (Quality of Service - QoS) representa um conjunto de me-canismos aplicados da rede do cliente até o o backbone IP/MPLS da operadora, visando

Figura 5.11. Serviço de rede privativa L2 VPN ponto a ponto (VLL).
garantir requisitos de desempenho para diferentes fluxos de dados como por exemplo voze vídeo. As características de QoS podem ser especificadas em termos quantitativos devazão de tráfego, de atraso, variação do atraso (jitter), descarte de pacotes e banda dispo-nível. O protocolo MPLS, como o protocolo IP permitem utilizar os seguintes modelosbásicos de QoS: serviços diferenciados (DiffServ-Differentiated Services) e serviços in-tegrados (IntServ-Integrated Services) definido na RFC 1663. O modelo mais utilizadoé o de serviços diferenciados, definido na RFC 2475 [documents, 2001], gerenciandorecursos de rede e criando classes de serviço que são atendidas em filas diferentes., queidentifica o nível de prioridade do fluxo de dados. No campo ToS do pacote IPv4 os 6bits mais significativos são do campo tipo de serviço são denominados DSCP (DiffservCode Point), e os 3 bits mais significativos são denominados IP precedence. No MPLS ainformação de qualidade de serviço é definida no campo EXP bits contida no rótulo. AFigura 5.12 mostra a marcação de classes de serviço DSCP, IP Precedence e no MPLS.
A RFC 3270 [Rose, 2014] define dois modelos básicos de diferenciação de servi-ços no MPLS: o modo uniforme (Uniform Mode) onde a informação do campo IP prece-dence é repassado para EXP bits do MPLS de forma uniforme e vice-versa, o modo tubo(Pipe Mode) o IP precedence não é repassado ao EXP bits do MPLS, sendo preservadoindependente das remarcações dos EXP bits ao longo da rede de roteadores de núcleo.
Na (Figure 5.13) são ilustrados os principais mecanismos de QoS na rede: clas-sificação, marcação, policiamento, condicionamento e enfileiramento do tráfego. Ao in-gressar em uma rede com QoS um pacote IP os pacotes são classificados segundo camposdo cabeçalho IPv4: endereço físico de rede (MAC address), IP de origem/destino, portaTCP/UDP de origem/destino. Após ser classificado o pacote é marcado, indicando suaclasse de serviço que será utilizada em toda a rede. A marcação é feita no campo de tipo

Figura 5.12. Marcações de QoS no pacote IPv4 e MPLS.
de serviço (Type of Service - ToS) no cabeçalho IP e no EXP bits do MPLS, de acordo comas características do serviço ofertado. O policiamento descarta o tráfego fora das políticasque mantém a integridade da rede, como por exemplo a banda assegurada e excedentepermitida em um determinado fluxo de dados. O condicionamento controla as rajadasde tráfego evitando descartes através da conformação do tráfego (shapping). Antes dopacote ser transmitido este é separado em filas, que utilizam diferentes mecanismos deexpedição dos pacotes ou escalonamento, adequando o fluxo de dados com sua marcaçãode prioridade. de enfileiramento baseado em classes com ponderações razoáveis (Class-Based Weighted Fair Queueing) - CBWFQ). No caso de congestionamento os descartessão inevitáveis. As filas começam a descartar pacotes segundo critérios pré-estabelecidospara cada classe [Marzo et al., 2003].
Podemos dizer que o MPLS para engenharia de tráfego é uma forma de proverqualidade de serviço.O conceito de engenharia de tráfego no MPLS, ou MPLS-TE (MPLSTraffic Engineering), foi desenvolvido para resolver estes problemas: congestionamento,otimização da banda dos enlaces e convergência da rede com fornecimento da proteçãonecessária ao tráfego sem superdimensionar a banda de cada enlace, através da reservade recursos. A estratégia do MPLS-TE é o cálculo de caminhos baseados em restriçõespresentes na rede como banda disponível, latência, perda de pacotes e outras métricas(Constraint Shortest Path First - CSPF), sugerindo uma rota diferente do IGP (InteriorGateway Protocol), como o OSPF usado em redes IP/MPLS sem engenharia de tráfego[Xipeng Xiao, 2000, Alvarez, 2016].
O cálculo de caminhos (CSPF) com é feito pelo PCE (Path Computation Element),papel desempenhado pelo plano de controle dos roteadores de núcleo.
A reserva de recursos para o caminho é feita pelo protocolo de reserva de re-cursos com engenharia de tráfego (Resource reSerVation Protocol Traffic Engineering –RVSP-TE), que é uma extensão do protocolo RSVP definido na RFC 3208 [Rose, 2014],garantindo o QoS para cada fluxo de dados. O RSVP-TE é usado para o estabelecimentodo LSP (Label Switch Path). Os LSPs podem ser configurados manualmente (ExplicitLSP) ou dinâmicamente (Dynamic LSP) através do IGP com extensões para engenhariade tráfego , como o OSPF-TE (Open Shortest Path First - Traffic Engineering) através da
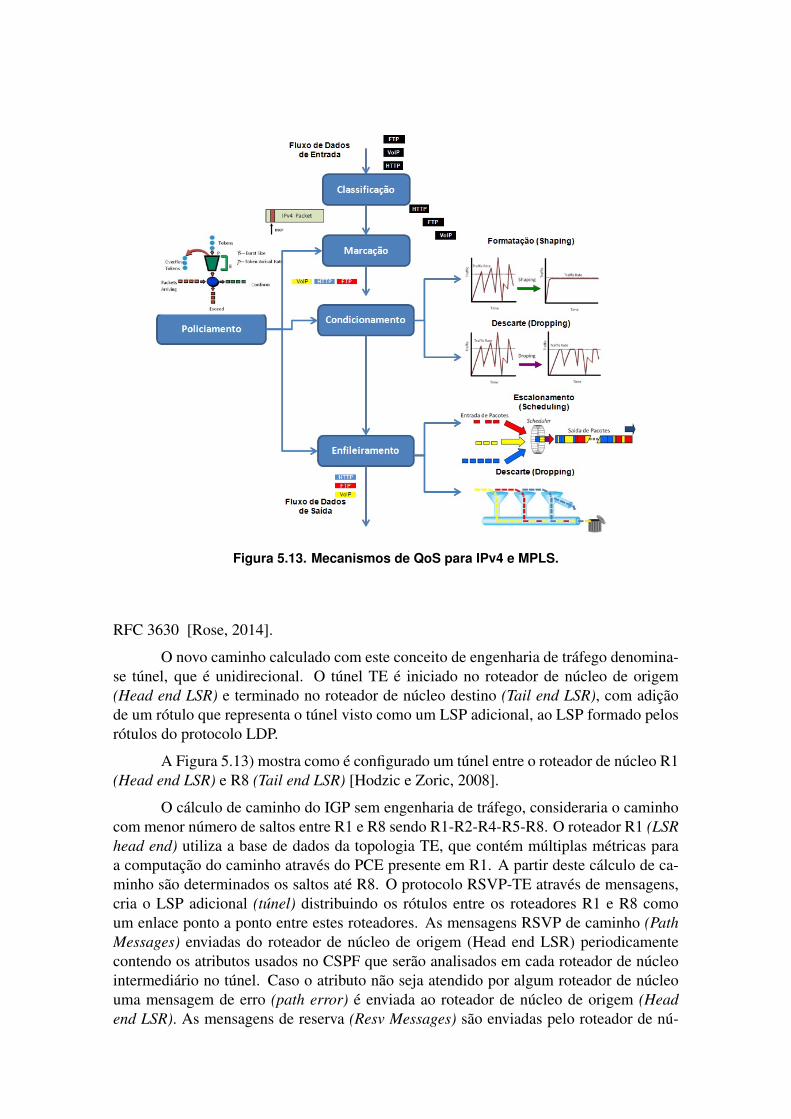
Figura 5.13. Mecanismos de QoS para IPv4 e MPLS.
RFC 3630 [Rose, 2014].
O novo caminho calculado com este conceito de engenharia de tráfego denomina-se túnel, que é unidirecional. O túnel TE é iniciado no roteador de núcleo de origem(Head end LSR) e terminado no roteador de núcleo destino (Tail end LSR), com adiçãode um rótulo que representa o túnel visto como um LSP adicional, ao LSP formado pelosrótulos do protocolo LDP.
A Figura 5.13) mostra como é configurado um túnel entre o roteador de núcleo R1(Head end LSR) e R8 (Tail end LSR) [Hodzic e Zoric, 2008].
O cálculo de caminho do IGP sem engenharia de tráfego, consideraria o caminhocom menor número de saltos entre R1 e R8 sendo R1-R2-R4-R5-R8. O roteador R1 (LSRhead end) utiliza a base de dados da topologia TE, que contém múltiplas métricas paraa computação do caminho através do PCE presente em R1. A partir deste cálculo de ca-minho são determinados os saltos até R8. O protocolo RSVP-TE através de mensagens,cria o LSP adicional (túnel) distribuindo os rótulos entre os roteadores R1 e R8 comoum enlace ponto a ponto entre estes roteadores. As mensagens RSVP de caminho (PathMessages) enviadas do roteador de núcleo de origem (Head end LSR) periodicamentecontendo os atributos usados no CSPF que serão analisados em cada roteador de núcleointermediário no túnel. Caso o atributo não seja atendido por algum roteador de núcleouma mensagem de erro (path error) é enviada ao roteador de núcleo de origem (Headend LSR). As mensagens de reserva (Resv Messages) são enviadas pelo roteador de nú-

Figura 5.14. Cálculo de caminho do túnel TE.
cleo de destino (Tail end LSR) após receber uma mensagem de caminho (Path Messages),iniciando o processo de distribuição de rótulos, e cada roteador de núcleo intermediárioinforma o rótulo a ser usado pelo antecessor. Se um dos roteadores de núcleo interme-diários (Mid point) não puder confirmar a reserva, envia uma mensagem de erro (Resverror) ao roteador de núcleo de origem do túnel. A Figura 2.12 mostra como o RSVP-TEatravés de sua sinalização, constrói o túnel TE [Alvarez, 2016].
Um dos requisitos da engenharia de tráfego é a capacidade de rerotear um túnelTE baseado em políticas administrativas. O mecanismo de reroteamento rápido (FastReroute - FRR) previne falhas de nós de rede e enlace, podendo ser utilizado também nadisponibilidade de uma rota mais otimizada, na ocorrência da falha de recursos do túnel,ou por uma decisão administrativa da Operadora. A Figura 2.13 mostra a criação do túnelprimário (Primary Tunnel) formado pelos roteadores A, B, D, E e o túnel de proteção(Backup Tunnel), que é pré-provisionado nos roteadores B, C e D. O tráfego é reroteadosobre o túnel de proteção em 50 ms. O protocolo BFD (Bidirectional Failure Detection) éusado para a detecção de falhas nos roteadores de núcleo vizinhos a esta, propiciando ummecanismo de convergência rápida para a comutação do túnel primário para o de proteção[Simha, 2002, Alvarez, 2016].
A engenharia de tráfego também pode ser usada para balanceamento de tráfego

Figura 5.15. Criação do túnel TE.
através de múltiplos túneis TE de mesmo custo, ou de custos ponderados, permitindoum balanceamento do tráfego ponderado. A malha de túneis e sua banda podem serconfigurados manualmente ou automaticamente (Auto Tunnel/Auto Bandwidth) atravésde um roteiro repetitivo de configurações (templates). A (Figure 5.17) mostra a malha detúneis para atendimento a uma dada matriz de tráfego [Simha, 2002].
Na topologia de túneis em malha para balanceamento de tráfego, ou nos túneisprimários e de proteção, necessitam de caminhos disjuntos. Alguns túneis podem utilizaro mesmo recurso físico, por exemplo o mesmo cabo de fibra óptica. O SLRG (Shared RiskLink Group) identifica grupos com enlaces físicos comuns. No exemplo da (Figure 5.18),o SLRG de número 10, indica enlace comum no caminho de R2-R4 e R2-R3. A infor-mação do SLRG é usada como um atributo adicional pelo IGP para evitar a configuraçãotúneis no mesmo enlace físico [Alvarez, 2016].
5.2.4. Desafios para Engenharia de Tráfego e Restauração em Redes IP/MPLS
A Operadora de Telecomunicações utiliza engenharia de tráfego pata o tratamentode falhas nos enlaces físicos da rede. A camada de rede física (Layer 0 e 1), também de-nominada Rede de Transporte, é composta por equipamentos DWDM (Dense WavelenghtDivision Multiplex), ROADM (Reconfigurable Add Drop Multiplex) e comutadores OTN(Optical Transport Network). Estes elementos da rede de transporte realizam a multiple-xação e comutação no domínio óptico e elétrico de forma conveniente com as demandasde tráfego, além de realizar funções de formatação e regeneração dos sinais, de proteção erestauração de rede. A rede de transporte possui um plano de controle próprio baseado nopadrão ASON (Automatically switched optical network) e GMPLS (Generalized MPLS).
A rede de transporte (camada L0 e L1) é segregada da rede de roteadores de núcleo
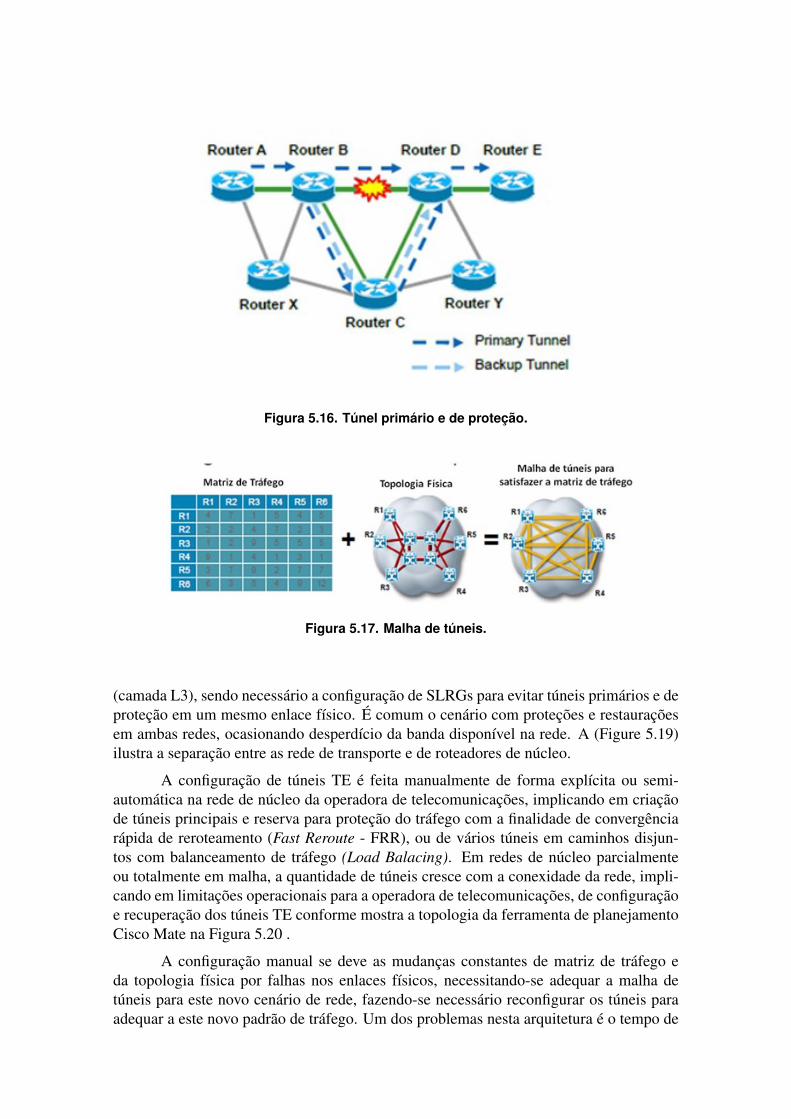
Figura 5.16. Túnel primário e de proteção.
Figura 5.17. Malha de túneis.
(camada L3), sendo necessário a configuração de SLRGs para evitar túneis primários e deproteção em um mesmo enlace físico. É comum o cenário com proteções e restauraçõesem ambas redes, ocasionando desperdício da banda disponível na rede. A (Figure 5.19)ilustra a separação entre as rede de transporte e de roteadores de núcleo.
A configuração de túneis TE é feita manualmente de forma explícita ou semi-automática na rede de núcleo da operadora de telecomunicações, implicando em criaçãode túneis principais e reserva para proteção do tráfego com a finalidade de convergênciarápida de reroteamento (Fast Reroute - FRR), ou de vários túneis em caminhos disjun-tos com balanceamento de tráfego (Load Balacing). Em redes de núcleo parcialmenteou totalmente em malha, a quantidade de túneis cresce com a conexidade da rede, impli-cando em limitações operacionais para a operadora de telecomunicações, de configuraçãoe recuperação dos túneis TE conforme mostra a topologia da ferramenta de planejamentoCisco Mate na Figura 5.20 .
A configuração manual se deve as mudanças constantes de matriz de tráfego eda topologia física por falhas nos enlaces físicos, necessitando-se adequar a malha detúneis para este novo cenário de rede, fazendo-se necessário reconfigurar os túneis paraadequar a este novo padrão de tráfego. Um dos problemas nesta arquitetura é o tempo de

Figura 5.18. SLRG (Shared Risk Link Group).
Figura 5.19. Separação de camadas de rede de transporte e IP/MPLS.
convergência da rede em caso de falhas, intrinsecamente relacionado com a separação darede de roteadores de núcleo (camada L3) com a rede de transporte (camada L0 e L1).Outro problema é a sobrecarga nos enlaces com tráfego adicional reroteado na situação defalha. A sobrecarga de enlaces com banda insuficiente pode ocasionar a perda de tráfego.Uma solução para aliviar este problema é superdimensionar a banda de cada enlace, querepresenta maiores investimentos em equipamentos nas diversas camadas de rede.
O crescimento da Internet e de serviços convergentes que trafegam nas redes denúcleo impulsionaram redes de transmissão óptica de alta capacidade DWDM ((DenseWavelength Division Multiplex) e a necessidade de topologias físicas em malha para sal-vamento do tráfego sujeito a interrupções de rede simultâneas. A desvinculação da topo-logia de rede física da rede lógica de túneis TE representa um desafio enfrentado pelasoperadoras , pois uma interrupção em um enlace físico pode corresponder à interrupçãode ambos os túneis, TE principal e reserva. Este fato decorre do plano de controle MPLSnão possuir mecanismos de visão da topologia da rede no que se refere a caminhos físicose de integração de diferentes camadas de rede, representando um grande desafio para asOperadoras o dimensionamento e a configuração das diversas camadas de rede.

Figura 5.20. Configuração de túneis TE com a ferramenta Cisco Mate.
5.3. Conceitos de Redes Definidas por Software (8 páginas)5.3.1. Arquitetura e Desenvolvimento do SDN
O conceito Redes Definidas por Software ( Software Defined Networks - SDN)nasceu em 2007 nas universidades de Stanford e Berkeley, com a ideia de se obter umcontrole centralizado que fosse programável e ágil para administração de capacidade derede e de serviços fim a fim. A arquitetura de rede SDN é formada por quatro pilaresfundamentais :
• O desacoplamento do plano de controle e de encaminhamento de dados.
• As decisões são baseadas em fluxos ao invés do endereçamento de destino. A pro-gramação de fluxos permite uma grande flexibilidade, limitada ao tamanho das ta-belas de fluxos.
• A lógica de controle está em uma entidade externa denominada controlador ( con-troller ) ou sistema operacional ( Network Operating System – NOS). O controla-dor é uma plataforma de software que roda em um servidor de uso comum COTS( Commercial off the shelf ), provendo os recursos essenciais de rede e abstraçõespara facilitar a programação dos dispositivos de encaminhamento. As abstraçõesem SDN são ferramentas de prover informações de forma ubíqua qualquer que sejaa arquitetura de computadores e sistema.
• A rede é programável através de aplicações de software que rodam em cima dosistema operacional ou controlador. Surgiram diversas propostas de separação doplano de encaminhamento e de controle no contexto do SDN, como por exemploo ForCES ( Fowarding and Control Element Separation ) definido na RFC 5810,onde o controlador e os elementos de rede estão localizados no mesmo dispositivo,enquanto na proposta com o protocolo OpenFlow, o controlador e os elementos derede estão separados fisicamente. Em uma visão simplificada da arquitetura de redeSDN, a infraestrutura física é formada pelos dispositivos de encaminhamento de

pacotes, como por exemplo Switches Openflow ou outros dispositivos como rotea-dores sem o plano de controle ou com o plano de controle reduzido, com interfacesabertas.A Figura 5.21 mostra uma visão simplificada da arquitetura SDN.
Figura 5.21. Visão da Arquitetura SDN simplificada.
O controle da rede é composto de módulos de fácil manuseio, simplificando acriação e introdução de novas abstrações de rede facilitando sua evolução [3,4]. Na arqui-tetura da figura anterior, o controlador SDN, corresponde ao sistema operacional de rede,sendo um elemento crítico na arquitetura de redes definidas por software. Os controla-dores SDN podem ser centralizados ou distribuídos, fornecendo serviços básicos de redecomo o estado da rede e sua topologia, caminhos mais curtos, e interfaces de programa-ção de aplicação abertas (Application Programming Interface - API) para os dispositivosda infraestrutura física (Southbound Interface - SBI) e para a camada das aplicações derede ( Northbound Interface - NBI). O plano de gerência é o conjunto de aplicações quepermite que as funções do NBI sejam implementadas pela lógica de controle e operaçãode rede. Um exemplo de ampla aceitação de Southbound API na comunidade de soft-ware aberto é o protocolo OpenFlow, e o switch OpenFlow sendo este último programadopelo controlador para comportar-se como um roteador, switch, firewall, ou com outrasfuncionalidades de rede como balanceadores e condicionadores de tráfego. Embora oOpenFlow tenha iniciado em experimentos acadêmicos, hoje desponta com destaque naindústria, como por exemplo na Google que empregou o OpenFlow em seus projetos deSDN para interligação de Datacenters.
Em redes IP tradicionais o plano de controle e de dados são fortemente acopla-dos, embutidos no mesmo dispositivo de rede. Esta integração vertical é a razão pelaqual as redes IP são rígidas e complexas, para gerenciar e controlar, e é difícil introduzirinovações tecnológicas. Por exemplo, a transição do IPv4 para IPv6 começou cerca deuma década, e sua implantação ainda se encontra incompleta. Outro problema de redesIP tradicionais, são a configuração e gerenciamento da rede. Se um único dispositivo darede tem uma configuração errada, poderá resultar em um comportamento indesejado em

toda a rede, incluindo perda de tráfego. Para gerência de redes, a maior parte dos fabri-cantes oferecem soluções com hardware, sistemas operacionais e programas de controleproprietários. As redes de núcleo TCP/IP sobre MPLS apresentam também grande com-plexidade de configuração devido aos inúmeros protocolos envolvidos, bem como a faltade flexibilidade em resposta a mudanças da rede, falhas e balanceamento de tráfego.
As Redes Definidas por Software (Software Defined Networks - SDN) constituemuma mudança de paradigma em redes de computadores que rompe a integração verticalda rede, separando o plano de controle do plano de encaminhamento de dados de rotea-dores e switches, promovendo a centralização do controle da rede, introduzindo assim acapacidade de programação e flexibilidade da rede. A Figura 5.22 mostra a comparaçãoentre uma rede tradicional e uma rede SDN.
Figura 5.22. Rede Tradicional x Rede Definida por Software.
A Figura 5.23 o diagrama da arquitetura de sistemas de rede SDN, detalha planos,camadas e sistemas. O plano de dados é constituída pela infraestrutura de rede e interfaces“southbound” (SBI). A infraestrutura de rede similar a uma rede tradicional, correspondeaos dispositivos de rede que desempenham instruções elementares de encaminhamento detráfego. Estas instruções são definidas por interfaces abertas SBI como o OpenFlow, porexemplo. O plano de controle é constituído por uma camada de virtualização, outra cor-respondente ao sistema operacional de rede e as interfaces northbound (NBI). O sistemaoperacional de rede pode estar ou não em uma infraestrutura de hardware virtualizadaatravés do “Hypervisor”, que permite a criação de máquinas virtuais dos servidor físicoonde será instalado o controlador, funcionalidade e aplicações de rede. O controlador ousistema operacional de rede programa os dispositivos de rede, sendo o controlador de redeconsiderado o “cérebro” do sistema. Por fim ainda neste plano, as interfaces northbound(NBI) oferecem APIs para desenvolvedores de aplicação. O plano de gerência corres-ponde ao conjunto de aplicações, utilizando linguagens de programação e linguagens deprogramação apropriadas para ambiente virtualizado, interligando todas as funcionalida-des de rede para que as aplicações possam implementar a lógica e controle da rede atravésda NBI.
A seguir serão detalhados cada uma das camadas da arquitetura de rede SDN.

Figura 5.23. Diagrama de arquitetura de sistema de rede SDN.
5.3.2. Plano de Dados
5.3.2.1. Infraestrutura de rede
A infraestrutura de rede física do SDN é similar às redes tradicionais composta porum conjunto de equipamentos de rede, com a diferença que estes dispositivos são simples-mente elementos de encaminhamento de dados, sem controle ou software embarcado quepermita o dispositivo tomar decisões autônomas. A inteligência reside no sistema operaci-onal de rede e aplicações. Estes dispositivos possuem interfaces padrões SBI que podemser abertas, como o OpenFlow. Vários dispositivos de encaminhamento OpenFlow sãodisponíveis no mercado com pequena capacidade de memória TCAM (ternary content-addressable memory) de 8000 entradas, no entanto switches e roteadores OpenFlow comcircuito integrado de alto desempenho permitem alcançar 1 x 106 de entradas. A quan-tidade de entradas é um dos fatores limitantes do emprego destes dispositivos em redesde grandes dimensões. Um grande número de empresas iniciantes (startups) surgiram nomercado fabricantes de diversos dispositivos switches L2 e L3 habilitados no plano deencaminhamento com o protocolo aberto OpenFlow, denominados “Bare Metal” Swit-ches"ou “Whitebox” baseado em hardware x.86, onde o usuário final tem livre escolha dosistema operacional de rede. Switches virtuais são uma promissora e emergente soluçãopara Datacenters e infraestrutura de redes virtualizadas.
Figura 5.24. Dispositivo OpenFlow: WhiteBox x.86.

5.3.2.2. Interfaces Southbound: NETCONF, PCEP, BGP-LS, OpenFlow e outros
A separação entre o plano de encaminhamento de dados é realizada através deuma interface padronizada de programação de aplicação API, denominada SBI (South-bound Interfaces), e estas interfaces podem ser abertas como o protocolo Openflow, NET-CONF, BGP-LS (Border Gateway Protocol - Link State ), PCEP (Path Computation Ele-ment Communication Protocol) [10], OVSDB (Open vSwitch Database), SNMP (SimpleNetwork Management Protocol) e CLI (Command Line Interface) [3].
Um tendência alternativa de SBI para o SDN é a utilização de APIs legadas comoSNMP, CLI, TL1 (Transaction Language 1) e o protocolo de gerenciamento de equipa-mento de premissa de usuário em redes WAN (CPE WAN Management Protocol) definidona norma ETSI TR-069. O protocolo SNMP é um padrão que foi concebido para itera-ção da gerência e dos dispositivos de rede, envolvendo um protocolo simples controladopor funções para retirar (GET) e por (SET) informações no dispositivo de redes em umabase de gerenciamento de informações (Management Information Base – MBI). A CLI éuma forma iterativa onde o administrador de rede acessa um dispositivo. Em um dispo-sitivo de rede legado, as funcionalidades do dispositivo de rede são acessíveis através daCLI e não por SNMP. Alguns tipos de CLI tem suporte a “scripts”, que confere algumaautomação na configuração dos dispositivos de forma estática. A TL1 foi desenvolvidaespecificamente para equipamentos de telecomunicações, cujo objetivo é a comunicaçãoentre máquinas. A TR-069 teve como objetivo a comunicação entre o CPE e um servidorde autoconfiguração (Autoconfiguration Server – ACS). O ACS provê uma forma segurade automação da configuração do dispositivo, incorporando funções de gerenciamentoem uma estrutura unificada de software. O protocolo NETCONF foi desenvolvido paraser o sucessor natural do SNMP, pois o SNMP tinha o foco no monitoramento e não naconfiguração da rede. O OVSDB (Open vswitch Database) é um protocolo de gerencia-mento em redes definidas por software, definido na RFC 7047. O protocolo OVSDB foicriado pela empresa Nicira, adquirida pela VMware. Originalmente o OVSDB era partedo OVS (Open vSwitch) que é uma funcionalidade de switch virtual projetado para “Hy-pervisors” em LINUX. O OVS representa uma evolução dos protocolos de gerenciamentode rede, permitindo a programar e configurar bridges, portas e interfaces de plataformasde equipamentos SDN e de virtualização de funções de rede (Network Virtualization -NFV).
NETCONF e YANG
O NETCONF é um protocolo de gerenciamento de rede definido em 2006 peloIETF para configuração e monitoramento da rede, este último papel desempenhado pelopopular protocolo SNMP desde o final dos anos 80. O IETF reuniu requisitos de ge-renciamento das Operadoras de Telecomunicações na RFC 3535, identificando a lista detecnologias relevantes para gerenciamento de redes, como exemplo o uso corrente de CLIcujo ponto forte era a interface texto, no entanto proprietária para cada fabricante comoponto fraco. O SNMP tinha como ponto fraco não possuir recursos de configuração derede além da interface binária BER (Basic Encoding Rules) além de MIBs proprietárias.O protocolo NETCONF utiliza mecanismos que permitem instalar, manipular e apagar a

configuração de dispositivos de rede através de uma implementação cliente-servidor. ONETCONF opera no topo do protocolo RPC ( Remote Call Procedure). Os dados co-dificados no protocolo NETCONF são baseados em XML tanto para dados quanto paraas mensagens. O protocolo de transporte é o TCP, utilizando na camada de aplicação oHTTP ou HTTPS A Figura 5.26 mostra as camadas do NETCONF definidos na RFC6241:
Figura 5.25. Modelo de implementação cliente-servidor do NETCONF.
Figura 5.26. Quatro camadas do protocolo NETCONF.
A RFC6241 define repositórios de dados de configurações necessárias a um dis-positivo sair do estado inicial para o estado operacional, e também define modelos transa-cionais para aplicação das configurações corrente (running), inicial (startup) e candidatas(candidate) que representam o estado intermediário antes de serem aplicadas (commit),tornando-se configuração corrente. Após estabelecimento da sessão segura de transporte,o protocolo NETCONF envia uma mensagem de “hello” para anúncio das capacidadesdo protcocolo e modelos de dados suportados como no exemplo abaixo em XML:S: <hello xmlns="urn:ietf:params:xml:ns:netconf:base:1.0»S: <capabilities>S: <capability>S: urn:ietf:params:xml:ns:netconf:base:1.1S: </capability>S: <capability>S: urn:ietf:params:xml:ns:netconf:capability:startup:1.0

S: </capability>S: <capability>S: urn:ietf:params:xml:ns:yang:ietf-interfaces?S: module=ietf-interfaces&revision=2012-04-29S: </capability>S: </capabilities>S: <session-id>4<session-id>S: </hello>
O NETCONF suporta a subscrição e o recebimento de notificações de eventos deforma assíncrona. Outra importante funcionalidade do protocolo NETCONF é o fecha-mento parcial (partial locking) de uma configuração corrente de um dispositivo de rede,permitindo múltiplas sessões de edição, permitindo agilizar de forma eficiente o processode configuração. O protocolo NETCONF pode ser monitorado e gerenciado por uma en-tidade autônoma (Gerente NETCONF), com repositório de dados, sessões, fechamentos(lock) e estatísticas estão disponíveis no servidor NETCONF.
O YANG é uma linguagem formal de modelo de dados com uma rica sintaxe esemântica permitindo a construção de aplicações, definida na RFC 6020. O modelo dedados YANG é legível e de fácil aprendizado, com configurações hierárquicas de modelode dados, estruturas reutilizáveis, através de módulos, submódulos e versões com regrasbem definidas. O modelo YANG pode se traduzir em um arquivo de formato XML ouJSON. O modelo de dados YANG é estruturado em uma árvore para cada módulo, compropriedades que correspondem às funcionalidades do dispositivo; e declarações (state-ment ) de tipos, dados, restrições, acréscimos de estruturas reutilizáveis. Os tipos de dadosYANG estão definidos na RFC 6021
Figura 5.27. Modelo de dados YANG.

Figura 5.28. Exemplo de módulo YANG para inventário de rede.
BGP-LS
Existem duas formas básicas de obtenção de informações de topologia de rede:protocolos de gerenciamento e roteamento. Um protocolo de roteamento responsável porobter a informação da topologia da rede é o BGP-LS (Border Gateway Protocol LinkState), que é uma extensão do protocolo BGP que permite carregar informações dos esta-dos dos enlaces. Esta informação é usada pelo IGP, que normalmente utiliza outra base deinformações de estados dos enlaces como a TED ( Traffic Engineering Database) usadana engenharia de tráfego, sendo que ambas provêm o mesmo conjunto de informações .Esta informação pode ser agregada de múltiplas áreas e de diferentes sistemas autônomos(Autonomous System - AS), permitindo uma análise interessante do estado da rede. OBGP-LS foi desenvolvido especificamente para alavancar algumas propriedades do BGPcom melhor escalabilidade, como o controle baseado em fluxos TCP e o uso estratégicode roteadores RR (Router Reflectors), quando é necessário adquirir informações de topo-logia multiarea, o que tradicionalmente é feito por um elemento da rede de um sistemaautônomo que reúne as informações dos demais elementos de outros sistemas autônomosatravés de meios manuais. Um controlador de engenharia de tráfego, por exemplo umaaplicação de servidor PCE (Path Computation Server - PCS) implementa BGP-LS paraadquirir a topologia de roteamento. O BGP-LS suporta também mecanismos de políticasque limitam o uso de certos nós e enlaces da rede, ou seções de topologia particionadaspelo operador da rede. A Figura 5.29 mostra um controlador SDN interagindo com dis-positivos de rede de diferentes AS e com IGP tradicional e com o BGP-LS. O BGP-LS édefinido no draft-ietf-idr-ls-distribution-13 do IETF.
Figura 5.29. Southbound interface BGP-LS.

PCEP
O protocolo PCEP (Path Computation Element Protocol) é usado para comuni-cação entre o PCC (Path Computation Client) e o PCE (Path Computation Element) uti-lizando informações dos estados do enlace LSDB (Link-State Database) conforme mos-trado na Figura 5.30 O protocolo PCEP é usado desde 2006 e definido na RFC 5440. OPCE de controle dinâmico (stateful PCE) definido no IETF no draft-ietf-pce-stateful-pcee o PCE iniciado pelo LSP definido no draft-ietf-pce-pce-initiated-lsp com extensões re-centes para habilitar para emprego destes no SDN. As extensões em ambos os “drafts”do IETF ainda não avançaram como uma proposição de padrão final, devido às signifi-cativas revisões e porque muitos fabricantes relutam em manter apenas as mudanças quefavorecem suas versões de software. A maior parte dos fabricantes de dispositivos derede e controladores SDN suportam as seguintes implementações de PCEP draft-ietf-pce-stateful-pce-02 and draft-crabbe-pce-pce-initiated-lsp-00 e draft-ietf-pce-stateful-pce-07and draft-ietf-pce-pce-initiated-lsp-00 Estas duas versões não iteroperam, e como resul-tado as aplicações de orquestração para que estas versões possam suportar redes de múl-tiplos fabricantes.
Figura 5.30. Protocolo PCEP.
OpenFlow
Outra tendência de SBI para SDN aberta é o protocolo OpenFlow. O protocoloOpenFlow foi desenvolvido para fins acadêmicos na Universidade de Stanford e atravésda ONF (Open Network Foundation) que ganhou notoriedade na indústria, e atualmenteé a entidade responsável pela especificação de cada versão deste protocolo. O OpenFlowé um protocolo que utiliza tabelas com regras de manuseio de pacotes, denominadas ta-belas de fluxos (Flow Tables). Cada regra permite certas ações como encaminhamento(Fowarding), descarte (Dropping) e modificação (Modify) do fluxo. O OpenFlow per-mite controlar os fluxos de dados encaminhando e processando os pacotes, conformeas ações (action) e regras (rule) instruídas pelo controlador em switches OpenFlow. Oswitch OpenFlow é um dispositivo simples de encaminhamento de pacotes, permitindoencaminhar o pacote para uma determinada porta, descartar o pacote ou passar os pa-cotes para o controlador. Existem switches puramente OpenFlow e switches OpenFlowhíbridos que permitem o encaminhamento dos pacotes com a lógica do controlador e da

forma dos switches ethernet e roteadores IP legados. Entre o switch OpenFlow existeum canal seguro que conecta o switch ao controlador da rede e é implementado por umcanal de comunicação TLS (Transport Layer Security) com criptografia simétrica sobreTCP na porta 6633. No canal seguro diferentes tipos de mensagens são trocadas entre ocontrolador e o switch OpenFlow. Cada mensagem contém um cabeçalho OpenFlow queespecifica a versão do protocolo OpenFlow utilizada. O protocolo Openflow suporta 3categorias de mensagens:
• Controlador-Switch : inciada pelo controlador e usado para inspeção do estado doswitch.
• Assíncrona: iniciadas pelo switch e usada para atualizar o controlador de eventosna rede e mudanças de estado dos switches.
• Simétrica: Iniciadas por ambos e sem solicitação. Exemplos de mensagens simétri-cas: “Packet-Ins, Flow-Removed, Port-Status or Error”.
A Figura 5.31 mostra uma arquitetura de controlador e switch OpenFlow.
Figura 5.31. Controlador e Switch OpenFlow.
O plano de dados de um dispositivo SDN OpenFlow (Switch OpenFlow) é base-ado em tabelas de fluxos (Flow Table). Cada linha da tabela é denominada entrada natabela de fluxo (Flow-Entry) formada por uma regra, uma acão, e uma estatística, quemantém registrado o numero de pacotes e bytes para cada fluxo A Figura 5.32 mostra re-sumidamente o funcionamento da SBI OpenFlow, com suas tabelas de fluxos e as entradana tabela de fluxo. As regras são baseadas na porta do switch, identificador da VLAN(VLAN id), prioridade da VLAN (VLAN priority), endereço físico de origem e destino(Source MAC/Destination MAC), tipo de frame (Frame Type), IP de origem e destino,tipo de protocolo, tipo de serviço (Type of Service - ToS), porta TCP/UDP de origem edestino. O protocolo OpenFlow tem diferentes versões de especificação. A primeira es-pecificação “draft” foi lançada em 2008, OF (OpenFlow) 0.2.0, a especificação OF 1.0foi a primeira versão com suporte oficial para fabricantes. A versão 1.0 suporta apenasuma tabela de fluxos, onde cada entrada de fluxo contém campos de cabeçalho que com-põem as regras, as ações e contadores de estatísticas. A versão 1.1 suporta várias tabelasde fluxos interligadas. As instruções contém o comando “Go To” que aponta para outra

tabela, e as ações na mesma tabela que pertence ao mesmo grupo (Group Table) são apli-cadas a múltiplos fluxos. A versão 1.1 suporta VLAN e Q-in-Q, portas virtuais e túneis,roteamento multipercurso e ECMP (Equal-cost multi-path routing) e MPLS. A versão 1.2suporta IPv6 e capacidade de extensões OXM (OpenFlow Extensible Match) baseado emestruturas TLV (Type-Length-value). A versão 1.3 introduz a tabela de fluxos não casadosa cada regra tabela de fluxo e operações de QoS. A versão 1.4 incorpora novas estrutu-ras TLV melhorando as extensões do protocolo OpenFlow, como por exemplo o suportede portas ópticas, com novas propriedades como a potência do Laser e frequências detransmissão e recepção. Ainda na versão 1.4 uma opção de despejo (eviction) foi adi-cionada para eliminar entradas menos importantes automaticamente, conseguindo vagaspara novas entradas na tabela de fluxos, além de informar o controlador as tabelas de fluxoesgotadas. A Figura 5.33 mostra a evolução das diversas versões do OpenFlow.
Figura 5.32. Tabelas de fluxos OpenFlow.
Figura 5.33. Evolução do protocolo OpenFlow.
5.3.3. Plano de Controle
5.3.3.1. Arquitetura de virtualização para o SDN: Hypervisor de rede
A virtualização é uma tecnologia já consolidada na computação moderna. O con-trolador SDN e as Aplicações de Rede podem ser instalados ou não em uma infraestruturavirtualizada de computação através de máquinas virtuais (Virtual Machine - VM). Outroconceito aplicável ao contexto de virtualização em redes, é a virtualização de funcionali-dades de rede (Network Functions Virtualization - NFV), formalmente especificada pelogrupo ISG (Industry Specifications Group - ISG) mostrado na Figura 5.34. O NFV moveas funções de rede para uma arquitetura de computação em nuvem (Cloud Computing)para servidores comerciais COTS (Commercial Off-the-Shelf) baseados em x.86. O con-trole da rede e as funções são abstraídas com a introdução de um “Hypervisor”, criando

uma rede que seja independente do tipo de aplicação conforme mostrado na Figura 5.35.O gerenciamento e orquestração da rede é realizado pelo orquestrador como por exemploo protolocolo aberto Openstack, e até em alguns casos SDN, que permite virtualizar osservidores e a infraestrutura da rede. A orquestração e gerenciamento baseado em nuvemfacilita a gerência de redes maiores e distribuídas, com oferta de serviços inovadores comoa cadeia de serviços (Service Chaining), permitindo que múltiplas funções de rede virtu-ais (Virtual Network Functions - VNF) sejam encadeadas tipicamente interconectadas porum switch virtual (vSwitch).
Figura 5.34. Implementação de funções de rede tradicional x funções virtualizadas.
O “Hypervisor” permite que máquinas virtuais compartilhem o mesmo recursode hardware físico permitindo a criação, remoção e movimentação de máquinas virtuaisdos controladores SDN e de aplicações de rede de forma flexível, elástica e com fácilgerenciamento, aproveitando os recursos disponíveis da computação em nuvem. Algunsexemplos de Hypervisors são o VMWARE, KVM e Openstack, sendo este último umpadrão aberto de software. A indústria reconhece que SDN e NFV são complementares,entretanto os serviços em NFV podem ser configurados diretamente com e sem o SDN, eo SDN também pode ser implementado com ou sem uma infraestrutura de virtualização.A Figura 5.36 mostra as opções de implementação de SDN e NFV de forma complemen-tar um ao outro. Existem protocolos de tunelamento para sobreposição de soluções devirtualização em redes, usando protocolos de tunelamento como VxLAN (Virtual eXten-sible Local Area Network), NVGRE ( Network Virtualization using GRE ), STT ( Sta-teless Transport Tunneling). Para prover de forma adequada a virtualização em SDN, arede física deve possuir propriedades similares à camada de computação. A Figura 5.37mostra uma arquitetura comparativa de rede tradicional,de rede de SDN através de APIsexistentes, onde o ambiente de virtualização é utilizado para a camada de controle e ge-renciamento de rede com aplicações de rede, sistemas OSS (Operations Support System) eBSS (Business Support Systems) e exemplo de implementação de SDN com virtualizaçãode funcionalidades de redes (NFV) no conceito de sobreposição.

Figura 5.35. Implementações de SDN e NFV complementares.
5.3.3.2. Controladores de Redes Definidas por Software: Opendaylight, ONOS eoutros
O controlador SDN, corresponde ao sistema operacional de rede, sendo um ele-mento crítico na arquitetura de redes definidas por software. Os sistemas operacionaistradicionais proveem abstrações (APIs de alto nível) para acessar um nível mais baixodos dispositivos, gerenciando o acesso concorrente dos recursos subjacentes como adap-tador de rede, hard drive, CPU e memória, oferecendo mecanismos de proteção e segu-rança. Em contraste, as redes foram gerenciadas e configuradas utilizando-se instruçõesde baixo nível específicas do dispositivo de rede e na maioria das vezes sistemas opera-cionais proprietários, como por exemplo IOS da Cisco e Junos da Juniper. Atualmenteos projetistas de protocolos de roteamento precisam lidar com complicados algoritmosdistribuídos para solução de problemas em redes. As redes definidas por software sãouma promessa para facilitar a gerência de redes e as soluções de problemas através deuma lógica centralizada. No entanto existem na indústria soluções híbridas onde parte doplano de controle ainda reside no dispositivo de rede conforme ilustrado na Figura 5.37.
São alguns dos serviços essenciais dos sistemas operacionais de rede: estado einformação da topologia da rede, descoberta dos dispositivos de rede e distribuição daconfiguração da rede. O sistema operacional de rede ou controlador é o elemento crí-tico de uma arquitetura SDN e é a chave da lógica de controle baseada nas aplicaçõespara gerar a configuração baseada em políticas definidas pela operadora de telecomuni-cações. Existem uma grande diversidade de controladores e plataformas de controle comdiferentes projetos e arquiteturas. As arquiteturas relevantes são com controladores cen-

Figura 5.36. SDN via API e SDN Overlay.
Figura 5.37. Rede Tradicional, Rede puramente SDN e Rede híbrida.
tralizados ou distribuídos, fornecendo serviços básicos de rede como o estado da rede esua topologia, caminhos mais curtos, e interfaces de programação de aplicação (Appli-cation Programming Interface - API) para os dispositivos da infraestrutura física e paraa camada das aplicações de rede. Um controlador centralizado tem a desvantagem deter um ponto único de falhas, sem escalabilidade e confiabilidade conforme mostrado naFigura 5.38, no entanto são simples de operar e possuem um controle do comportamentoda rede. Os controladores de código aberto NOX,POX, Floodlight e Ryu são do tipo cen-tralizado. O controlador centralizado pode ter outro controlador redundante no caso defalhas do controlador principal.
Os controladores distribuídos podem escalar melhor os requisitos de qualquer tipode rede de pequena a de grande escala. Um controlador distribuído pode ser um grupo(cluster) de controladores ou um conjunto de controladores distribuídos fisicamente emdiferentes domínios de rede. São exemplos de controladores distribuídos: Opendaylight,ONOS e yanc. Para controladores distribuídos as APIs de fronteira leste e oeste (East-bound e Westbound), são importantes em controladores distribuídos em diferentes domí-nios. Atualmente cada controlador implementa sua API de fronteira lest-oeste, com o
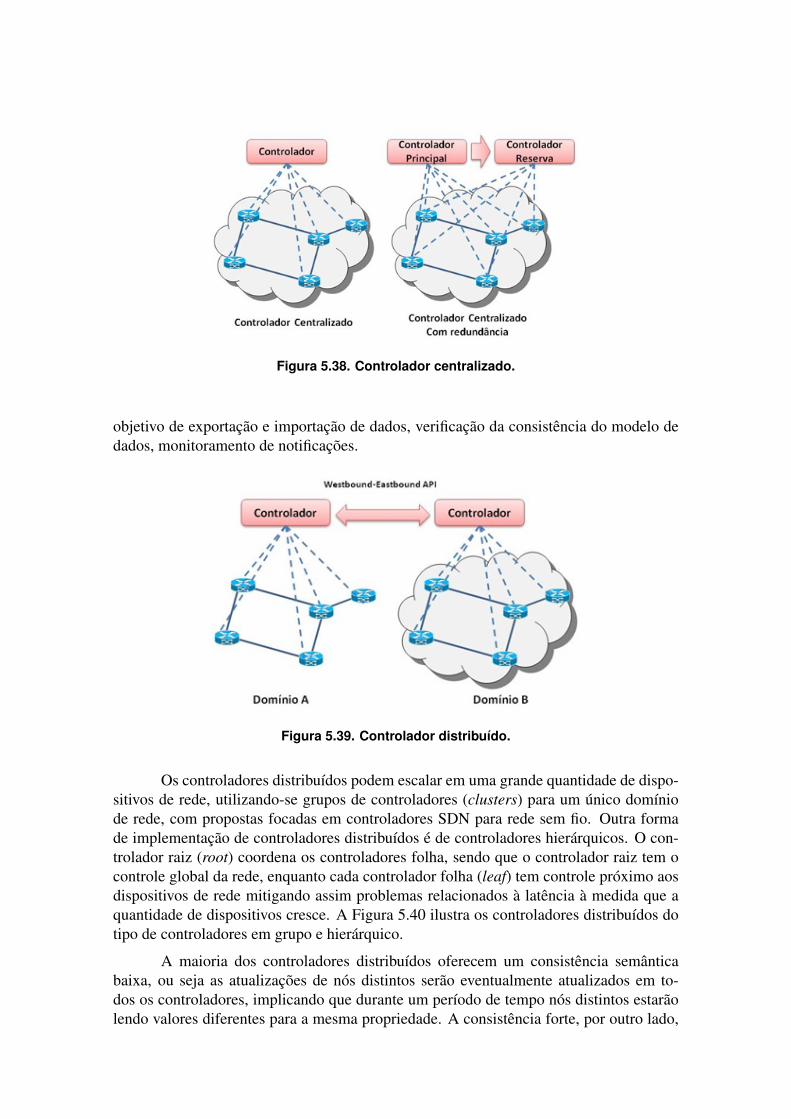
Figura 5.38. Controlador centralizado.
objetivo de exportação e importação de dados, verificação da consistência do modelo dedados, monitoramento de notificações.
Figura 5.39. Controlador distribuído.
Os controladores distribuídos podem escalar em uma grande quantidade de dispo-sitivos de rede, utilizando-se grupos de controladores (clusters) para um único domíniode rede, com propostas focadas em controladores SDN para rede sem fio. Outra formade implementação de controladores distribuídos é de controladores hierárquicos. O con-trolador raiz (root) coordena os controladores folha, sendo que o controlador raiz tem ocontrole global da rede, enquanto cada controlador folha (leaf) tem controle próximo aosdispositivos de rede mitigando assim problemas relacionados à latência à medida que aquantidade de dispositivos cresce. A Figura 5.40 ilustra os controladores distribuídos dotipo de controladores em grupo e hierárquico.
A maioria dos controladores distribuídos oferecem um consistência semânticabaixa, ou seja as atualizações de nós distintos serão eventualmente atualizados em to-dos os controladores, implicando que durante um período de tempo nós distintos estarãolendo valores diferentes para a mesma propriedade. A consistência forte, por outro lado,

Figura 5.40. Controlador distribuído em cluster e hieráquico.
assegura que todos os controladores terão a propriedade mais atualizada depois de umaoperação de escrita. Embora tenha impacto no desempenho do sistema, a consistênciaforte é uma aplicação simples de implementar pelo desenvolvedor. O controlador ONOSé um exemplo de consistência forte. Os controladores distribuídos são tolerantes a falha.Quando um nó controlador de rede falha outro nó vizinho assume as tarefas e dispositi-vos do nó controlador que falhou. Um controlador centralizado pode ser suficiente paragerenciar uma pequena rede, no entanto, representa um ponto de falha da rede. De formasimilar, controladores independentes podem ser espalhados na rede, e cada um controlaseu segmento de rede.
Atualmente existe um grande número de implementações de controladores SDNno mercado, incluindo controladores SDN de código aberto e controladores SDN co-merciais, de código aberto ou proprietário. Os controladores SDN de código aberto teminterfaces padrões, bem documentadas, não proprietárias. A premissa é ter interfacesnorthbound (NBI) e southbound (SBI) abertas para o controlador SDN permitindo pes-quisar métodos inovadores de operação da rede. Adicionalmente à pesquisa e experimen-tação, as interfaces abertas permitem que equipamentos de fabricantes diferentes possaminteroperar. A seguir são enumerados alguns controladores de código aberto e comerciais:
• VmWare/Nicira: Antes da aquisição da Nicira pela VMWare, a plataforma devirtualização (Network Virtualization Plataform-NVP), atualmente comercializadocomo VMware NSX foi considerada o modelo mais popular de SDN overlay, ba-seado em "Hypervisors"no mercado e empregado largamente em Datacenters. Aplatforma NVP utiliza o a switch virtual aberta (Open Virtual Switch - OVS) e oprotocolo OpenFlow como interface SBI.
• NOX/POX: controlador desenvolvido pela Nicira doado à comunidade, e desde2008, tornou-se um controlador de código aberto utilizando o protocolo OpenFlow1.0. Subsequentemente a pesquisa foi continuada pelo ON.LAB (Open NetworkingLab), desenvolvendo o controlador ONOS aplicado atualmente na indústria de equi-pamentos de redes de telecomunicações. O controlador NOX foi desenvolvido emC++ e carecendo de uma boa documentação e de um ambiente de desenvolvimento,não tendo sido implementado de forma massiva. O controlador POX foi o sucessordo NOX com ambiente de fácil desenvolvimento, com uma boa documentação eAPIs. Possui uma interface gráfica escrita na linguagem Python, que encurta osciclos de desenvolvimento e experimentação.
• Ryu: controlador desenvolvido pelo laboratório da NTT (Nippon Telegraph and Te-

lephone) com implementação em Python. O Ryu possui um serviço de mensagensde componentes implementadas em outras linguagens de programação, como porexemplo bibliotecas do protocolo OpenFlow, gerenciamento de aplicações, serviçosde infraestrutura e bibliotecas reutilizáveis como do protocolo NETCONF.
• Beacon: controlador bem escrito e organizado implementado em JAVA e integradoà IDE do Eclipse. O Beacon foi o primeiro controlador a criar um ambiente detrabalho de SDN, mas é limitado a topologia em estrela.
• Big Switch Networks/Floodlight: é uma ramificação do controlador Beacon. Nocomeço de sua implementação foi construído usando-se o Apache Ant, que é umferramenta de construção de software popular, tornando-o de fácil uso e flexível.O controlador Floodlight é muito ativo na comunidade com um grande númerode funcionalidades que podem ser adicionados para requisitos específicos de umaempresa. Possui uma interface gráfica baseada em JAVA, e a maioria de suas funci-onalidades está exposta em APIs REST.
• Opendaylight: é um projeto colaborativo da Linux Foundation suportado pelaCisco e diversas outras empresas. Tal como o Floodlight, o Opendaylight foi escritoem JAVA, com um excelente suporte. É orientado a API REST e interfaces gráficasWeb. A segunda "release"do Opendaylight, a versão Helium inclui suporte a SDN,NFV e tem propósito de escalar redes de grandes dimensões. Como o Floodlightpossui módulos plugáveis (interfaces, protocolos e aplicações) que podem ser uti-lizados de acordo com a necessidade da operadora. O controlador Opendaylight éum pouco diferente dos demais controladores por oferecer outros protocolos comosouthbound interfaces (SBI) além do OpenFlow, como o BGP e PCEP. Adicional-mente o Opendaylight tem interfaces com Openstack e Open vSwitch (OVSDB). OOpendaylight é baseado em uma arquitetura de microserviços, através do comparti-lhamento de estruturas de dados baseados em YANG para armazenamento de dadose troca de mensagens. Através de um modelo dirigido à camada de abstração de ser-viços (Model Driven Service Abstraction Layer - MD-SAL) qualquer aplicação oufunção pode ser agregada a um serviço e carregada pelo controlador. Possui suportemultiprotocolo. A Figura 5.42 mostra a plataforma do projeto Opendaylight.
• ONOS: controlador SDN voltado para Operadoras de Telecomunicações (CarrierGrade) projetado para alta disponibilidade, desempenho e escalabilidade através deinstâncias distribuídas que conferem redundância do controlador em caso de falhadeste. A Figura 5.43 mostra a arquitetura do controlador distribuído ONOS.
• Opencontrail: existem diversos controladores comerciais no mercado como o Open-contrail da Juniper, baseado no Apache 2.0, com foco em NFV, com API REST, nãopossuindo o mesmo suporte do Opendaylight.
• Outros controladores comerciais: existem diversos controladores comerciais ba-seados em software e em hardware, com soluções abertas e proprietárias. Algunsexemplos de controladores comerciais como o Brocade Vyatta, Cisco WAE (WANAutomation Engine) baseados em Opendaylight, com implementações próprias. OHP Virtual Application Networks (VAN) trabalha em conjunto com Openstack com

melhorias no controle do Open vSwitch, com suporte a diferentes tipos de “Hyper-visors”, suportando roteadores distribuídos. O Juniper Contrail é aplicado em redede operadoras de serviço em redes corporativas, provendo um plataforma de orques-tração e automação, como o Openstack, provendo virtualização da rede de switches,roteadores e serviços de rede, também implementando com OSS e BSS, provendofuncionalidades de NFV.
A Tabela 5.41 mostra um resumo comparativo de diferentes plataformas de con-troladores SDN de código aberto.
Figura 5.41. .
Figura 5.42. Plataforma do controlador Opendaylight.
5.3.3.3. Elemento de computação PCE
O PCE (Path Computation Element) é uma entidade que calcula caminhos da redebaseado em restrições (constraints) fornecidas a partir do comportamento dos roteadores,de um OSS (Operations Support System), ou ainda de outro PCE da rede. A arquiteturaPCE já possui um cálculo de caminho centralizado para grandes redes multidomínio e

Figura 5.43. Arquitetura do controlador ONOS.
multicamadas, sendo adequada como ferramenta do SDN. Quando um nó de rede neces-sita de um caminho para um determinado LSP, este faz uma requisição ao PCE através doprotocolo PCEP (Path Computation Element Protocol). O PCE tem acesso às informaçõesde topologia de um domínio inteiro da rede, utilizando estas informações para o cálculodos caminhos. A arquitetura do PCE é definida na RFC 4655, ilustrada na Figura 5.44.A principal função do PCE é resolver o problema de multidomínios, pois o PCE tem avisão da rede como um todo, e não apenas em um único domínio, construindo uma basede dados através destes múltiplos domínios. A sessão entre o PCC (Path ComputationClient) e o PCS (PCE Server) ou simplesmente PCE, é estabelecida sobre TCP, como oBGP. Uma vez a sessão estabelecida o PCE constrói a base de dados de topologia TED(Traffic Engineering Database) usando um IGP como OSPF ou IS-IS, ou ainda através doBGP-LS, este último possui estruturas TLV (Type-Length-value) que permitem ao PCEaprender ou construir esta base de dados. Quando o PCC solicita um LSP com certasrestrições (constraints) como por exemplo banda, custo e prioridade, o PCE calcula o ca-minho baseado na base de dados e responde com o caminho apropriado. Esta abordagemcentralizada que mantém a base de dados de topologia, ajuda no cálculo e no provisiona-mento do caminho, tem como benefícios aumentar o desempenho, flexibilidade e melhoruso dos recursos de rede.
O PCE pode ser classificado da seguinte forma ilustrados na Figura 3.23 :
• PCE de controle estático (Stateless PCE): tem habilidade reduzida para otimizarrecursos de rede, não possui conhecimento prévio dos caminhos pré-estabelecidos,é útil entre domínios do MPLS-TE, mas não é adequado para emprego em SDN.
• PCE de controle dinâmico (Stateful PCE): tem um controle do cálculo de caminhoótimo (por exemplo estado do LSP, recursos, políticas, análise de redes), habilita ainicialização de caminhos e atualizações de controle, requer sincronismo do estadosda base de dados dos LSPs (LSP Database).
O Stateful PCE, este pode ser passivo ou ativo :

Figura 5.44. Arquitetura do PCE.
• Stateful PCE passivo o PCC inicia a configuração do caminho, atualizando as infor-mações de controle, e o PCE aprende o estado do LSP para otimização do cálculodo caminho.
• Stateful PCE ativo, tanto o PCC quanto o PCE podem iniciar a configuração docaminho, mas a atualização do controle é feita pelo PCE, delegada pelo PCC. NoStateful PCE ativo o LSP pode ser iniciado pelo PCE, sendo mais integrado àsdemandas das aplicações, e o PCE pode fazer parte do controlador SDN determi-nando quando e quais caminhos a serão configurados. No Stateful PCE o LSP podeser iniciado no PCC baseado nos estados que estão distribuídos na rede e pode serusado em conjunto com os LSPs iniciados pelo PCE sendo uma abordagem de redehíbrida com controle IP/MPLS e SDN.
Figura 5.45. Tipos de PCE.
Existem basicamente quatro métodos para construir a base de dados através demultidomínios: cálculo de caminhos por domínio, cooperação entre PCEs, cálculo de ca-minhos de forma recursiva, PCE hierárquico utilizado em multicamada IP/Óptica. Umaproposta de SDN para o PCE é uma solução ideal para operadoras de telecomunicações,desacoplando o plano de controle do plano de encaminhamento de dados, e com mecanis-mos de controle centralizado que controlam a configuração dos caminhos. O PCE forneceum controle centralizado dos caminhos que são configurados para os fluxos de dados darede IP/MPLS. Empregando-se o PCE com as políticas apropriadas provenientes do OSS,

Figura 5.46. Stateless e Stateful PCE.
é a forma mais rápida e fácil para introduzir o SDN nas redes tradicionais IP/MPLS ede transporte da operadora de telecomunicações. Com o emprego de PCEs, as redes deroteadores de núcleo das operadoras de telecomunicações tem um ganho substancial dosbenefícios de roteamento intra-áreas, a customização do cálculo de caminhos, melhoriano desempenho da rede e a melhor utilização dos recursos.
Figura 5.47. Exemplo de PCE intradomínios.
5.3.3.4. Interfaces Northbound: REST, RESTFUL, NETCONF e outros
As interfaces Northbound (NBI) ainda são objeto de esforço de padronização epesquisa no sentido de padrões abertos que garantam a portabilidade e interoperabili-dade entre diferentes plataformas de controle. Alguns controladores como por exemploo Opendaylight e FloodLight propõem suas próprias NBIs. A API REST utiliza HTTP(Hypertext Transfer Protocol) ou HTTPS (Hyper Text Transfer Protocol Secure). A APIREST foi desenvolvida inicialmente para acessar informações de serviços WEB (WorldWide Web). O uso do REST em SDN se deve as seguintes vantagens:
• Simplicidade: o REST utiliza um mecanismo baseado em web que utilizam o proto-colo HTTP e os comandos GET, PUT, POST e DELETE. Para acesso aos dados queenvolvem recursos nos dispositivos de destino é utilizado o conhecido mecanismode código URL (Uniform Resource Locator).

• Flexibilidade: as entidades requisitantes acessam os componentes de configuraçãodefinidas em um dispositivo usando os recursos REST em URLs diferentes.Nãoexistem esquemas complexos ou base de gerenciamento de informações (Manage-ment Information Base – MBI) para tornar o dado acessível.
• Extensibilidade: suporte para novos recursos que não requer a recompilação deesquemas ou MIBs, mas somente a chamada da URL apropriada pela aplicação.
• Segurança: existem formas diretas de tornar segura a comunicação REST. Apli-cando o protocolo HTTPS os aspectos de segurança são resolvidos, e estão presen-tes na maioria das redes de computadores seguras, permitindo passar por Firewalls.A flexibilidade e entensibilidade podem representar um risco potencial do uso doREST pela falta de formalismo comparado a outros métodos, no entanto o custo ver-sus benefício da facilidade de uso e do controle estrito, tendem a indicar o RESTcomo uma API propícia para utilização em SDN. A API REST pode trabalhar comdiferentes formatos de arquivos como XML (Extensible Markup Language) e JSON(JavaScript Object Notation ). A seguir é mostrado um exemplo de uso API RESTpara o controlador Ryu para informar o estado das portas de um switch:
GET PORT STATSMétodo URI (Uniform Resource Identifier) : /stats/port/<dpid> , onde dpid é Datapath ID$ curl -X GET http://localhost:8080/stats/port/1 Resposta:
5.3.4. Plano de Gerenciamento
5.3.4.1. Aplicações de Rede e Linguagens de Programação
5.3.4.2. Roteamento com serviço: Routeflow e RCP
5.3.5. Esforços de Padronização
O cenário de padronização do SDN é amplo e está ainda sendo desenvolvido.Enquantoalguns esforços estão em consórcios da indústria e da comunidade como por exemploo Opendaylight, Openstack e OpenNFV (Open Network Function Virtualization) ofere-cendo resultados que podem ser candidatos a padrões de fato. A razão desta fragmentaçãoé devido ao fato que os conceitos de SDN se distribuem em diferentes áreas de tecnolo-gia da informação (TI) e de redes, também segmentando-se em redes de acesso, núcleo epor tecnologias como a IP/MPLS, Óptica e de Redes sem Fio (Wireless). A ONF (OpenNetwork Foudantion) é uma organização criada para promover a adoção do SDN atra-vés do desenvolvimento do protocolo OpenFlow com padrão aberto de comunicação dedecisão do plano de controle do controlador com o plano de encaminhamento de dadosdos dispositivos de rede físicos. A ONF possui vários grupos de trabalho definindo asextensões do protocolo OpenFlow para transporte óptico, redes sem fio e redes móveis. AONF além das extensões do protocolo OpenFlow define componentes da arquitetura SDNe suas interfaces, as NI para controladores SDN, especificação de testes de conformidadeem SDN, além da disseminação do conhecimento através de publicações. O Internet TaskForce (IETF) desenvolveu diversos grupos considerando a influência de redes programá-

veis na evolução da internet como o protocolo SBI Network Configuration (NETCONF),especificação de protocolos entre o plano de controle e de encaminhamento de dados(Fowarding and Control Element Separation - ForCES), interoperabilidade do protocoloOpenFlow e casos de uso de SDN através do grupo SPRING (Source Packet Routing inNetworking), que está especificando as RFCs (Request for Comments) para o roteamentopor segmentos. A União Internacional de Telecomunicações (International Telecommu-nications Union - ITU-T) já iniciou atividades de emissão de recomendações através degrupos de estudo (Study Groups - SG) para uso de SDN em redes de acesso banda largae de rede de transporte óptica, requisitos funcionais e de arquitetura SDN e aspectos desegurança. O Broadband Fórum (BBF) trabalha em tópicos de inovação de serviços e re-quisitos de mercado para o SDN e o Metro Ethernet Fórum (MEF) cujo objetivo é definira oequestração dos serviços com APIs para redes existentes. O IEEE o comitê 802 iniciourecentemente atividades para padronização do plano de controle com SDN em redes 802,através de novas interfaces de controle. O Optical Internetworking Forum (OIF) lançouum grupo de trabalho para definição de um conjunto de requisitos de redes de transporteem SDN. O Instituto de Padrões de Telecomunicações Europeu (European Telecommuni-cation Standards Institute - ETSI) tem esforços direcionados para virtualização de funçõesde rede (Network Function Virtualization - NFV) através da definição de uma arquiteturapara orquestração de funções de rede, incluindo o controle da computação, armazena-mento e recursos de rede.O ETSI está empenhado em um grupo da indústria (IndustrySpecification Group - ISG) para acelerar a introdução do NFV (Network Function Vir-tualization) [6] e redes definidas por software, considerados conceitos complementares[8].
5.3.6. Casos de Uso
As redes de núcleo TCP/IP sobre MPLS apresentam grande complexidade de con-figuração devido aos inúmeros protocolos envolvidos, bem como a falta de flexibilidadeem resposta a mudanças da rede, falhas e balanceamento de tráfego. As Redes Definidaspor Software (SDN) constituem uma mudança de paradigma em redes de computadoresque rompe a integração vertical da rede, separando o plano de controle do plano de enca-minhamento de dados de roteadores e comutadores. Essa separação promove a centrali-zação do controle da rede, introduzindo assim a capacidade de programação e uma maiorflexibilidade de utilização. O controle da rede é visto como módulos de fácil manuseio,simplificando a criação e introdução de novas abstrações de rede [Kreutz et al., 2015]. Osconceitos de redes definidas por software são importantes para a compreensão do rotea-mento por segmentos, visto que o roteamento por segmentos é uma aplicação SDN. Estaseção, portanto, apresenta os conceitos de SDN que serão utilizados na seção seguintepara a apresentação do roteamento por segmentos.
–termina aqui.
Em uma visão simplificada da arquitetura de rede SDN, a infraestrutura física éformada pelos dispositivos de encaminhamento de pacotes, como por exemplo comuta-dores ou outros dispositivos como roteadores sem o plano de controle ou com o planode controle reduzido. O controlador SDN, corresponde ao sistema operacional de rede,sendo um elemento crítico na arquitetura de redes definidas por software. Os controla-dores SDN podem ser centralizados ou distribuídos, fornecendo serviços básicos de rede

como o estado da rede e sua topologia, caminhos mais curtos e interfaces de programa-ção de aplicações. Tais interfaces podem ser usadas tanto para acessar os dispositivos dainfraestrutura física quanto para simplificar a programação de aplicações de rede. Grandeparte dos controladores utilizam o OpenFlow como interface de programação de aplica-ção, sendo o ONOS e o OpenDaylight os controladores distribuídos adotados pela indús-tria [Kreutz et al., 2015]
O controlador SDN e as aplicações de rede podem ser instalados ou não em umainfraestrutura virtualizada de computação através de máquinas virtuais (Virtual Machine- VM). Um hipervisor permite que máquinas virtuais compartilhem o mesmo substratofísico. Dessa forma. é possível criar, remover e movimentar as máquinas virtuais doscontroladores SDN e das aplicações de rede de forma flexível, elástica e com fácil geren-ciamento. Toda essa liberdade é interessante para as operadoras visto que tanto o controlequanto as aplicações podem ser disponibilizadas em uma nuvem IaaS (Infrastructure asa Service) [Matias et al., 2015].
A separação entre o plano de encaminhamento de dados é realizada através deuma interface padronizada de programação de aplicação API, denominada SouthboundInterfaces, e essas interfaces podem ser abertas como o protocolo OpenFlow, NETCONF,BGP-LS (Border Gateway Protocol-Link State), PCEP (Path Computation Element Com-munication Protocol), OVSDB (Open vSwitch Database) e CLI (Command Line Inter-face) [Rowshanrad et al., 2014]. Ainda na visão simplificada da arquitetura de rede SDN,a plataforma de controle se comunica com as aplicações de rede através de interfacespadronizadas denominadas Northbound Interfaces, que oferece uma API para desenvol-vedores de aplicação, a API Restful e RESTCONF e linguagens de programação comJava, Python, C e C++ [Xia et al., 2015]. Dentre as aplicações de rede, destacam-se osbalanceadores de carga, a lista de acesso para segurança, a detecção de ataques, o moni-toramento da rede, a virtualização da rede e os protocolos de roteamento, neste último seencaixa o roteamento.
5.4. Roteamento por Segmentos (23 páginas)1. Conceitos preliminares
2. Plano de dados: MPLS e IPv6
3. Bloco Global de Roteamento por Segmentos (SRGB)
4. Plano de controle IGP: IS-IS e OSPF
5. Coexistência do Roteamento por Segmentos e LDP
6. Servidor de Mapeamento
7. Mecanismo de proteção - Topology Independent LFA (TI-LFA)
8. Padronização IETF
O roteamento por segmentos (Segment Routing – SR) define um protocolo deroteamento programado como uma aplicação de redes definidas por software. O ro-teamento por segmentos aumenta o desempenho do encaminhamento de pacotes sem

a necessidade de manutenção de estados por fluxo na rede de núcleo das operadoras.Dessa forma, o roteamento por segmentos reduz a complexidade do plano de controlee de dados. A partir do roteamento por segmentos, um caminho pode ser determinadoatravés de uma lista ordenada de funções de processamento e encaminhamento, que po-dem consistir não somente de roteadores e enlaces, mas também de um filtro de paco-tes [Bhatia et al., 2015]. A cadeia desses segmentos é chamada de Caminho de Rotea-mento por Segmentos (Segment Routing Path – SR path), identificado por uma Lista deIdentificadores de Segmento (Segment Routing Identifiers – SID), que pode ser globalou local. O roteamento por segmentos baseia-se no conceito de roteamento pela fonte,pois a lista de SIDs que especifica a informação do caminho é inserida no pacote na ori-gem através de extensões do cabeçalho do protocolo IPv6 [SPRING, 2015] ou por rótulosdo protocolo MPLS [SPRING, 2015]. O protocolo de roteamento intra-domínio (IGP)passa a atuar baseado em segmentos, através de extensões do OSPF ou do protocolo deroteamento IS-IS (Intermediate System to Intermediate System). A lista de SIDs é in-serida somente no roteador de borda de um domínio de roteamento por segmentos e oestado de cada fluxo é mantido apenas nos nós da borda, onde ocorre o ingresso do trá-fego [SPRING, 2015].
Os segmentos podem ser divididos em Segmentos de Nó e Segmentos de Adjacên-cia. O primeiro tem uma numeração global (Segment Routing Global Block – SRGB) [Sgambelluri et al., 2015b]dentro do domínio IGP, identificando de forma única o nó. Já o segundo tem significadolocal e está relacionado a uma ou mais adjacências. Os segmentos de nó são usadospelo IGP para o cálculo do menor caminho para qualquer outro nó da rede, enquanto osegmento de adjacências é encaminhado através dos nós adjacentes do IGP. Extensõessimples no IGP permitem construir e manter a lista de segmentos. O caminho é formadopor uma lista de segmentos que combina segmentos de nó e de adjacência, permitindoconduzir o tráfego em qualquer caminho da rede, não necessitando de sinalizações ouestados por fluxo de dados. A base de dados de encaminhamento de pacotes (ForwardInformation Base – FIB) tem complexidade O(N +A), onde N é o número de segmen-tos de nó e A o número de segmentos de adjacência. Em outras palavras, o tamanho dabase de dados deixa de ser uma função do número de túneis e passa ser função do nú-mero de segmentos de nó e de adjacência. Como consequência, a quantidade de túneisna rede de núcleo das operadoras pode aumentar. O uso de segmentos de nó e de adja-cência, combinados ou não, permitem o controlador SDN calcular o melhor caminho emfunção de métricas específicas ditadas por uma aplicação de rede, podendo ser alteradamais facilmente [Sgambelluri et al., 2015b]. A engenharia de tráfego é um exemplo deaplicação no contexto de roteamento por segmentos. O roteamento por segmentos per-mite a configuração, a modificação e a remoção de caminhos TE dentro de um domíniode rede [Davoli et al., 2015], operando somente na borda da rede. O plano de controle deroteamento por segmentos pode ser mantido de forma centralizada ou distribuída.
Em redes IP/MPLS, o protocolo LDP e RSVP-TE não são mais utilizados, sim-plificando a rede. O IETF vem trabalhando na elaboração de normas para padronizara interoperabilidade de redes IP/MPLS com roteamento por segmentos e o protocoloLDP [SPRING, 2015], permitindo a coexistência das redes legadas tradicionais IP/MPLScom roteamento por segmentos. Tais propostas visam a integração e a interoperabilidadedo protocolo LDP com o roteamento por segmentos, ou até mesmo, a migração de redes

IP/MPLS com LDP para roteamento por segmentos. O Servidor de Mapeamento (Map-ping Server) é usado para promover a interoperabilidade entre nós que executam e quenão executam o roteamento por segmentos. Os prefixos de rede e SIDs são mapeados noServidor de Mapeamento, de forma similar ao Refletor de Rotas (Router Reflector – RR).
O mecanismo de proteção Topology Independent Loop Free Alternate (TI-LFA) éuma técnica eficiente e simples de desvio para rota alternativa (reroteamento) com con-vergência menor que 50 ms. O LFA clássico em redes IP/MPLS depende da topologia,nem sempre provendo o melhor caminho de proteção, enquanto o TI-LFA previne decongestionamentos transientes e roteamento de proteção sub-ótimo.
A padronização de roteamento por segmentos está sendo conduzida pelo IETF,no grupo de trabalho SPRING (Source Packet Routing In NetworkinG), através de docu-mentos ainda em fase de padronização (Request For Comments em versão “draft”). Essesdocumentos focam sobretudo na arquitetura, casos de uso e extensões dos protocolos IS-IS, OSPF, BGP e IPv6 para roteamento por segmentos [SPRING, 2015].
5.4.1. Experimentação Prática (5 páginas)
1. Introdução do Mininet
2. Construção de uma rede OSPF no Mininet
3. Open Source Hybrid IP/SDN (OSHI)
4. Construção de uma rede MPLS com o OSHI–SRTE
A seção de experimentação prática utiliza a ferramenta de simulação OSHI-OpenSource Hybrid IP/SDN networking [Salsano et al., 2014a, Salsano et al., 2014b], desen-volvida pelo o Projeto Dreamer da GÉANT, que representa a Rede de Pesquisa e Edu-cação Pan-Européia, interconectando os centros de pesquisa e de educação da Europa.A ferramenta foi desenvolvida com o objetivo de investigar e prototipar redes definidaspor software baseadas em protocolo OpenFlow, podendo ainda prover as mesmas funci-onalidades que as redes IP/MPLS [OSHI, 2015]. A ideia foi desenvolver um simuladorque permita o trabalho com nós de redes virtuais e reais, com implementação de softwareaberto em IP e SDN. A interface southbound com o controlador SDN é OpenFlow, e asinterfaces northbound com o servidor de gerenciamento são APIs REST. O tráfego é envi-ado em vários tipos de túneis tais como MPLS, VLAN, Q-in-Q e Ethernet PBB (ProviderBackbone Bridge), através do controlador SDN. O sistema operacional de rede escolhidofoi o ONOS, desenvolvido pelo ON.LAB (Open Networking Lab) [Kreutz et al., 2015].O simulador de rede híbrida IP/SDN possui três formas de implementação: no VirtualBox “run time”, no ambiente de simulação do Mininet [Mininet, 2015] e em provas deconceito de redes SDN como no projeto OFELIA (OpenFlow in Europe: Linking In-frastructure and Applications). Essa alternativa aplica o conceito de experimento comoserviço (testbed as a service) [SPRING, 2015]. Nesta seção, a segunda opção com oemulador Mininet é utilizada [OSHI e Mininet, 2015].
O simulador utiliza nós virtuais de rede de núcleo denominados Roteadores deNúcleo em software aberto (Open Source Label Switch Routers – OpenLSR), que ge-ram pacotes OSPF e LDP utilizando o Quagga. Este último computa os rótulos MPLS

que são instalados nos computadores usando o protocolo OpenFlow. O controlador SDNtambém possui um módulo de software para engenharia de tráfego e roteamento por seg-mentos [SPRING, 2015].
5.5. Considerações Finais e Direções Futuras (2 páginas)O roteamento por segmentos tende futuramente a ser aplicado em redes de trans-
porte óptica com GMPLS (Generalized MPLS) [Sgambelluri et al., 2015a, Cai et al., 2014,Bidkar et al., 2014], que utilizam instâncias hierárquicas de sessões de sinalizações. Taissessões de sinalização devem ser estabelecidas também nos nós de trânsito da rede detransporte óptica tendo como consequência uma complexa implementação do plano decontrole. O roteamento por segmentos tem grande potencial de integração entre as ca-madas de rede de transporte óptica e de roteadores de núcleo, permitindo a convergênciaIP e óptica, o que proporciona benefícios para a operadora de telecomunicações como ouso racional e otimizado da capacidade da rede, com proteção e restauração de acordosde níveis de serviço (Service Level Agreement – SLA) diferenciados por fluxo de dados.
Referências[Alvarez, 2016] Alvarez, S. (2016). Brkmpl-2100 - deploying mpls traffic engineering
(2013 orlando). Acessado em fev/2016 https://www.ciscolive.com/online/connect/sessionDetail.ww?SESSION_ID=7818&backBtn=true.
[Asati, 2012] Asati, R. (2012). Brkipm-2017 - designing ip/mpls vpn networks (2012london). Acessado em fev/2016 https://www.ciscolive.com/online/connect/sessionDetail.ww?SESSION_ID=2636&backBtn=true.
[Bhatia et al., 2015] Bhatia, R., Hao, F., Kodialam, M. e Lakshman, T. (2015). Optimizednetwork traffic engineering using segment routing. Em IEEE Conference on ComputerCommunications (INFOCOM), p. 657–665.
[Bidkar et al., 2014] Bidkar, S., Gumaste, A., Ghodasara, P., Hote, S., Kushwaha, A.,Patil, G., Sonnis, S., Ambasta, R., , Nayak, B. e Agrawal, P. (2014). Field trial of asoftware defined network (SDN) using carrier ethernet and segment routing in a tier-1provider. Em IEEE Global Communications Conference (GLOBECOM), p. 2166–2172.
[Cai et al., 2014] Cai, D., Wielosz, A. e Wei, S. (2014). Evolve Carrier Ethernet archi-tecture with SDN and segment routing. Em IEEE International Symposium on a Worldof Wireless, Mobile and Multimedia Networks (WoWMoM), p. 1–6.
[Cisco, 2001] Cisco (2001). Implementing mpls traffic engineering. Acessado emfev/2016 http://www.cisco.com/c/en/us/td/docs/routers/crs/software/crs_r3-9/mpls/configuration/guide/gc39crs1book_chapter4.html.
[Davoli et al., 2015] Davoli, L., Veltri, L., Ventre, P. L., Siracusano, G. e Salsano, S.(2015). Traffic engineering with segment routing: SDN-based architectural design and

open source implementation. Em European Workshop on Software Defined Networks(EWSDN), p. 111–112.
[De Ghein, 2007] De Ghein, L. (2007). MPLS fundamentals - a comprehensive introduc-tion to MPLSnnn theory and practice. Em MPLS Fundamentals - A ComprehensiveIntroduction to MPLS Theory and Practice, p. 4–322.
[documents, 2001] documents, I. M. (2001). Mpls ietf wg. Acessado em fev/2016https://datatracker.ietf.org/wg/mpls/documents/.
[El-Sayed e Jaffe, 2002] El-Sayed, M. e Jaffe, J. (2002). A view of telecommunicationsnetwork evolution. IEEE Communications Magazine, 40:74–81.
[Guichard, 2003] Guichard, J., P. (2003). Mpls and vpn architectures. Em MPLS andVPN Architectures, p. 139–382.
[Hodzic e Zoric, 2008] Hodzic, H. e Zoric, S. (2008). Traffic engineering with constraintbased routing in MPLS networks. Em International Symposium ELMAR, p. 269–272.
[Kreutz et al., 2015] Kreutz, D., Ramos, F. M. V., Veríssimo, P. E., Rothenberg, C. E.,Azodolmolky, S. e Uhlig, S. (2015). Software-defined networking: A comprehensivesurvey. Proceedings of the IEEE, 103:14–76.
[Marzo et al., 2003] Marzo, J. L., Calle, E., Scoglio, C. e Anjah, T. (2003). QoS onlinerouting and MPLS multilevel protection: a survey. IEEE Communications Magazine,41:126–132.
[Matias et al., 2015] Matias, J., Garay, J., Toledo, N., Unzilla, J. e Jacob, E. (2015).Toward an SDN-enabled NFV architecture. IEEE Communications Magazine, 53:187–193.
[Mininet, 2015] Mininet (2015). Mininet tutorial. Aces-sado em https://github.com/mininet/mininet/wiki/Teaching-and-Learning-with-Mininet.
[OSHI, 2015] OSHI (2015). OSHI - Open Source Hybrid IP/SDN tutorial. Acessado emhttp://netgroup.uniroma2.it/OSHI.
[OSHI e Mininet, 2015] OSHI e Mininet (2015). OSHI - Open Source HybridIP/SDN networking and its emulation on Mininet and on distributed SDN test-beds. Acessado em htttp://netgroup.uniroma2.it/twiki/bin/view/Oshi/WebHome\#AnchorSegRouting.
[Rose, 2014] Rose, E. (2014). Brkmpl-1101 - understanding mpls (2014 melbourne).Acessado em fev/2016 https://www.ciscolive.com/online/connect/sessionDetail.ww?SESSION_ID=77795&backBtn=true.
[Rowshanrad et al., 2014] Rowshanrad, S., Namvarasl, S., Abdi, V., Hajizadeh, M. eKeshtgary, M. (2014). A survey on SDN, the future of networking. Journal of Ad-vanced Computer Science & Technology, 3:232–248.

[Sadok D.; Kamienski, 2000] Sadok D.; Kamienski, C. A. (2000). Qualidade de serviçona internet, minicurso, in xviil sbrc. Em (Simpósio Brasileiro de Redes de Computa-dores), Belo Horizonte. Brasil, 2000, p. 4–44.
[Salsano et al., 2014a] Salsano, S., Ventre, P. L., Prete, L., Siracusano, G., Gerola, M.e Salvadori, E. (2014a). OSHI - Open Source Hybrid IP/SDN networking (and itsemulation on mininet and on distributed SDN testbeds). Em European Workshop onSoftware Defined Networks (EWSDN), p. 13–18.
[Salsano et al., 2014b] Salsano, S., Ventre, P. L., Prete, L., Siracusano, G., Gerola, M.,Salvadori, E., Santuari, M., Campanella, M. e Prete, L. (2014b). OSHI - Open SourceHybrid IP/SDN networking and Mantoo - Management tools for SDN experiments.Em European Workshop on Software Defined Networks (EWSDN), p. 123–124.
[Santos, 2007] Santos, Christiane Borges, F. D. C. M. B. R. B. (2007). Tutori-ais teleco mpls: Re-roteamento dinâmico em redes ip utilizando network simu-lator. Acessado em fev/2016 http://www.teleco.com.br/tutoriais/tutorialmplsrd/default.asp.
[Sgambelluri et al., 2015a] Sgambelluri, A., Paolucci, F., Giorgetti, A., Cugini, F. eCastoldi, P. (2015a). Experimental demonstration of segment routing. Journal ofLightwave Technology, p. 1–1.
[Sgambelluri et al., 2015b] Sgambelluri, A., Paolucci, F., Giorgetti, A., Cugini, F. e Cas-toldi, P. (2015b). SDN and PCE implementations for segment routing. Em EuropeanConference on Networks and Optical Communications (NOC), p. 1–4.
[Simha, 2002] Simha, E. (2002). Traffic engineering with mpls. Em Traffic Engineeringwith MPLS, p. 139–382.
[SPRING, 2015] SPRING (2015). Source packet routing in networking(SPRING). Acessado em https://datatracker.ietf.org/wg/spring/documents/.
[Xia et al., 2015] Xia, W., Wen, Y., Foh, C., Niyto, D. e Xie, H. (2015). A survey onsoftware-defined networking. IEEE Communications Surveys & Tutorials, 17:27–51.
[Xipeng Xiao, 2000] Xipeng Xiao, Alan Hannan, B. B. L. M. N. (2000). Traffic engine-ering with mpls in the internet. IEEE Network, p. 1–1.





























