Embed Size (px)
Citation preview

RICE UNIVERSITY
High performance, power-efficient DSPsbased on the TI C64x
Sridhar Rajagopal, Joseph R. Cavallaro, Scott RixnerRice University
{sridhar,cavallar,rixner}@rice.edu

2RICE UNIVERSITY
Recent (2003) Research Results
Stream-based programmable processors meet real-time requirements for a set of base-station phy layer algorithms+,*
Map algorithms on stream processors and studied tradeoffs between packing, ALU utilization and memory operations
Improve power efficiency in stream processors by adapting compute resources to workload variations and varying voltage and clock frequency to real-time requirements*
Design exploration between #ALUs and clock frequency to minimize power consumption of the processor
+ S. Rajagopal, S. Rixner, J. R. Cavallaro 'A programmable baseband processor design for software defined radios’, 2002, *Paper draft sent previously, rest of the contributions in thesis

3RICE UNIVERSITY
Recent (2003) Research Results
Peak computation rate available : ~200 billion arithmetic operations at 1.2 GHz
Estimated Peak Power (0.13 micron) : 12.38 W at 1.2 GHz
Power:
12.38 W for 32 users, constraint 9 decoding, at 128Kbps/user
At 1.2 GHz, 1.4 V
300 mW for 4 users, constraint 7 decoding, at 128Kbps/user
At 433 MHz, 0.875 V

4RICE UNIVERSITY
Motivation
This research could be applied to DSP design!
Designing High performance DSPsPower-efficientAdapt computing resources with workload changes
Such thatGradual changes in C64x architectureGradual changes in compilers and tools

5RICE UNIVERSITY
Levels of changes
To allow changes in TI DSPs and tools gradually
Changes classified into 3 levelsLevel 1 : simple, minimum changes (next silicon)Level 2 : intermediate, handover changes (1-2 years)Level 3 : actual proposed changes (2-3 years)
We want to go to Level 3 but in steps!
6RICE UNIVERSITY
Level 1 changes:Power-efficiency

7RICE UNIVERSITY
Level 1 changes: Power saving features
(1) Use Dynamic Voltage and Frequency scalingWhen workload changes such asUsers, data rates, modulation, coding rates, …Already in industry : Crusoe, XScale …
(2) Use Voltage gating to turn off unused resourcesWhen units idle for a ‘sufficiently’ long timeSaves static and dynamic power dissipationSee example on next page
8RICE UNIVERSITY
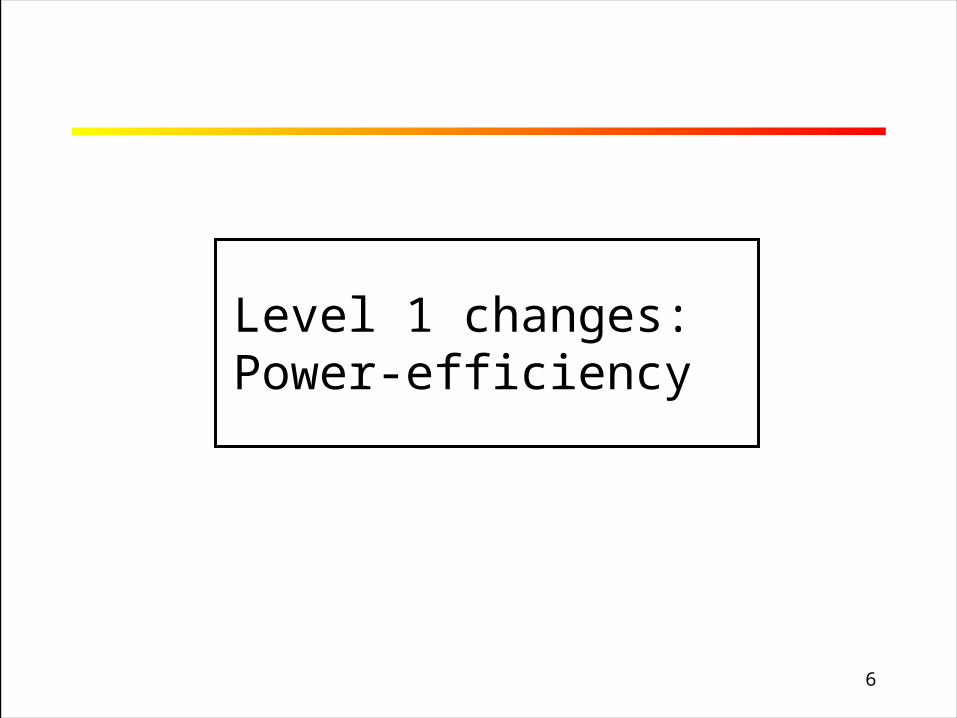
Turning off ALUs
Adders Multipliers Adders Multipliers
Default schedule Schedule after exploration
Inst
ruct
ion
Sch
edul
e
‘Sle
ep’ I
nstr
uctio
n2 multipliers turned off to save power
Turned off using voltage gating toeliminate static anddynamic power dissipation

9RICE UNIVERSITY
Level 1: Architecture tradeoffs
DVS: Advanced voltage regulation scheme Cannot use NMOS pass gates Cannot use tri-state buffers Use at a coarser time scale (once in a million cycles)
100-1000 cycles settling time
Voltage gating: Gating device design important Should be able to supply current to gated circuit Use at coarser time scale (once in 100-1000 cycles)
1-10 cycles settling time

10RICE UNIVERSITY
Level 1: Tools/Programming impact
Need a DSP BIOS “TASK” running continuously which looks at the workload change and changes voltage/frequency using a look-up table in memory
Compiler should be made ‘re-targetable’ Target subset of ALUs and explore static
performance with different adder-multiplier schedules
Voltage gating using a ‘sleep’ instruction that the compiler generates for unused ALUs
ALUs should be idle for > 100 cycles for this to occurOther resources can be gated off similarly to save
static power dissipation
Programmer is not aware of these changes
11RICE UNIVERSITY
Level 2 changes:Performance

12RICE UNIVERSITY
Solutions to increase DSP performance
(1) Increasing clock frequencyC64x: 600 – 720 – 1000 - ?Easiest solution but limited benefitsNot good for power, given cubic dependence with
frequency
(2) Increasing ALUsLimited instruction level parallelism (ILP)Register file area, ports explosionCompiler issues in extracting more ILP
(3) Multiprocessors (MIMD)Usually 3rd party vendors (except C40-types)
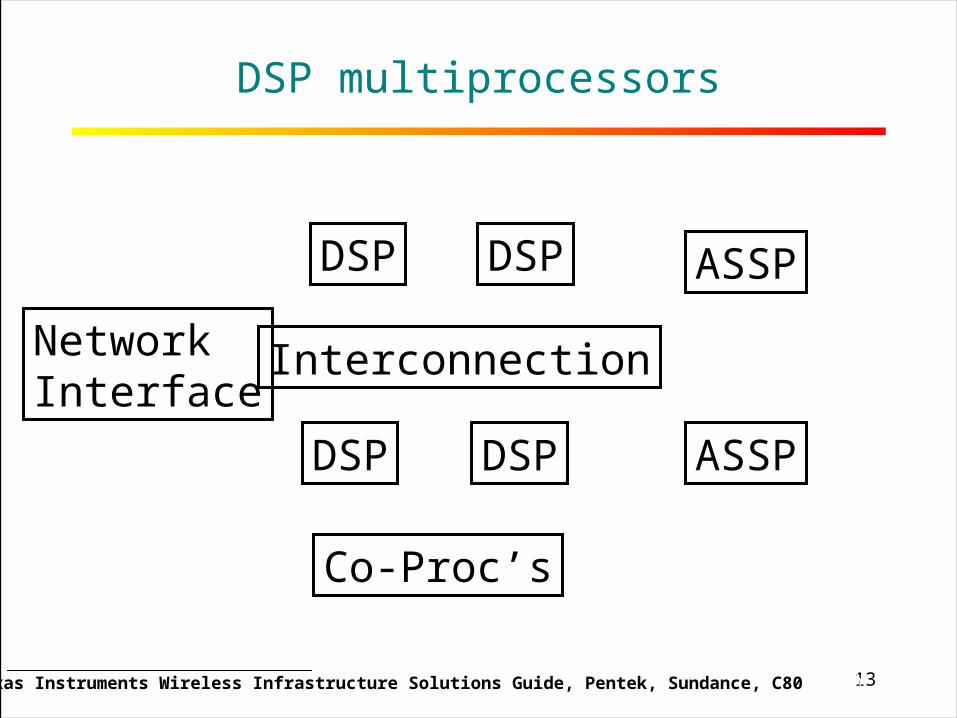
13RICE UNIVERSITY
DSP multiprocessors
Source: Texas Instruments Wireless Infrastructure Solutions Guide, Pentek, Sundance, C80
DSP
DSP
DSP
DSP
ASSP
ASSP
Co-Proc’s
NetworkInterface
Interconnection

14RICE UNIVERSITY
Multiprocessing tradeoffs
Advantages:Performance, and tools don’t have to change!!
Load-balancing algorithms on multiple DSPs not straight-forward+
Burden pushed on to the programmerNot scalable with number of processorsdifficult to adapt with workload changes
Traditional DSPs not built for multiprocessing* (except C40-types) I/O impacts throughput, power and area (E)DMA use minimizes the throughput problem Power and area problems still remain
*R. Baines, The DSP bottleneck, IEEE Communications Magazine, May 1995, pp 46-54 (outdated?)+S. Rajagopal, B. Jones and J.R. Cavallaro, Task partitioning wireless base-station algorithms on multiple DSPs and FPGAs, ICSPAT’2001

15RICE UNIVERSITY
Options
Chip multiprocessors with SIMD parallelism (Level 3)SIMD parallelism can alleviate load balancing (shown in Level 3)Scalable with processorsAutomatic SIMD parallelism can be done by the compilerSingle chip will alleviate I/O bottlenecksTool will need changes
To get to level 3, intermediate (Level 2) level investigation
Level 2 Do SPMD on DSP multiprocessor
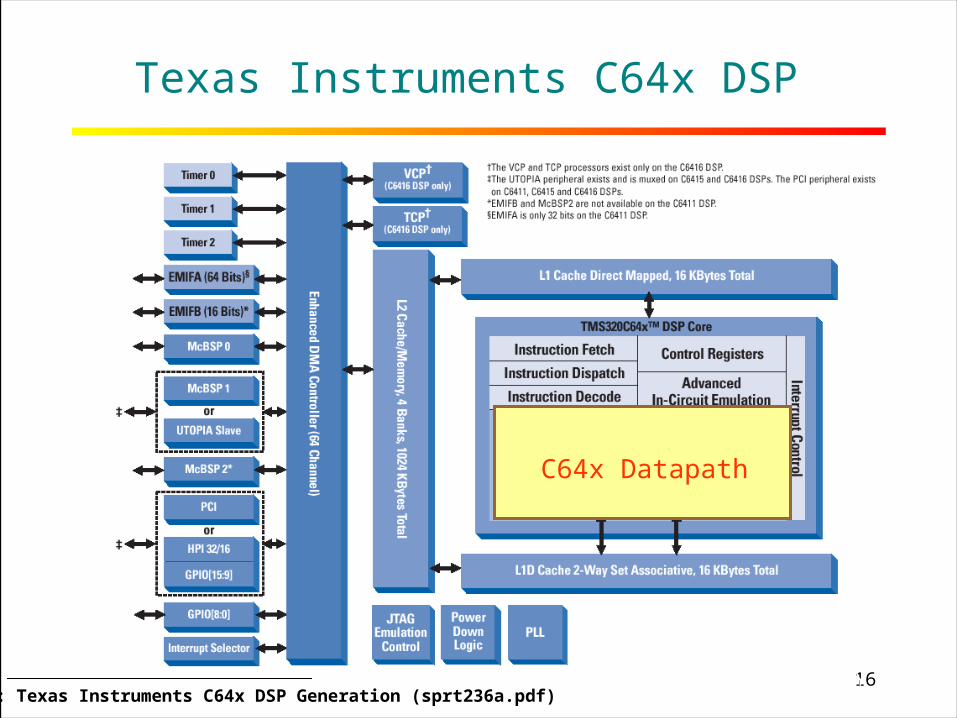
16RICE UNIVERSITY
Texas Instruments C64x DSP
Source: Texas Instruments C64x DSP Generation (sprt236a.pdf)
C64x Datapath

17RICE UNIVERSITY
A possible, plausible solution
Exploit data parallelism (DP)*Available in many wireless algorithmsThis is what ASICs do!
int i,a[N],b[N],sum[N]; // 32 bitsshort int c[N],d[N],diff[N]; // 16 bits packed
for (i = 0; i< 1024; ++i)
{
sum[i] = a[i] + b[i];
diff[i] = c[i] - d[i];
}
ILP
DP
Subword *Data Parallelism is defined as the parallelism available after subword packing and loop unrolling
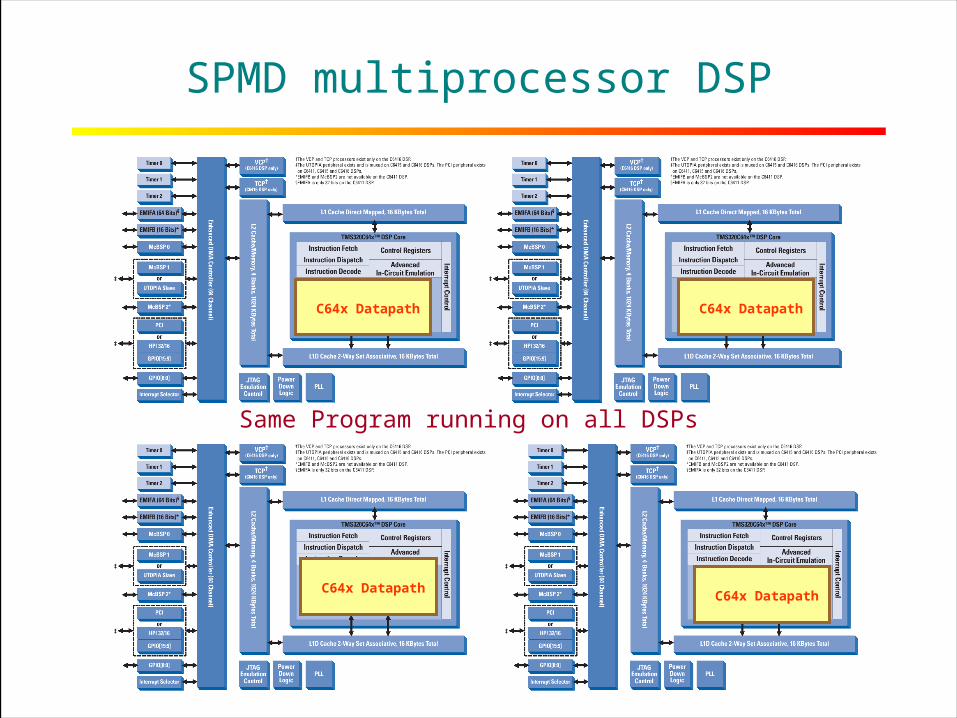
18RICE UNIVERSITY
SPMD multiprocessor DSP
C64x Datapath
C64x Datapath
C64x Datapath
C64x Datapath
Same Program running on all DSPs

19RICE UNIVERSITY
Level 2: Architecture tradeoffs
C64x’s
Interconnection could be similar to the ones used by 3rd party vendorsFPGA- based C40 comm ports (Sundance) ~400
MBpsVIM modules (Pentek) ~300 MBpsOthers developed by TI, BlueWave systems

20RICE UNIVERSITY
Level 2: Tools/Programming impact
All DSPs run the same program
Programmer thinks of only 1 DSP programBurden now on tools
Can use C8x compiler and tool support expertise Integration of C8x and C6x compilersData parallelism used for SPMDDMA data movement can be left to programmer at
this stage to keep data fed to the all the processors
MPI (Message Passing) can also be alternatively applied

21RICE UNIVERSITY
Level 3 changes:Performance and Power
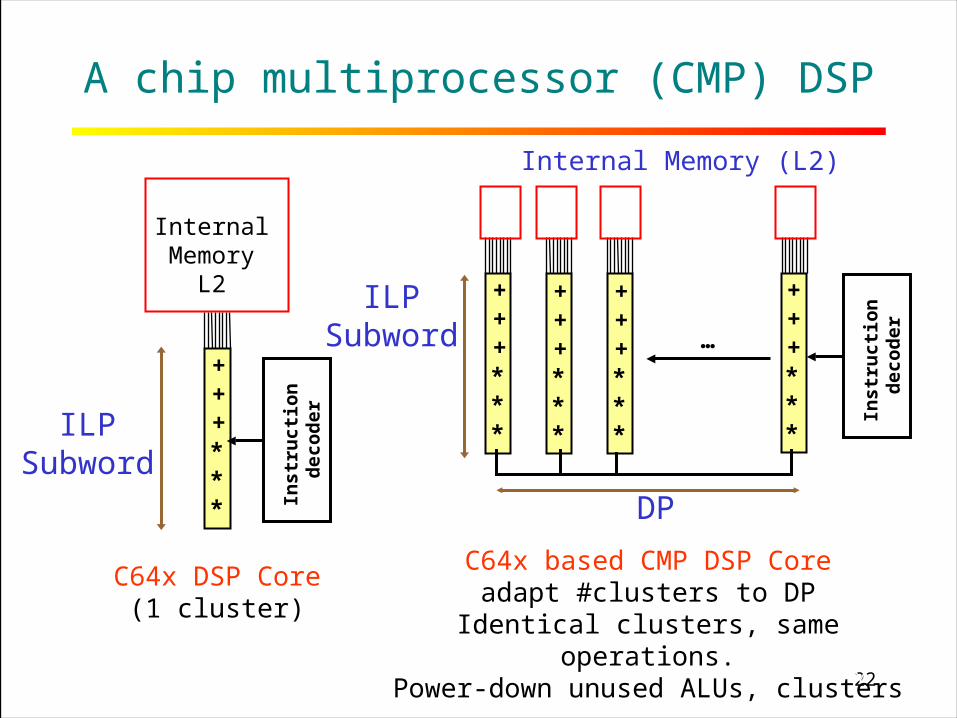
22RICE UNIVERSITY
A chip multiprocessor (CMP) DSP
+++***
InternalMemory
L2
ILPSubword
Internal Memory (L2)
C64x DSP Core(1 cluster)
+++***
+++***
+++***
+++***
…
ILPSubword
DP
C64x based CMP DSP Coreadapt #clusters to DP
Identical clusters, same operations.Power-down unused ALUs, clusters
Inst
ruct
ion
d
eco
der
Inst
ruct
ion
d
eco
der
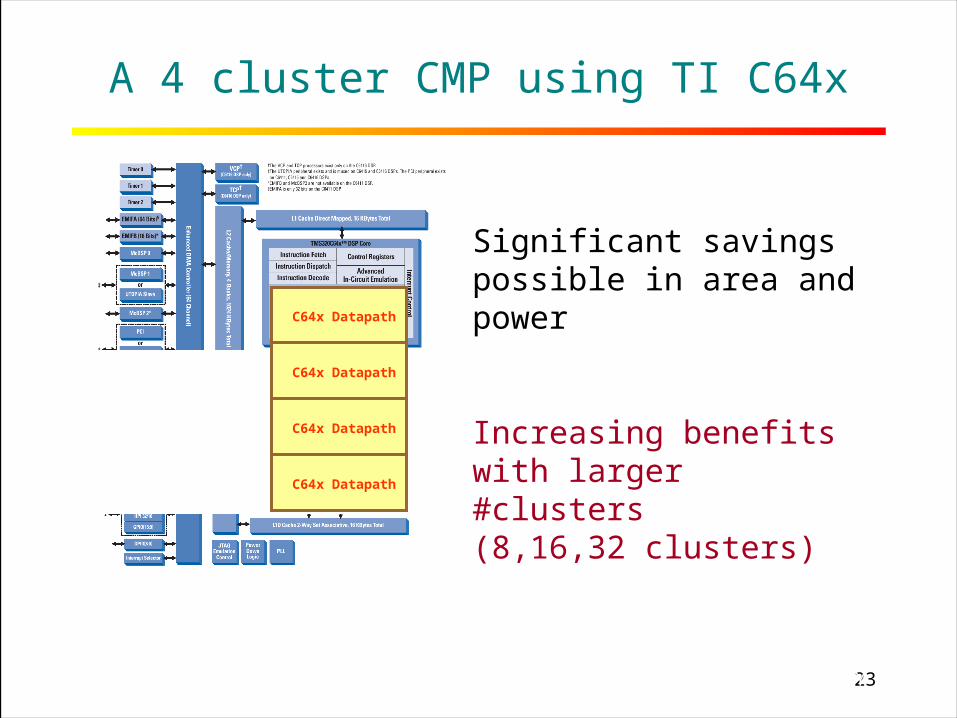
23RICE UNIVERSITY
A 4 cluster CMP using TI C64x
C64x Datapath
C64x Datapath
C64x Datapath
C64x Datapath
Significant savings possible in area and power
Increasing benefits with larger #clusters(8,16,32 clusters)
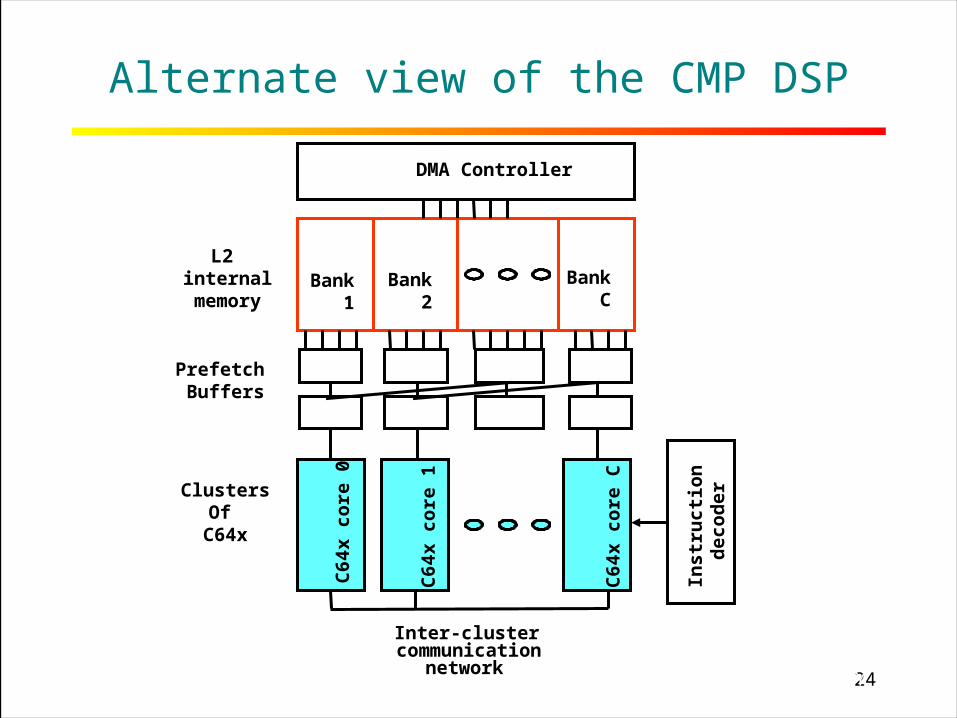
24RICE UNIVERSITY
Alternate view of the CMP DSP
DMA Controller
L2 internalmemory
Bank C
Inter-clustercommunication
network
Bank 2
Bank 1
Prefetch Buffers
ClustersOf
C64x
C64
x co
re C
C64
x co
re 0
C64
x co
re 1
Inst
ruct
ion
d
eco
der
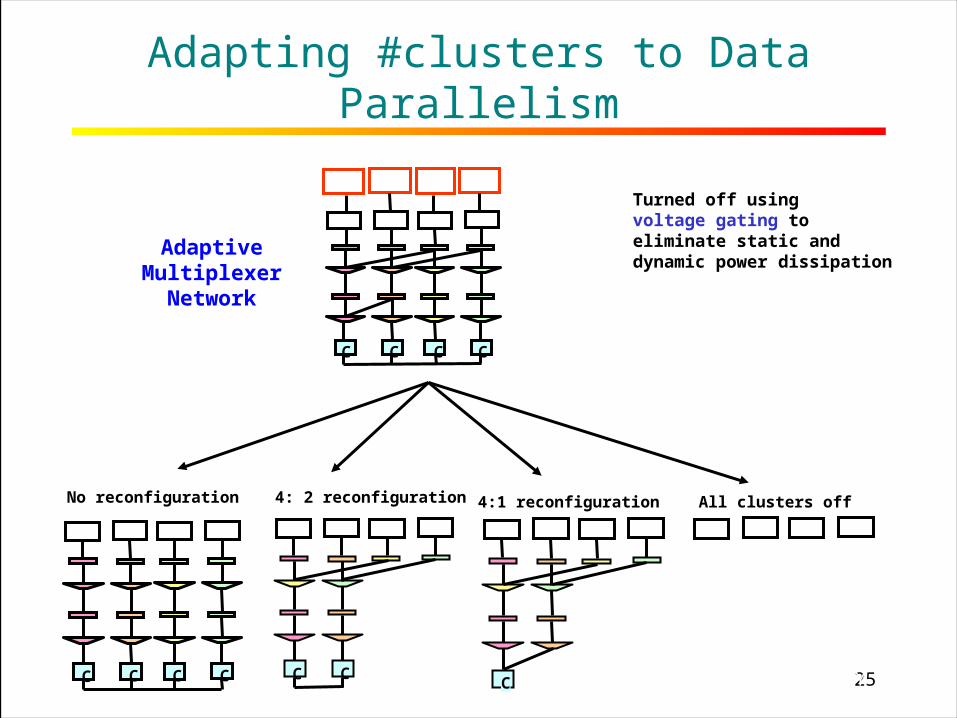
25RICE UNIVERSITY
Adapting #clusters to Data Parallelism
AdaptiveMultiplexer
Network
C C C C
C C C C C CC
No reconfiguration 4: 2 reconfiguration 4:1 reconfiguration All clusters off
Turned off using voltage gating toeliminate static anddynamic power dissipation

26RICE UNIVERSITY
Level 3: Architecture tradeoffs
Single processor -> SPMD -> SIMD Single chip :
Max die size limited to 128 clusters with 8 functional units/cluster at 90 nm technology [estimate]
Number of memory banks = #clusters
Instruction addition to turn off clusters when data parallelism is insufficient

27RICE UNIVERSITY
Level 3: Tools/Programming impact
Level 2 compiler provides support for data parallelismadapt #clusters to data parallelism for power savingscheck for loop count index after loop unrolling If less than #clusters, provide instruction to turn off
clusters
Design of parallel algorithms and mapping important
Programmer still writes regular C code Transparent to the programmerBurden on the compilerAutomatic DMA data movement to keep data feeding
into the arithmetic units

28RICE UNIVERSITY
Level 3 potential verification usingthe Imagine stream processor simulator
Replacing the C64x DSP with a cluster containing 3 +, 3 Xand a distributed register file
Verification of potential benefits

29RICE UNIVERSITY
Need for adapting to flexibility
Base-stations are designed for worst case workload
Base-stations rarely operate at worst case workload
Adapting the resources to the workload can save power!
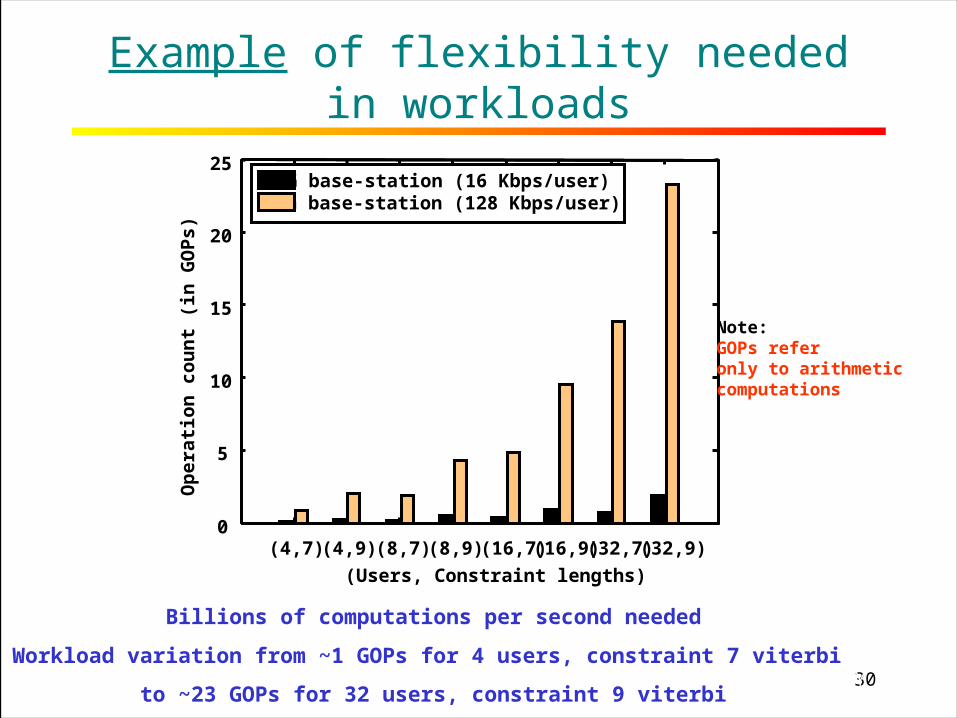
30RICE UNIVERSITY
Example of flexibility needed in workloads
0
5
10
15
20
25O
per
atio
n c
ou
nt
(in
GO
Ps)
(4,7) (4,9) (8,7) (8,9) (16,7) (16,9) (32,7) (32,9)
2G base-station (16 Kbps/user)3G base-station (128 Kbps/user)
(Users, Constraint lengths)
Billions of computations per second needed
Workload variation from ~1 GOPs for 4 users, constraint 7 viterbi
to ~23 GOPs for 32 users, constraint 9 viterbi
Note:GOPs referonly to arithmeticcomputations
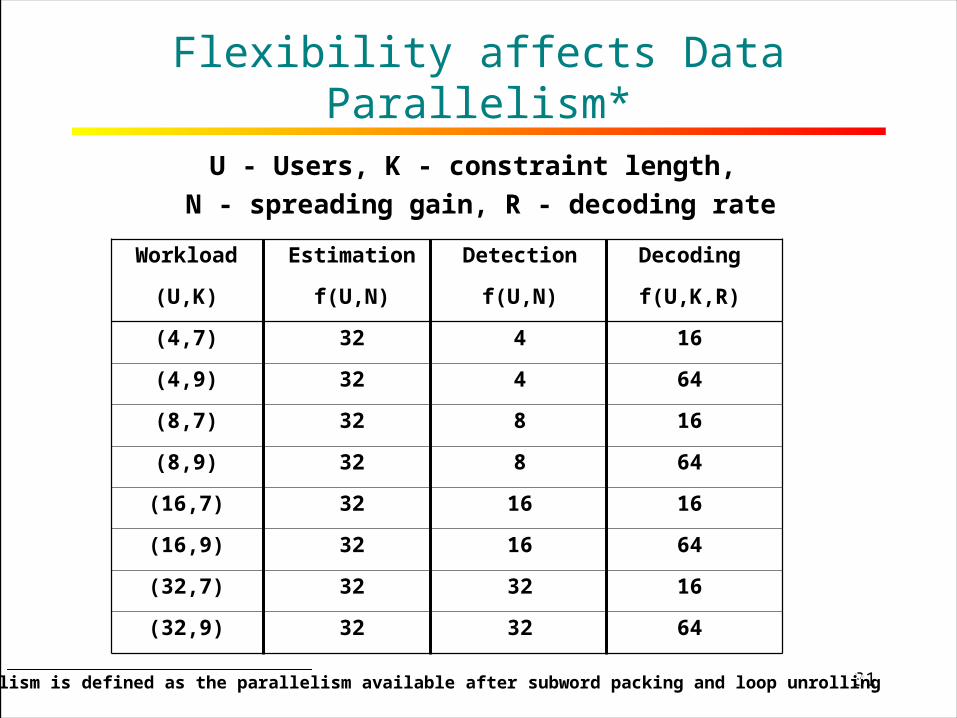
31RICE UNIVERSITY
Flexibility affects Data Parallelism*
Workload Estimation Detection Decoding
(U,K) f(U,N) f(U,N) f(U,K,R)
(4,7) 32 4 16
(4,9) 32 4 64
(8,7) 32 8 16
(8,9) 32 8 64
(16,7) 32 16 16
(16,9) 32 16 64
(32,7) 32 32 16
(32,9) 32 32 64
U - Users, K - constraint length,
N - spreading gain, R - decoding rate
*Data Parallelism is defined as the parallelism available after subword packing and loop unrolling

32RICE UNIVERSITY
Cluster utilization variation with workload
0 5 10 15 20 25 300
50
100(4,9)(4,7)
0 5 10 15 20 25 300
50
100(8,9)(8,7)
0 5 10 15 20 25 300
50
100
(16,9)(16,7)
0 5 10 15 20 25 300
50
100
(32,9)(32,7)
Cluster Index
Clu
ster
Uti
liza
tio
n
Cluster utilization variation on a 32-cluster processor
(32, 9) = 32 users, constraint length 9 Viterbi
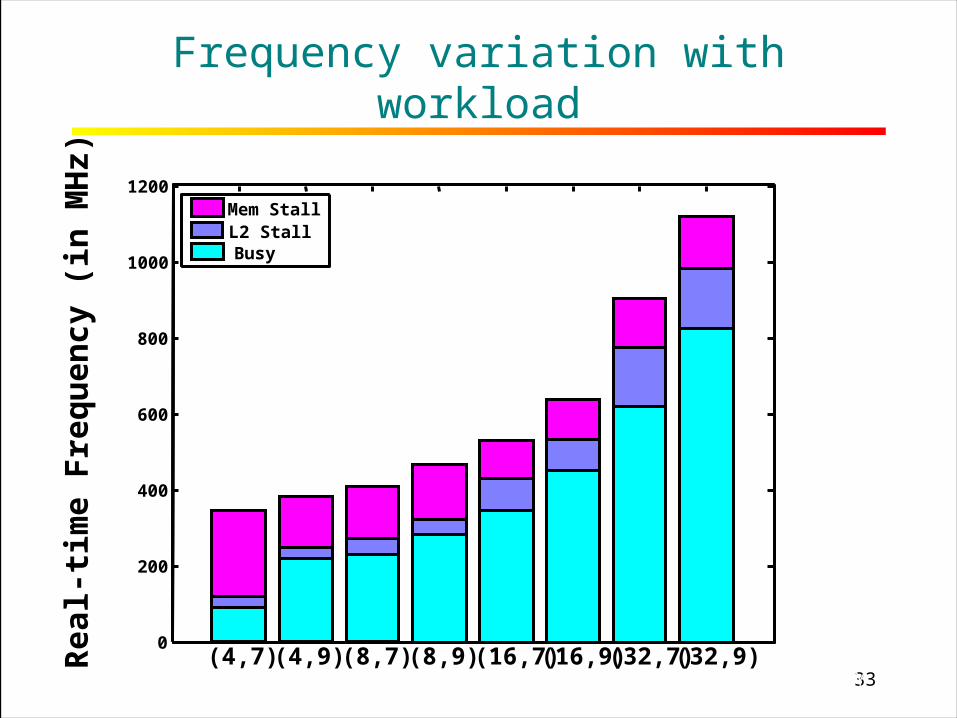
33RICE UNIVERSITY
Frequency variation with workload
0
200
400
600
800
1000
1200
Rea
l-ti
me
Fre
qu
ency
(in
MH
z)
(4,7) (4,9) (8,7) (8,9) (16,7) (16,9) (32,7) (32,9)
Mem StallL2 Stall
Busy

34RICE UNIVERSITY
Operation
DVS when system changes significantly Users, data rates …Coarse time scale (every few seconds)
Turn off clusters when parallelism changes significantlyParallelism can change within the same algorithmEg: spreading gain changes during matched filteringFiner time scales (100’s of microseconds)
Turn off ALUs when algorithms change significantlyestimation, detection, decodingFiner time scales (100’s of microseconds)
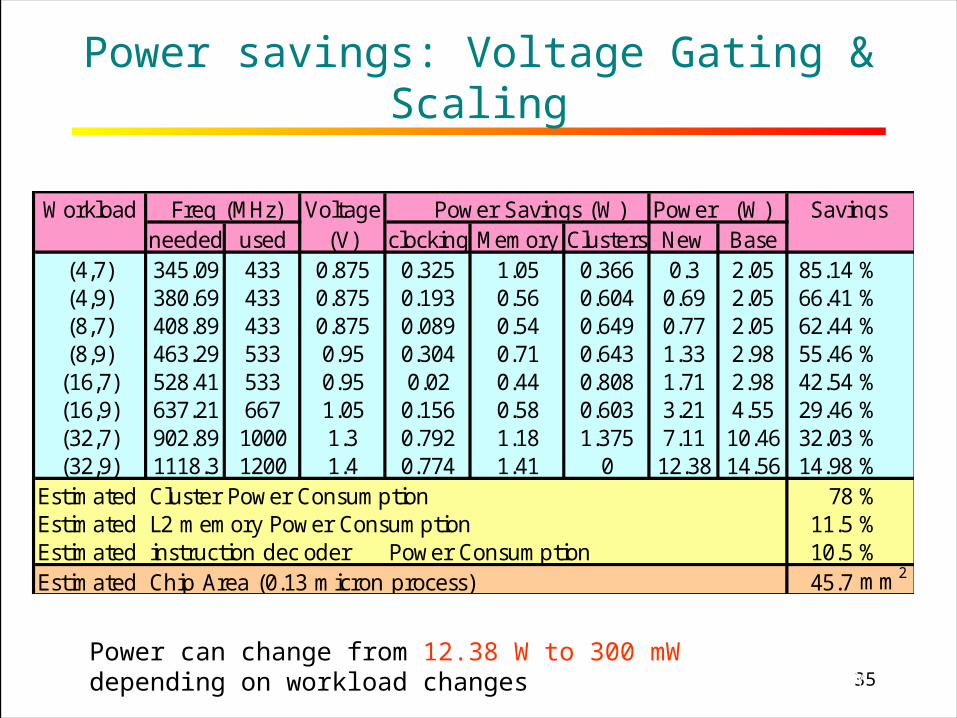
35RICE UNIVERSITY
Power savings: Voltage Gating & Scaling
Workload Freq (MHz) Voltage Power Savings (W) Power (W) Savingsneeded used (V) clocking Memory Clusters New Base
(4,7) 345.09 433 0.875 0.325 1.05 0.366 0.3 2.05 85.14 %(4,9) 380.69 433 0.875 0.193 0.56 0.604 0.69 2.05 66.41 %(8,7) 408.89 433 0.875 0.089 0.54 0.649 0.77 2.05 62.44 %(8,9) 463.29 533 0.95 0.304 0.71 0.643 1.33 2.98 55.46 %(16,7) 528.41 533 0.95 0.02 0.44 0.808 1.71 2.98 42.54 %(16,9) 637.21 667 1.05 0.156 0.58 0.603 3.21 4.55 29.46 %(32,7) 902.89 1000 1.3 0.792 1.18 1.375 7.11 10.46 32.03 %(32,9) 1118.3 1200 1.4 0.774 1.41 0 12.38 14.56 14.98 %
Estimated Cluster Power Consumption 78 %Estimated L2 memory Power Consumption 11.5 %Estimated instruction decoderoder Power Consumption 10.5 %Estimated Chip Area (0.13 micron process) 45.7 mm2
Power can change from 12.38 W to 300 mW depending on workload changes

36RICE UNIVERSITY
How to decide ALUs vs. clock frequency
No independent variablesClusters, ALUs, frequency, voltage Trade-offs exist
How to find the right combination for real-time @ lowest power!
2P CV f V f 3P f
‘1’ cluster
100 GHz
(A)
+++***
‘a’+
‘m’*
+++***
‘a’+
‘m’*
+++***
‘a’+
‘m’*
‘c’ clusters
‘f’ MHz
+++***
‘1’+
‘1’*
+++***
‘10’+
‘10’*
+++***
‘10’+
‘10’*
+++***
‘10’+
‘10’*
‘100’ clusters
10 MHz
(B) (C)

37RICE UNIVERSITY
Setting clusters, adders, multipliers
If sufficient DP, linear decrease in frequency with clustersSet clusters depending on DP and execution time
estimate
To find adders and multipliers,Let compiler schedule algorithm workloads across
different numbers of adders and multipliers and let it find execution time
Put all numbers in previous equationCompare increase in capacitance due to added ALUs
and clusters with benefits in execution time
Choose the solution that minimizes the power
Details available in Sridhar’s thesis

38RICE UNIVERSITY
Conclusions
We propose a step-by-step methodology to design high performance power-efficient DSPs based on the TI 64x architecture Initial results show benefits in power/performance greater
than an order-of-magnitude over a conventional C64x
We tailor the design to ensure maximum compatibility with TI’s C6x architecture and tools
We are interested in exploring opportunities in TI for designing and actual fabrication of a chip and associated tool development
We are interested in feedback limitations that we have not accounted for Unreasonable assumptions that we have made
Recommended reading:S. Rixner et al, A register organization for media processing, HPCA 2000B. Khailany et al, Exploring the VLSI scalability of stream processors, HPCA 2003U. J. Kapasi et al, Programmable Stream Processors, IEEE Computer, August 2003