Embed Size (px)
Citation preview

Programming Parallel and Distributed Systems for Large Scale Numerical Simulation Application
Christian PerezINRIA researcher
IRISARennes, France

2
IRISA
IRISA INRIA Rennes CNRS Univ. of Rennes I INSA
600 people (march 06) 233 researchers 184 PhD students 120 Engineers, technicians

3
Project team composition
Tenured personnel (11) F. André (Prof IFSIC) G. Antoniu (CR INRIA) J-P. Banâtre (Prof IFSIC) L. Bougé (Prof ENS) Y. Jégou (CR INRIA) D. Margery (IR INRIA) 50% C. Morin (DR INRIA) P. Morillon (IE IFSIC) J.L. Pazat (Prof. INSA) C. Perez (CR INRIA) T. Priol (DR INRIA)
Post-docs (5) PhD students (11) Engineers (6)

4
PARIS objectives
Objects of study: Cluster and Cluster of Clusters (aka Grids)
Main objectives: Study and design operating systems, middleware and runtime systems to
make the programming of such computing infrastructures easier with: High-performance High-availability Scalability
Design advanced programming models for the programming of Clusters of Clusters
Combining both parallel and distributed computing paradigms Evaluation of the proposed operating systems, runtimes and middleware
through the development of advanced software (not only software prototype)
Technology transfer through collaboration with industrial partners

5
Research activities
Operating System and Runtime systems for Clusters and Cluster Federations Single System Image Operating System Grid-aware Operating System
Middleware for Computational Grids Component-based middleware for computational Grids
Communication framework Parallel components Deployment of parallel components within a grid Adaptive components
Large-scale data management for Grids Coupling of Distributed Shared Memories Data sharing services for mutable data using a P2P approach
Advanced Models for the Grids High-order Gamma Enactment of workflows based on a chemical metaphor
Experimental Grid Infrastructures The Grid’5000 testbed

6
Orsay1000 (684)
Rennes518 (658)
Bordeaux500 (96)
Toulouse500 (116)
Lyon500 (252)
Grenoble500 (270)
Sophia Antipolis500 (434)
Lille500 (106)
Nancy:500 (94)
Grid’5000 testbed
10 Gbps Dark fiberDedicated LambdaFully isolated traffic!Provided by RENATER
7
Component-based middleware for computational Grids
Apply modern software practices to scientific computing
High-performance & Scalability Specialized component models for high
performance computing (clusters & grids) Code coupling applications Parametric applications
Increase the level of abstraction SPMD paradigm (MxN communications) Master-worker paradigm Data sharing paradigm
High-performance communication Independence vis à vis of the networking
technologies Adaptation
Adaptation to the dynamic behavior of grids Deployment
Map components to available resources Technology independent
(CCM, CCA, Fractal, CoreGRID GCM)
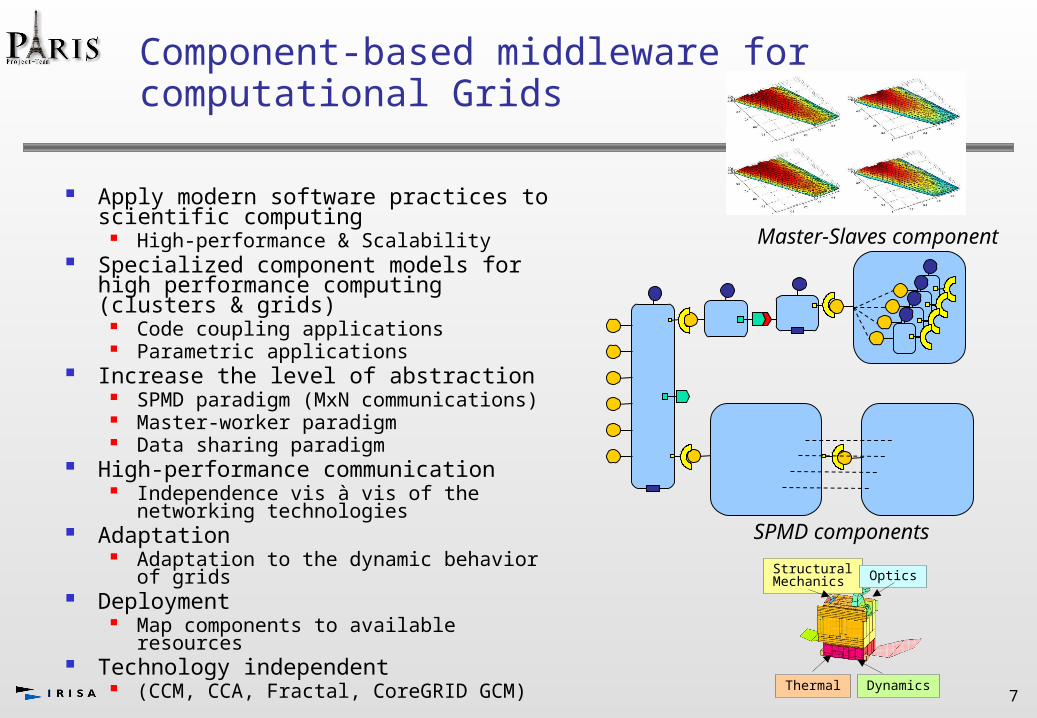
SPMD components
Master-Slaves component
Thermal Dynamics
StructuralMechanics Optics

8
High Performance Components for code coupling:SPMD paradigm
SPMD component Parallelism is a non-functional
property of a component It is an implementation issue
Collection of sequential components SPMD execution model
Support of distributed arguments API for data redistribution API for communication scheduling w.r.t.
network properties Support of parallel exceptions
0
50
100
150
200
250
300
1->1 2->2 4->4 8->8
Component configuration
Aggregated Bandwidth in MB/s0
20
40
60
80
100
120
140
160
Latency in microseconde
Java/EthC++/EthC++/MyriC++/Myri
Object Request Broker
CORBA stub/skeleton
CommunicationLibrary ( MPI)
Application
Application view management- Data distribution description
Communication management- Comm. Matrix computation- Comm. Matrix scheduling- Communication execution
Redistribution Library 1
CommunicationLibrary
GridCCM runtime
SchedulingLibrary
6 7 8 9 10 11 12 13 14 15 1675
77.5
80
82.5
85
87.5
90
92.5
95
97.5
100
Without scheduling With scheduling
Number of processors per parallel component
Component A Component B
9
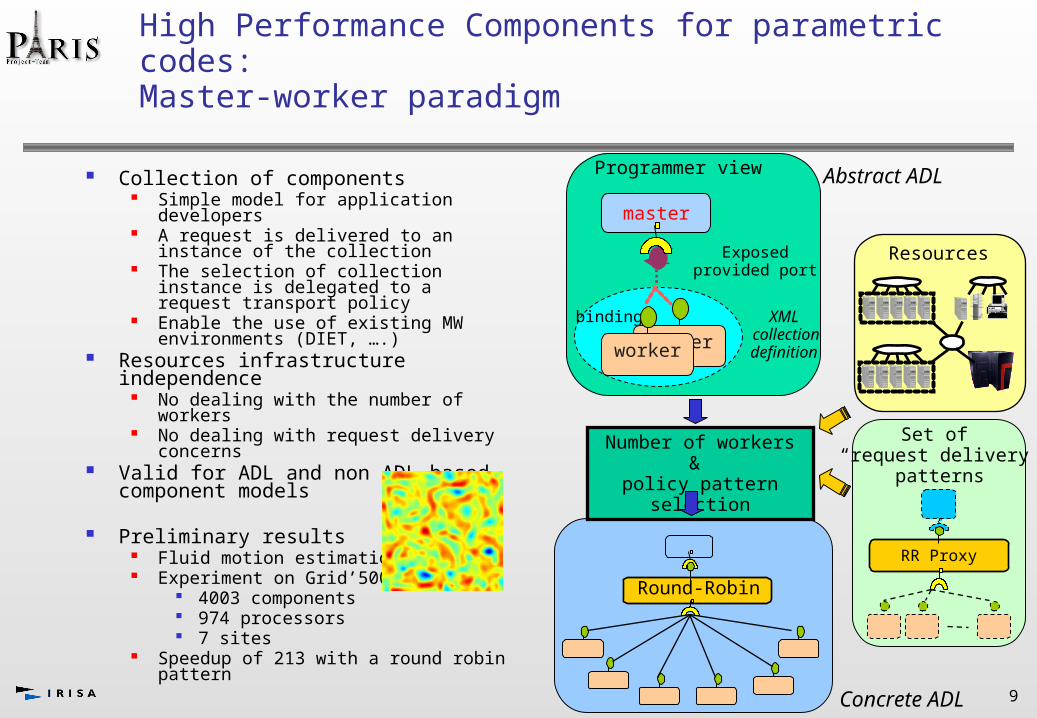
High Performance Components for parametric codes:Master-worker paradigm
Collection of components Simple model for application developers A request is delivered to an instance of
the collection The selection of collection instance is
delegated to a request transport policy Enable the use of existing MW
environments (DIET, ….) Resources infrastructure independence
No dealing with the number of workers No dealing with request delivery concerns
Valid for ADL and non ADL based component models
Preliminary results Fluid motion estimation Experiment on Grid’5000
4003 components 974 processors 7 sites
Speedup of 213 with a round robin patternRound-Robin
Programmer view
binding
master
worker
Exposed provided port
RR Proxy
Set of “request delivery”
patterns
Number of workers & policy pattern selection
Resources
Abstract ADL
Concrete ADL
XML collectiondefinition worker

10
PadicoTM: Communication framework
Provides an open integration platform to combine various communication middleware and runtimes
Message based runtimes (MPI, PVM, …) DSM-based runtimes (TreadMarks, …) RPC and RMI based middleware (DCE,
CORBA, Java, …) Allows several communication middleware
and runtime to share various networking technologies
Ethernet, Myrinet, Infiniband, Quadrics, SCI Last but not least: get the maximum
performance of the network! Available as an open source software
under the GPL licence http://padico.gforge.inria.fr > 200 downloads since July 2002
MadeleinePortability across networks
MarcelI/O aware multi-threading
Myrinet SCI
PadicoTMCore
PadicoTM Services
Multithreading
Netw
orksDSM JVMMPI CORBA JXTA
TCP
Personality Layer
Internal engine
Mpich
OmniORBMICOOrbacusOrbix/E
Kaffe JuxMemMome

11
ADAGE: Automatic Deployment of Application in a Grid Environment
Deploy a same application on any kind of resources
from clusters to grids Support multi-middleware application
MPI+CORBA+JUXMEM+... Planner as plugin
round robin & random Some successes
29.000 JXTA peers on ~400 nodes 4003 components on 974 processors
on 7 sites Alpha support for dynamic application
MPI Application Description
CCM Application Description
Resource Description
Generic Application Description
Control Parameters
Deployment Planning
Deployment Plan Execution
Application Configuration



























