Embed Size (px)
Citation preview

PARALLEL SKYLINE QUERIES
Foto AfratiParaschos KoutrisDan SuciuJeffrey Ullman
University of Washington

2
WHAT IS THE SKYLINE?
• A d-dimensional set R• A point x dominates x’ if forall k: x(k) ≤ x’(k)• The skyline of R are all non-dominated points of R
domination
skyline

3
CONTRIBUTIONS
• We design algorithms for Skyline Queries based on two parallel models:– MP: perfect load balancing [Koutris, Suciu ‘11]
– GMP: weaker load balancing [Afrati, Ullman ’10]
• We present 3 algorithms with theoretical guarantees for:– # synchronization steps– load balance

4
PREVIOUS APPROACHES
• Several efficient algorithms for skyline queries exist in the literature
• Parallel algorithms use various partitionings:– Grid-based partitioning [WZFZAA ’06]
– Random partitioning [CRZ ’07]
– Angle-based space partitioning [VDK ’08]
– Hyperplane projections [KYZ ’11]
• Previous approaches typically require a logarithmic number of communication steps: our algorithms achieve 1 or 2 steps

5
MASSIVELY PARALLEL MODELS
• P servers: R partitioned into R1,R2,…, RP
• n = |R|• The algorithm alternates between communication
and computation steps• MP model: each node holds O(n/P) data • GMP model: each node holds O(Pε * n/P) where 0
≤ ε < 1 – ε = 0 : GMP = MP– ε = 1 : GMP = sequential computation in one node

6
AN EXAMPLE• How do we compute set intersection in one step
in the MP model?• Hash each value x (from R or S) to a server
Communication Phase send tuple R(x) to server @h(x) send tuple S(x) to server @h(x)Computation Phase output a tuple only if it occurs twice
Intersection Q(x):-R(x),S(x)

7
THE BROADCAST STEP• In addition to regular communication steps, we
allow broadcast steps:• the data exchanged is independent of n
• Known results:• Q(x,y)=R(x),S(x,y) can be computed in 1 MP step iff
a broadcast step is allowed [Koutris, Suciu ‘11]
• Q(x,y)=R(x),S(x,y),T(y) can not be computed in 1 MP step [Koutris, Suciu ‘11] , but can be in 1 GMP step with ε=1/2 [Afrati, Ullman ‘10]

8
• Broadcast• Grid-based partitioning into cells• Pre-processing the cells to compute the relaxed
skyline
• Communication• Careful distribution of the cells (with their data) to
the servers
• Computation: • Local computation of the skyline at each server
OUTLINE OF OUR APPROACH

9
BUCKETIZING• Partition R into M buckets across some dimension,
such that each partition contains O(n/M) points • Equivalently, compute (M+1) partition points:
-∞ = b0 , b1 , … , bM = +∞
Algorithm:Local: each server evenly partitions its data to M bucketsBroadcast: servers exchange MxP partition pointsLocal: each server picks every P-th value as partition point
bucketize acrossdimension 1
bucketize acrossdimension 2
M=P or P1/(d-1)

10
CELLS• A cell is an intersection of buckets from all dimensions• Every point belongs in exactly one cell• Every cell holds O(n/P) data (and not O(n/Pd) !!)
In each cell, we can keep only candidates for skyline points
candidate rejected

11
• Broadcast• Grid-based partitioning into cells• Pre-processing the cells to compute the relaxed
skyline
• Communication• Careful distribution of the cells (with their data) to
the servers
• Computation: • Local computation of the skyline at each server
OUTLINE OF OUR APPROACH
12
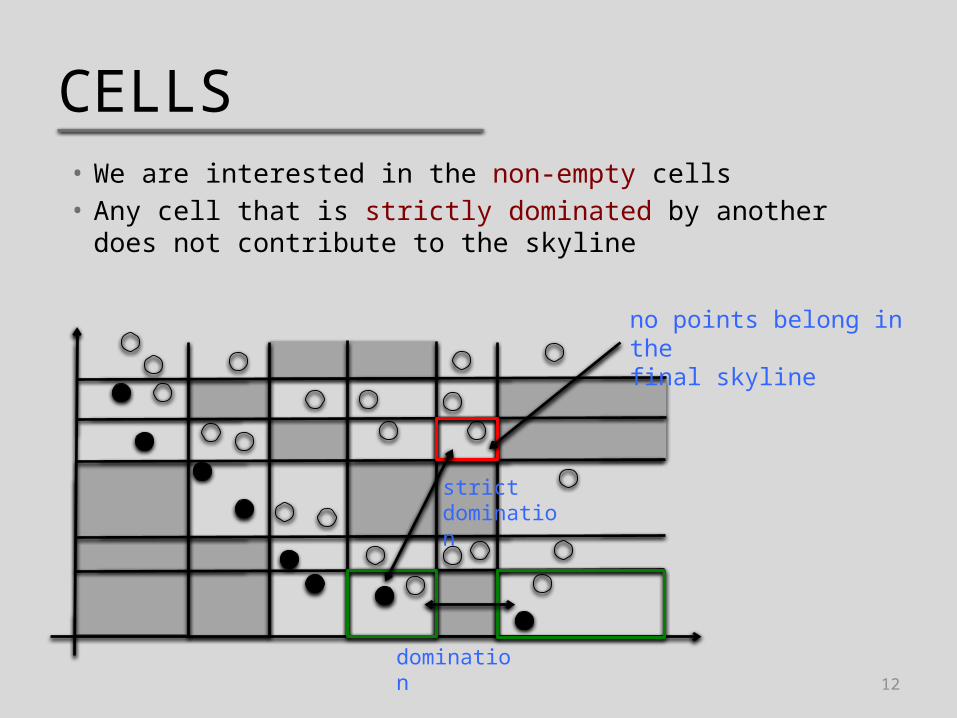
CELLS• We are interested in the non-empty cells• Any cell that is strictly dominated by another does not
contribute to the skyline
no points belong in thefinal skyline
strictdomination
domination

13
RELAXED SKYLINE OF CELLS• The relaxed skyline consists of the non-empty cells
that are not strictly dominated by non-empty cells• We focus on the relaxed skyline of non-empty cells
skyline
relaxed skyline
14
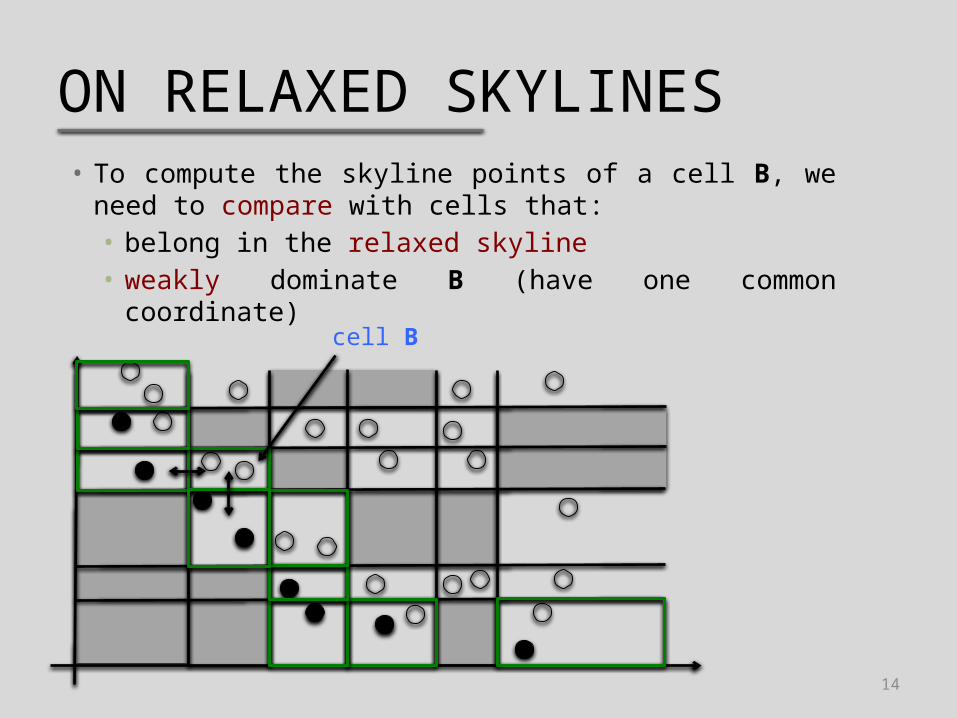
ON RELAXED SKYLINES• To compute the skyline points of a cell B, we need to
compare with cells that:• belong in the relaxed skyline• weakly dominate B (have one common coordinate)
cell B

15
• Broadcast• Grid-based partitioning into cells• Pre-processing the cells to compute the relaxed
skyline
• Communication• Careful distribution of the cells (with their data) to
the servers
• Computation: • Local computation of the skyline at each server
OUTLINE OF OUR APPROACH

16
A NAÏVE APPROACH• Try the following:• Partition into P buckets (M=P)• Allocate cells in the relaxed skyline to servers + cells
that weakly dominate them: O(n/P) data per cell• Locally compute the skyline points
• This works if the relaxed skyline is small• But the relaxed skyline can have as many as
Ω(Pd-1) cells for dimension d

17
A 1-STEP ALGORITHM• Choose a coarser bucketization (<P buckets)• This gives a weak load-balanced algorithm with
maximum load of O( (n/P) P(d-2)/(d-1) )
• ε = (d-2)/(d-1) (ε=0 implies GMP=MP)
Corollary. For d=2 dimensions, we obtain a perfectly load balanced algorithm for MP
18
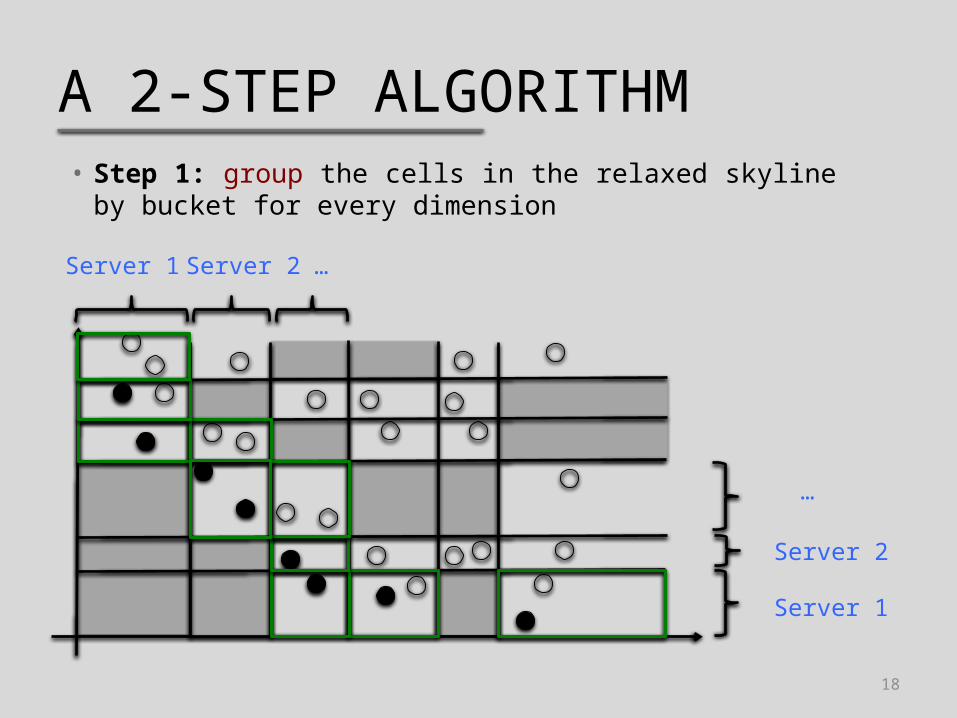
A 2-STEP ALGORITHM• Step 1: group the cells in the relaxed skyline by
bucket for every dimension
Server 1
Server 2
Server 1 Server 2
…
…
19
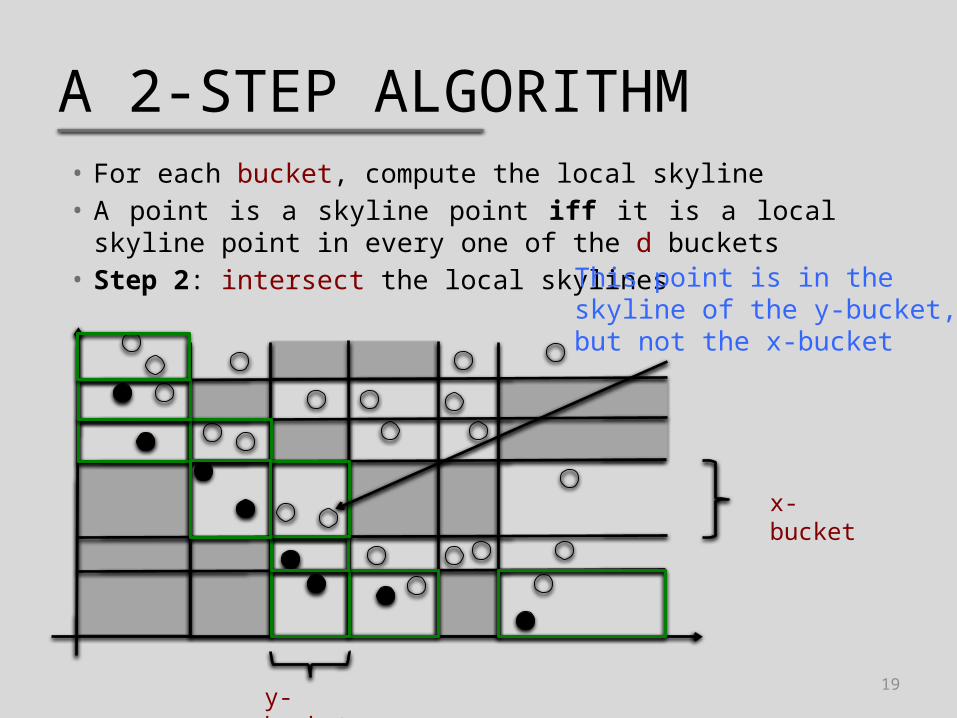
A 2-STEP ALGORITHM• For each bucket, compute the local skyline• A point is a skyline point iff it is a local skyline point in
every one of the d buckets• Step 2: intersect the local skylines This point is in the skyline of
the y-bucket, but not the x-bucket
x-bucket
y-bucket
20
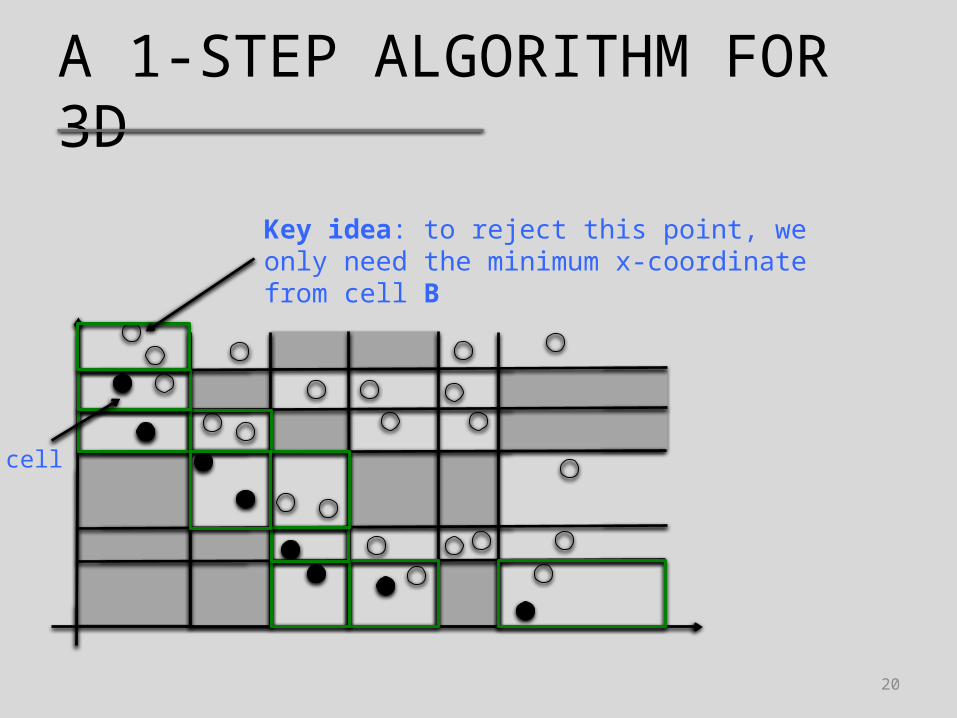
A 1-STEP ALGORITHM FOR 3D
Key idea: to reject this point, we only need the minimum x-coordinate from cell B
cell B

21
A 1-STEP ALGORITHM FOR 3D• The observation reduces the number of points that
need to be communicated• With smart partitioning, we can achieve perfect load-
balance in 1 step• However, the property holds only for 2 and 3
dimensions

22
CONLUSION
3 algorithms for Skyline Queries:• 2 step + perfect load balance• 1 step + some replication• 1 step + perfect load balance for d < 4
Open Questions• Can we compute the skyline in 1 step with perfect load
balance for >3 dimensions?• A more general question: what classes of queries can
we compute in the MP model with perfect or weaker load balance guarantees?

23
Thank you!

24
INTERIOR CELLS• Two cells are co-linear if they share exactly two
coordinates• A cell i is interior if every colinear cell in Sr(J) belongs in
the same hyperplane as i. Else, it is a corner cell. • Interior cells are easy to handle: we can send the whole
plane to a single processor

25
CORNER CELLS• We group the corner cells into lines• Border cells are the minimal/maximal cells of each line• Fact: lines meet only on border cells• Grouping: each line is a group, a cell is assigned to the
lexicographically first line it belongs to

26
Assigning the groups• We have two ways to assign groups to servers• The first is deterministic and greedily assigns a
group to any server that is not overloaded (M=P)• The second is randomized and sends each group
randomly to some server (M = P log P)

27
About the MP model• [KS11] A dichotomy result on Conjunctive
Queries that can be computed in 1 step with perfect load balancing
• Easy Queries: – Q(x,y,z) :- R(x,y) , S(y,z)– Q(x,y,z,) :- R(x), S(x,y), T(x,y,z)
• Hard Queries:– Q(x,y) :- R(x), S(x,y), T(y)– Q(x,y) :- R(x), S(x), T(y)





![Domain References - Springer978-1-4471-3082-6/1.pdf · [Afrati 90] [Akscyn 88] [Alexander 77] [Allesi 91] [Appino 92] [Apple 91] [Arnheim 71] 233 F. Afrati, and C.D. Koutras. "A Hypertext](https://img.pdfslide.us/doc/110x75/5c68de9209d3f2f5638c49d6/domain-references-springer-978-1-4471-3082-61pdf-afrati-90-akscyn-88.jpg)
![ECOMPOSITION CHEMA NORMALIZATIONpages.cs.wisc.edu/~paris/cs564-s18/lectures/lecture-07.pdf · EXAMPLE: INFORMATION LOSS CS 564 [Spring 2018] -Paris Koutris 8 name age phoneNumber](https://img.pdfslide.us/doc/110x75/5ab0784a7f8b9a1d168b5b67/ecomposition-chema-pariscs564-s18lectureslecture-07pdfexample-information-loss.jpg)


















