Embed Size (px)
Citation preview

Roweis, S. T., & Saul, L. K. (2000). Nonlinear dimensionality reduction by locally linear embedding. science, 290(5500), 2323-2326.
Nonlinear Dimensionality Reduction by Locally Linear Embedding and more
Ahmed Zamzam
1
CSCI 8314: Sparse Matrix Computations
04/13/2017
Horseshoe Theory
2
The far-left and far-right are more similar to each
other in essentials than either is to the political center.
Pierre, Faye Jean. "Le siècle des idéologies." (2002).
Why Nonlinear Manifold Learning?
3
Difficulty of comprehending data in
high dimensions
Meaningful “intrinsic variables”
Nonlinearity of the reduced
dimension
Numerous applications

Problem Statement
MDS: Compute embeddings that preserve the pairwise distances
4
Problem statement
Given data points each point lies in a high dimensional space . Find a mapping , with , such thatthe local structure is preserved.
ISOMAP: Incorporate the geodesic distances imposed by a
weighted graph.

Global vs. Local approaches
5
Global (MDS and ISOMAP):
Require computing pairwise distances
Produce non-sparse high dimensional matrices
Offer theoretical guarantees
Local:
Consider only distances between neighbors
Require solving sparse eigenvalues problem
Does NOT have exact reconstruction guarantees
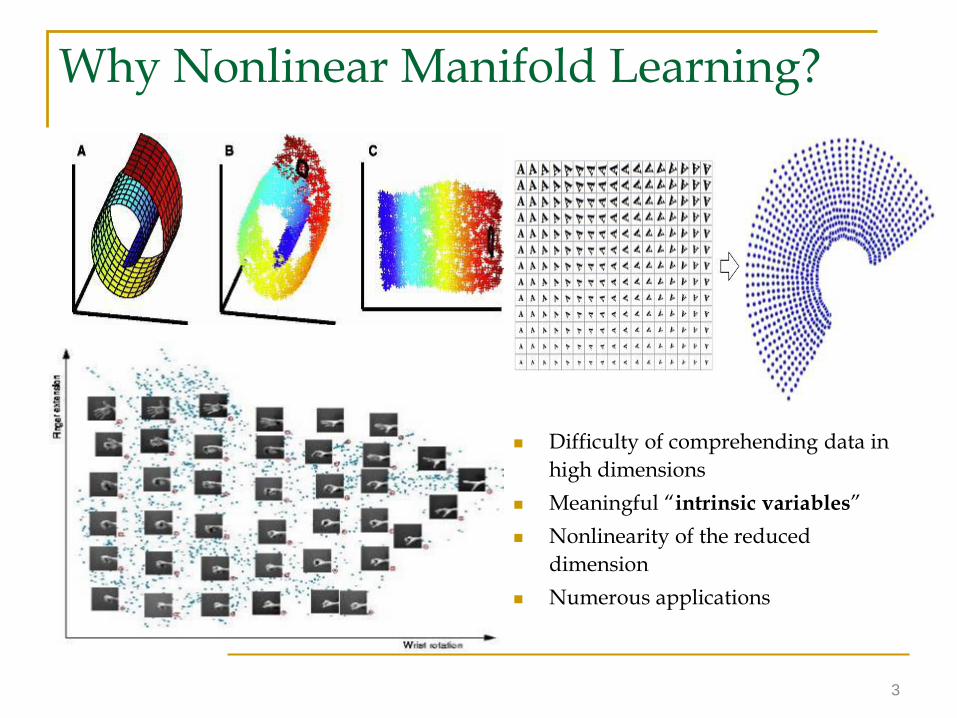
Fit locally, think globally
6
Manifolds is a topological space which is locally Euclidean

Local fitting
Each data point and its neighbors are expected to lie on or close to a
locally linear patch of the manifold
Each data point can be reconstructed using its neighbors
Neighbors are selected using a specific criterion (to be discussed)
Optimal reconstruction is obtained by solving
where is the contribution of the j-th point to the i-th point
reconstruction.
7

Neighbors selection
K-nearest neighbors
Choose the neighbors set of point to be its K nearest neighbors.
Q: How many neighbors are enough?
Q: What is the main shortcoming of this method?
8
-close neighbors
Choose the neighbors set of point to be all points with .
Q: What is the main shortcoming of this method?

Global thinking
We want a linear mapping that preserves the local
neighborhood structure
We expect the computed weights to be able to reconstruct
the reduced dimension data points from the same neighbors
The problem to be solved:
9
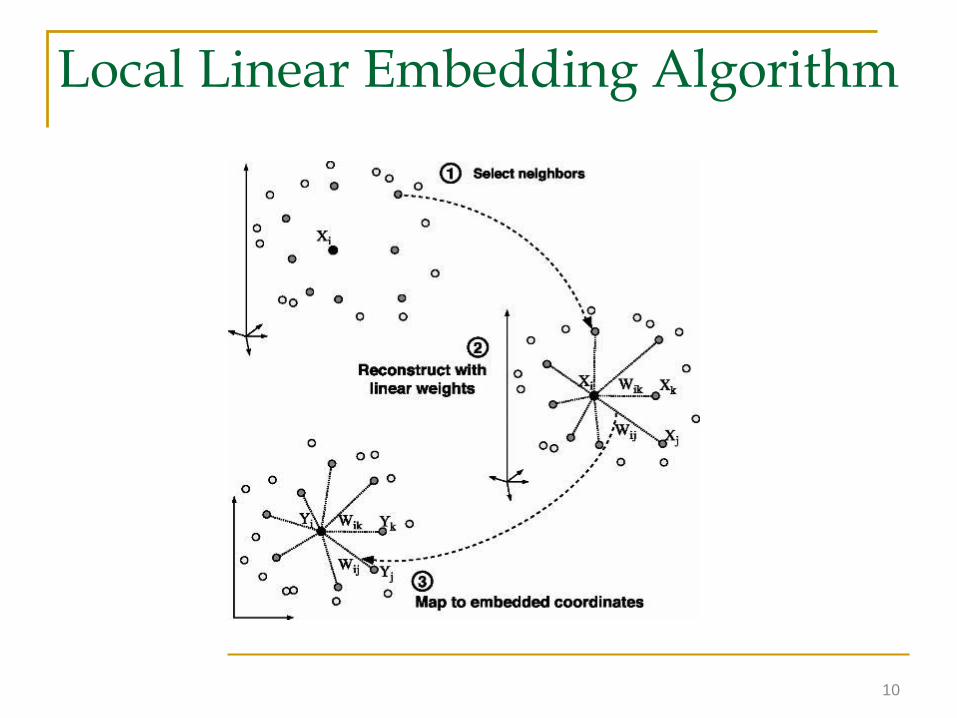
Local Linear Embedding Algorithm
10
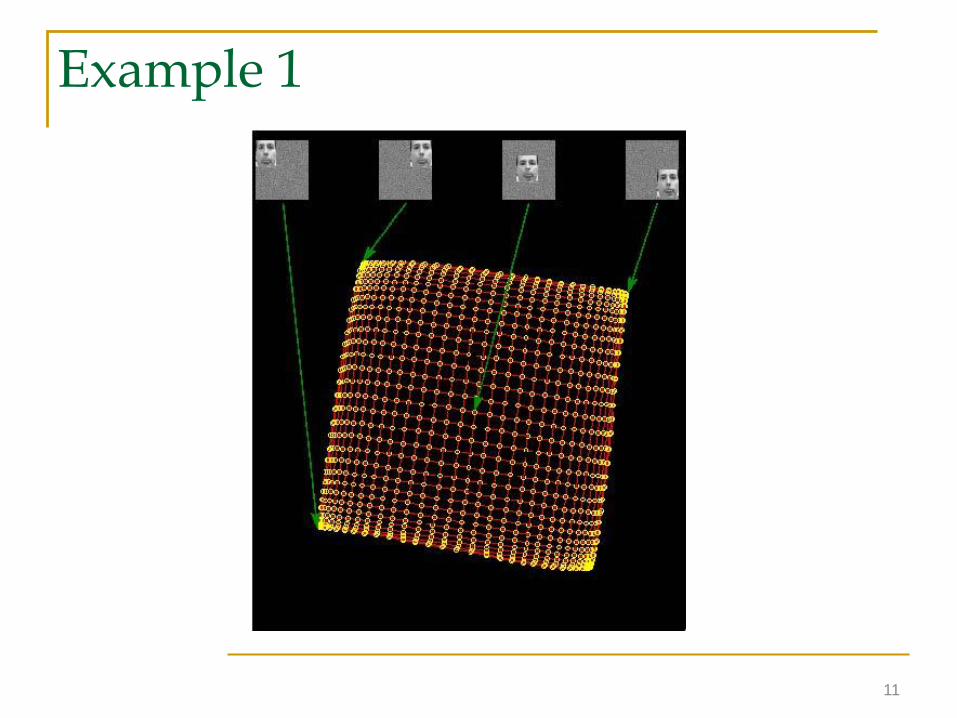
Example 1
11

Example 2
12
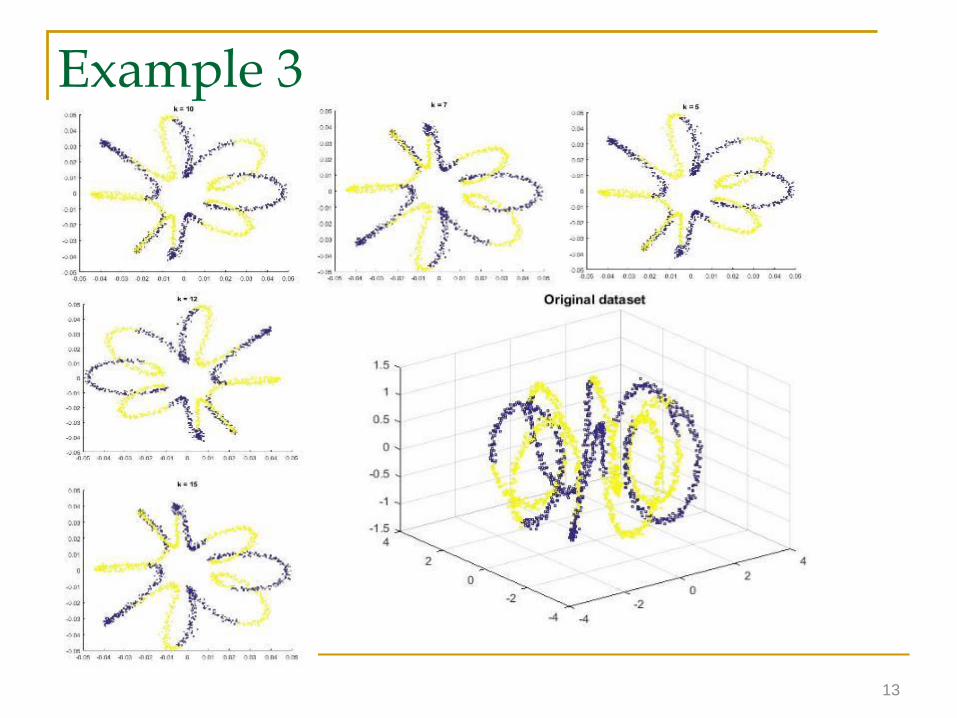
13
Example 3

Hessian LLE
Choose the neighboring set for all points
Find each point, perform PCA on the neighboring set to estimate
the tangent subspace at
Compute least-squares Hessian estimates based on projections on
the tangent subspace
Find discrete approximation for
Optimal Solution is given by the rows of the eigenvectors with
minimal eigenvalues, excluding the smallest eigenvector
14
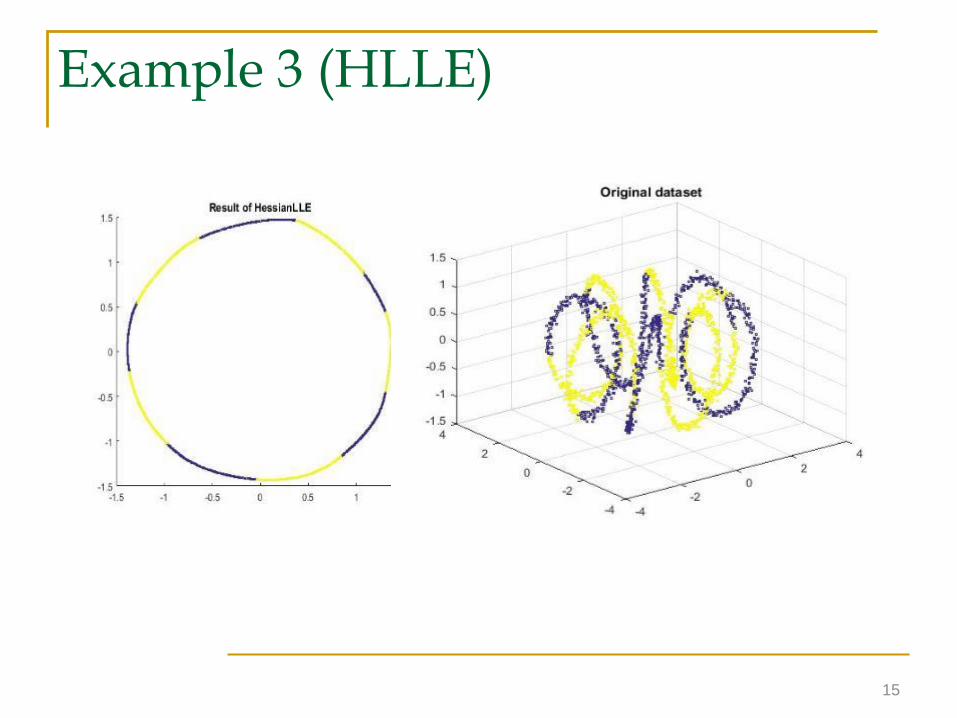
15
Example 3 (HLLE)
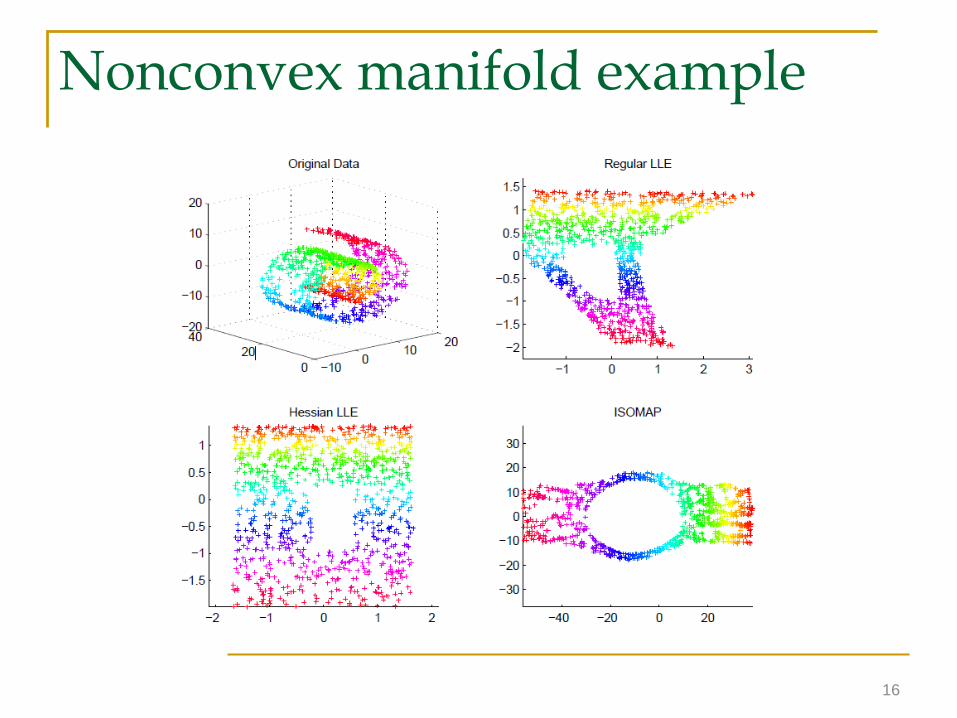
Nonconvex manifold example
16

Take-home messages…
17
LLE models the neighborhood as linear patches and then
embed in a lower dimension manifold
LLE is a local approach, and hence benefits from the sparsity
of local representation
Can capture nonconvex manifolds with holes
Extensions of LLE: Laplacian Eigenmaps, Hessian LLE, etc.
Thank You!

References Roweis, Sam T., and Lawrence K. Saul. "Nonlinear dimensionality reduction by
locally linear embedding." science 290.5500 (2000): 2323-2326.
Saul, Lawrence K., and Sam T. Roweis. "Think globally, fit locally: unsupervised
learning of low dimensional manifolds." Journal of Machine Learning Research 4.Jun
(2003): 119-155.
Tenenbaum, Joshua B., Vin De Silva, and John C. Langford. "A global geometric
framework for nonlinear dimensionality reduction." science 290.5500 (2000): 2319-
2323.
Donoho, David L., and Carrie Grimes. "Hessian eigenmaps: Locally linear embedding
techniques for high-dimensional data." Proceedings of the National Academy of
Sciences 100.10 (2003): 5591-5596.
18
Matlab Toolbox for Dimensionality Reductionhttps://lvdmaaten.github.io/drtoolbox/
contains Matlab implementations of 34 techniques for dimensionality reduction and metric learning.

Intuitive explanation for HLLE
The HLLE method may be viewed as variant of the Local Linear
Embedding method.
The conceptual framework may be viewed as a modification of the
Laplacian Eigenmaps framework.
In these modifications, a quadratic form is substituted based on the
Hessian in place of the original ones based on the Laplacian.
The point of interest is that a linear function has everywhere
vanishing Laplacian, but not every function with everywhere
vanishing Laplacian is linear, while a function is linear if and only if
it has everywhere vanishing Hessian.
By substituting the Hessian for the Laplacian, a global embedding is
found which is nearly linear in every set of local tangent coordinates.
19

HLLE Algorithm
20