Embed Size (px)
Citation preview

New Theoretical Frameworks for Machine Learning
Maria-Florina Balcan
Thesis Proposal
05/15/2007

2
Thanks to My Committee
Avrim Blum Tom MitchellManuel Blum
Yishay Mansour Santosh Vempala

3
The Goal of the Thesis
Connections between Machine Learning Theory and Algorithmic Game Theory
New Theoretical Frameworks for Modern Machine Learning Paradigms

4
Semi-supervised Learning
New Frameworks for Modern Learning Paradigms
Active Learning
Incorporating Unlabeled Data in the Learning Process
Modern Learning Paradigms
Unified theoretical treatment is lacking
Qualitative gap between theory and practice
Semi-supervised learning
Active Learning- new positive theoretical results
- a unified PAC framework
Our Contributions
Extensions to clustering
Our ContributionsA theory of learning with general similarity functions
Kernel based Learning
With Avrim and Santosh
5
New Frameworks for Modern Learning Paradigms
Incorporating Unlabeled Data in the Learning Process
Modern Learning Paradigms
Unified theoretical treatment is lacking
Qualitative gap between theory and practice
Semi-supervised learning
Active Learning- new positive theoretical results
- a unified PAC framework
Our Contributions
Extensions to clustering
Our ContributionsA theory of learning with general similarity functions
Kernel, Similarity based Learning and Clustering
With Avrim and Santosh

6
Machine Learning Theory and Algorithmic Game Theory
Mechanism Design, ML, and Pricing Problems
Generic Framework for reducing problems of incentive-compatible mechanism design to standard algorithmic questions. [Balcan-Blum-Hartline-Mansour, FOCS 2005, JCSS 2007]
Approximation Algorithms for Item Pricing.[Balcan-Blum, EC 2006]
• Revenue maximization in comb. auctions with single-minded consumers
Brief Overview of Our Results

7
The Goal of the Thesis
Connections between Machine Learning Theory and Algorithmic Game Theory
New Theoretical Frameworks for Modern Machine Learning Paradigms
• Semi-Supervised and Active Learning
• Similarity Based Learning and Clustering
• Use MLT techniques for designing and analyzing auctions in the context of Revenue Maximization

8
The Goal of the Thesis
New Theoretical Frameworks for Modern Machine Learning Paradigms
Semi-supervised learning (SSL)
Active Learning (AL)
Incorporating Unlabeled Data in the Learning Process
Kernel, Similarity based learning and Clustering
- An Augmented PAC model for SSL [Balcan-Blum, COLT 2005; book chapter, “Semi-Supervised Learning”, 2006]
- Generic agnostic AL procedure[Balcan-Beygelzimer-Langford, ICML 2006]
- Margin based AL of linear separators[Balcan-Broder-Zhang, COLT 2007]
[Balcan-Blum-Vempala, MLJ 2006]
- Extensions to Clustering[Balcan-Blum-Vempala, work in progress]
- Connections between kernels, margins and feature selection
- A general theory of learning with similarity functions[Balcan-Blum, ICML 2006]

9
The Goal of the Thesis
New Theoretical Frameworks for Modern Machine Learning Paradigms
Semi-supervised learning (SSL)
Active Learning (AL)
Incorporating Unlabeled Data in the Learning Process
Kernel, Similarity based learning and Clustering
- An Augmented PAC model for SSL [Balcan-Blum, COLT 2005; book chapter, “Semi-Supervised Learning”, 2006]
- Generic agnostic AL procedure[Balcan-Beygelzimer-Langford, ICML 2006]
- Margin based AL of linear separators[Balcan-Broder-Zhang, COLT 2007]
[Balcan-Blum-Vempala, MLJ 2006]
- Extensions to Clustering[Balcan-Blum-Vempala, work in progress]
- Connections between kernels, margins and feature selection
- A general theory of learning with similarity functions[Balcan-Blum, ICML 2006]

Part I, Incorporating Unlabeled Data in the Learning Process
Semi-Supervised Learning
[Balcan-Blum, COLT 2005; book chapter, “Semi-Supervised Learning”, 2006]
A unified PAC-style framework

12
Standard Supervised Learning Setting
• X – instance/feature space• S={(x, l)} - set of labeled examples
– labeled examples - assumed to be drawn i.i.d. from some distr. D over X and labeled by some target concept c* 2 C
– labels 2 {-1,1} - binary classification
• Classic models for learning from labeled data.
• PAC (Valiant)
• Statistical Learning Theory (Vapnik)
– err(h)=Prx 2 D(h(x) c*(x))
• Want to do optimization over S to find some hypothesis h, but we want h to have small error over D.

13
• E.g., Finite Hypothesis Spaces, Realizable Case
Standard Supervised Learning Setting
Sample Complexity
• In PAC, can also talk about efficient algorithms.

14
Semi-Supervised Learning
• Several methods have been developed to try to use unlabeled data to improve performance, e.g.:
• Transductive SVM [Joachims ’98]
• Co-training [Blum & Mitchell ’98], [Balcan-Blum-Yang’04]
• Graph-based methods [Blum & Chawla01], [ZGL03]
Hot topic in recent years in Machine Learning.
Scattered Theoretical Results…

15
An Augmented PAC model for SSL [BB05]
Different algorithms are based on different assumptions about how data should behave.
Challenge – how to capture many of the assumptions typically used.
Unlabeled data is useful if we have beliefs not only about the form of the target, but also about its relationship with the underlying distribution.
Extends PAC naturally to fit SSL.
Key Insight
• When will unlabeled data help and by how much.
• How much data should I expect to need to perform well.
Can generically analyze:
16
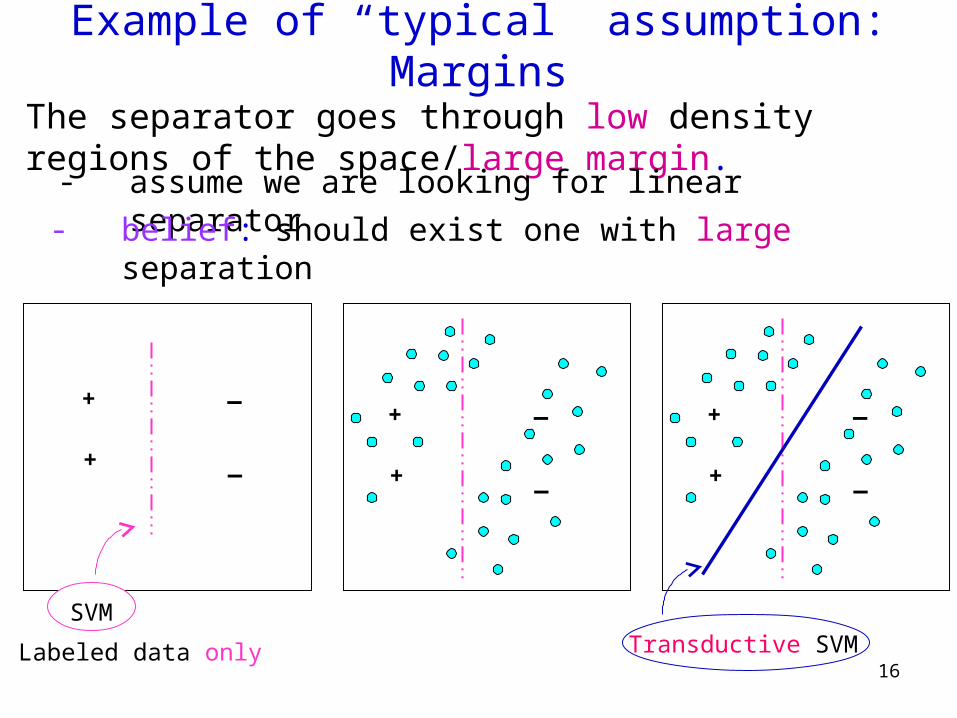
Example of “typical” assumption: Margins
+
+
_
_
Labeled data only
+
+
_
_
+
+
_
_
Transductive SVMSVM
The separator goes through low density regions of the space/large margin.
- assume we are looking for linear separator- belief: should exist one with large separation

17
Another Example: Self-consistency
My Advisor
Prof. Avrim Blum
My Advisor
Prof. Avrim Blum
x1- Text info x2- Link infox - Link info & Text info
x = h x1, x2 i
Agreement between two parts : co-training [BM98].- examples contain two sufficient sets of features, x = h x1, x2 i
For example, if we want to classify web pages:
- the belief is that the two parts of the example are consistent, i.e. 9 c1, c2 such that c1(x1)=c2(x2)=c*(x)

18
Problems thinking about SSL in the PAC model
PAC model talks of learning a class C under (known or unknown) distribution D.
• Doesn’t give you any info about which c 2 C is the
target function.
• Not clear what unlabeled data can do for you.
We extend the PAC model to capture these (and more) uses of unlabeled data.
• Give a unified framework for understanding when and why unlabeled data can help.
Su={xi} - unlabeled examples drawn i.i.d. from D
Sl={(xi, yi)} – labeled examples drawn i.i.d. from D and
labeled by some target concept c*.

19
Proposed Model, Main Idea (1)Augment the notion of a concept class C with a notion of compatibility between a concept and the data distribution.
“learn C” becomes “learn (C,)” (i.e. learn class C under compatibility notion )
Express relationships that one hopes the target function and underlying distribution will possess.
Idea: use unlabeled data & the belief that the target is compatible to reduce C down to just {the highly compatible functions in C}.
+
+
_
_

20
Proposed Model, Main Idea (2)
Idea: use unlabeled data & our belief to reduce size(C) down to size(highly compatible functions in C) in our sample complexity bounds.
Need to be able to analyze how much unlabeled data is needed to uniformly estimate compatibilities well.
Require that the degree of compatibility be something that can be estimated from a finite sample.
Require to be an expectation over individual examples:
• (h,D)=Ex2 D[(h, x)] compatibility of h with D, (h,x)2 [0,1]• errunl(h)=1-(h, D) incompatibility of h with D (unlabeled error rate of h)

21
Margins, Compatibility
Margins: belief is that should exist a large margin separator.
+
+
_
_Highly compatible
Incompatibility of h and D (unlabeled error rate of h) – the probability mass within distance of h.
Can be written as an expectation over individual examples(h,D)=Ex 2 D[(h,x)] where:
(h,x)=0 if dist(x,h) · (h,x)=1 if dist(x,h) ¸

22
Margins, CompatibilityMargins: belief is that should exist a large margin separator.
+
+
_
_Highly compatible
If do not want to commit to in advance, define (h,x) to be a smooth function of dist(x,h), e.g.:
Illegal notion of compatibility: the largest s.t. D has probability mass exactly zero within distance of h.

23
Co-training: examples come as pairs hx1, x2i and the goal is to learn a pair of functions hh1,h2i.
Co-Training, Compatibility
Hope is that the two parts of the example are consistent.Legal (and natural) notion of compatibility: - the compatibility of hh1,h2i and
D:
- can be written as an expectation over examples:

24
Types of Results in the [BB05] Model
As in PAC, can discuss algorithmic and sample complexity issues.
Sample Complexity issues that we can address:
– How much unlabeled data we need:• depends both on the complexity of C and the on the complexity of our notion of compatibility.
- Ability of unlabeled data to reduce # of labeled examples needed:
• compatibility of the target
• (various) measures of the helpfulness of the distribution
Give both uniform convergence bounds and epsilon-cover based bounds.

25
Examples of results: Sample Complexity, Uniform Convergence Bounds
Finite Hypothesis Spaces, Doubly Realizable Case
Bound the # of labeled examples as a measure of the helpfulness of D with respect to
– helpful D is one in which CD, () is small
CD,() = {h 2 C :errunl(h)
·}
ALG: pick a compatible concept that agrees with the labeled sample.

26
Examples of results: Sample Complexity, Uniform Convergence Bounds
Finite Hypothesis Spaces, Doubly Realizable Case
CD,() = {h 2 C :errunl(h)
·}
ALG: pick a compatible concept that agrees with the labeled sample.
Highly compatible +
+_
_

27
Sample Complexity Subtleties
Distr. dependent measure of complexity
Depends both on the complexity of C and on the complexity of
-Cover bounds much better than Uniform Convergence bounds.For algorithms that behave in a specific way:
• first use the unlabeled data to choose a representative set of compatible hypotheses• then use the labeled sample to choose among these
Uniform Convergence Bounds
Highly compatible +
+_
_

28
Sample Complexity Implications of Our Analysis
Ways in which unlabeled data can help
• If c* is highly compatible and have enough unlabeled data, then can reduce the search space (from C down to just those h 2 C whose estimated unlabeled error rate is low).
• By providing an estimate of D, unlabeled data can allow a more refined distribution-specific notion of hypothesis space size (e.g. the size of the smallest -cover).
Subsequent Work, E.g.:
P. Bartlett, D. Rosenberg, AISTATS 2007
J. Shawe-Taylor et al., Neurocomputing 2007

30
Efficient Co-training of linear separators
• Assume independence given the label – both points from D+ or from D-.
• [Blum & Mitchell] show can co-train (in polynomial time) if have enough labeled data to produce a weakly-useful hypothesis to begin with.
• [BB05] shows we can learn (in polynomial time) with only a single labeled example.
• Key point: independence given the label implies that the functions with low errunl rate are:
• close to c*
• close to : c*
• close to the all positive function • close to the all negative function
Idea: use unlabeled data to generate poly # of candidate hyps s.t. at least one is weakly-useful (uses Outlier Removal Lemma). Plug
into [BM98].

33
Semi-supervised learning (SSL)
Active Learning (AL)
Incorporating Unlabeled Data in the Learning Process
Modern Learning Paradigms
- An Augmented PAC model for SSL [Balcan-Blum, COLT 2005][Balcan-Blum, book chapter, “Semi-Supervised Learning”, 2006]
- Generic agnostic AL procedure[Balcan-Beygelzimer-Langford, ICML 2006]
- Margin based AL of linear separators[Balcan-Broder-Zhang, COLT 2007]
[Balcan-Blum-Vempala, MLJ 2006]
- Extensions to Clustering[Balcan-Blum-Vempala, work in progress]
- Connections between kernels, margins and feature selection
- A general theory of learning with similarity functions[Balcan-Blum, ICML 2006]
Modern Learning Paradigms: Our Contributions
Kernel, Similarity based learning and Clustering

34
Semi-supervised learning (SSL)
Active Learning (AL)
Incorporating Unlabeled Data in the Learning Process
Modern Learning Paradigms
Kernel, Similarity based learning and Clustering
- An Augmented PAC model for SSL [Balcan-Blum, COLT 2005][Balcan-Blum, book chapter, “Semi-Supervised Learning”, 2006]
- Generic agnostic AL procedure[Balcan-Beygelzimer-Langford, ICML 2006]
- Margin based AL of linear separators[Balcan-Broder-Zhang, COLT 2007]
[Balcan-Blum-Vempala, MLJ 2006]
- Extensions to Clustering[Balcan-Blum-Vempala, work in progress]
- Connections between kernels, margins and feature selection
- A general theory of learning with similarity functions[Balcan-Blum, ICML 2006]
Modern Learning Paradigms: Our Contributions

Part II, Similarity Functions for Learning
[Balcan-Blum, ICML 2006]
Extensions to Clustering
(With Avrim and Santosh, work in progress)

36
Kernels and Similarity Functions
• Useful in practice for dealing with many different kinds of data.
• Elegant theory about what makes a given kernel good for a given learning problem.
Our Work: analyze more general similarity functions.
• In the process we describe ways of constructing good data dependent kernels.
Kernels have become a powerful tool in ML.

37
Kernels• A kernel K is a pairwise similarity function s.t. 9 an implicit mapping s.t. K(x,y)=(x) ¢ (y).
• Point is: many learning algorithms can be written so only interact with data via dot-products.
• If replace x¢y with K(x,y), it acts implicitly as if data was in higher-dimensional -space.
• If data is linearly separable by large margin in -space, don’t have to pay in terms of data or comp time.
If margin in -space, only need 1/2 examples to learn well.
w
(x)
1

38
General Similarity Functions
We provide: characterization of good similarity functions for a learning problem that:
1) Talks in terms of natural direct properties:
• no implicit high-dimensional spaces• no requirement of positive-
semidefiniteness2) If K satisfies these properties for our given
problem, then has implications to learning.
3) Is broad: includes usual notion of “good kernel”.
(induces a large margin separator in -space)

39
A First Attempt: Definition satisfying properties (1) and (2)
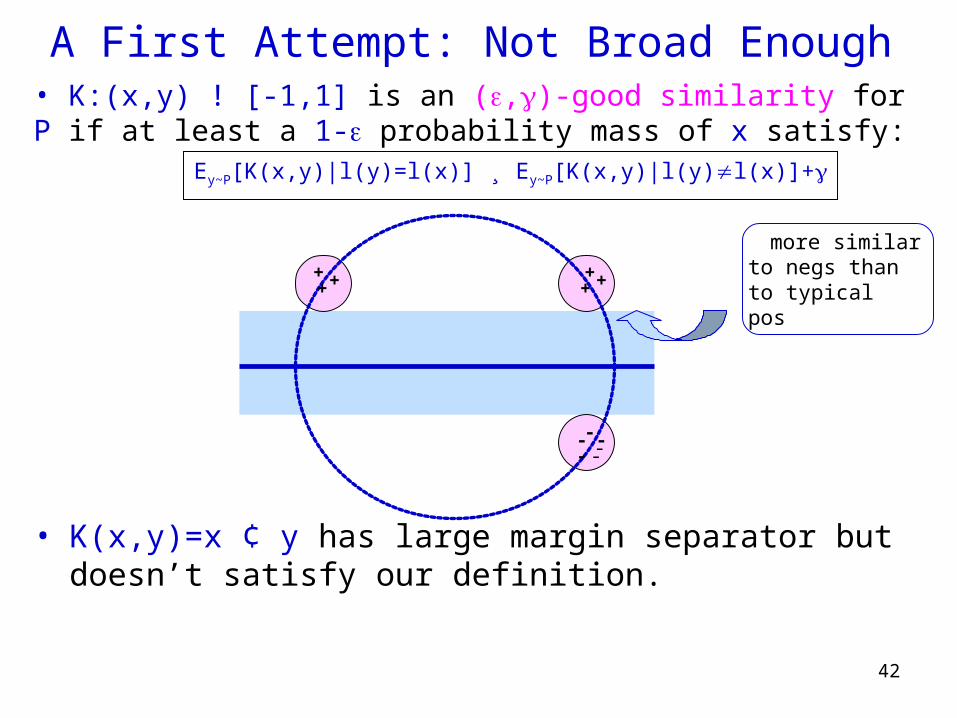
• K:(x,y) ! [-1,1] is an (,)-good similarity for P if at least a 1- probability mass of x satisfy:
Ey~P[K(x,y)|l(y)=l(x)] ¸ Ey~P[K(x,y)|l(y)l(x)]+
Note: this might not be a legal kernel.
• Suppose that positives have K(x,y) ¸ 0.2, negatives have K(x,y) ¸ 0.2, but for a positive and a negative K(x,y) are uniform random in [-1,1].
Let P be a distribution over labeled examples (x, l(x))
A
BC
+
--

40
A First Attempt: Definition satisfying properties (1) and (2). How to use it?
• K:(x,y) ! [-1,1] is an (,)-good similarity for P if at least a 1- probability mass of x satisfy:
Ey~P[K(x,y)|l(y)=l(x)] ¸ Ey~P[K(x,y)|l(y)l(x)]+
Algorithm
• Draw S+ of O((1/2) ln(1/2)) positive examples.• Draw S- of O((1/2) ln(1/2)) negative examples.• Classify x based on which gives better score.

41
A First Attempt: How to use it?• K:(x,y) ! [-1,1] is an (,)-good similarity for P if at least a 1- probability mass of x satisfy:
Algorithm
• Draw S+ of O((1/2) ln(1/2)) positive examples.• Draw S- of O((1/2) ln(1/2)) negative examples.• Classify x based on which gives better score.
• Hoeffding: for any given “good x”, probability of error w.r.t. x (over draw of S+, S-) at most 2.
• By Markov, at most chance that the error rate over GOOD is more than . So overall error rate · + .
Guarantee: with probability ¸ 1-, error · + Proof
Ey~P[K(x,y)|l(y)=l(x)] ¸ Ey~P[K(x,y)|l(y)l(x)]+
42
A First Attempt: Not Broad Enough• K:(x,y) ! [-1,1] is an (,)-good similarity for P if at least a 1- probability mass of x satisfy:
Ey~P[K(x,y)|l(y)=l(x)] ¸ Ey~P[K(x,y)|l(y)l(x)]+
• K(x,y)=x ¢ y has large margin separator but doesn’t satisfy our definition.
+ +++++
-- -- --
more similar to negs than to typical pos

43
A First Attempt: Not Broad Enough• K:(x,y) ! [-1,1] is an (,)-good similarity for P if at least a 1- probability mass of x satisfy:
Idea: would work if we didn’t pick y’s from top-left.
Broaden to say: OK if 9 non-negligable region R s.t. most x are on average more similar to y2R of same label than to y2 R of other label.
Ey~P[K(x,y)|l(y)=l(x)] ¸ Ey~P[K(x,y)|l(y)l(x)]+
R+ ++++
+
-- -- --

44
Broader/Main Definition
• K:(x,y) ! [-1,1] is an (,)-good similarity for P if exists a weighting function w(y) 2 [0,1] at least a 1- probability mass of x satisfy:
Ey~P[w(y)K(x,y)|l(y)=l(x)] ¸ Ey~P[w(y)K(x,y)|l(y)l(x)]+

45
Main Definition, How to Use It• K:(x,y) ! [-1,1] is an (,)-good similarity for P if exists a weighting function w(y) 2 [0,1] at least a 1- probability mass of x satisfy:
Ey~P[w(y)K(x,y)|l(y)=l(x)] ¸ Ey~P[w(y)K(x,y)|l(y)l(x)]+
Algorithm
• Draw S+={y1, , yd}, S-={z1, , zd}, d=O((1/2) ln(1/2)).
• Use to “triangulate” data:
F(x) = [K(x,y1), …,K(x,yd), K(x,zd),…,K(x,zd)].
• Take a new set of labeled examples, project to this space, and run your favorite alg for learning lin. separators.
Point is: with probability ¸ 1-, exists linear separator of error · + at margin /4.
(w = [w(y1), …,w(yd),-w(zd),…,-w(zd)])

46
Main Definition, Implications
Algorithm
• Draw S+={y1, , yd}, S-={z1, , zd}, d=O((1/2) ln(1/2)).• Use to “triangulate” data:F(x) = [K(x,y1), …,K(x,yd), K(x,zd),…,K(x,zd)].
Guarantee: with prob. ¸ 1-, exists linear separator of error · + at margin /4.
Implications legal kernel
K arbitrary sim. function
(,)-good sim. function
(+,/4)-good kernel function

47
Good Kernels are Good Similarity Functions
Main Definition: K:(x,y) ! [-1,1] is an (,)-good similarity for P if exists a weighting function w(y) 2 [0,1] at least a 1- probability mass of x satisfy:
Ey~P[w(y)K(x,y)|l(y)=l(x)] ¸ Ey~P[w(y)K(x,y)|l(y)l(x)]+
• An (,)-good kernel is an (’,’)-good similarity function under main definition.
Theorem
Our proofs incurred some penalty: ’ = + extra, ’ = 3extra.
Nati Srebro (COLT 2007) has improved the bounds.

50
Learning with Multiple Similarity Functions
• Let K1, …, Kr be similarity functions s. t. some (unknown) convex combination of them is (,)-good.
• Draw S+={y1, , yd}, S-={z1, , zd}, d=O((1/2) ln(1/2)).
• Use to “triangulate” data:
F(x) = [K1(x,y1), …,Kr(x,yd), K1(x,zd),…,Kr(x,zd)].
Guarantee: The induced distribution F(P) in R2dr has a separator of error · + at margin at least
Algorithm
Sample complexity is roughly

51
Implications• Theory that provides a formal way of understanding
kernels as similarity functions.• Algorithms work for sim. fns that aren’t necessarily PSD.
• Suggests natural approach for using similarity functions to augment feature vector in “anytime” way.– E.g., features for document can be list of words in it,
plus similarity to a few “landmark” documents.
• Formal justification for “Feature Generation for Text Categorization using World Knowledge”, GM’05 Mugizi has
proposed on this

Clustering via Similarity Functions
(Work in Progress, with Avrim and Santosh)

53
Consider the following setting:• Given data set S of n objects.
• There is some (unknown) “ground truth” clustering. Each x has true label l(x) in {1,…,t}.
• Goal: produce hypothesis h of low error up to isomorphism of label names.
What if only unlabeled examples available?
[documents,web pages]
[topic]
People have traditionally considered mixture models here.
Can we say something in our setting?

54
What if only unlabeled examples available?
For all clusters C, C’, for all A in C, A’ in C’: A and A’ are not both more attracted to
each other than to their own clusters.K(x,y) is
attraction between x
and y
• Suppose our similarity function satisfies the stronger condition:
• Ground truth is “stable” in that
• Then, can construct a tree (hierarchical clustering) such that the correct clustering is some pruning of this tree.

55
What if only unlabeled examples available?
For all clusters C, C’, for all A in C, A’ in C’: A and A’ are not both more attracted to
each other than to their own clusters.K(x,y) is
attraction between x
and y
• Suppose our similarity function satisfies the stronger condition:
• Ground truth is “stable” in that
sports fashion
soccervolleyball
gymnastics
Dolce & Gabbana
Cocco Chanel

56
Main point• Exploring the question: what are minimal conditions on a
similarity function that allow it to be useful for clustering?
a. List Clustering -- small number of candidate clusterings.
b. Hierarchical clustering -- output a tree such that right answer is some pruning of it.
• Allow for right answer to be identified with a little bit of additional feedback.
• Have considered two relaxations of the Clustering objective:

57
Active Learning
Incorporating Unlabeled Data in the Learning Process
Modern Learning Paradigms
Kernel, Similarity based learning and Clustering
- Margin based AL of linear separators
Clustering via Sim. Functions
Can we get an efficient alg. for the stability of large subsets property
Learning with Sim. Functions
Modern Learning Paradigms: Future Work
Extend the analysis to a more generalclass of distributions, e.g. log-concave.
Alternative/tighter definitionsand connections.
Interactive Feedback

58
MLA and Algorithmic Game Theory, Future Work
Mechanism Design, ML, and Pricing Problems
Extend BBHM’05 to the limited supply setting.
Approximation algorithms for the case of pricing below cost.
Revenue maximization in comb. auctions with general preferences.

59
Timeline• Plan to finish in a year
Wrap-up; writing; job search!Spring 08
- Clustering via Similarity Functions- Active Learning under Log-Concave Distributions
Fall 07
- Revenue Maximization in General Comb. Auctions, limited and unlimited supply.
Summer 07

60




















![Guiding dynamics in potential games Avrim Blum Carnegie Mellon University Joint work with Maria-Florina Balcan and Yishay Mansour [Cornell CSECON 2009]](https://img.pdfslide.us/doc/110x75/56649de55503460f94adcaa7/guiding-dynamics-in-potential-games-avrim-blum-carnegie-mellon-university-joint.jpg)








