Embed Size (px)
Citation preview

Learning Submodular Functions
Maria Florina Balcan
LGO, 11/16/2010

f(S)+f(T) ¸ f(S Å T) + f(S [ T), 8 S,Tµ V
Submodular functions
V={1,2, …, n}; set-function f : 2V ! R
Decreasing marginal returnf(T [ {x})-f(T)¸ f(S [ {x})-f(S), 8 S,Tµ V, T µ S, x not in T
• Concave Functions Let h : R ! R be concave. For each S µ V, let f(S) = h(|S|)
• Vector Spaces Let V={v1,,vn}, each vi 2 Fn.
For each S µ V, let f(S) = rank(V[S])
Examples:

3
Submodular set functions• Set function f on V is called submodular if
For all S,T µ V: f(S)+f(T) ¸ f(S[T)+f(SÅT)
• Equivalent diminishing returns characterization:
xS Tx
+
+
Large improvement
Small improvement
For TµS, xS, f(T [ {x}) – f(T) ¸ f(S [ {x}) – f(S)
Submodularity:
TS S [ TSÅT
++ ¸

4
Example: Set cover
Node predictsvalues of positionswith some radius
SERVER
LAB
KITCHEN
COPYELEC
PHONEQUIET
STORAGE
CONFERENCE
OFFICEOFFICE
For S µ V: f(S) = “area (# locations) covered by sensors placed at S”
Formally: W finite set, collection of n subsets Wi µ W
For S µ V={1,…,n} define f(S) = |i2 S Wi|
Want to cover floorplan with discsPlace sensorsin building Possible
locations V

5
Set cover is submodular
SERVER
LAB
KITCHEN
COPYELEC
PHONEQUIET
STORAGE
CONFERENCE
OFFICEOFFICE
SERVER
LAB
KITCHEN
COPYELEC
PHONEQUIET
STORAGE
CONFERENCE
OFFICEOFFICE
W1 W2
W1 W2
W3
W4 x
x
T={W1,W2}
S = {W1,W2,W3,W4}
f(T[{x})-f(T)
f(S[{x})-f(S)
¸

f(S)+f(T) ¸ f(S Å T) + f(S [ T), 8 S,Tµ V
Submodular functions
V={1,2, …, n}; set-function f : 2V ! R
Decreasing marginal returnf(T [ {x})-f(T)· f(S [ {x})-f(S), 8 S,Tµ V, S µ T, x not in T
• Concave Functions Let h : R ! R be concave. For each S µ V, let f(S) = h(|S|)
• Vector Spaces Let V={v1,,vn}, each vi 2 Fn.
For each S µ V, let f(S) = rank(V[S])
Examples:

f(S)+f(T) ¸ f(S Å T) + f(S [ T), 8 S,Tµ V
Submodular functions
V={1,2, …, n}; set-function f : 2V ! R
f(S) · f(T) , 8 S µ T
f(S) ¸ 0, 8 S µ V Non-negative:
Monotone:

Submodular functions
• A lot of work on optimization and submodularity.
• Substantial interest in the ML community recently.
• Tutorials, workshops at ICML, NIPS, etc.
• www.submodularity.org/ owned by ML.
• Algorithmic game theory
• decreasing marginal utilities.
• Can be minimized in polynomial time.

Learnability of Submodular Fns
Important to also understand their learnability.
• Algorithm allowed to (adaptively) pick sets and query the value of the target on those sets.
Goemans, Harvey, Iwata, Mirrokni, SODA 2009
• Can we learn the target with a polynomial number of queries in poly time?
Exact learning with value queries Previous Work:
• There is an unknown submodular target function.
Output a function that approximates the target within a factor of ® on every single subset.
[GHIM’09] Model

Exact learning with value queries
9 an alg. for learning a submodular function with an approx. factor O(n1/2).
Any alg. for learning a submodular must have an approx. factor of (n1/2).
Theorem: (General lower bound)
Theorem: (General upper bound)
Goemans, Harvey, Iwata, Mirrokni, SODA 2009

Problems with the GHIM model
- Lower bound fails if our goal is to do well on most of the points.
- Well known that value queries are undesirable in some learning applications.
Is there a better model that gets around these problems?
- Many simple functions that are easy to learn in the PAC model (e.g., conjunctions) are impossible to get exactly from a poly number of queries

Problems with the GHIM model
- Lower bound fails if our goal is to do well on most of the points.
- Well known that value queries are undesirable in some learning applications.
Learning submodular fns in a distributional learning setting [BH10]
- Many simple functions that are easy to learn in the PAC model (e.g., conjunctions) are impossible to get exactly from a poly number of queries

Labeled Examples
Our model: Passive Supervised Learning
Learning Algorithm
Expert / Oracle
Data Source
Alg.outputs
Distribution D on {0,1}n
f : {0,1}n R+
(x1,f(x1)),…, (xk,f(xk))
g : {0,1}n R+

Our model: Passive Supervised Learning
Distribution D on {0,1}n
Labeled Examples
Learning Algorithm
Expert / Oracle
Data Source
Alg.outputsf : {0,1}n
R+g : {0,1}n R+
(x1,f(x1)),…, (xk,f(xk))
• Algorithm sees (x1,f(x1)),…, (xk,f(xk)), xi i.i.d. from D
“Probably Mostly Approximately Correct”
• Algorithm produces “hypothesis” g. (Hopefully g ¼ f)Prx1,…,xm[ Prx[g(x) · f(x)· ® g(x)]¸ 1-²] ¸ 1-±

Main results
9 an alg. for PMAC-learning the class of non-negative, monotone, submodular fns (w.r.t. an arbitrary distribution) with an approx. factor O(n1/2).
No algorithm can PMAC learn the class of non-neg., monotone, submodular fns with an approx. factor õ(n1/3).
Theorem: (Our general lower bound)
Theorem: (Our general upper bound)
Much simpler alg. compared to GIHM’09
Note: The GIHM’09 lower bound fails in our model.
Note:
Matroid rank functions, const. approx.
Theorem: (Product distributions)

A General Upper Bound
Theorem:
9 an alg. for PMAC-learning the class of non-negative, monotone, submodular fns (w.r.t. an arbitrary distribution) with an approx. factor O(n1/2).

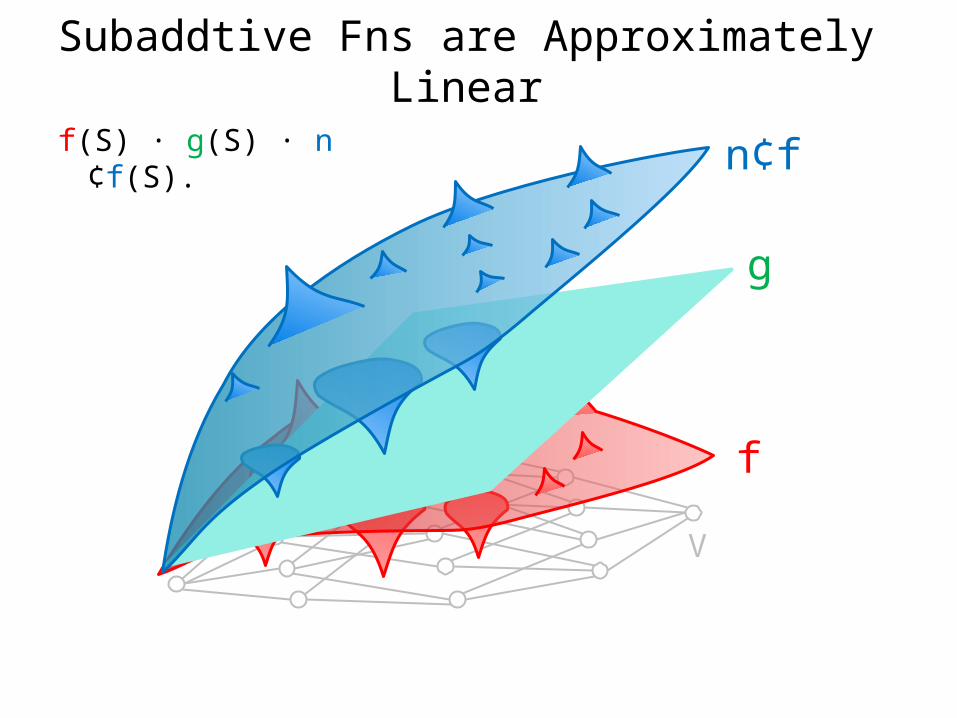
Subaddtive Fns are Approximately Linear
• Let f be non-negative, monotone and subadditive• Claim: f can be approximated to within factor n
by a linear function g.
Subadditive: f(S)+f(T) ¸ f(S[ T) 8 S,T µ V Monotonicity: f(S) · f(T) 8 Sµ T
Non-negativity: f(S) ¸ 0 8 S µ V
• Proof Sketch: Let g(S) = s in S f({s}).Then f(S) · g(S) · n ¢ f(S).
V
Subaddtive Fns are Approximately Linear
f
n¢f
g
f(S) · g(S) · n¢f(S).

• f non-negative, monotone, subadditive approximated to within factor n by a linear function g,g (S) =w ¢ Â (S).
• Labeled examples ((Â(S), f(S) ), +) and ((Â(S), n¢f(S) ), -) are linearly separable in Rn+1.
• Idea: learn a linear separator. Use std sample complex.
PMAC Learning Subadditive Fns
• Problem: data not i.i.d.• Solution: create a related distribution.
Sample S from D; flip a coin.
• If heads add ((Â(S), f(S) ), +).
• Else add ((Â(S), n¢f(S) ), -).

Input: (S1, f(S1)) …, (Sm, f(Sm))
• For each Si, flip a coin.
Algorithm:PMAC Learning Subadditive Fns
• If heads add ((Â(S), f(Si) ), +).
• Else add ((Â(S), n¢f(Si) ), -).
• Theorem: For m = £(n/²), g approximates f to within a factor n on a 1-² fraction of the distribution.
• Learn a linear separator u=(w,-z) in Rn+1.
Output: g(S)=1/(n+1) w ¢ Â (S).
Note: Deal with the
set {S:f(S)=0 } separately.

Input: (S1, f(S1)) …, (Sm, f(Sm))
• For each Si, flip a coin.
Algorithm:PMAC Learning Submodular Fns
• If heads add ((Â(S), f2(S_i)) ), +).• Else add ((Â(S), n f2(S_i) ),
-).• Learn a linear separator u=(w,-z) in Rn+1.
Output: g(S)=1/(n+1)1/2 w ¢ Â (S)
• Theorem: For m = £(n/²), g approximates f to within a factor \sqrt{n} on a 1-² fraction of the distribution.
Proof idea: f non-negative, monotone, submodular approximated to within factor \sqrt{n} by a \sqrt{linear function}.
[GHIM, 09]
Note: Deal with the
set {S:f(S)=0 } separately.

Input: (S1, f(S1)) …, (Sm, f(Sm))
• For each Si, flip a coin.
Algorithm:PMAC Learning Submodular Fns
• If heads add ((Â(S), f2(S_i)) ), +).• Else add ((Â(S), n f2(S_i) ),
-).• Learn a linear separator u=(w,-z) in Rn+1.
Output: g(S)=1/(n+1)1/2 w ¢ Â (S)
• Much simpler than [GIHM09]. More robust to variations.
Note: Deal with the
set {S:f(S)=0 } separately.
• the target only needs to be within an ¯ factor of a submodular fnc.
• 9 a submodular fnc that agrees with target on all but a ´ fraction of the points (on the points it disagrees it can be arbitrarily far).[the alg is inefficient in this
case]

A General Lower Bound
Use the fact that any matroid rank fnc is submodular.Construct a hard family of matroid rank functions.
A1 A2 ALA3
X
X X
Low=log2n
High=n1/3
X
… … …. ….
L=nlog log n
Plan:
No algorithm can PMAC learn the class of non-neg., monotone, submodular fns with an approx. factor õ(n1/3).
Theorem: (Our general lower bound)

Ind={I: |I Å Aj| · uj, for all j }
Partition Matroids
• E.g., n=5, A1={1,2,3}, A2={3,4,5}, u1=u2=2.
A1, A2, …, Ak µ V={1,2, …, n}, all disjoint; ui · |Ai|-1
Then (V, Ind) is a matroid.
If sets Ai are not disjoint, then (V,Ind) might not be a matroid.
• {1,2,4,5} and {2,3,4} both maximal sets in Ind; do not have the same cardinality.

Almost partition matroids
k=2, A1, A2 µ V (not necessarily disjoint); ui · |Ai|-1
Then (V,Ind) is a matroid.
Ind={I: |I Å Aj| · uj , |I Å (A1 [ A2)| · u1 +u2 - |A1 Å A2|}

Almost partition matroids
More generally
Ind= { I: |I Å A(J)| · f(J), 8 J µ [k] }
f(J)= j 2 J uj +|A(J)|-j 2 J|Aj|, 8 J µ [k]
f : 2[k] ! Z
Then (V, Ind) is a matroid (if nonempty).
Rewrite f, f(J)=|A(J)|-j 2 J(|Aj| - uj), 8 J µ [k]
=<0A1, A2, …, Ak µ V={1,2, …, n}, ui · |Ai|-1;

A generalization of partition matroids
Proof technique:
More generally
Ind= { I: |I Å A(J)| · f(J), 8 J µ [k] }
f(J)=|A(J)|-j 2 J(|Aj| - uj), 8 J µ [k]
f : 2[k] ! Z
Then (V, Ind) is a matroid (if nonempty).
Uncrossing argument
For a set I, define T(I) to be the set of tight constraints
T(I)= {J µ [k], |I Å A(J)|=f(J)}
8 I 2 Ind, J1, J2 2 T(I), then (J1 [ J2 2 T(I)) or (J1 Å J2 =)
Ind is the family of independent sets of a matroid.

A generalization of almost partition matroids
Note: This requires k· n (for k > n, f becomes negative)
Do some sort of truncation to allow k>>n.
Ind= { I: |I Å A(J)| · h(J), 8 J µ [k] }
f(J)=|A(J)|-j 2 J(|Aj| -uj), 8 J µ [k]; ui · |Ai|-1 f : 2[k] ! Z,
Then (V,Ind) is a matroid (if nonempty).
f(J) is (¹, ¿) good if f(J) ¸ 0 for J µ [k], |J| · ¿ and
f(J) ¸ ¹ for J µ [k], ¿ ·|J| · 2¿ -2
h(J)=f(J) if |J| · ¿ and h(J)=¹, otherwise.
But we want k=n^{log log n}.

A generalization of partition matroids
Let L = nlog log n. Let A1, A2, …, AL be random subsets of V. (Ai -- include each elem of V indep with prob n-
2/3. )
Each subset J µ {1,2, …, L} induces a matroid s.t. for any i not in J, Ai is indep in this matroid
Let ¹=n^{1/3} log2 n, u=log2 n, ¿=n1/3
• Rank(Ai), i not in J, is roughly |Ai| (i.e., £(n^{1/3})),
A1 A2 ALA3
X
X X
Low=log2n
High=n1/3
X
… … …. ….
L=nlog log n
• The rank of sets Aj, j in J is u=log2 n.

Product distributions, Matroid Rank Fns
P [jR ¡ E(R)j ¸ (®+ 1=4)E(R)] · 4e¡ ®2E(R)=12
Talagrand implies: Let D be a product distribution on V, R=rank(X), X drawn
from D. If E[R] ¸ 4000,
If E[R]· 500 log(1/²),
P [R ¸ 1200log(1=²)] · ²
Related Work:
• [Chekuri, Vondrak ’09] and [Vondrak ’10] prove a slightly more general result by two different techniques

Product distributions, Matroid Rank Fns
P [jR ¡ E(R)j ¸ (®+ 1=4)E(R)] · 4e¡ ®2E(R)=12
• Let ¹= i=1m f (xi) / m
• Let g be the constant function with value ¹
Talagrand implies:
• This achieves approximation factor O(log(1/²)) on a 1-² fraction of points, with high probability.
Let D be a product distribution on V, R=rank(X), X drawn from D. If E[R] ¸ 4000,
Algorithm:
If E[R]· 500 log(1/²),
P [R ¸ 1200log(1=²)] · ²

Conclusions and Open Questions
Open questions
• Analyze intrinsic learnability of submodular fns
• Our analysis reveals interesting novel extremal and structural properties of submodular fns.
• Improve (n1/3) lower bound to (n1/2)
• Non-monotone submodular functions

Other interesting structural properties
• Let h : R ! R+ be concave, non-decreasing. For each Sµ V, let f(S) = h(|S|)
;
V
Claim: These functions f are submodular, monotone, non-negative.

Theorem: Every submodular function looks like this.
Lots of approximatelyusually.
;
V

Theorem: Every submodular function looks like this.Lots of approximately
usually.
Let f be a non-negative, monotone, submodular, 1-Lipschitz function.For any ²>0, there exists a concave function h : [0,n] ! R s.t.for every k2[0,n], and for a 1-² fraction of SµV with |S|=k,we have:
h(k) · f(S) · O(log2(1/²))¢h(k).
;
V
Proof: Based on Talagrand’s Inequality.In fact, h(k) is just E[ f(S) ], where S is uniform on sets of size k.
Theorem

Conclusions and Open Questions
Open questions
• Analyze intrinsic learnability of submodular fns
• Our analysis reveals interesting novel extremal and structural properties of submodular fns.
• Improve (n1/3) lower bound to (n1/2)
Any algorithm?Lower bound better than (n1/3)
• Non-monotone submodular functions





























