Embed Size (px)
Citation preview

Literature Mining BMI 730
Kun HuangDepartment of Biomedical Informatics
Ohio State University

Announcement
• HW #3 is cancelled. The grades will be adjusted accordingly.

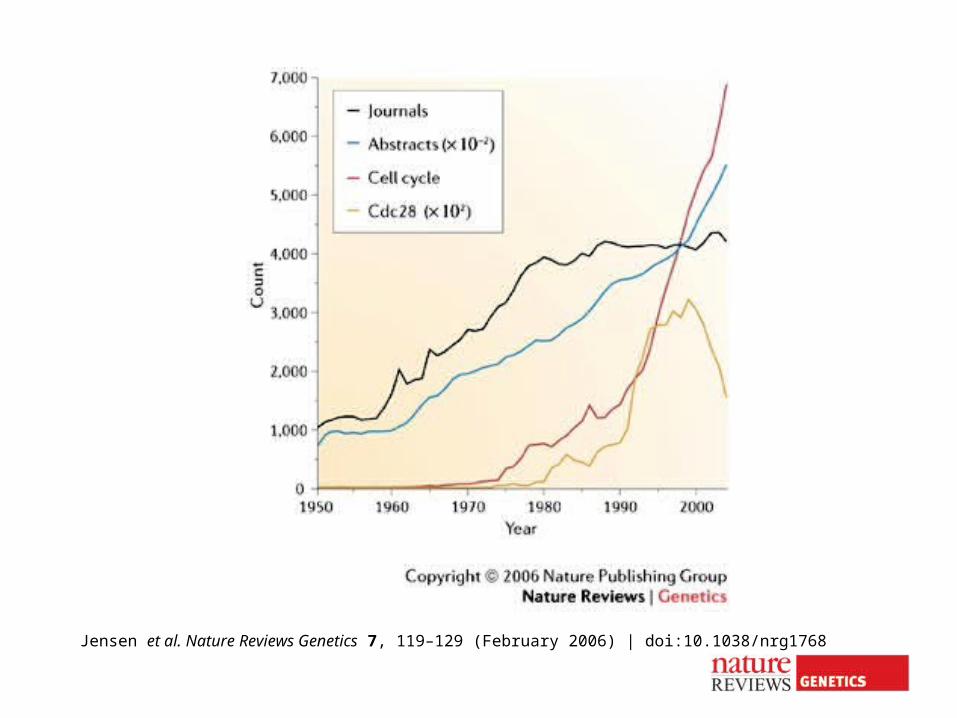
Jensen et al. Nature Reviews Genetics 7, 119–129 (February 2006) | doi:10.1038/nrg1768
Acknowledgement

Acknowledgement
• Dr. Hongyu Peng (Brandies Univ.)• Dr. Hagit Shatkay (
http://www.shatkay.org)
provided part of the slides.

Connecting the dots
• Story of Thalidomide (from sedative to birth defects to anti-cancer drug)
Jensen et al. Nature Reviews Genetics 7, 119–129 (February 2006) | doi:10.1038/nrg1768

Jensen et al. Nature Reviews Genetics 7, 119–129 (February 2006) | doi:10.1038/nrg1768

Information Retrieval (IR)• Finding the papers• IR systems aim to identify the text
segments (be it full articles, abstracts, paragraphs or sentences) that pertain to a certain topic (e.g., yeast cell cycle).
• E.g., PubMed, Google Scholar• Ad hoc IR• Text categorization (pre-defined set of
papers)• Advanced – integrate Entity Recognition

Ad Hoc IR• User provide query • Boolean model• Index based (e.g. “Gene and CD”)
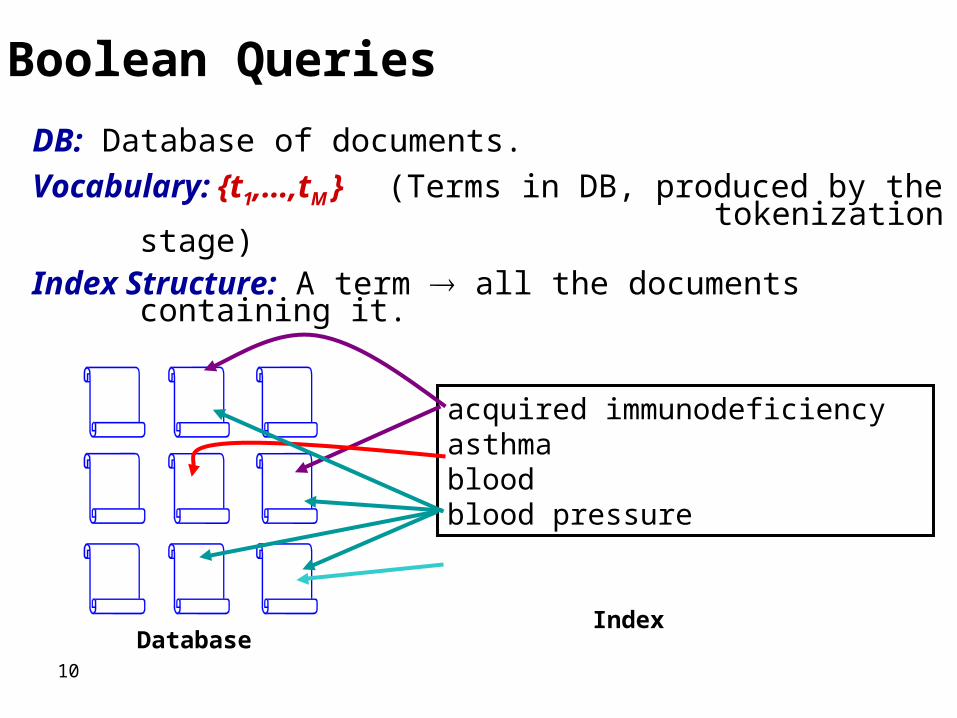
10
DB: Database of documents.
Vocabulary: {t1,…,tM } (Terms in DB, produced by the tokenization stage)
Index Structure: A term all the documents containing it.
Boolean Queries
acquired immunodeficiencyasthmabloodblood pressure
IndexDatabase

Ad Hoc IR• User provide query • Boolean model• Challenges
CD
Chagas' disease
cytosine deaminase
Crohn‘s disease
capillary density
Cortical dysplasia
(54,745 Pubmed entries)
compact disk...
Synonymy (AGP1, aka, Amino Acid Permease1)
Polysemy

• Similarity query, e.g., Vector based. Semantic search
TIME (Sept 5, 2005): Search engines are good at matching words … The next step is semantic search – looking for meaning, not just matching key words. … Nervana, which analyzes language by linking word patterns contextually to answer questions in defined subject areas, such as medical-research literature.
Ad Hoc IR• User provide query • Vector-based model

13
DB: Database of documents.
Vocabulary: {v1,…,vM } {Terms in DB}
Document dDB: Vector, <w1d,…,wM
d>, of weights.
The Vector Model
Weighting Principles
• Document frequency: Terms occurring in a few documents are more useful than terms occurring in many.
• Local term frequency: Terms occurring frequently within a document are likely to be significant for the document.
• Document length: A term occurring the same # of times in a long document and in a short one has less significance in the long one.
• Relevance: Terms occurring in documents judged as relevant to a query, are likely to be significant (WRT the query).
[Sparck Jones et al. 98]

Some Weighting Schemes:
Binary
TF Wid = fi
d = # of times ti occurs in d.
Wid=
fid
fi
(fi= # of docs containing ti)
TF X IDF(one version...)
Wid =
1 if ti d
0 otherwise
Consider Local term frequency
Consider Local term frequency and (Inverse) Document frequency

Document d= <w1d,…,wM
d>DB
Query q = < w1q,…,wM
q> (q could itself be a document in DB...)
Vector-Based similarity
Sim(q, d) = cosine (q, d ) =
q • d
|q| |d|
d
q
[Salton89, Witten et al99] Introductory IR.

[Sparck Jones et al. 98, Sahami98, Ponte&Croft 98, Hoffman 99]
Probabilistic Models
Query q ; Document d
Log[Log[PP(relevant | (relevant | dd, , qq))
PP(Irrelevant | (Irrelevant | dd, , qq)) ]]Maximize log-odds:Maximize log-odds:
• Goal:Goal: Find all Find all dd’s such that ’s such that PP(relevant | (relevant | dd, , qq) is high) is high

17
Latent Semantics Analysis [Dumais, Deerwester et al,1988,1990]
Motivation: Overcoming synonymy and polysemy.Reducing dimensionality.
Idea: Project from “explicit term” space to a lower dimension, “abstract concept” space.
Methodology: PCA applied to the document-term matrix. Highest singular values are used as the features for representing documents.

18
Information Retrieval- Details(cont.)
Text Categorization (semantic)
Automatically place documents in right categories so as to make them easy-to-find.
......
Cancer
Apoptosis Elongation

19
Information Retrieval-Details(cont.)
Rule-Based Text ClassificationA knowledge-engineering approach. Boolean rules (DNF), based on the presence/absence of specific terms within the document, decide its membership in the class. (e.g. the CONSTRUE system [Hayes et al. 90,92] )
Example: If ( (<GENE_Name> ⋀ transcript) ⋁ ((<GENE_Name> Western Blot) ⋀ ⋁ ((<GENE_Name> Northern Blot))⋀ Then GeneExpressionDoc Else Gene⌝ ExpressionDoc

20
Information Retrieval-Details(cont.)
Machine Learning for Text Classification (supervised)
• Take a training set of pre-classified documents• Build a model for the classes from the training examples• Assign each new document to the class that best fits it
(e.g. closest or most-probable class.)
Types of class assignment:
Hard: Each document belongs to exactly one class
Soft: Each document is assigned a “degree of membership” in several classes
Methods
Nearest neighbor
Summarizing document vectors
SVM, Bayesian, boosting

21
Evaluating Extraction and Retrieval
To say how good a system is we need:1. Performance metrics (numerical measures)2. Benchmarks, on which performance is
measured (the gold-standard).

22
Evaluating Extraction and Retrieval(cont.)
Performance Metrics
N items (e.g. documents, terms or sentences) in the collection
REL: Relevant items (documents, terms or sentences) in the collection.These SHOULD be extracted or retrieved.
RETR: Retrieved items (e.g. documents, terms or sentences) are actually extracted/retrieved
Some correctly (A = |REL ⋀ RETR|),Some incorrectly (B = |RETR – REL| )|RETR| = A+B

23
Evaluating Extraction and Retrieval(cont.)
Performance Metrics (cont.)
|RETR – REL| = B
Collection
REL RETR
|REL RETR| = ⋀ A
|Collection| = N
|REL-RETR| = D
|NotREL – RETR| = C

24
Performance Metrics (cont.)
Precision: P = A/(A+B)
How many of the retrieved/extracted items are correct
Recall: R = A/(A+D)
How many of the items that should be retrieved are recovered
Accuracy: (A+C)/N (Ratio of Correctly classified items)
F-score: 2PR / (P+R)
Harmonic mean, in the range [0,1]
Combination Scores:
Fβ-score: (1+β2)PR / (β2·P + R)β >1 Prefer recall, β <1 Prefer precision
E-measure: 1 – F(β)-scoreInversely proportional to performance (Error measure).

25
Performance Metrics (cont.)
Precision-Recall Curves
4 relevant documents in the collection.
7 retrieved and ranked.
1
7
6
5
4
3
225% Recall
50%
75%
100%
6675
66
100
0102030405060708090
100
0 25 50 75 100
Recall
Pre
cisi
on

26
Performance Metrics (cont.)
Average ScoresAverage Precision: Average the precision over all the ranks in which a relevant document is retrieved.
Mean Average Precision: Mean of the Average Precision over all the queries.Micro-Average: Average over individual items across queriesMacro-Average: Average over queries
For a given rank n, Pn: Precision at rank n (P@n)
R-Precision: PR where R is the number of relevant documents
Accounting for Ranks

Jensen et al. Nature Reviews Genetics 7, 119–129 (February 2006) | doi:10.1038/nrg1768

Entity Recognition (ER)• Identifying the substance(s)• Rule and contextual based approach
(manual) – e.g., ‘-ase’ for enzyme• Rule and contextual based approach
(machine learning)• Dictionary-based approach
• How the names are written - CDC28, cdc28, cdc28p, cdc-28
• Curation of the dictionary

Entity Recognition (ER)• Major Challenge
Lack of standardization of names• ‘cdc2’ refers to two completely unrelated
genes in budding and fission yeast• ‘SDS’ - serine dehydratase gene vs. Sodium
Dodecyl Sulfate vs. Shwachman-Diamond syndrome
Synonymy (AGP1, aka, Amino Acid Permease1) Polysemy

Entity Recognition (ER)• Simpler version – if this symbol is for
gene or its product• iHOP (Information hyperlinked over
proteins) http://www.pdg.cnb.uam.es/UniPub/iHOP

Vocabulary• Many, many• SNOWMED, ICD, …• ICD (
International Statistical Classification of Diseases and Related Health Problems)

Vocabulary• ICD
573.3 Hepatitis, unspecifiedToxic (noninfectious) hepatitisUse additional E code to identify cause
571.4 Chronic hepatitisExcludes:
viral hepatitis (acute) (chronic) (070.0-070.9)
571.49 OtherChronic hepatitis:
activeaggressive
Recurrent hepatitis
070 Viral hepatitisIncludes:
viral hepatitis (acute) (chronic)Excludes:
cytomegalic inclusion virus hepatitis (078.5)

Unified Medical Language system (UMLS)

Jensen et al. Nature Reviews Genetics 7, 119–129 (February 2006) | doi:10.1038/nrg1768

Information Extraction (IE)• Extract pre-defined types of fact — in
particular, relationships between biological entities.
• Co-occurrence based method• Natural language processing (NLP) based
method

36
Information Extraction
• Identify the relevant sentences• Parse to extract specific information • Assume “well-behaved” fact sentences• Using co-occurrence relationships alone
does not require parsing or good fact-structure
Usually it requires

Jensen et al. Nature Reviews Genetics 7, 119–129 (February 2006) | doi:10.1038/nrg1768

Text Mining (TM)• The discovery by computer of new,
previously unknown information, by automatically extracting information from different written records.
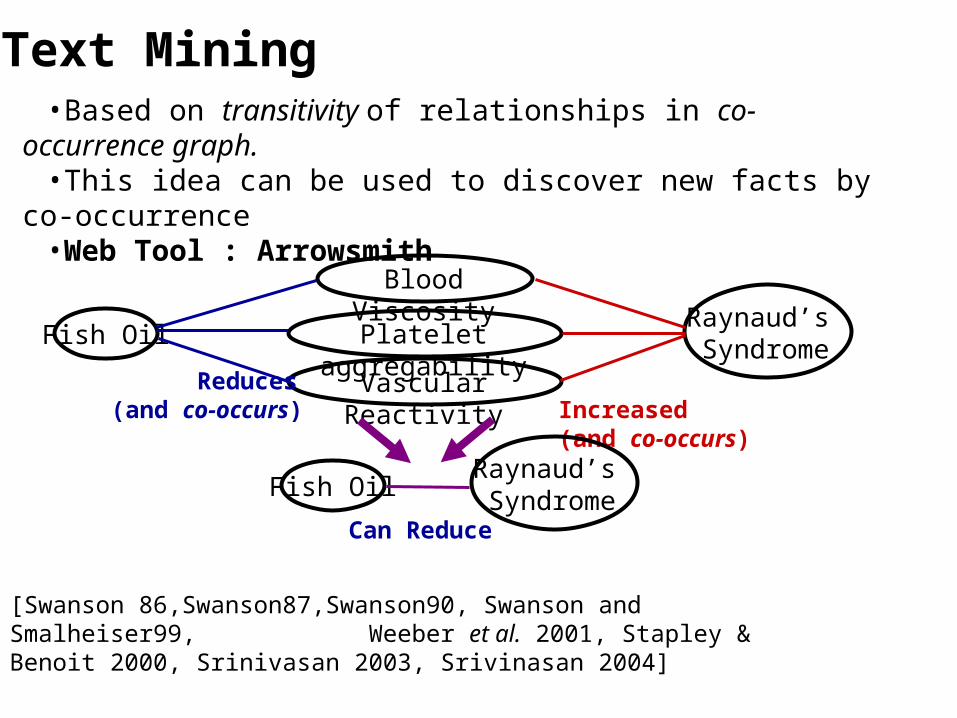
Text Mining
Fish Oil
Blood Viscosity
Platelet aggregability
Vascular Reactivity Reduces(and co-occurs)
Raynaud’s Syndrome
Increased(and co-occurs)
Fish OilRaynaud’s Syndrome
•Based on transitivity of relationships in co-occurrence graph.•This idea can be used to discover new facts by co-occurrence•Web Tool : Arrowsmith
[Swanson 86,Swanson87,Swanson90, Swanson and Smalheiser99, Weeber et al. 2001, Stapley & Benoit 2000, Srinivasan 2003, Srivinasan 2004]
Can Reduce

Jensen et al. Nature Reviews Genetics 7, 119–129 (February 2006) | doi:10.1038/nrg1768

Jensen et al. Nature Reviews Genetics 7, 119–129 (February 2006) | doi:10.1038/nrg1768

Integration: combining text and biological data
Jensen et al. Nature Reviews Genetics 7, 119–129 (February 2006) | doi:10.1038/nrg1768

Jensen et al. Nature Reviews Genetics 7, 119–129 (February 2006) | doi:10.1038/nrg1768





























