Embed Size (px)
Citation preview

Linear Upper Confidence Bound Algorithm forContextual Bandit Problem with Piled Rewards
Kuan-Hao Huang and Hsuan-Tien Lin
Department of Computer Science & Information EngineeringNational Taiwan University
April 20, 2016 (PAKDD)
K.-H. Huang and H.-T. Lin (NTU) LinUCB Algorithm with Piled Rewards PAKDD, 2016 0 / 13
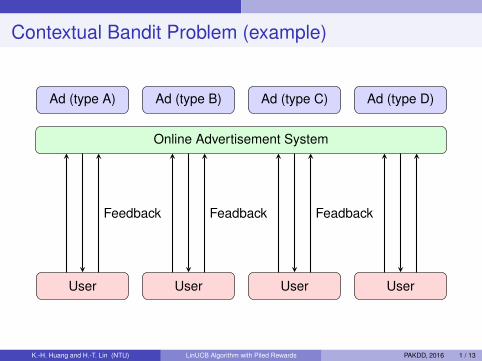
Contextual Bandit Problem (example)
Ad (type A) Ad (type B) Ad (type C) Ad (type D)
Online Advertisement System
User User User User
Feedback Feadback Feadback
K.-H. Huang and H.-T. Lin (NTU) LinUCB Algorithm with Piled Rewards PAKDD, 2016 1 / 13

Contextual Bandit Problem (traditional)
NotationI user: context x ∈ Rd
I ad: action a ∈ {1, 2, ..,K}I feedback: reward r ∈ [0, 1]
Contextual bandit problem (traditional setting)
for round t = 1, 2, ..., T
I algorithm A receives a context xtI algorithm A selects an action at based on the context xtI algorithm A receives the reward rt,at
algorithm A tries to maximize the cumulative rewardsT∑t=1
rt,at
Challenge for contextual bandit problemI partial feedback: exploitation vs. exploration
K.-H. Huang and H.-T. Lin (NTU) LinUCB Algorithm with Piled Rewards PAKDD, 2016 2 / 13
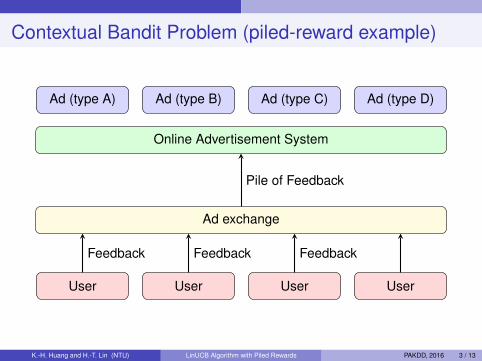
Contextual Bandit Problem (piled-reward example)
Ad (type A) Ad (type B) Ad (type C) Ad (type D)
Online Advertisement System
Ad exchange
User User User User
Feedback Feedback Feedback
Pile of Feedback
K.-H. Huang and H.-T. Lin (NTU) LinUCB Algorithm with Piled Rewards PAKDD, 2016 3 / 13

Contextual Bandit Problem (piled-reward)
NotationI user: context x ∈ Rd
I ad: action a ∈ {1, 2, ..,K}I feedback: reward r ∈ [0, 1]
Contextual bandit problem (piled-reward setting)
for round t = 1, 2, ..., T
I for i = 1, 2, ..., nI algorithm A receives a context xtiI algorithm A selects an action ati based on the context xt
I algorithm A receives n rewards rt1,at1 , rt2,at2 , ..., rtn,atn
algorithm A tries to maximize the cumulative rewardsT∑t=1
n∑i=1
rti,ati
K.-H. Huang and H.-T. Lin (NTU) LinUCB Algorithm with Piled Rewards PAKDD, 2016 4 / 13

Linear Upper Confidence Bound (LinUCB)
LinUCB [Li et al., 2010]I state-of-the-art algorithm for the traditional setting (n = 1)I for each round t and context xt, LinUCB gives every actions a a scoreI selected action at = argmaxa(scoret,a(xt))
scoret,a(xt) = estimated reward + uncertainty= estimated reward + confidence bound
= w>t,ax+ α√x>t (I+X>t−1,aXt−1,a)−1xt
I estimated reward for exploitation, is obtained by the regression frompairs (xτ , rτ,a) of action a
I uncertainty for exploration, estimates how confident for the estimatedreward
I update the scoring function whenever receiving the reward
K.-H. Huang and H.-T. Lin (NTU) LinUCB Algorithm with Piled Rewards PAKDD, 2016 5 / 13

Applying LinUCB to Piled-reward setting
LinUCB under the piled-reward setting
for round t = 1, 2, ..., T
I for i = 1, 2, ..., nI LinUCB receives context xtiI LinUCB selects an action ati with the same scoring function
I LinUCB receives n rewards rt1,at1 , rt2,at2 , ..., rtn,atnI LinUCB updates the scoring function with n rewards
Problem for LinUCB under the piled-reward settingI no update for scoring function within the roundI LinUCB selects action with high uncertainty but low estimated reward
risk for some contextsI these contexts come again and again→ low rewardI need strategic exploration within the round
K.-H. Huang and H.-T. Lin (NTU) LinUCB Algorithm with Piled Rewards PAKDD, 2016 6 / 13

Strategic Exploration
Our solutionI use previous contexts xt1 ,xt2 , ...,xti−1
in this round to help for selectingaction for xti
I give each previous context xtτ a pseudo reward ptτ ,atτI use the pseudo reward to pretend the true rewardI we design two pseudo rewards:
I estimated reward: estimated rewardI underestimated reward: estimated reward - confidence bound
Score after the update with pseudo reward
pseudo reward estimated reward uncertaintyestimated reward no change become lower
underestimated reward become lower become lowerI achieve strategic explorationI underestimated reward is more aggressive than estimated reward
K.-H. Huang and H.-T. Lin (NTU) LinUCB Algorithm with Piled Rewards PAKDD, 2016 7 / 13

Linear Upper Confidence Bound with Pseudo Reward
A novel algorithmI Linear Upper Confidence Bound with Pseudo Reward (LinUCBPR)
I LinUCBPR-ER: estimated reward as the pseudo rewardI LinUCBPR-UR: underestimated reward as the pseudo reward
LinUCBPR under the piled-reward setting
for round t = 1, 2, ..., T
I for i = 1, 2, ..., nI LinUCBPR receives context xtiI LinUCBPR selects an action ati with the scoring functionI LinUCBPR updates the scoring function with the pseudo rewards pti,ati
I LinUCBPR receives n true rewards rt1,at1 , rt2,at2 , ..., rtn,atnI LinUCBPR discards the change caused by the pseudo rewardsI LinUCBPR updates the scoring function with n true rewards
K.-H. Huang and H.-T. Lin (NTU) LinUCB Algorithm with Piled Rewards PAKDD, 2016 8 / 13

Theoretical Analysis
Regret for algorithm A
Regret(A) =T∑t=1
n∑i=1
rti,a∗ti−
T∑t=1
n∑i=1
rti,ati
Theorem
For some α = O(√ln(nTK/δ)), with probability 1− δ, the regret bounds of
LinUCB and LinUCBPR-ER under the piled-reward setting are both
O(√dn2TK ln3(nTK/δ))
I when the number of contexts (nT ) is constant, the regret bound ∝√n
I LinUCB and LinUCBPR-ER enjoy the same regret bound
K.-H. Huang and H.-T. Lin (NTU) LinUCB Algorithm with Piled Rewards PAKDD, 2016 9 / 13
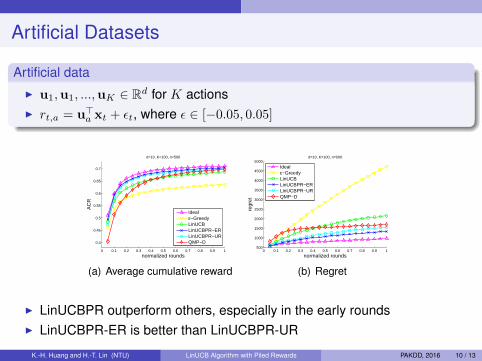
Artificial Datasets
Artificial dataI u1,u1, ...,uK ∈ Rd for K actionsI rt,a = u>a xt + εt, where ε ∈ [−0.05, 0.05]
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
0.4
0.45
0.5
0.55
0.6
0.65
0.7
d=10, K=100, n=500
normalized rounds
AC
R
Idealε−GreedyLinUCBLinUCBPR−ERLinUCBPR−URQMP−D
(a) Average cumulative reward
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1500
1000
1500
2000
2500
3000
3500
4000
4500
5000d=10, K=100, n=500
normalized roundsre
gret
Idealε−GreedyLinUCBLinUCBPR−ERLinUCBPR−URQMP−D
(b) Regret
I LinUCBPR outperform others, especially in the early roundsI LinUCBPR-ER is better than LinUCBPR-UR
K.-H. Huang and H.-T. Lin (NTU) LinUCB Algorithm with Piled Rewards PAKDD, 2016 10 / 13
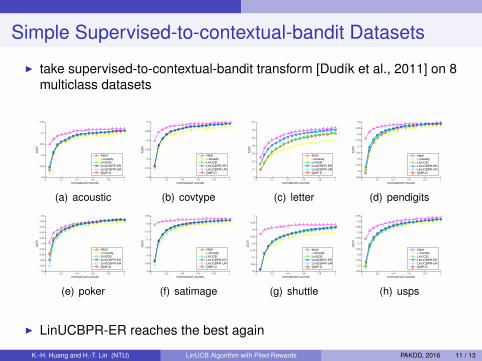
Simple Supervised-to-contextual-bandit Datasets
I take supervised-to-contextual-bandit transform [Dudı́k et al., 2011] on 8multiclass datasets
normalized rounds0 0.2 0.4 0.6 0.8 1
AC
R
0.5
0.55
0.6
0.65
0.7
0.75
Ideal0-GreedyLinUCBLinUCBPR-ERLinUCBPR-URQMP-D
(a) acoustic
normalized rounds0 0.2 0.4 0.6 0.8 1
AC
R
0.4
0.45
0.5
0.55
0.6
0.65
0.7
Ideal0-GreedyLinUCBLinUCBPR-ERLinUCBPR-URQMP-D
(b) covtype
normalized rounds0 0.2 0.4 0.6 0.8 1
AC
R
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
Ideal0-GreedyLinUCBLinUCBPR-ERLinUCBPR-URQMP-D
(c) letter
normalized rounds0 0.2 0.4 0.6 0.8 1
AC
R
0.45
0.5
0.55
0.6
0.65
0.7
0.75
0.8
0.85
0.9
Ideal0-GreedyLinUCBLinUCBPR-ERLinUCBPR-URQMP-D
(d) pendigits
normalized rounds0 0.2 0.4 0.6 0.8 1
AC
R
0.3
0.32
0.34
0.36
0.38
0.4
0.42
0.44
0.46
0.48
0.5
Ideal0-GreedyLinUCBLinUCBPR-ERLinUCBPR-URQMP-D
(e) poker
normalized rounds0 0.2 0.4 0.6 0.8 1
AC
R
0.5
0.55
0.6
0.65
0.7
0.75
0.8
0.85
Ideal0-GreedyLinUCBLinUCBPR-ERLinUCBPR-URQMP-D
(f) satimage
normalized rounds0 0.2 0.4 0.6 0.8 1
AC
R
0.6
0.65
0.7
0.75
0.8
0.85
0.9
0.95
1
Ideal0-GreedyLinUCBLinUCBPR-ERLinUCBPR-URQMP-D
(g) shuttle
normalized rounds0 0.2 0.4 0.6 0.8 1
AC
R
0.45
0.5
0.55
0.6
0.65
0.7
0.75
0.8
0.85
0.9
0.95
Ideal0-GreedyLinUCBLinUCBPR-ERLinUCBPR-URQMP-D
(h) usps
I LinUCBPR-ER reaches the best again
K.-H. Huang and H.-T. Lin (NTU) LinUCB Algorithm with Piled Rewards PAKDD, 2016 11 / 13
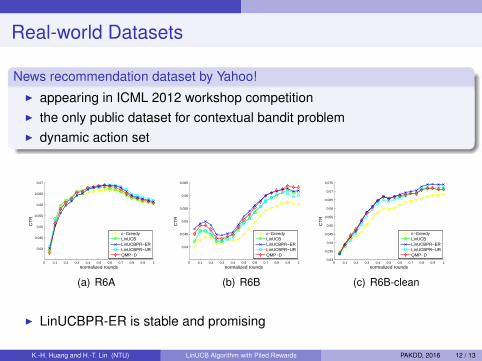
Real-world Datasets
News recommendation dataset by Yahoo!I appearing in ICML 2012 workshop competitionI the only public dataset for contextual bandit problemI dynamic action set
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
0.04
0.045
0.05
0.055
0.06
0.065
0.07
normalized rounds
CT
R
ε−GreedyLinUCBLinUCBPR−ERLinUCBPR−URQMP−D
(a) R6A
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
0.04
0.045
0.05
0.055
0.06
0.065
normalized rounds
CT
R
ε−GreedyLinUCBLinUCBPR−ERLinUCBPR−URQMP−D
(b) R6B
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10.03
0.035
0.04
0.045
0.05
0.055
0.06
0.065
0.07
0.075
normalized rounds
CT
R
ε−GreedyLinUCBLinUCBPR−ERLinUCBPR−URQMP−D
(c) R6B-clean
I LinUCBPR-ER is stable and promising
K.-H. Huang and H.-T. Lin (NTU) LinUCB Algorithm with Piled Rewards PAKDD, 2016 12 / 13
Conclusion
I formalize the piled-reward setting for contextual bandit problemI demonstrate how LinUCB can be applied to the piled-reward setting, and
prove its regret boundI propose LinUCBPR, and prove the regret bound of LinUCBPR-ERI validate the promising performance of LinUCBPR-ER
Thank you! Any question?
K.-H. Huang and H.-T. Lin (NTU) LinUCB Algorithm with Piled Rewards PAKDD, 2016 13 / 13





























