Embed Size (px)
Citation preview

Leis de Potência, Lei de Zipf’se distribuições de cauda pesada
Revisão do Artigo:
M. E. J. Newman, Power laws, Pareto distributions and Zipf's law,and Zipf s law,
Contemporary Physics 46, 323-351 (2005)

Tópicos
Distribuições do tipo Power law: caracteísticasDistribuições do tipo Power law: caracteísticas estatísticas
“Fitting”
Dados para os projetos do curso
Expectativa: que nós tenhamos uns 4 ou 5 bons papers para submissao em conferencias internacionais Qualis pA, como resultado do projeto.

DatasetsWeb data from Panayiotis Tsaparas There are a number of interesting networkWeb data from Panayiotis Tsaparas. There are a number of interesting network datasets available on the Web; they form a valuable resource for trying out algorithms and models across a range of settings. Collaboration and citation networks: For the 2003 KDD Cup competition, Johannes Gehrke, Paul Ginsparg, and I provided a dataset based on the arXiv pre-print database, which allows one to study the networks of co-authorships and citations among a large community of physicists. Here is the KDD Cup dataset and a paper describing the competition in more detail.
KDD C d t tKDD Cup dataset.P. Ginsparg, J. Gehrke, J. Kleinberg. Overview of the 2003 KDD Cup. SIGKDD Explorations, 2004.
Internet topology: The network structure of the Internet can be studied at severalInternet topology: The network structure of the Internet can be studied at several levels of resolution. Here is a dataset at the autonomous system (AS) level.
AS graphs.Web subgraphs: There are many such datasets available for download One set isWeb subgraphs: There are many such datasets available for download. One set is maintained by Panayiotis Tsaparas; the experiments that used this data are described in his Ph.D. thesis, and in other papers linked from his home page
P. Tsaparas, Link Analysis Ranking, Ph.D. Thesis, Department of ComputerP. Tsaparas, Link Analysis Ranking, Ph.D. Thesis, Department of Computer Science, University of Toronto, 2004.
Semantic networks: Free association datasets for words have been collected by cognitive scientists; these are constructed by compiling the free responses of test subjects when presented with cue words. (For example, a test subject presented with the cue word `ice' might react with the word `cold,' `cream,' or `water.')
University of South Florida Free Association Norms.

O que é uma distribuição de cauda pesada (heavy-tailed)?(heavy tailed)?
Inclinação para a direitaDistribuição normal (não é heavy tailed)
Ex: altura de homens centrada em torno de 180cm Zipf’s ou power-law distribution (heavy tailed)Zipf s ou power-law distribution (heavy tailed)
e.g. Tamanho das populações das cidades: São Paulo tem 14 milhões, mas existem centenas de cidades no interior de menos de 1 mil habitantes (diferença de ordens de grandeza)1 mil habitantes. (diferença de ordens de grandeza)
Razão alta entre o máximo e mínimoRazão alta entre o máximo e mínimoAlturas humanas
Homen-gigante: 272cm, homen-anão: 57 cm razão: 4.8“Guinness Book of world records”
Tamanho das cidadesSão Paulo: pop 17 milhões Serra Nova Dourada em Mato GrossoSão Paulo: pop. 17 milhões, Serra Nova Dourada, em Mato Grosso com 562 hab. razão: 300.000
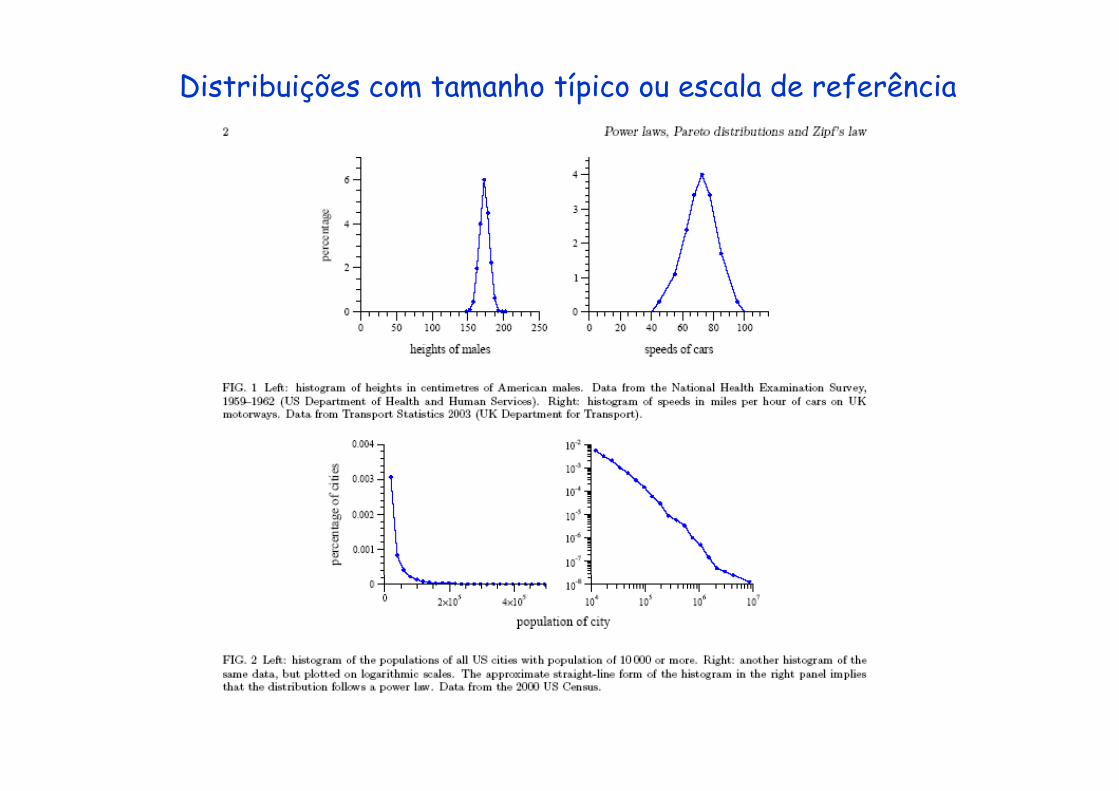
Distribuições com tamanho típico ou escala de referência
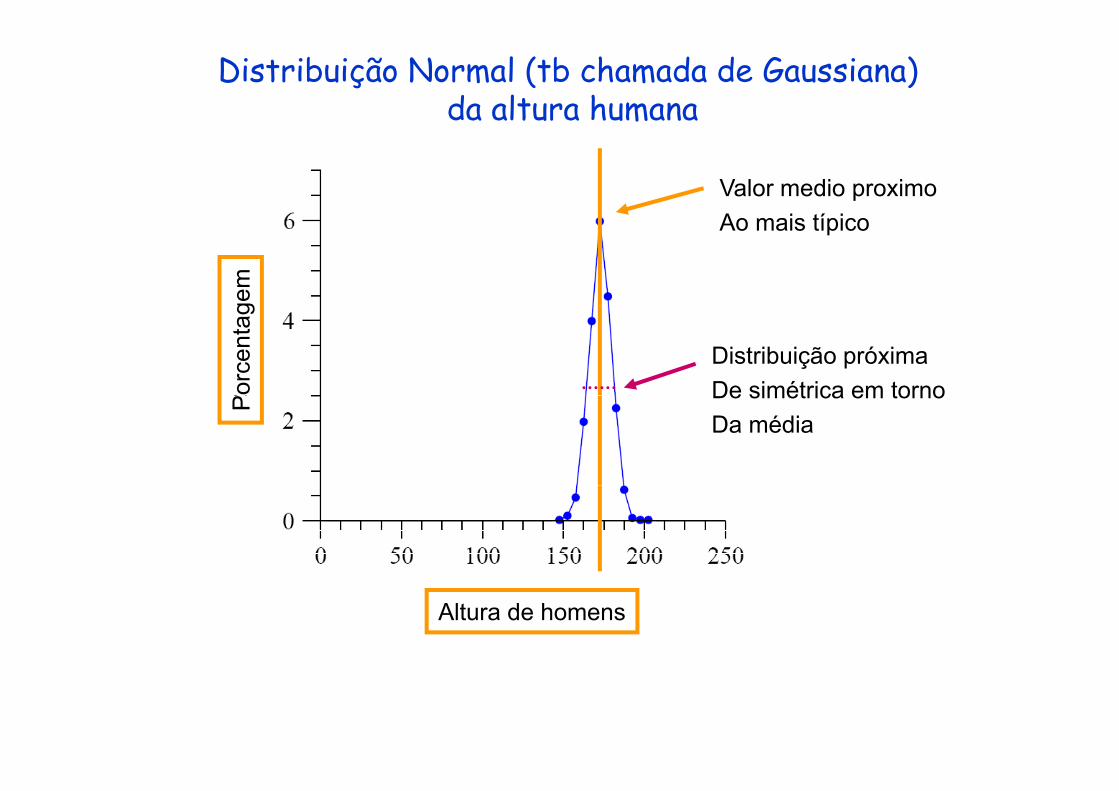
Distribuição Normal (tb chamada de Gaussiana)da altura humana
Valor medio proximoA i tí iAo mais típico
gem
Distribuição próximaDe simétrica em tornoor
cent
ag
De simétrica em tornoDa média
P
Altura de homens
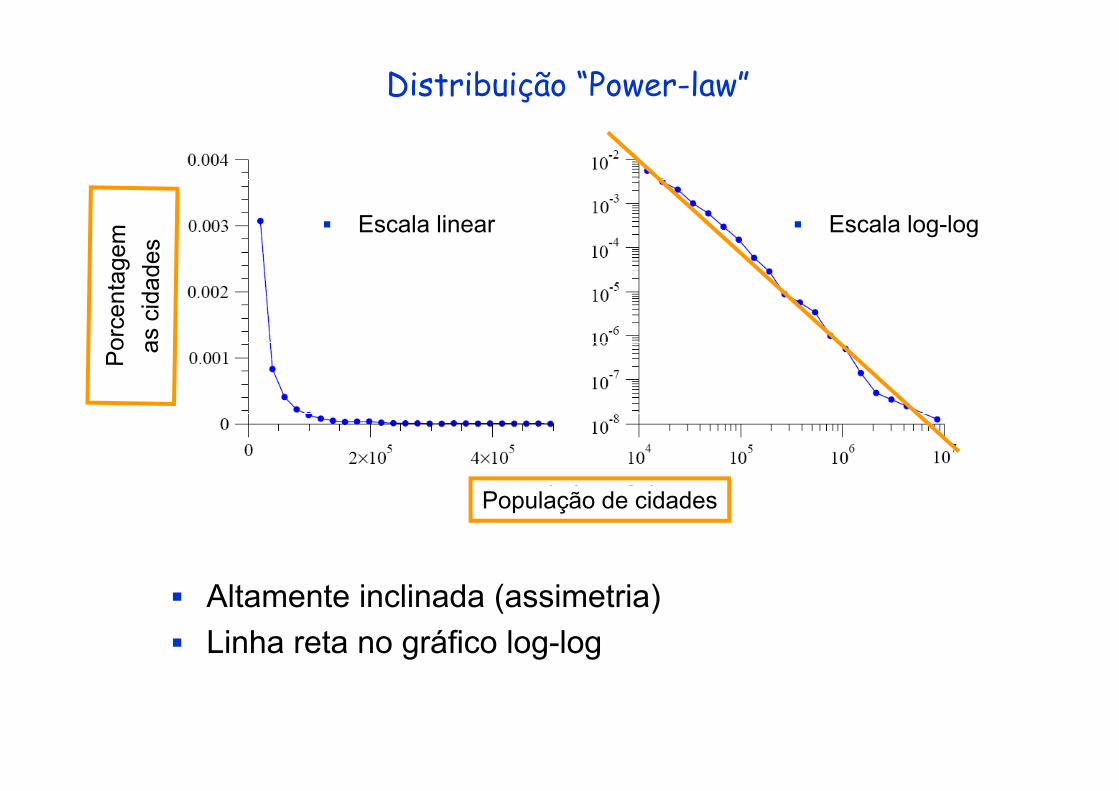
Distribuição “Power-law”
E l li E l l lEscala linear Escala log-log
População de cidades
Altamente inclinada (assimetria)Linha reta no gráfico log-log
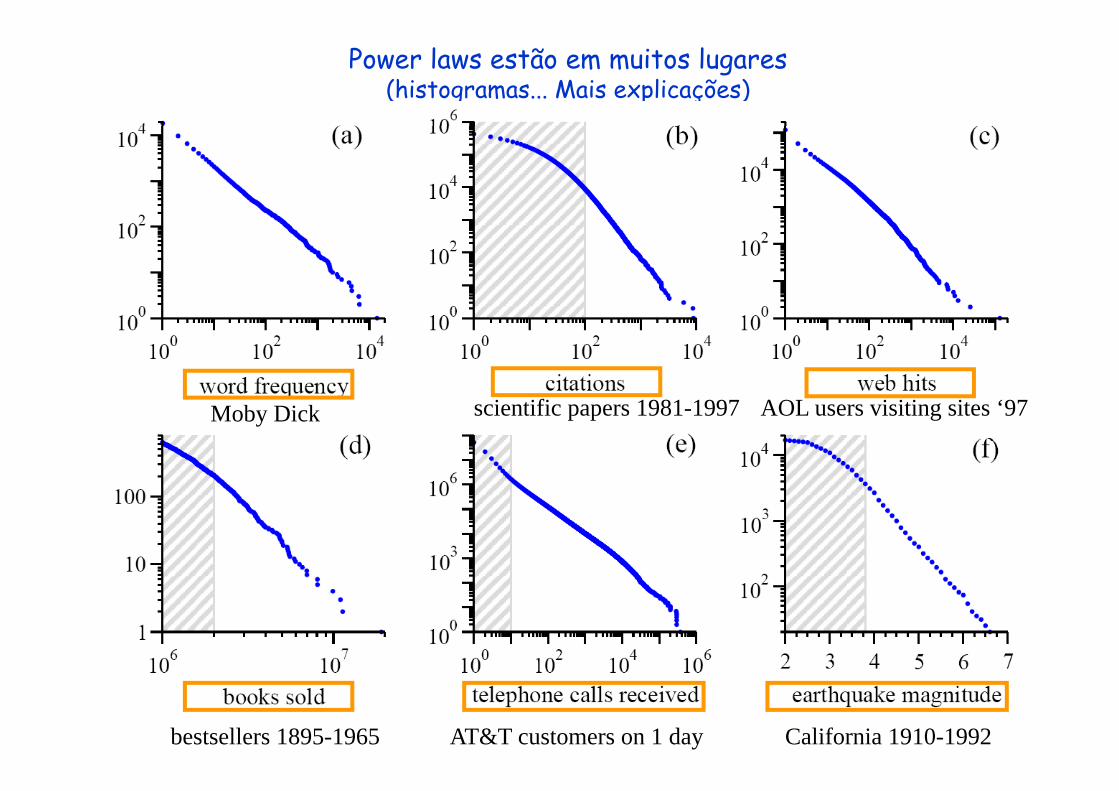
Power laws estão em muitos lugares(histogramas... Mais explicações)
Moby Dick scientific papers 1981-1997 AOL users visiting sites ‘97
bestsellers 1895-1965 AT&T customers on 1 day California 1910-1992
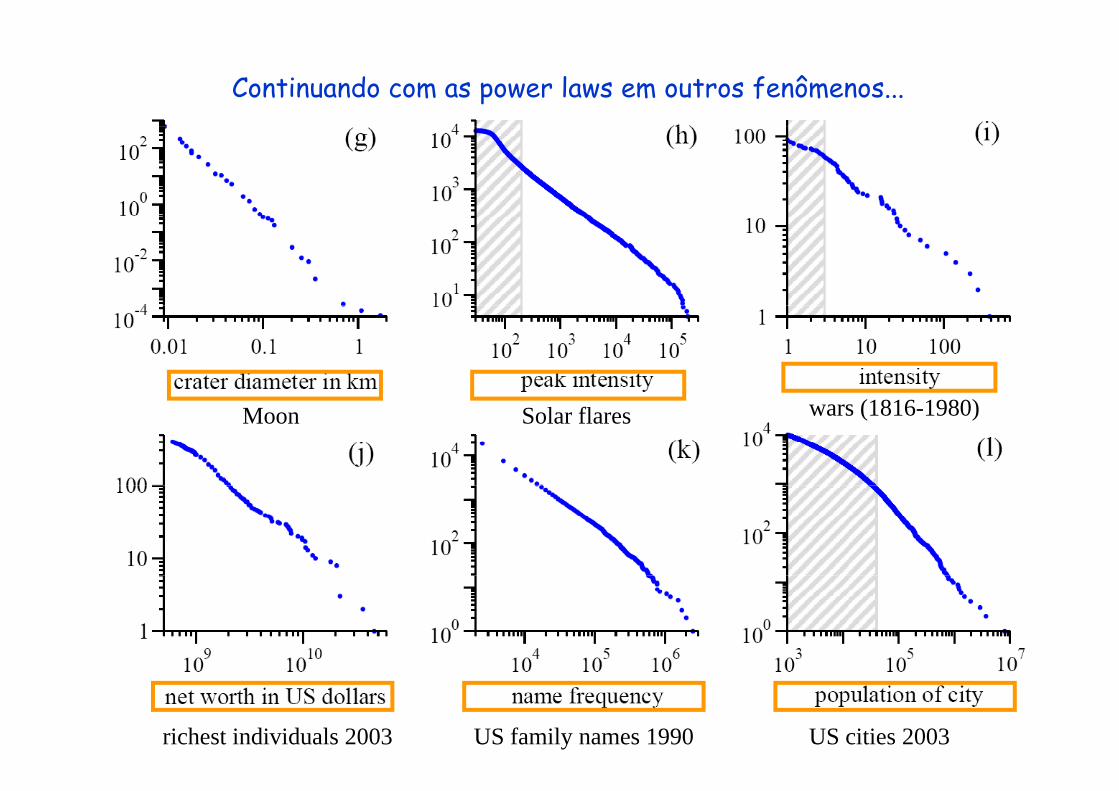
Continuando com as power laws em outros fenômenos...
Moon Solar flares wars (1816-1980)
richest individuals 2003 US family names 1990 US cities 2003

Distribuição de uma Função de Potência (Power law)
Linha reta em um gráfico log-log
)l ())(l ()( α →− )ln())(ln()( xcxpcxxp αα −=→=
Função de probabilidade p(x), em função do tamanho de ‘x”
α−= Cxxp )( Cxxp )(
C t t dConstante de normalização(probabidades para todos de em somar
Expoente da lei de potência α
todos x devem somar1)

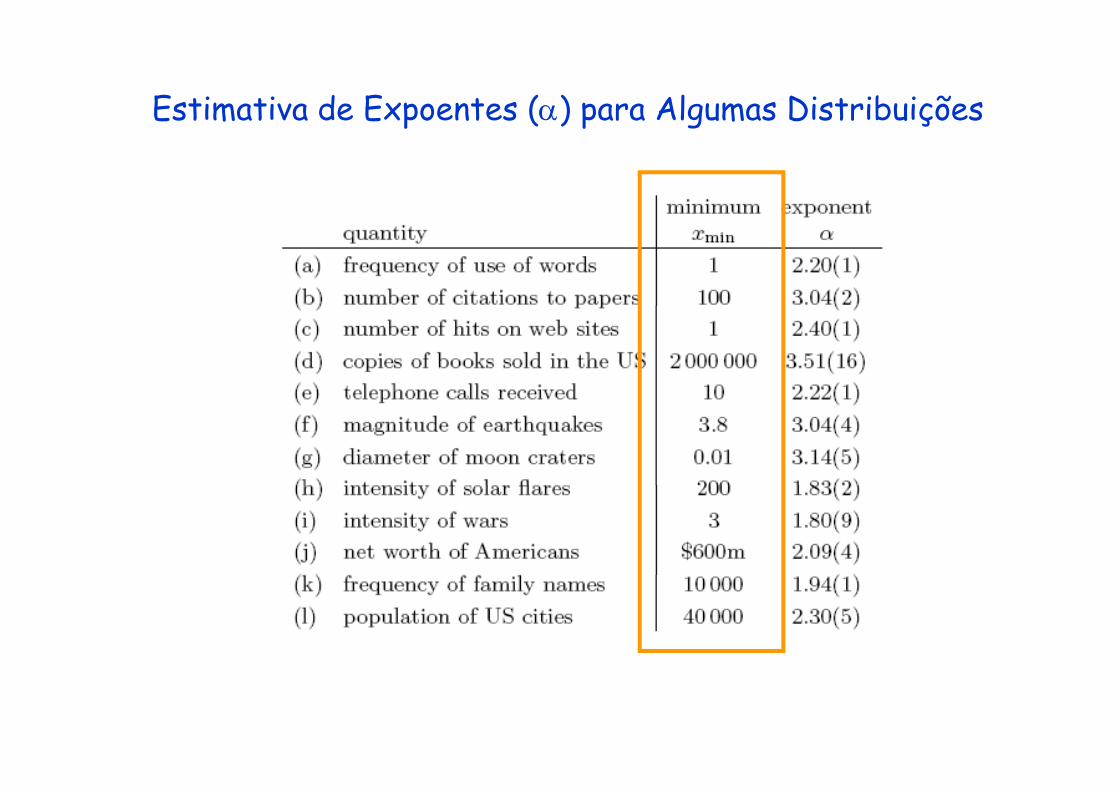
Estimativa de Expoentes (α) para Algumas Distribuiçõesp ( ) p g ç
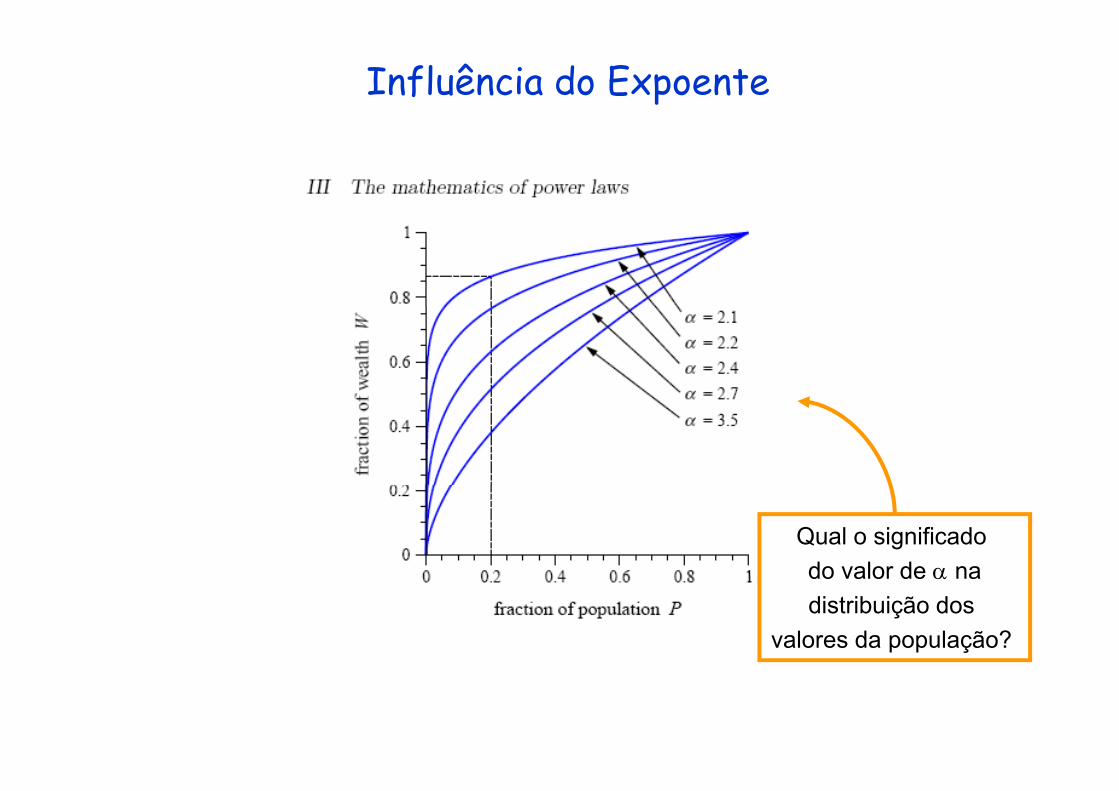
Influência do Expoente
Qual o significado do valor de α nado valor de α nadistribuição dos
valores da população?
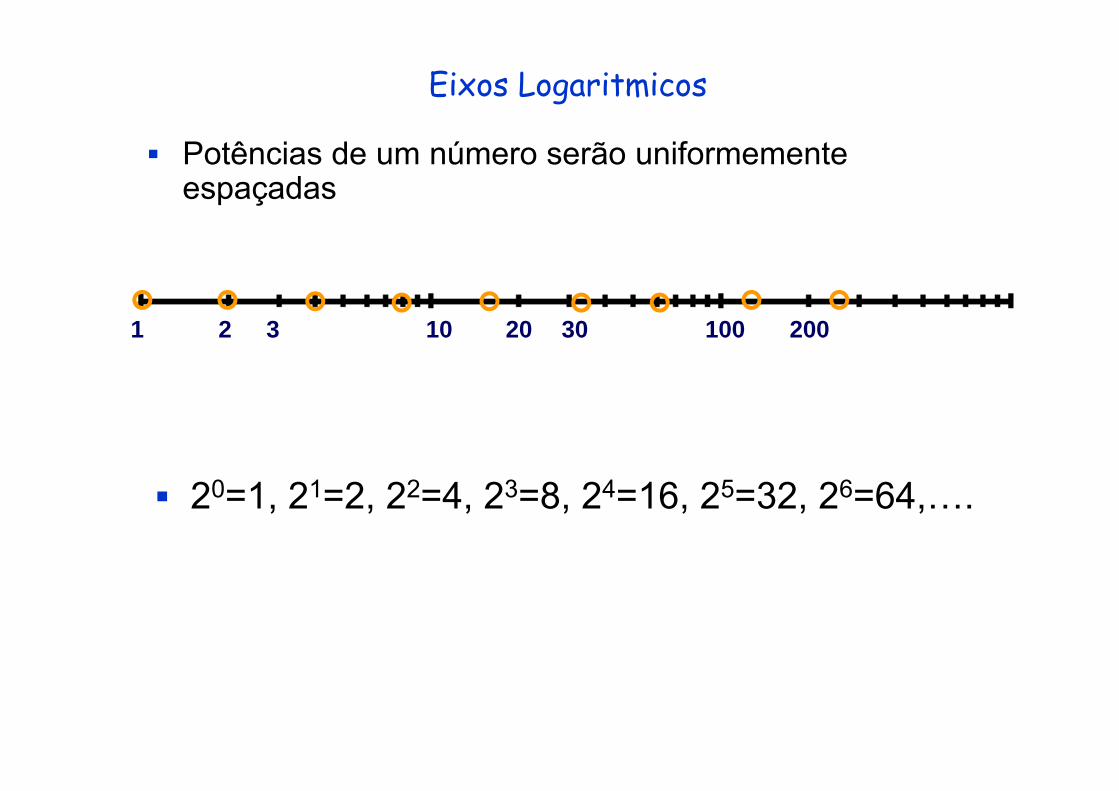
Eixos Logaritmicos
Potências de um número serão uniformemente espaçadas
1 2 3 10 20 30 100 200
20 1 21 2 22 4 23 8 24 16 25 32 26 6420=1, 21=2, 22=4, 23=8, 24=16, 25=32, 26=64,….

Determinando o “fitting” em distribuições “power laws”
Método mais comum, sem muita precisão:Coloque em “Bins” os diferentes valores de x e crie um histograma de f ê ifrequência
ln(# de vezesx ocorreu)
ln(x) é logaritmo natural de x,Pode-se usar qq base,log10(x) = ln(x)/ln(10)
ln(x)
X pode representar várias quantidades, o “indegree” de um nodo de uma rede, a p p q , g ,densidade de sensores em várias áreas geográficas, a frequência de palavras num texto, etc.

Exemplo: um “dataset” gerado articialmente
Use 1 milhão de números randomicos de uma distribuição com α = 2 5distribuição com α = 2.5
Para gerar os números pode se usar o método daPara gerar os números pode-se usar o método da função inversa CDF F(x) u = F(x) x = F-1(u)
Gere números aleatórios no intervalo 0≤r<1
Então x = (1-r)−1/(α−1) é um número aleatório real distribuido segundo uma “power law” no intervalo 1 ≤ xdistribuido segundo uma power law no intervalo 1 ≤ x< ∞
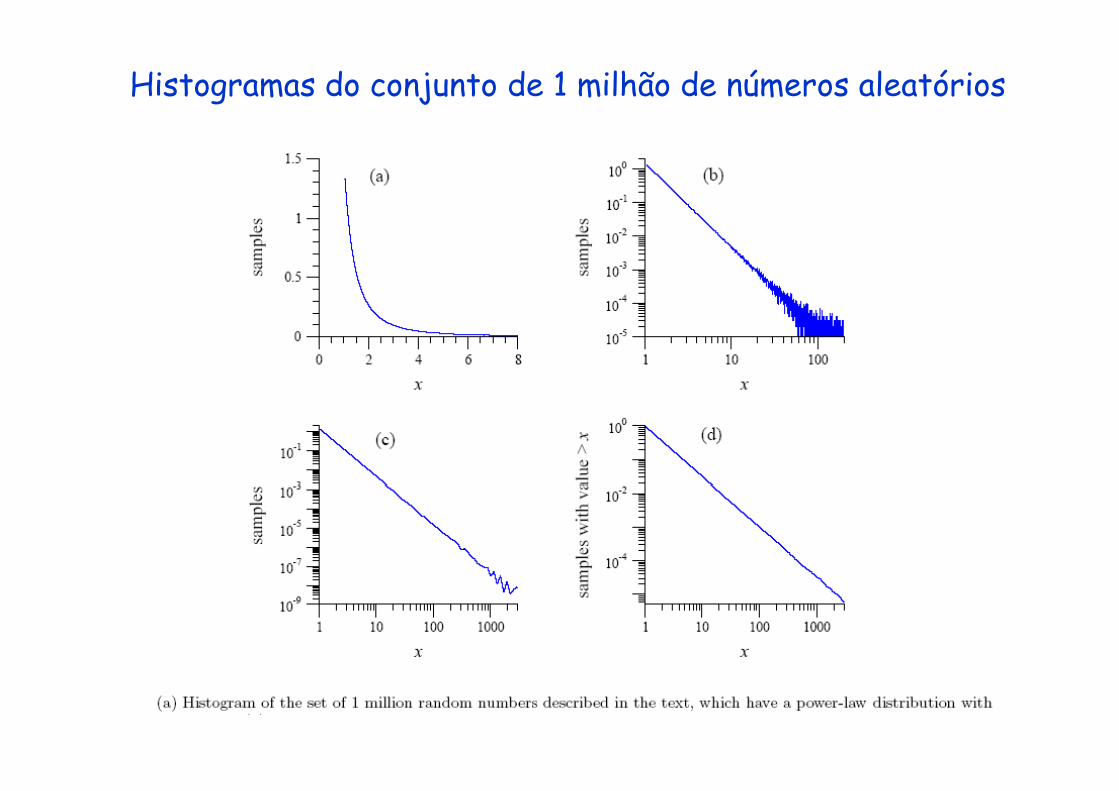
Histogramas do conjunto de 1 milhão de números aleatórios
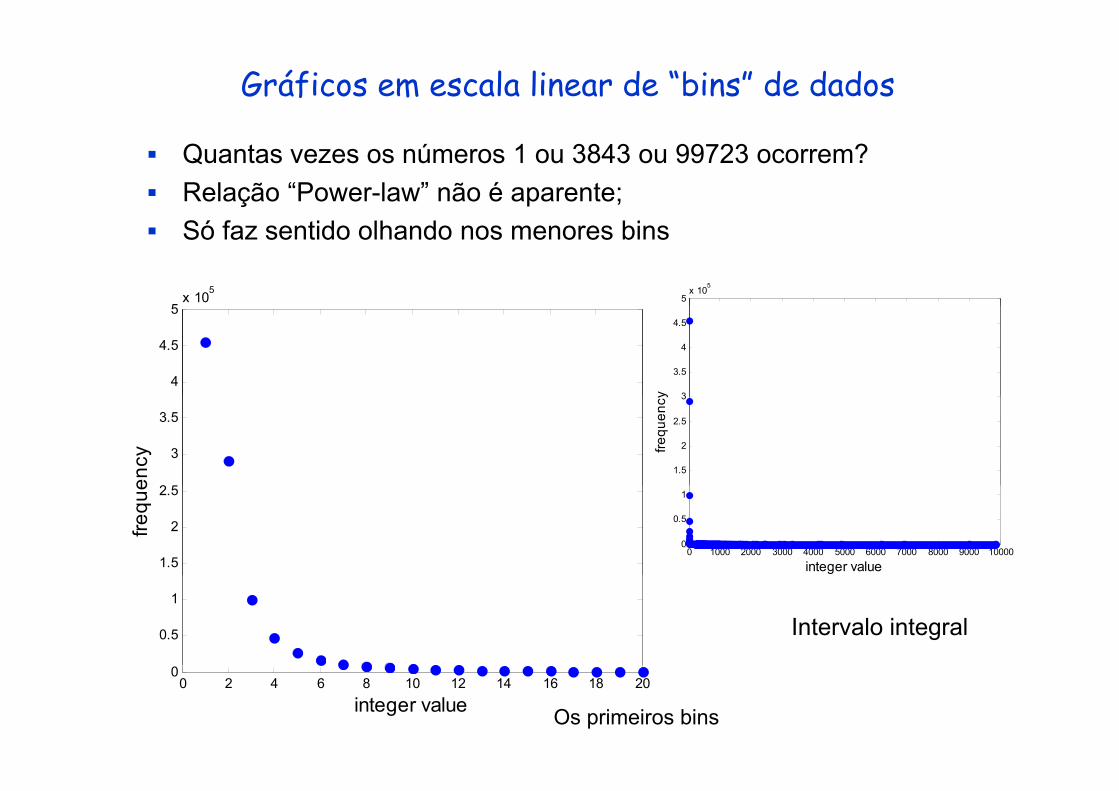
Gráficos em escala linear de “bins” de dados
Quantas vezes os números 1 ou 3843 ou 99723 ocorrem?Relação “Power-law” não é aparente;
5x 10
5
Só faz sentido olhando nos menores bins
5x 105
4
4.5
5
3
3.5
4
4.5
y
2 5
3
3.5
ency
1.5
2
2.5
3
frequ
ency
1.5
2
2.5
frequ
e
0 1000 2000 3000 4000 5000 6000 7000 8000 9000 100000
0.5
1
integer value
0.5
1
Intervalo integral
0 2 4 6 8 10 12 14 16 18 200
integer value Os primeiros bins
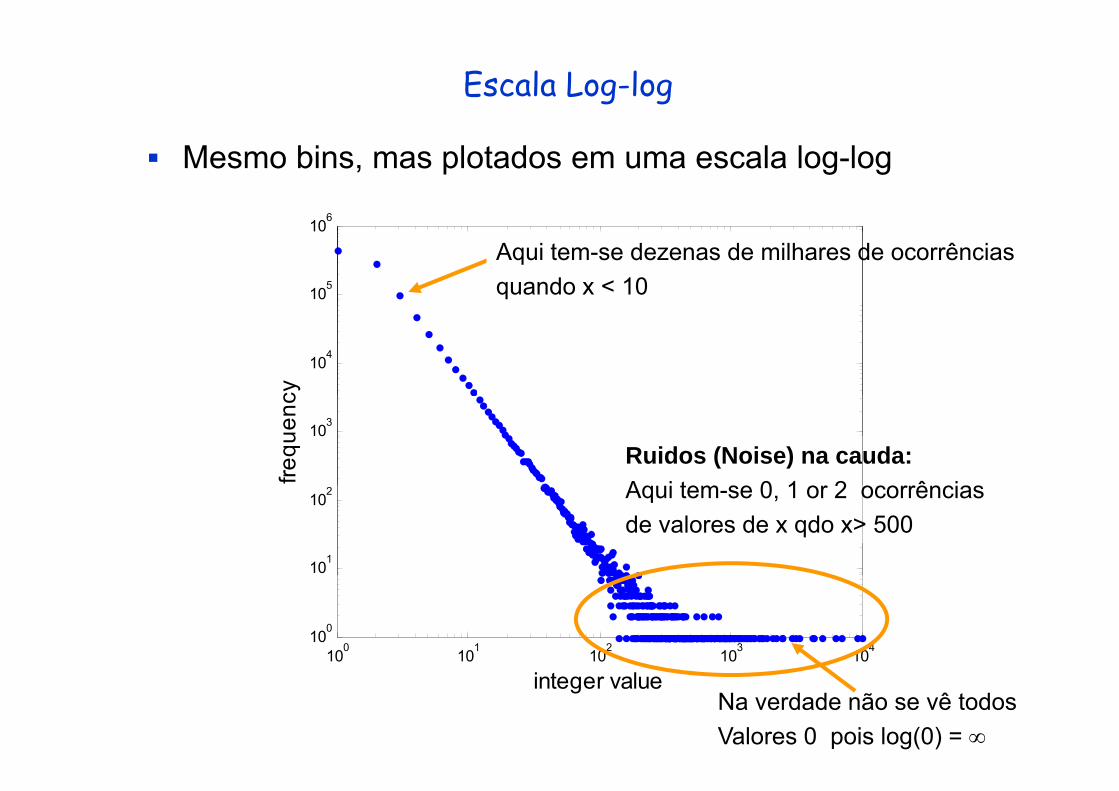
Escala Log-log
Mesmo bins, mas plotados em uma escala log-log6
105
106
Aqui tem-se dezenas de milhares de ocorrênciasquando x < 10
104
cy
103
frequ
enc
Ruidos (Noise) na cauda:Aq i tem se 0 1 or 2 ocorrências
101
102 Aqui tem-se 0, 1 or 2 ocorrênciasde valores de x qdo x> 500
100 101 102 103 104100
integer valueNa verdade não se vê todosValores 0 pois log(0) = ∞
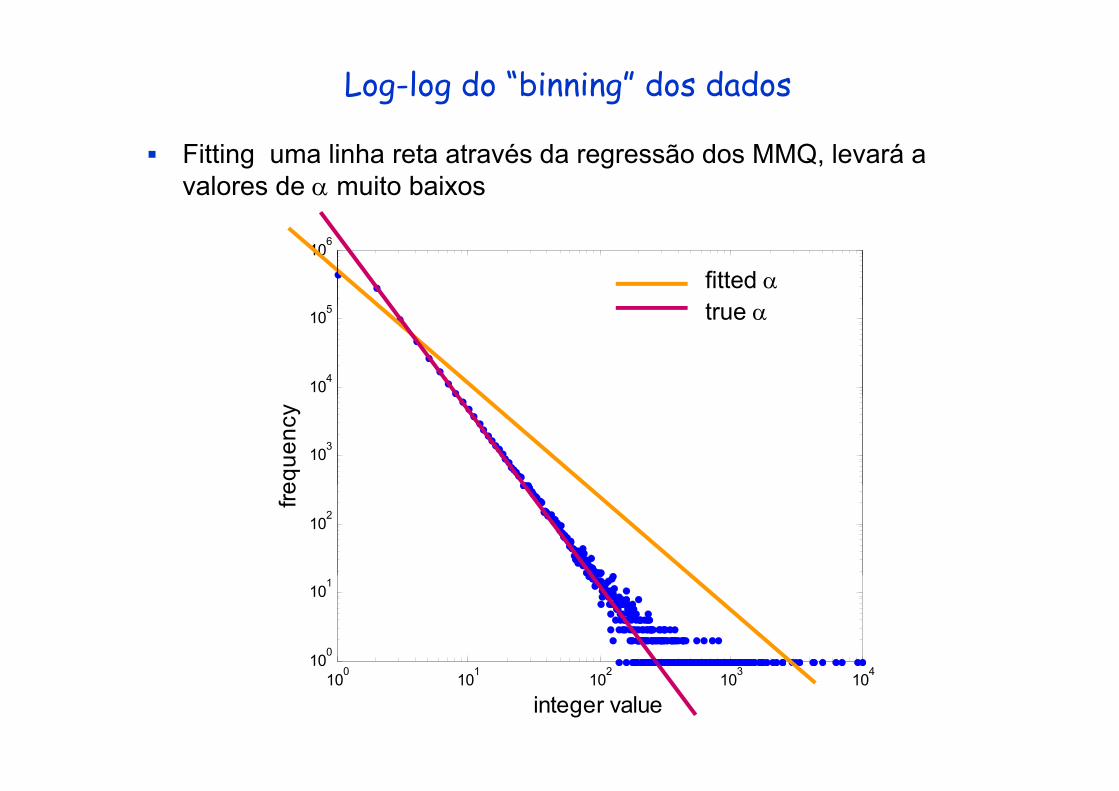
Log-log do “binning” dos dados
Fitting uma linha reta através da regressão dos MMQ, levará a valores de α muito baixos
5
106
fitted αt
104
105 true α
103
eque
ncy
102
fre
100
101
100 101 102 103 10410
integer value
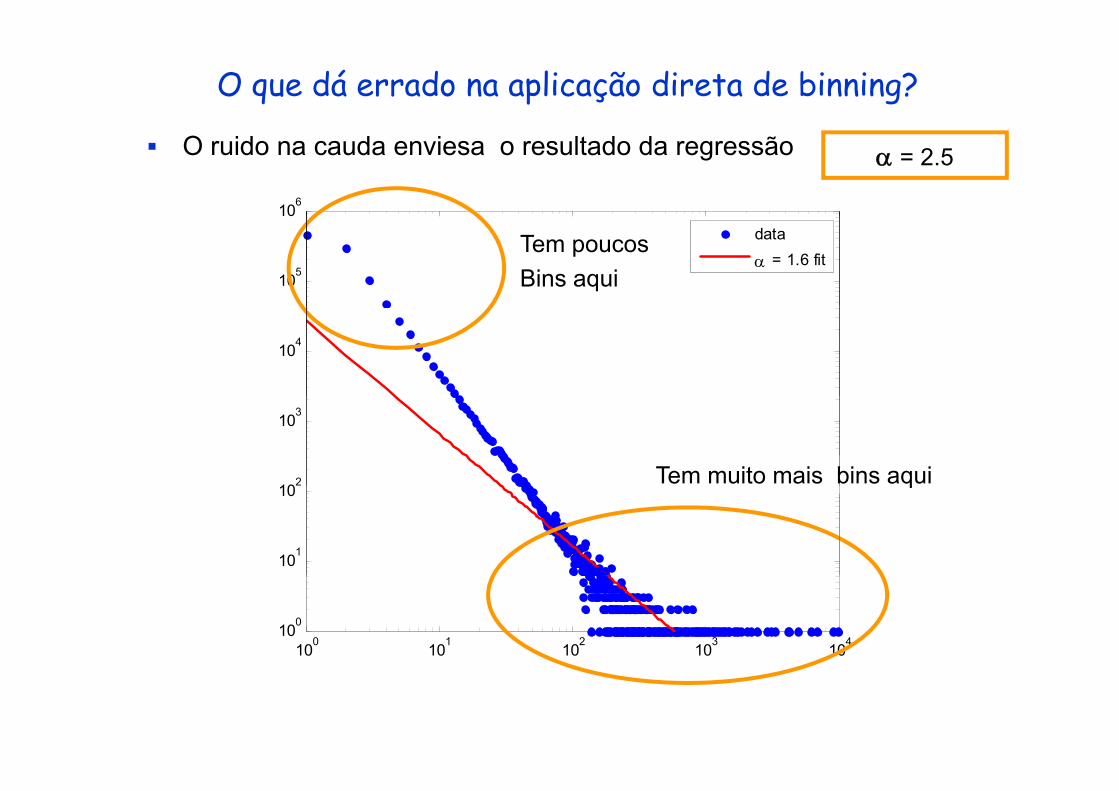
O que dá errado na aplicação direta de binning?
O ruido na cauda enviesa o resultado da regressão
106
α = 2.5
105
0data
α = 1.6 fitTem poucos Bins aqui
104
102
103
Tem muito mais bins aqui
101
102 q
100 101 102 103 104100
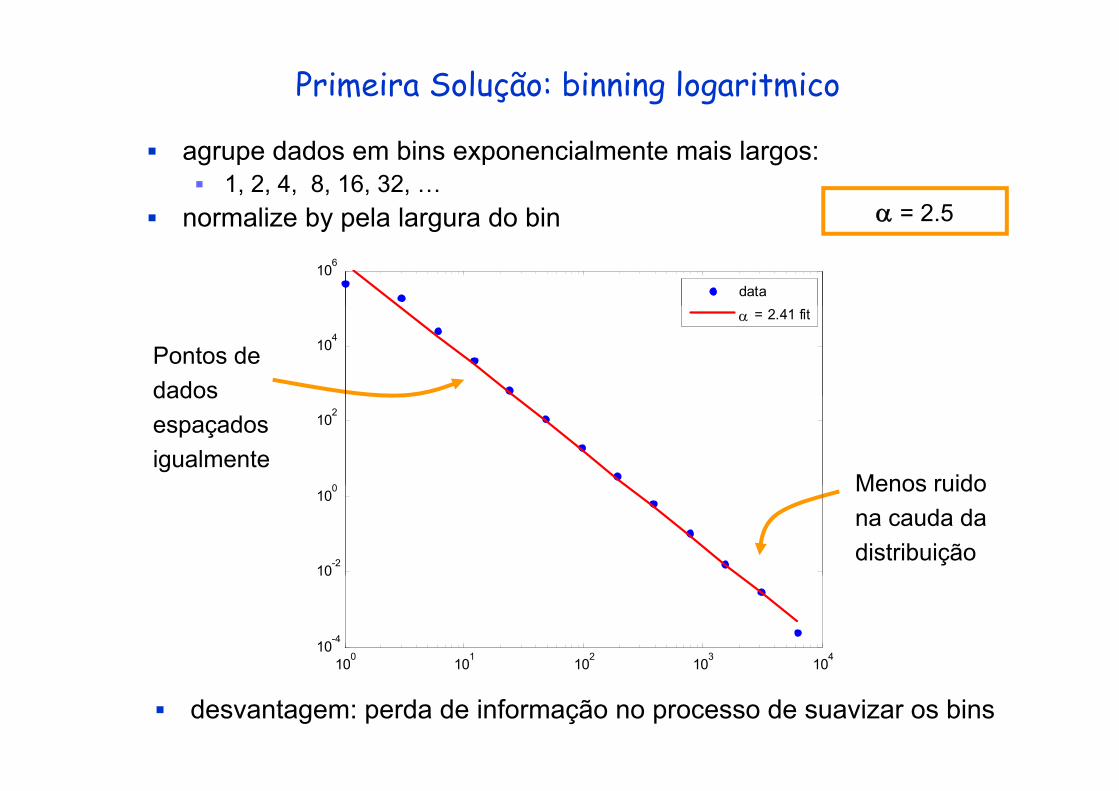
Primeira Solução: binning logaritmico
agrupe dados em bins exponencialmente mais largos:1, 2, 4, 8, 16, 32, …
normalize by pela largura do bin α = 2 5normalize by pela largura do bin
106 data
α = 2.5
104
α = 2.41 fit
Pontos de dados
0
102
dados espaçadosigualmente
Menos ruido
10-2
100 Menos ruidona cauda dadistribuição
100 101 102 103 10410-4
10
10 10 10 10 10
desvantagem: perda de informação no processo de suavizar os bins

Segunda solução: binning cumulativo
Sem perda de informaçãoNão são necessários bins, há valor para cada valor de ocorrência de x
Mas, tem-se uma distribuição acumuladai Q t l d ã í i i i Xi.e. Quantos valores de x são no mínimo iguais a X
A probabilidade acumulada de uma distribuição power law éA probabilidade acumulada de uma distribuição power law é também power law, mas com expoente α - 1
∫ −−−
−= xccx )1(
1αα
α
∑ ∑∞
=−−∞
=− ∝==>
xk xkxCkckPxXP )1()()(
1αα
α
xk xk
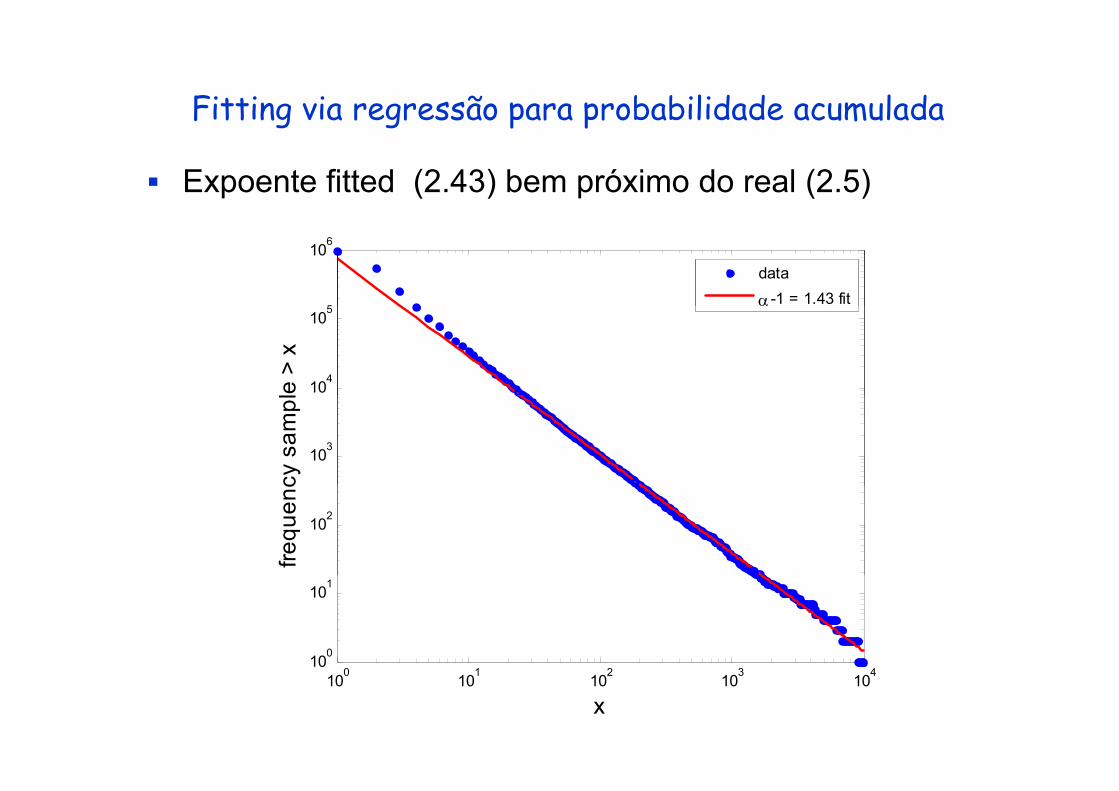
Fitting via regressão para probabilidade acumuladag g p p
Expoente fitted (2.43) bem próximo do real (2.5)
5
106 data
α-1 = 1.43 fit
104
105le
> x
α
103
cy s
ampl
102
frequ
enc
100
101
100 101 102 103 10410
x

Onde deve-se começar o o fitting?
Algumas massas de dados somente exibem uma power law na cauda;cauda;
Depois de fazer o binning or a distribuição acumulada, voce pode fazer o fit para a cauda;
Então é necessário seleionar um xmin o valor de x onde voce min considera que a power-law começa;
certamente xmin necessita ser maior que 0, pois x−α é ∞ em x = 0
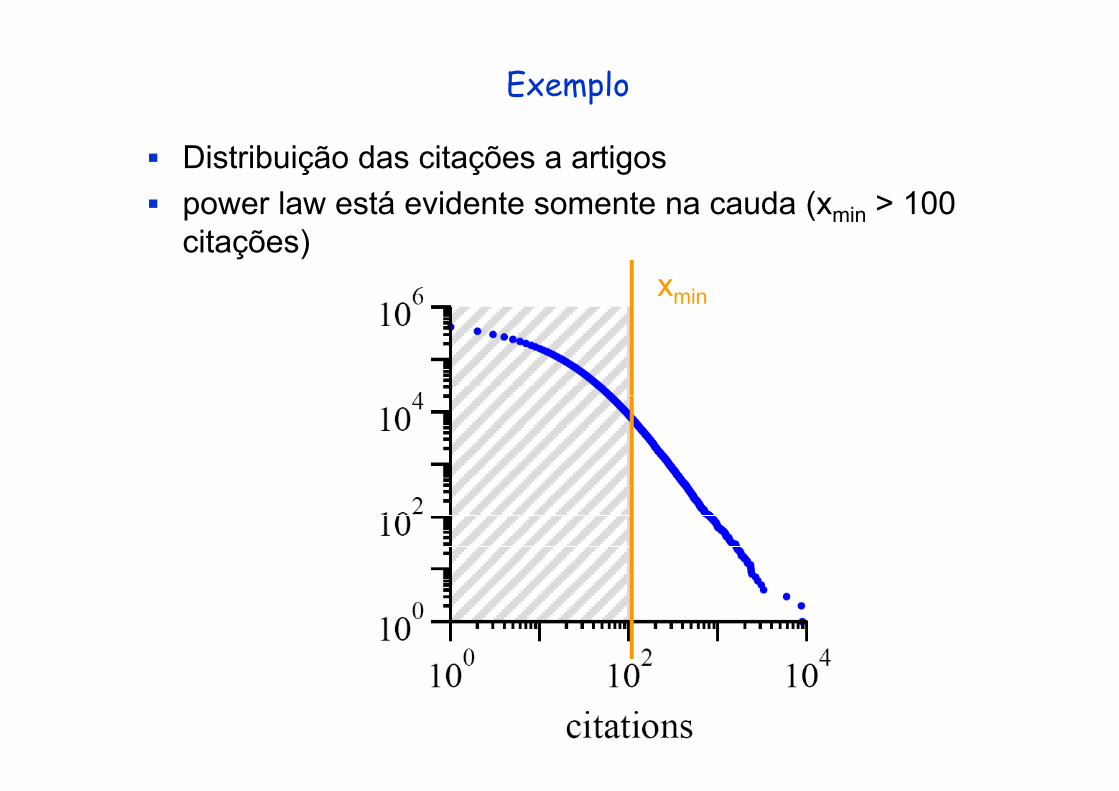
Exemplo
Distribuição das citações a artigospower law está evidente somente na cauda (xmin > 100 p ( mincitações)
xmin
Estimativa de Expoentes (α) para Algumas Distribuiçõesp ( ) p g ç

“Maximum likelihood fitting” (melhor)
Voce necessita estar certo que tem uma distribuição power-law (o método lhe dará simplesmente o expoente, mas quão bom é o “fit”)
1
l1−
⎥⎤
⎢⎡∑
nix
1 min
ln1=
⎥⎦
⎢⎣
+= ∑i
i
xnα
xi são todos pontos de dados, e voce tem n pontos!i são todos po tos de dados, e oce te po tosPara o dataset exemplo α = 2.503 – bem próximo!
α = 2 5α = 2.5

Muitas redes reais são “power law”
Exemplos de redes recentes expoente αExemplos de redes recentes expoente α(in/out degree)
Redes de email 1.5/2.0R d d t t i 3 2Redes de contatos sexuais 3.2WWW 2.3/2.7Internet 2.5peer-to-peer 2.1
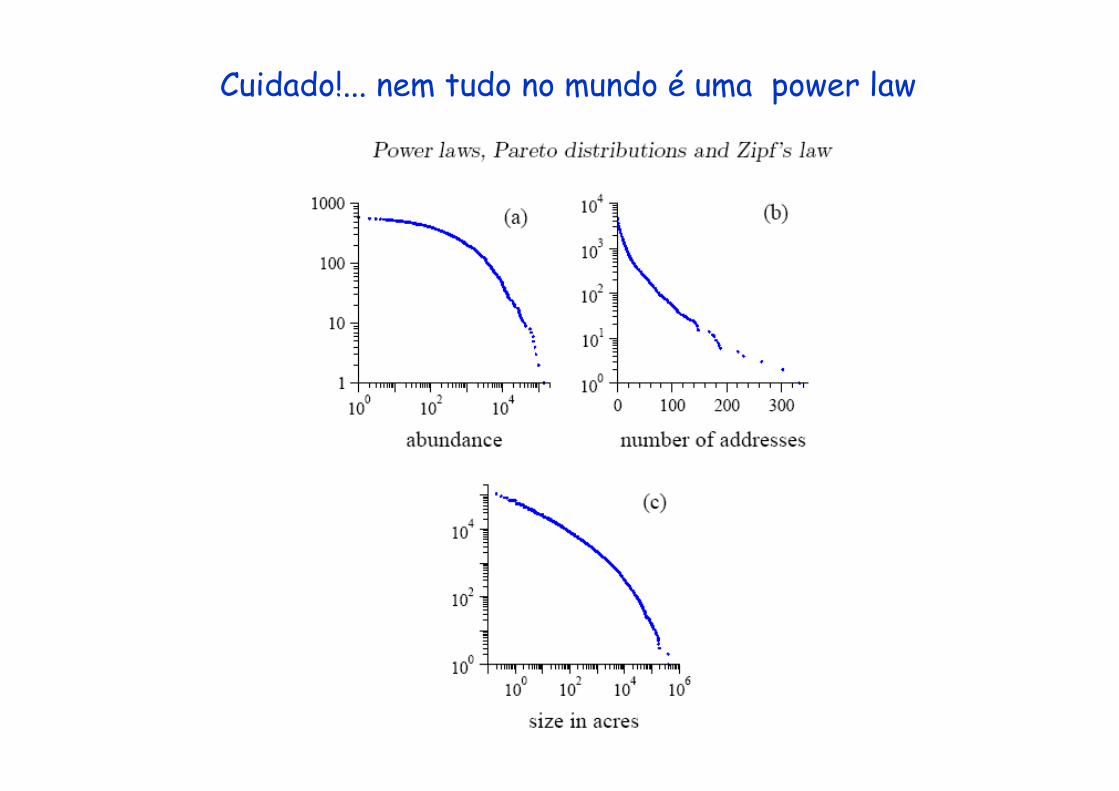
Cuidado!... nem tudo no mundo é uma power law
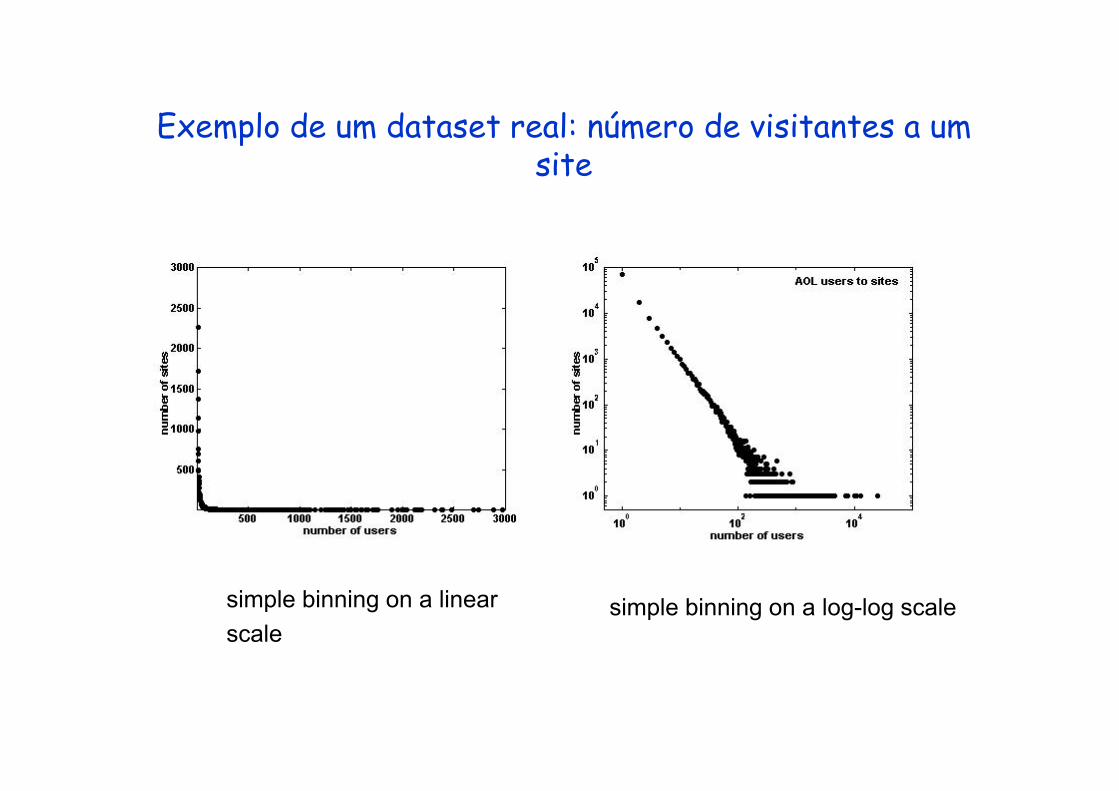
Exemplo de um dataset real: número de visitantes a um Exemplo de um dataset real: número de visitantes a um site
simple binning on a linearscale
simple binning on a log-log scale

Ao tentar fazer o fit diretamente …
Fit direto é muito baixo: α = 1.17…
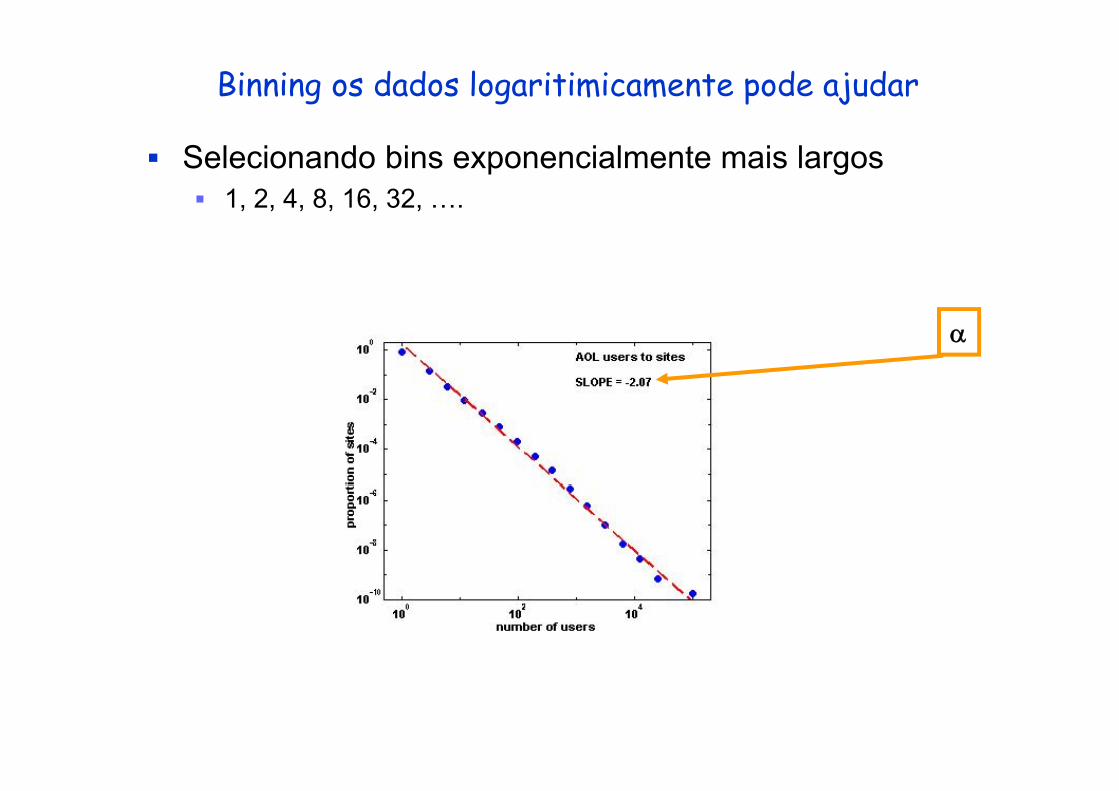
Binning os dados logaritimicamente pode ajudar
Selecionando bins exponencialmente mais largos1, 2, 4, 8, 16, 32, ….
α
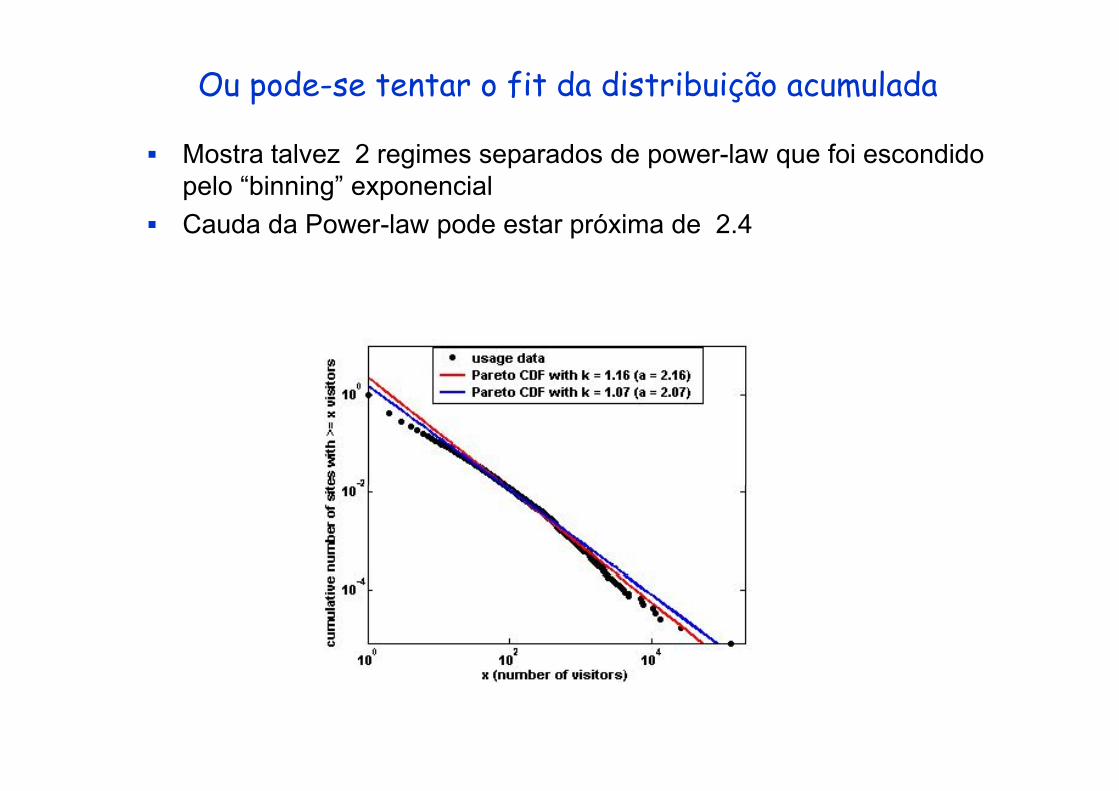
Ou pode-se tentar o fit da distribuição acumulada
Mostra talvez 2 regimes separados de power-law que foi escondido pelo “binning” exponencialC d d P l d t ó i d 2 4Cauda da Power-law pode estar próxima de 2.4
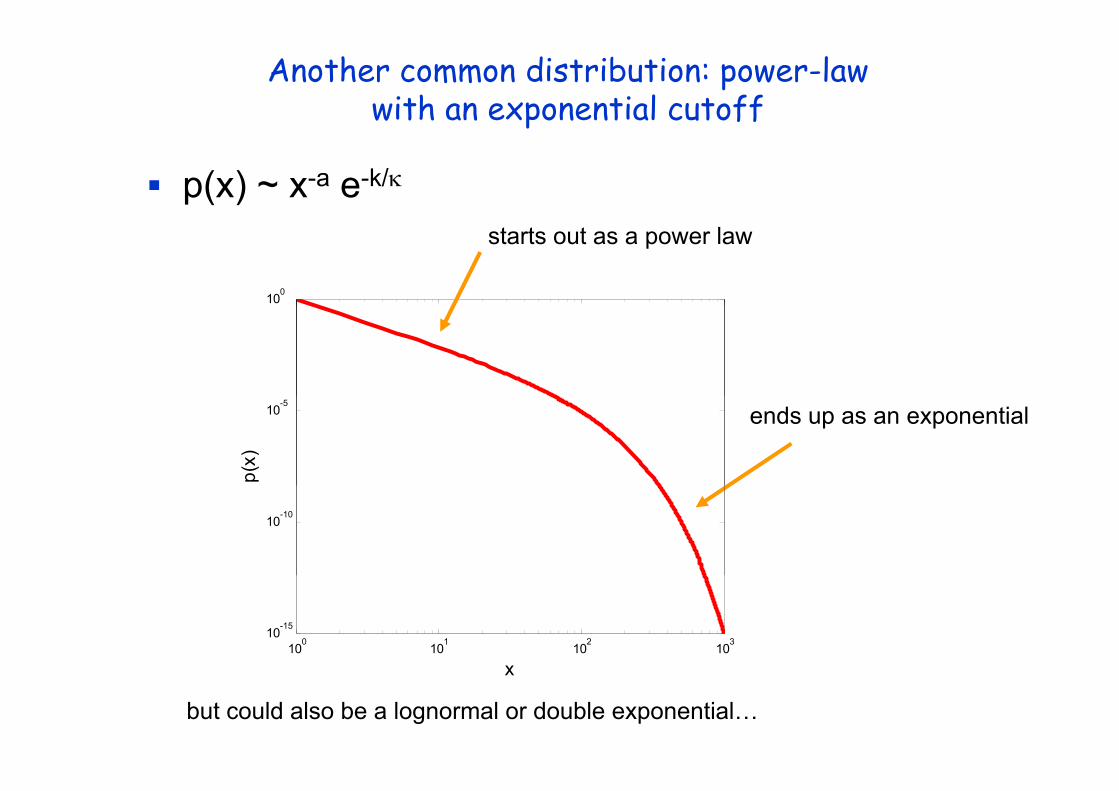
Another common distribution: power-lawwith an exponential cutoffp
p(x) ~ x-a e-k/κ
100
starts out as a power law
10-5
p(x)
ends up as an exponential
10-10
100
101
102
103
10-15
x
but could also be a lognormal or double exponential…

Zipf & Pareto: qual a relação com power-laws?q ç p
ZipfGeorge Kingsley Zipf, um professor de lingística de Harvard,procurou determinar o ‘tamanho' da 3a ou 8a ou 100a palavra mais comum.
“Tamanho”significa a frequencia de uso da palavra em ingles em um texto em ingles e não o comprimento da palavraum texto em ingles e não o comprimento da palavra propriamente.
Zipf's law afirma que o tamanho (i e frequência = y) da rZipf's law afirma que o tamanho (i.e., frequência = y) da r-ésima maior ocorrência do evento é inversamente proporcional a sua posição no rank:
y ~ r -β , com β próximo de 1.
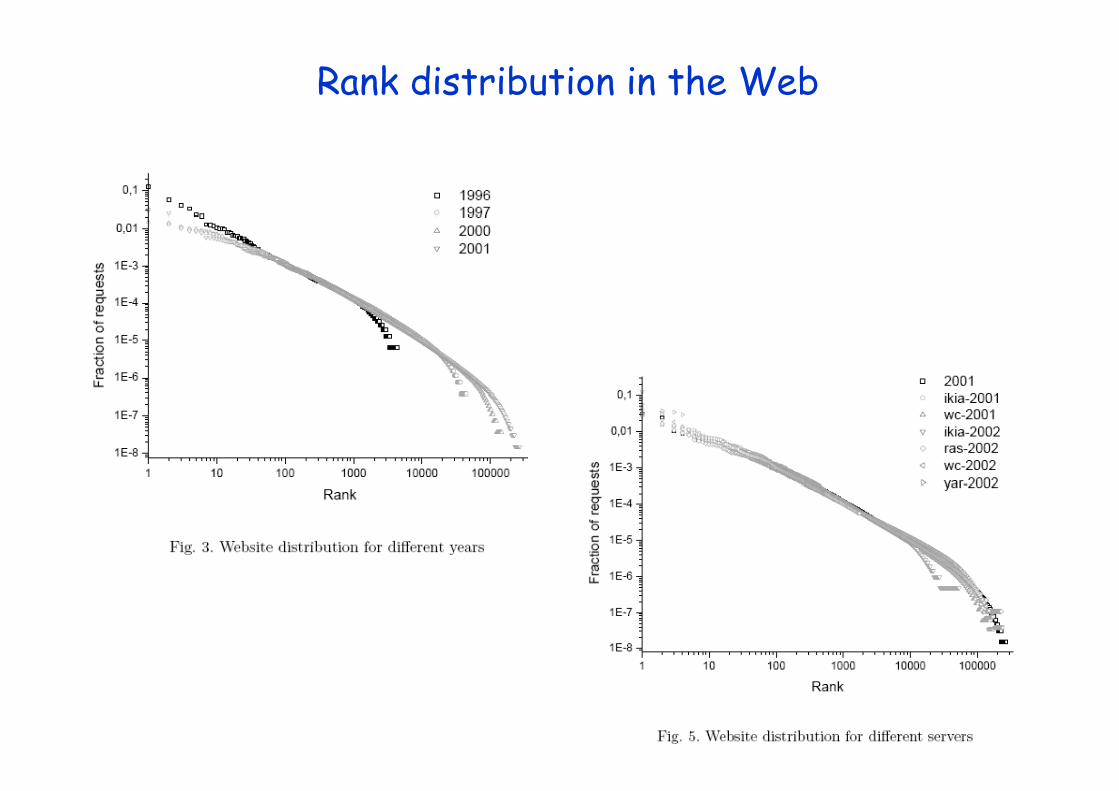
Rank distribution in the Web
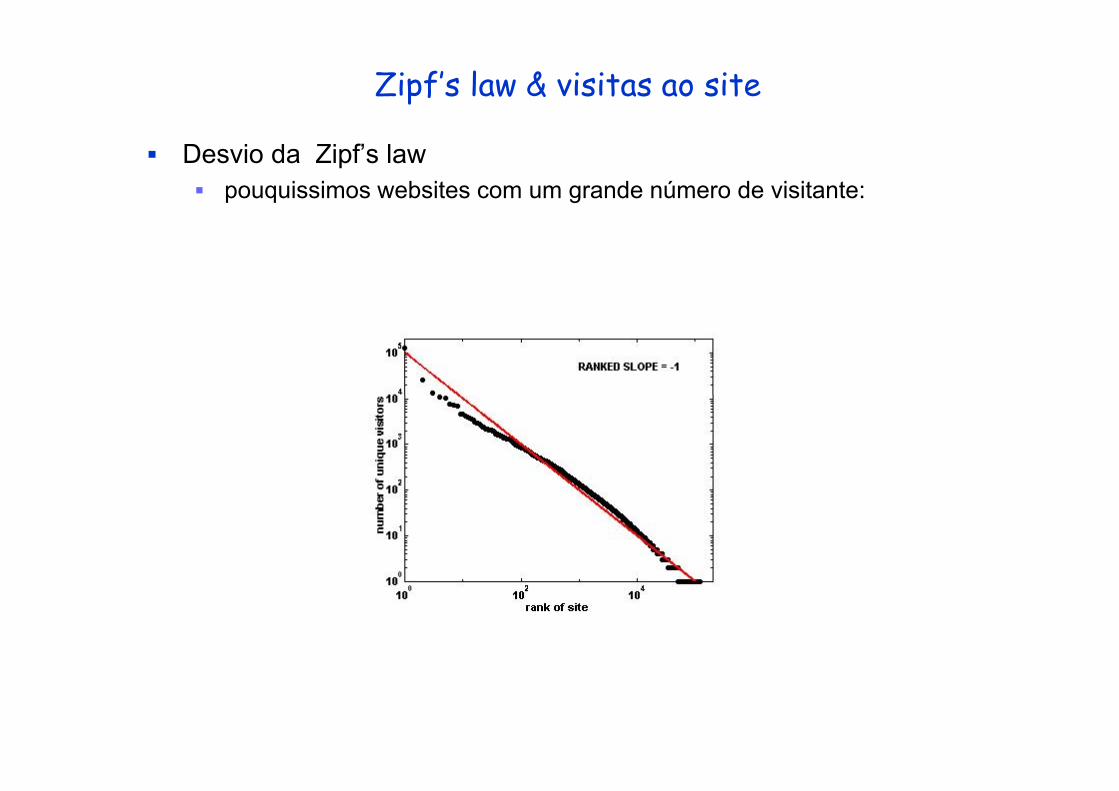
Zipf’s law & visitas ao site
Desvio da Zipf’s lawpouquissimos websites com um grande número de visitante:
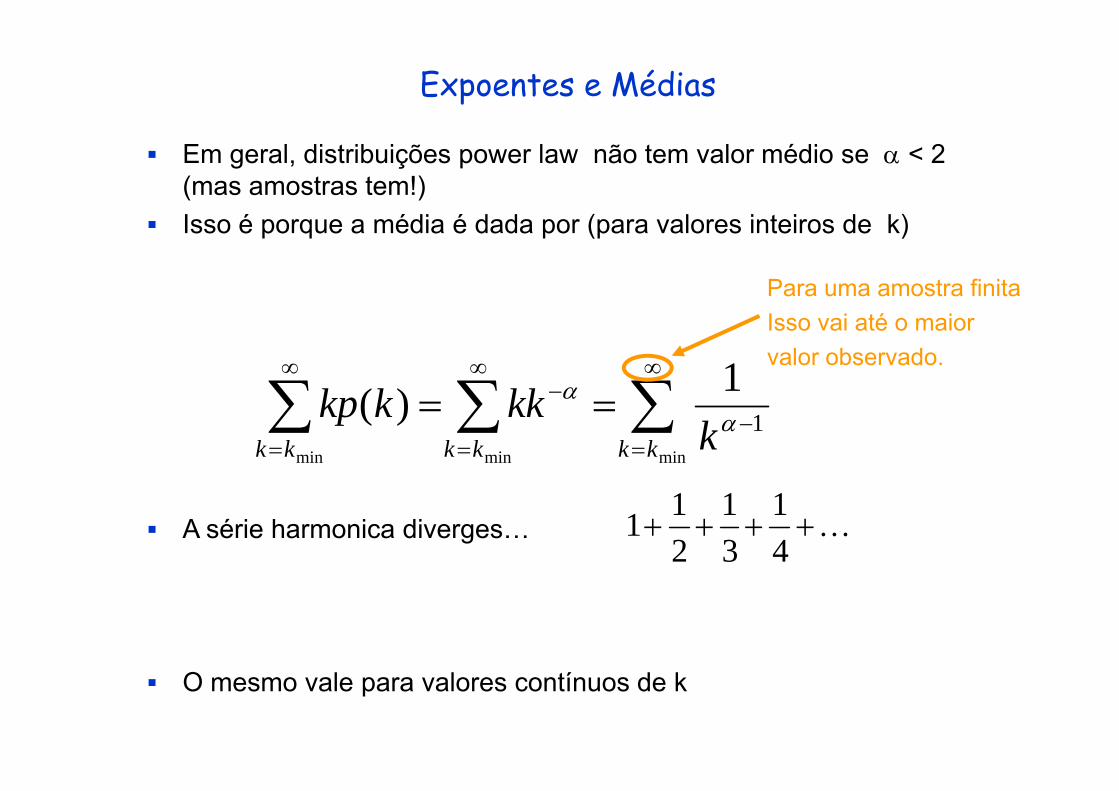
Expoentes e Médias
Em geral, distribuições power law não tem valor médio se α < 2 (mas amostras tem!)I é édi é d d ( l i t i d k)Isso é porque a média é dada por (para valores inteiros de k)
Para uma amostra finita
∑∑∑∞∞
−∞ 1)( kkkk α
Isso vai até o maior valor observado.
∑∑∑=
−==
==minminmin
1)(kkkkkk k
kkkkp αα
K++++41
31
211A série harmonica diverges…
O mesmo vale para valores contínuos de k

Regra 80/20
A fração W da riqueza nas mãos os P mais ricos da ç qpopulação é dada por:
( )/( )W = P(α−2)/(α−1)
Exemplo: riqueza nos EUA: α = 2.120% mais ricos da população detém 86% da riqueza

Processos Geradores de Power-lawsProcessos Geradores de Power-laws
Muitos processos diferentes podem levar a power lawsMuitos processos diferentes podem levar a power laws
Não existe um único mecanismo que explique todos q p qprocessos.
Próximas aulas: preferential attachment em redes, como Web e InternetWeb e Internet.





























