Embed Size (px)
Citation preview

Lectures 5 & 6: Classifiers
Hilary Term 2007 A. Zisserman
• Bayesian Decision Theory • Bayes decision rule
• Loss functions
• Likelihood ratio test
• Classifiers and Decision Surfaces • Discriminant function
• Normal distributions
• Linear Classifiers• The Perceptron
• Logistic Regression
Decision Theory
Suppose we wish to make measurements on a medical image and classify it as showing evidence of cancer or not
image x
C1cancer
C2 no cancerimage processing
decision rule
measurement
and we want to base this decision on the learnt joint distribution
How do we make the “best” decision?
p(x,Ci) = p(x|Ci)p(Ci)
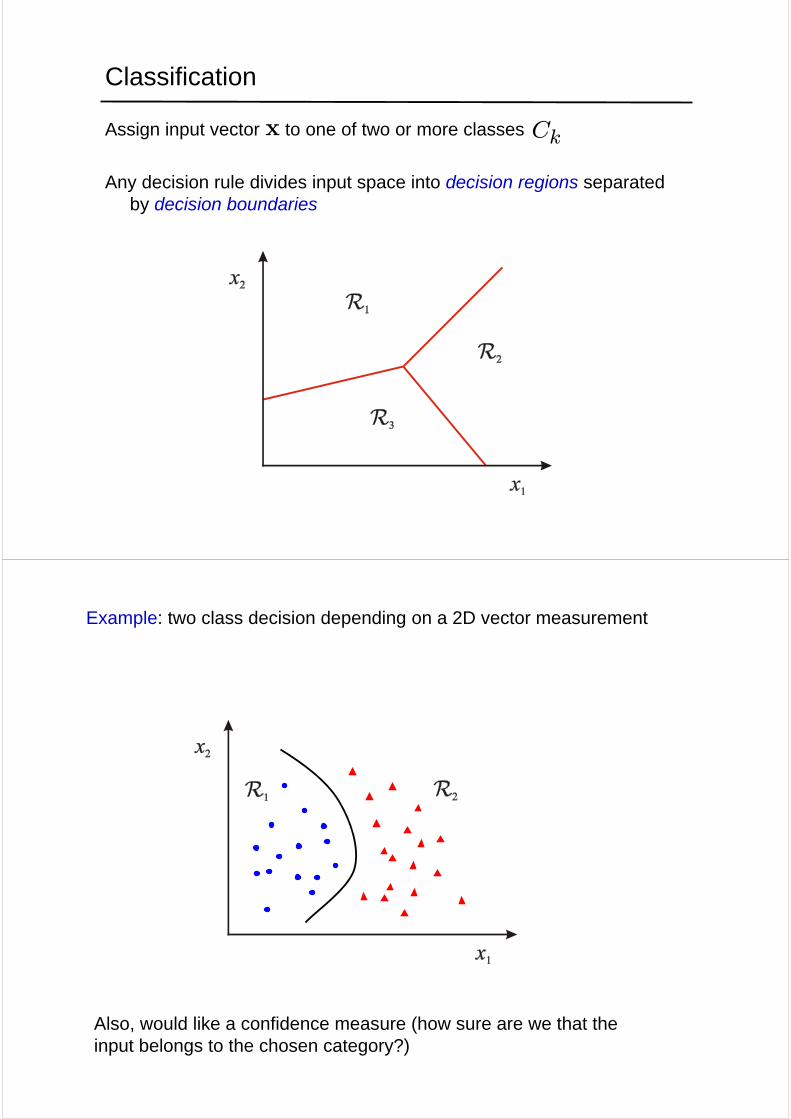
Classification
Assign input vector to one of two or more classes
Any decision rule divides input space into decision regions separated by decision boundaries
x Ck
Example: two class decision depending on a 2D vector measurement
Also, would like a confidence measure (how sure are we that the input belongs to the chosen category?)
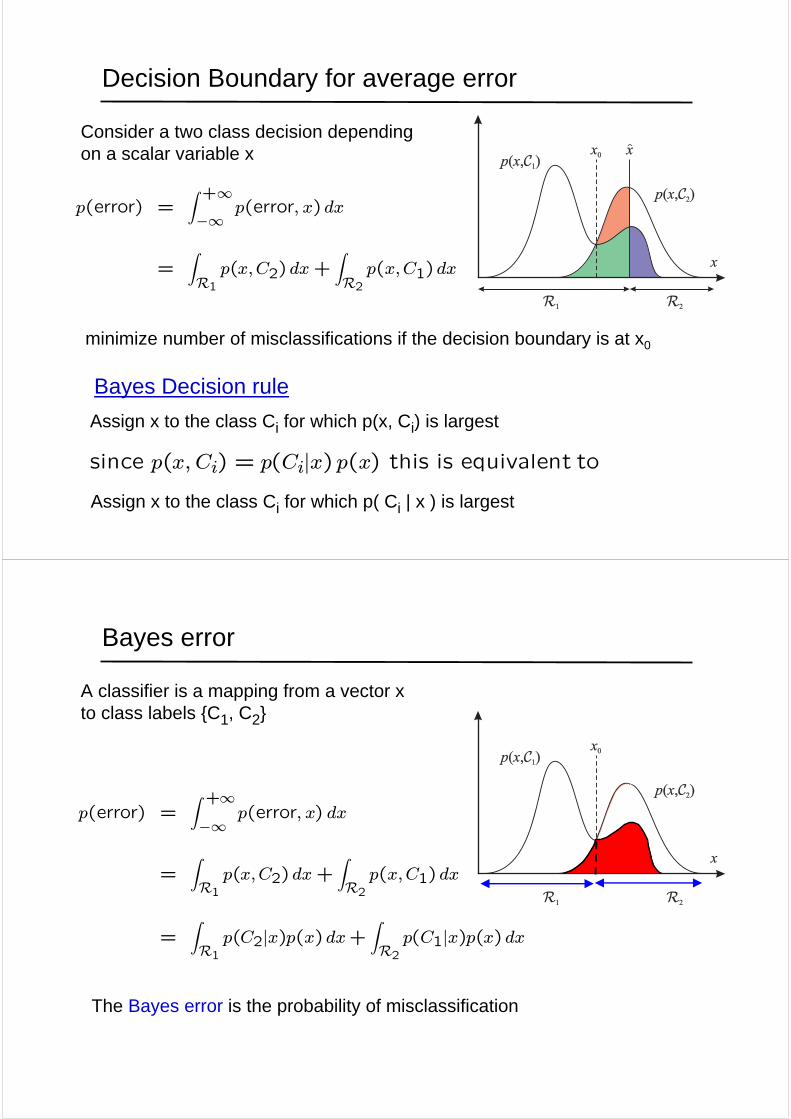
Decision Boundary for average error
Consider a two class decision depending on a scalar variable x
x
R1R1 R2R2
p x( , )C2p x( , )C2
p x( , )C1p x( , )C1
x^
x^
x0x0
minimize number of misclassifications if the decision boundary is at x0
Bayes Decision rule
Assign x to the class Ci for which p(x, Ci) is largest
Assign x to the class Ci for which p( Ci | x ) is largest
since p(x, Ci) = p(Ci|x) p(x) this is equivalent to
p(error) =Z +∞−∞
p(error, x) dx
=ZR1p(x,C2) dx+
ZR2p(x,C1) dx
Bayes error
A classifier is a mapping from a vector x to class labels {C1, C2}
The Bayes error is the probability of misclassification
p(error) =Z +∞−∞
p(error, x) dx
=ZR1p(x,C2) dx+
ZR2p(x,C1) dx
=ZR1p(C2|x)p(x) dx+
ZR2p(C1|x)p(x) dx
x
R1R1 R2R2
p x( , )C2p x( , )C2
p x( , )C1p x( , )C1
x^
x^
x0x0
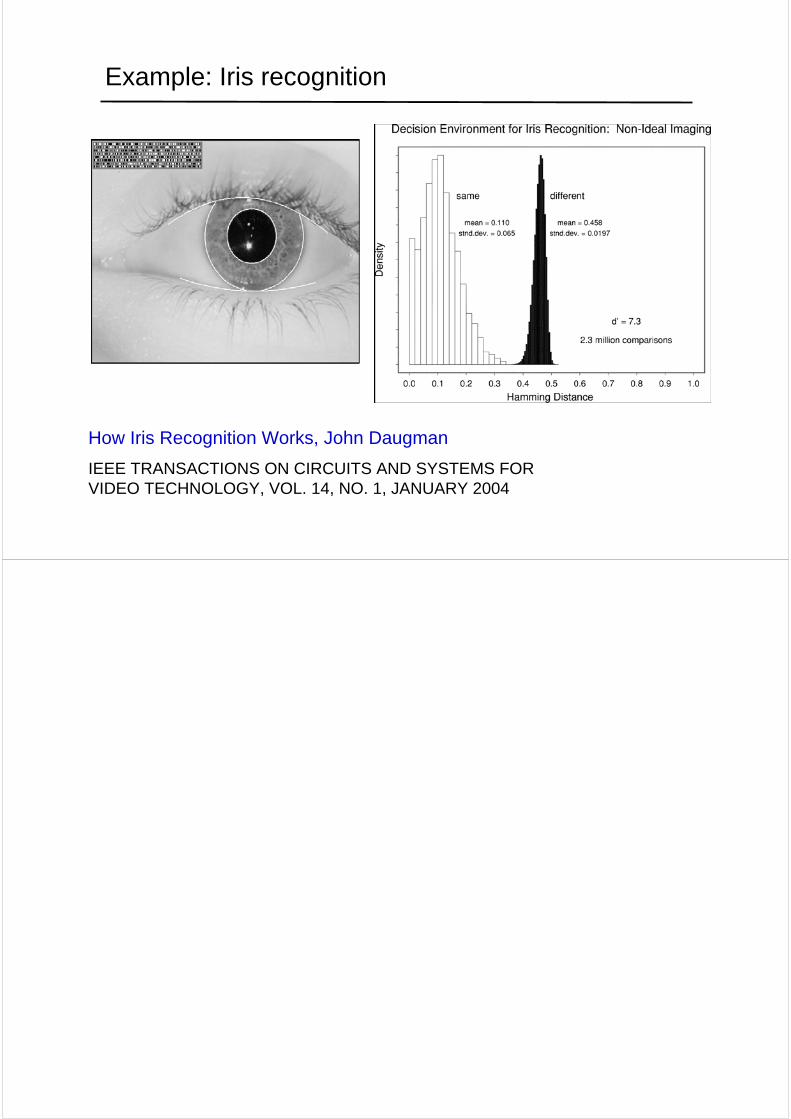
Example: Iris recognition
How Iris Recognition Works, John Daugman
IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY, VOL. 14, NO. 1, JANUARY 2004
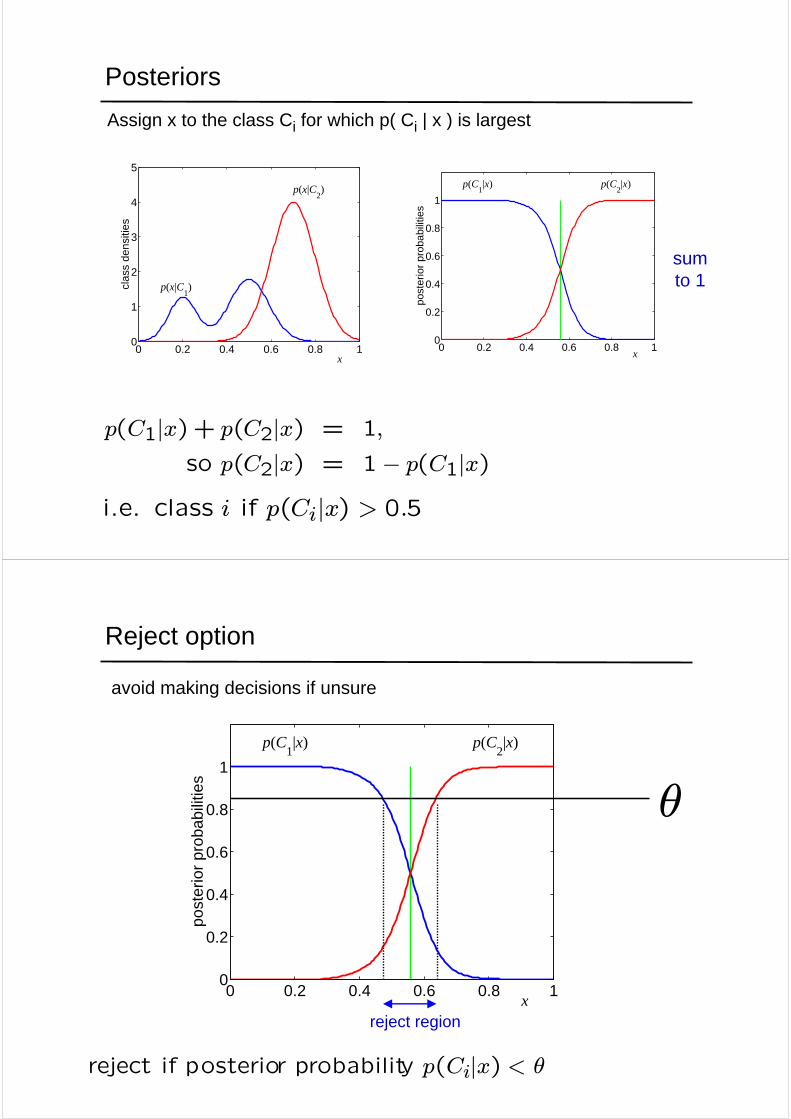
Posteriors
0 0.2 0.4 0.6 0.8 10
1
2
3
4
5
clas
s de
nsiti
es
p(x|C1)
p(x|C2)
x0 0.2 0.4 0.6 0.8 1
0
0.2
0.4
0.6
0.8
1
post
erio
r pr
obab
ilitie
s
x
p(C1|x) p(C
2|x)
Assign x to the class Ci for which p( Ci | x ) is largest
i.e. class i if p(Ci|x) > 0.5
p(C1|x)+ p(C2|x) = 1,
so p(C2|x) = 1− p(C1|x)
sum to 1
0 0.2 0.4 0.6 0.8 10
0.2
0.4
0.6
0.8
1
post
erio
r pr
obab
ilitie
s
x
p(C1|x) p(C
2|x)
Reject option
avoid making decisions if unsure
θ
reject if posterior probability p(Ci|x) < θ
reject region
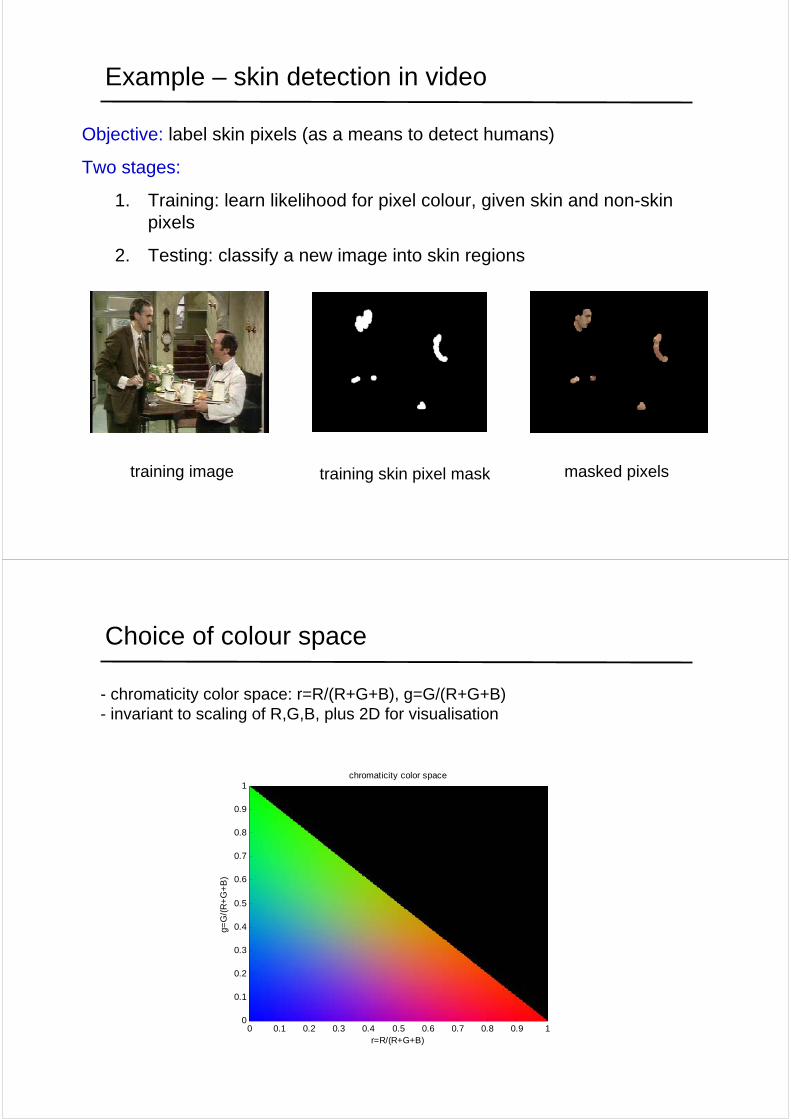
Example – skin detection in video
Objective: label skin pixels (as a means to detect humans)
Two stages:
1. Training: learn likelihood for pixel colour, given skin and non-skin pixels
2. Testing: classify a new image into skin regions
training image training skin pixel mask masked pixels
r=R/(R+G+B)
g=G
/(R
+G
+B
)
chromaticity color space
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
- chromaticity color space: r=R/(R+G+B), g=G/(R+G+B)- invariant to scaling of R,G,B, plus 2D for visualisation
Choice of colour space
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
r=R/(R+G+B)
g=G
/(R
+G
+B
)
skin pixels in chromaticity space
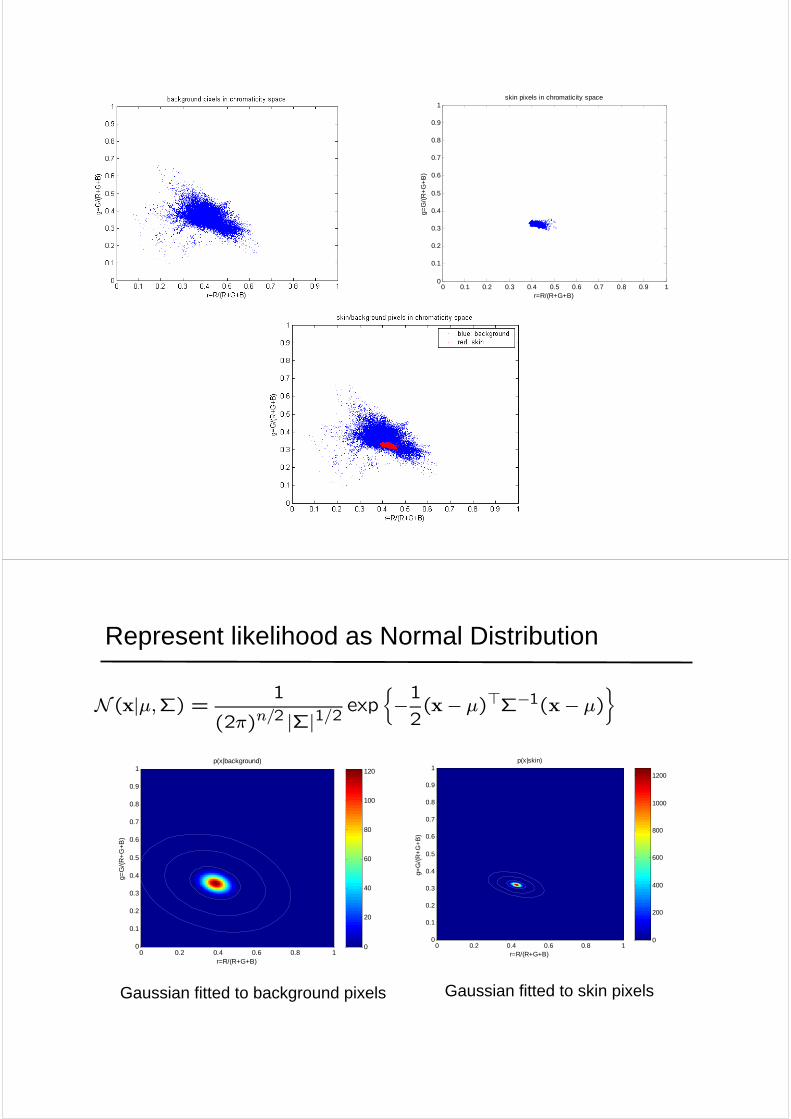
Represent likelihood as Normal Distribution
N (x|µ,Σ) = 1
(2π)n/2 |Σ|1/2exp
½−12(x− µ)>Σ−1(x− µ)
¾
r=R/(R+G+B)
g=G
/(R
+G
+B
)
p(x|background)
0 0.2 0.4 0.6 0.8 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0
20
40
60
80
100
120
Gaussian fitted to background pixels
r=R/(R+G+B)
g=G
/(R
+G
+B
)
p(x|skin)
0 0.2 0.4 0.6 0.8 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0
200
400
600
800
1000
1200
Gaussian fitted to skin pixels
r=R/(R+G+B)
g=G
/(R
+G
+B
)
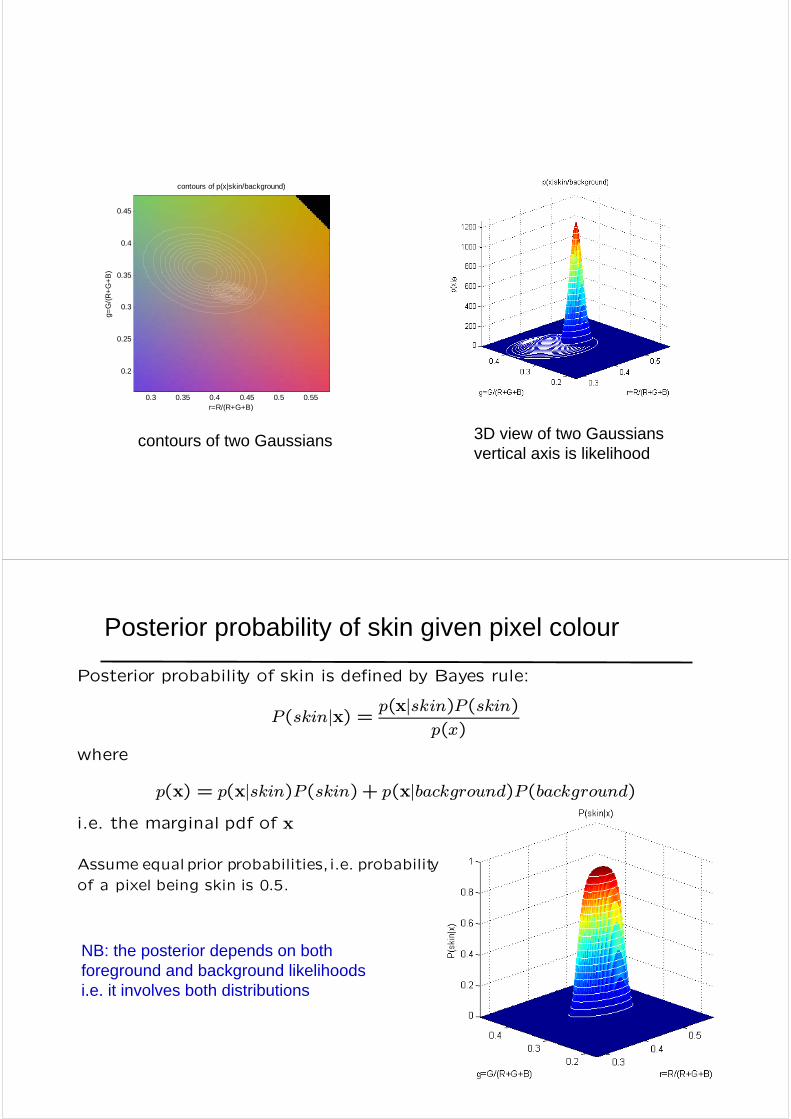
contours of p(x|skin/background)
0.3 0.35 0.4 0.45 0.5 0.55
0.2
0.25
0.3
0.35
0.4
0.45
contours of two Gaussians 3D view of two Gaussiansvertical axis is likelihood
Posterior probability of skin given pixel colour
Assume equal prior probabilities, i.e. probability
of a pixel being skin is 0.5.
Posterior probability of skin is defined by Bayes rule:
P(skin|x) = p(x|skin)P(skin)p(x)
where
p(x) = p(x|skin)P(skin)+ p(x|background)P(background)i.e. the marginal pdf of x
NB: the posterior depends on both foreground and background likelihoods i.e. it involves both distributions
P(x|background)
0
20
40
60
80
100
120
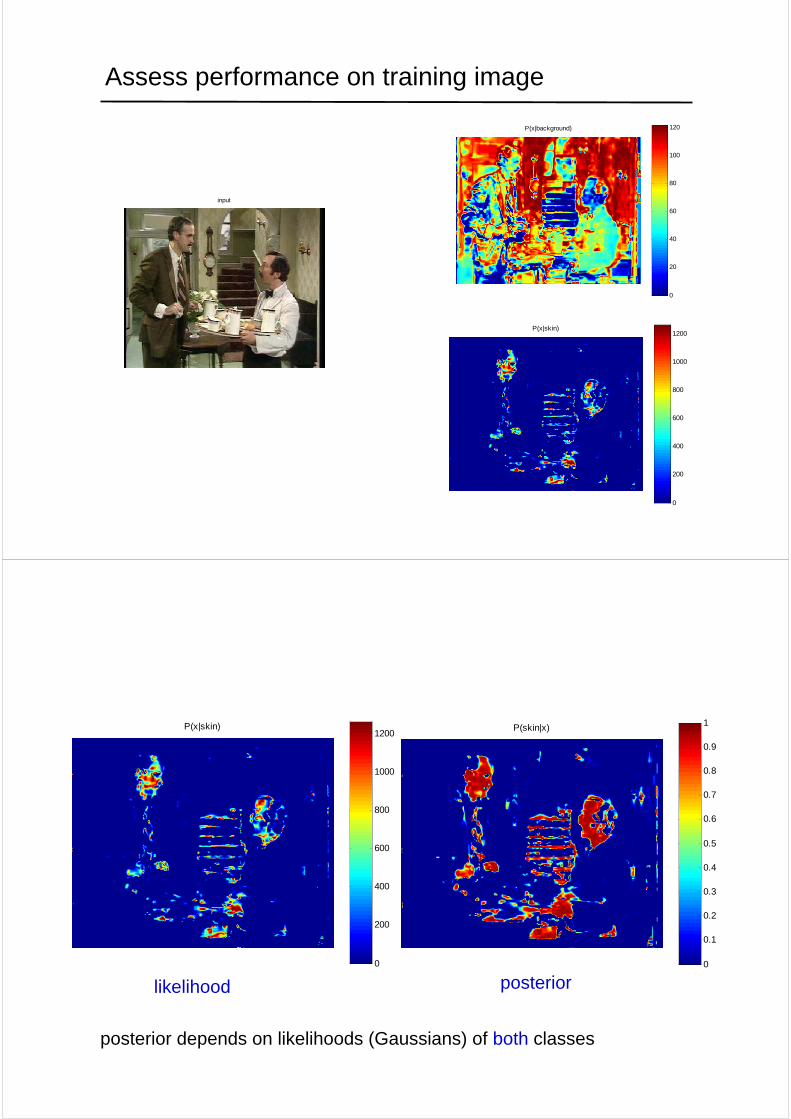
Assess performance on training image
input
P(x|skin)
0
200
400
600
800
1000
1200
P(skin|x)
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1P(x|skin)
0
200
400
600
800
1000
1200
likelihood posterior
posterior depends on likelihoods (Gaussians) of both classes
P(skin|x)
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1P(skin|x)>0.5
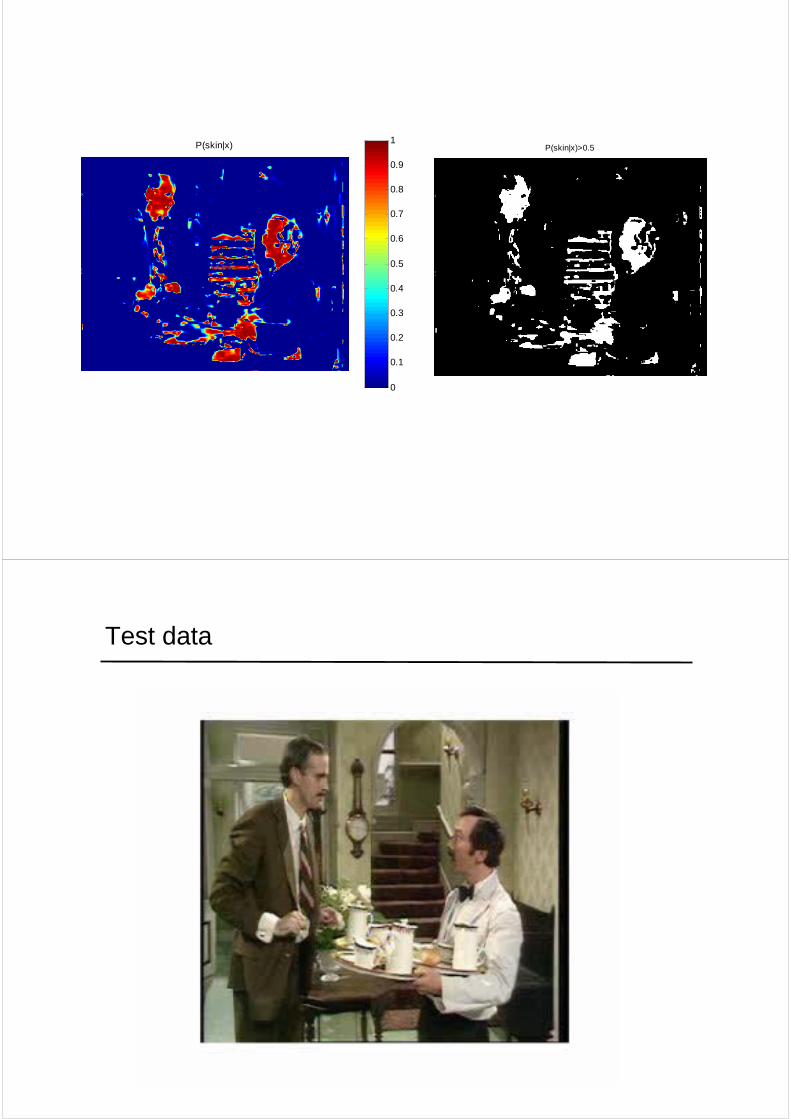
Test data

p(x|background)
p(x|skin)

p(skin|x)
p(skin|x)>0.5
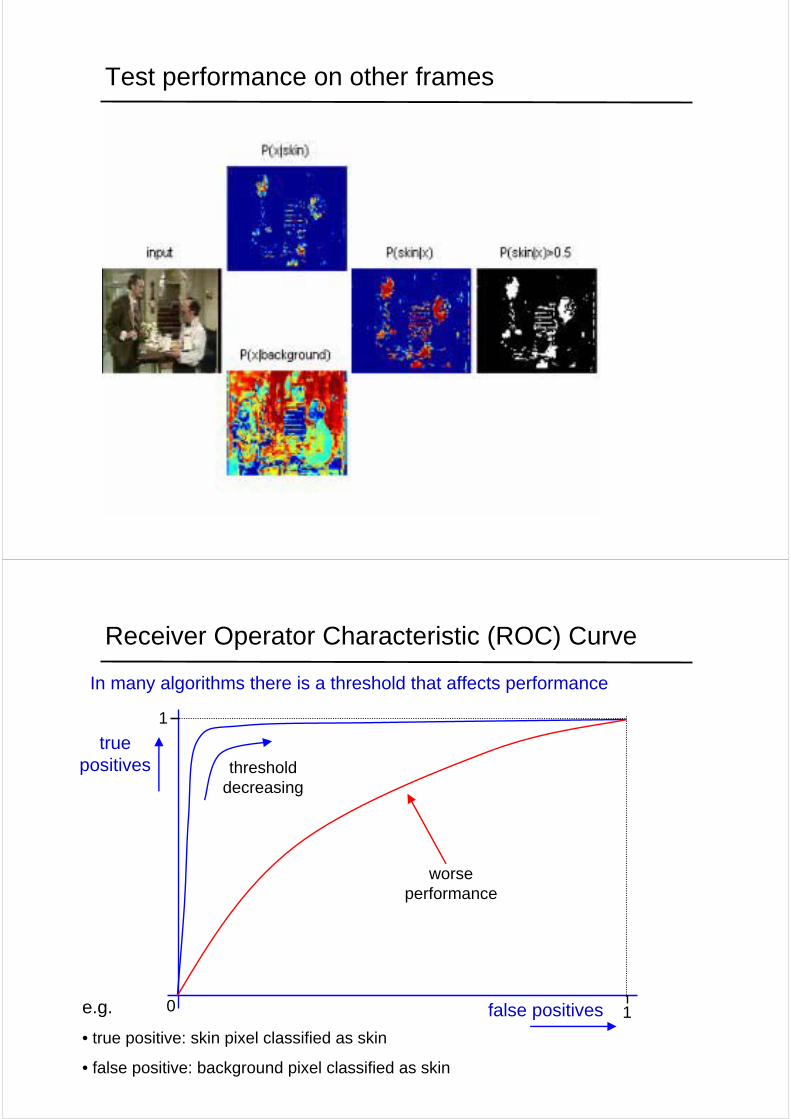
Test performance on other frames
Receiver Operator Characteristic (ROC) Curve
In many algorithms there is a threshold that affects performance
true positives
false positives
1
10e.g.
• true positive: skin pixel classified as skin
• false positive: background pixel classified as skin
threshold decreasing
worse performance

Loss function revisited
Consider again the cancer diagnosis example. The consequences for an incorrect classification vary for the following cases:
• False positive: does not have cancer, but is classified as having it
> distress, plus unnecessary further investigation
• False negative: does have cancer, but is classified as not having it
> no treatment, premature death
The two other cases are true positive and true negative.
Because the consequences of a false negative far outweigh the others, rather than simply minimize the number of mistakes, a loss function can be minimized.
Loss matrix
R(Ci|x) =Xj
Lijp(Cj|x)
Lij =0 1
1000 0
cancer normal
cancer
normalclassification
truth
true +ve false +ve
false -ve true -ve
Risk

Bayes Risk
The class conditional risk of an action is
R(ai|x) =Xj
L(ai|Cj)p(Cj|x)
action
measurement
loss incurred if action i taken and true state is j
Bayes decision rule: select the action for which R(ai | x) is minimum
Mininimize Bayes risk
This decision minimizes the expected loss
ai = argminaiR(ai|x)
Likelihood ratio
Two category classification with loss function
Conditional risk
R(a1|x) = L11p(C1|x)+ L12p(C2|x)R(a2|x) = L21p(C1|x)+ L22p(C2|x)
Thus for minimum risk, decide C1 if
L11p(C1|x)+ L12p(C2|x) < L21p(C1|x) + L22p(C2|x)p(C2|x)(L12− L22) < p(C1|x)(L21− L11)
p(x|C2)p(C2)(L12− L22) < p(x|C1)p(C1)(L21 − L11)Assuming L21 − L11 > 0, then decide C1 if
p(x|C1)p(x|C2)
>p(C2)(L22 − L12)p(C1)(L11− L21)
i.e. likelihood ratio exceeds a threshold that is independent of x
Bayes
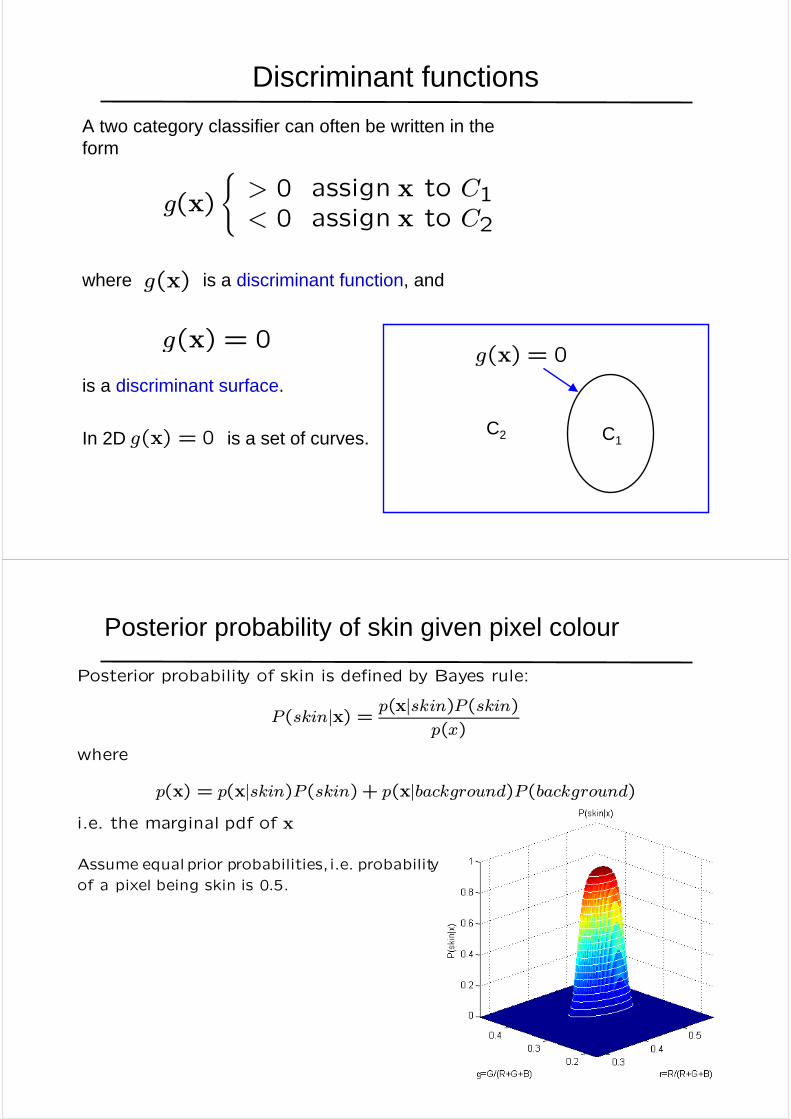
A two category classifier can often be written in the form
where is a discriminant function, and
is a discriminant surface.
In 2D is a set of curves.
Discriminant functions
g(x)
C1C2
g(x)
(> 0 assign x to C1< 0 assign x to C2
g(x) = 0
g(x) = 0
g(x) = 0
Posterior probability of skin given pixel colour
Assume equal prior probabilities, i.e. probability
of a pixel being skin is 0.5.
Posterior probability of skin is defined by Bayes rule:
P(skin|x) = p(x|skin)P(skin)p(x)
where
p(x) = p(x|skin)P(skin)+ p(x|background)P(background)i.e. the marginal pdf of x

ExampleIn the minimum average error classifier, the assignment rule is: decide C1if the posterior p(C1|x) > p(C2|x).
The equivalent discriminant function is
g(x) = p(C1|x)− p(C2|x)or
g(x) = lnp(C1|x)p(C2|x)
Note, these two functions are not equal, but the decision boundaries are
the same.
Developing this further
g(x) = lnp(C1|x)p(C2|x)
= lnp(x|C1)p(x|C2)
+ lnp(C1)
p(C2)
Decision surfaces for Normal distributions
Suppose that the likelihoods are Normal:
p(x|C1) ∼ N(µ1,Σ1) p(x|C2) ∼ N(µ2,Σ2)
Then
g(x) = lnp(x|C1)p(x|C2)
+ lnp(C1)
p(C2)
= lnp(x|C1)− lnp(x|C2)+ lnp(C1)
p(C2)
∼ −(x− µ1)>Σ−11 (x− µ1)+ (x− µ2)>Σ−12 (x− µ2) + c0
where c0 = ln p(C1)p(C2)
− 12 ln |Σ1|+12 ln |Σ2|.
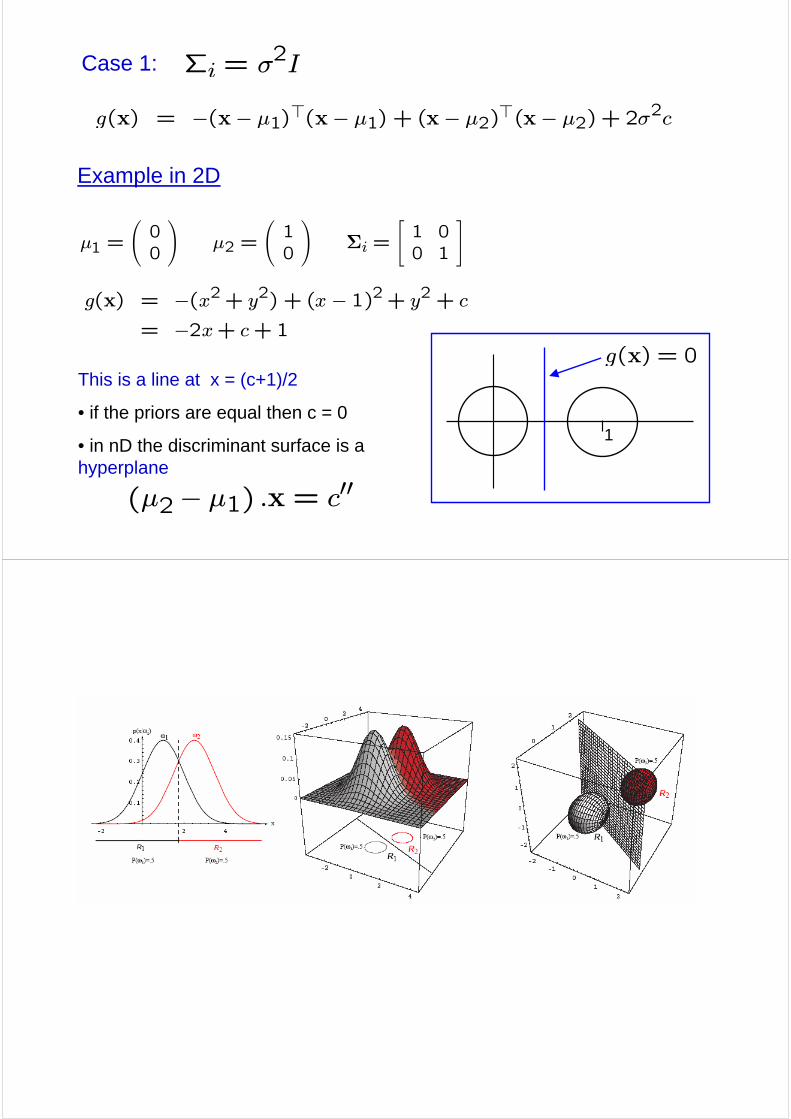
Case 1: Σi = σ2I
g(x) = −(x− µ1)>(x− µ1) + (x− µ2)>(x− µ2)+ 2σ2c
µ1 =
Ã00
!µ2 =
Ã10
!Σi =
"1 00 1
#Example in 2D
This is a line at x = (c+1)/2
• if the priors are equal then c = 0
• in nD the discriminant surface is a hyperplane
1
g(x) = 0
(µ2− µ1) .x= c00
g(x) = −(x2+ y2) + (x − 1)2+ y2 + c
= −2x+ c+1
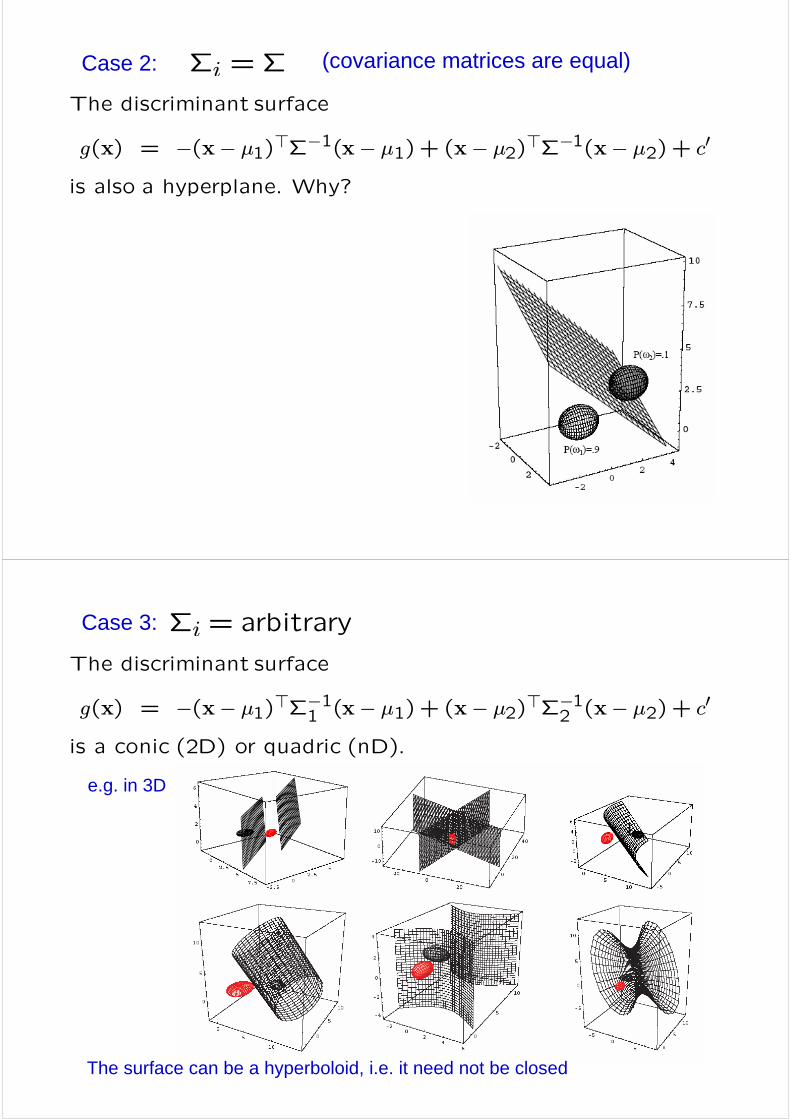
Case 2:
The discriminant surface
g(x) = −(x− µ1)>Σ−1(x− µ1)+ (x− µ2)>Σ−1(x− µ2)+ c0
is also a hyperplane. Why?
Σi =Σ (covariance matrices are equal)
Case 3: Σi = arbitrary
The discriminant surface
g(x) = −(x− µ1)>Σ−11 (x− µ1)+ (x− µ2)>Σ−12 (x− µ2)+ c0
is a conic (2D) or quadric (nD).
e.g. in 3D
The surface can be a hyperboloid, i.e. it need not be closed

Discriminative Methods
1. Measure feature vectors (e.g. in 2D for skin colour) for each class from training data
2. Learn likelihood pdfs for each class (and priors)
3. Represent likelihoods by fitting Gaussians
4. Compute the posteriors p(Ci | x )
5. Compute the discriminant surface (from the likelihood Gaussians)
6. In 2D the curve is a conic …X2
X1
Why not fit the discriminant curve to the data directly?
So far, we have carried out the following steps in order to compute a discriminant surface:
Linear classifiers
X2
X1
A linear discriminant has the form
• in 2D a linear discriminant is a line, in nD it is a hyperplane
• is the normal to the plane, and the bias
• is known as the weight vector
g(x) = 0
g(x) = w>x+ w0
w w0
w
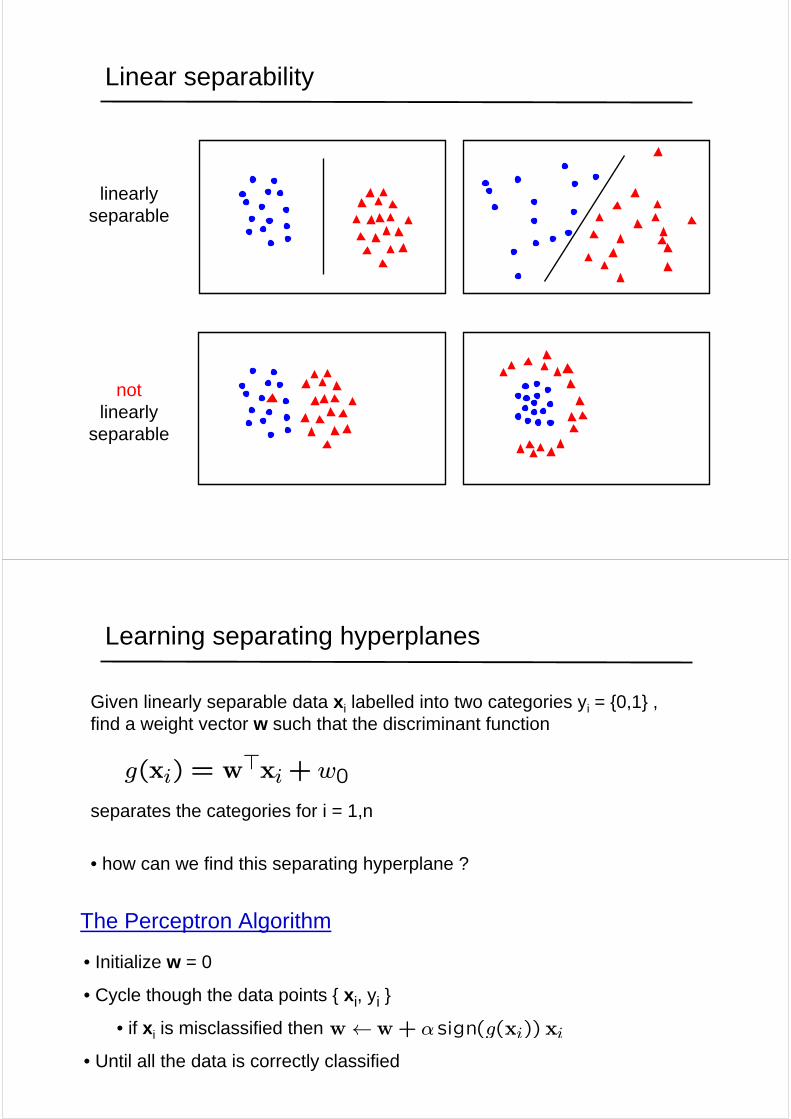
Linear separability
linearly separable
not linearly
separable
Given linearly separable data xi labelled into two categories yi = {0,1} , find a weight vector w such that the discriminant function
separates the categories for i = 1,n
• how can we find this separating hyperplane ?
Learning separating hyperplanes
g(xi) = w>xi+ w0
The Perceptron Algorithm
• Initialize w = 0
• Cycle though the data points { xi, yi }
• if xi is misclassified then
• Until all the data is correctly classified
w←w+ α sign(g(xi)) xi
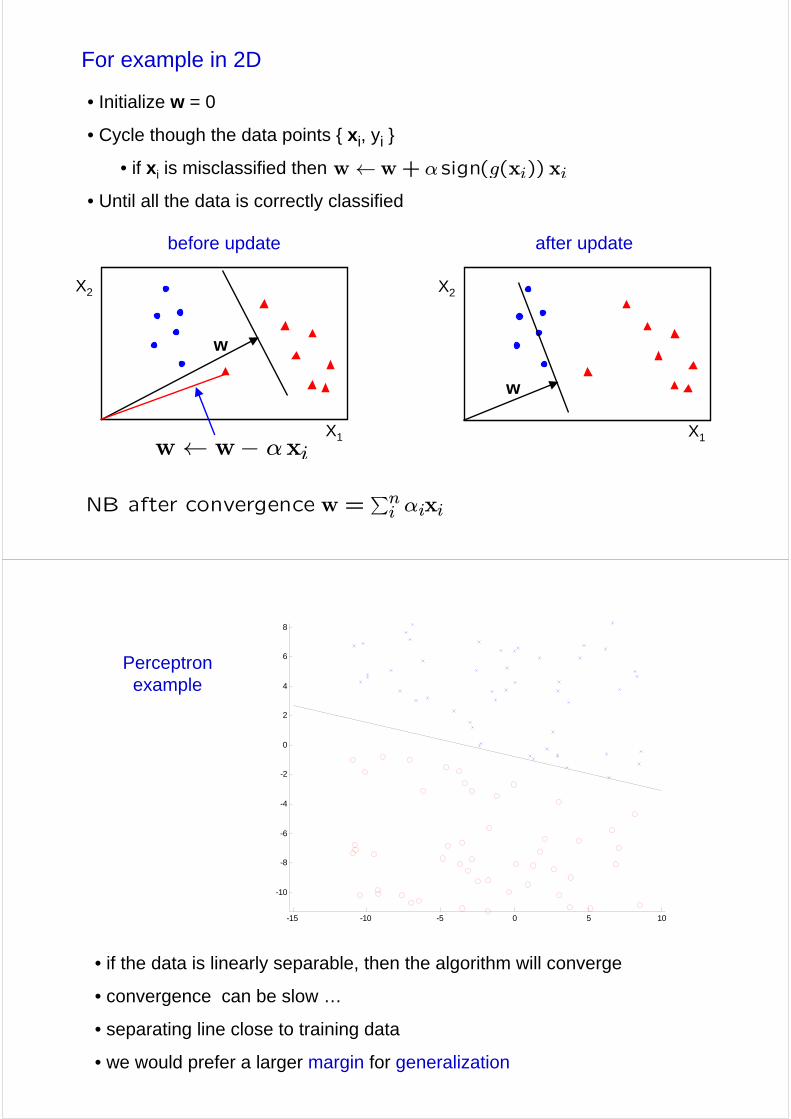
For example in 2D
X2
X1
X2
X1
w
before update after update
w
NB after convergence w =Pni αixi
• Initialize w = 0
• Cycle though the data points { xi, yi }
• if xi is misclassified then
• Until all the data is correctly classified
w←w+ α sign(g(xi)) xi
w← w− αxi
• if the data is linearly separable, then the algorithm will converge
• convergence can be slow …
• separating line close to training data
• we would prefer a larger margin for generalization
-15 -10 -5 0 5 10
-10
-8
-6
-4
-2
0
2
4
6
8
Perceptronexample
-15 -10 -5 0 5 10-12
-10
-8
-6
-4
-2
0
2
4
6
8
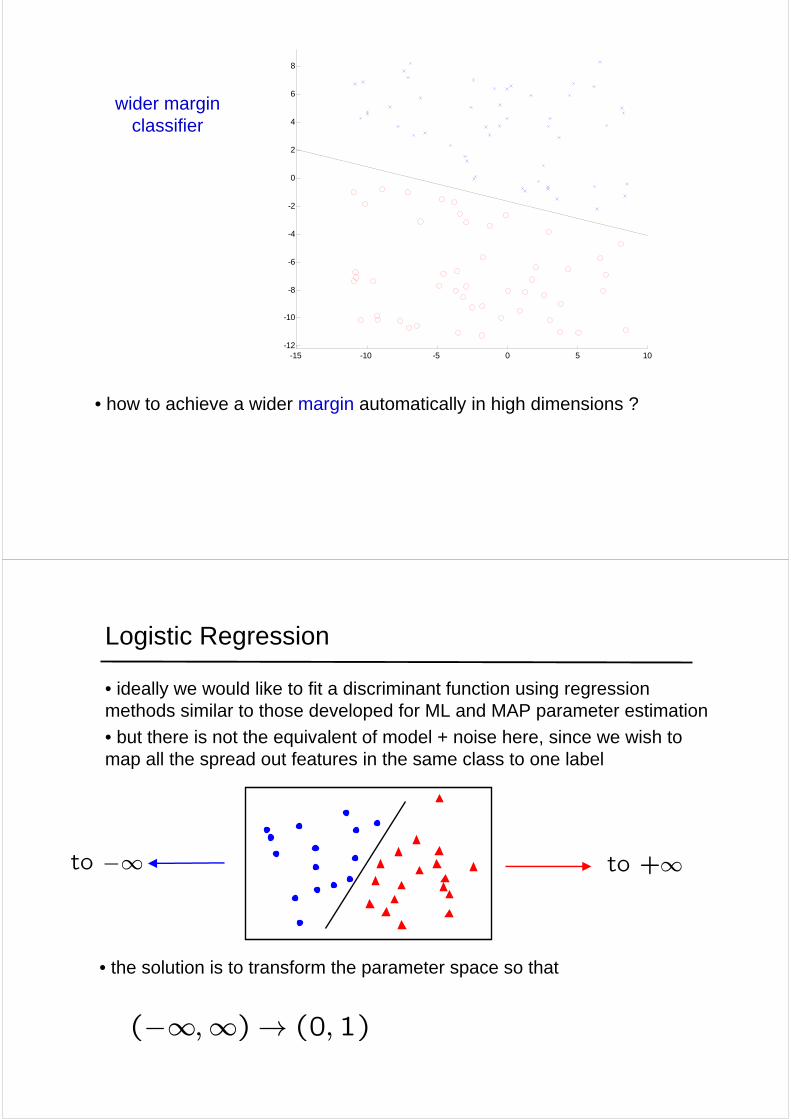
wider margin classifier
• how to achieve a wider margin automatically in high dimensions ?
Logistic Regression
• ideally we would like to fit a discriminant function using regression methods similar to those developed for ML and MAP parameter estimation
• but there is not the equivalent of model + noise here, since we wish to map all the spread out features in the same class to one label
to +∞to −∞
(−∞,∞)→ (0, 1)
• the solution is to transform the parameter space so that
Notation: write the equation
more compactly as
• e.g. in 2D
g(x) = w>x
g(x) =³w2 w1 w0
´⎛⎜⎝ x1x21
⎞⎟⎠
g(x) = w>x+ w0
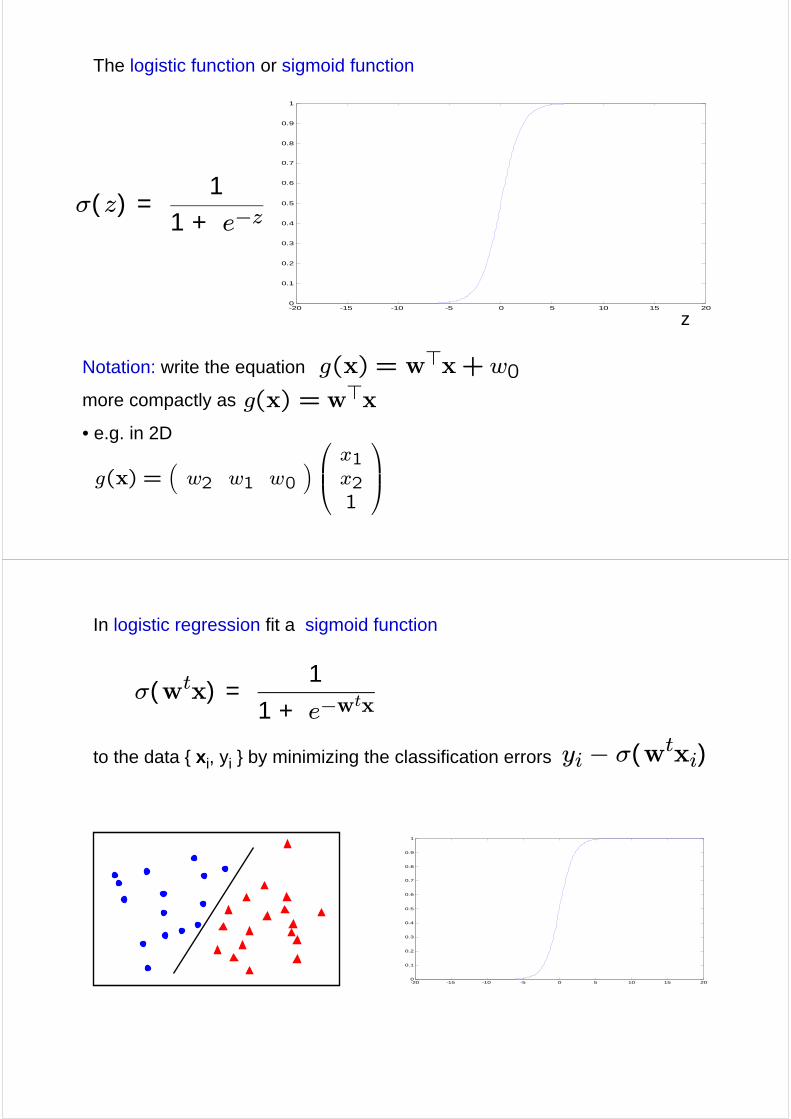
The logistic function or sigmoid function
-20 -15 -10 -5 0 5 10 15 200
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
z
σ( z) =1
1 + e−z
In logistic regression fit a sigmoid function
to the data { xi, yi } by minimizing the classification errors
-20 -15 -10 -5 0 5 10 15 200
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
σ(wtx) =1
1 + e−wtx
yi − σ(wtxi)

Maximum Likelihood Estimation
Assume
p(y = 1|x;w) = σ(w>x)p(y = 0|x;w) = 1− σ(w>x)
write this more compactly as
p(y|x;w) =³σ(w>x)
´y ³1− σ(w>x)
´(1−y)
Then the likelihood (assuming independence) is
p(y|x;w) ∼nYi
³σ(w>xi)
´yi ³1− σ(w>xi)
´(1−yi)and the negative log likelihood is
L(w) = −nXi
yi logσ(w>xi)+ (1− yi) log(1− σ(w>xi))
Note
• this is similar, but not identical, to the perceptron update rule.
• there is a unique solution for
• in n-dimensions it is only necessary to learn n+1 parameters. Comparethis with learning normal distributions where learning involves 2n parameters for the means and n(n+1)/2 for a common covariance matrix
w
[exercise]Minimize L(w) using gradient descent
∂
∂wjL(w) = −
Xi
³yi− σ(w>xi)
´xj
which gives the update rule
w← w+ α(σ(w>xi) − yi)xi
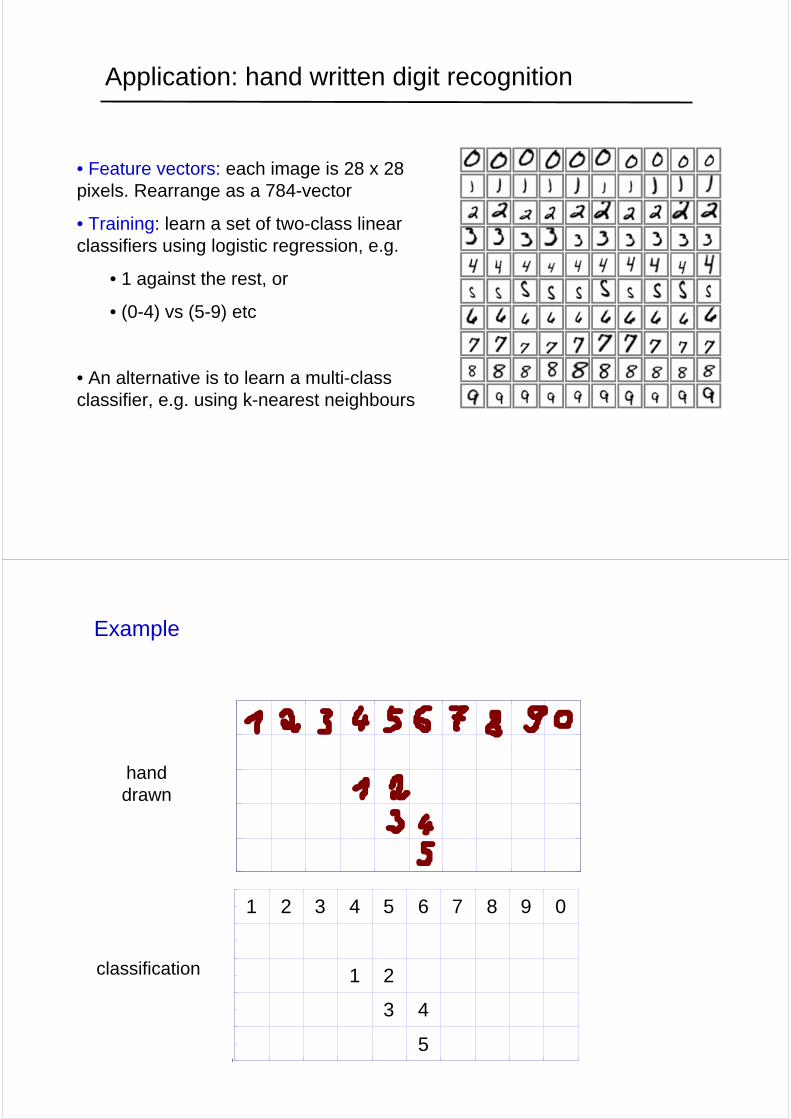
Application: hand written digit recognition
• Feature vectors: each image is 28 x 28 pixels. Rearrange as a 784-vector
• Training: learn a set of two-class linear classifiers using logistic regression, e.g.
• 1 against the rest, or
• (0-4) vs (5-9) etc
• An alternative is to learn a multi-class classifier, e.g. using k-nearest neighbours
0
5
5
2
5
3
5
4
5
5
1 2 3 4 5 6 7 8 9 0
1 2
3 4
5
Example
hand drawn
classification

Comparison of discriminant and generative approaches
Discriminant+ don’t have to learn parameters which aren’t used (e.g. covariance)+ easy to learn - no confidence measure- have to retrain if dimension of feature vectors changed
Generative+ have confidence measure+ can use ‘reject option’+ easy to add independent measurements
- expensive to train (because many parameters)
p(Ck|xA ,xB ) ∝ p(xA ,xB |Ck)p(Ck)
∝ p(xA |Ck)p(xB |Ck)p(Ck)
∝ p(Ck|xA )p(Ck|xB )
p(Ck)
Perceptrons (1969)
Recent progress in Machine Learning
Perceptron
Generalize to
g(x) = w>x where w =Pni αixi
g(x) =Xi
αixi>x
g(x) =Xi
αiφ(xi)tφ(x)
Non-examinable
where φ(x) is a map from x to a higher dimension.
For example, for x= (x1, x2)t
φ(x) = (x21, x22,√2x1x2)
t
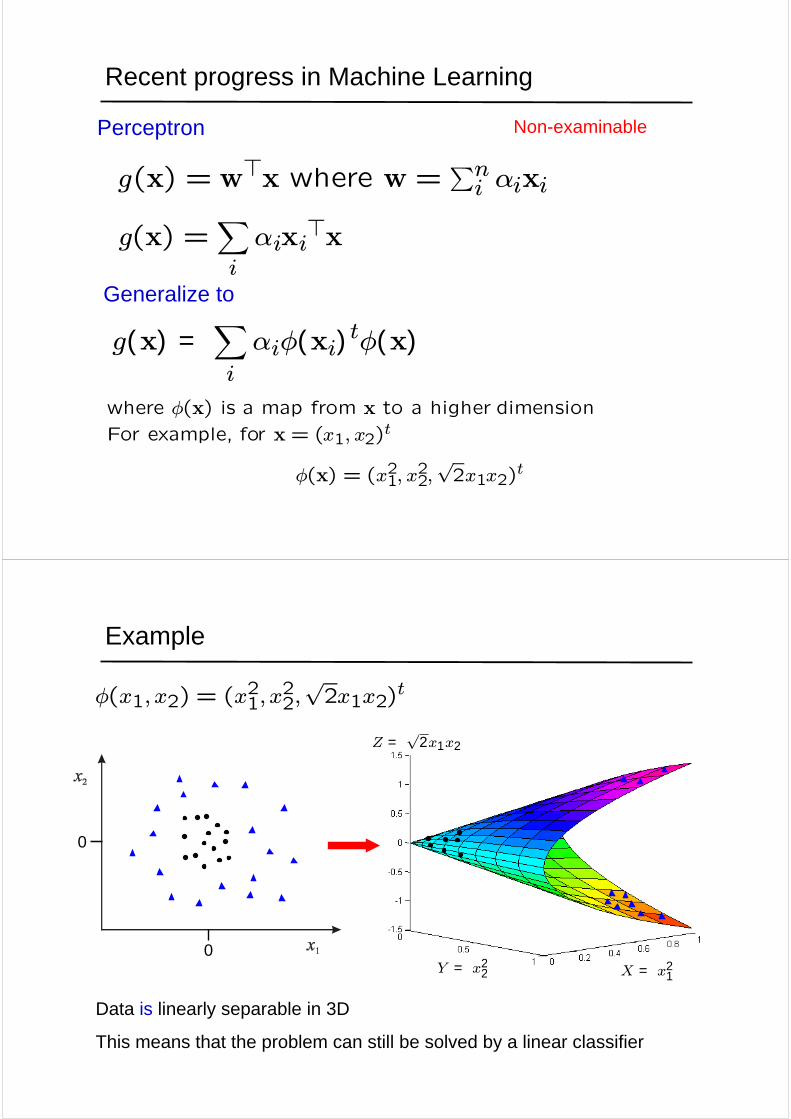
Example
0
0X = x2
1Y = x2
2
Z =√
2x1x2
Data is linearly separable in 3D
This means that the problem can still be solved by a linear classifier
φ(x1, x2) = (x21, x22,√2x1x2)
t

Example
Kernels
Generalize further to
Exercise
g(x) =Xi
αiK(xi,x)
where K(x,z) is a (non-linear) Kernel function.
For example
K(x, z) ∼ exp−n(x− z)2/(2σ2)
ois a radial basis function kernel, and
K(x, z) ∼ (x.z)n
is a polynomial kernel.
If n= 2 show that
K(x, z) ∼ (x.z)2 = φ(x)tφ(z)