Embed Size (px)
Citation preview

Lecture 12 Classifiers Part 2
Lecture 12 Classifiers Part 2
Topics Topics Classifiers Maxent Classifiers Maximum Entropy Markov Models Information Extraction and chunking intro
Readings: Chapter Chapter 6, 7.1Readings: Chapter Chapter 6, 7.1
February 25, 2013
CSCE 771 Natural Language Processing

– 2 – CSCE 771 Spring 2013
OverviewOverviewLast TimeLast Time
Confusion Matrix Brill Demo NLTK Ch 6 - Text Classification
TodayToday Confusion Matrix Brill Demo NLTK Ch 6 - Text Classification
ReadingsReadings NLTK Ch 6
– 3 – CSCE 771 Spring 2013
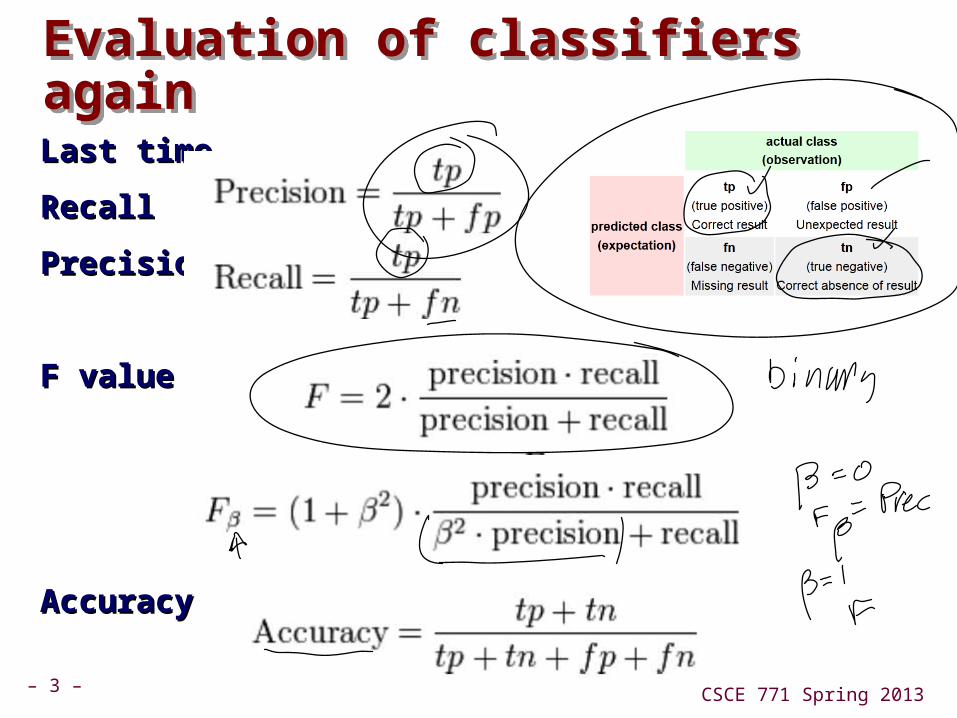
Evaluation of classifiers againEvaluation of classifiers again
Last timeLast time
RecallRecall
PrecisionPrecision
F valueF value
AccuracyAccuracy

– 4 – CSCE 771 Spring 2013
Reuters Data setReuters Data set
21578 documents21578 documents
118 categories118 categories
document can be in multiple classesdocument can be in multiple classes
118 binary classifiers118 binary classifiers

– 5 – CSCE 771 Spring 2013
Confusion matrixConfusion matrix
CCijij – documents that are really C – documents that are really Cii that are classified as C that are classified as Cjj..
CCiiii – documents that are really C – documents that are really Cii that correctly classified that correctly classified

– 6 – CSCE 771 Spring 2013
Micro averaging vs Macro AveragingMicro averaging vs Macro Averaging
Macro Averaging – average performance of individual Macro Averaging – average performance of individual classifiers (average of averages)classifiers (average of averages)
Micro averaging sum up all correct and all fp and fnMicro averaging sum up all correct and all fp and fn
– 7 – CSCE 771 Spring 2013
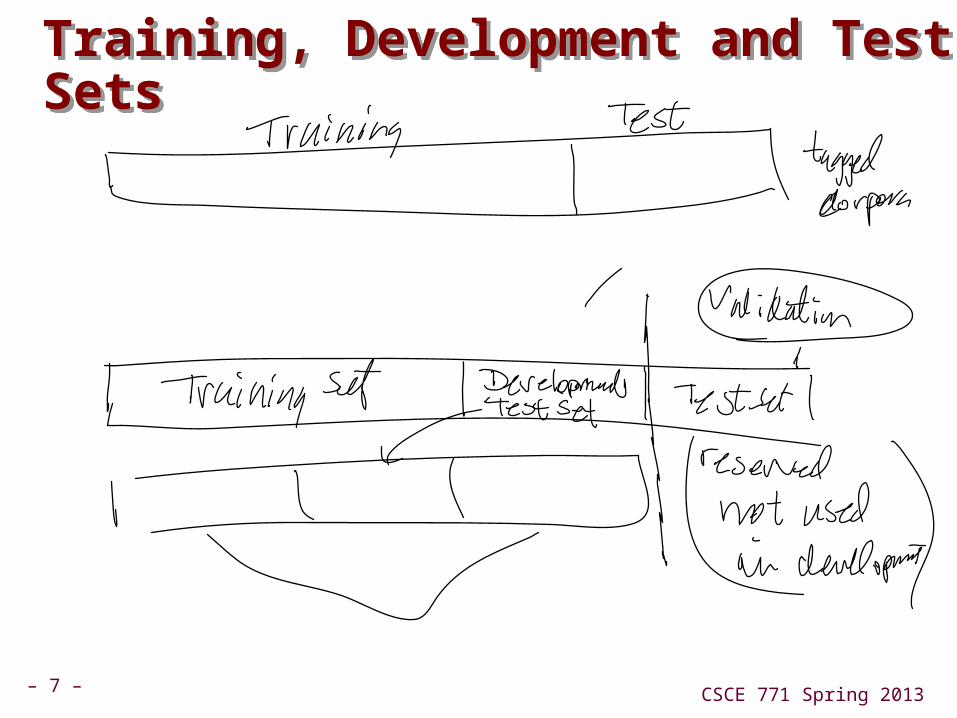
Training, Development and Test SetsTraining, Development and Test Sets

– 8 – CSCE 771 Spring 2013
Code_consecutive_pos_tagger.pyrevisited to trace history developmentCode_consecutive_pos_tagger.pyrevisited to trace history development
def pos_features(sentence, i, history): # [_consec-pos-tag-features]def pos_features(sentence, i, history): # [_consec-pos-tag-features] if debug == 1 : print "pos_features *********************************"if debug == 1 : print "pos_features *********************************" if debug == 1 : print " sentence=", sentenceif debug == 1 : print " sentence=", sentence if debug == 1 : print " i=", iif debug == 1 : print " i=", i if debug == 1 : print " history=", historyif debug == 1 : print " history=", history features = {"suffix(1)": sentence[i][-1:],features = {"suffix(1)": sentence[i][-1:], "suffix(2)": sentence[i][-2:],"suffix(2)": sentence[i][-2:], "suffix(3)": sentence[i][-3:]}"suffix(3)": sentence[i][-3:]} if i == 0:if i == 0: features["prev-word"] = "<START>"features["prev-word"] = "<START>" features["prev-tag"] = "<START>"features["prev-tag"] = "<START>" else:else: features["prev-word"] = sentence[i-1]features["prev-word"] = sentence[i-1] features["prev-tag"] = history[i-1]features["prev-tag"] = history[i-1] if debug == 1 : print "pos_features features=", featuresif debug == 1 : print "pos_features features=", features return featuresreturn features

– 9 – CSCE 771 Spring 2013
Trace of one sentence - SIGINT to interruptTrace of one sentence - SIGINT to interrupt
sentence= ['Rookie', 'southpaw', 'George', sentence= ['Rookie', 'southpaw', 'George', 'Stepanovich', 'relieved', 'Hyde', 'at', 'the', 'start', 'of', 'Stepanovich', 'relieved', 'Hyde', 'at', 'the', 'start', 'of', 'the', 'ninth', 'and', 'gave', 'up', 'the', "A's", 'fifth', 'the', 'ninth', 'and', 'gave', 'up', 'the', "A's", 'fifth', 'tally', 'on', 'a', 'walk', 'to', 'second', 'baseman', 'Dick', 'tally', 'on', 'a', 'walk', 'to', 'second', 'baseman', 'Dick', 'Howser', ',', 'a', 'wild', 'pitch', ',', 'and', 'Frank', 'Howser', ',', 'a', 'wild', 'pitch', ',', 'and', 'Frank', "Cipriani's", 'single', 'under', 'Shortstop', 'Jerry', "Cipriani's", 'single', 'under', 'Shortstop', 'Jerry', "Adair's", 'glove', 'into', 'center', '.'] i= 0"Adair's", 'glove', 'into', 'center', '.'] i= 0
history= [ ]history= [ ]pos_features features= {'suffix(3)': 'kie', pos_features features= {'suffix(3)': 'kie', 'prev-word': '<START>', 'prev-word': '<START>', 'suffix(2)': 'ie', 'suffix(2)': 'ie', 'prev-tag': '<START>', 'prev-tag': '<START>', 'suffix(1)': 'e'}'suffix(1)': 'e'}

– 10 – CSCE 771 Spring 2013
Trace continuedTrace continuedpos_features *************************************pos_features ************************************* sentence= ['Rookie', …'.']sentence= ['Rookie', …'.'] i= 1i= 1 history= ['NN']history= ['NN']pos_features features= {'suffix(3)': 'paw', 'prev-word': pos_features features= {'suffix(3)': 'paw', 'prev-word':
'Rookie', 'suffix(2)': 'aw', 'prev-tag': 'NN', 'suffix(1)': 'Rookie', 'suffix(2)': 'aw', 'prev-tag': 'NN', 'suffix(1)': 'w'}'w'}
pos_features *************************************pos_features ************************************* sentence= ['Rookie', 'southpaw', … '.']sentence= ['Rookie', 'southpaw', … '.'] i= 2i= 2 history= ['NN', 'NN']history= ['NN', 'NN']pos_features features= {'suffix(3)': 'rge', 'prev-word': pos_features features= {'suffix(3)': 'rge', 'prev-word':
'southpaw', 'suffix(2)': 'ge', 'prev-tag': 'NN', 'suffix(1)': 'southpaw', 'suffix(2)': 'ge', 'prev-tag': 'NN', 'suffix(1)': 'e'}'e'}

– 11 – CSCE 771 Spring 2013
nltk.tagnltk.tagClassesClasses
AffixTaggerBigramTaggerBrillTaggerBrillTaggerTrainerDefaultTaggerFastBrillTaggerTrainerHiddenMarkovModelTaggerHiddenMarkovModelTrainerNgramTaggerRegexpTaggerTaggerITrigramTaggerUnigramTagger
FunctionsFunctions
batch_pos_tagpos_taguntag

– 12 – CSCE 771 Spring 2013
Module nltk.tag.hmmModule nltk.tag.hmm
Source Code for Source Code for Module nltk.tag.hmm
import nltkimport nltk
nltk.tag.hmm.demo()nltk.tag.hmm.demo()
nltk.tag.hmm.demo_pos()nltk.tag.hmm.demo_pos()
nltk.tag.hmm.demo_pos_bw()nltk.tag.hmm.demo_pos_bw()

– 13 – CSCE 771 Spring 2013
HMM demoHMM demo
import nltkimport nltk
nltk.tag.hmm.demo()nltk.tag.hmm.demo()
nltk.tag.hmm.demo_pos()nltk.tag.hmm.demo_pos()
nltk.tag.hmm.demo_pos_bw()nltk.tag.hmm.demo_pos_bw()

– 14 – CSCE 771 Spring 2013
Common SuffixesCommon Suffixes
from nltk.corpus import brownfrom nltk.corpus import brown
suffix_fdist = nltk.FreqDist()suffix_fdist = nltk.FreqDist()
for word in brown.words():for word in brown.words():
word = word.lower()word = word.lower()
suffix_fdist.inc(word[-1:])suffix_fdist.inc(word[-1:])
suffix_fdist.inc(word[-2:])suffix_fdist.inc(word[-2:])
suffix_fdist.inc(word[-3:])suffix_fdist.inc(word[-3:])
common_suffixes = suffix_fdist.keys()[:100]common_suffixes = suffix_fdist.keys()[:100]
print common_suffixes print common_suffixes

– 15 – CSCE 771 Spring 2013
rtepair = nltk.corpus.rte.pairs(['rte3_dev.xml'])[33]rtepair = nltk.corpus.rte.pairs(['rte3_dev.xml'])[33]extractor = nltk.RTEFeatureExtractor(rtepair)extractor = nltk.RTEFeatureExtractor(rtepair)print extractor.text_wordsprint extractor.text_words
set(['Russia', 'Organisation', 'Shanghai', …set(['Russia', 'Organisation', 'Shanghai', …print extractor.hyp_wordsprint extractor.hyp_words
set(['member', 'SCO', 'China'])set(['member', 'SCO', 'China'])print extractor.overlap('word')print extractor.overlap('word')
set([ ])set([ ])print extractor.overlap('ne')print extractor.overlap('ne')
set(['SCO', 'China'])set(['SCO', 'China'])print extractor.hyp_extra('word')print extractor.hyp_extra('word')
set(['member'])set(['member'])

– 16 – CSCE 771 Spring 2013
tagged_sents = list(brown.tagged_sents(categories='news'))tagged_sents = list(brown.tagged_sents(categories='news'))random.shuffle(tagged_sents)random.shuffle(tagged_sents)size = int(len(tagged_sents) * 0.1)size = int(len(tagged_sents) * 0.1)train_set, test_set = tagged_sents[size:], tagged_sents[:size]train_set, test_set = tagged_sents[size:], tagged_sents[:size]file_ids = brown.fileids(categories='news')file_ids = brown.fileids(categories='news')size = int(len(file_ids) * 0.1)size = int(len(file_ids) * 0.1)train_set = brown.tagged_sents(file_ids[size:])train_set = brown.tagged_sents(file_ids[size:])test_set = brown.tagged_sents(file_ids[:size])test_set = brown.tagged_sents(file_ids[:size])
train_set = brown.tagged_sents(categories='news')train_set = brown.tagged_sents(categories='news')test_set = brown.tagged_sents(categories='fiction')test_set = brown.tagged_sents(categories='fiction')
classifier = nltk.NaiveBayesClassifier.train(train_set)classifier = nltk.NaiveBayesClassifier.train(train_set)
– 17 – CSCE 771 Spring 2013
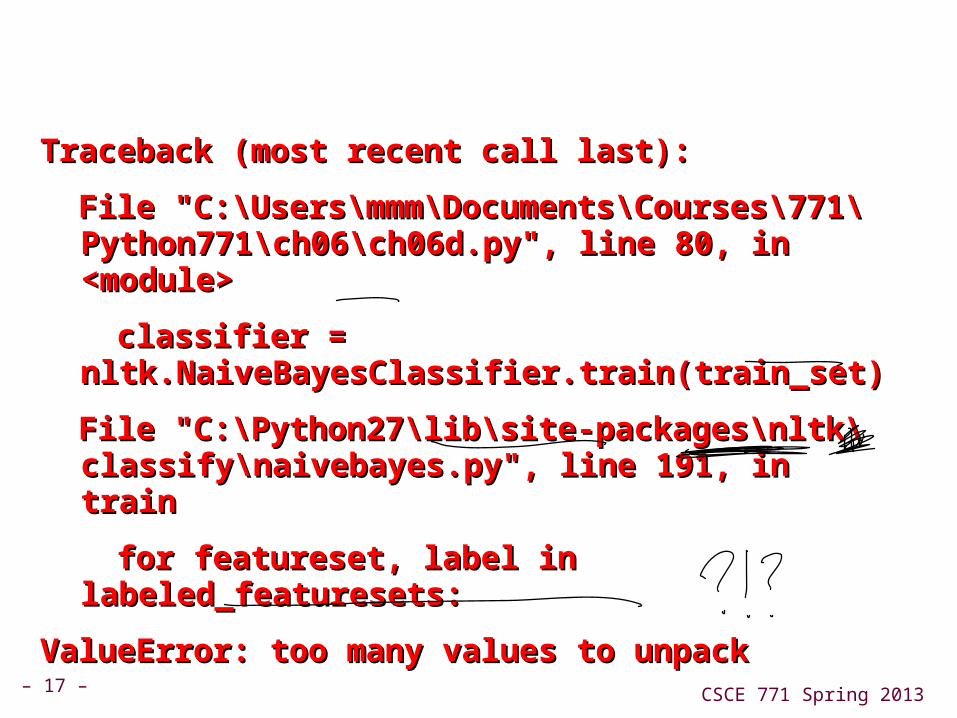
Traceback (most recent call last):Traceback (most recent call last):
File "C:\Users\mmm\Documents\Courses\771\File "C:\Users\mmm\Documents\Courses\771\Python771\ch06\ch06d.py", line 80, in <module>Python771\ch06\ch06d.py", line 80, in <module>
classifier = nltk.NaiveBayesClassifier.train(train_set)classifier = nltk.NaiveBayesClassifier.train(train_set)
File "C:\Python27\lib\site-packages\nltk\classify\File "C:\Python27\lib\site-packages\nltk\classify\naivebayes.py", line 191, in trainnaivebayes.py", line 191, in train
for featureset, label in labeled_featuresets:for featureset, label in labeled_featuresets:
ValueError: too many values to unpackValueError: too many values to unpack

– 18 – CSCE 771 Spring 2013
from nltk.corpus import brownfrom nltk.corpus import brown
brown_tagged_sents = brown_tagged_sents = brown.tagged_sents(categories='news')brown.tagged_sents(categories='news')
size = int(len(brown_tagged_sents) * 0.9)size = int(len(brown_tagged_sents) * 0.9)
train_sents = brown_tagged_sents[:size]train_sents = brown_tagged_sents[:size]
test_sents = brown_tagged_sents[size:]test_sents = brown_tagged_sents[size:]
t0 = nltk.DefaultTagger('NN')t0 = nltk.DefaultTagger('NN')
t1 = nltk.UnigramTagger(train_sents, backoff=t0)t1 = nltk.UnigramTagger(train_sents, backoff=t0)
t2 = nltk.BigramTagger(train_sents, backoff=t1)t2 = nltk.BigramTagger(train_sents, backoff=t1)

– 19 – CSCE 771 Spring 2013
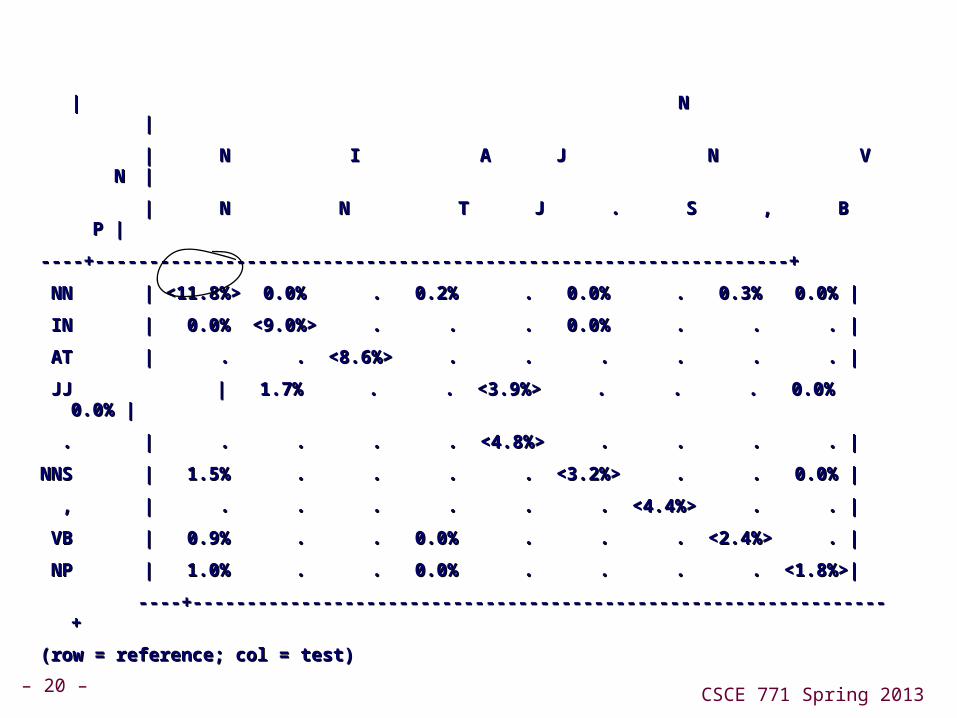
def tag_list(tagged_sents):def tag_list(tagged_sents):
return [tag for sent in tagged_sents for (word, tag) in return [tag for sent in tagged_sents for (word, tag) in sent]sent]
def apply_tagger(tagger, corpus):def apply_tagger(tagger, corpus):
return [tagger.tag(nltk.tag.untag(sent)) for sent in return [tagger.tag(nltk.tag.untag(sent)) for sent in corpus]corpus]
gold = gold = tag_list(brown.tagged_sents(categories='editorial'))tag_list(brown.tagged_sents(categories='editorial'))
test = tag_list(apply_tagger(t2, test = tag_list(apply_tagger(t2, brown.tagged_sents(categories='editorial')))brown.tagged_sents(categories='editorial')))
cm = nltk.ConfusionMatrix(gold, test)cm = nltk.ConfusionMatrix(gold, test)
print cm.pp(sort_by_count=True, show_percents=True, print cm.pp(sort_by_count=True, show_percents=True, truncate=9)truncate=9)
– 20 – CSCE 771 Spring 2013
| N | N ||
| N I A J N V N | N I A J N V N ||
| N N T J . S , B P || N N T J . S , B P |
----+----------------------------------------------------------------+----+----------------------------------------------------------------+
NN NN | <11.8%> 0.0% . 0.2% . 0.0% . 0.3% 0.0% || <11.8%> 0.0% . 0.2% . 0.0% . 0.3% 0.0% |
IN IN | 0.0% <9.0%> . . . 0.0% . . . || 0.0% <9.0%> . . . 0.0% . . . |
AT AT | . . <8.6%> . . . . . . || . . <8.6%> . . . . . . |
JJJJ | 1.7% . . <3.9%> . . . 0.0% 0.0% || 1.7% . . <3.9%> . . . 0.0% 0.0% |
. . | . . . . <4.8%> . . . . || . . . . <4.8%> . . . . |
NNS NNS | 1.5% . . . . <3.2%> . . 0.0% || 1.5% . . . . <3.2%> . . 0.0% |
, , | . . . . . . <4.4%> . . || . . . . . . <4.4%> . . |
VB VB | 0.9% . . 0.0% . . . <2.4%> . || 0.9% . . 0.0% . . . <2.4%> . |
NP NP | 1.0% . . 0.0% . . . . <1.8%>|| 1.0% . . 0.0% . . . . <1.8%>|
----+----------------------------------------------------------------+----+----------------------------------------------------------------+
(row = reference; col = test)(row = reference; col = test)

– 21 – CSCE 771 Spring 2013
EntropyEntropy
import mathimport math
def entropy(labels):def entropy(labels):
freqdist = nltk.FreqDist(labels)freqdist = nltk.FreqDist(labels)
probs = [freqdist.freq(l) for l in nltk.FreqDist(labels)]probs = [freqdist.freq(l) for l in nltk.FreqDist(labels)]
return -sum([p * math.log(p,2) for p in probs])return -sum([p * math.log(p,2) for p in probs])

– 22 – CSCE 771 Spring 2013
print entropy(['male', 'male', 'male', 'male'])print entropy(['male', 'male', 'male', 'male'])
-0.0-0.0
print entropy(['male', 'female', 'male', 'male'])print entropy(['male', 'female', 'male', 'male'])
0.8112781244590.811278124459
print entropy(['female', 'male', 'female', 'male'])print entropy(['female', 'male', 'female', 'male'])
1.01.0
print entropy(['female', 'female', 'male', 'female'])print entropy(['female', 'female', 'male', 'female'])
0.8112781244590.811278124459
print entropy(['female', 'female', 'female', 'female']) print entropy(['female', 'female', 'female', 'female'])
-0.0-0.0

– 23 – CSCE 771 Spring 2013
The Rest of NLTK Chapter 06The Rest of NLTK Chapter 06
6.5 Naïve Bayes Classifiers6.5 Naïve Bayes Classifiers
6.6 Maximum Entropy Classifiers6.6 Maximum Entropy Classifiers
• nltk.classify.maxent.BinaryMaxentFeatureEncoding(nltk.classify.maxent.BinaryMaxentFeatureEncoding(llabelsabels, , mappingmapping, , unseen_features=Falseunseen_features=False, , alwayson_features=Falsealwayson_features=False))
6.7 Modeling Linguistic Patterns6.7 Modeling Linguistic Patterns
6.8 Summary6.8 Summary
But no more Code?!?But no more Code?!?

– 24 – CSCE 771 Spring 2013
Maximum Entropy Models (again)Maximum Entropy Models (again)
features are elements of evidence that connect features are elements of evidence that connect observations d with categories cobservations d with categories c
f: C X D f: C X D R R
Example featureExample feature
f(c,d) = { c = LOCATION & wf(c,d) = { c = LOCATION & w-1-1 = IN & is Capitalized(w)} = IN & is Capitalized(w)}
An “input-feature” is a property of an unlabeled token.An “input-feature” is a property of an unlabeled token.
A “joint-feature” is a property of a labeled token.A “joint-feature” is a property of a labeled token.

– 25 – CSCE 771 Spring 2013
Feature-Based Liner ClassifiersFeature-Based Liner Classifiers
p(c |d, lambda)=p(c |d, lambda)=

– 26 – CSCE 771 Spring 2013
Maxent Model revisitedMaxent Model revisited
– 27 – CSCE 771 Spring 2013
Maximum Entropy Markov Models (MEMM)Maximum Entropy Markov Models (MEMM)repeatedly use Maxent classifier to iteratively apply to a repeatedly use Maxent classifier to iteratively apply to a
sequencesequence

– 28 – CSCE 771 Spring 2013

– 29 – CSCE 771 Spring 2013
Named Entity Recognition (NER)Named Entity Recognition (NER)
enities – enities –
1.1. aa : : being, , existence; ; especiallyespecially : independent, : independent, separate, or self-contained existence separate, or self-contained existence b : the existence of a thing as contrasted with its attributes
2.2. : something that has separate and distinct existence : something that has separate and distinct existence and objective or conceptual reality and objective or conceptual reality
3.3. : an organization (as a business or governmental : an organization (as a business or governmental unit) that has an identity separate from those of its unit) that has an identity separate from those of its members members
one of those with a nameone of those with a name
• http://nlp.stanford.edu/software/CRF-NER.shtmlhttp://nlp.stanford.edu/software/CRF-NER.shtml

– 30 – CSCE 771 Spring 2013
Classes of Named EntitiesClasses of Named Entities
Person (PERS)Person (PERS)
Location (LOC)Location (LOC)
Organization (ORG)Organization (ORG)
DATEDATE
Example: Example: Jim bought 300 shares of Acme Corp. in 2006.Jim bought 300 shares of Acme Corp. in 2006. And producing an annotated block of text, such as And producing an annotated block of text, such as this one:this one:
<ENAMEX TYPE="PERSON">Jim</ENAMEX> bought <ENAMEX TYPE="PERSON">Jim</ENAMEX> bought <NUMEX TYPE="QUANTITY">300</NUMEX>shares <NUMEX TYPE="QUANTITY">300</NUMEX>shares of<ENAMEX TYPE="ORGANIZATION">Acme of<ENAMEX TYPE="ORGANIZATION">Acme Corp.</ENAMEX> in <TIMEX Corp.</ENAMEX> in <TIMEX TYPE="DATE">2006</TIMEX>TYPE="DATE">2006</TIMEX>. .
http://nlp.stanford.edu/software/CRF-NER.shtml

– 31 – CSCE 771 Spring 2013
IOB taggingIOB tagging
B – beginning a chunk, B – beginning a chunk, e.g., B LOCe.g., B LOC
I – in a chunkI – in a chunk
O – outside chunkO – outside chunk
ExampleExample
text = '''text = '''
he PRP B-NPhe PRP B-NP
accepted VBD B-VPaccepted VBD B-VP
the DT B-NPthe DT B-NP
position NN I-NPposition NN I-NP
of IN B-PPof IN B-PP
vice NN B-NPvice NN B-NP
chairman NN I-NPchairman NN I-NP
, , O, , O
– 32 – CSCE 771 Spring 2013
..

– 33 – CSCE 771 Spring 2013
Chunking - partial parsingChunking - partial parsing

– 34 – CSCE 771 Spring 2013
NLTK ch07.pyNLTK ch07.py
def ie_preprocess(document):def ie_preprocess(document): sentences = nltk.sent_tokenize(document) sentences = nltk.sent_tokenize(document) sentences = [nltk.word_tokenize(sent) for sent in sentences] sentences = [nltk.word_tokenize(sent) for sent in sentences] sentences = [nltk.pos_tag(sent) for sent in sentences] sentences = [nltk.pos_tag(sent) for sent in sentences]
sentence = [("the", "DT"), ("little", "JJ"), ("yellow", "JJ"), # sentence = [("the", "DT"), ("little", "JJ"), ("yellow", "JJ"), # [_chunkex-sent] ("dog", "NN"), ("barked", "VBD"), ("at", "IN"), [_chunkex-sent] ("dog", "NN"), ("barked", "VBD"), ("at", "IN"), ("the", "DT"), ("cat", "NN")]("the", "DT"), ("cat", "NN")]
grammar = "NP: {<DT>?<JJ>*<NN>}" # [_chunkex-grammar]grammar = "NP: {<DT>?<JJ>*<NN>}" # [_chunkex-grammar]
cp = nltk.RegexpParser(grammar) cp = nltk.RegexpParser(grammar) result = cp.parse(sentence) result = cp.parse(sentence) print resultprint result

– 35 – CSCE 771 Spring 2013
(S(S
(NP the/DT little/JJ yellow/JJ dog/NN)(NP the/DT little/JJ yellow/JJ dog/NN)
barked/VBDbarked/VBD
at/INat/IN
(NP the/DT cat/NN))(NP the/DT cat/NN))
(S(S
(NP the/DT little/JJ yellow/JJ dog/NN)(NP the/DT little/JJ yellow/JJ dog/NN)
barked/VBDbarked/VBD
at/INat/IN
(NP the/DT cat/NN))(NP the/DT cat/NN))
(S (NP money/NN market/NN) fund/NN)(S (NP money/NN market/NN) fund/NN)

– 36 – CSCE 771 Spring 2013
chunkex-drawchunkex-draw
grammar = "NP: {<DT>?<JJ>*<NN>}" grammar = "NP: {<DT>?<JJ>*<NN>}" # [_chunkex-grammar]# [_chunkex-grammar]
cp = nltk.RegexpParser(grammar) # [_chunkex-cp]cp = nltk.RegexpParser(grammar) # [_chunkex-cp]
result = cp.parse(sentence) # [_chunkex-test]result = cp.parse(sentence) # [_chunkex-test]
print result # [_chunkex-print]print result # [_chunkex-print]
result.draw()result.draw()

– 37 – CSCE 771 Spring 2013
Chunk two consecutive nounsChunk two consecutive nouns
nouns = [("money", "NN"), ("market", "NN"), ("fund", nouns = [("money", "NN"), ("market", "NN"), ("fund", "NN")]"NN")]
grammar = "NP: {<NN><NN>} # Chunk two consecutive grammar = "NP: {<NN><NN>} # Chunk two consecutive nouns"nouns"
cp = nltk.RegexpParser(grammar)cp = nltk.RegexpParser(grammar)
print cp.parse(nouns)print cp.parse(nouns)
(S (NP money/NN market/NN) fund/NN)(S (NP money/NN market/NN) fund/NN)

– 38 – CSCE 771 Spring 2013
cp = nltk.RegexpParser('CHUNK: {<V.*> <TO> <V.*>}')cp = nltk.RegexpParser('CHUNK: {<V.*> <TO> <V.*>}')
brown = nltk.corpus.brownbrown = nltk.corpus.brown
for sent in brown.tagged_sents():for sent in brown.tagged_sents():
tree = cp.parse(sent)tree = cp.parse(sent)
for subtree in tree.subtrees():for subtree in tree.subtrees():
if subtree.node == 'CHUNK': print subtreeif subtree.node == 'CHUNK': print subtree
(CHUNK combined/VBN to/TO achieve/VB)(CHUNK combined/VBN to/TO achieve/VB)
……
(CHUNK serve/VB to/TO protect/VB)(CHUNK serve/VB to/TO protect/VB)
(CHUNK wanted/VBD to/TO wait/VB) (CHUNK wanted/VBD to/TO wait/VB)
……

– 39 – CSCE 771 Spring 2013
nltk.chunk.accuracy examplenltk.chunk.accuracy example
from nltk.corpus import conll2000from nltk.corpus import conll2000
test_sents = conll2000.chunked_sents('test.txt', test_sents = conll2000.chunked_sents('test.txt', chunk_types=['NP'])chunk_types=['NP'])
print nltk.chunk.accuracy(cp, test_sents)print nltk.chunk.accuracy(cp, test_sents)
0.417459948920.41745994892

– 40 – CSCE 771 Spring 2013
First attempt ?!?First attempt ?!?
from nltk.corpus import conll2000from nltk.corpus import conll2000
cp = nltk.RegexpParser("")cp = nltk.RegexpParser("")
test_sents = conll2000.chunked_sents('test.txt', test_sents = conll2000.chunked_sents('test.txt', chunk_types=['NP'])chunk_types=['NP'])
print cp.evaluate(test_sents)print cp.evaluate(test_sents)
ChunkParse score:ChunkParse score:
IOB Accuracy: IOB Accuracy: 43.4%43.4%
Precision: Precision: 0.0%0.0%
Recall: Recall: 0.0%0.0%
F-Measure: F-Measure: 0.0%0.0%

– 41 – CSCE 771 Spring 2013
from nltk.corpus import conll2000from nltk.corpus import conll2000
test_sents = conll2000.chunked_sents('test.txt', chunk_types=['NP'])test_sents = conll2000.chunked_sents('test.txt', chunk_types=['NP'])
from nltk.corpus import conll2000from nltk.corpus import conll2000
test_sents = conll2000.chunked_sents('test.txt', chunk_types=['NP'])test_sents = conll2000.chunked_sents('test.txt', chunk_types=['NP'])
print nltk.chunk.accuracy(cp, test_sents)print nltk.chunk.accuracy(cp, test_sents)
0.417459948920.41745994892
Carlyle NNP B-NPCarlyle NNP B-NP
Group NNP I-NPGroup NNP I-NP
, , O, , O
a DT B-NPa DT B-NP
merchant NN I-NPmerchant NN I-NP
banking NN I-NPbanking NN I-NP
concern NN I-NPconcern NN I-NP
. . O. . O
''''''
nltk.chunk.conllstr2tree(text, chunk_types=['NP']).draw()nltk.chunk.conllstr2tree(text, chunk_types=['NP']).draw()
from nltk.corpus import conll2000from nltk.corpus import conll2000
print conll2000.chunked_sents('train.txt')[99]Group NNP I-NPprint conll2000.chunked_sents('train.txt')[99]Group NNP I-NP
, , O, , O
a DT B-NPa DT B-NP
merchant NN I-NPmerchant NN I-NP
banking NN I-NPbanking NN I-NP
concern NN I-NPconcern NN I-NP
. . O. . O
''''''
nltk.chunk.conllstr2tree(text, chunk_types=['NP']).draw()nltk.chunk.conllstr2tree(text, chunk_types=['NP']).draw()
from nltk.corpus import conll2000from nltk.corpus import conll2000
print conll2000.chunked_sents('train.txt')[99]print conll2000.chunked_sents('train.txt')[99]

– 42 – CSCE 771 Spring 2013
Chunking using connll2000Chunking using connll2000
text = '''text = '''
he PRP B-NPhe PRP B-NP
accepted VBD B-VPaccepted VBD B-VP
the DT B-NPthe DT B-NP
position NN I-NPposition NN I-NP
of IN B-PPof IN B-PP
vice NN B-NPvice NN B-NP
chairman NN I-NPchairman NN I-NP
……
. . O. . O
''''''
nltk.chunk.conllstr2tree( text, nltk.chunk.conllstr2tree( text, chunk_types=['NP']).draw()chunk_types=['NP']).draw()
from nltk.corpus import conll2000from nltk.corpus import conll2000
print print conll2000.chunked_sents('train.txconll2000.chunked_sents('train.txt')[99]t')[99]

– 43 – CSCE 771 Spring 2013
. (S. (S
(PP Over/IN)(PP Over/IN)
(NP a/DT cup/NN)(NP a/DT cup/NN)
(PP of/IN)(PP of/IN)
(NP coffee/NN)(NP coffee/NN)
,/,,/,
(NP Mr./NNP Stone/NNP)(NP Mr./NNP Stone/NNP)
(VP told/VBD)(VP told/VBD)
(NP his/PRP$ story/NN)(NP his/PRP$ story/NN)
./.)./.)

– 44 – CSCE 771 Spring 2013
A Real AttemptA Real Attempt
grammar = r"NP: {<[CDJNP].*>+}"grammar = r"NP: {<[CDJNP].*>+}"
cp = nltk.RegexpParser(grammar)cp = nltk.RegexpParser(grammar)
print cp.evaluate(test_sents)print cp.evaluate(test_sents)
ChunkParse score:ChunkParse score:
IOB Accuracy: IOB Accuracy: 87.7%87.7%
Precision: Precision: 70.6%70.6%
Recall: Recall: 67.8%67.8%
F-Measure: F-Measure: 69.2%69.2%

– 45 – CSCE 771 Spring 2013
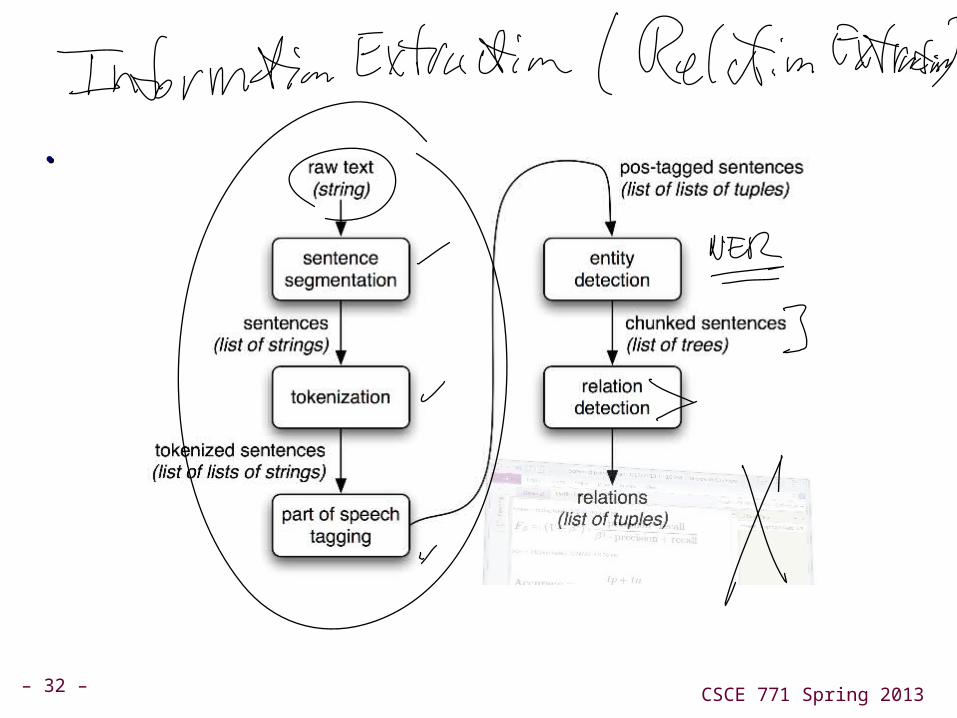
Information extractionInformation extraction
Step towards understandingStep towards understanding
Find named entitiesFind named entities
Figure out what is being said about them; actually just Figure out what is being said about them; actually just relations of named entitiesrelations of named entities
http://en.wikipedia.org/wiki/Information_extraction

– 46 – CSCE 771 Spring 2013
Outline of natural language processingOutline of natural language processing
1 What is NLP NLP ?
2 Prerequisite technologies
3 Subfields of NLPNLP
4 Related fields
5 Processes of NLP: : Applications, Components, Components
6 History of NLP
6.1 Timeline of NLP software
7 General NLP concepts
8 NLP software
•8.1 Chatterbots
•8.2 NLP toolkits
•8.3 Translation software
9 NLP organizations
10 NLP publications:: Books, , Journals
11 Persons 12 See also 13 References 14 External links
http://en.wikipedia.org/wiki/Outline_of_natural_language_processing

– 47 – CSCE 771 Spring 2013
Persons influential in NLPPersons influential in NLPAlan Turing – originator of the – originator of the Turing Test..
Noam Chomsky – author of the – author of the seminal work seminal work Syntactic Structures, which , which revolutionized Linguistics with 'revolutionized Linguistics with 'universal grammar', a rule based ', a rule based system of syntactic structures.system of syntactic structures.[15]
Daniel Bobrow – –
Joseph Weizenbaum – author of – author of the ELIZA chatterbot.the ELIZA chatterbot.
Roger Schank – introduced the Roger Schank – introduced the conceptual dependency theory conceptual dependency theory for natural language for natural language understanding.understanding.[16][16]
––
Terry Winograd –Terry Winograd –
Kenneth Colby –Kenneth Colby –
Rollo Carpenter –Rollo Carpenter –
David Ferrucci – principal David Ferrucci – principal investigator of the team that investigator of the team that created Watson, IBM's AI created Watson, IBM's AI computer that won the quiz computer that won the quiz show show Jeopardy!Jeopardy!
William Aaron WoodsWilliam Aaron Woods