Embed Size (px)
DESCRIPTION
Learning First-Order Probabilistic Models with Combining Rules. Sriraam Natarajan Prasad Tadepalli Eric Altendorf Thomas G. Dietterich Alan Fern Angelo Restificar School of EECS Oregon State University. First-order Probabilistic Models. - PowerPoint PPT Presentation
Citation preview

Learning First-Order Learning First-Order Probabilistic Models Probabilistic Models
with Combining Ruleswith Combining RulesSriraam NatarajanSriraam NatarajanPrasad TadepalliPrasad TadepalliEric AltendorfEric Altendorf
Thomas G. DietterichThomas G. DietterichAlan FernAlan Fern
Angelo RestificarAngelo Restificar
School of EECSSchool of EECSOregon State UniversityOregon State University

First-order Probabilistic First-order Probabilistic ModelsModels
Combine the expressiveness of first-order logic Combine the expressiveness of first-order logic with the uncertainty modeling of the graphical with the uncertainty modeling of the graphical modelsmodels
Several formalisms already exist: Several formalisms already exist: Probabilistic Relational Models (PRMs)Probabilistic Relational Models (PRMs) Bayesian Logic Programs (BLPs)Bayesian Logic Programs (BLPs) Stochastic Logic Programs (SLPs)Stochastic Logic Programs (SLPs) Relational Bayesian Networks (RBNs)Relational Bayesian Networks (RBNs) Probabilistic Logic Programs (PLPs), …Probabilistic Logic Programs (PLPs), …
Parameter sharing and quantification allow Parameter sharing and quantification allow compact representationcompact representation

Multiple Parents Multiple Parents ProblemProblem
Often multiple objects are related to an object Often multiple objects are related to an object by the same relationshipby the same relationship One’s friend’s drinking habits influence one’s ownOne’s friend’s drinking habits influence one’s own A student’s GPA depends on the grades in the A student’s GPA depends on the grades in the
courses he takes courses he takes The size of a mosquito population depends on the The size of a mosquito population depends on the
temperature and the rainfall each day since the last temperature and the rainfall each day since the last freezefreeze
The target variable in each of these statements The target variable in each of these statements
has multiple influents (“parents” in Bayes net has multiple influents (“parents” in Bayes net jargon)jargon)

Population
Rain1Temp1 Rain2Temp2 Rain3Temp3
Multiple Parents for Multiple Parents for populationpopulation
■ Variable number of parents■ Large number of parents■ Need for compact parameterization

Solution 1: AggregatorsSolution 1: Aggregators
Population
Rain1Temp1 Rain2Temp2 Rain3Temp3
AverageRainAverageTemp
Deterministic
Problem: Does not take into account the interaction between related parents Rain and Temp
Stochastic
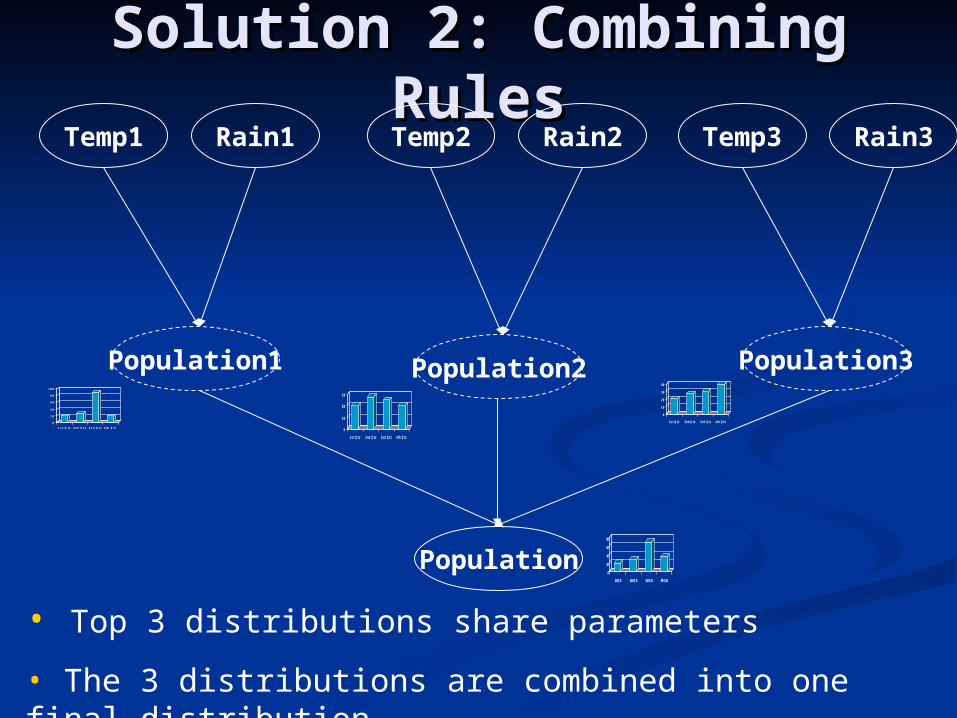
Solution 2: Combining Solution 2: Combining RulesRules
Population
Rain1Temp1 Rain2Temp2 Rain3Temp3
Population3Population1 Population20
10
20
30
40
1st Qtr 2nd Qtr 3r d Qtr 4th Qtr
0
10
20
30
1st Qtr 2nd Qtr 3r d Qtr 4th Qtr
0
20
40
60
80
1st Qtr 2nd Qtr 3rd Qtr 4th Qtr
0
20
40
60
80
100
1s t Qtr 2nd Qtr 3r d Qtr 4th Qtr
• Top 3 distributions share parameters
• The 3 distributions are combined into one final distribution

First-order Conditional First-order Conditional Influence Language Influence Language
(FOCIL)(FOCIL) Task and role of a document influence its Task and role of a document influence its
folderfolder if {task(t), doc(d), role(d,r,t)} then r.id, t.id Qinf d.folderif {task(t), doc(d), role(d,r,t)} then r.id, t.id Qinf d.folder..
The folder of the source of the document The folder of the source of the document influences the folder of the document influences the folder of the document
if {doc(d1), doc(d2), source(d1,d2)} then d1.folder Qinf if {doc(d1), doc(d2), source(d1,d2)} then d1.folder Qinf d2.folderd2.folder
The difficulty of the course and the The difficulty of the course and the intelligence of the student influence intelligence of the student influence his/her GPAhis/her GPA
if (student(s), course(c), takes(s,c))} then s.IQ, c.difficulty Qinf if (student(s), course(c), takes(s,c))} then s.IQ, c.difficulty Qinf
s.gpas.gpa))

Combining Multiple Combining Multiple Instances of a Single Instances of a Single
StatementStatement
If {task(t), doc(d), role(d,r,t)} then If {task(t), doc(d), role(d,r,t)} then t.id, r.id Qinf (Mean) t.id, r.id Qinf (Mean) d.folderd.folder
t1.id
d.folder
d.folder d.folder
Mean
r1.id t2.id r2.id
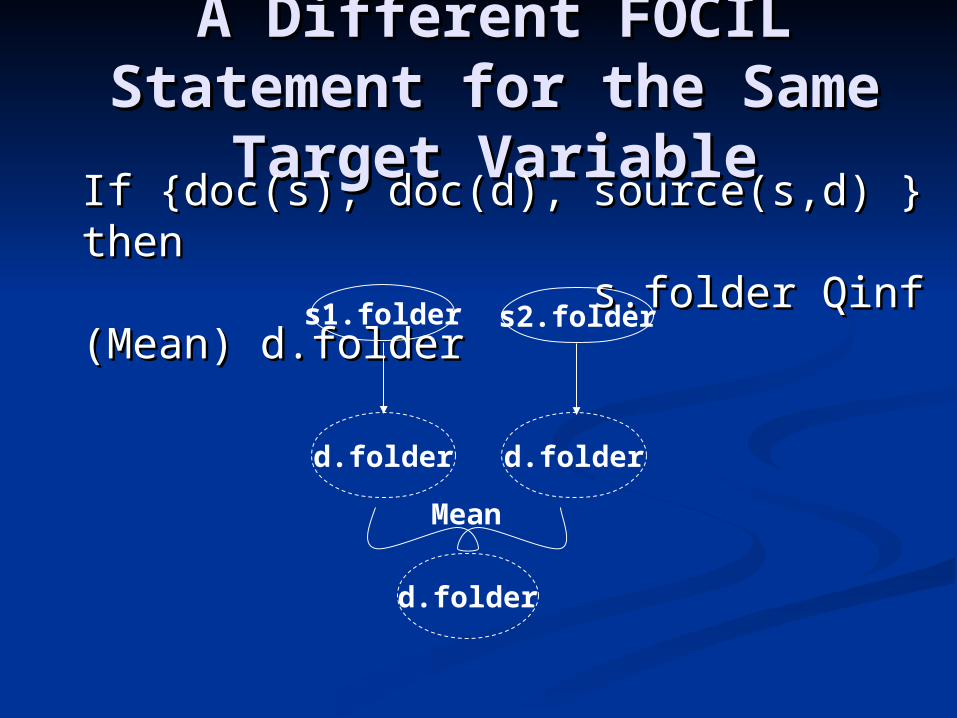
A Different FOCIL A Different FOCIL Statement for the Same Statement for the Same
Target VariableTarget Variable
If {doc(s), doc(d), source(s,d) } then If {doc(s), doc(d), source(s,d) } then s.folder Qinf (Mean) s.folder Qinf (Mean) d.folderd.folder
d.folder
s2.folder
d.folder d.folder
Mean
s1.folder

Combining Multiple Combining Multiple StatementsStatements
Weighted Mean{Weighted Mean{
If {task(t), doc(d), role(d,r,t)} then If {task(t), doc(d), role(d,r,t)} then
t.id, r.id Qinf (Mean) d.foldert.id, r.id Qinf (Mean) d.folder
If {doc(s), doc(d), source(s,d) } then If {doc(s), doc(d), source(s,d) } then
s.folder Qinf (Mean) d.folders.folder Qinf (Mean) d.folder
}}
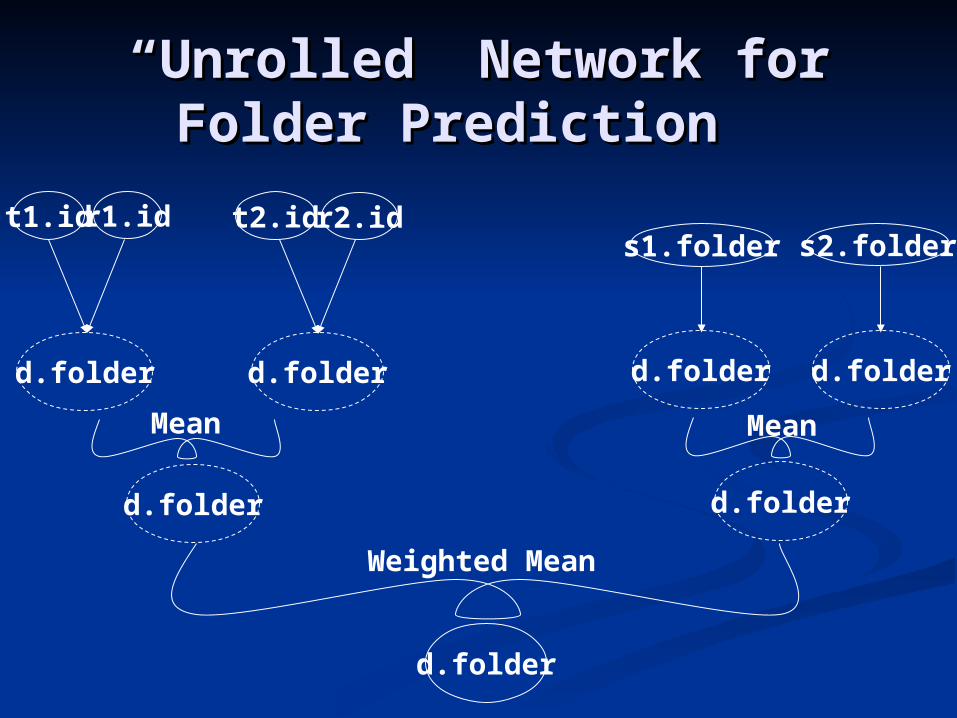
““Unrolled” Network for Unrolled” Network for Folder Prediction Folder Prediction
t1.id
d.folder d.folder
d.folder
Weighted Mean
d.folder d.folder
s2.folder
d.folder d.folder
Mean Mean
r1.id t2.id r2.ids1.folder
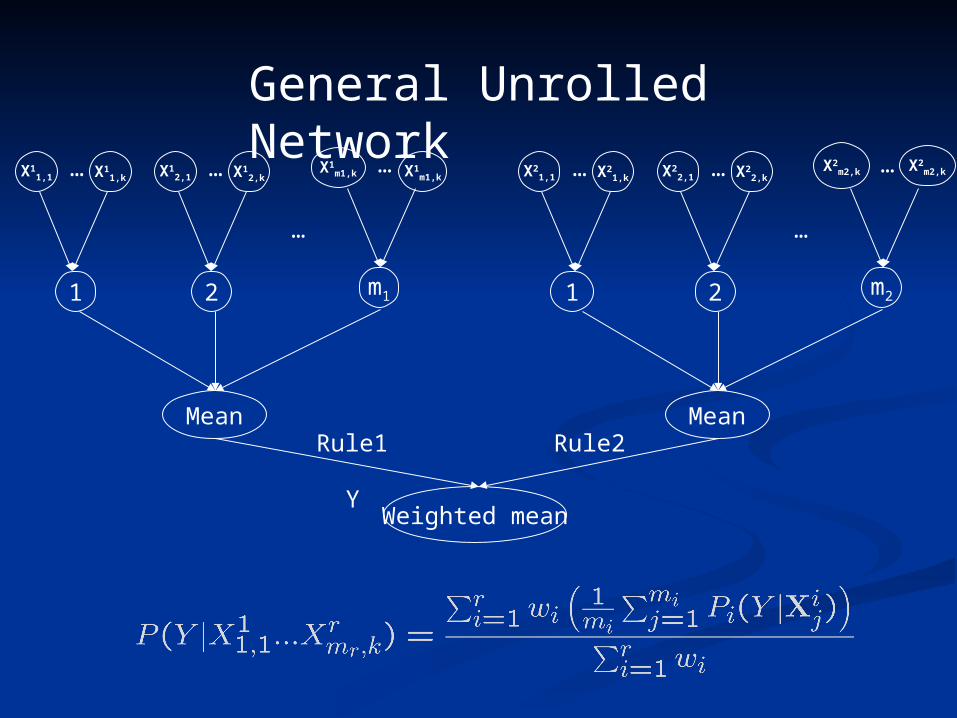
X11,1 X11,k…
1
X12,1 X12,k…
2
…
X1m1,k X1m1,k…
m1
Mean
X21,1 X21,k…
1
X22,1 X22,k…
2
…
X2m2,k X2m2,k…
m2
Mean
Weighted mean
Rule1 Rule2
Y
General Unrolled Network

Gradient Descent for Gradient Descent for Squared ErrorSquared Error
Squared errorSquared error
where

Gradient Descent for Gradient Descent for Loglikelihood Loglikelihood
LoglikelihoodLoglikelihood
, where

Learning the weightsLearning the weights
Mean Squared Mean Squared ErrorError
LoglikelihoodLoglikelihood
X11,1 X11,k…
1
…
X1m1,k X1m1,k…
m1
Mean
X21,1 X21,k…
1
…
X2m2,k X2m2,k…
m2
Mean
Weighted mean
w1w2
Y
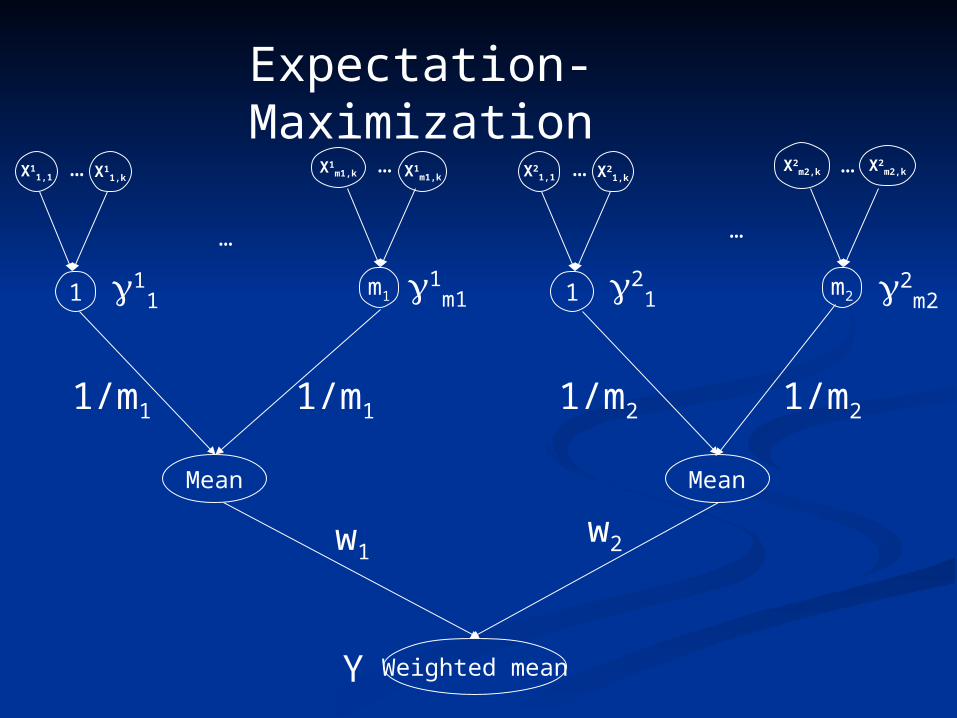
Expectation-Maximization
11 1
m1 21 2
m2
1/m1 1/m1 1/m2 1/m2

EM learningEM learning Expectation-step: Compute the Expectation-step: Compute the
responsibilities of each instance of each ruleresponsibilities of each instance of each rule
Maximization-step: Compute the maximum Maximization-step: Compute the maximum likelihood parameters using responsibilities likelihood parameters using responsibilities as the countsas the counts
where n is the # of examples with 2 or more rules instantiated

Experimental SetupExperimental Setup
500 documents, 6 tasks, 2 roles, 11 folders500 documents, 6 tasks, 2 roles, 11 folders Each document typically has 1-2 task-role Each document typically has 1-2 task-role
pairspairs 25% of documents have a source folder25% of documents have a source folder 10-fold cross validation10-fold cross validation
Weighted Mean{Weighted Mean{
If {task(t), doc(d), role(d,r,t)} then t.id, r.id If {task(t), doc(d), role(d,r,t)} then t.id, r.id Qinf (Mean) d.folder.Qinf (Mean) d.folder.
If {doc(s), doc(d), source(s,d) } then If {doc(s), doc(d), source(s,d) } then s.folder Qinf (Mean) d.folder. }s.folder Qinf (Mean) d.folder. }

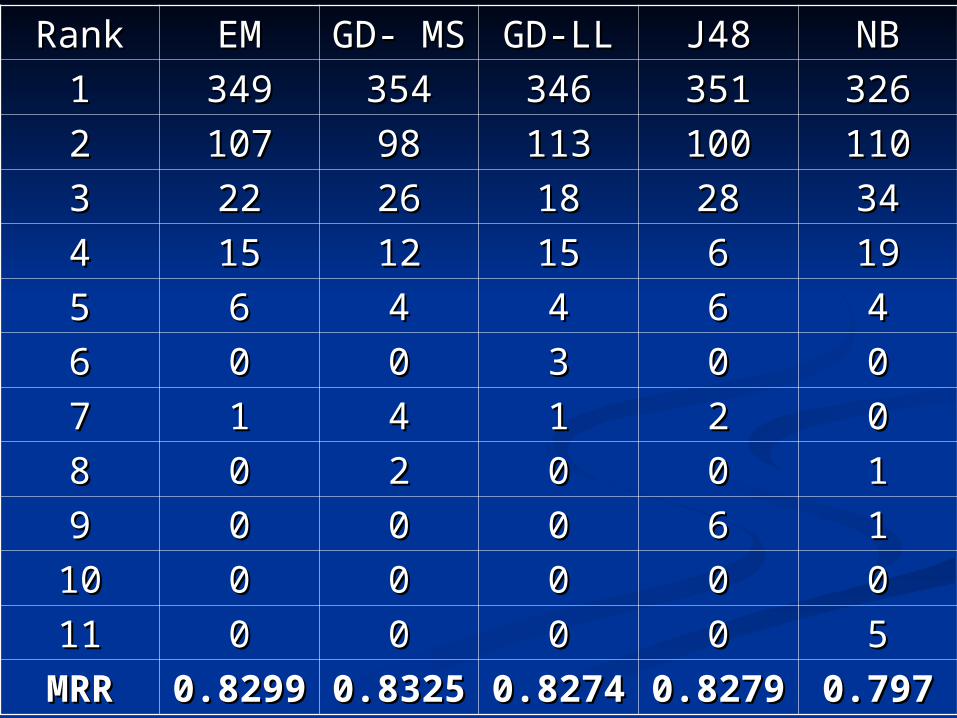
Folder prediction taskFolder prediction task
Mean reciprocal rank –Mean reciprocal rank –
where nwhere nii is the number of times the is the number of times the true folder was ranked as true folder was ranked as ii
Propositional classifiers:Propositional classifiers: Decision trees and Naïve BayesDecision trees and Naïve Bayes Features are the number of occurrences Features are the number of occurrences
of each task-role pair and source of each task-role pair and source document folderdocument folder
RankRank EMEM GD- GD- MSMS
GD-LLGD-LL J48J48 NBNB
11 349349 354354 346346 351351 326326
22 107107 9898 113113 100100 110110
33 2222 2626 1818 2828 3434
44 1515 1212 1515 66 1919
55 66 44 44 66 44
66 00 00 33 00 00
77 11 44 11 22 00
88 00 22 00 00 11
99 00 00 00 66 11
1010 00 00 00 00 00
1111 00 00 00 00 55
MRRMRR 0.8290.82999
0.8320.83255
0.8270.82744
0.8270.82799
0.7970.797

Lessons from Real-world Lessons from Real-world DataData
The propositional learners are almost as The propositional learners are almost as good as the first-order learners in this good as the first-order learners in this domain!domain! The number of parents is 1-2 in this domainThe number of parents is 1-2 in this domain About ¾ of the time only one rule is applicableAbout ¾ of the time only one rule is applicable Ranking of probabilities is easy in this caseRanking of probabilities is easy in this case
Accurate modeling of the probabilities is Accurate modeling of the probabilities is neededneeded Making predictions that combine with other Making predictions that combine with other
predictionspredictions Cost-sensitive decision makingCost-sensitive decision making

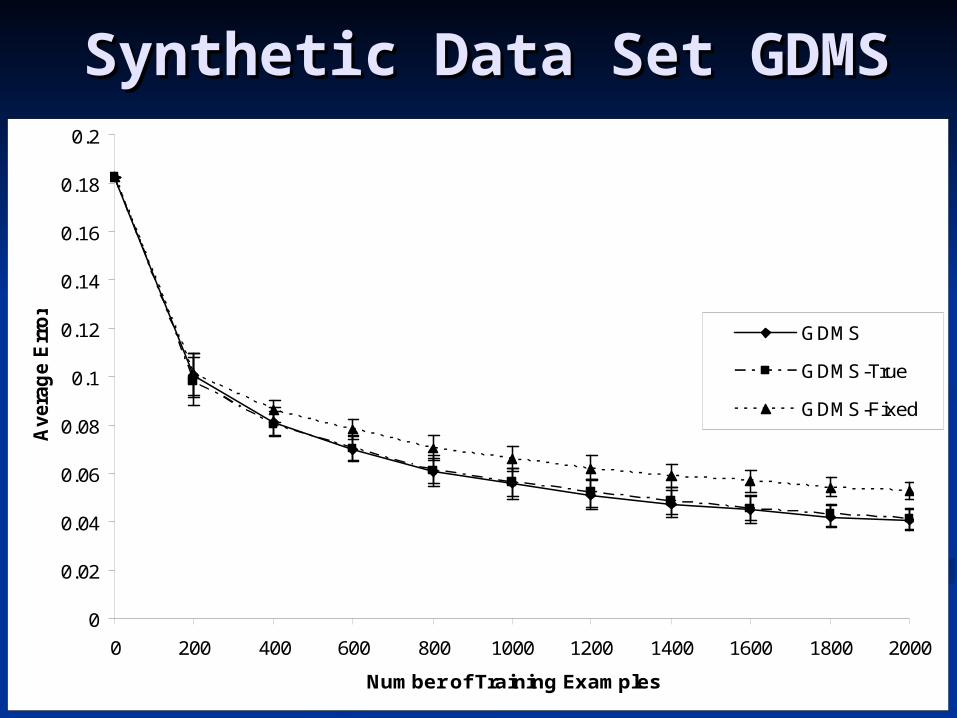
2 rules with 2 inputs each: W2 rules with 2 inputs each: Wrule1rule1= = 0.1,W0.1,Wrule2rule2= 0.9= 0.9
Probability that an example matches Probability that an example matches a rule = .5a rule = .5
If an example matches a rule, the If an example matches a rule, the number of instances is 3 - 10number of instances is 3 - 10
Performance metric: average Performance metric: average absolute error in predicted absolute error in predicted probabilityprobability
Synthetic Data SetSynthetic Data Set
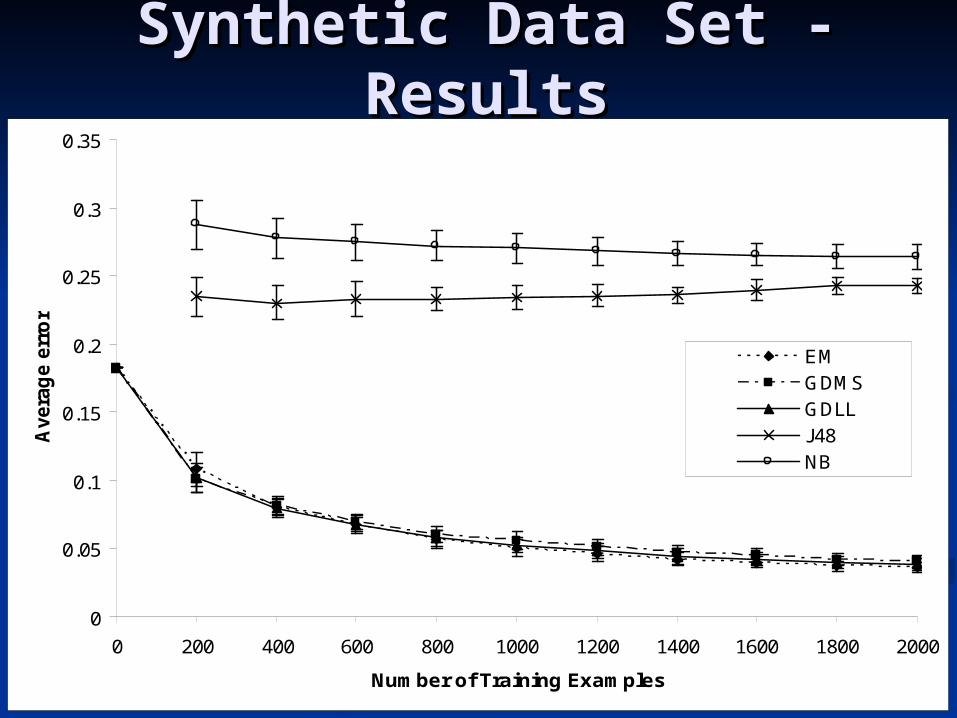
Synthetic Data Set - Synthetic Data Set - ResultsResults
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0 200 400 600 800 1000 1200 1400 1600 1800 2000
Number of Training Examples
Avera
ge e
rro
r
EMGDMSGDLLJ48NB
0
0.02
0.04
0.06
0.08
0.1
0.12
0.14
0.16
0.18
0.2
0 200 400 600 800 1000 1200 1400 1600 1800 2000
Number of Training Examples
Avera
ge E
rro
r
GDMS
GDMS-True
GDMS-Fixed
Synthetic Data Set GDMSSynthetic Data Set GDMS
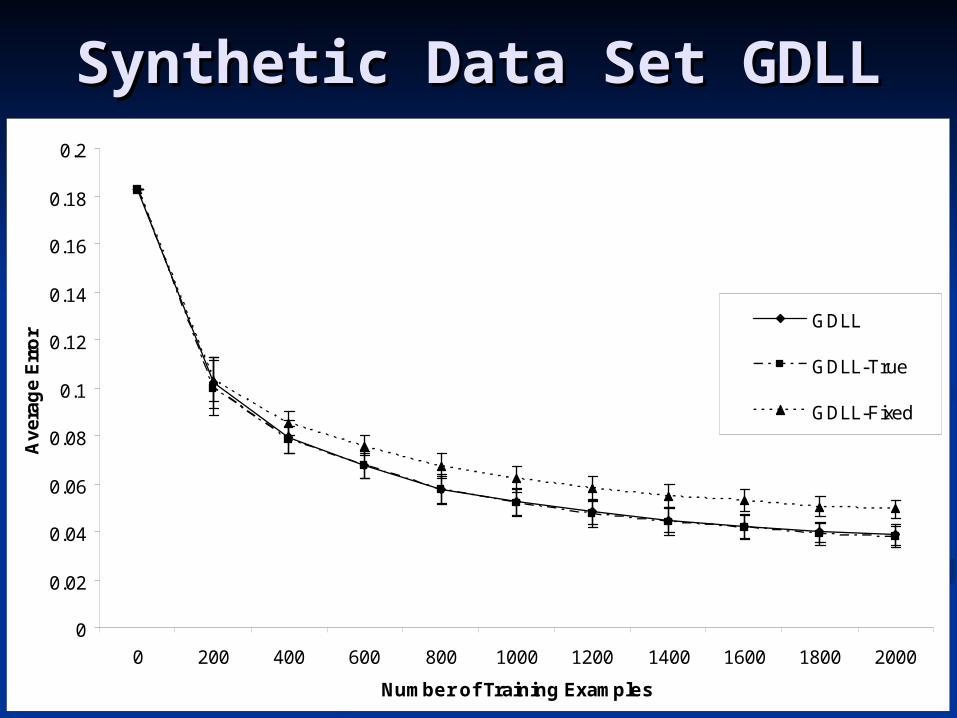
Synthetic Data Set GDLLSynthetic Data Set GDLL
0
0.02
0.04
0.06
0.08
0.1
0.12
0.14
0.16
0.18
0.2
0 200 400 600 800 1000 1200 1400 1600 1800 2000
Number of Training Examples
Av
era
ge
Err
or
GDLL
GDLL-True
GDLL-Fixed
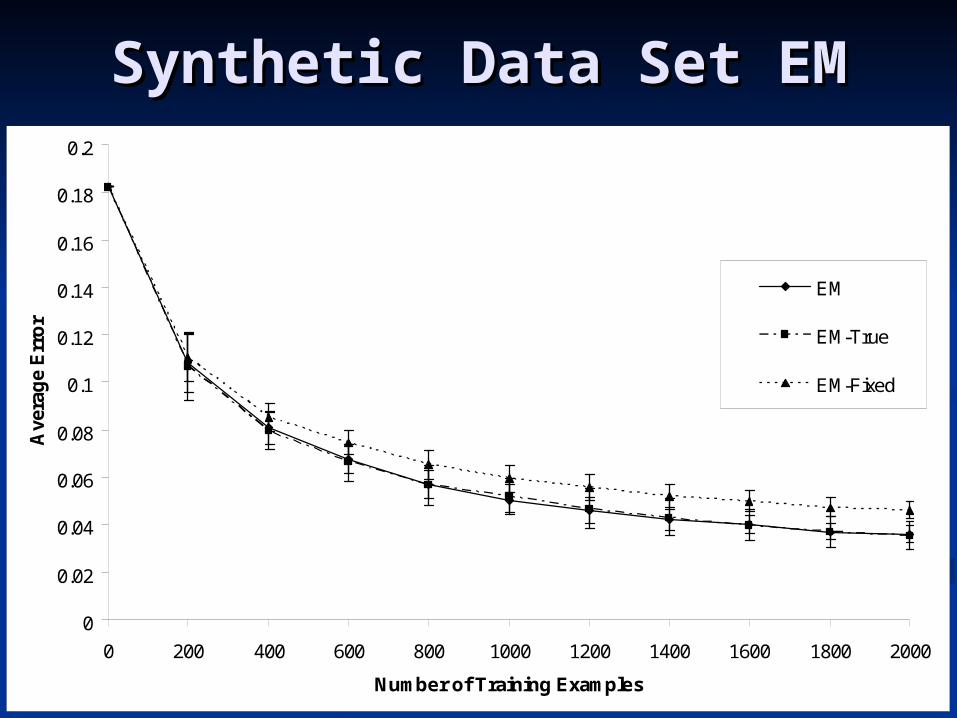
Synthetic Data Set EMSynthetic Data Set EM
0
0.02
0.04
0.06
0.08
0.1
0.12
0.14
0.16
0.18
0.2
0 200 400 600 800 1000 1200 1400 1600 1800 2000
Number of Training Examples
Ave
rag
e E
rro
r
EM
EM-True
EM-Fixed

ConclusionsConclusions
Introduced a general instance of multiple Introduced a general instance of multiple parents problem in first-order probabilistic parents problem in first-order probabilistic languageslanguages
Gradient descent and EM successfully Gradient descent and EM successfully learn the parameters of the conditional learn the parameters of the conditional distributions as well as the parameters of distributions as well as the parameters of the combining rules (weights)the combining rules (weights)
First order methods significantly First order methods significantly outperform propositional methods in outperform propositional methods in modeling the distributions when the modeling the distributions when the number of parents number of parents ¸̧ 3 3

Future WorkFuture Work
We plan to extend these results to We plan to extend these results to more general classes of combining more general classes of combining rulesrules
Develop efficient inference Develop efficient inference algorithms with combining rulesalgorithms with combining rules
Develop compelling applications Develop compelling applications Combining rules and aggregators Combining rules and aggregators
Can they both be understood as Can they both be understood as instances of causal independence?instances of causal independence?





























