Embed Size (px)
Citation preview

SHOC: Overview and Kernel
Walkthrough
Kyle Spafford
Keeneland Tutorial
April 14, 2011
2 Managed by UT-Battellefor the U.S. Department of Energy
The Scalable Heterogeneous Computing Benchmark Suite (SHOC)• Focus on scientific computing
workloads, including common kernels like SGEMM, FFT, Stencils
• Parallelized with MPI, with support for multi-GPU and cluster scale comparisons
• Implement in both CUDA and OpenCL for a 1:1 comparison
• Include system, stability tests
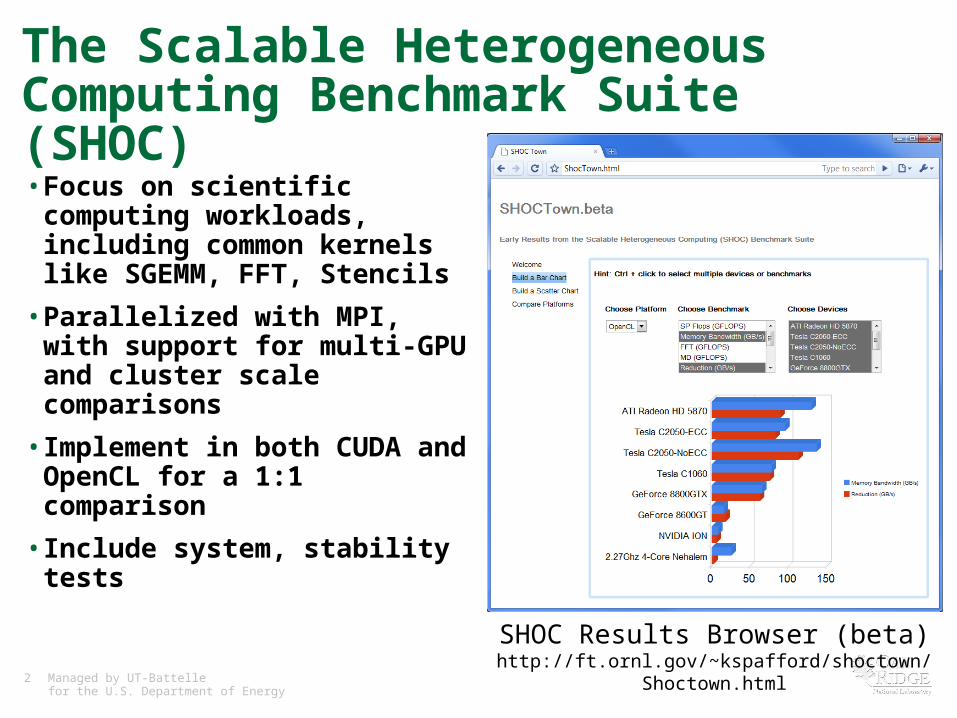
SHOC Results Browser (beta)http://ft.ornl.gov/~kspafford/shoctown/Shoctown.html

3 Managed by UT-Battellefor the U.S. Department of Energy
Download SHOC
• Source code– http://ft.ornl.gov/doku/shoc/downloads
• Build and Run– http://ft.ornl.gov/doku/shoc/gettingstarted
• sh ./conf/config-keeneland.sh
• make
• cd tools
• perl driver.pl –cuda –s 4
– Includes example output for Keeneland
• FAQ– http://ft.ornl.gov/doku/shoc/faq

4 Managed by UT-Battellefor the U.S. Department of Energy
SHOC Categories
• Performance:– Level 0
• Speeds and feeds: raw FLOPS rates, bandwidths, latencies
– Level 1• Algorithms: FFT, matrix multiply, stencil, sort, etc.
– Level 2:• Application kernels: S3D (chemistry), molecular dynamics
• System:– PCIe Contention, MPI latency vs. host-device bandwidth, NUMA
• Stability:– FFT-based, error detection

5 Managed by UT-Battellefor the U.S. Department of Energy
(Level 0 Example): DeviceMemory
• Motivation– Determine sustainable device memory bandwidth– Benchmark local, global, and image memory
• Basic design– Test different memory access patterns, i.e. coalesced,
uncoalesced– Measure both read and write bandwidth– Vary number of threads in a block
Coalesced
Thread sequential /Uncoalesced
Thread 1
Thread 2
Thread 3
Thread 4

6 Managed by UT-Battellefor the U.S. Department of Energy
SHOC: Level 0 Tests
• BusSpeedDownload/Readback– Measures bandwidth/latency of the PCIe bus
• DeviceMemory– Measures global/constant/shared memory
• KernelCompilation– Measures OpenCL JIT kernel compilation speeds
• MaxFlops– Measures achievable FLOPS (synthetic, not-bandwidth bound)
• QueueDelay– Measures OpenCL queueing system overhead

7 Managed by UT-Battellefor the U.S. Department of Energy
(Level 1 Example): Stencil2D
• Motivation– Supports investigation of accelerator
usage within parallel application context– Serial and True Parallel versions
• Basic design– 9-point stencil operation applied to 2D data set– MPI uses 2D Cartesian data distribution, with periodic halo exchanges– Applies stencil to data in local memory
• OpenCL/CUDA observations– Runtime dominated by data movement
• Between host and card
• Between MPI processes

8 Managed by UT-Battellefor the U.S. Department of Energy
SHOC: Level 1 Tests• FFT
• Reduction
• Scan
• SGEMM
• Sort
• SpMV
• Stencil2D
• Triad

9 Managed by UT-Battellefor the U.S. Department of Energy
(Level 2 Example): S3D• Motivation
– Measure performance of important DOE application
– S3D solves Navier-Stokes equations for a regular 3D domain, used to simulate combustion
• Basic design– Assign each grid point to a device
thread– Highly parallel, as grid points are
independent
• OpenCL/CUDA observations– CUDA outperforms OpenCL
• Big factor: native transcendentals (sin, cos, tan, etc.)
3D Regular Domain Decomposition – Each thread handles a grid point, blocks handle regions

10 Managed by UT-Battellefor the U.S. Department of Energy
SHOC: Other Tests
• Stability– FFTs are sensitive to small errors– Repeated simultaneous FFT/iFFT– Parallel for testing large systems
• System– MPI contention
• Impact of GPU usage on MPI latency
– Chipset contention• Impact of MPI communication on GPU performance
– NUMA• Multi-socket, multiple PCIe slot, multiple RAM banks
11 Managed by UT-Battellefor the U.S. Department of Energy
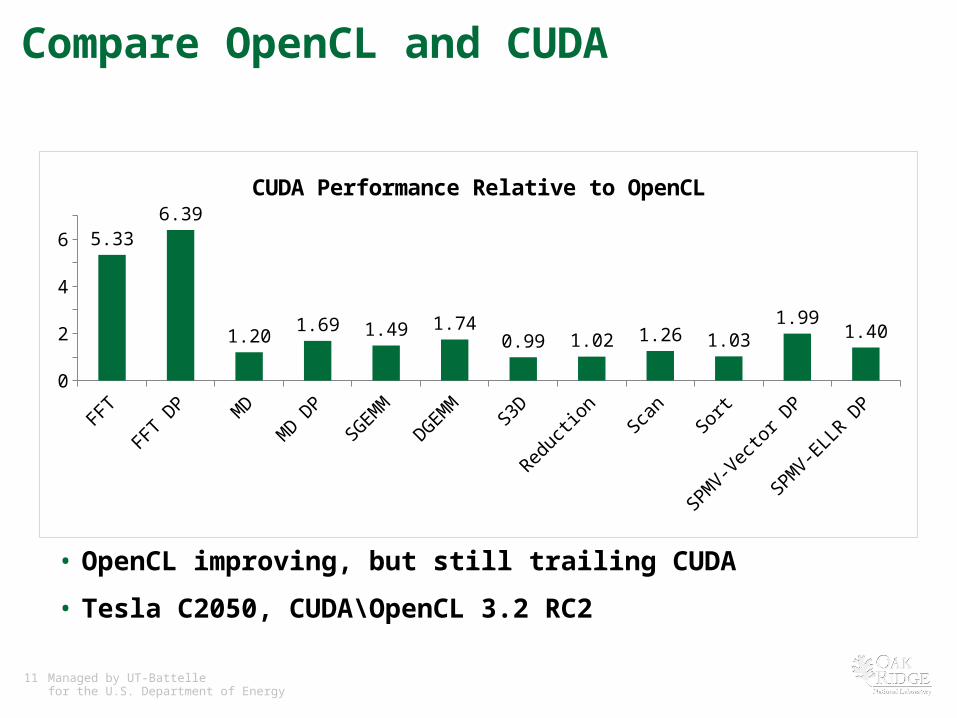
Compare OpenCL and CUDA
• OpenCL improving, but still trailing CUDA
• Tesla C2050, CUDA\OpenCL 3.2 RC2
FFT
FFT DPMD
MD DP
SGEMM
DGEMM S3D
Reduction
Scan
Sort
SPMV-Vecto
r DP
SPMV-ELLR DP
01234567
5.33
6.39
1.201.69 1.49 1.74
0.99 1.02 1.26 1.031.99
1.40
CUDA Performance Relative to OpenCL
12 Managed by UT-Battellefor the U.S. Department of Energy
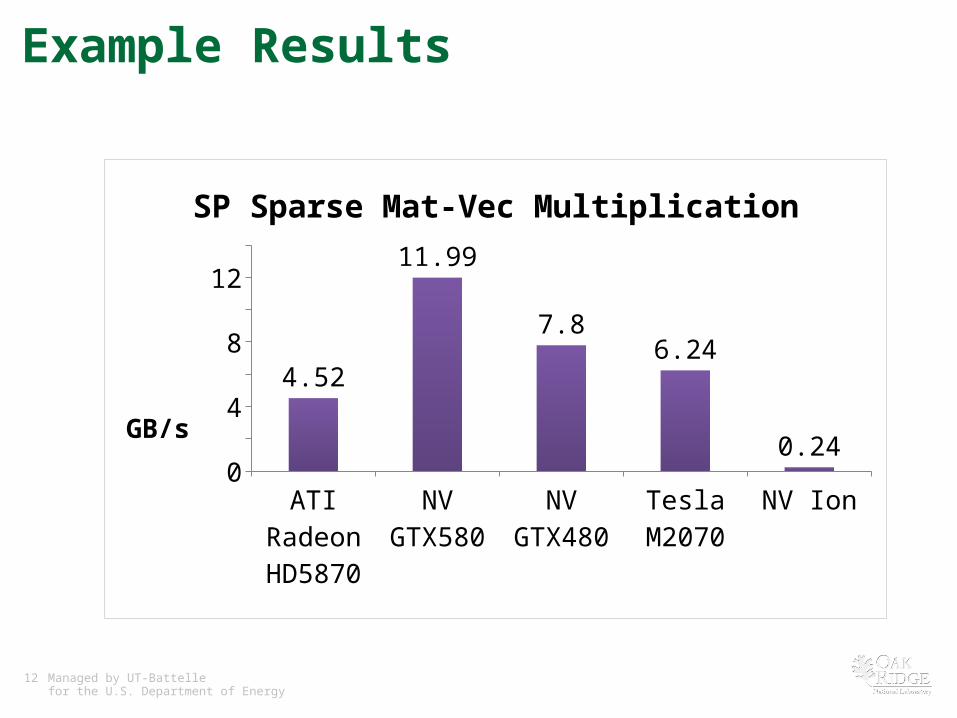
Example Results
ATI Radeon HD5870
NV GTX580
NV GTX480
Tesla M2070
NV Ion02468
101214
4.52
11.99
7.86.24
0.24
SP Sparse Mat-Vec Multiplication
GB/s

13 Managed by UT-Battellefor the U.S. Department of Energy
Reduction Walkthrough

14 Managed by UT-Battellefor the U.S. Department of Energy
Reduction Walkthrough
• Fundamental kernel in almost all programs
• Easy to implement, but hard to get right
• We’ll walk through the optimization process.
• Code for these kernels is at http://ft.ornl.gov/~kspafford/tutorial.tgz
• Graphics from a similar presentation by Mark Harris, NVIDIA
15 Managed by UT-Battellefor the U.S. Department of Energy
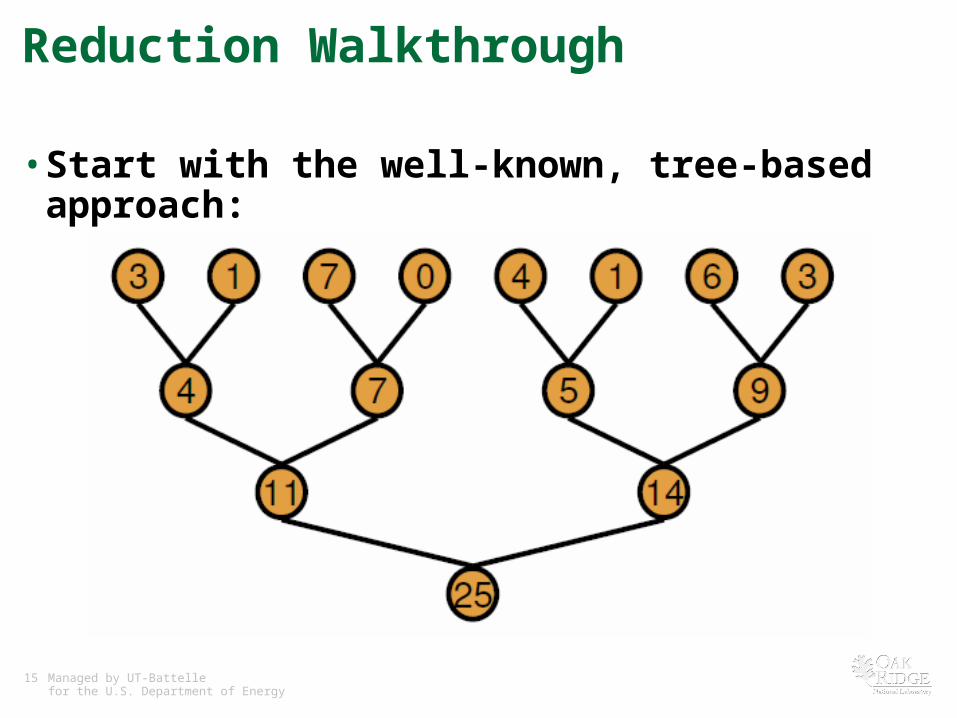
Reduction Walkthrough
• Start with the well-known, tree-based approach:

16 Managed by UT-Battellefor the U.S. Department of Energy
Algorithm Sketch
• Launch 1 thread per element
• Each thread loads an element from global memory into shared memory
• Each block reduces its shared memory into 1 value
• This value is written back out to global memory

17 Managed by UT-Battellefor the U.S. Department of Energy
Algorithm Sketch with Code
• Main steps– Each thread loads a value from global memory into shared
memory
extern __shared__ float sdata[];
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*blockDim.x + threadIdx.x;
sdata[tid] = g_idata[i];– Synchronize threads__syncthreads();
– Reduce shared memory into a single value– Write value out to global memory

18 Managed by UT-Battellefor the U.S. Department of Energy
Reduction of Shared Memory
for(int s = 1; s < blockDim.x;
s *= 2) {
if (tid % (2*s) == 0) {
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}
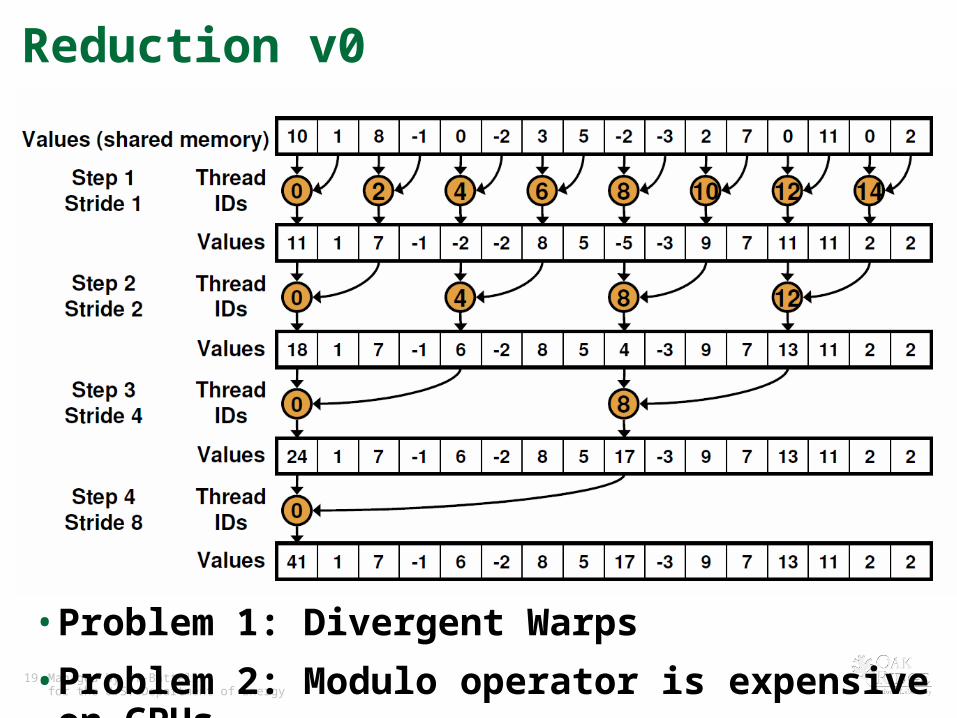
19 Managed by UT-Battellefor the U.S. Department of Energy
Reduction v0
• Problem 1: Divergent Warps
• Problem 2: Modulo operator is expensive on GPUs

20 Managed by UT-Battellefor the U.S. Department of Energy
Recursive Invocation
• Problem: We want a single value, but blocks can’t communicate
• Solution: Recursive kernel invocation
21 Managed by UT-Battellefor the U.S. Department of Energy
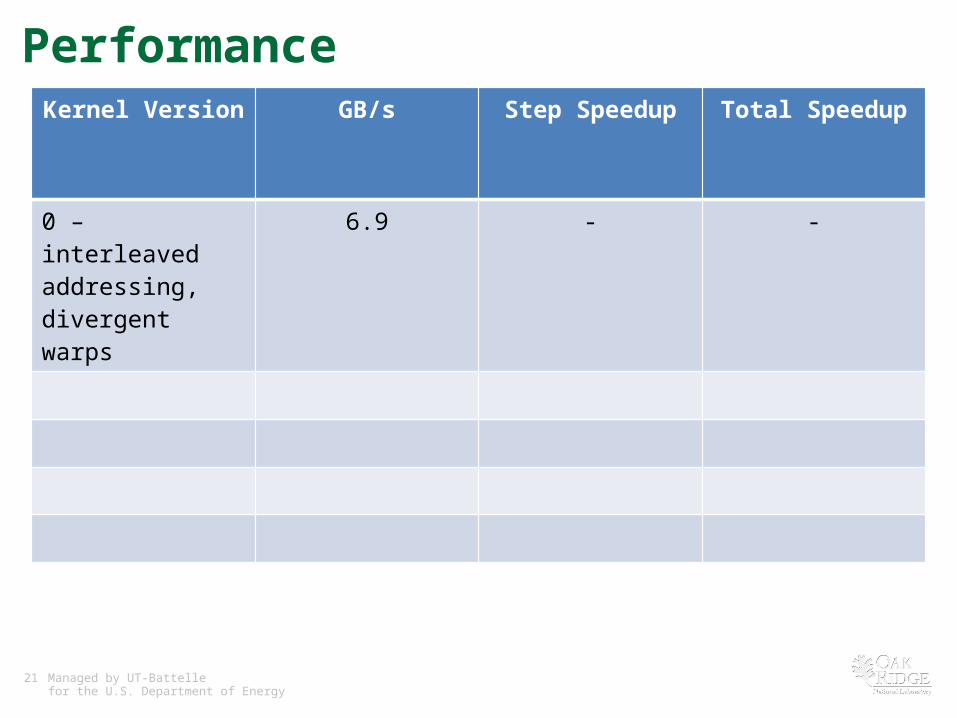
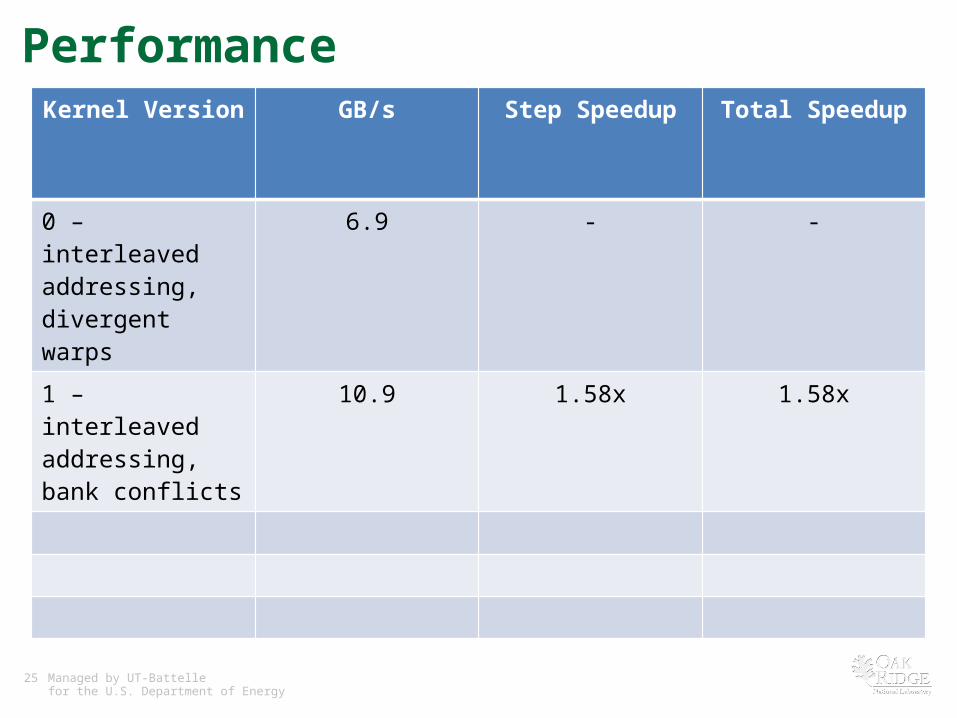
PerformanceKernel Version GB/s Step Speedup Total Speedup
0 – interleaved addressing, divergent warps
6.9 - -

22 Managed by UT-Battellefor the U.S. Department of Energy
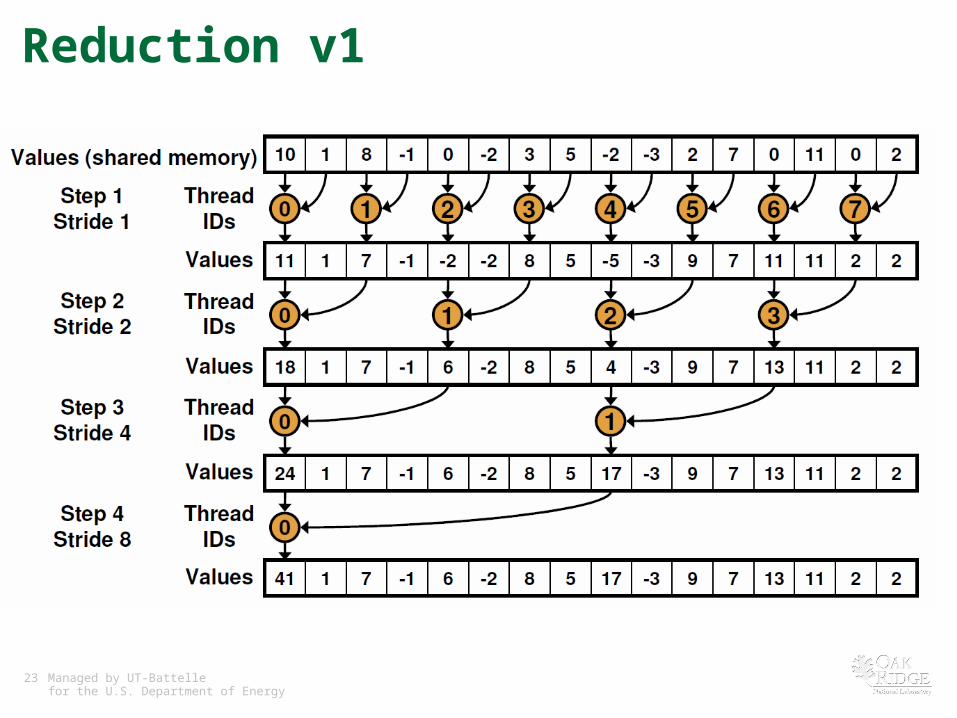
Reduction v1
• Get rid of divergent branch and modulo operator
23 Managed by UT-Battellefor the U.S. Department of Energy
Reduction v1
24 Managed by UT-Battellefor the U.S. Department of Energy
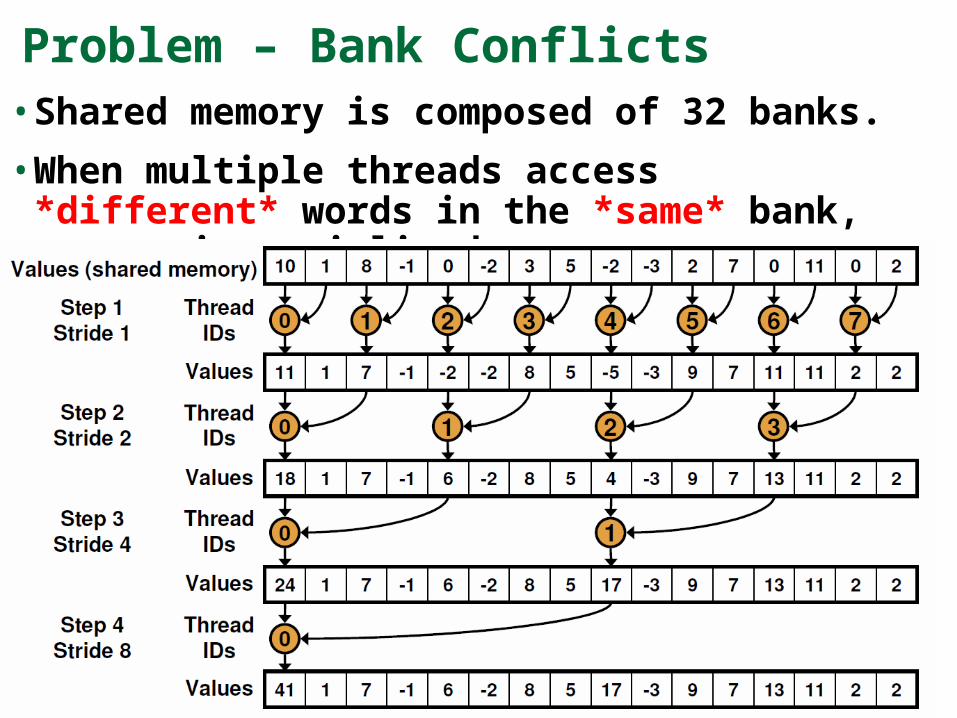
Problem – Bank Conflicts• Shared memory is composed of 32 banks.
• When multiple threads access *different* words in the *same* bank, access is serialized
25 Managed by UT-Battellefor the U.S. Department of Energy
PerformanceKernel Version GB/s Step Speedup Total Speedup
0 – interleaved addressing, divergent warps
6.9 - -
1 – interleaved addressing, bank conflicts
10.9 1.58x 1.58x

26 Managed by UT-Battellefor the U.S. Department of Energy
Reduction v2 – Sequential Addressing
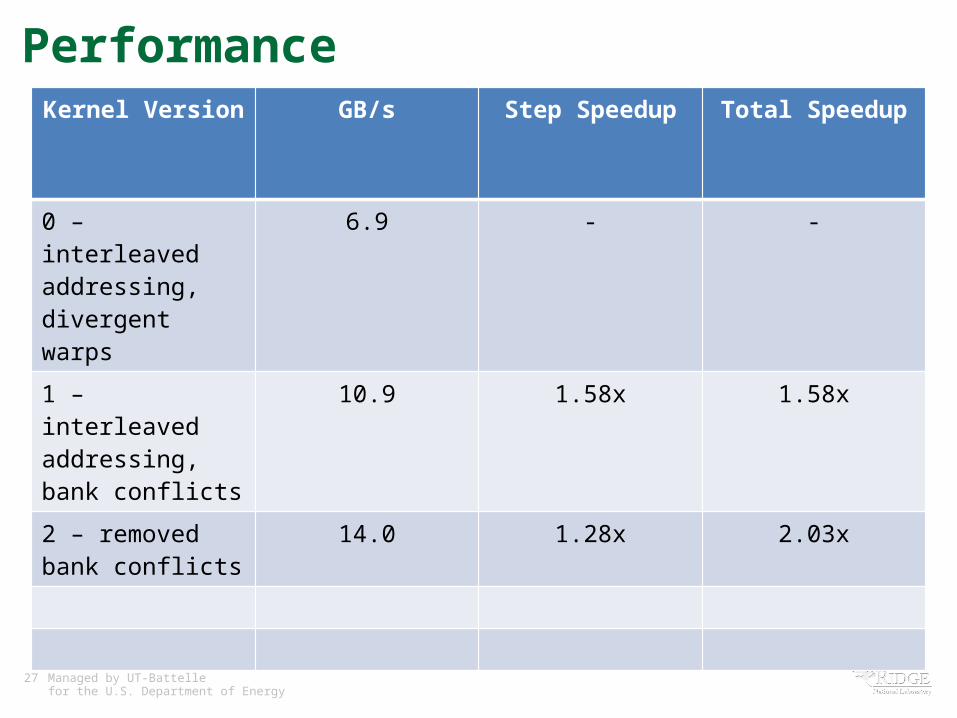
27 Managed by UT-Battellefor the U.S. Department of Energy
PerformanceKernel Version GB/s Step Speedup Total Speedup
0 – interleaved addressing, divergent warps
6.9 - -
1 – interleaved addressing, bank conflicts
10.9 1.58x 1.58x
2 – removed bank conflicts
14.0 1.28x 2.03x

28 Managed by UT-Battellefor the U.S. Department of Energy
Reduction v3 – Unrolling the Last Warp• We know threads execute in a warp-synchronous fashion
• For the last few steps, we can get rid of extra __syncthreads() calls
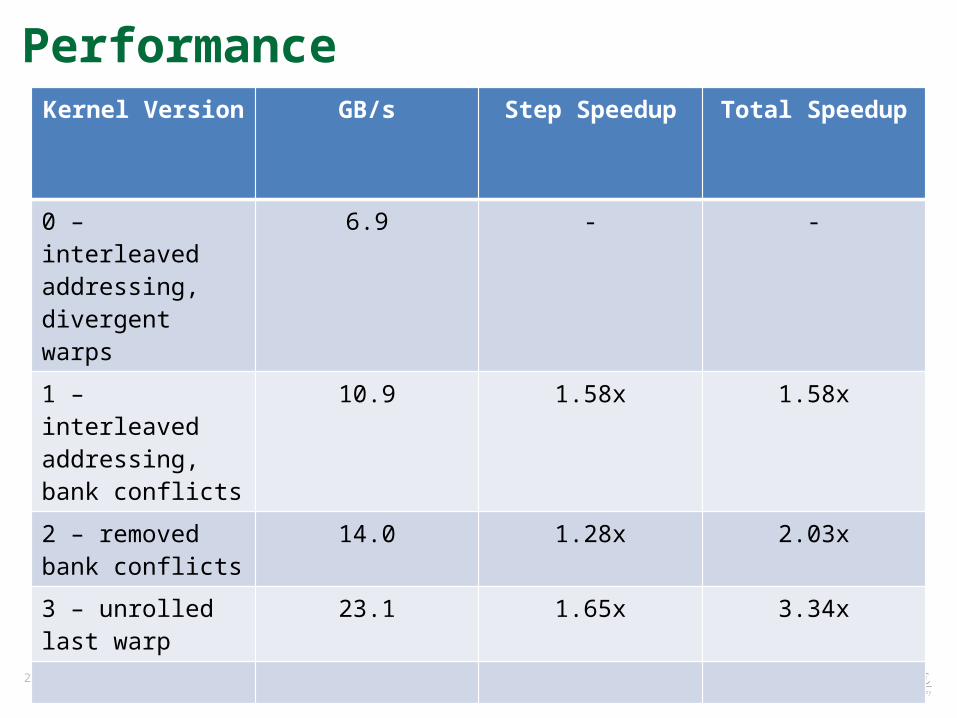
29 Managed by UT-Battellefor the U.S. Department of Energy
PerformanceKernel Version GB/s Step Speedup Total Speedup
0 – interleaved addressing, divergent warps
6.9 - -
1 – interleaved addressing, bank conflicts
10.9 1.58x 1.58x
2 – removed bank conflicts
14.0 1.28x 2.03x
3 – unrolled last warp
23.1 1.65x 3.34x

30 Managed by UT-Battellefor the U.S. Department of Energy
Reduction v4 – Multiple Elements Per Thread• Still have some instruction overhead
– Can use templates to totally unroll the loop– Can have threads handle multiple elements from global memory
• Bonus: reduces any array size to 2 kernel invocations
• This is a useful optimization for most kernels
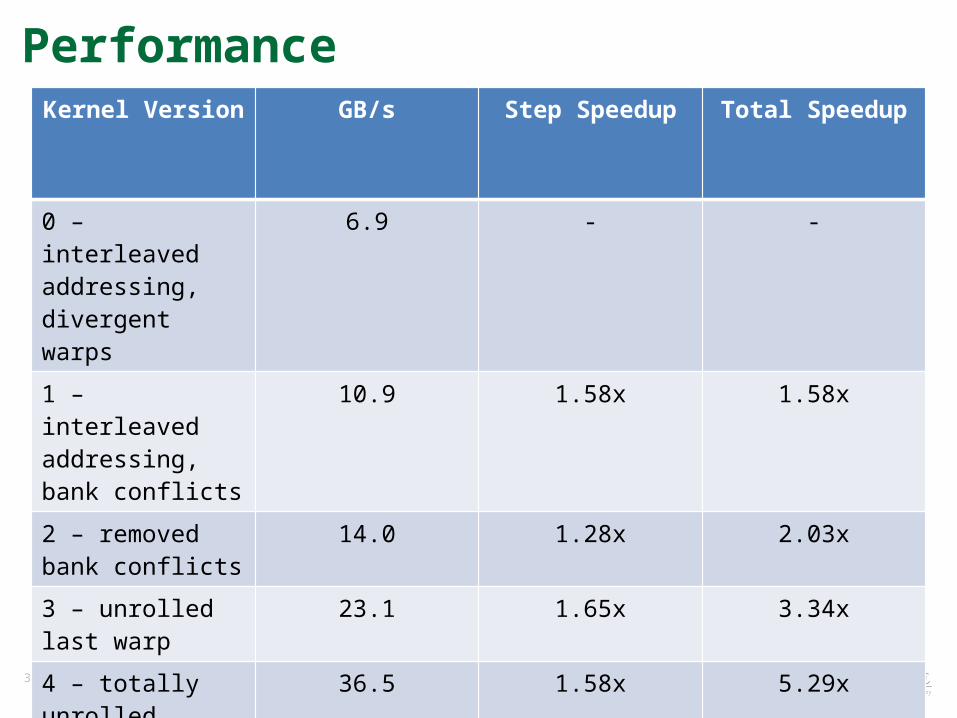
31 Managed by UT-Battellefor the U.S. Department of Energy
PerformanceKernel Version GB/s Step Speedup Total Speedup
0 – interleaved addressing, divergent warps
6.9 - -
1 – interleaved addressing, bank conflicts
10.9 1.58x 1.58x
2 – removed bank conflicts
14.0 1.28x 2.03x
3 – unrolled last warp
23.1 1.65x 3.34x
4 – totally unrolled, multiple elems per thread
36.5 1.58x 5.29x

32 Managed by UT-Battellefor the U.S. Department of Energy
More about Reduction
• http://developer.download.nvidia.com/assets/cuda/files/reduction.pdf
• Demo
wget http://ft.ornl.gov/~kspafford/tutorial.tgz

33 Managed by UT-Battellefor the U.S. Department of Energy
Programming Problem - Scan
• Now let’s think about how this extends to Scan (aka prefix sum)
Scan takes a binary associative operator , and an array of n ⊕elements:
[a0, a1, …, an-1],
and returns the array
[a0, (a0 a⊕ 1), …, (a0 a⊕ 1 … a⊕ ⊕ n-1)].
Example: If is addition⊕
[3 1 7 0 4] [3 4 11 11 15]
34 Managed by UT-Battellefor the U.S. Department of Energy
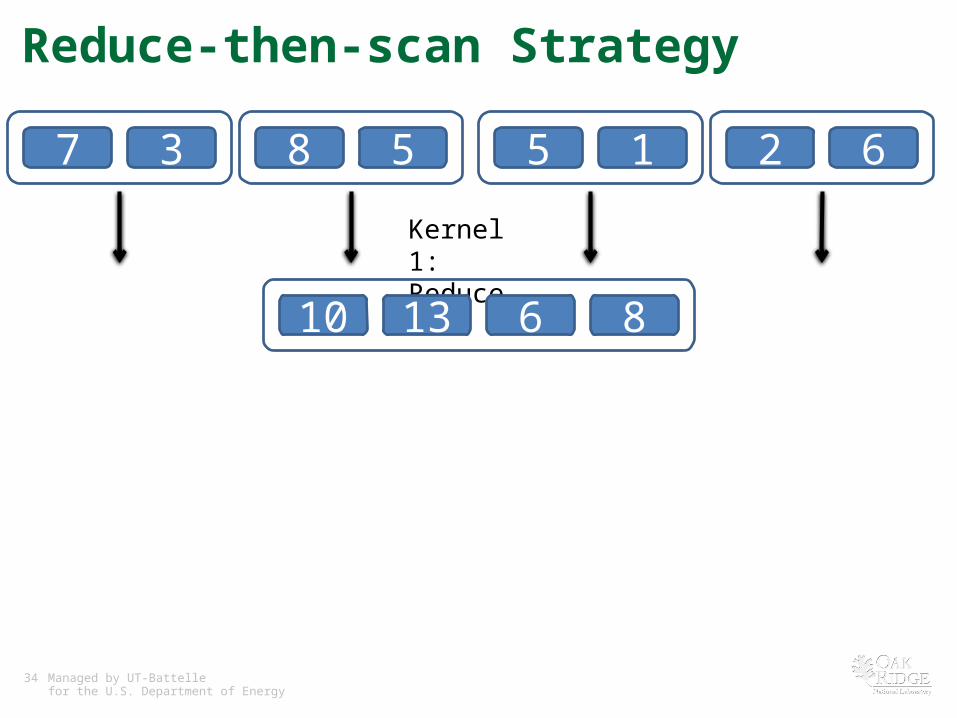
Reduce-then-scan Strategy
7 3 8 5 5 1 2 6
Kernel 1: Reduce
10 13 6 8

35 Managed by UT-Battellefor the U.S. Department of Energy
Reduce-then-scan Strategy
7 3 8 5 5 1 2 6
Kernel 1: Reduce
10 13 6 8
Kernel 2: Exclusive Top-level scan
0 10 23 29
36 Managed by UT-Battellefor the U.S. Department of Energy
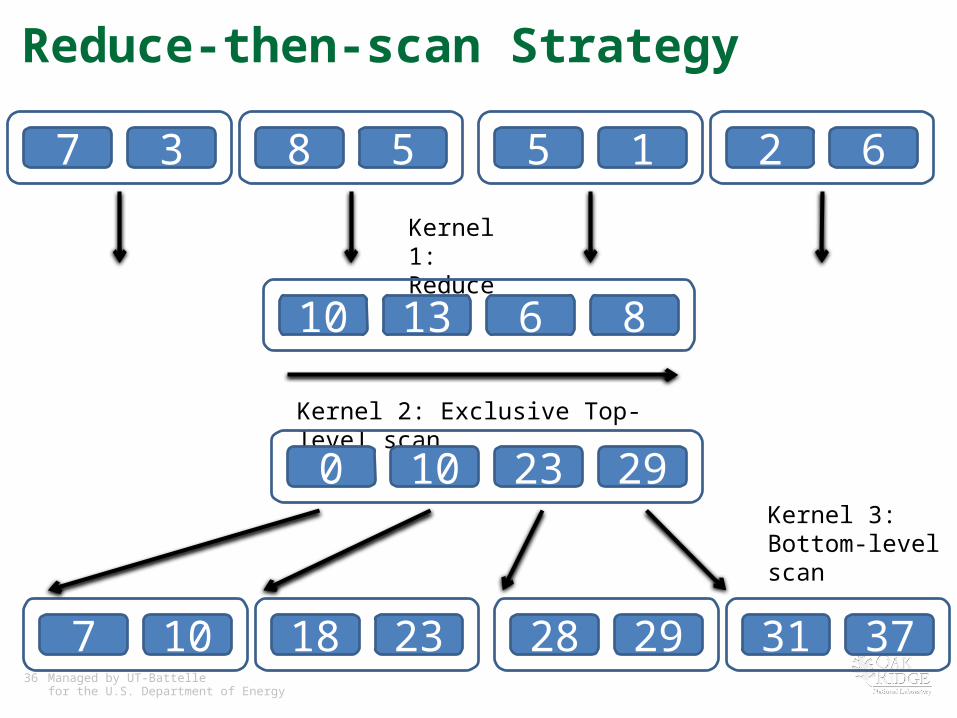
Reduce-then-scan Strategy
7 3 8 5 5 1 2 6
Kernel 1: Reduce
10 13 6 8
Kernel 2: Exclusive Top-level scan
0 10 23 29
7 10 18 23 28 29 31 37
Kernel 3: Bottom-level scan
37 Managed by UT-Battellefor the U.S. Department of Energy
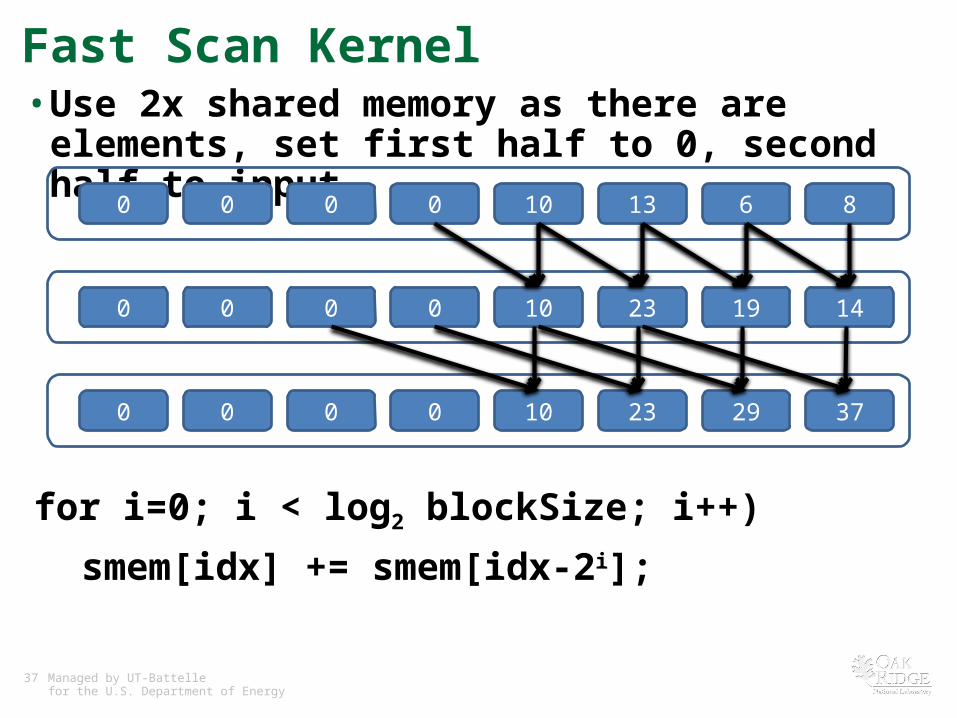
Fast Scan Kernel• Use 2x shared memory as there are elements, set first half
to 0, second half to input.
10 13 6 80 0 0 0
10 23 19 140 0 0 0
10 23 29 370 0 0 0
for i=0; i < log2 blockSize; i++)
smem[idx] += smem[idx-2i];

38 Managed by UT-Battellefor the U.S. Department of Energy
Example Code
• Kernel Found in SHOC (src/level1/scan/scan_kernel.h) in the scanLocalMem function
• You can adapt this function for the top-level exclusive scan and the bottom-level inclusive scans.
• Problems:– Determine how reduction should stride across global memory– Figure out how to make it exclusive/inclusive (hint: remember the
first half of smem is 0)– Figure out how to use the scan kernel for the bottom level scan

39 Managed by UT-Battellefor the U.S. Department of Energy
Good Luck! Further reading on Scan:• Examples in the CUDA SDK
• http://developer.download.nvidia.com/compute/cuda/1_1/Website/projects/scan/doc/scan.pdf
• http://back40computing.googlecode.com/svn/wiki/documents/ParallelScanForStreamArchitecturesTR.pdf

40 Managed by UT-Battellefor the U.S. Department of Energy
MD Walkthrough
• Motivation– Classic n-body pairwise
computation, important to all MD codes such as GPU-LAMMPS, AMBER, NAMD, Gromacs, Charmm
• Basic design– Computation of the Lennard
Jones potential force– 3D domain, random
distribution– Neighbor list algorithm

41 Managed by UT-Battellefor the U.S. Department of Energy
Algorithm Sketch
for each atom, i {
force = 0;
for each neighbor, j {
dist = distance(pos[i],pos[j]);
if (dist < cutoff)
force += interaction(i,j);
}
forces[i] = force;
}

42 Managed by UT-Battellefor the U.S. Department of Energy
Performance Observations
• Neighbors are data-dependent– Results in an uncoalesced read on pos[j].
• Uncoalesced reads kill performance– But sometimes the texture cache can help

43 Managed by UT-Battellefor the U.S. Department of Energy
(in cuda/level1/md/MD.cu)
44 Managed by UT-Battellefor the U.S. Department of Energy
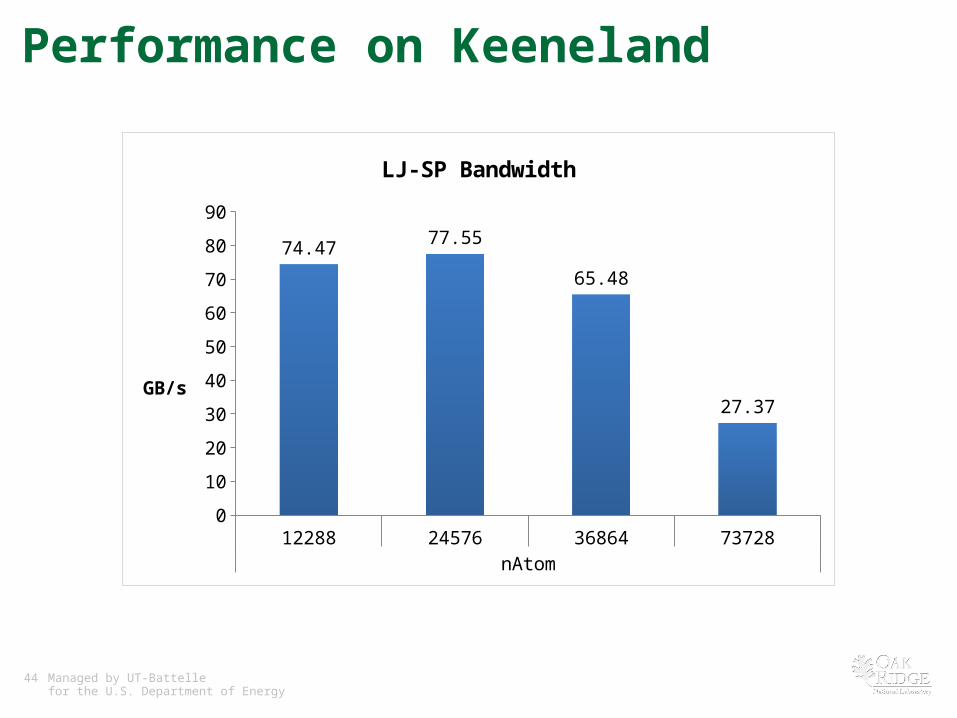
Performance on Keeneland
12288 24576 36864 73728nAtom
0
10
20
30
40
50
60
70
80
90
74.47 77.55
65.48
27.37
LJ-SP Bandwidth
GB/s

45 Managed by UT-Battellefor the U.S. Department of Energy
For the Hands-On Session
• Scan Competition
• Goal: Best performance on 16 MiB input of floats.– Use this slide deck and knowledge from the other presentations– Test harness with timing and correctness check provided in
scan.cu– Download it from ft.ornl.gov/~kspafford/tutorial.tgz
• Email submissions (scan.cu) to [email protected]
• I will announce the winner at the end of the hands-on session.






























