Embed Size (px)
Citation preview

Quantifying NUMA and Contention
Effects in Multi-GPU Systems
Kyle Spafford
Jeremy S. Meredith
Jeffrey S. Vetter
http://ft.ornl.gov
2 Managed by UT-Battellefor the U.S. Department of Energy
S3D DCA++
Early Work

3 Managed by UT-Battellefor the U.S. Department of Energy
“An experimental high performance
computing system of innovative design.”
“Outside the mainstream of what is routinely
available from computer vendors.”
- National Science Foundation, Track2D Call Fall 2008

4 Managed by UT-Battellefor the U.S. Department of Energy
Keeneland ID @ GT\ORNL

5 Managed by UT-Battellefor the U.S. Department of Energy
Inside a Node
4 Hot plug SFF (2.5”) HDDs
1 GPU module in the rear, lower 1U
2 GPU modules in upper 1U
Dual 1GbE
Dedicated management iLO3 LAN & 2 USB ports
VGA
UID LED & Button
Health LED
Serial (RJ45)
Power ButtonQSFP
(QDR IB)
2 Non-hot plug SFF (2.5”) HDD

6 Managed by UT-Battellefor the U.S. Department of Energy
Node Block Diagram
DDR3
DDR3
PCIe x16
PCIe x16
CPU
CPUGPU (6GB)
GPU (6GB)
RAMRAMRAM
RAMRAMRAM
QPI
QPI
Infiniband
QPI I/O Hub
I/O Hub GPU (6GB)
integrated
PCIe x16
QPI

7 Managed by UT-Battellefor the U.S. Department of Energy
Why a dual I/O hub?
8
8
8 GPU #0
GPU #1
PCIe Switch
Tesla 1U
IOH

8 Managed by UT-Battellefor the U.S. Department of Energy
Why a dual I/O hub?
8
8
8.0 GPU #0
GPU #1
PCIe Switch
Tesla 1U
IOH
Bottleneck!

9 Managed by UT-Battellefor the U.S. Department of Energy
Why a dual I/O hub?
8
8
8.0 GPU #0
GPU #1
PCIe Switch
Tesla 1U
IOH
8.0
8.0
CPU #0
CPU #1
GPU #1
GPU #2
12.8
12.8
12.8IOH
GPU #08.0
12.8
IOH
Bottleneck!

10 Managed by UT-Battellefor the U.S. Department of Energy
Introduction of NUMA
8.0
CPU #0
GPU #1IOH
12.8
IOH
CPU #0
GPU #0IOH
12.8
12.8 8.0Short Path
Long Path
11 Managed by UT-Battellefor the U.S. Department of Energy
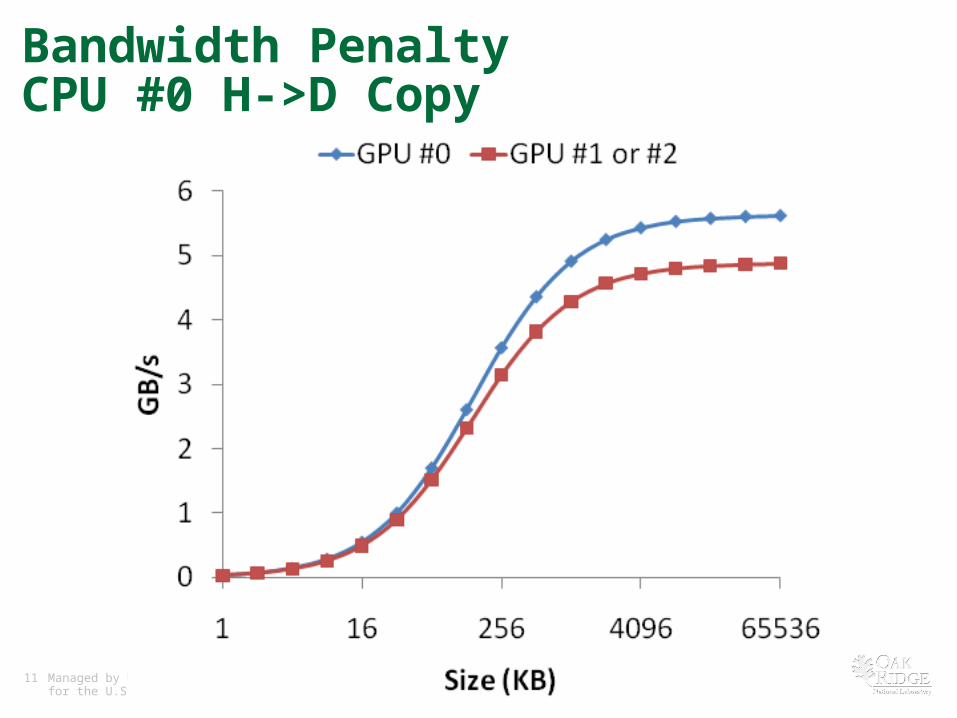
Bandwidth PenaltyCPU #0 H->D Copy

12 Managed by UT-Battellefor the U.S. Department of Energy
Bandwidth PenaltyCPU #0 D->H Copy
~2 GB/s
13 Managed by UT-Battellefor the U.S. Department of Energy
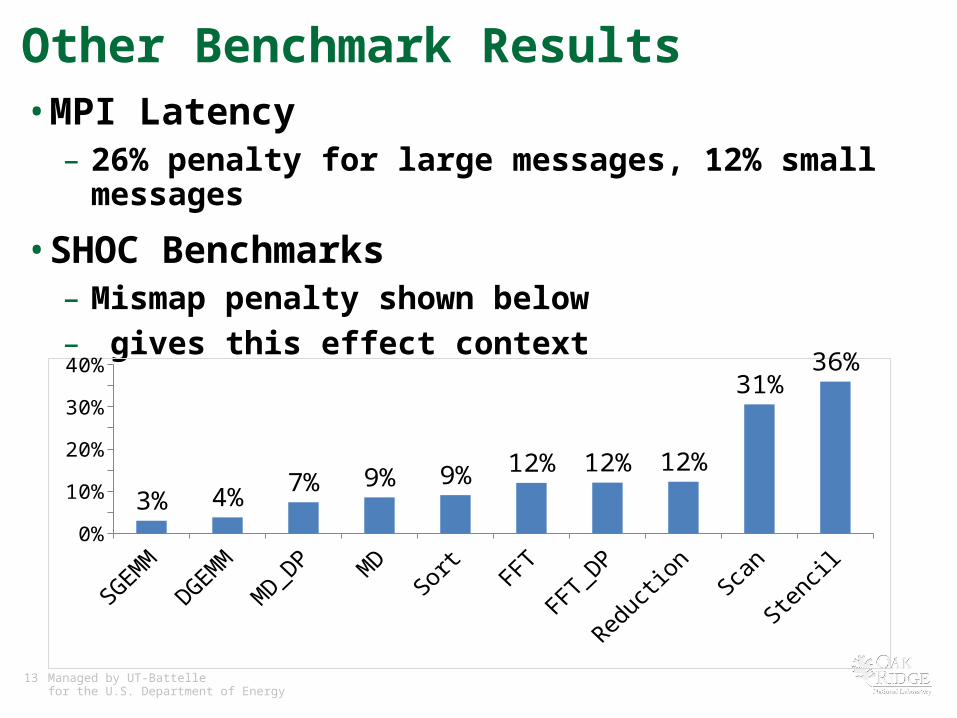
Other Benchmark Results• MPI Latency
– 26% penalty for large messages, 12% small messages
• SHOC Benchmarks– Mismap penalty shown below– gives this effect context
SGEM
M
DGEMM
MD_DP
MD
Sort FF
T
FFT_DP
Reduction
Scan
Stencil
0%5%
10%15%20%25%30%35%40%
3% 4%7% 9% 9% 12% 12% 12%
31%36%

14 Managed by UT-Battellefor the U.S. Department of Energy
Given a Multi-GPU app, how should processes be pinned?

15 Managed by UT-Battellefor the U.S. Department of Energy
Given a Multi-GPU app, how should processes be pinned?
0 1 2

16 Managed by UT-Battellefor the U.S. Department of Energy
CPU #1
CPU #0
GPU #1IOH
IOHInfiniband
GPU #0
GPU #2
Maximize GPU Bandwidth

17 Managed by UT-Battellefor the U.S. Department of Energy
CPU #1
CPU #0
GPU #1IOH
IOHInfiniband
GPU #0
GPU #2
0
12
Maximize GPU Bandwidth

18 Managed by UT-Battellefor the U.S. Department of Energy
CPU #1
CPU #0
GPU #1IOH
IOHInfiniband
GPU #0
GPU #2
0
12
Maximize MPI Bandwidth

19 Managed by UT-Battellefor the U.S. Department of Energy
CPU #1
CPU #0
GPU #1IOH
IOHInfiniband
GPU #0
GPU #2
0
12
Maximize MPI Bandwidth
Pretty easy, right?

20 Managed by UT-Battellefor the U.S. Department of Energy
Pinning with numactl
numactl --cpunodebind=0 --membind=0 ./program

21 Managed by UT-Battellefor the U.S. Department of Energy
if [[ $OMPI_COMM_WORLD_LOCAL_RANK == "2" ]]
then
numactl --cpunodebind=1 --membind=1 ./prog
else
if [[ $OMPI_COMM_WORLD_LOCAL_RANK == "1" ]]
then
numactl --cpunodebind=1 --membind=1 ./prog
else # rank = 0
numactl --cpunodebind=0 --membind=0 ./prog
fi
fi
0-1-1 Pinning with numactl

22 Managed by UT-Battellefor the U.S. Department of Energy
HPL Scaling
• Sustained MPI and GPU ops
• Uses other CPU cores via Intel MKL
23 Managed by UT-Battellefor the U.S. Department of Energy
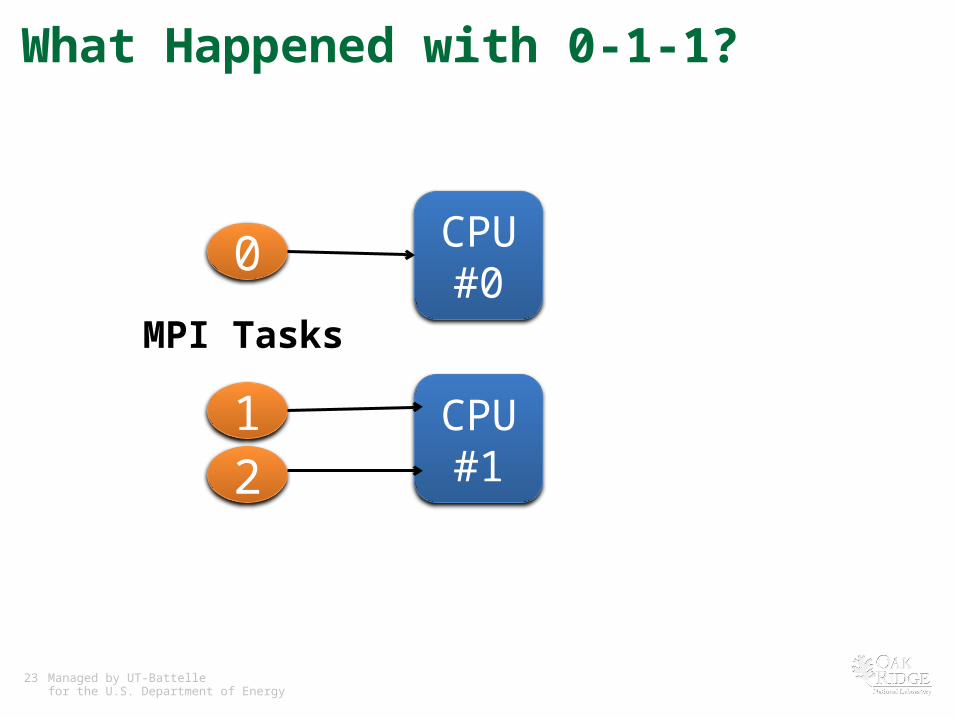
What Happened with 0-1-1?
CPU #1
CPU #0
0
12
MPI Tasks

24 Managed by UT-Battellefor the U.S. Department of Energy
What Happened with 0-1-1?
0
1
2
CPU #0
CPU #1
MPI Tasks

25 Managed by UT-Battellefor the U.S. Department of Energy
What Happened with 0-1-1?
0
1
2
CPU #0
CPU #1
MPI Tasks
MKL Threads

26 Managed by UT-Battellefor the U.S. Department of Energy
What Happened with 0-1-1?
0
1
2
CPU #0
CPU #1
MPI Tasks
MKL Threads
Threads inherit pinning!

27 Managed by UT-Battellefor the U.S. Department of Energy
What Happened with 0-1-1?
0
1
2
CPU #0
CPU #1
MKL Threads

28 Managed by UT-Battellefor the U.S. Department of Energy
What Happened with 0-1-1?
0
1
2
CPU #0
CPU #1
MKL Threads
Two idle cores, 1 oversubscribed socket!

29 Managed by UT-Battellefor the U.S. Department of Energy
NUMA Impact on Apps

30 Managed by UT-Battellefor the U.S. Department of Energy
Well…
time

31 Managed by UT-Battellefor the U.S. Department of Energy
Can we improve utilization by sharing a Fermi among multiple
tasks?

32 Managed by UT-Battellefor the U.S. Department of Energy
Bandwidth of Most Bottlenecked Task
1 2 3 40.00
1.00
2.00
3.00
4.00
5.00
6.00
5.13
2.57
1.71
0.07
5.43
2.72
1.81
0.96
min mean
Tasks sharing a GPU
GB/s
ec

33 Managed by UT-Battellefor the U.S. Department of Energy
Is the second IO hub worth it?

34 Managed by UT-Battellefor the U.S. Department of Energy
Is the second IO hub worth it?
• Aggregate bandwidth to GPUs is 16.9 GB/s
• What about real app behavior?– Scenario A: “HPL” -- 1 MPI & 1 GPU task per GPU– Scenario B: A + 1 MPI for each other core

35 Managed by UT-Battellefor the U.S. Department of Energy
Contention Penalty

36 Managed by UT-Battellefor the U.S. Department of Energy
Puzzler – Pinning Redux
Do ranks 1 and 2 always have a long path?

37 Managed by UT-Battellefor the U.S. Department of Energy
Puzzler – Pinning Redux
Do ranks 1 and 2 always have a long path?
CPU #0
GPU #1IOH
IOH

38 Managed by UT-Battellefor the U.S. Department of Energy
Puzzler – Pinning Redux
Do ranks 1 and 2 always have a long path?
CPU #0
GPU #1IOH
IOH
CPU #1
Infiniband
IOH
IOH

39 Managed by UT-Battellefor the U.S. Department of Energy
Split MPI and GPU – MPI Latency

40 Managed by UT-Battellefor the U.S. Department of Energy
Split MPI and GPU – PCIe bandwidth

41 Managed by UT-Battellefor the U.S. Department of Energy
Takeaways
• Dual IO hubs deliver– But add complexity
• Ignoring the complexity will sink some apps– Wrong pinning sunk HPL– Bandwidth bound kernels & “function offload” apps
• Threads and libnuma can help– but can be tedious to use






























