Embed Size (px)
Citation preview

K F U S I O N
Simple Annotations for Optimized Data FlowLiam Kiemele, Celina Berg, Aaron Gulliver, Yvonne Coady
University of Victoria
with thanks to Tim Mattson, Andrew Brownsword (Intel)

2
Road MapKFusion at work
Motivation
KFusion
Costs and benefitsannotations, lines of code
modularity, performance
Future work and conclusionexplicit composition of computation around data flow
IWOCL 2013 Kiemele
KFusion
Eval
Future!

IWOCL 2013 Kiemele 3
Parallel HardwareBackgroun
d

4
Good News and Bad News…
ParallelismAdded complexity
OptimizationMemory and Bandwidth
Modularity: Let’s talk LibrariesDetails behind an API
Optimize data access (prefetching, caching…)
Better separation of concerns
IWOCL 2013 Kiemele
Background

5
OpenCL LibrariesOpenCL (Computing Language), for CPUs and GPUs
At the heart of any given library will be kernels
Suppose we build an OpenCL Linear Algebra Library
__kernel void add_vectors(__global float* sum, __global float* v1, __global float* v2) {
int i = get_global_id(0); sum[i] = v1[i] + v2[i];}
IWOCL 2013 Kiemele
KFusion

6
What you get…c = sqrt(add(square(x), square(y));
square
square
add
sqrt
IWOCL 2013 Kiemele
KFusion

7
What you get…c = sqrt(add(square(x), square(y));
IWOCL 2013 Kiemele
KFusion
Kernel Operation
Memory Access Cycles
square 1 load and store 804
square 1 load and store 804
add 1 2 loads and 1 store
804
sqrt 1 load and store 804
total 4 9 3216

8
What you WANT!
c = sqrt(add(square(x), square(y));
x
y
add
sqrt
IWOCL 2013 Kiemele
KFusion

9
What you WANT!c = sqrt(add(square(x), square(y));
IWOCL 2013 Kiemele
KFusion
Kernel Operation
Memory Access Cycles
square 1 load and store 804
square 1 load and store 804
add 1 2 loads and 1 store
804
sqrt 1 load and store 804
total 4 9 3216
Kernel Operation
Memory Access Cycles
fu
1 load 404
1 load 404
1 - 4
1 store 404
total 4 3 1216

10
Two Choices
IWOCL 2013 Kiemele
KFusion
Modular ImplementationReusable
Easy to maintain and develop
Individual Kernel optimization
Monolithic ImplementationPerformance
Allows for optimizations which will otherwise exist between modules
Can we do both?

11
Introducing KFusion
IWOCL 2013 Kiemele
square(…) kernel square
Application File
Library File Kernel File
float* square
square(…)
add(…)kernel add …
float* add …
sqrt(…)kernel sqrt …
float* sqrt …
Kernel Operation Memory Access Cycles
square 1 load and store 804
square 1 load and store 804
add 1 2 loads and 1 store 804
sqrt 1 load and store 804
total 4 9 3216
KFusion

12
After KFusion…
IWOCL 2013 Kiemele
square(…) kernel square
Application File
Library File Kernel File
void square …
square(…)
add(…)kernel add …
void add …
sqrt(…)kernel sqrt …
void sqrt …
New Call:c = fu(…);
New Function:
float* fu(…)
New Kernel:kernel fu(…)
Kernel Operation Memory Access Cycles
fu
1 load 404
1 load 404
1 - 4
1 store 404
total 4 3 1216
KFusion
13
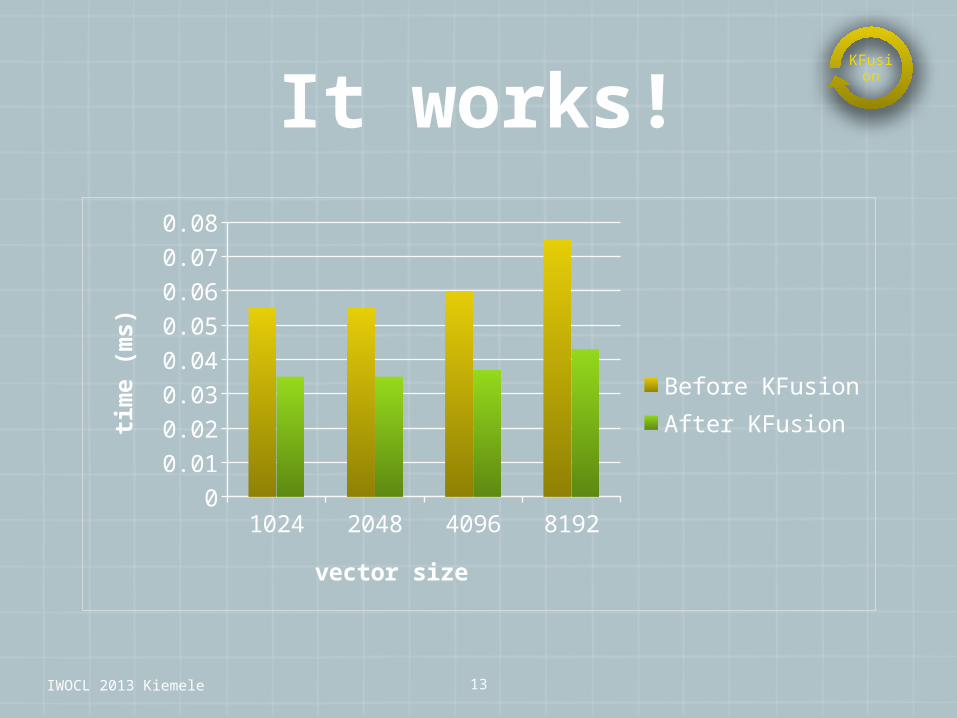
It works!
1024 2048 4096 81920
0.01
0.02
0.03
0.04
0.05
0.06
0.07
0.08
Before KFusionAfter KFusion
vector size
tim
e (
ms)
IWOCL 2013 Kiemele
KFusion

14
Road MapKFusion at work
what and how
…why!
Costs and benefitsannotations, lines of code
modularity, performance
Future work and conclusionexplicit composition of computation around data flow
IWOCL 2013 Kiemele
KFusion
Eval
Future!

15
CostsAnnotations
application hints
library synchronization
kernel data flow for compositions
Preprocessorbuild dependency graph
source-to-source transformationloop fusion
deforestation
IWOCL 2013 Kiemele
KFusion
Eval

16
Annotations#pragma start fuse
square(x,x)
square(y,y)
add(c,x,y)
sqrt(c, c) c = sqrt(add(, square(y));#pragma end fuse
#pragma sync out
public void dot_product(double result, vector x);
#pragma sync in
public void matrix_vector_mult(vector b, Matrix A, vector x)
IWOCL 2013 Kiemele
applicatio
n
Library
KFusion
Eval

17
Annotations__kernel void add_vectors(__global float* sum, __global float* v1,
__global float* v2) {#pragma kload
{
int i = get_global_id(0); float arg1 = v1[i]; float arg2 = v2[i]; float s; } s = arg1 + arg2; #pragma kstore
{ sum[i] = s; }}
IWOCL 2013 Kiemele
kernel
KFusion
Eval
add

18
Dependency Graph
IWOCL 2013 Kiemele
square(x) square(y)
add(c,x,y)
sqrt(c)
x y
c
KFusion
Eval

19
Transformation…
IWOCL 2013 Kiemele
square(x) square(y)
add_sqrt(c,x,y)
x
c
y
KFusion
Eval

20
Replacement Kernel!
IWOCL 2013 Kiemele
fu(c,x,y)
x
c
y
KFusion
Eval
AOSD 2013 Kiemele 21
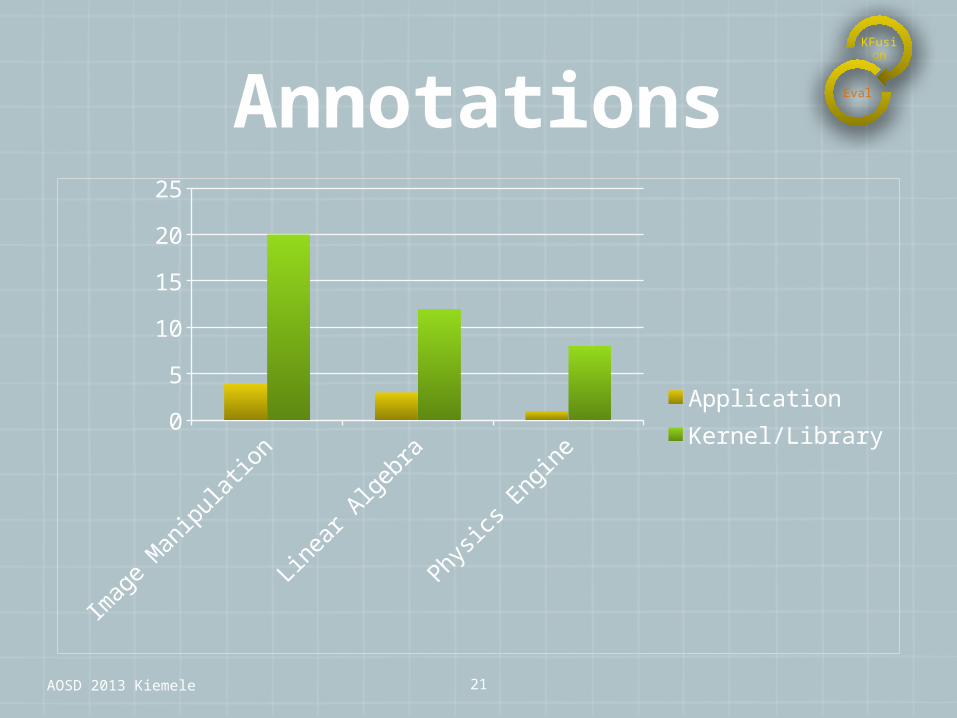
Annotations
Imag
e Man
ipul
atio
n
Line
ar A
lgeb
ra
Phys
ics En
gine
0
5
10
15
20
25
ApplicationKernel/Library
KFusion
Eval

22
Benefits
IWOCL 2013 Kiemele
KFusion
Eval
Imag
e Man
ipul
atio
n
Line
ar A
lgeb
ra
Phys
ics En
gine
0
200
400
600
800
1000
1200
Lines of Code Generated
LibraryKernelFused LibraryFused Kernel
23
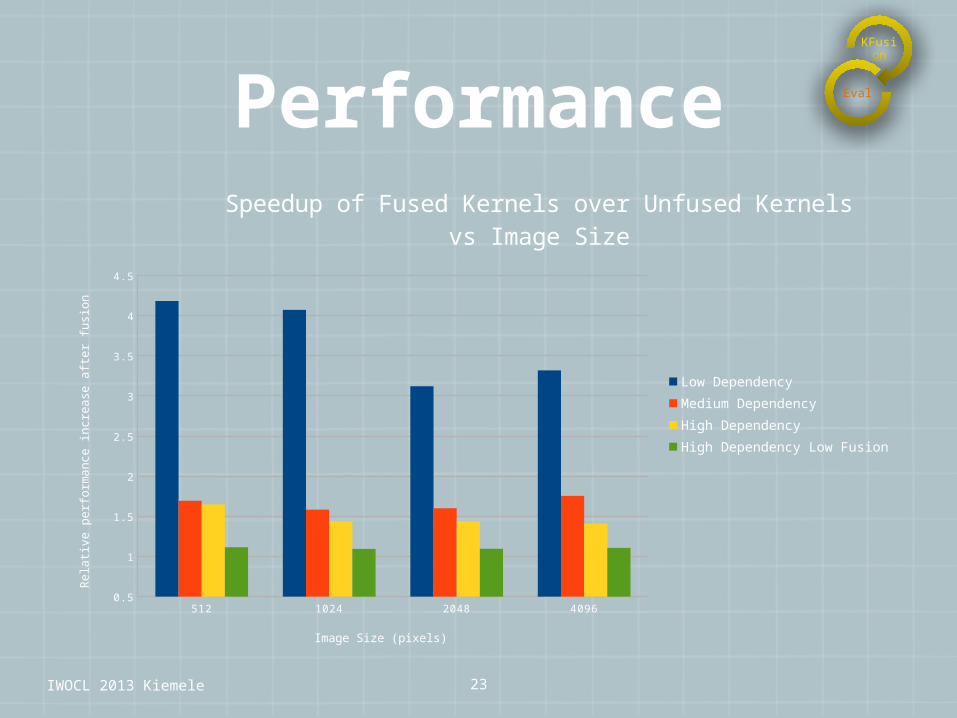
Performance
IWOCL 2013 Kiemele
KFusion
Eval
512 1024 2048 40960.5
1
1.5
2
2.5
3
3.5
4
4.5
Speedup of Fused Kernels over Unfused Kernels vs Image Size
Low DependencyMedium DependencyHigh DependencyHigh Dependency Low Fusion
Image Size (pixels)
Rela
tive p
erf
orm
an
ce in
cre
ase
aft
er
fusi
on

24
Performance
IWOCL 2013 Kiemele
KFusion
Eval
512 1024 2048 40960
0.2
0.4
0.6
0.8
1
1.2
Speedup of Automatic Fusion over Manual Fusion vs Image Size
Low Dependency
Medium Dependency
High Dependency
High Dependency Low Fusion
Image Size (Pixels)
Rela
tive S
peed
up

AOSD 2013 Kiemele 25
Roofline Analysis of Performance
Peak Actual GFlops =minimum(Bandwidth x flops/byte, Peak Performance)
Three Linear Algebra Scenariosc = sqrt(a2 + b2)
d = sqrt( (x1 – x2)2 + (y1 – y2)2)
Start of conjugate gradientr = Ax – b
p = r
R2 = r*r

26
c = sqrt(a2 + b2)
IWOCL 2013 Kiemele
KFusion
Eval

27
d = sqrt((x1 – x2)2 + (y1 – y2)2)
IWOCL 2013 Kiemele
KFusion
Eval

28
Conjugate Gradient
IWOCL 2013 Kiemele
KFusion
Eval
AOSD 2013 Kiemele 29
Road MapKFusion at work
what and how
…why!
Costs and benefitsannotations, lines of code
modularity, performance
Future work and conclusionexplicit composition of computation around data flow
KFusion
Eval
Future!

30
Future WorkTools
comprehension and visualization
emulation
performance testing
Combine with other approaches
Optimizing compiles
Code Generators
IWOCL 2013 Kiemele
KFusion
Eval
Future!
kfuse{ calls}
__kernel void k(…) { kload { … } computation kstore { … }}

IWOCL 2013 Kiemele 31
ConclusionKFusion is a first step towards
explicit, flexible control
Allowing optimizations between modules
separation of concerns
github.com/4Liamk/KFusion/wiki
512
1024
2048
4096
0
2
4
Sp
eed
up
0600
1200
01020





























