Embed Size (px)
Citation preview

THE JOURNAL OF BIOLOGICAL CHEMl8TRY Vol. 259, No. 22, Issue of November 25, pp. 13668-13673 1984 Printed in L~.s.A.
Isolation and Characterization of a cDNA Clone for the Amino-terminal Portion of the Pro-cul(I1) Chain of Cartilage Collagen*
(Received for publication, May 9,1984)
Kimitoshi Kohno, George R. Martin, and Yoshihiko Yamada From the Laboratory of Devehrmental Biology and Anomalies, National Institute of Dental Research, National Institutes of Health, Bethesda, Ma&land 20205
”
We have isolated a cDNA clone (pRcol 2) which is complementary to the 5’4erminal portion of the rat pro-al(I1) chain mRNA. A synthetic oligonucleotide was used both as a primer for cDNA synthesis and as a probe for screening a cDNA library. The probe was a mixture of sixteen 14-mers deduced from an amino acid sequence present in the amino-terminal telopep- tide of the rat cartilage al(II) chain. This primer was chosen so that the resulting cDNA would contain the sequence of the 5’ end of the mRNA.
The nucleotide sequences of the cDNA were deter- mined and compared with that of three other intersti- tial procollagen chain mRNAs (pro-al(I), pro-a2(1), and pro-al(II1) chain mRNA). pRcol2 contains a 621- base pair (bp) insert, including 163 bp of the 6’ un- translated region plus 368 bp coding for the signal peptide, the amino-terminal propeptide, and a part of the telopeptide. The signal peptide of the type 11 colla- gen chain is composed of about 20 amino acids. There is little homology between the amino acid sequence of the signal peptide in the pro-al(I1) chain and that of three other interstitial procollagen chains. The NH2- terminal propeptide is deduced to contain short non- helical sequences at its amino and carboxyl ends and an internal helical collagenous domain comprising 25 repeats of Gly-X-Y with one interruption. There is a strong conservation of the amino acid sequence of the carboxyl-terminal part of the NHz-terminal propeptide in the pro-al(II), pro-al(I), and pro-a2(1) chains. Type I1 collagen mRNA does not contain a sequence corre- sponding to a uniquely conserved nucleotide sequence around the translation initiation site which occurs in mRNA for other procollagen chains.
Type I1 collagen is the major structural component of cartilage matrix and, with the exception of the vitreous humor, is unique to this tissue. It forms thin randomly oriented fibers which confer tensile strength and provide a scaffolding for proteoglycans and other constituents of cartilage matrix (1- 3). It arises from pro-al(I1) chains which are synthesized from a distinct mRNA, which after various post-translational modifications, form triple helical molecules. Type I1 collagen appears to be regulated separately from other collagens. A switch in synthesis from type I to type I1 collagen is observed as mesenchymal cells differentiate into chondrocytes. Follow- ing treatment of chondrocytes in culture with embryo extract, or BudR, the cells dedifferentiate and no longer synthesize
* The costa of publication of this article were defrayed in part by the payment of page charges. This article must therefore be hereby marked “aduertisement” in accordance with 18 U.S.C. Section 1734 solely to indicate this fact.
type I1 collagen (4, 5). The basis for these changes is not understood, but regulation appears to occur at the transcrip- tional level.
Considerable information is available on the structure of certain collagen genes. Studies on the genes for type I procol- lagen chains indicate that they are large and contain many exons and introns (6,7). Studies on cDNA and genomic clones for the chick pro-al(I1) chains show considerable similarity between the 3’ end of this gene and those for the chains of type I and 111 procollagen. Specifically, the carbohydrate- containing region at the carboxyl end of the pro-al(I1) chain shows striking homology to similar regions of the pro-al(I), pro-a2(1), and pro-al(II1) chains (8-10).
Conventional approaches for isolating full-sized cDNA are difficult to apply to collagen mRNA due to its large size (>5 kilobase pairs) and high GC content. To facilitate the study of the type I1 collagen gene, we have constructed a cDNA clone complementary to the 5”terminal part of the pro-al(I1) chain mRNA. The Swarm chondrosarcoma is a transplantable rat tumor used as the source of type I1 collagen. A portion of the amino-terminal end of the al(I1) chain, including the amino-terminal telopeptide, has been sequenced by Dr. Peter Fietzek (Freundenberg Co., Weinheim, West Germany). We used a synthetic oligonucleotide, deduced from a portion of the amino acid sequence of the telopeptide, as a primer for cDNA synthesis and as a probe for screening a cDNA library. From the position of the primer, we expected that the resulting cDNA would be about 500 base pairs in length and would contain the 5’ untranslated segment, the sequences coding for the signal peptide, the N-propeptide,’ and a portion of the telopeptide of the pro-al(I1) chain. In this report, we describe the isolation of such a cDNA clone. We have also determined its nucleotide sequence and compared it with that of other collagen mRNAs.
MATERIALS AND METHODS
Reagents-Restriction enzymes were purchased from New England Biolabs and Bethesda Research Laboratories, reverse transcriptase from Life Science, T4 polynucleotide kinase, terminal deoxynucleo- tidyltransferase, and oligonucleotides from P-L Biochemicals, [a-”P] ATP (7000 Ci/mol), [a-3ZP]dATP, [a-SzP]dGTP, [ O - ~ ~ P I ~ C T P , and [a-”P]dTTP (3000 Ci/mol each) from New England Nuclear.
Preparation of RNA-The chondrosarcoma was maintained by serial transplantation in Sprague-Dawley rata (11). The animals were sacrificed when the tumors had reached 15-20 g, usually 3 to 4 weeks after transplantation. Pieces of tumor were treated with 0.5% colla- genase to digest the extracellulh matrix (12). Total RNA was then extracted by the guanidine HC1 method as previously described (13). Poly(A)-containing RNA was prepared by oligo(dT)-cellulose column chromatography. Poly(A)RNA was further fractionated on a methyl mercury agarose gel. Approximately 300 pg of mRNA was denatured
The abbreviations used are: N-propeptide, amino-terminal pro- peptide; C-propeptide, carboxyl-terminal propeptide.
13668

cDNA Clone to the 5' End of Rat Type I I Collagen mRNA 13669
with 10 mM methyl mercury hydroxide for 1 min at 65 "c , prior to electrophoresis through a 1% low-melting-temperature agarose gel which contained 5 mM methyl mercury hydroxide. After the desired separation was obtained, the gel was rinsed in 0.1 M dithiothreitol for 1 h. RNA was extracted as described previously (14) from slices of gel corresponding to material around the 30 S region.
Cloning of Doubh-stranded cDNA-cDNA was synthesized accord- ing to the method described by Agarwal et al. (15). Several micrograms of fractionated poly(A) RNA and 0.2 pg of oligonucleotides were mixed in 50 p1 of 5 mM sodium phosphate, pH 6.8, with 5 mM EDTA. The mixture was heated at 90 "C for 5 min, and then NaCl was added to 94 mM. The mixture was slowly cooled to room temperature for 20 min. The reaction mixture was adjusted to 50 mM Tris-HC1, pH 8.3, supplemented with dithiothreitol(5 mM), MgClz (7.5 mM), and 1 mM of each of the four unlabeled deoxyribonucleoside triphosphates plus 200 pCi of each of the [~-32P]de~xyribonucle~side triphosphates (3000 Ci/mmol), 60 mM NaCI, 1400 units/ml of RNasin, and 100 units of reverse transcriptase. After incubation for 60 min at 39 "C, EDTA was added to 20 mM and then NaOH was added to 45 mM. RNA was hydrolyzed for 60 min at 65 "C. The reaction mixture was then neutralized by adding 2 M Tris-HC1 (pH 7.5) and 1 M HCl. After adding ammonium acetate up to 2 M, single-stranded cDNA was precipitated by 2 volumes of ethanol. This alcohol precipitation step was repeated once more, and the pellet was washed once with 80% ethanol. The cDNA was tailed with dC by terminal deoxynucleoti- dyltransferase (16). Second-strand synthesis was carried out with reverse transcriptase primed with oligo(dG) as described above. The double-stranded cDNA was resuspended in 30 pI of 50 mM Tris-HC1, pH 7.5,s mM MgC12, 10 mM 8-mercaptoethanol, and 0.05 mM of each of the 4 dNTPs. One unit of Klenow fragment was added and incubated at room temperature for 20 min to ensure blunt-ended molecules. The reaction mixture was extracted with phenol/CHC& (1:l). After the cDNA was precipitated by 2 volumes of ethanol in the presence of 2 M ammonium acetate, the pellet was washed twice with 80% ethanol. Tailing of the cDNA with dCTP was carried out under the same conditions as described above. The dC-tailed double- stranded cDNA was annealed to dG-tailed pUC9 and transformed to Escherichia coli N38 by Hanahan's procedure (17).
The oligonucleotide primer was also used as a hybridization probe to screen a cDNA library. It was, therefore, necessary to preserve the 3' end of the cDNA with the sequence corresponding to the primer. In the first attempt, we constructed a cDNA library by conventional methods using S1 nuclease digestion to remove the hairpin structure which results from self-priming. However, we failed to obtain strong positive clones from this library possibly because Sl nuclease cleaved off the 3' portion of the desired cDNA. For this reason, we chose the method described by Land et al. (18) in which the S1 treatment step is not required.
Isohtion and Screening of cDNA Clones-Transformants were plated on nitrocellulose filters and the plasmids amplified on chlor- amphenicol plates (19). Filters were prepared for hybridization as follows. Replica filters were placed on a Whatman 3" paper saturated with 10% sodium dodecyl sulfate for 3 min and then transferred onto 3" paper saturated with denaturing buffer con-
taining 0.5 M NaOH and 1.5 M NaCl for 5 min. For neutralization, filters were then placed on 3" paper saturated with 1.5 M NaCl and 0.5 M Tris-HC1 (pH 8) for 5 min. To reduce background filters were treated with proteinase K (1 mg/ml) in 0.5 mM NaC1, 10 mM Tris-HC1 (pH 7.4), 5 mM EDTA, and 0.1% sodium dodecyl sulfate at 37 "C for 60 min. After blotting between two sheets of dry Whatman 3MM paper, the filters were washed with 2 X SSC and then baked for 2 h at 80 "C.
Colony filters were prehybridized in 6 X NET (1 X NET = 0.15 M NaCl, 0.015 M Tris-HC1 (pH 7.5), 0.001 M EDTA), 5 X Denhardt's reagent (1 X Denhardt's reagent = 0.02% (w/v) each of bovine serum albumin, polyvinylpyrrolidone, and Ficoll), 0.5% Nonidet P-40, and 100 pg/ml denatured E. coli DNA for 2 h at 68 "C (20). A synthetic oligonucleotide was labeled with [y3*P]ATP by T4 kinase and used as a hybridization probe. Hybridization was done in the same solution for 16 h at 37 "C. Filters were then washed at 4 "C with four changes of 6 X SSC. Filters were dried and exposed to Kodak XR-5 film for 5 h at -70 "C.
Northern Hybridization-RNA was electrophoresed on 1% formal- dehyde agarose gels and then transferred to nitrocellulose filters as previously described (21). The filter-bound RNA was hybridized to nick-translated plasmid DNA. Hybridization was carried out as de- scribed previously (22).
Nuckic Acid Sequence Analysis-Nucleotide sequence determina- tions were carried out as described by Maxam and Gilbert (23).
RESULTS
Synthetic Oligonucleotides Used for the Synthesis of cDNA-To isolate a cDNA clone for the 5' end of the mRNA for the pro-al(I1) chain by the primer extension method, we used a synthetic oligonucleotide to prime cDNA synthesis. Fig. 1 shows a portion of the amino acid sequence of the amino-terminal telopeptide of the rat type I1 collagen. The deduced nucleotide sequence of the corresponding mRNA and oligonucleotide primer are also shown in Fig. 1. The nucleotide sequence of the primer was derived from the pentapeptide, Phe-Asp-Glu-Lys-Ala. This particular sequence was selected for a primer since it is close to the 5' end of the mRNA and has the least codon degeneracy. It is a mixture of 16 different tetradecamers representing all possible sequences predicted from the amino acid sequence, except that the third nucleotide of the alanine codon was excluded. One of these sequences was expected to match that in the pro-al(I1) chain mRNA.
Synthesis and Screening of cDNA Clones-The Swarm rat chondrosarcoma was chosen as the source of mRNA. The tumor cells were dissociated with collagenase before extract- ing RNA. This step was necessary to increase the yield of RNA. Total RNA was extracted from the cells, and poly(A)- containing RNA was isolated by oligo(dT)-cellulose column
(A) Reprocollagen
FIG. 1. Primer used to synthesize pro-al(I1) cDNA. A, diagrammatic representation of entire preprocollagen and chain. N-tebpptide, amino-termi- nal telopeptide. B, the amino acid se- quence of the amino-terminal telopep- tide. The underlined amino acid se- quence corresponds to the mRNA nu- cleotide gequence selected for the prep- aration of the primer.
Sequence Gln-Met-Ala-Gly-Gly-Phe-Asp-Gln-Lys-Ala-Gly-Gly-Ala- -
mRNA Sequence
Oligonucleotide Used as Primer

13670
A
28s - w
18s-
cDNA Clone to the 5' End of Rat Type 11 Collagen mRNA
B
- 18s
FIG. 2. Northern Hybridization. Poly(A)-containing RNA from a rat chondrosarcoma was separated on a formaldehyde agarose gel and transferred to nitrocellulose paper (21). The PstI fragment from pRcol 2 and PstI pCs I (8) were labeled with [32P]deoxynucleo- tides by nick translation. Hybridization was carried out as described previously (22). A, rat chondrosarcoma poly(A) RNA hybridized to a PstI fragment from pRcol 2, the rat pro-al(I1) chain 5' probe. B, rat chondrosarcoma poly(A) RNA hybridized to a PstI fragment from pCs I, the chick pro-al(I1) 3' probe.
Hindlll Aval Aval Barn HI
T4 W ' A I ml AJU I R s a l PR I
"
0 c " - 0
- 0 5
0 - 1 0 0 bo
FIG. 3. Restriction map and DNA sequencing strategy of the cDNA. The arrows indicate the direction of sequencing.
chromatography. In a preliminary experiment using total poly(A) RNA as a template, we found that the extended cDNA was very heterogeneous. I t is likely that this was due to the degeneracy of the synthetic oligonucleotide, i.e. a variety of sequences may form hybrids of comparable stability with mRNAs other than the pro-al(I1) mRNA. For this reason, we attempted to select fractions from the chondrosarcoma mRNA which were enriched in pro-al(I1) chain mRNA by fractionating the RNA by electrophoresis on methyl mercury gels. In these experiments, the presence of pro-al(I1) chain mRNA was detected by hybridization after transfer to nitro- cellulose using a chick pro-al(I1) probe (8). Subsequently, the mRNA in that portion of the gel was enriched, as described under "Materials and Methods," and used as a template for
1 50 C A G G G C G C C G C T G G G C T G C C G G G T C T C C T G C C T C C T C C T C C T G C T C C G A G
1 l a , A G C C T C C T G C A T G A G G G C G C G G T A G A G A C C C G G A C C C G C T C C G G T C T C T G -
C C G C C T C G C C G A G C T T C G C C C G G G C C A A G G C T C T G C G G G C C T C G C G G T G A 150
2 m G C C ~ G A T T C G C C T C G G G G C T C C C C A G T C G C T G G T G C T G C T G A C G C T G C T
M s t l l s A r g L s u G l ~ A l a P r o G l n S s r L s u V l l L s u L e u L s u T h r l e u l e
3 M C A T C G C C A C G G T C C T A C A A T G T C A G G G C C A G G A ~ G C C C G A A A A T T A G G A C u l l s A l t T h r V a l L e u G l n C r , G l n C l y G l n G l ~ G l n A s p A l a A r g L ~ s L e u G l ~ P
300 C A A A G G G G C A G A A A G G A G A A C C T G G A G A T A T C A A A G A T A T C A T A G G A C C T r o L ~ s G l ~ G l n L ~ s G l ~ G l u P r o G l ~ A s p l l e L ~ s A s p l l e l l s G l ~ P r o
A A A G G A C C T C C T G G C C C T C A G G G A C C T G C C G G T G A A C A A G G A C C A A G A G G L y s G l y P r o P r o G l y P r o G I n G l ~ P r o A l a G l y c l u G l u G l n G l ~ P r o A r g G l
350
400 T G A C C G T G G T G A C A A G G G A G A G A G G G G T G C A C C T G G A C C C C G T G G C A G A G v A s p A r g G l y A s p L ~ s G l ~ G l u A r g G l ~ A l a P r D G l ~ P r o A r g G l ~ A r g A
1 ~ G G A G A A C C T G G T A C C C C T G G A A A T C C T G G T C C C C C T G G C C C T C C A G G C
150
s p G l v G l u P r o G l ~ T h r P r o G l ~ A s n P r o G l ~ P r o P f o G l ~ P r o P r o G l ~
C C C C C T G G T C C C C C T G G C C T T G G T G G A G G A A A C T T T G C G G C C C A G ~ G C P r o P r o G l ~ P r o P r o G l ~ L s u G l ~ G l ~ G l ~ A s n P h s A l a A l a G l n M s l A i
5 5 0 0
T G G A G G A T T T G A T C A G A A G G C a G l ~ G l v P h s A s p G l n L y s
FIG. 4. cDNA sequence of the 5"terminal portion of the rat pro-al(I1) mRNA and deduced amino acid sequence. Residues are numbered from 5' to 3', after the poly(dC) tail in pRcol 2. The AUG codons are underlined.
cDNA extension using the synthetic oligonucleotide as a primer.
About 3 X lo4 colonies were screened with 32P-labeled oligonucleotide primer, and 20 colonies showed a strong sig- nal. One of these clones, pRcol2, containing about a 600-base pair PstI insert, was chosen for further characterization.
Characterization ofthe cDNA Clone-Plasmid pRcol2 DNA was labeled with [ a-32P]deoxynucleotides by nick translation and hybridized to a nitrocellulose filter to which RNA from the rat chondrosarcoma separated by electrophoresis had been transferred (Fig. 2). The labeled probe hybridized to a 5.5- kilobase pair RNA species in the rat chondrosarcoma (Fig. 2, lane A ) . The same RNA band also hybridized with chick type I1 collagen cDNA (Fig. 2, lane B ) . This RNA is slightly larger than the pro-al(I1) mRNA from chick cartilage.
To further establish the identity of the clone, we determined the nucleotide sequence of the 600-base pair insert of pRcol 2. Fig. 3 shows a restriction map of the clone which also indicates the sequence strategy used with this insert. The entire nucleotide sequence is depicted in Fig. 4, except that some 50 G residues at the 5' end and 17 C residues at the 3' end of the insert are not shown. The 14-nucleotide sequence TTTGATCAGAAGGC at the 3' end is identical to one of the complementary sequences in the primers used for cDNA extension. The adjacent nucleotide sequence and the amino acid sequence deduced from it (Glu-Met-Ala-Gly-Gly) agree with the amino acid sequence determined for this portion of the protein. These data establish that pRcol2 corresponds to a portion of the mRNA for the pro-a(I1) chain.
The first and third AUG codons lead only to short reading frames. Therefore, the second AUG triplet is probably the
cDNA Clone to the 5' End of Rat Type 11 Collagen mRNA 13671
(A) S i g n a l P e p t i d e
1 10 20 + + + Kat al(I1) Met Ile Arg Leu Gly Ala Pro Gln Ser Leu Val Leu Leu Thr Leu Leu I l e Ala Thr Val Leu Gln Cys Gln Gly G l n Mouse &(I) - Leu Ser Phe Val Asp Thr Arg Thr - Leu - - Ala Ala Thr Ser Cy6 Leu Ala Thr Cy6 Gln Chick &(I) - Leu S e r Phe Val Asp Thr Arg I l e - Leu - - Ala Val Thr Ser Tyr Leu Ala Thr Ser Gln Chick al(1) - Phe Ser Phe Val Asp S e r Arg Leu - Leu - I l e Ala Ala Thr Val Leu Leu Thr Arg Gly Gln Chick a l ( I L 1 ) - Met Ser Phe Val Gln Lys Val - - Phe Ile - Ala V a l Phe Gln P ro Se r Val Ile Leu Ala Gln Gln
(B) N-propeptide
Rat al(I1) C h i c k & ( I )
C a l f a l ( I I 1 ) Calf &(I) Glu Glu Glu Gly Gln Glu Glu Gly Gln Glu Glu Asp Ile Pro Pro Val Thr w Val Gln Asp Gly Leu Arg
Glu Gln Glu Ala Val Asp Gly Gly Ser His Leu Gly Gln Ser
Rat al(I1) Chick &(I) Calf al(1) Tyr H i s Asp Arg Asp Val Trp Lys Pro Val Pro Gln I l e Val w Asp Asn Gly A m Val Leu Calf al(II1) Tyr Ala Asp Arg Asp Val Trp Lys Pro Glu Pro Gln I l e -Val e Asp Ser Gly Ser Val Leu
+22 + + 40 Kat al(I1) Gln Gln Gly Gln Asp Ala Arg Lys Leu Gly Pro Lys Gly Gln Lys Gly Glu Pro Gly Asp I l e Lys Asp - Chick &(I) Calf al(1) Asp Asp Val Ile Asp Gln Leu Lys Asp - Pro Asn Ala Lys Val Pro Thr Asp Glu Cy6 Cy6 Pro Val Calf al(II1) Asp Asp I l e I le - Asp Asp Gln Glu Leu Asp Pro Asn Pro Glu I le Pro Phe - Glu Cy6 Cy6 Ala
60 Kat al(I1) Ile Ile Gly Pro Lys Gly Pro Pro Gly Pro Gln Gly Pro A l a Gly Glu Gln Gly Pro Arg Gly Asp Arg Gly Ch ick &( I I ) G ln His Val S e r Glu Ala Ser Ala - Arg Lys - Calf al(1) - Pro Glu Gly Gln Glu Ser - Thr Asp - Glu Thr Thr - Val Glu - - Lys - Asp Thr - C a l f a l ( I I 1 ) Val Pro Gln Pro Pro Thr Ala Pro Thr Arg Pro - Asp - Gln[Pro - Glx Pro - Ala LySj -
80 Rat al(I1) Asp Lys Gly Glu Arg Gly Ala Pro Gly Pro Arg Gly Arg Asp Gly Glu Pro Gly Thr Pro Gly Asn Pro Gly Chick &(II) Pro Arg - Asp Lys - Pro Glu - Glu - - Pro Pro - Pro - - Arg Asp - Glu Asp - Calf d(1) Pro Arg - Pro - - Pro Ala - - Pro - - - - Ile - - Gln - - Leu - - Calf al(II1) - Pro - Pro Pro - I l e - - Arg Asn - Asp Pro - Pro - - S e r - - Ser - -
100 Kat al(I1) Pro Pro Gly Pro Pro Gly Pro Pro Gly Pro Pro Gly Leu Gly Gly Gly Asn Phe Ala Ala
E:i5 $[€lI) S e r - - - - - Ile Glu Ser pro Thr - - GIn - Thr Ser pro + b - - - Pro
Chick &(I) - - - - - - - - - - - - - - - A - - - - " " " " " " " -
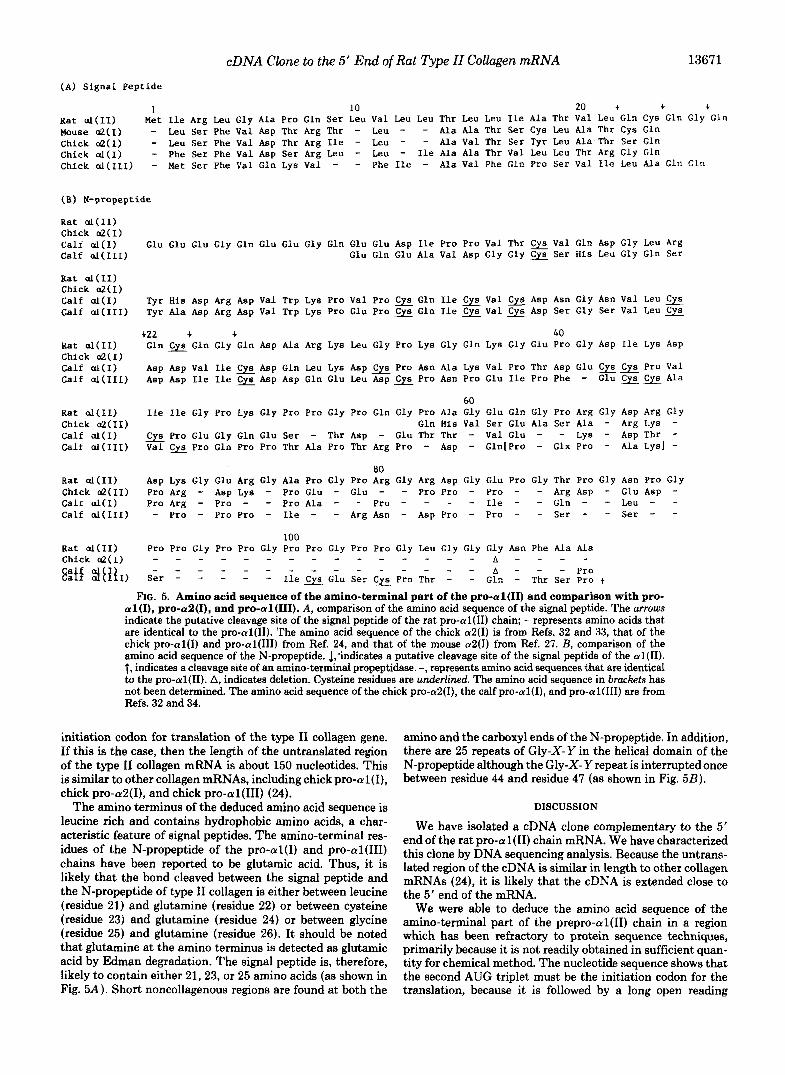
FIG. 5. Amino acid sequence of the amino-terminal part of the pro-al(I1) and comparison with pro- al(I), pro-a2(1), and pro-al(II1). A , comparison of the amino acid sequence of the signal peptide. The arrows indicate the putative cleavage site of the signal peptide of the rat pro-al(I1) chain; - represents amino acids that are identical to the pro-al(I1). The amino acid sequence of the chick a2(I) is from Refs. 32 and 33, that of the chick pro-al(1) and pro-al(II1) from Ref. 24, and that of the mouse a2(I) from Ref. 27. B, comparison of the amino acid sequence of the N-propeptide. 1,'indicates a putative cleavage site of the signal peptide of the al(I1). t, indicates a cleavage site of an amino-terminal propeptidase. -, represents amino acid sequences that are identical to the pro-al(I1). A, indicates deletion. Cysteine residues are underlined. The amino acid sequence in brackets has not been determined. The amino acid sequence of the chick pro-a2(1), the calf pro-al(I), and pro-al(II1) are from Refs. 32 and 34.
initiation codon for translation of the type I1 collagen gene. If this is the case, then the length of the untranslated region of the type I1 collagen mRNA is about 150 nucleotides. This is similar to other collagen mRNAs, including chick pro-al(I), chick pro-aS(I), and chick pro-al(1II) (24).
The amino terminus of the deduced amino acid sequence is leucine rich and contains hydrophobic amino acids, a char- acteristic feature of signal peptides. The amino-terminal res- idues of the N-propeptide of the pro-al(1) and pro-al(II1) chains have been reported to be glutamic acid. Thus, it is likely that the bond cleaved between the signal peptide and the N-propeptide of type I1 collagen is either between leucine (residue 21) and glutamine (residue 22) or between cysteine (residue 23) and glutamine (residue 24) or between glycine (residue 25) and glutamine (residue 26). It should be noted that glutamine at the amino terminus is detected as glutamic acid by Edman degradation. The signal peptide is, therefore, likely to contain either 21,23, or 25 amino acids (as shown in Fig. 5A). Short noncollagenous regions are found at both the
amino and the carboxyl ends of the N-propeptide. In addition, there are 25 repeats of Gly-X-Y in the helical domain of the N-propeptide although the Gly-X- Y repeat is interrupted once between residue 44 and residue 47 (as shown in Fig. 5B).
DISCUSSION
We have isolated a cDNA clone complementary to the 5' end of the rat pro-al(I1) chain mRNA. We have characterized this clone by DNA sequencing analysis. Because the untrans- lated region of the cDNA is similar in length to other collagen mRNAs (24), it is likely that the cDNA is extended close to the 5' end of the mRNA.
We were able to deduce the amino acid sequence of the amino-terminal part of the prepro-al(1I) chain in a region which has been refractory to protein sequence techniques, primarily because it is not readily obtained in sufficient quan- tity for chemical method. The nucleotide sequence shows that the second AUG triplet must be the initiation codon for the translation, because it is followed by a long open reading

13672 cDNA Clone to the 5' End of Rat Type II Collagen mRNA
frame which contains the sequence for Gly-X- Y repeats which are characteristic of the collagenous domain for the N-pro- peptide and for the predicted amino acid sequence of the amino-terminal telopeptide of the rat pro-al(I1) chain. The model proposed by Kozak (25) suggests that the sequences around the translation initiation codon play a role in deter- mining which AUG is recognized. It has been recently re- ported that a sequence CCGCCAUG(G) is a consensus se- quence flanking the initiation codon of eukaryotic mRNA. A related sequence, GAGCCAUGA, is present near the second AUG, as would be predicted by a proposed model (26).
It has been reported that in three chick mRNAs (pro-al(I), pro-aZ(I), and pro-al(II1) mRNA) a sequence of about 50 nucleotides around the translation initiation site is highly conserved and contains a large stretch of inverted repeat sequence that could form a stable stem-loop structure (24). This conserved sequence has been speculated to play a role in determining the level of expression of those genes by modu- lating translational efficiency (24, 27). We did not, however, find any such conserved sequence in the pro-al(I1) chain mRNA. The absence of the conserved sequence in type I1 collagen mRNA may reflect the difference in regulation of these genes but could be due to species' differences.
The amino acid sequence of the signal peptide of the rat pro-al(I1) chain shows little homology to that of chick pro- al(I) , chick and mouse pro-aZ(I), and chick pro-al(1II) chains, except for the presence of a stretch of hydrophobic amino acids (Fig. 5A) . However, the size of the signal peptides is almost the same in all four collagen species.
The N-propeptides of interstitial collagens are composed of three structurally distinct regions: the globular domain, the collagenous domain (containing Gly-X-Y repeats), and the carboxyl-terminal noncollagenous region. Though the func- tion of the N-propeptide is not clear, it has been postulated that it may prevent premature intracellular deposition of procollagen (34) and when cleaved it may inhibit translation of collagen mRNA, (28-30). Fig. 5B shows the amino acid sequence of the N-propeptide of pro-al(II), pro-aZ(I), pro- al(1) and pro-al(II1). DNA sequence analysis of the cDNA shows that the pro-al(1) chain has a very short globular domain as predicted by the previous amino acid composition analysis of the chick amino-terminal propeptide (31). A short globular domain is also found in the pro-aZ(1) chain (32). However, there is no homology between the amino acid se- quence of the globular domain of the N-propeptide of the rat pro-al(I1) chain and that of the chick pro-aZ(1) chain. In the N-propeptide of type I1 collagen, there is no cysteine residue involved in intra- or interchain disulfide bonds. In contrast, the N-propeptides of the pro-al(1) and pro-al(II1) chains contain 5 or more cysteines, which are likely to participate in intra- or interchain cross-linking. On the other hand, the pro- al(1I) chain has a much larger collagenous domain than do calf pro-aI(I), calf pro-a2(1), and chick pro-al(II1) chains (Fig. 5 B ) . The larger collagenous domain would be expected to form a more stable helical structure. It is of interest that in the collagenous domain of the N-propeptide of the pro- al(I1) chain, the basic Gly-X- Y repeat is interrupted once following four repeating triplets.
There is a strong homology between the amino acid se- quence of the carboxyl-terminal part of the N-propeptides of rat pro-al(II), calf pro-al(I), and chick pro-aZ(1). Particu- larly, 20 amino acids (position 93-112 in Fig. 5 B ) are com- pletely conserved in pro-al(II), pro-al(I), and pro-aZ(1) chains except for an additional glycine at position 109 in the pro-al(I1) chain. The conserved sequence in the carboxyl-
terminal noncollagenous region suggests that this region is important as the recognition site for cleavage of the procol- lagen N-propeptide by the NHn-terminal propeptidase. By analogy with other procollagens, we identify the bond between alanine (position 113) and gluatmine (position 114) as the NH2-terminal propeptidase cleavage site. Another interesting feature in this conserved region is that a tripeptide, Gly-Pro- Pro, is repeated four consecutive times (positions 93-104). It has been suggested that triple helix formation is initiated from the C-propeptide of procollagen. Because the Gly-Pro- Pro-rich region of the N-propeptide could form particularly stable helices, it may be important in initiating helix forma- tion at this end of the molecule.
In addition to its use in elucidating the protein sequence of the amino-terminal propeptide of the rat type I1 procollagen chain, p k o l 2 has been used to isolate a genomic clone containing the 5' flanking sequences of the type I1 collagen gene.2
Acknowledgments-We thank Dr. Peter Fietzek for providing us with amino acid sequences before publication, Dr. Mark Sobel for his advice and for deducing the appropriate nucleotide sequences of the synthetic probe, Drs. Marian Young and Kurt Doege for reviewing the manuscript, and Irma Burke and Sandra Ward for assistance in the preparation of this manuscript.
REFERENCES
1. Bornstein, P., and Sage, H. (1980) Annu. Biochem. 49,954-1003 2. Miller, E. J., and Gay, S. (1982) Methods Enzymol. 82,3-32 3. von der Mark, K. (1980) Curr. Top. Den Biol. 14,199-225 4. Mayne, R., Vail, M. S., and Miller, E. J. (1976) Deu. Biol. 64,
5. Mayne, R., Vail, M. S., and Miller, E. J. (1975) Proc. Natl. Acad. Sci. U. S. A. 72,4511-4515
6. Ohkubo, H., Vogeli, G., Mu*, M., Awedimento, E. V., Sullivan, M., Pastan, I., and de Crombrugghe, B. (1980) Proc. Natl. Acad. Sci. U. S. A. 77,7059-7063
7. Wozney, J., Hanahan, D., Tate, V., Boedtker, H., and Doty, P. (1981) Nature (Lord.) 294,129-135
8. Young, M. F., Vogeli, G., Nunez, A. M., Fernandez, M. P., Sullivan, M., and Sobel, E. M. (1984) Nucleic Acids Res. 12 ,
9. Ninomiya, Y., Showalter, A. M., van der Rest, M., Seidah, N. G., Chritien, M., and Olsen, B. R. (1984) Biochemistry 23, 617- 624
10. Sandell, L. J., Prentice, H. L., Kravis, D., and Upholt, W. B. (1984) J. Biol. Chem. 2 6 9 , 7826-7834
11. Smith, B. D., Martin, G. R., Miller, E. J., Dorfman, A., and Swarm, R. (1975) Arch. Biochem. Biophys. 166,181-186
12. Kimura, J. H., Hardingham, T. E., Hascall, V. C., and Solursh, M. (1979) J. Biol. Chem. 254,2600-2609
13. Sobel, M. E., Yamamoto, T., de Crombrugghe, B., and Pastan, I. (1981) Biochemistry 20,2678-2684
14. Maniatis, T., Fritsch, E. F., and Sambrook, J. (1982) Molecular Cloning. DD. 199-206. Cold Spring Harbor Laboratory, Cold
230-240
4207-4228
SpriniHkbor, NY '
Chem. 256.1023-1028
"
15. Agarwal, K. L., Brunstedt, J., and Noyes, B. E. (1981) J. Biol.
16. Nelson, T., and Brutlag, D. (1979) Methods Enzymol. 68,41-50 17. Hanahan, D. (1983) J. Mol. Bwl. 166, 557-580 18. Land, H., Greg, M., Hausen, H., Lindenmaier, W., and Schritz,
19. Hanahan, D., and Meselson, M. (1980) Gene 10,63-67 20. Wallace, R. B., Johnson, M. J., Hirose, T., Miyake, T., Kawash-
894 ima, E. H., and Itakura, K. (1981) Nucleic Acids Res. 9 , 879-
21. Goldberg, A. A. (1980) Proc. Natl. Acad. Sci. U. S. A. 7 7 , 5794- 5798
22. Adams, S. L., Sobel, M. E., Howard, B. H., Olden, K., Yamada, K. M., de Crombrugghe, B., and Pastan, I. (1977) Proc. Natl. Acad, Sci. U. S. A. 74,3399-3403
G. (1981) Nucleic Acids Res. 9,2251-2266
* K. Kohno and Y. Yamada, manuscript in preparation.

cDNA Clone to the 5' End of Rat Type II Collagen mRNA 13673
23. Maxam, A. M., and Gilbert, W. (1977) Proc. Natl. Acad. Sei. U. 30. Paglia, L. M., Wiester, M., Duchene, M., Ouellette, L. A., Horlein,
24. Yamada, Y., Madryj, M., and de Crombrugghe, B. (1983) J. Biol. D., Martin, G. R., and Muller, P. K. (1981) Biochemistry 20 ,
25. Kozak, M. (1981) Nucleic Acids Res. 9,5233-5252 31. Curran, S., and Prockop, J. D. (1982) Biochemistry 2 1 , 1482-
1487 26. Kozak, M. (1984) Nucleic Acids Res. 12,857-872 32. Tate, V. E., Finer, M. H., Boedtker, H., and Doty, P. (1983) 27. Schmidt, A., Yamada, Y., and de Cromhrugghe, B. (1984) J. Biol. Nucleic Acids Res. 11,91-104
33. Vogeli, G., Ohkubo, H., Sobel, M. E., Yamada, Y., Pastan, I., and 28. Wiestner, M., Krieg, T., Horlein, D., Glanville, R. W., Fietzek, de Crombrugghe, B. (1981) Proc. Natl. Acad. Sei. U. S. A. 7 8 ,
29. Paglia, L. M., Wilczek, J., Diaz de Leon, L., Martin, G. R., Holein, 34. Timpl, R., and Glanville, W. R. (1981) Clin. Orthp . Res.
S. A. 74,560-564 3523-3527
Chem. 258,14914-14919
Chem. 2 6 9 , 7411-7415
P., and Muller, P. K. (1979) J. Biol. Chem. 2 5 4 , 7016-7023 5334-5338
D., and Muller, P. K. (1979) Biochemistry 18,5030-5034 158,224-241














![Expression multifunctional · We report the isolation of a cDNA clone encoding a GA 20-oxidase[gibberellin, 2-oxoglutarate:oxygen oxidoreductase (20-hydroxylating, oxidizing) EC 1.14.11.-]](https://img.pdfslide.us/doc/110x75/61025b607f589d169e1821be/expression-multifunctional-we-report-the-isolation-of-a-cdna-clone-encoding-a-ga.jpg)