Embed Size (px)
Citation preview

Ischia, Italy - 9-21 July 2006 1
Session 25
Monday 17th July
Malcolm Atkinson

Ischia, Italy - 9-21 July 2006 2

Ischia, Italy - 9-21 July 2006 3
Introduction to Structured Data in GridsIntroduction to Structured Data in Grids
Reminders: Distributed Systems & Data scale
Significance of Structure
Strategies for Data Integration
Metadata Challenges
A view of OGSA-DAI

Ischia, Italy - 9-21 July 2006 4

Ischia, Italy - 9-21 July 2006 5
Foundations of CollaborationFoundations of Collaboration
• Strong commitment by individuals– To work together– To take on communication challenges– Mutual respect & mutual trust
• Distributed technology– To support information interchange– To support resource sharing– To support data integration– To support trust building
• Sufficient time• Common goals• Complementary knowledge, skills & data
Can we predictwhen it will work?Can we findremedies when itdoesn’t?

Ischia, Italy - 9-21 July 2006 6
A strategy that works wellA strategy that works well
• Collaboratively constructed
• Shared access
• Data Resources– Sequence databases– Protein structure and Crystallography databases– Sky Surveys– Census data– Zoo DB– Mouse Atlas– …
Works betterwhen linked toFunding &Publication.But fundingthe maintenance?

Ischia, Italy - 9-21 July 2006 7
Works better with an organising nucleusWorks better with an organising nucleus
• EBI
• BIRN
• GEON
• SEEK / Species 2000
• IVOA
• CaBIG
• …Helping to OrganiseGiving user supportEstablishing standardsSharing methods

Ischia, Italy - 9-21 July 2006 8
Principles of Distributed ComputingPrinciples of Distributed Computing
Issues you can’t avoid– Lack of Complete Knowledge (LOCK)– Latency– Heterogeneity– Autonomy– Unreliability– Change
A Challenging goal– balance technical feasibility– against virtual homogeneity, stability and reliability
Appropriate balance between usability and productivity
– while remaining affordable, manageable and maintainable
This is NOT easy

Ischia, Italy - 9-21 July 2006 9
Compound Causes of Data GrowthCompound Causes of Data Growth
• Faster devices• Cheaper devices• Higher-resolution
– all ~ Moore’s law
• Increased processor throughput more derived data
• Cheaper & higher-volume storage• Remote data more accessible
– Public policy to make research data available– Bandwidth increases– Latency doesn’t get less though
Growth is the cross-product>> Moore’s law & disc capacity

Ischia, Italy - 9-21 July 2006 10

Ischia, Italy - 9-21 July 2006 11
Interpretational Opportunities & ChallengesInterpretational Opportunities & Challenges
• Finding & Accessing data– Variety of mechanisms & policies
• Interpreting data– Variety of forms, value systems & ontologies
• Independent provision & ownership– Autonomous changes in availability, form, policy, …
• Processing data– Understanding how it may be related– Devising models that expose the relationships
• Presenting results– Humans need either
• Derived small volumes of statistics• Visualisations

Ischia, Italy - 9-21 July 2006 12
Interpretational Opportunities & ChallengesInterpretational Opportunities & Challenges
• Finding & Accessing data– Variety of mechanisms & policies
• Interpreting data– Variety of forms, value systems & ontologies
• Independent provision & ownership– Autonomous changes in availability, form, policy, …
• Processing data– Understanding how it may be related– Devising models that expose the relationships
• Presenting results– Humans need either
• Derived small volumes of statistics• Visualisations

Ischia, Italy - 9-21 July 2006 13
Interpretational Opportunities & ChallengesInterpretational Opportunities & Challenges
• Finding & Accessing data– Variety of mechanisms & policies
• Interpreting data– Variety of forms, value systems & ontologies
• Independent provision & ownership– Autonomous changes in availability, form, policy, …
• Processing data– Understanding how it may be related– Devising models that expose the relationships
• Presenting results– Humans need either
• Derived small volumes of statistics• Visualisations

Ischia, Italy - 9-21 July 2006 14
Data Access and Integration: motivesData Access and Integration: motives
• Key to Integration of Scientific Methods– Publication and sharing of results
• Primary data from observation, simulation & experiment
• Encourages novel uses• Allows validation of methods and derivatives• Enables discovery by combining data
independently collected
and Decisions!

Ischia, Italy - 9-21 July 2006 15
Data Access and Integration: motivesData Access and Integration: motives
• Key to Large-scale Collaboration– Economies: data production, publication
& management• Sharing cost of storage, management and curation• Many researchers contributing increments of data• Pooling annotation rapid incremental publication • And criticism
– Accommodates global distribution• Data & code travel faster and more cheaply
– Accommodates temporal distribution• Researchers assemble data• Later (other) researchers access data
ResponsibilityOwnershipCreditCitation
?

Ischia, Italy - 9-21 July 2006 16
Data Access and Integration: challengesData Access and Integration: challenges
• Scale– Many sites, large collections, many uses
• Longevity– Research requirements outlive technical decisions
• Diversity– No “one size fits all” solutions will work– Primary Data, Data Products, Meta Data,
Administrative data, …
• Many Data Resources– Independently owned & managed
• No common goals• No common design• Work hard for agreements on foundation types and
ontologies• Autonomous decisions change data, structure, policy, …
– Geographically distributed
Petabyte of Digital Data / Hospital / Year

Ischia, Italy - 9-21 July 2006 17
Data Integration: Scientific discoveryData Integration: Scientific discovery
• Choosing data sources– How do you find them?– How do they describe and advertise them?– Is the equivalent of Google possible?
• Obtaining access to that data– Overcoming administrative barriers– Overcoming technical barriers
• Understanding that data– The parts you care about for your research
• Extracting nuggets from multiple sources– Pieces of your jigsaw puzzle
• Combing them using sophisticated models– The picture of reality in your head
• Analysis on scales required by statistics– Coupling data access with computation
• Repeated Processes– Examining variations, covering a set of candidates– Monitoring the emerging details– Coupling with scientific workflows
You’re an innovator
Your model their model
Negotiation & patienceneeded from both sides

Ischia, Italy - 9-21 July 2006 18
Scientific Data: Opportunities & ChallengesScientific Data: Opportunities & Challenges
• Opportunities– Global Production of
Published Data– Volume Diversity– Combination
Analysis Discovery
• Challenges– Data Huggers– Meagre metadata– Ease of Use– Optimised integration– Dependability
OpportunitiesSpecialised IndexingNew Data OrganisationNew AlgorithmsVaried ReplicationShared AnnotationIntensive Data & Computation
ChallengesFundamental PrinciplesApproximate MatchingMulti-scale optimisationAutonomous ChangeLegacy structuresScale and LongevityPrivacy and MobilitySustained Support / Funding

Ischia, Italy - 9-21 July 2006 19
Requirements: User’s viewpointRequirements: User’s viewpoint
• Find Data– Registries & Human communication
• Understand data– Metadata description, Standard / familiar formats &
representations, Standard value systems & ontologies
• Data Access– Find how to interact with data resource– Obtain permission (authority)– Make connection– Make selection
• Move Data– In bulk or streamed (in increments)

Ischia, Italy - 9-21 July 2006 20
Requirements: User’s viewpoint 2Requirements: User’s viewpoint 2
• Transform Data– To format, organisation & representation
required for computation or integration
• Combine data– Standard DB operations + operations relevant to
the application model
• Present results– To humans: data movement + transform for viewing– To application code: data movement + transform to the
required format– To standard analysis tools, e.g. R– To standard visualisation tools, e.g. Spotfire

Ischia, Italy - 9-21 July 2006 21
Requirements: Owner’s viewpointRequirements: Owner’s viewpoint
• Create Data– Automated generation, Accession Policies, Metadata
generation– Storage Resources: SRM, SRB, …
• Preserve Data– Archiving– Replication– Metadata– Protection
• Provide Services with available resources– Definition & implementation: costs & stability– Resources: storage, compute & bandwidth

Ischia, Italy - 9-21 July 2006 22
Requirements: Owner’s viewpoint 2Requirements: Owner’s viewpoint 2
• Protect Services– Authentication, Authorisation, Accounting, Audit– Reputation
• Protect data– Comply with owner requirements – encryption for privacy,
…
• Monitor and Control use– Detect and handle failures, attacks, misbehaving users– Plan for future loads and services
• Establish case for Continuation– Usage statistics– Discoveries enabled

Ischia, Italy - 9-21 July 2006 23

Ischia, Italy - 9-21 July 2006 24
Why structure dataWhy structure data
• It always is structured• Without structure it is just a bag of bits
– Is the next 32 bits• An integer• Two integers• Part of a double• 4 characters• 2 characters in Ucode• …
• Is this a 1D, 2D or 3D array?– How big is it?
• Where is the UUID?
Of course the Author of the ApplicationKnows this

Ischia, Italy - 9-21 July 2006 25
More interesting questionsMore interesting questions
• How do you discover the structure?– If the application developer isn’t available– They are virtually never available– There were lots of them who made changes
• Perhaps a community has defined the structure– Then communicated it among themselves– How do you find that community

Ischia, Italy - 9-21 July 2006 26
More interesting questions 2More interesting questions 2
• Perhaps structure description written with the data– Binary data at start of file(s)– Binary data in another file
• How do you know the relationship between the files
– Binary data among the other data• How do you find it
• How do you find these binary structure descriptions?
• How do you interpret them?

Ischia, Italy - 9-21 July 2006 27
Structure Described textuallyStructure Described textually
• Binary data is efficient– TRY Separate textual description– E.g. MIME types– Bespoke structural description language
• Product specific• Computing language specific• Application community specific
– Attempt a standard data structure description language• E.g. GGF DFDL
– Still have to discover which description applies to which data• A binding problem
– Still have to understand the names & interpretation• E.g. a field described “Distance IEE64bitFloat”• Which distance?• What units?• When measured?
Data interpretation problem

Ischia, Italy - 9-21 July 2006 28
Textual data is easy to useTextual data is easy to use
• Humans can read & write it– Though there is a limit as to how much!
• Humans can edit it– Though they make errors & break structure
• It allows structural flexibility & extension• The structure may be implicit
– E.g. a standard natural language text– A popular format maintained by user discipline– A format maintained by tools
• E.g. mail message headers
– That then make the structure explicit & maintained

Ischia, Italy - 9-21 July 2006 29
Structured textual dataStructured textual data
• Semistructured data– May use layout and tags to code structure
• E.g. field-name text newline• E.g. column names, newline, comma-separated values, newline,
…• E.g. XML tag pairs
– Structure may be more or less consistently• This may be improved with a schema• AND schema checking• E.g. XML schema, e.g. XSD• Another binding problem – which schema controls which
document?– May be some implicit rules
• E.g. XML tag pairing– Structure may be partially inferred
• E.g. recognise integers• With textual exceptions, e.g. “not yet known”
Data interpretation problem

Ischia, Italy - 9-21 July 2006 30
Databases provide Databases provide somesome structure structure
• Manage data• Manage description of structure
– Schema (logical and physical metadata)• Constraints• Authorisation rules
• Manage storage– Often efficient layout & binary / compressed
• Manage Privacy– E.g. guarantee encryption
• Provide operations– Queries, updates, bulk loads, rule checks, stored
procedures
Reduces inconsistencydoesn’t eliminate it
Interpretation challenges remain

Ischia, Italy - 9-21 July 2006 31
Exploit structureExploit structure
• Go directly to parts of data• Extract relevant parts
– Transform during this process
• Generate descriptions of data structure• Store bindings between
– Structure description and data
• Transfer smaller volumes of data• Compress exploiting structure• Aids to interpretation
– Require a structural foundation

Ischia, Italy - 9-21 July 2006 32

Ischia, Italy - 9-21 July 2006 33
Basic Strategies for UsersBasic Strategies for Users
• Use a Service provided by a Data Owner
• Use a self-administered workflow
• Use a scripted workflow
• Use data virtualisation services

Ischia, Italy - 9-21 July 2006 34
Basic Strategies for UsersBasic Strategies for Users
• Use a Service provided by a Data Owner– Easiest as pre-packaged
• Web-based form interfaces• E.g. for BLAST jobs at EBI
– Now may be provided as Web Services• Accessed by client portal• E.g. Initiating BLAST runs in BRIDGES project
– No multi-source data integration• Unless provided by Data Owner• Opportunity for discovery restricted to that data
• Use a self-administered workflow• Use a scripted workflow• Use data virtualisation services

Ischia, Italy - 9-21 July 2006 35
Basic Strategies for UsersBasic Strategies for Users
• Use a Service provided by a Data Owner
• Use a self-administered workflow– Use a sequence of Services– Plus own data– Organise each step– Collect and manage intermediate results– Organise integration processes manually– Common strategy
• Very laborious• Error prone• Tedious repetition• Hard to provide to other researchers
• Use a scripted workflow• Use data virtualisation services
e.g. one projectin Glasgow, studyinggenetics of a form of myelitis: 2000 subjects,6-monthly samplesrework functional genetics & searchesFor each candidate gene

Ischia, Italy - 9-21 July 2006 36
Basic Strategies for UsersBasic Strategies for Users
• Use a Service provided by a Data Owner• Use a self-administered workflow• Use a scripted workflow
– Describe the steps in a Scripting Language– Steps performed by Workflow Enactment Engine– Many languages in use
• Trade off: familiarity & availability• Trade off: detailed control versus abstraction
– Incrementally develop correct process• Sharable & Editable• Basis for scientific communication & validation• Valuable IPR asset
– Repetition is now easy• Parameterised explicitly & implicitly
• Use data virtualisation services
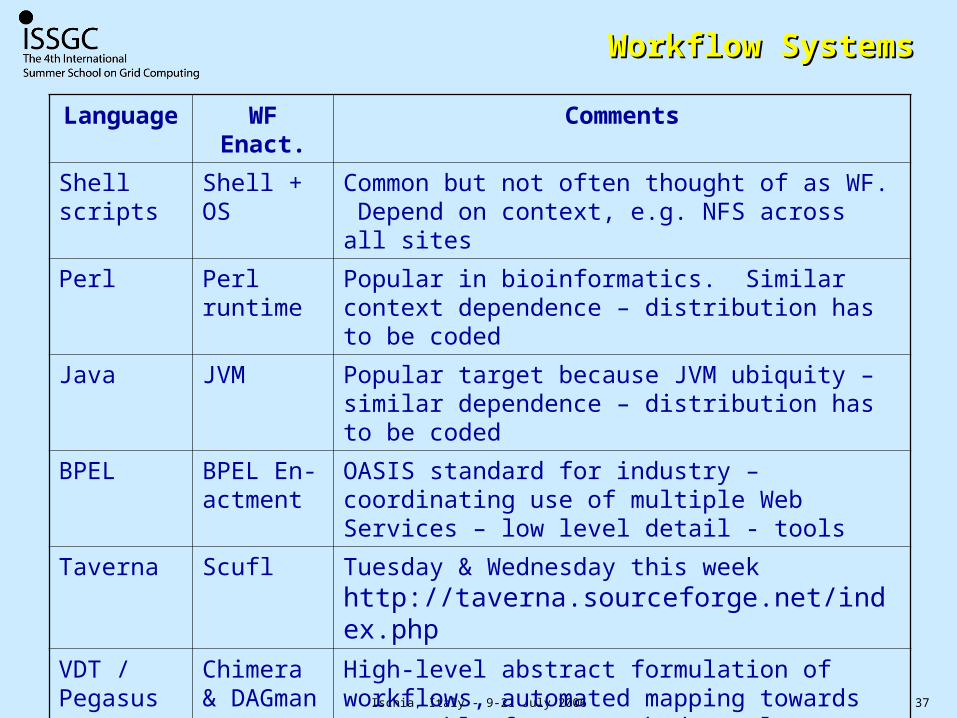
Ischia, Italy - 9-21 July 2006 37
Workflow SystemsWorkflow Systems
Language WF Enact. Comments
Shell scripts
Shell + OS Common but not often thought of as WF. Depend on context, e.g. NFS across all sites
Perl Perl runtime
Popular in bioinformatics. Similar context dependence – distribution has to be coded
Java JVM Popular target because JVM ubiquity – similar dependence – distribution has to be coded
BPEL BPEL En-actment
OASIS standard for industry – coordinating use of multiple Web Services – low level detail - tools
Taverna Scufl Tuesday & Wednesday this week http://taverna.sourceforge.net/index.php
VDT / Pegasus
Chimera & DAGman
High-level abstract formulation of workflows, automated mapping towards executable forms, cached result re-use
Kepler Kepler Tuesday & Wednesday this week
http://kepler-project.org/

38Example Grid3 Application:NVO Mosaic Construction
NVO/NASA Montage: A small (1200 node) workflow
Construct custom mosaics on demand from multiple data sources
User specifies projection, coordinates, size, rotation, spatial sampling
Work by Ewa Deelman et al., USC/ISI and Caltech

39
Basic Strategies for Users Use a Service provided by a Data Owner Use a self-administered workflow Use a scripted workflow Use data virtualisation services
Form a federation Set of data resources – incremental addition Registration & description of collected resources Warehouse data or access dynamically to obtain updated data Virtual data warehouses – automating division between collection and
dynamic access Describe relevant relationships between data sources
Incremental description + refinement / correction Run jobs, queries & workflows against combined set of data
resources Automated distribution & transformation
Example systems IBM’s Information Integrator GEON, BIRN & SEEK OGSA-DAI is an extensible framework for building such systems

Ischia, Italy - 9-21 July 2006 40
Basic Strategies for UsersBasic Strategies for Users
• Use a Service provided by a Data Owner• Use a self-administered workflow
• Use a scripted workflow• Use data virtualisation services
– Arrange that multiple data services have common properties
– Arrange federations of these– Arrange access presenting the common properties– Expose the important differences– Support integration accommodating those differences

Ischia, Italy - 9-21 July 2006 41
Virtualisation variationsVirtualisation variations
• Extent to which homogeneity obtained– Regular representation choices – e.g. units– Consistent ontologies– Consistent data model– Consistent schema – integrated super-schema– DB operations supported across federation– Ease of adding federation elements– Ease of accommodating change as federation
members change their schema and policies– Drill through to primary forms supported

Ischia, Italy - 9-21 July 2006 42

Ischia, Italy - 9-21 July 2006 43
Metadata DefinitionMetadata Definition
• Metadata is data that describes other data– Any property of the other data
• Structure• Physical organisation• Usage and storage policies• Destruction policies• Privacy and legal constraints• Provenance• Aids to interpretation• Known uses and users• …
One person’s metadata can be another person’s data

Ischia, Italy - 9-21 July 2006 44
Challenges for metadataChallenges for metadata
• All the challenges of Data– E.g. authorisation, privacy, dependable storage, …– Managing changes, quality, …
• The binding between Data & Metadata– What metadata describes this data?– What data does this metadata describe?
• Specific data• All the data about a particular topic• All the data that will be produced in a particular way
• Good abstractions for using data & metadata together
• Good mechanisms for generating metadata– Automation & incentives

Ischia, Italy - 9-21 July 2006 45
Metadata modes of use: creationMetadata modes of use: creation
• Generate Metadata– Then generate and store data that complies
• Generate Metadata & Data– At the same time– “Atomic” operation
• Have already a collection of data– And some metadata, e.g. structural– Mine or generate further information about the data– Store that as additional metadata
• Note constructing bindings in each case– Must maintain stable and accurate bindings

Ischia, Italy - 9-21 July 2006 46
Modes of using metadataModes of using metadata
• Query or search metadata– Use this to find specific parts
• Browse metadata (after query)– To understand data– To consider exploitation strategies
• Create indexes– Use these to accelerate algorithms– This should be done more often!
• Applications & tools read metadata– Use it to drive selections, mappings, presentations
• E.g. use it to generate detailed workflows from abstract workflows• E.g. construct wrappers and data transformers

Ischia, Italy - 9-21 July 2006 47
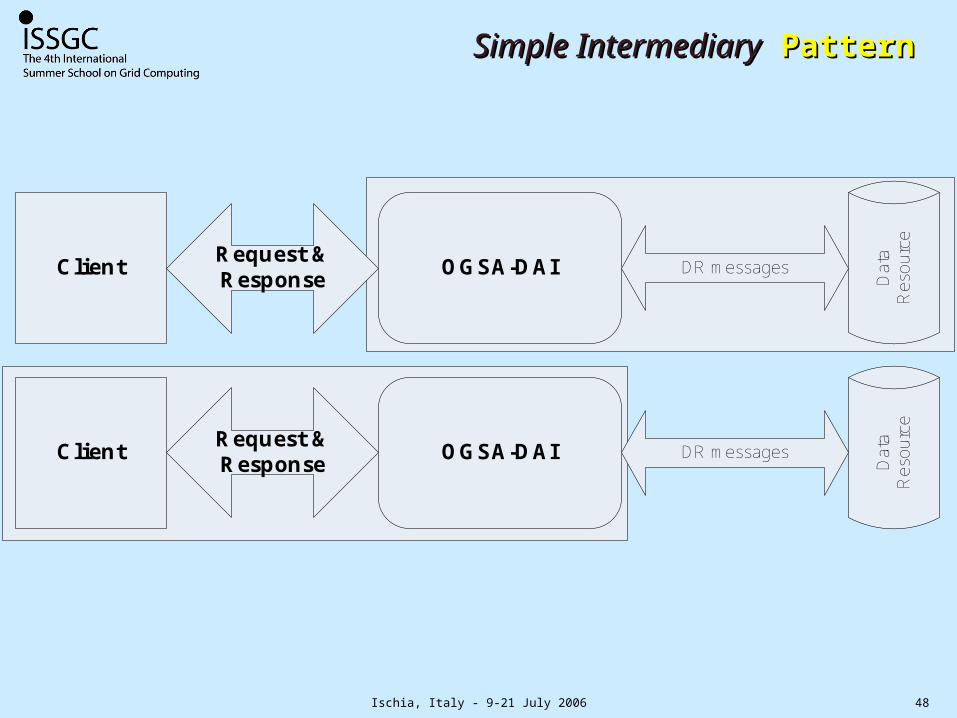
Ischia, Italy - 9-21 July 2006 48
Simple IntermediarySimple Intermediary Pattern Pattern
Client OGSA-DAIRequest & Response D
ata
Res
ourc
e
DR messages
Client OGSA-DAIRequest & Response D
ata
Res
ourc
e
DR messages
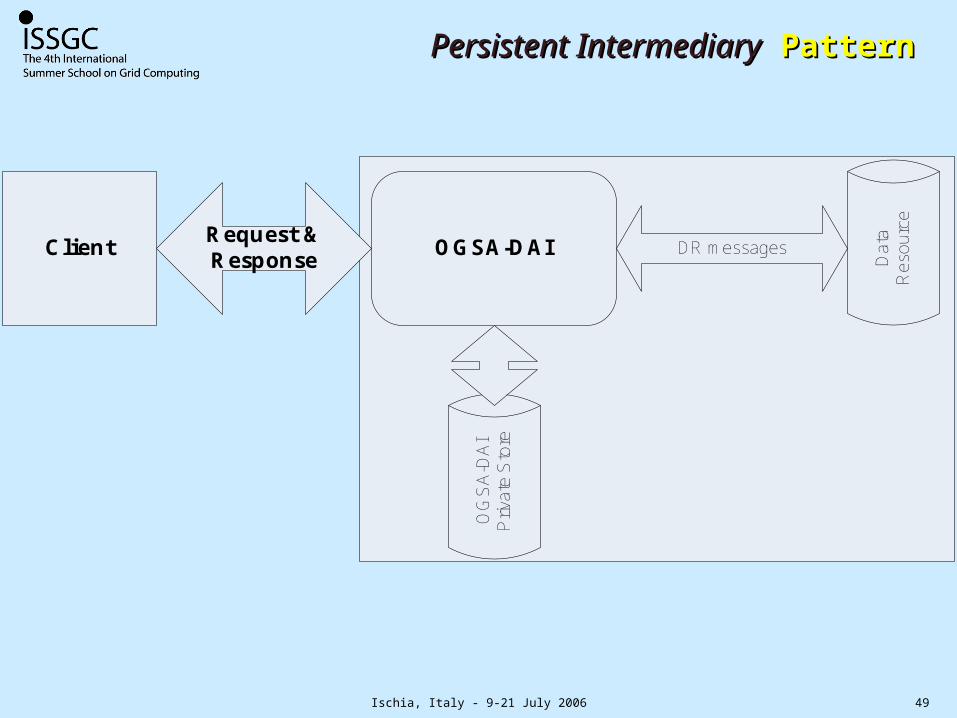
Ischia, Italy - 9-21 July 2006 49
Persistent IntermediaryPersistent Intermediary Pattern Pattern
Client OGSA-DAIRequest & Response D
ata
Res
ourc
e
DR messages
OG
SA
-DA
IP
rivat
e S
tore
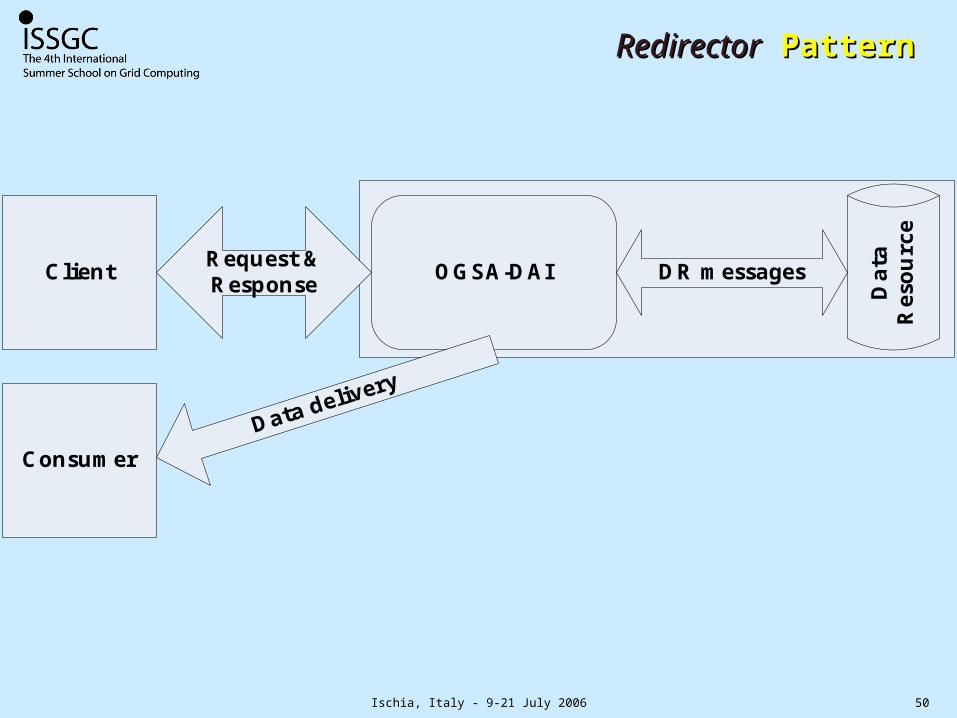
Ischia, Italy - 9-21 July 2006 50
RedirectorRedirector Pattern Pattern
Client OGSA-DAIRequest & Response D
ata
Res
ourc
e
DR messages
Consumer
Data delivery

Ischia, Italy - 9-21 July 2006 51
RedirectorRedirector: OGSA-DAI as the consumer: OGSA-DAI as the consumer
consumer
Data
Res
ourc
e
DR messages
Client OGSA-DAIRequest & Response D
ata
Res
ourc
e
DR messages
Data
del
iver
yOGSA-DAI
Request & Response
Ischia, Italy - 9-21 July 2006 52
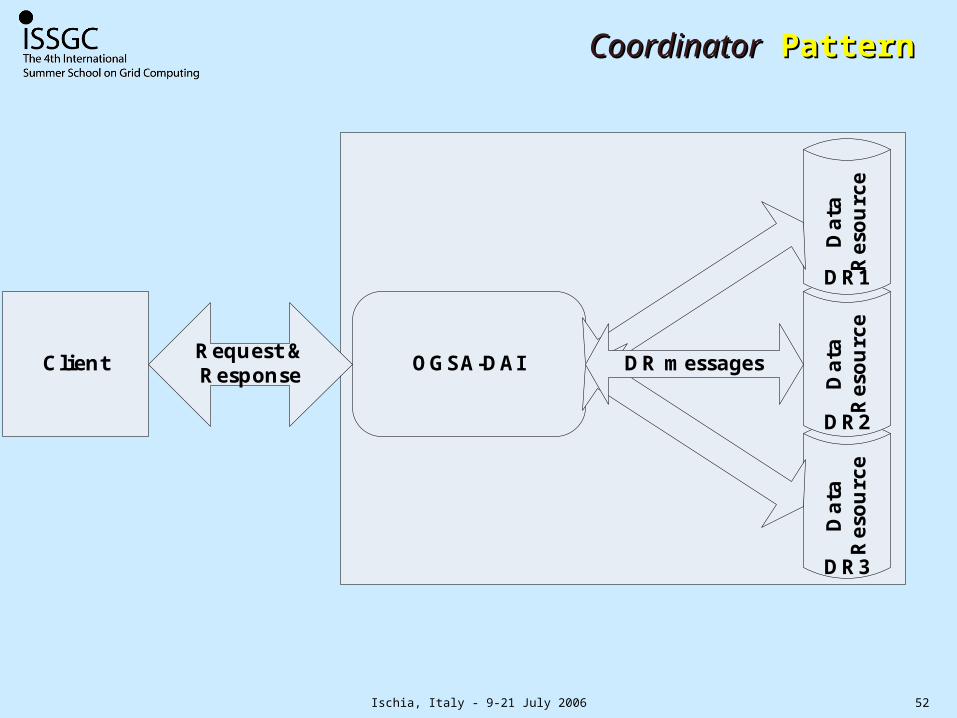
CoordinatorCoordinator Pattern Pattern
Data
Res
ourc
e
Client OGSA-DAIRequest & Response D
ata
Res
ourc
eD
ata
Res
ourc
e
DR messages
DR1
DR2
DR3
Ischia, Italy - 9-21 July 2006 53
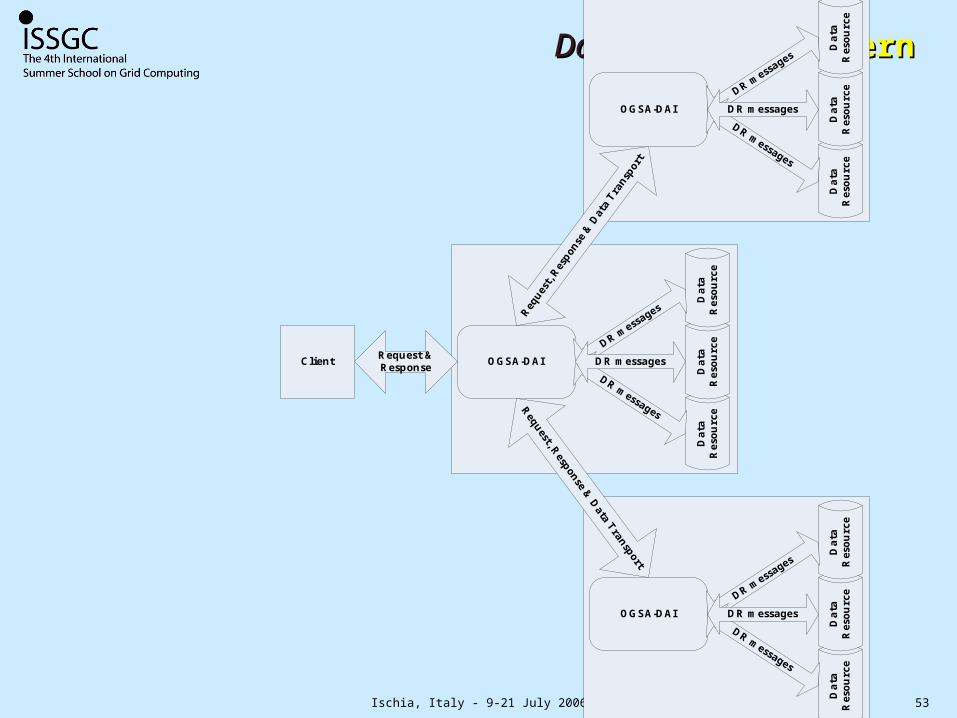
Data AssemblyData Assembly Pattern Pattern
Client
DR1
DR2
DR3
Data
Res
ourc
e
OGSA-DAI
Data
Res
ourc
eD
ata
Res
ourc
e
DR mes
sage
s
DR messages
DR messages
Data
Res
ourc
e
OGSA-DAI
Data
Res
ourc
eD
ata
Res
ourc
e
DR mes
sage
s
DR messages
DR messages
Data
Res
ourc
e
OGSA-DAI
Data
Res
ourc
eD
ata
Res
ourc
e
DR mes
sage
s
DR messages
DR messages
Request, R
esponse & D
ata Transport
Req
uest
, Res
pons
e & D
ata
Tran
spor
t
Request & Response
Ischia, Italy - 9-21 July 2006 54
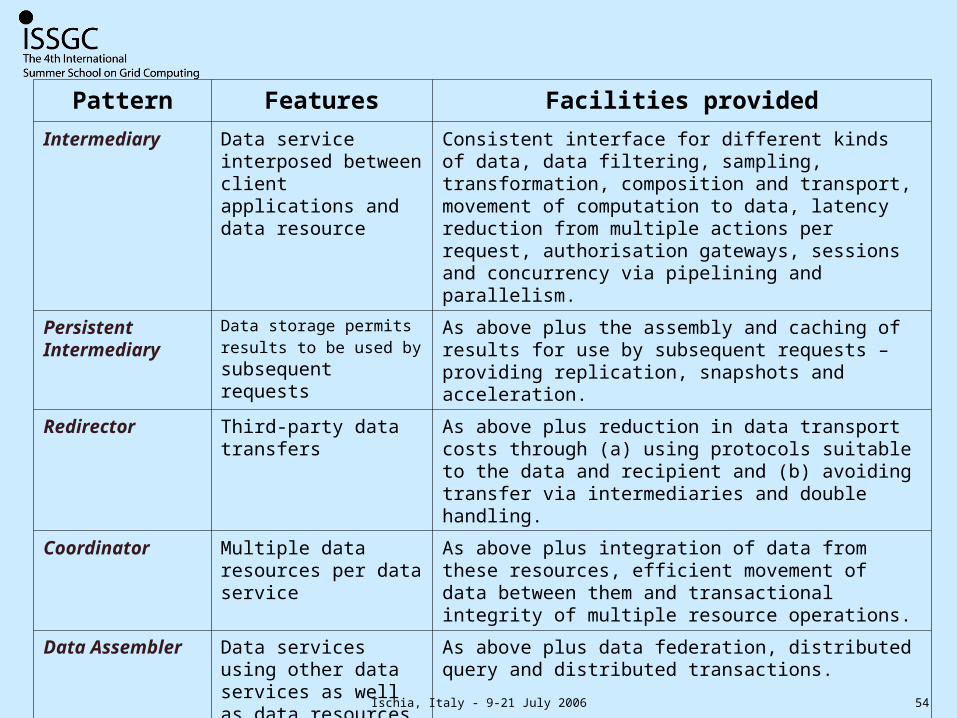
Pattern Features Facilities providedIntermediary Data service
interposed between client applications and data resource
Consistent interface for different kinds of data, data filtering, sampling, transformation, composition and transport, movement of computation to data, latency reduction from multiple actions per request, authorisation gateways, sessions and concurrency via pipelining and parallelism.
Persistent Intermediary
Data storage permits results to be used by subsequent requests
As above plus the assembly and caching of results for use by subsequent requests – providing replication, snapshots and acceleration.
Redirector Third-party data transfers
As above plus reduction in data transport costs through (a) using protocols suitable to the data and recipient and (b) avoiding transfer via intermediaries and double handling.
Coordinator Multiple data resources per data service
As above plus integration of data from these resources, efficient movement of data between them and transactional integrity of multiple resource operations.
Data Assembler
Data services using other data services as well as data resources
As above plus data federation, distributed query and distributed transactions.
Ischia, Italy - 9-21 July 2006 55
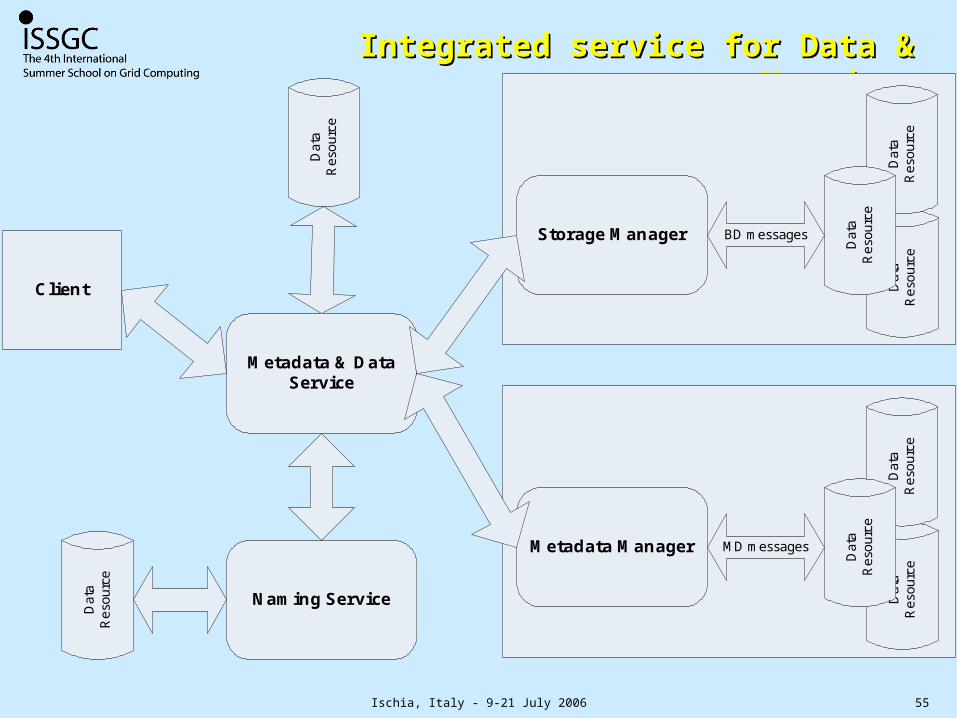
Integrated service for Data & MetadataIntegrated service for Data & Metadata
Dat
aR
esou
rce
Dat
aR
esou
rce
Storage Manager
Dat
aR
esou
rce
BD messages
Dat
aR
esou
rce
Dat
aR
esou
rce
Metadata Manager
Dat
aR
esou
rce
MD messages
Naming Service
Metadata & Data Service
Client
Dat
aR
esou
rce
Dat
aR
esou
rce

Ischia, Italy - 9-21 July 2006 56
?Picture
compositionby
Luke Humphrybased on prior
art





























