Embed Size (px)
Citation preview

LLNL-PRES-689302 This work was performed under the auspices of the U.S. Department of Energy by Lawrence Livermore National Laboratory under contract DE-AC52-07NA27344. Lawrence Livermore National Security, LLC
Investigation of Portable Event-Based Monte Carlo TransportCOEPhoenix,AZ
RyanBleileLawrenceLivermoreNa;onalLaboratory
UniversityofOregon,Eugene
April 20, 2016

LLNL-PRES-689302 2
Current Landscape of Architectures
– GPU (NVIDIA) • Sub-architectures :
– Fermi, Kepler, Maxwell • Multiple Memory Types:
– Global, shared, constant, texture
• Memory Amount: – Up to 12 GB
• 1000s of threads – Grids, blocks, and
warps
– CPU/MIC • Multiple ISAs:
– Vector Unit Widths: » 2,4,8 / 16
• Single Memory Type – Shared/private caches
• Larger Memory Size (CPU) • Up to 20/60 threads
– No explicit organization
*Slide courtesy of Matthew Larsen University of Oregon, CDUX research group

LLNL-PRES-689302 3
TheProblem
• Forces developers to either: – Pick a target architecture – Add additional implementations of the same
algorithm:
A B C D E F Algorithm
Architecture
*Slide courtesy of Matthew Larsen University of Oregon, CDUX research group

LLNL-PRES-689302 4
Data-ParallelPrimi0vesLibraries
A B C D E F Algorithm
Backend
Data Parallel Framework
§ Backend–Implementfastparallelprimi;veoperatorsforeachnewarchitecture
§ Frontend–Re-thinkcurrentalgorithmsintermsoftheprimi;ves
*Slide courtesy of Matthew Larsen University of Oregon, CDUX research group

LLNL-PRES-689302 5
DataParallelPrimi0ves(DPP)
§ Whatarethey?— Providealevelofabstrac;onbasedonBlelloch’sparallelprimi;ve
operators— Providesnodelevelparallelism
§ Bigchallenge— “re-thinking”algorithmstouseDPP— Not“por;ng”algorithmstoDPP
§ Benefits— Portableperformance— Futureproofimplementa;ons
§ WhatisaDPP— IfitcanbecompletedinO(logN)whereNisthearraysizethanitcanbea
DPP
5
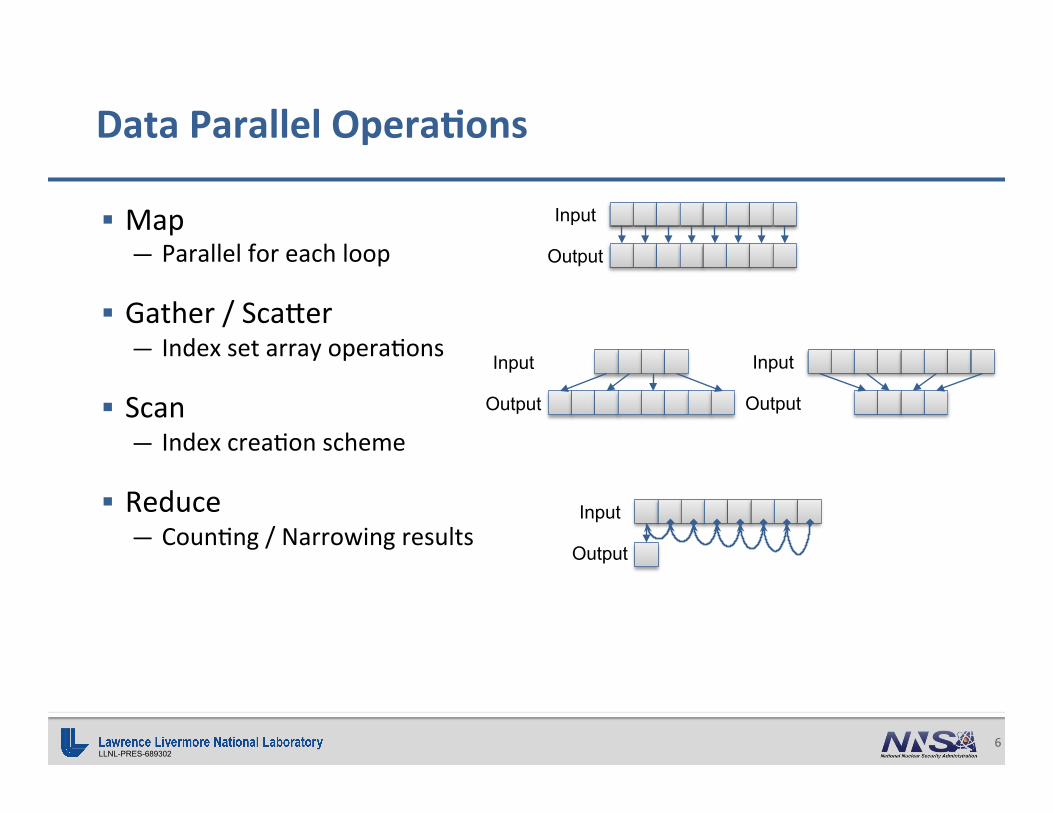
LLNL-PRES-689302 6
§ Map— Parallelforeachloop
§ Gather/Sca^er— Indexsetarrayopera;ons
§ Scan— Indexcrea;onscheme
§ Reduce— Coun;ng/Narrowingresults
DataParallelOpera0ons
Input
Output
Input
Output
Input
Output
Input
Output

LLNL-PRES-689302 7
§ PreviousworkdoneinresearchgroupatUO— RayTracing
• Promisingresults• UsingVTK-m,EAVL,etc…
§ ApplyingthistechniquetoMonteCarloTransport— Manypossibleavenuestoconsider
• Thrust– supportsdataparallelopera;ons
• RAJAstyle– Supportssimplifyingkeyideaswithatemplate/MACROdefini;on
PortablePerformance–Abstrac0onLayer

LLNL-PRES-689302 8
§ Modelspar;cletransportina1Dbinarystochas;cmedium
§ Par;clesarecreatedandthentrackedthroughaseriesofevents
§ Talliesofmul;pletypesareincremented— SingleValue:Reflec;on,Transmission— Mul;Value(permaterial):Absorp;on,Sca^er— ManyValue(perzone):ZonalFlux
§ Legacyapproach(history-based)didnotlenditselftomany-core
§ Recentworktakesanewapproach(event-based)thatissuitableformany-coresystems(Inves;ga;onofPortableEvent-BasedMonteCarloTransportUsingtheNVIDIAThrustLibrary.inpress.)
MonteCarloTransport–ALPS_MC

LLNL-PRES-689302 9
§ Determineabatchsize— Howmanypar;clesfitinGPUmemory
§ Foragivenbatch— Generateallpar;clesinbatch— Whileanypar;cleslemtocompute
• ForeacheventX– Getpar;cleswhosenexteventisX– DoeventXandcomputetheirnextevent
• Deletekilledpar;cles
§ 3eventstracked— Collision— Materialinterfacecrossing— Zonalboundarycrossing
§ Excludedzonalfluxtallyasfutureworktostudyitseffect
Eventbasedalgorithm-overview

LLNL-PRES-689302 10
§ Par;cleclasscontainsmanyvariables— (3ints,1Long,6doubles)— Realcasescenarioscontainevenlargerclasses
§ Notallvariablesusedineachkernel— Reducesizeofmemoryreadsandwrites
§ CoalescedmemoryaccesswithSOA
§ Reducedmemoryusageinkernel
AOSandSOAPar0cleDataStructure

LLNL-PRES-689302 11
§ Reorganizingpar;clesiscostly— Morecostlythenallcomputekernelscombined
§ Onlycallremovefunc;onwhenitmakesanimpacqulchangetoarraysize
§ Ifnumbertokill>=par;cles_remaining.size()/2;— Decreasesamountof;mespentremovingpar;cles— Increaseamountof;meneededtoestablishcomputekernels
NewPar0cleRemovalScheme

LLNL-PRES-689302 12
§ ExplicitlymanagedGPUmemory(cudaMalloc,etc.)
§ ModifiedCUDAversionfirst— MadenewThrust,RAJAmethodsfromop;mizedCUDAmethod
§ Changedpar;cledatastructuretoallowSOAorAOS
§ Kernelsread/writestrategychangedtoensure-read,compute,writepa^ernupheld
§ Newpar;cleremovalscheme
DetailsofImplementa0on
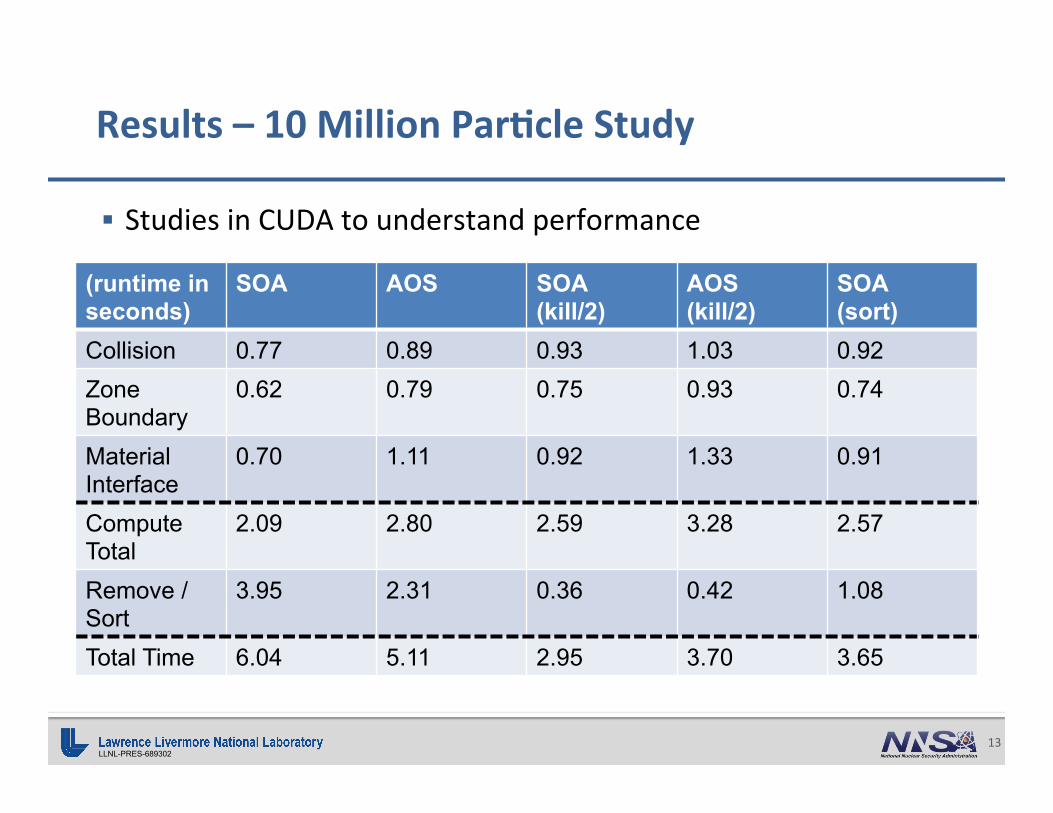
LLNL-PRES-689302 13
§ StudiesinCUDAtounderstandperformance
Results–10MillionPar0cleStudy
(runtime in seconds)
SOA AOS SOA (kill/2)
AOS (kill/2)
SOA (sort)
Collision 0.77 0.89 0.93 1.03 0.92 Zone Boundary
0.62 0.79 0.75 0.93 0.74
Material Interface
0.70 1.11 0.92 1.33 0.91
Compute Total
2.09 2.80 2.59 3.28 2.57
Remove / Sort
3.95 2.31 0.36 0.42 1.08
Total Time 6.04 5.11 2.95 3.70 3.65
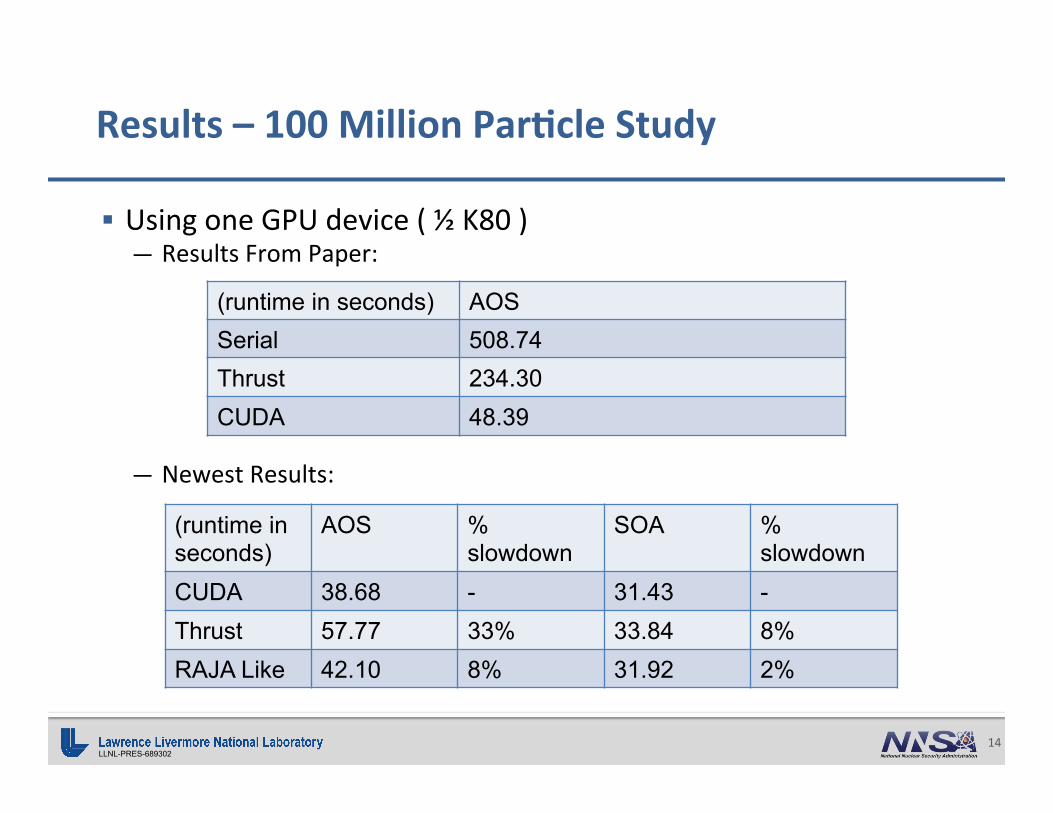
LLNL-PRES-689302 14
§ UsingoneGPUdevice(½K80)— ResultsFromPaper:
— NewestResults:
Results–100MillionPar0cleStudy
(runtime in seconds) AOS Serial 508.74 Thrust 234.30 CUDA 48.39
(runtime in seconds)
AOS % slowdown
SOA % slowdown
CUDA 38.68 - 31.43 - Thrust 57.77 33% 33.84 8% RAJA Like 42.10 8% 31.92 2%

LLNL-PRES-689302 15
§ Spending;metomaketheSOAchangesanddirectlymanagingCUDAmemorypaidoffinperformanceforallversions
§ Star;ngwithCUDA,backingoutanabstrac;onlayerwassimple
§ Ini;alpassabstrac;onlayera^emptsufferedsignificantperformancedegrada;on— Lessonslearnednowcanpayoffdownthelineinfuturea^emptsat
star;ngwithanabstrac;onlayer
§ DPPportableperformanceapproachpromisingforeventbasedMonteCarlotransport
Conclusion

LLNL-PRES-689302 16
§ ThisworkwasperformedundertheauspicesoftheU.S.DepartmentofEnergybyLawrenceLivermoreNa;onalLaboratoryunderContractDE-AC52-07NA27344.
§ FundingforthisworkwasprovidedbytheLLNLLivermoreGraduateScholarProgram.
§ ResearchadvisorsPatrickBrantley(LLNL),HankChilds(UO),Ma^O’Brien(LLNL).
Acknowledgements

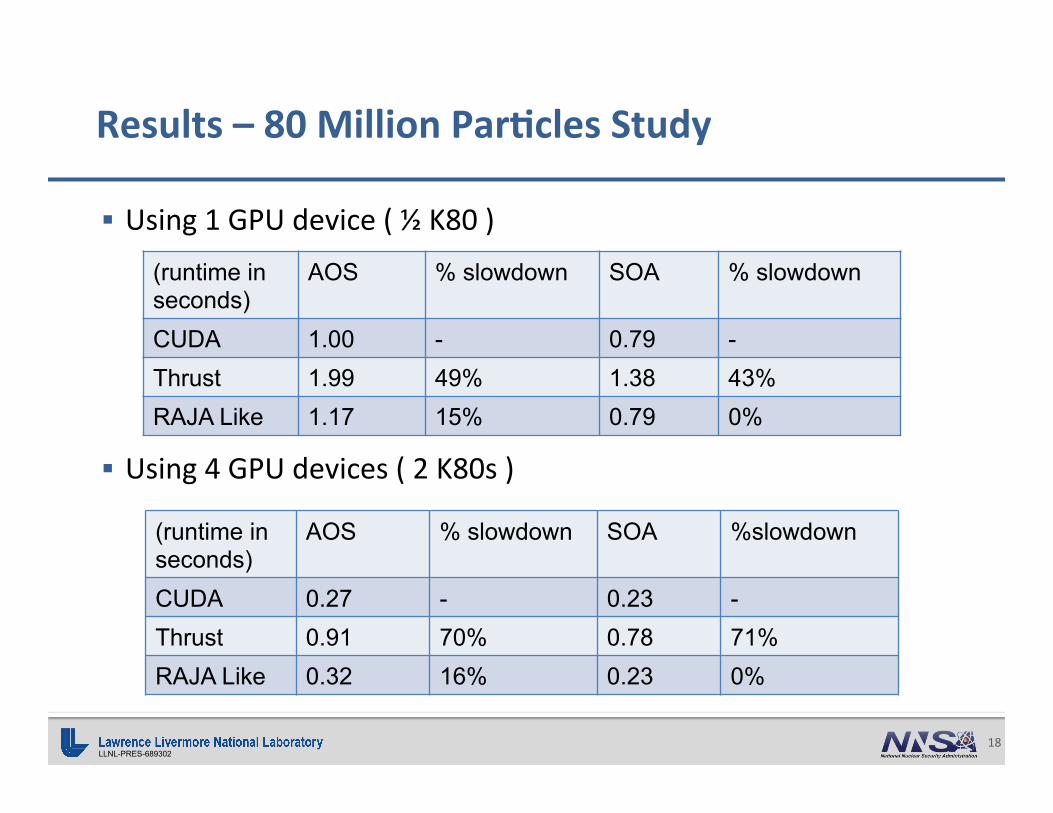
LLNL-PRES-689302 18
§ Using1GPUdevice(½K80)
§ Using4GPUdevices(2K80s)
Results–80MillionPar0clesStudy
(runtime in seconds)
AOS % slowdown SOA % slowdown
CUDA 1.00 - 0.79 - Thrust 1.99 49% 1.38 43% RAJA Like 1.17 15% 0.79 0%
(runtime in seconds)
AOS % slowdown SOA %slowdown
CUDA 0.27 - 0.23 - Thrust 0.91 70% 0.78 71% RAJA Like 0.32 16% 0.23 0%
LLNL-PRES-689302 19
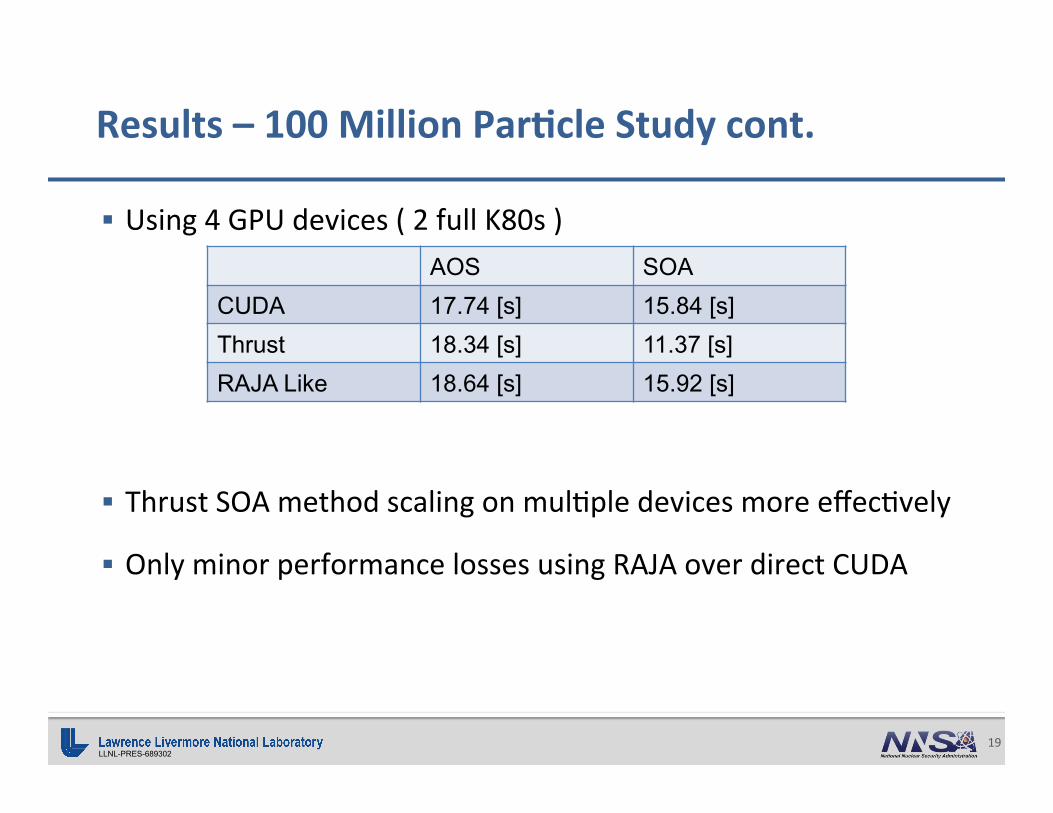
§ Using4GPUdevices(2fullK80s)
§ ThrustSOAmethodscalingonmul;pledevicesmoreeffec;vely
§ OnlyminorperformancelossesusingRAJAoverdirectCUDA
Results–100MillionPar0cleStudycont.
AOS SOA CUDA 17.74 [s] 15.84 [s] Thrust 18.34 [s] 11.37 [s] RAJA Like 18.64 [s] 15.92 [s]

LLNL-PRES-689302 20
§ 100MillionPar;cleStudy–DoneonCPU— [ SOA AOS ]— Thrust: XXX.XX XXX.XX— RAJAlike: XXX.XX XXX.XX— ThrustHistory: XXX.XX — OMPHistory: XXX.XX
§ CommentonOMPresults
§ CommentonPortabilityofeventversushistory
[resultsnotyetdetermined]
Results–CPUPortability





























