Embed Size (px)
Citation preview

Introducción a Gestión y Monitoreo de Redes
Network Startup Resource Centerwww.nsrc.org
Estos materiales están bajo la Licencia Creative Commons Atribución-No comercial 4.0 Licencia internacional (https://creativecommons.org/licenses/by-nc/4.0/deed.es_ES)
Last updated 18th October 2016

Objetivos
Presentar Conceptos Fundamentales y Terminología
• Gestión y Monitoreo de Redes• Qué y por qué monitoreamos • Expectativas de tiempo disponible y cálculos • Rendimiento típico & detección de ataques• Qué y por qué gestionamos• Herramientas para gestionar y monitorear redes• El “NOC”: consolidando sistemas

NOC: Consolidando Sistemas
NOC = Centro de Operaciones de Red
• Coordinación de tareas, manejo de incidentes (sistema de tickets)
• Estado de la red y servicios (herramientas de monitoreo)
• Donde se acceden las herramientas de gestión y monitoreo
• Almacén de documentación (wiki, base de datos, repositorios Herramientas de documentación)

NOC: Consolidando Sistemas
Ubicación del NOC
• NOC es un concepto lógico organizacional • No tiene que ser un lugar, o un servidor específico• Un NOC remoto/distribuido es posible cuando
usamos conexiones fuera de banda (OOB)

Ejemplos de NOCs

Gestión y Monitoreo de Redes
Monitoreo• Comprobar el estado de una red
Gestión
• Los procesos para operar con éxito una red

Monitoreo de Sistemas y Servicios
Sistemas Enrutadores Switches Servidores
Servicios DNS HTTP SMTP SNMP, etc.

Por qué monitoreamos?
• Podemos llegar a los sistemas y servicios?• Están disponibles?• Cuántos recursos utilizan?• Cuál es su rendimiento?
- Tiempos de ida y vuelta, rendimiento de la red?
- Fallas y cortes• Que ha sido configurado o cambiado?• Están siendo atacados?

Por qué monitoreamos?
• Para saber cuando hay problemas – antes que nuestros clientes!
• Supervisar la utilización de recursos y facturar a clientes
• Proveer el nivel de servicio acordado (SLAs)- Expectativas de nuestra gerencia?- Expectativas de los clientes?- Expectativas del resto de Internet?

Por qué monitoreamos?
• Para demostrar que se provee el nivel de servicio prometido - ¿Hemos logrado “cinco nueves”? 99.999%?
• Asegurar que cumplimos con las expectativas (SLAs) en el futuro- Está a punto de fallar nuestra red?- Estará congestionada la red?

Expectativas de Disponibilidad
• ¿Qué se necesita para dar el 99.9% de tiempo de disponibilidad del servicio? - Sólo 44 minutos al mes!
• ¿Necesita apagar una hora a la semana?- Eso es sólo 99.4% de tiempo de disponibilidad ((732-4) / 732 = .9945355 ...)
• El mantenimiento podría negociarse en las SLAs• ¿Qué significa que la red está disponible?
- ¿Funciona en todos los lugares? ¿En todas las estaciones? - ¿Está la red disponible, si funciona en el escritorio del jefe? - ¿Es posible acceder a la red desde Internet?

Estableciendo Punto de Referencia
• Se puede usar el monitoreo para establecer un punto de referencia o línea base (baseline)
• Punto de referencia = Qué es normal en la red?- Demora de red típica a través de rutas
- Nivel de variabilidad (jitter) a través de rutas
- La carga en los enlaces
- El porcentaje de uso de recursos
- Nivel de “ruido” típico:
• Escaneos de la red y ataques aleatorios desde el Internet
• Paquetes perdidos
• Errores y fallas reportadas
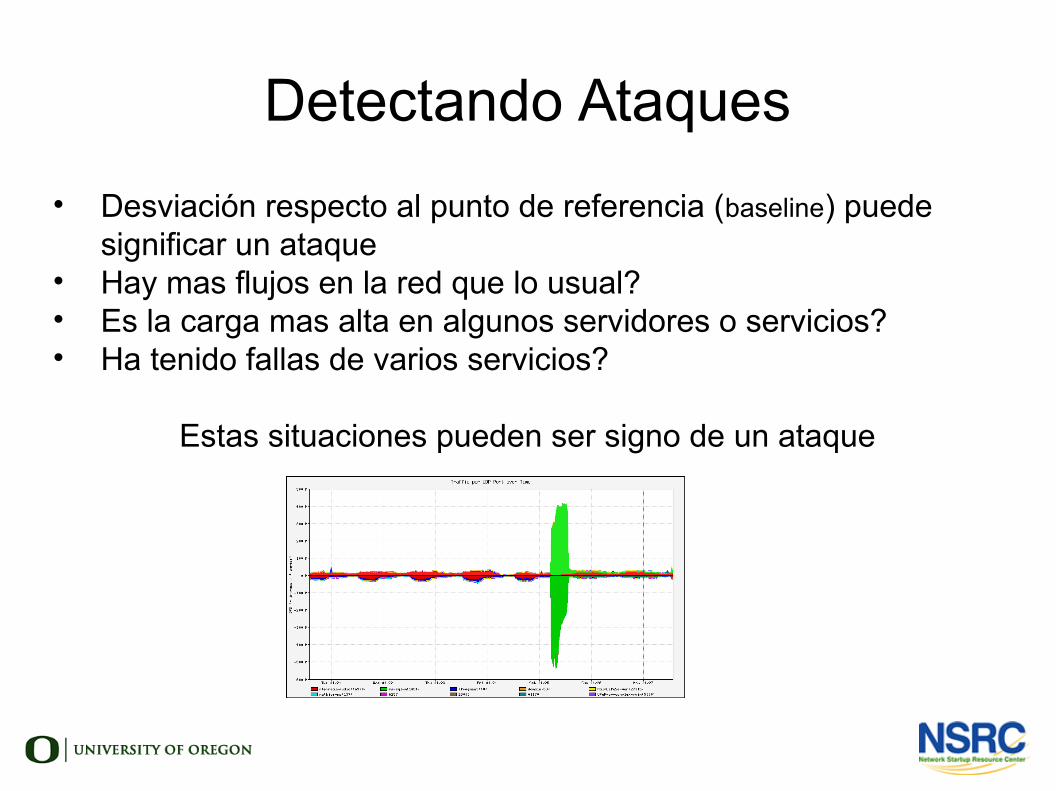
Detectando Ataques
• Desviación respecto al punto de referencia (baseline) puede significar un ataque
• Hay mas flujos en la red que lo usual?• Es la carga mas alta en algunos servidores o servicios?• Ha tenido fallas de varios servicios?
Estas situaciones pueden ser signo de un ataque

Que Gestionamos?• Gestión de recursos: Qué equipos hemos
instalado? - Que versión de software están corriendo- Cual es su configuración (hardware y software)- Donde está instalado? - Tenemos equipos de repuestos, en caso de fallo?
• Gestión de incidentes: seguimiento y resolución de fallas
• Gestión de cambio: Estamos satisfaciendo las solicitudes de los usuarios? - Instalar, mover, añadir o cambiar elementos
• Administración de personal

Por qué gestionamos?
• Garantizar que cumpliremos con los requisitos de negocio para el nivel de servicio, los tiempos de respuesta a incidentes, etc.
• Hacer uso eficiente de nuestros recursos (incluyendo el personal)
• Aprender de los problemas e introducir mejoras para reducir problemas en el futuro
• Planificar actualizaciones y tomar decisiones de compra en un plazo de tiempo suficiente

Herramientas de Monitoreo y Gestión
• Disponibilidad: Nagios - Para servicios, servidores, enrutadores (routers), switches,
entorno. • Confiabilidad: Smokeping
- Estado de conexión, rrt, tiempo de respuesta del servicio, jitter
• Rendimiento: LibreNMS- Tráfico, utilización de puertos, CPU, memoria, disco,
procesos.
• Estas aplicaciones comparten algunos elementos y se complementan!

Herramientas de Gestión
• Sistema de Pedidos (Tickets): RT- Manejar la instalación de equipos y soporte a usuarios
• Gestión de configuración: RANCID- Darle seguimiento a las configuraciones de los enrutadores
y switches• Documentación de la Red: Netdot
- Inventario, localización del inventario y a quien le pertenece.
• Estas aplicaciones comparten algunos elementos y se complementan!
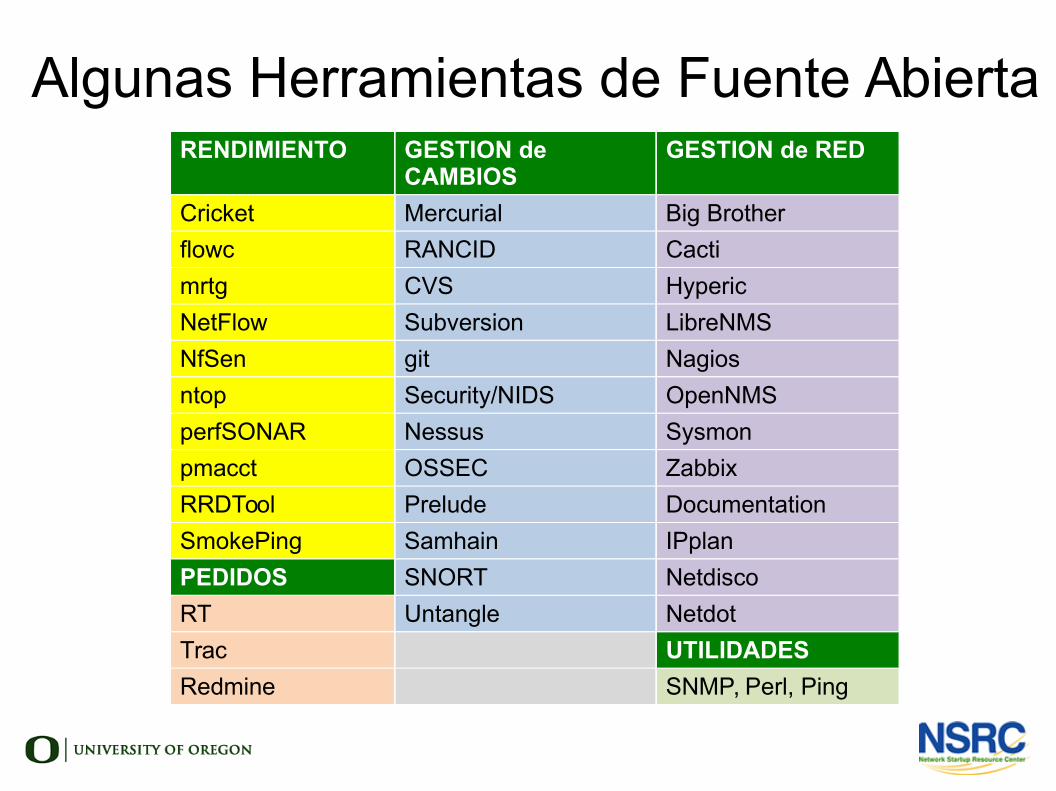
Algunas Herramientas de Fuente AbiertaRENDIMIENTO GESTION de
CAMBIOSGESTION de RED
Cricket Mercurial Big Brother
flowc RANCID Cacti
mrtg CVS Hyperic
NetFlow Subversion LibreNMS
NfSen git Nagios
ntop Security/NIDS OpenNMS
perfSONAR Nessus Sysmon
pmacct OSSEC Zabbix
RRDTool Prelude Documentation
SmokePing Samhain IPplan
PEDIDOS SNORT Netdisco
RT Untangle Netdot
Trac UTILIDADES
Redmine SNMP, Perl, Ping

Repaso de Gestión y Monitoreo
• Gestión y Monitoreo de Redes
• Qué y por qué monitoreamos?
• Expectativas de tiempo de disponibilidad y como
calcularlas
• Establecimiento de puntos de referencia y
detección de ataques
• Detección de ataques de red
• Qué y por qué gestionamos?
• Herramientas de gestión y monitoreo
• El NOC: Consolidando sistemas

Preguntas?



























![Welcome! [nsrc.org] · •Recursive Server ... •Lab 3 – Configuring Domains –TEA BREAK •DNS Registries •Troubleshooting (dig, traceroute, nslookup, ethereal) ... triggers](https://img.pdfslide.us/doc/110x75/5f04af277e708231d40f3122/welcome-nsrcorg-arecursive-server-alab-3-a-configuring-domains-atea.jpg)