Embed Size (px)
Citation preview

arX
iv:1
901.
0592
7v4
[cs
.IT
] 1
0 M
ar 2
021
1
Information Theoretic Framework for Single and
Multi-Server Private Authentication
Narges Kazempour, Mahtab Mirmohseni and Mohammad Reza Aref
Information Systems and Security Lab (ISSL)
Department of Electrical Engineering, Sharif University of Technology, Tehran, Iran
Email: [email protected],{mirmohseni,aref}@sharif.edu
Abstract
One of the main security service in the connected world of cyber physical systems necessitates to authenticate
a large number of nodes privately. In this paper, the private authentication problem is considered that consists of a
certificate authority, a verifier (or verifiers), many legitimate users (prover) and arbitrary number of attackers. Each
legitimate user wants to be authenticated (using his personal key) by the verifier(s), while simultaneously staying
completely anonymous (even to the verifier). On the other hand, an attacker must fail to be authenticated. We analyze
this problem from an information theoretical perspective. First, we propose a general interactive information-theoretic
model for the problem. As a metric to measure the reliability, we consider the authentication key rate whose rate
maximization has a trade-off with establishing privacy. Then, we consider the problem in two different setups: single
server scenario and multi-server scenario. In the single server scenario only one verifier is considered, which all the
provers connected to. In the multi-server scenario, n verifiers are assumed, where each verifier is connected to a
subset of users. For both scenarios, two regimes are considered: finite size regime (i.e., the variables are elements of a
finite field) and asymptotic regime (i.e., the variables are considered to have large enough length). In the single server
scenario, for both regimes, we propose schemes that satisfy the completeness, soundness and privacy properties. In
finite size regime, the idea is to generate the authentication keys according to a secret sharing scheme. In asymptotic
regime, we use a random binning based scheme which relies on the joint typicality to generate the authentication keys.
Moreover, providing the converse proof, we show that our scheme achieves capacity in the asymptotic regime. For finite
size regime our scheme achieves capacity for large field size. In multi-server scenario two methods are considered:
individual authentication and distributed authentication. In individual authentication, the process of authentication is
done by only one single verifier, but for authentication to different verifiers, one key is used by the users. In this case,
for both regimes, we propose schemes that satisfy the completeness, soundness and privacy properties. In distributed
authentication, the process of authentication is done collaboratively by all the verifiers. For this case, when all the
provers are connected to all the verifiers, we propose an optimal scheme in finite size regime.
This work was presented in part at the ITW 2019.

2
Index Terms
Information theoretic privacy, private authentication, Shamir’s secret sharing, random binning, Symmetric private
information retrieval.
I. INTRODUCTION
With the growth of cyber physical systems, the authentication is an essential security feature in the communication
systems. Based on application, authentication protocols may authenticate the user and/or the message. In fact, an
authentication protocol seeks the answer to, who sends the data is the user authorized to access the service or
whether the message received is unaltered. The traditional cryptography-based methods for user authentication are
mostly based on key validation, that is, it is examined if the key is valid according to a specific data set, e.g.,
public key or passwords of the users. While the signed hash of the message is traditionally used for the message
authentication.
The nature of user authentication requires to reveal some of the user’s identity. However, nowadays, by increasing
privacy concerns, users wish to stay anonymous when sending authentication requests. Anonymity ensures that a user
may use a resource or service without disclosing the user’s identity. In other words, anonymity of a user means that
the user is not identifiable (not uniquely characterized) within a specific set of users [1]. This has many emerging
applications such as vehicular network [2], cloud computing, distributed servers [3], crypto-currencies and services on
blockchain [4]. In this paper, we study the inherent contradiction between the authentication and the privacy, referred
as private authentication (PA) problem, where a legitimate user while passing the authentication, does not reveal his
identity even to the server (he hides in a group of users), but an illegitimate user (attacker) fails to be authenticated.
In practice, PA problem is encountered when the server should not distinguish the one who requests the service with
which key is authenticated [2]. Though there are cryptographic methods that are based on zero-knowledge proof
[5], or use tokens for private authentication [6] or other cryptographic protocols [7], [8], known as privacy-aware
or anonymous authentication, to the best of our knowledge, the fundamental limits of the problem have not been
studied.
With no privacy concern, the authentication problem has been studied fundamentally in works such as [9]–[13].
In [9], Simmons considers message authentication over a noiseless channel with a shared key between peers of
authentication, where the lower bounds on the success probability of impersonation attack and substitution attack
are established. In [10], the results of [9] have been extended to noisy channels. In [11], the hypothesis testing is
proposed to derive generalized lower bounds on the success probability of impersonation and substitution attacks.
The idea of using characteristics of wireless channel, instead of shared key, has been analyzed in works such as [12],
[13].

3
Privacy constraints from information theory perspective have been studied in some problems [14]–[17]. With no
connection to the authentication problem, [14] derives the capacity of private information retrieval, and [15] studies
privacy in data base systems. The privacy of biometric characteristics is studied in [16], [17]. In biometric security
systems, a user wishes to authenticate himself by some biometric characteristics, such as fingerprint, called enrollment
sequence. The privacy constraint is to avoid leakage of information about enrollment sequence. [16], [17] derive the
trade-off between secret key, generated from the enrollment sequence, rate and privacy leakage rate.
In this paper, we propose an information-theoretic interactive setup for the user-authentication problem with privacy
constraint. We consider a PA problem consisting of a certificate authority (CA), single verifier or multiple verifiers
(e.g., server), many legitimate users and arbitrary number of attackers. A legitimate user wishes to be authenticated
to the verifier in order to gain access to a service, while he wants to stay anonymous to anyone observing the
authentication process (in particular the verifier). An attacker wants to impersonate himself as a legitimate user and
gain access to the service, who is not permitted to. The verifier(s) wants to understand that the user, who requests
authentication (prover), either is a legitimate user or is an attacker. We assume semi-honest verifiers, they follow the
protocol but they are curious about the identity of the provers. CA is an entity that shares correlated randomness
between the verifier(s) and the legitimate users. This randomness can be used by the verifier in the authentication
process to distinguish an attacker from a legitimate user.
In an authentication protocol, two conditions should be considered: the legitimate user who follows the protocol
must pass the authentication (completeness condition) and an attacker must fail to authenticate (soundness condition).
The privacy condition is satisfied when the user stays anonymous, i.e., the verifier(s) cannot distinguish the legitimate
users’ identities. In addition, it is desirable that the exposure of the key of a legitimate user releases as less information
about the other keys as possible, so we consider a reliability metric defined as total key rate of the users.
As a solution to the above problem, we propose a general interactive information-theoretic protocol. Our proposed
PA protocol is considered in two scenarios: single server and multi-server scenarios. In the single server scenario,
only one verifier is assumed, that is connected to all users. In the multi-server scenario, N verifiers are assumed, such
that a subset of the users are connected to each verifier. For multi-server scenario, we study two cases: (i) Individual
authentication, that each verifier privately authenticates the users that are connected to him (same as single server
scenario). (ii) Distributed authentication, that the process of privately authenticating the user is done distributively
by all the verifiers, by collaboratively sending the helper data. We also discuss the differences and pros and cons of
these two cases.
Each single server or multi-server scenario is analyzed in two regimes: finite size and asymptotic regimes (the
distributed authentication case is just studied in the finite size regime). In the finite size regime, the variables used in
the PA protocol are elements of a finite field. In the asymptotic regime, the variables of the protocol are sequences
of length of order l, for arbitrary large l, where l is the length of the key available at the legitimate user, required

4
for authentication.
In the single server scenario, for both the finite size and asymptotic regimes, we propose an achievable PA protocol,
that satisfies the completeness, soundness and privacy conditions. The privacy condition is guaranteed by generating
correlation between the users. This correlation enables us to generate correlated keys such that checking the availability
of the keys at the users does not need the identity of the user. In the finite size regime, if the size of the field tends
to infinity the achievable rate reaches the upper bound. In the asymptotic regime, the proposed scheme achieves the
capacity, proves its optimality. Our finite size scheme uses the idea that the key of the legitimate users should lie
on a specific polynomial (inspired by Shamir secret sharing [18]). Checking that this polynomial passes through
the key of the user without knowing the exact value of the key, satisfies privacy constraint. Here, the completeness
and privacy conditions are satisfied with probability 1 and the probability of soundness is its maximum. For the
asymptotic regime, we propose an optimal scheme, where the main idea is using the Wyner-Ziv coding [19], the
random binning and the joint typicality between the keys of the legitimate users and the data available at the verifier
to generate required correlation. Using this correlation satisfies privacy. All three conditions (completeness, soundness
and privacy) are satisfied with probabilities arbitrary close to 1.
In the multi-server scenario, individual authentication case, for both the finite size and asymptotic regimes, we
propose achievable protocols. Both these protocols are the generalization of the protocols proposed in single server
scenario, and thus have their properties. The proposed protocol in asymptotic regime is optimal. For distributed case,
in the condition that all the verifiers are connected to all the provers, we propose an optimal scheme in finite size
regime. This protocol uses symmetric private information retrieval (SPIR) [20] at the verifiers to send the desired
data by the prover privately, and simultaneously the prover cannot gain information about other users’ keys. In this
protocol, the authentication process is done distributively by the verifiers.
The rest of the paper is organized as follows. In Section II, we introduce the system framework. In Section III, the
single server scenario is studied, achievable protocols are proposed and its conditions are analyzed. In Section IV,
the multi-server scenario is considered. In Section V some extra services and extra attacks are considered and a
comparison of finite size versus asymptotic regime as well as individual versus distributed authentication is provided.
We conclude the paper in Section VI.
Notations: Capital letters are used to show random variables and small letters are their realizations. The mutual
information between X and Y is shown with I(X;Y ), H(X) shows the entropy of discrete random variable X. Let
T(l)ξ (X,Y ) be the set of jointly typical sequences (X l, U l). [K] = {1, 2, · · · ,K}, X1:N = {X1, · · · ,XN} and X ∼ Y
means that X and Y are identically distributed. For stating asymptotic results (Landau notation), f(x) = Θ(g(x)) if
limx→∞f(x)g(x) < ∞.

5
II. PRIVATE USER AUTHENTICATION FRAMEWORK
The PA protocol consists of a CA, single or multiple verifiers, K legitimate users and an attacker1. Each legitimate
user wants to be authenticated without revealing his identity to the verifier. Two scenarios are considered. Single
server scenario (i.e., one verifier) and multi-server scenario (i.e., N verifiers). For simplicity, we first consider the
single server scenario.
A. Single Server (verifier)
A single server PA protocol consists of a CA, a verifier, K legitimate users and an attacker. Each legitimate user
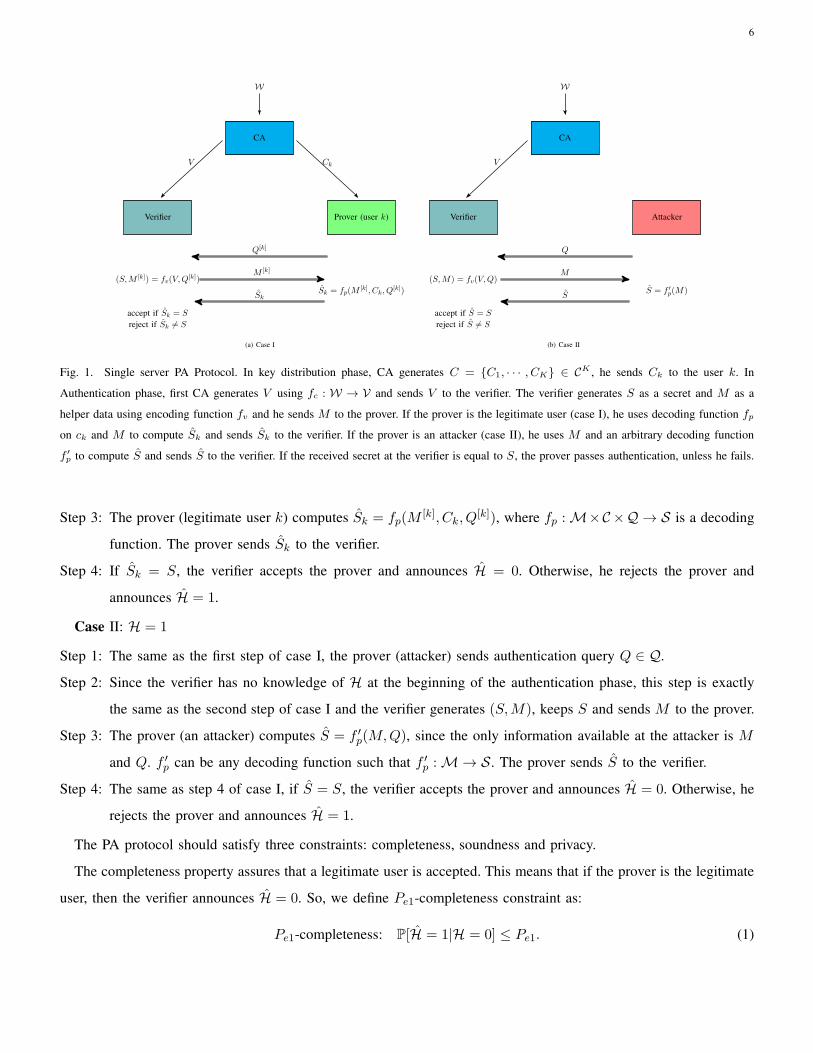
wishes to authenticate himself to the verifier without revealing his identity. The PA protocol, shown in Fig. 1, has
two phases: 1) Key distribution phase: in this phase CA generates Ck ∈ C as personal key of user k using function
f [k] : W → C, where W is an authentication space, and sets C = {C1, · · · , CK} ∈ CK . CA sends Ck to legitimate
user k, which will be used later by the verifier to authenticate user k.
2) Authentication phase: user k ∈ [K] wants to prove knowledge of Ck ∈ C without revealing index “k” to the
verifier. The decoding and encoding functions of the protocol are designed to specify the verification process which
includes the variables PSingle =(
V,Q[k],M [k], S, Sk
)
. These parameters will be defined in the following. Any time
that a prover request an authentication from the verifier, an authentication process happens which includes this phase.
So, in each authentication process the verification process is specified. First, CA generates the set V ∈ V using
encoding function fc : W → V and sends V to the verifier. A prover is a user who sends the authentication request
to the verifier. We have two cases:
Case I: H = 0, the prover is a legitimate user
Case II: H = 1, the prover is an attacker.
When the prover claims that he has some c ∈ C , the verifier decides on H, where H = 0 means the verifier
accepts the prover as a legitimate user, and H = 1 means that the verifier rejects the prover.
Then as shown in Fig. 1, four steps of authentication follows.
Case I: H = 0
Step 1: The prover (legitimate user k) sends authentication query Q[k] ∈ Q , a request for authentication and required
data by the prover.
Step 2: The verifier, knowing V and receiving Q[k], uses encoding function fv : V ×Q → S×M to generate S and
M [k], i.e., (S,M [k]) = fv(V,Q[k]). The output of the encoding function has two parts because one part, S,
is used as secret for authentication process in the following steps and the other part, M [k], is used as helper
data for the prover. Then, the verifier keeps S and sends M [k] to the prover.
1Arbitrary number of attackers may exists, but considering one of them is enough.
6
CA
Verifier Prover (user k)
W
V Ck
Q[k]
(S,M [k]) = fv(V,Q[k])
M [k]
Sk = fp(M[k], Ck, Q
[k])Sk
accept if Sk = S
reject if Sk 6= S
(a) Case I
CA
Verifier Attacker
W
V
Q
(S,M) = fv(V,Q)M
S = f ′p(M)
S
accept if S = S
reject if S 6= S
(b) Case II
Fig. 1. Single server PA Protocol. In key distribution phase, CA generates C = {C1, · · · , CK} ∈ CK , he sends Ck to the user k. In
Authentication phase, first CA generates V using fc : W → V and sends V to the verifier. The verifier generates S as a secret and M as a
helper data using encoding function fv and he sends M to the prover. If the prover is the legitimate user (case I), he uses decoding function fp
on ck and M to compute Sk and sends Sk to the verifier. If the prover is an attacker (case II), he uses M and an arbitrary decoding function
f ′
p to compute S and sends S to the verifier. If the received secret at the verifier is equal to S, the prover passes authentication, unless he fails.
Step 3: The prover (legitimate user k) computes Sk = fp(M[k], Ck, Q
[k]), where fp : M×C×Q → S is a decoding
function. The prover sends Sk to the verifier.
Step 4: If Sk = S, the verifier accepts the prover and announces H = 0. Otherwise, he rejects the prover and
announces H = 1.
Case II: H = 1
Step 1: The same as the first step of case I, the prover (attacker) sends authentication query Q ∈ Q.
Step 2: Since the verifier has no knowledge of H at the beginning of the authentication phase, this step is exactly
the same as the second step of case I and the verifier generates (S,M), keeps S and sends M to the prover.
Step 3: The prover (an attacker) computes S = f ′p(M,Q), since the only information available at the attacker is M
and Q. f ′p can be any decoding function such that f ′
p : M → S . The prover sends S to the verifier.
Step 4: The same as step 4 of case I, if S = S, the verifier accepts the prover and announces H = 0. Otherwise, he
rejects the prover and announces H = 1.
The PA protocol should satisfy three constraints: completeness, soundness and privacy.
The completeness property assures that a legitimate user is accepted. This means that if the prover is the legitimate
user, then the verifier announces H = 0. So, we define Pe1-completeness constraint as:
Pe1-completeness: P[H = 1|H = 0] ≤ Pe1. (1)

7
Next, the soundness property guarantees that an attacker is rejected, which means if the prover is an attacker, then
the verifier announces H = 1. Thus Pe2-soundness constraint is defined as:
Pe2-soundness: P[H = 0|H = 1] ≤ Pe2. (2)
To make user identity private, all provers’ requests should be indistinguishable from the verifier’s perspective, i.e.,
knowing M and V all requests must be identically distributed. So perfect privacy is defined as:
Perfect Privacy: (S1, S,M[1], V,Q[1]) ∼ (Sk, S,M
[k], V,Q[k]), ∀k ∈ [K].
In the proposed model, we use the Pp-privacy property as following:
Pp-privacy: P
[
(S1, Q[1], S,M [1], V ) ∼ (Sk, Q
[k], S,M [k], V ), ∀k ∈ [K]]
≥ 1− Pp. (3)
Since Ck is the personal key of user k, it is desired that (C1, C2, · · · , CK) has the maximum entropy, so that
exposure of a user’s key reveals minimum information about other users’ keys. In other words, users wish others
gain as less information as possible about their keys. On the other hand, for preserving privacy, it is desired that the
personal keys of the users have correlated information. This correlated information is used for authentication without
revealing the identity of the user. So, there is a trade-off between maximizing the entropy of (C1, C2, · · · , CK) and
establishing privacy. Considering length(C) as the length of the keys, we define a reliability metric as the total key
rate:
R =H(C1, C2, · · · , CK)
length(C). (4)
Our goal is to design a PA protocol that satisfies completeness, soundness and privacy constraints while achieving
higher R. Two regimes are considered: finite size and asymptotic regimes. In the finite size regime, the variables of
the protocol are elements of a finite field. For example, for a variable X used in the protocol, X ∈(
GF (q)L)lx
, i.e.,
X is a lx-tuple where each element is of length L in a q-ary unit. lx is chosen properly according to the protocol. So
length(X) = lxL, to be used in (4). In the asymptotic regime, the elements of the protocol are sequences of arbitrary
large length. More exactly, each variable of the protocol, X, chooses from its specific alphabet a sequence of length
lx. So length(X) = lx, where lx approaches infinity.
Considering Ck ∈(
GF (q)L)lc
for k ∈ [K] in finite size regime, we present the following definition.
Definition 1: Pair (R, lc) is achievable for a PA protocol in the finite size regime, if there are encoding functions
fc and fv, a decoding function fp and functions f [k] for k ∈ [K], such that Pe1 = 0, Pe2 =1|S| and Pp = 0.
Remark 1: It is worth noting that, since an attacker can guess the key, the lowest possible for Pe2 is equal to 1|S| .
Definition 2: The capacity pair (Cfin, lc) for a PA protocol is:
Cfin , sup{R : R is an achievable key rate for a PA protocol in finite size regime for fixed lc}.

8
CA
Verifier 1
Verifier 2
...
Verifier N
N1
N2
User 1
User 2
User 3
...
User K − 1
User K
......
C1 V1
CK VN
Fig. 2. Multi-server (verifiers) PA Protocol.
Definition 3: A key rate R is achievable for a PA protocol in the asymptotic regime, if there are encoding functions
fc and fv, a decoding function fp and functions f [k] for k ∈ [K], such that Pe1, Pe2 and Pp tend to zero as the
length of the variables goes to infinity.
Definition 4: The key capacity for a PA protocol in asymptotic regime is:
Casymp , sup{R : R is an achievable key rate for a PA protocol in asymptotic regime}.
B. Multi-server (verifiers)
In this section, a multi-server version of the protocol is considered. A multi-server PA protocol, shown in Fig. 2,
consists of a CA, N verifiers, K legitimate users and an attacker.
Each legitimate user wants to have access to a subset of verifiers using only one personal key. Verifier n (for
n ∈ [N ]) must authenticate any legitimate user in the set Nn ⊆ [K] and |Nn| = Kn. Nn can be any arbitrary subset
of [K] and consists of the users that are allowed to connect to the verifier n. However for privacy reasons, the user
wants to be anonymous in the set Nn, that is the verifier n could not understand which user in the set Nn requests
accessing the service.
Definition 5: (k, n) forms a feasible pair if k ∈ Nn.
The same as single server, multi-server PA protocol has two phases: 1) Key distribution phase: similar to the single
server case, CA sends the personal key of user k, Ck, to him. 2) Authentication phase: User k wants to prove
knowledge of Ck ∈ C without revealing index “k” to the verifier n. In each authentication process, the verification
process is specified which includes the variables PMulti =(
Vn, Q[k]n ,M
[k]n , Sn, S
[k]n , n ∈ [N ]
)
. These parameters will
be defined in the following. The overall functionality is the same as the single server scenario. First, CA generates

9
the sets Vn ∈ V , n ∈ [N ] using encoding function fcn : W → V , where W is an authentication space. CA sets
V = {V1, V2, · · · , VN} and sends Vn to the n-th verifier.
Two cases are considered, for each feasible pair (k, n):
Case I: H = 0
Step 1: Legitimate user k sends authentication query Q[k]n ∈ Q to the verifier n.
Step 2: The n-th verifier, knowing Vn, uses encoding function fvn to generate Sn and M[k]n , i.e., (Sn,M
[k]n ) =
fvn(Vn, Q[k]n ) and fvn : V ×Q → S ×M. The verifier keeps Sn and sends M
[k]n to the prover.
Step 3: The prover (legitimate user k) computes S[k]n = fp(M
[k]n , Ck, Q
[k]n ), where fp is a decoding function and
fp : M×C ×Q → S . The prover sends S[k]n to the verifier.
Step 4: If S[k]n = Sn, the verifier accepts the prover and announces H = 0; Otherwise, he rejects the prover and
announces H = 1.
Case II: H = 1
The steps are the same as Case II in the single server scenario.
Considering each feasible pair, the interaction between the prover and the verifier is similar to single server
case in authentication phase. However, existence of multiple servers (verifiers) provides different situations such as
authentication in a distributed manner.
For each feasible pair, the completeness constraint is defined as (1) and the soundness constraint is defined as (2)
for each verifier. For verifier n, the privacy constraint is as follows:
Pp-privacy: P
[
(S[k1]n , Q[k1]
n , Sn,M[k1]n , Vn) ∼ (S[k]
n , Q[k]n , Sn,M
[k]n , Vn), ∀k, k1 ∈ Nn
]
≥ 1− Pp. (5)
Also, the total key rate is defined as (4).
By designing the verification process for multi-server scenario, PMulti, the definitions of achievable rate and capacity
is the same as Definitions 1-4 considering appropriate encoding and decoding functions.
III. SINGLE SERVER SCENARIO
In this section, for the single server scenario, we present achievablity schemes for both finite size regime and
asymptotic regime, and we show the optimality of the scheme in asymptotic regime.
A. Finite size regime
In this subsection, we consider a finite field version of the single server PA protocol, and thus we assume all the
variables of the protocol are chosen as elements of a finite field, i.e, W = GF (qL), C = (GF (qL))lc , V = (GF (qL))lv ,
M = (GF (qL))lm and S = (GF (qL))ls , where q is a prime number and L is an integer. lc, lv, lm and ls are integers
that will be determined through the scheme. All operations in this section are done in the finite field GF (qL).
10
−2 −1.8−1.6−1.4−1.2 −1 −0.8−0.6−0.4−0.2 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2 2.2 2.4
−2
−1
1
2
3
4
5
6
7
(X3, f(X3))
(X1, f(X1))
(X2, f(X2))
x
f(x)
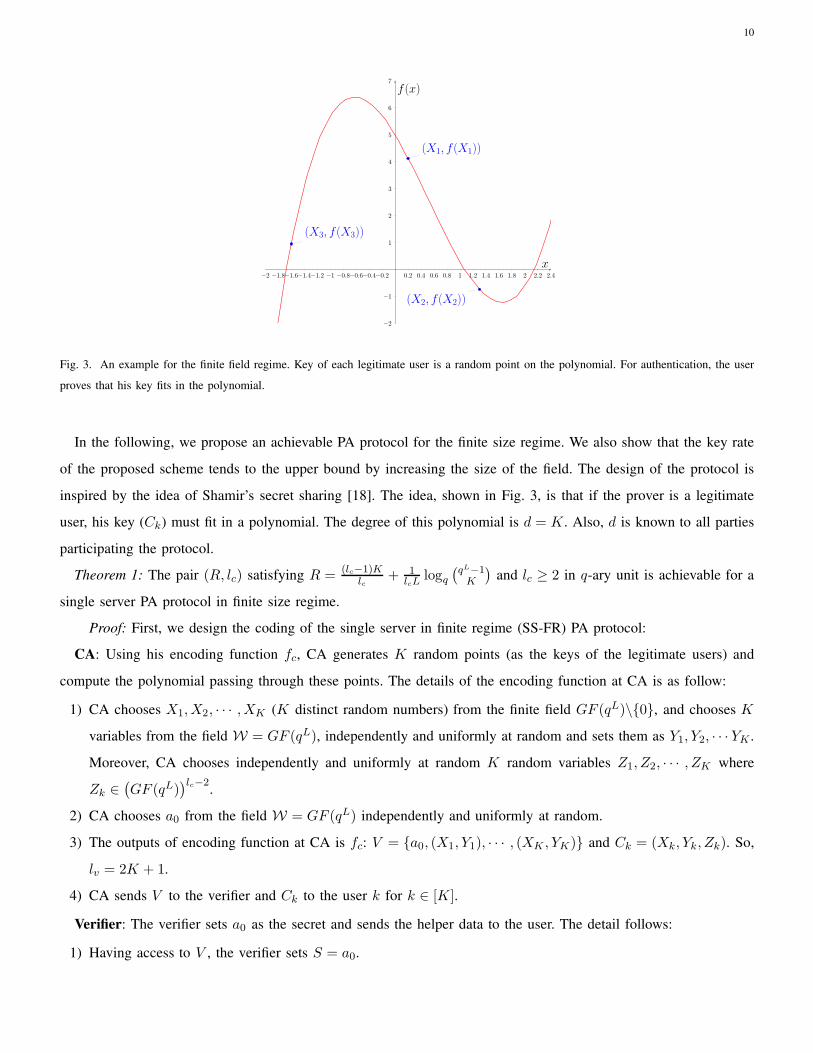
Fig. 3. An example for the finite field regime. Key of each legitimate user is a random point on the polynomial. For authentication, the user
proves that his key fits in the polynomial.
In the following, we propose an achievable PA protocol for the finite size regime. We also show that the key rate
of the proposed scheme tends to the upper bound by increasing the size of the field. The design of the protocol is
inspired by the idea of Shamir’s secret sharing [18]. The idea, shown in Fig. 3, is that if the prover is a legitimate
user, his key (Ck) must fit in a polynomial. The degree of this polynomial is d = K. Also, d is known to all parties
participating the protocol.
Theorem 1: The pair (R, lc) satisfying R = (lc−1)Klc
+ 1lcL
logq(
qL−1K
)
and lc ≥ 2 in q-ary unit is achievable for a
single server PA protocol in finite size regime.
Proof: First, we design the coding of the single server in finite regime (SS-FR) PA protocol:
CA: Using his encoding function fc, CA generates K random points (as the keys of the legitimate users) and
compute the polynomial passing through these points. The details of the encoding function at CA is as follow:
1) CA chooses X1,X2, · · · ,XK (K distinct random numbers) from the finite field GF (qL)\{0}, and chooses K
variables from the field W = GF (qL), independently and uniformly at random and sets them as Y1, Y2, · · · YK .
Moreover, CA chooses independently and uniformly at random K random variables Z1, Z2, · · · , ZK where
Zk ∈(
GF (qL))lc−2
.
2) CA chooses a0 from the field W = GF (qL) independently and uniformly at random.
3) The outputs of encoding function at CA is fc: V = {a0, (X1, Y1), · · · , (XK , YK)} and Ck = (Xk, Yk, Zk). So,
lv = 2K + 1.
4) CA sends V to the verifier and Ck to the user k for k ∈ [K].
Verifier: The verifier sets a0 as the secret and sends the helper data to the user. The detail follows:
1) Having access to V , the verifier sets S = a0.

11
2) Since k + 1 points can uniquely determine a k degree polynomial, the verifier computes unique polynomial
f(X) of degree d = K that passes through {(0, a0), (X1, Y1), · · · , (XK , YK)}.
3) The verifier selects d new points from the space GF (qL), that is the verifier chooses at random d distinct
elements M1,M2, · · · ,Md of GF (qL)\{0}, where Mi 6= Xj , ∀i ∈ [d] and ∀j ∈ [K]. To make this possible we
need qL ≥ K + d+ 1. The verifier computes the value of polynomial at the new points, i.e., f(Mi) for i ∈ [d].
4) The outputs of encoding function at the verifier are fv: M [k] = {(M1, f(M1)), · · · , (Md, f(Md))} and S = a0.
So, lm = 2d = 2K and ls = 1.
5) The verifier sends M [k] to the prover and keeps S.
Prover (legitimate user k): Using decoding function fp, the prover wishes to prove that his key is a valid point
on the polynomial f(x). The detail of the decoding function follows:
1) At first the user sends Q[k] as an authentication request.
2) Knowing M [k] and Ck = (Xk, f(Xk)), the prover has access to d + 1 distinct points of the polynomial f(x)
(of degree d), so he can derive the polynomial and compute a0.
3) The output of the decoding function at the prover is fp: Sk = a0.
These steps determine the variables of verification process PSingle.
Remark 2: Since V does not change in any authentication process in the proposed protocol, it can be sent to the
verifier with the key distribution phase only once at the system setup.
Remark 3: The attacker only knows M [k]. He can use any arbitrary decoding function f ′p to estimate S. His success
probability is derived in the analysis of the soundness property in the following.
Now with determining coding and decoding functions, we show the 0-completeness, 1|S| -soundness and 0-privacy
properties of the proposed protocol.
0-completeness: The user k, having (Xk, Yk) and M = {(M1, f(M1)), · · · , (Md, f(Md))}, d + 1 points of the
polynomial, derives the polynomial with Lagrange interpolation and computes a0 [18]. So, Sk = S = a0 for all
k ∈ [K] and thus:
P[H = 1|H = 0] = P[Sk 6= S] = 0. (6)
This proves the 0-completeness property of the scheme.
1|S| -soundness: By information theoretic secrecy of Shamir secret sharing, M [k] does not give any information
about S [18], [21], i.e., I(S;M [k]) = 0. This means that if the prover is an attacker, by observing M [k] (d points
of the polynomial), the attacker obtains no information about the secret. Considering that H(S) = log |S| (S is
uniformly distributed) and using Lemma 2 in Appendix A (by substituting α = 0), we have:
P[H = 0|H = 1] = P[S = S] ≤1
qL. (7)

12
This means that, the best possible attack strategy is to guess the secret. Thus, the success probability of the attacker
is equal to 1qL
, and it shows the larger the size of the finite field, the lower the probability of attack. This completes
the proof of 1|S| -soundness property.
0-privacy: As stated above, every legitimate user can compute S correctly. So, S1 = Sk = S for all k ∈ [K].
Thus, (S1, S,M [1], V,Q[1]) ∼ (Sk, S,M [k], V,Q[k]) for all k ∈ [K], and 0-Privacy is satisfied. This means, since
every legitimate prover always sends S, the verifier cannot distinguish which user requests the authentication.
Now with determining the protocol we can compute the key rate of the proposed protocol as,
R =H(C1, C2, · · · , CK)
length(C)
=H((X1, Y1, Z1), (X2, Y2, Z2), · · · , (XK , YK , ZK))
lcL
(a)=
H(X1, · · · ,XK) +∑K
i=1 H(Yi) +∑K
i=1 H(Zi)
lcL
(b)=
logq(
qL−1K
)
+K(lc − 1)L
lcL(8)
where (a) follows from the fact that Yi and Zi, for i ∈ [K], are chosen independently and uniformly at random,
and (b) can be obtained by considering that X1,X2, · · · ,XK are chosen uniformly at random from all subsets of
cardinality K of the field GF (qL).
Lemma 1: The key rate is upper bounded by K in q-ary unit for all lc.
Proof: Noting (4), we have:
R =H(C1, C2, · · · , CK)
length(C)
≤
∑Ki=1H(Ci)
Llc=
KLlc
Llc= K.
Corollary 1: The proposed SS-FR PA protocol is asymptotically optimal as qL → ∞ or lc → ∞.
Proof: We show that (8) tends to the upper bound, K, as qL → ∞.We must show that limqL→∞
(
qL−1K
)
=
Θ(
(qL)K)
.
(
qL − 1
K
)
=(qL − 1)!
K!(qL −K − 1)!=
1
K!(qL − 1)(qL − 2) · · · (qL −K)
=(qL − 1)K
K!
(
1
(
1−1
qL − 1
)(
1−2
qL − 1
)
· · ·
(
1−K − 1
qL − 1
))
(a)= Θ
(
(qL)K)
where (a) follows from the fact that K is fixed.
Case of lc → ∞, can be shown easily.
Remark 4: It should be noted that any time, the verifier receives an authentication request, he must send exactly
the same set M to the prover. More precisely, if the prover is an attacker and the helper sets sent to him in two
requests, differ only in one point, then he has d + 1 points that the polynomial f(x) fits and he can compute S

13
. . .
S = 1 S = 2l(I(U ;Y )−ϕ(ξ))
M = 1
. . .
S = 1 S = 2l(I(U ;Y )−ϕ(ξ))
M = 2
. . .
. . .
S = 1 S = 2n(l(U ;Y )−ϕ(ξ))
M = 2l(I(U ;X)−I(U ;Y )+ϕ(ξ)+ϕ(ξ′))
Fig. 4. The binning scheme of Theorem 2. The dots show the U l(m, s) sequences where the bin index m is the helper data sent by the
verifier to the prover and s is the secret the verifier keeps.
correctly. Thus M [k] is not a function of k and is always the same. In Subsection IV-B, we propose a solution in
multi-server scenario, that does not need this condition.
Remark 5: By information theoretic secrecy of Shamir secret sharing, we know that the attacker cannot derive the
polynomial and thus he cannot obtain much information about V (the only information available at the attacker is
the set M [k]). Setting qL >> d, we conclude I(M ;V ) is negligible.
B. Asymptotic regime
In this section, we consider the asymptotic version of the single server PA protocol, i.e., all the variables of the
protocol are sequences of length Θ(l) for arbitrary large l, in particular we define Ck = Y lk for Y ∈ Y .
We present the optimal single server PA protocol for the asymptotic regime. This means that we show that the
key rate of the proposed protocol achieves capacity. The idea is to provide the verifier and the legitimate provers
with correlated data (done by CA), and then to verify the existence of this correlation. This verification is based on
a random binning technique shown in Fig. 4 and is done in an interactive protocol. This idea was also used in the
biometric security systems [16], [17] in a different setup.
Theorem 2: The capacity of the single server PA protocol in asymptotic scheme is equal to KH(Y ).
Proof: Converse: Noting Ck = Y lk , it is obvious that R ≤ KH(Y ).
Achivability: The proof is based on the strong typicality defined in [22]. We propose the achievable scheme, single
server in asymptotic regime (SS-AR) PA protocol, by defining the functions at CA, the verifier and the legitimate
users.
CA: First, we describe the codebook generation at CA. Considering auxiliary random variables X ∈ X and U ∈ U ,
fix a joint distribution PUXY (u, x, y) = PX(x)PY |X(y|x) PU |X(u|x), i.e., U → X → Y forms a Markov chain such
that 0 < I(U ;Y ) ≤ I(X;Y ) = µ. Obtaining PU (u) =∑
x PUX(ux) and fixing ξ and ξ′ such that ξ > ξ′ > 0, form
the set J by randomly and independently generating 2lR sequences of U l, each according to∏l
i=1 PU (ui).
Randomly partition the set J to 2lR′
equal size subsets (bins), as shown in Fig. 4. So, each bin contains 2l(R−R′)
sequences. Each sequence U l ∈ J can be shown as U l(m, s), where m is the bin index and s is the index of sequence

14
in the bin. The sequences U l(m, s) constitutes the codebook, which is revealed to every participants of the protocol
(the verifier and the provers).
Now, we describe the details of generation of the keys and encoding function fc:
1) From marginal distribution PX(x), generate an i.i.d sequence X l.
2) Conditioned on X l, randomly and conditionally independently generate K sequences Y l1 , Y
l2 , · · · , Y
lK each
according to the conditional distribution PY |X(y|x), i.e., Y lk |X
l ∼∏l
i=1 PY |X(yi|xi) for k ∈ [K].
3) The outputs of the encoding functions at CA are fc: V = {X l, Y l1:K} and fk: Ck = Y l
k .
4) CA sends V to the verifier and Ck to the user k for k ∈ [K].
Verifier: Using encoding function fv, the verifier determines S and M [k] based on finding jointly typical sequences
U l with X l. The details of the encoding function follow:
1) The verifier finds a sequence U l ∈ J that is jointly typical with X l, i.e., (X l, U l(m, s)) ∈ T lξ′(X,U). If no
such sequence exists, the verifier chooses a sequence from J randomly. If there are more than one sequence,
the verifier chooses one of them randomly.
2) Knowing U l(m, s) the outputs of encoding function are M [k] = m and S = s.
3) The verifier sends M [k] to the prover and keeps S.
Prover (legitimate user k): The prover wants to prove that his key, Y lk , is correlated with the verifier’s sequence
X l. Thus knowing the bin index, he must estimate U l as a sequence in that bin. The detail follows:
1) The user k sends Q[k] as an authentication request.
2) Having access to Y lk and bin index M [k], the prover looks for a sequence U l in bin M [k] that is jointly typical
with Y lk , i.e., (U l(M [k], s), Y l) ∈ T
(l)ξ (U, Y ). One of the following cases occur:
• There is only one sequence in bin M [k] that is jointly typical with Y l 7−→ the prover takes this sequence
as U l.
• There are more than one sequence in bin M [k] that are jointly typical with Y l 7−→ the prover chooses one
of these sequences randomly and sets the chosen sequence as U l.
• There is no sequence in bin M [k] that is jointly typical with Y l 7−→ the prover chooses U l at random from
the bin M [k].
3) The index s of U l in bin M [k] is the output of the decoding function at the prover, i.e., fp: Sk = s.
The above steps determine the variables of verification process Psingle in SS-AR.
Remark 6: Remark 2 applies here, too.
Remark 7: The attacker only knows M , i.e., the index of the bin. His information about the index of sequence in
the bin (the secret) and his success probability is discussed in analysis of soundness in Appendix B.
An outline of the analysis of the constraints follows. The detailed analysis is provided in Appendix B.

15
For completeness, error occurs if Sk 6= S. By setting R > I(U ;X) and R − R′ < I(U ;Y ), there are more than
2lI(U ;X) sequences in J . Using covering lemma [22], with high probability the verifier finds a sequence U l that
is jointly typical with X l. On the other hand, by law of large number (LLN), the prover finds a sequence U l that
is jointly typical with Y lk . And by packing lemma, with high probability the prover finds a unique sequence. This
proves that liml→∞ Pe1 = 0.
The soundness property is derived by showing that as l→∞, 1lI(S;M) → 0 and using Lemma 2 in Appendix A.
If {S1 6= Sk}, privacy may be violated. So P[S1 6= Sk] is an upper bound on the probability of the event that privacy
is violated. Utilizing similar technique used in the proof of completeness property, we show that the probability of
S1 6= Sk tends to zero. Since the number of legitimate provers is finite (K), the probability of S1 6= Sk for k ∈ [K]
tends to zero.
Now, we analyze the key rate of the proposed scheme:
R =H(C1, C2, · · · , CK)
n=
H(Y l1 , · · · , Y
lK)
l
≥H(Y l
1 , · · · , YlK |X l)
l
(a)=
1
l
K∑
i=1
H(Y li |X
l)(b)= KH(Y |X),
where (a) follows from the fact that Y l1 , Y
l2 , · · · , Y
lK are mutually independent conditioned on X l and (b) is derived
by Y lk |X
l ∼∏l
i=1 PY |X(yi|xi) for k ∈ [K].
In the converse we have showed that R ≤ KH(Y ). The difference of H(Y ) and H(Y |X) is equal to I(X;Y ) = µ.
If µ → 0, then Casymp = KH(Y ) is achievable. µ → 0 means negligible correlation between X and Y , which results
in vanishing correlation between the keys of the users.
Remark 8: Probability of soundness is proportional to 1lI(U ;Y ) . Thus, setting U = X results in the fastest diminishing
probability of soundness.
IV. MULTI-SERVER SCENARIO
In this section, we consider the multi-server scenario of PA protocol as shown in Fig. 2. According to the system
model of multi-server scenario, two methods can be considered. First, the individual authentication, where similar to
the single server case, each server tries to authenticate a group of users that it forms feasible pair with, by considering
privacy constraint. In other words, in each authentication process the legitimate user is connected to only one verifier,
and that verifier privately authenticate the user using the user’s key. Each user has only one key for authentication
process and can use this single key in authenticating himself to any of the verifiers that he forms feasible pair with.
The second method is to use multi-server structure to perform the authentication process in a distributed manner.
More precisely, unlike individual authentication, all (or some) of the servers contribute in the process of privately
authenticating the users in each authentication process.

16
In the following, we propose achievable schemes for both scenarios. The scheme for the distributed authentication
is proposed for the cases that all the users are connected to all the verifiers, i.e. Nn = [K], n ∈ [N ], and the variables
are elements of finite fields. This proposed scheme is optimal.
A. Individual Authentication
In individual authentication, in each authentication process, the prover is connected to only one verifier and wants
to be authenticated individually to that single verifier, who sends the helper data to the prover. Other verifiers do
not contribute in the authentication process. It must be emphasized that, the verifier has only one key, and uses this
single key for authentication to any of the verifiers that he forms a feasible pair with.
Similar to single server scenario, achievability schemes for both finite size regime and asymptotic regime are
provided, and the optimality of the scheme in asymptotic regime is shown.
1) finite size regime: The proposed scheme is generalization of the scheme proposed in the single server case,
Theorem 1, and each server tries to privately authenticate the groups of users that it forms feasible pair with. More
precisely, each verifier compute the polynomial that passes through the keys of the users that he forms a feasible pair
with. On the other hand the key of each legitimate user must lie on all the polynomials constructed by the verifiers
whom he forms feasible pair with.
Theorem 3: The pair (R, lc) for R = (lc−1)Klc
+ 1lcL
logq(
qL−1K
)
and lc ≥ 2 in q-ary unit is achievable for a
multi-server PA protocol in finite size regime.
Proof: First, we design coding of the muulti-server in finite size regime (MS-FR) protocol:
CA: Using his encoding function fc, CA generates K random points (as the keys of the legitimate users). The
details of the encoding functions at CA are as follow:
1) CA acts exactly the same as step 1 in protocol SS-FR, and sets the variables X1:K , Y1:K , Z1:K .
2) CA chooses independently and uniformly at random N variables a(1)0 , a
(2)0 , · · · , a
(N)0 from the field W .
3) The outputs of encoding functions at CA are fcn: Vn ={
a(n)0 , (Xk, Yk)|k ∈ Nn
}
for n ∈ [N ] and Ck =
(Xk, Yk, Zk).
4) CA sends Vn, n ∈ [N ] to the verifier n and Ck to the user k for k ∈ [K].
Verifier: Verifier n1 ∈ [N ] uses a(n1)0 as the secret and derives the polynomial that passes through the keys of the
users in Nn1and a
(n1)0 . Considering verifier n1, the detail follows:
1) The verifier n1 sets S = a(n1)0 .
2) The verifier n1 computes unique polynomial fn1(X) of degree dn1
= |Nn1| that passes through
{
(0, a(n1)0 ), (Xk, Yk)|
(n1, k) is a feasible pair}.
3) The verifier n1 selects dn1new points from GF (qL), that is the verifier chooses at random dn1
distinct elements
M(n1)1 ,M
(n1)2 , · · · ,M
(n1)dn1
of GF (qL)\{0} where M(n1)i 6= Xj , ∀i = 1, · · · , d and ∀j ∈ Nn1
. The verifier
computes the value of polynomial at the new points, i.e., fn1(M
(n1)i ) for i ∈ {1, · · · , dn}.

17
−3 −2.5 −2 −1.5 −1 −0.5 0.5 1 1.5 2 2.5 3
−4
−2
2
4
6
8
10
12
14
16
18
20
fn2
fn1
(X1, f (X1))
(X5, f (X5))
x
Fig. 5. An example of the case described in Remark 10, where users 1 and 5 form feasible pairs with both verifier n1 and verifier n2. When
user 1 computes fn1 and fn2 , he knows that the intersection points contains the keys of the users that form feasible pair with both n1 and
n2. So he knows that the key of user 5, (X5, f(X5)), is one of the blue points. So the security of the keys of users (against other users) is
violated.
4) The outputs of encoding functions at the verifier are fvn : M[k](n1)
={
(M(n1)1 , fn1
(M(n1)1 )), · · · , (M
(n1)dn1
, fn1(M
(n1)dn1
))}
and Sn1= a
(n1)0 .
5) The verifier n1 sends M[k](n1)
to the prover and keeps Sn1.
The prover acts the same as the prover in SS-FR protocol provided in Theorem 1.
These steps determine the variables of verification process PMulti.
Considering (6) – (7), 0-completeness and 1|S| -soundness is provided. Since, every legitimate user can compute S
correctly, (5) is satisfied with PP = 0 and 0-privacy is provided. R = (lc−1)Klc
+ 1lcL
logq(
qL−1K
)
can be computed
according to (8).
These steps determine the variables of verification process PMulti.
Remark 9: Remarks 2, 3 and 4 and Corollary 1 apply here.
Remark 10: Consider the case that user k1 and user k2 form feasible pairs with both verifier n1 and verifier n2.
Assume that user k1 requests authentication to both verifier n1 and verifier n2. After the execution of the protocol
MS-FR, user k1 computes polynomials fn1and fn2
. User k1 knows that the keys of the users that are both in
the Nn1and Nn2
, e.g. user k2, are the intersection of the polynomials fn1and fn2
. This violates the security of
the keys of users if the space of this intersection is small. An example of this situation is shown in Fig. 5. This
problem can be solved if the polynomial and the secret change in each execution of the authentication protocol.
However, changing the secrets and as a result, the polynomials can lead to security violation (the detailed discussion
is provided in Subsection V-A). The proposed protocol in distributed version of the multi-server protocol (DMS-FR),
Subsection IV-B, solves this problem.

18
2) Asymptotic scheme: In this section, we consider the multi-server asymptotic version of the PA protocol, i.e.,
all the variables of the protocol are sequences of length Θ(l) for arbitrary large l, in particular we define Ck = Y lk .
The proposed scheme is the generalization of the scheme proposed in Subsection III-B and the same as single
server this scheme is optimal. More precisely, the key of each legitimate user is correlated with the data available at
the verifiers whom he forms feasible pair with.
Theorem 4: The capacity of the multi-server PA protocol in asymptotic regime is equal to KH(Y ).
Proof: Converse: For converse, it is obvious that R ≤ KH(Y ).
Achivability: The proof and the encoding and decoding functions are mostly similar to proof of Theorem 2, the
main difference is that the key of the user k must be correlated to the data available at all the verifiers that he forms
feasible pair with. The differences of the multi-server in asymptotic regime (MS-AR) PA protocol are as follows:
CA:
1) Codebook generation at CA: Considering auxiliary random variables X1,X2, · · · ,XN ∈ X and Un ∈ U ,
fix a joint distribution PU1:NX1:NY (u1:N , x1:N , y) =∏N
n=1
(
PXn(xn)PUn|Xn
(un|xn))
PY |X1:N(y|x1:N ), such that
0 < I(Un;Y ) ≤ I(X1:N ;Y ) = µ, ∀n ∈ [N ]. Fixing ξ and ξ′ such that ξ > ξ′ > 0 and for each n ∈ [N ],
obtaining marginal distributions PUn(un), form the sets Jn by randomly and independently generating 2lRn
sequences of U ln, each according to
∏li=1 PUn
(uni).
Randomly partition each set Jn to 2lR′n equal size subsets (bins). So, each bin contains 2l(Rn−R′
n) sequences.
Each sequence U ln ∈ Jn can be shown as U l
n(mn, sn), where mn is the bin index and sn is the index of sequence
in the bin mn. The sequences U ln(mn, sn) constitutes the codebook, and is revealed to every participants of the
protocol.
2) From each marginal distribution PXn(xn), generate an i.i.d sequence X l
n.
3) Denote N [k] as the set of verifiers that user k forms a feasible pair with and X lN [k] = {X l
n|n ∈ N [k]}. For
each k ∈ [K], generate the sequence Y lk according to the conditional distribution PY |X
N [k], i.e., Y l
k |XlN [k] ∼
∏li=1 PY |X
N [k](yi|xiN [k]).
4) CA sends Vn = {X ln, Y
lk |k ∈ Nn} to the verifier n and Ck = Y n
k to the user k for k ∈ [K].
Verifier: Verifier n acts the same as SS-AR protocol using U ln(mn, sn) as codebook.
Prover (legitimate user k): The prover proves that his key, Y lk , is correlated to the n-th verifier’s sequence X l
n
using codebook U ln(mn, sn) and helper data mn that the verifier n sends to him the same as SS-AR protocol.
The analysis of probabilities of error is the same as SS-AR protocol, and for completeness the conditions Rn >
I(Un;Xn) and Rn −R′n < I(Un;Y ) must be satisfied.
The key rate of the proposed scheme is:
R =H(C1, C2, · · · , CK)
n=
H(Y l1 , · · · , Y
lK)
l
≥H(Y l
1 , · · · , YlK |X l
1:N )
l

19
=1
l
K∑
i=1
H(Y li |X
l1:N ) = KH(Y |X1:N ).
In the converse we showed that R ≤ KH(Y ). The difference of H(Y ) and H(Y |X1:N ) is equal to I(X1:N ;Y ) = µ.
Thus, if µ → 0, then the optimal rate C = KH(Y ) is achievable.
B. Distributed Authentication
Here, we consider the case of the multi-server scenario in which all the verifiers contribute in the process of
authentication, and so authentication is done distributively, i.e., all the verifiers contribute in sending helper data to
the prover. For this case, we propose an optimal interactive protocol (DMS-FR) in the finite size regime, between the
CA, the verifiers and the prover that uses symmetric private information retrieval (SPIR) [20], to deliver the prover
the desired data, without realizing the identity of the user. The DMS-FR protocol is applicated in the condition that
all the users are connecting to all the verifiers, i.e., (k, n) forms a feasible pair ∀k ∈ [K] and ∀n ∈ [N ]. In summary,
in DMS-FR, the prover sends the authentication request to one of the verifiers (verifier n) and this verifier informs
the CA. The CA sends required data to all the verifiers and the verifiers run the authentication process collaboratively
by using SPIR, described in Appendix C. In the end, the prover sends the estimated key to the verifier n and this
verifier accepts or reject the prover.
Theorem 5: When N1 = N2 = · · · = Nn = [K], the capacity pair of the multi-server PA protocol in finite size
regime in q-ary unit is equal to (K, lc), ∀lc.
For better understanding, first we present an example in the following.
Example 1: Consider N = 2 and K = 3, i.e., we have 2 verifiers and 3 users, and S = C = GF (23), i.e, q = 23
and L = 1. User 2 wants to gain access to verifier 1, and the following protocol is executed:
• CA chooses randomly from GF (23) the variables C1 = X1 = 14, C2 = X2 = 19 and C3 = X3 = 6. These are
the keys of the users that can be used in any authentication process. CA sends each user his key, Ck to user k,
and X1, X2 and X3 to both verifiers. This step is done only once before any authentication is done. The next
steps run for every authentication process.
• When user 2 sends an authentication request to verifier 1, CA chooses randomly from GF (23), S = 5 as secret,
R = 1 as common randomness and Y = 1. He also chooses randomly X = 15 from GF (23)\{0,X1 ,X2,X3}.
CA sends S, R and (X, Y ) to both the verifiers.
• Both verifiers compute the unique polynomial of degree 1 that passes through (0, S) and (X, Y ), This polynomial
is equal to f(X) = 12X + 5.
• Both verifiers compute Yk = f(Xk) for k ∈ {1, 2, 3}. Thus, Y1 = 12, Y2 = 3 and Y3 = 8. The verifiers store
these variables.

20
• Using a SPIR protocol (Appendix C) between user 2 and both the verifiers, user 2 retrieves Y2 = 3 privately
without gaining any information about Y1 and Y3.
• Verifier 1 sends (X, Y ) = (15, 1) to user 2.
• The user 2 computes the unique polynomial that passes through (X2, Y2) = (19, 3) and (X, Y ) = (15, 1), that
is equal to f(X) = 12X + 5. Thus user 2 can compute S = f(0) = 5.
Proof of Theorem 5: Converse: According to Lemma 1, R ≤ K in q-ary unit for any lc.
Achievability: First, we describe the encoding and decoding functions at different parties of the proposed DMS-FR
protocol. We describe the DMS-FR protocol for lc = 1, but any lc is achievable by increasing the space of variables lc
times. The servers must not gain any information about the identity of the user by observing the request for helper data
(privacy constraint), and on the other hand the users should not be able to compute the keys of other users observing the
helper data. Thus, the DMS-FR protocol uses SPIR to privately deliver the desired data to the prover. Here, the verifiers
have the role of the servers with replicated data (X1,X2, · · · ,XK). In each authentication process, the verifiers
compute Yk = f(Xk), ∀k ∈ [K], where f(.) is a degree 1 polynomial specified by the CA. So, (Y1, Y2, · · · , YK) is
stored in all the verifiers. An SPIR protocol is run between user k and the verifiers, such that the user can attain Yk
privately, without gaining any information about Y−k, where Y−k = (Y1, Y2, · · · , Yk−1, Yk+1, · · · , YK). In addition
to Yk, another point of f(.) is sent to the user as helper data. Using this point and Yk, beside Xk that is known to
the user, the user can compute f(.), and thus he can compute the secret. The detailed steps of the protocol is as
follows:
Key distribution phase: These steps are needed only once at the beginning and there is no need to repeat in each
authentication process.
1) The CA chooses X1,X2, · · · ,XK from the the field C = GF (qL), independently and uniformly at random. It
is worth noting that in this protocol, the condition that Xk, k ∈ [K] must be distinct is not necessary.
2) CA sends Xk to the k-th legitimate user, Ck = Xk.
3) CA sends the set {X1,X2, · · ·XK} to all the verifiers.
Authentication phase: These steps are done in each verification process.
1) The prover k wants to be authenticated to verifier n1, so he sends authentication request to this verifier.
2) The verifier n1 informs the CA of the authentication request.
3) The CA chooses S, randomly from the field GF (qL) as secret, and the point (X, Y ) where X ∈ GF (qL)\{0,Xk},∀k ∈
[K] and Y ∈ GF (qL) are chosen independently and uniformly at random. Also CA generates a common random
variable R ∈ Fq. CA sends S, (X, Y ) and R to the verifiers.
4) Each verifier generates the unique polynomial f(.) of degree 1 that passes through {(0, S), (X , Y )} and computes
Yk = f(Xk) for k ∈ [K].
5) An SPIR algorithm according to [20, Theorem 3] (described in Appendix C) is performed between the prover

21
and all the verifiers2. Here Y1, · · · , YK are the replicated data stored in all the verifiers, R is the common
shared randomness between the verifiers and the prover wants to retrieve Yk privately. Thus, the prover k sends
authentication query Q[k]n to the verifier n, ∀n ∈ [N ], according to [20, Theorem 3], in a way that he can retrieve
Yk, without revealing k to any of the verifiers. It must be mentioned that Q[k]n1 consists of both authentication
request that the prover sends to n1 (step 1) and the authentication query specified in SPIR protocol.
6) According to Q[k]n and R, verifier n generates answer A
[k]n , such that:
H(An|Qn, Y1, · · · , YK , R) = 0 (9)
(Q[k1]n , A[k1]
n , Y1:K , R) ∼ (Q[k]n , A[k]
n , Y1:K , R), ∀k1, k ∈ [K] (10)
I(Y−k;Q[k]1:N , A
[k]1:N ) = 0,∀k ∈ [K]. (11)
Also according to equation (26), the prover can compute Yk using A[k]1:n correctly.
7) The verifier n1 sends (X, Y ) in addition to A[k]n1 as helper data to the prover. More precisely, M
[k]n = A
[k]n for
n ∈ [N ]\{n1} and M[k]n1 = {A
[k]n1 , (X, Y )}.
8) Prover k knows (X, Y ) and (Xk, Yk). So, he can compute the polynomial f(.) and thus he can get the secret.
9) The prover sends the estimated secret S[k]n1 to the verifier n1.
10) If S[k]n1 = S the verifier accepts the prover as a legitimate user.
These steps determine the variables of verification process PMulti. Now we analyze completeness, soundness and
privacy conditions.
Completeness: User k has Xk as his own key. In each authentication process, he obtains Yk performing SPIR and
(X, Y ) as a helper data. Thus, he has two points of a polynomial of degree 1, so he can compute the polynomial
and also the secret. So regardless of the verifier S[k]n1 = S for k ∈ [K] and each legitimate user can compute the
secret correctly. Thus:
P[H = 1|H = 0] = P[Sk 6= S] = 0. (12)
This proves the 0-completeness property of the scheme.
Soundness: In each authentication process, the attacker can obtain Yk, where k is the index he masquerade with
and (X, Y ). But since he has no information about Xk (can be any element of the field GF (qL)), he cannot gain
any information about the secret, i.e., I(S;M) = 0. Considering that H(S) = log |S| (S is uniformly distributed)
and using Lemma 2 in Appendix A (by substituting α = 0), we have:
P[H = 0|H = 1] = P[S = S] ≤1
qL. (13)
2Considering the equivalence between GF (qL) and FLq SPIR can be executed.

22
This means that, the best possible attack strategy is to guess the secret. Thus, the success probability of the attacker
is equal to 1qL
, and it shows the larger the size of the finite field, the lower the probability of attack. This completes
the proof of 1|S| -soundness property.
Privacy: Every legitimate user can compute S correctly and since SPIR protocol is performed (equation (10)) the
verifiers cannot detect the index of the prover, Thus:
(S[k1]n , Q[k1]
n , Sn,M[k1]n , Vn) ∼ (S[k]
n , Q[k]n , Sn,M
[k]n , Vn), ∀k, k1 ∈ [K],∀n ∈ [N ],
and 0-Privacy is satisfied.
Now we can compute the key rate of the proposed protocol in q-ary unit as:
R =H(C1, C2, · · · , CK)
l
=H(X1,X2, · · · ,XK)
L
(a)=
H(X1) + · · ·+H(XK)
L
=KH(X1)
L
(b)= K, (14)
where (a) and (b) can be obtained by considering that X1,X2, · · · ,XK are chosen uniformly at random from the
field GF (qL).
V. ANALYSIS AND COMPARISON
A. Extra Services
Some extra services can be considered in PA protocol, described in the following. While these services are not
central to the protocol, they can strengthen the performance of the protocol. Some of the proposed protocols in
Sections III and IV provide these extra services.
Auditing: This service enable the CA to recognize the prover. There are systems and services that the CA is required
to recognize the prover, e.g., to recognize the malicious user. More precisely, auditing means while the verifier
(veifiers) cannot distinguish the index of the prover (i.e., legitimate user), the CA can distinguish the index of the
legitimate user by observation of the verification process. which means,
H(θ|C,Q[θ]1:N ,M
[θ]1:N , S
[θ]1:N , V ) = 0, (15)
where θ is uniformly and randomly chosen from [K].
• SS-FR, SS-AR, MS-FR and MS-AR: Each legitimate prover sends the secret key. So, neither the verifier nor
the CA can detect the ID of legitimate prover. Thus auditing is not provided and
H(θ|C,Q[k],M [k], Sk, V ) = H(θ).

23
• DMS-FR: Since CA has access to all of the verifiers, he has access to Q[k]1:N , considering the prover is user k.
So he has access to all the information available at the prover and thus, the CA can recognize the index ”k”
and the condition in (15) is satisfied.
Addition and deletion of users: This extra service means that the set of users, [K], and its partitioning in multi-
server scenario can be changed in each authentication process. In general, this service provides the CA to update the
list of users (add or delete a user) and its partitioning in each authentication process without information leakage (to
the attackers or other users) of secret variables of the protocol.
• SS-FR and MS-FR: This property cannot be provided. Because, adding and deleting a user changes the unique
polynomial that passes through the keys of the legitimate users. The intersection points of the polynomial before
deleting or adding a user and the new polynomial (after deleting or adding a user) are the keys (Xk, Yk) of
the other users. Thus, this can reveal the value of the keys. Of course, only legitimate users can compute the
unique polynomial, and thus only legitimate users can compute the keys of the users and violate the security of
the keys.
• SS-AR and MS-AR: It is possible to add a new legitimate user, user K+1, by generating Y nK+1 using conditional
distribution PY |X(y|x) the same as the process of generating other keys (step 2 of CA operation in the proof of
Theorem 2). But for deletion of a user, authentication process must be re-run another time to generate new Xn
and new keys for other users. As a result the key of the deleted user is not jointly typical (with high probability)
with new Xn and thus the deleted user cannot compute the new secret.
• DMS-FR: Since the degree 1 polynomial function, f(.) in each authentication process does not depend on the
keys of users, addition and deletion of the keys does not leak any information. In other word, if CA wants to
add a user to the protocol he selects a key randomly and updates the list of the keys and announce this update
to all the verifiers. On the other hand if the CA wants to delete a user he declares to the verifiers to delete that
user’s key. So if he wants to be authenticated he cannot get the access to the data and his operation is like an
attacker.
Expiring secret: This condition implies that the secret must be changed in each authentication process. The reason
behind this is that the legitimate user might be intended to reveal the secret, since their own personal keys are immune.
In addition, in authentication process or secret storing, the secret might be exposed. Thus, if in each authentication
process, the secret changes, the security of the protocol enhances.
• SS-FR and MS-FR: Changing the secret in each authentication process means changing the unique polynomial,
similar to addition and deletion of users service, and by detecting the intersection points of these polynomials
the users can get (Xk, Yk) of other users. So this property is not provided.
• SS-AR and MS-AR: In this protocol changing the secret in each authentication process means changing Xn
and as a result changing keys of the users. So, expiring secret feature is not provided.

24
• DMS-FR: As stated in the protocol in each authentication process the CA chooses a secret at random. So, the
secret changes in every verification process and this feature is available.
B. Additional Attacks
In addition to two attacks that are considered in the system framework, 1) the (semi-honest) verifier wants to
violate privacy, 2) an attacker wants to be authenticated illegally, we consider the following attacks. We analyze the
resistance of our proposed protocols against these attacks.
Colluding legitimate users: Legitimate users collude to gain information about other users keys.
• SS-FR and MS-FR:Colluding legitimate users cannot get anymore information than the unique polynomial. So
they cannot get additional information about other users keys by collusion. Thus, the protocol is resistant against
this attack.
• SS-AR and MS-AR: Since the keys of the legitimate users, have some common information, Colluding users
can gain some information about other users’ keys.
• DMS-FR: Each authentication request means a new verification process and as a result a new secret and a new
polynomial. Thus colluding legitimate users have access to secret and polynomials that are independent from
each other, so they cannot get any additional information by colluding. If a legitimate user wants to attack the
protocol to violate secrecy, his performance is like an attacker, that his success probability is computed in (13).
Malicious Verifier: We have considered semi-honest verifiers, who follow the protocol. But, in a stronger attack
scenario, it is possible that the verifiers do not follow the protocol and send helper data in a way to violate the
privacy of the prover or disrupt the process of authentication. In this situation the verifier may send incorrect helper
data M to distinguish the legitimate prover or disrupt the process of authentication.
• SS-FR, MS-FR and DMS-FR: The malicious verifier can act in two ways:
1) The malicious verifier can put the key of one or some of the users in the helper data. More precisely,
Ck1, Ck2
, · · · , CKj⊂ C can be part of helper data. In this case, if the prover is one of K1,K2, · · · ,Kj , he has
K points of the polynomial, so he cannot compute the polynomial and he cannot be authenticated as a legitimate
user. But, from the viewpoint of the verifier, there is no difference between this user and an attacker. So, the
verifier cannot violate the privacy of the user. Of course the user understands that the verifier does not follow
the protocol.
2) The malicious verifier can send completely wrong helper data. Again, in this case, the verifier cannot violate
the privacy and on the other hand, the user understands that the verifier does not follow the protocol.
The protocol cannot overcome this attack, unless CA himself produce helper data, send the helper data to the
verifier and he can force the verifier to send this helper data.

25
• SS-AR and MS-AR: The protocol cannot overcome this attack, unless CA himself produce helper data, send
the helper data to the verifier and can force the verifier to send the correct helper data.
Colluding verifiers: Verifiers collude to detect the prover’s identity and violate the privacy condition. It is worth
mentioning that this attack is possible in multi-server scenario.
• MS-FR: In this protocol, in each authentication process only one verifier is participating. Thus, this attack is
not meaningful.
• MS-AR: Similar to MS-FR protocol, this attack is not valid in this protocol.
• DMS-FR: Colluding verifier can get some information about the index of the data requested by the prover and
thus, they may gain some information about the prover’s identity. To overcome this attack a T-collude SPIR
algorithm according to [23] can be performed, that is resistant against colluding of T verifiers.
Malicious CA: In systems where auditing is not a requirement of the protocol, the CA may send the data, V (Vn),
to the verifier (verifiers) to violate privacy.
• SS-FR, SS-AR, MS-FR and MS-AR: From the perspective of the prover, this situation is exactly the same as
the case of malicious verifier. The privacy cannot be violated but on the other hand, the legitimate prover cannot
be authenticated. The proposed protocol cannot prevent the CA from sending incorrect data.
• DMS-FR: Since auditing is provided, this kind of attack is not considered.
C. Comparison
In this subsection, first we compare the protocols in finite size and asymptotic regime. Then, the differences and
properties of individual authentication and distributed authentication are studied.
1) Finite size vs asymptotic: In finite size regime, the variables are elements of finite fields, but the variables in
asymptotic regime are sequences of length Θ(l), for arbitrary large l. All the protocols proposed for finite size regime
are practical, however, SS-FR protocol and MS-FR protocol are not optimal. Thus, the SS-AR and MS-AR protocols
(in asymptotic regime) are proposed to show that optimal protocols are achievable.
2) Individual vs distributed: The main difference between these two authentication methods in multi-server scenario
is how the CA and the verifiers perform jointly to privately authenticate the prover. In the individual case in each
authentication process the prover is connected to only one verifier and that one verifier sends the helper data to
the prover. Also, except the only time that the CA sends the secret and the keys of the users (in the MS-FR) or
X ln and the keys of the users (in the MS-AR) to the verifiers, there is no need of data exchange between the CA
and the verifiers in any authentication process. In distributed case, the prover is connected to all (or some) of the
verifiers and these verifiers send helper data to the prover. In the DMS-FR protocol, there is a permanent interaction
between the CA and the verifiers in the process of authentication. In the following some other differences between
MS-FR/MS-AR and DMS-FR are stated:

26
• DMS-FR is proposed for the case that all the users are making feasible pair with all the verifiers, but both
MS-FR and MS-AR protocols are feasible for any connection structure.
• As stated in subsection V-A, auditing is available in DMS-FR, but both MS-FR and MS-AR cannot provide
auditing.
• Both addition and deletion of users are provided in DMS-FR protocol, but in MS-FR none of these properties
are available and only addition is available in MS-AR (Subsection V-A).
• According to Subsection V-A, expiring secret, which is an important security feature, is only possible in DMS-FR
protocol, and none of MS-FR and MS-AR can provide this feature.
• As stated in Remark 10, in MS-FR protocol, the users can gain information about other users keys (the space of
the estimated keys may be small). Thus, security of the keys is not provided. But, in the DMS-FR, because of the
changes of the polynomial and the secret in each authentication process, the users cannot gain any information
about other users keys. This happens because if a user wants to gain information about other users’ keys, he
acts exactly the same as an attacker, which his functionality is analyzed in soundness property in Theorem 5.
• The size of the keys are smaller in DMS-FR compared with MS-FR protocol for a fixed Pe2-soundness constraint.
For example for Pe2 =1qL
, in DMS-FR Ck ∈ GF (qL), but in MS-FR, Ck ∈ GF (qL)2.
• The complexity of computing secret in DMS-FR is far less than MS-FR. Since, in DMS-FR the participants
compute a polynomial of degree 2, but in MS-FR the polynomial of verifier n is of degree equal to |Nn|.
VI. CONCLUDING REMARKS
Computational complexity in the finite size scheme: We consider the participants of the protocol derive the
coefficient of the polynomial by Lagrange interpolation. However, there are efficient algorithms that can compute a0
directly from K +1 points without driving the polynomial [24]. Therefore, the computational complexity is of order
d.
Security condition: An extra condition can be considered, by which the prover should not get any further
information about other users’ keys at the end of the PA protocol. This means that H(ci|M, ck) = H(ci|ck) for
i ∈ [K]\{k}. This condition is satisfied in SS-AR and MS-AR protocols (asymptotic regime). It is satisfied in DMS-
FR protocol, too. But, in the SS-FR and MS-FR, the legitimate prover knows that the polynomial fits the legitimate
users’ keys. This reveals to him that any other points on the polynomial (not in helper data and not his own key) is
a possible key for the other legitimate users. So, to reduce the information leakage about the other users’ key in the
protocol we must have qL >> K.
Partition to smaller groups: To satisfy the above security condition in finite size size regime, our scheme concludes
qL >> K. One solution can be to partition the legitimate users into smaller groups with maximum size of K ′ < K
and PA protocol can be performed within these smaller groups. Then, it is enough to have qL >> K ′. However, this
weakens the privacy.

27
Number of verifiers in DMS-FR: In the DMS-FR protocol, any number (more than two) of the verifiers can
participate (in the SPIR algorithm), but the larger the number of the verifiers the lower the total data rate between
the verifiers and the prover [20]. On the other hand, the smaller the number of the verifiers the lower the total data
rate between the CA and the verifiers (because the CA sends Vn to the smaller set of the verifiers).
Distributed authentication for any structure: The proposed DMS-FR PA protocol is feasible for the cases that
all the verifiers are connected to all the provers. Solving the distributed authentication problem in multi-server PA
protocol scenario for any desired connection structure between the provers and the verifiers is of interest.
APPENDIX A
LEMMA 2
Lemma 2: If I(U ;J) ≤ α, where U ∈ U and J ∈ J , then P[U = g(J)] ≤ 1+α+log |U|−H(U)log |U| , with g : J → U any
arbitrary function.
Proof: Consider U = g(J). Setting e = P[U 6= U ] and using Fano’s inequality:
H(U |U) ≤ 1 + e log |U|. (16)
Since I(U ;J) ≤ α, we obtain I(U ; U ) ≤ α and thus:
H(U |U) ≥ H(U)− α,
substituting in (16) we have:
H(U)− α ≤ 1 + e log |U|,
and noting that 1− e = P[U = U ], we obtain:
P[U = U ] ≤1 + α+ log |U| −H(U)
log |U|.
APPENDIX B
PROBABILITY OF ERROR ANALYSIS OF THEOREM 2
To complete the proof, here we have to show that in the proposed scheme Pe1, Pe2 and PP tends to zero as l goes
to infinity.
Proof: Completeness: The verifier rejects (H = 1) the legitimate prover (user k, H = 1) if Sk 6= S, and this
may happen if one of the following events occurs:
1) E1: The verifier does not find a sequence U l that is jointly typical with X l.
2) E2: User k does not find a sequence U l that is jointly typical with Y lk .
3) E3: User k finds more than one sequence U l in bin M [k] that is jointly typical with Y lk .

28
Using the union bound, we obtain:
P[H = 1|H = 0] = P[Sk 6= S] ≤ P[E1] + P[E2 ∩ Ec1] + P[E3 ∩ Ec
1]. (17)
By covering lemma [22], if R ≥ I(X;U) + ϕ(ξ′) (there are more than 2lI(U ;X) sequences in J ), P[E1] → 0 when
l → ∞. Also, using LLN and the fact that ξ > ξ′, P[E2∩Ec1] → 0 as l → ∞. And if R−R′ ≤ I(U ;Y )−ϕ(ξ) (there
exist less than 2lI(U ;Y ) sequences in bin M [k]), according to packing lemma [22], P[E2∩Ec1] → 0 for large enough l.
ϕ(ξ) and ϕ(ξ′) are functions of ξ and ξ′, respectively, that goes to 0 as ξ, ξ′ → 0. So, by setting R = I(X;U)+ϕ(ξ′)
and R′ = I(X;U) − I(U ;Y ) + ϕ(ξ) + ϕ(ξ′), we obtain:
liml→∞
P[H = 1|H = 0] = 0. (18)
This proves the completeness property of the proposed scheme.
Soundness: From [16, equation (31)], we have I(S;M) ≤ l(ϕ(ξ′) + ζ), where ζ is a function of ξ′ and goes
to 0 as l → ∞. This means that the data the verifier sends to the prover contains negligible information about the
secret in average. Substituting α = l(ϕ(ξ′)+ ζ) in Lemma 2, we conclude that P[S = S] ≤ 1+l(ϕ(ξ′)+ζ+log |S|−H(S))log |S| .
Since S ranges from 1 to 2l(I(U ;Y )−ϕ(ξ)), we have log |S| = l(I(U ;Y ) − ϕ(ξ)) and using [16, equation (30)],
H(S) ≥ l(I(U ;Y )− ϕ(ξ) − ϕ(ξ′)− ζ . Thus,
P[H = 0|H = 1] = P[S = S] ≤1 + l(2ζ + 2ϕ(ξ′))
l(I(U ;Y )− ϕ(ξ)). (19)
Since we can choose ξ and ξ′ such that liml→∞(2ζ+2ϕ(ξ′))
(I(U ;Y )−ϕ(ξ)) → 0, the soundness property is proved.
Privacy: Now we analyze Pp-privacy property of the suggested protocol. First we define the event E as:
E =[
(S1, S,M[1], V,Q[1]) ∼ (Sk, S,M
[k], V,Q[k]), ∀k ∈ [K]]
.
If event E happens with probability 1, we have perfect privacy. Now we consider the case that E does not occur.
P[Ec] = P
[
∃k ∈ [K] : (S1, S,M[1], V,Q[1]) ≁ (Sk, S,M
[k], V,Q[k])] (a)
≤ P[∃k ∈ [K] : S1 6= Sk](b)
≤K∑
k=2
P[S1 6= Sk],
(20)
where (a) follows from the fact that if (S1, S,M[1], V,Q[1]) ≁ (Sk, S,M
[k], V,Q[k]), then S1 6= Sk (while there are
situations that S1 6= Sk but (S1, S,M[1], V,Q[1]) ∼ (Sk, S,M
[k], V,Q[k])), and (b) is obtained using union bound.
Now, for a fixed k we compute P[S1 6= Sk]. {S1 6= Sk} may happen in the following cases:
• P1: The verifier does not find a sequence U l that is jointly typical with X l.
• P2: Both user 1 and user k does not find a sequence U l that is jointly typical with Y l1 and Y l
k , respectively.
• P3: User 1 finds a unique U l that is jointly typical with Y l1 , but user k does not find a sequence U l that is
jointly typical with Y lk .
• P4: User k finds a unique U l that is jointly typical with Y lk , but user 1 cannot find a sequence U l that is jointly
typical with Y l1 .

29
• P5: User 1 finds a unique U l that is jointly typical with Y l1 , but user k finds more than one sequence U l that
are jointly typical with Y lk .
• P6: User 1 does not find a sequence U l that is jointly typical with Y l1 , but user k finds more than one sequence
U l that are jointly typical with Y lk .
• P7: User k finds a unique U l that is jointly typical with Y lk , but user 1 finds more than one sequence U l that
are jointly typical with Y l1 .
• P8: User k does not find a sequence U l that is jointly typical with Y lk , but user 1 finds more than one sequence
U l that are jointly typical with Y l1 .
• P9: Both user 1 and user k find more than one sequence U l that are jointly typical with Y l1 and Y l
k , respectively.
Using union bound, we have:
P[S1 6= Sk] ≤9
∑
i=1
P[Pi]. (21)
It should be considered that, there are 2l(I(U ;X)+ϕ(ξ′)) of U l sequences in J and there are 2l(I(U ;Y )−ϕ(ξ)) of U l
sequences in each bin. As a result, by covering lemma, P[P1] → 0. By LLN, P[P2], P[P3] and P[P4] goes to zero
when l is sufficiently large. By packing lemma and LLN, P[Pi] for i ∈ {5, 6, 7, 8, 9} tends to zero as l → ∞. So,
we conclude:
liml→∞
P[S1 6= Sk] = 0, (22)
and since K is fixed:
limn→∞
P[Ec] = 0,
and
liml→∞
P
[
(S1, S,M[1], V,Q[1]) ∼ (Sk, S,M
[k], V,Q[k]) ∀k ∈ [K]]
= 1. (23)
This completes privacy property.
APPENDIX C
SYMMETRIC PRIVATE INFORMATION RETRIEVAL
In this section, we describe the SPIR protocol presented in [20] and is used in the DMS-FR.
Consider K independent messages, Y1, Y2, · · · , YK , and N servers that each stores a database, such that each
database stores all the messages. The user wishes to retrieve Yθ privately and the databases do not want the user
to get any information beyond the desired message, Yθ. The user generates a random variable F , privately. The
realization of this random variable is not available to the servers. The servers share a common random variable R
that is not known to the user to achieve database privacy. An example of the SPIR problem is illustrated in Fig. 6.

30
Y1
Y2
· · ·
YK
R
Y1
Y2
· · ·
YK
R
User
DB1 DB2
θ θ✘ ✘
Answer Answer
QueryQuery
Yθ ✔
Y1, · · · , Yθ−1, Yθ+1, · · · , YK ✘
Fig. 6. The SPIR problem with two databases and K messages.
In order to retrieve message Yk, k ∈ [K] privately, the user privately generates N queries Q[k]1 , · · · , Q
[k]N ,
H(Q[k]1 , · · · , Q
[k]N |F) = 0. (24)
The user sends Q[k]n to the n-th database, n ∈ [N ]. Upon receiving Q
[k]n , the n-th database generates an answer string
A[k]n , which is a function of Q
[k]n , all messages Y1, · · · , YK , and the common randomness R,
H(A[k]n |Q[k]
n , Y1, · · · , YK , R) = 0. (25)
The n-th database returns A[k]n to the user.
The user decodes Yk using the information available to him, A[k]1:N , Q
[k]1:N ,F , according to a decoding rule specified
by the SPIR scheme, that is:
1
LH(Yk|A
[k]1:N , Q
[k]1:N ,F) = o(L), (26)
where H(Yk) = Llk, k ∈ [K].
To protect the user’s privacy, the K strategies must be indistinguishable from the perspective of any individual
database:
(A[k]1:N , Q
[k]1:N , Y1:K , R) ∼ (A
[k′]1:N , Q
[k′]1:N , Y1:K , R) ∀k, k′ ∈ [K],∀n ∈ [N ]. (27)
To protect the privacy of database, the user must not get any information beyond his desired message, thus:
I(Y−k;A[k]1:N , Q
[k]1:N ,F) = 0, ∀k ∈ [K], (28)
where Y−k = Y1, · · · , Yk−1, Yk+1, · · · , YK .
For detailed information about SPIR problem and its scheme, please refer to [20].

31
REFERENCES
[1] A. Pfitzmann and M. Hansen, “Anonymity, unlinkability, undetectability, unobservability, pseudonymity, and identity management-a
consolidated proposal for terminology,” Version v0, vol. 31, p. 15, 2008.
[2] N. Alexiou, M. Lagana, S. Gisdakis, M. Khodaei, and P. Papadimitratos, “Vespa: Vehicular security and privacy-preserving architecture,”
in Proceedings of the 2nd ACM workshop on Hot topics on wireless network security and privacy. ACM, 2013, pp. 19–24.
[3] R. Roman, J. Zhou, and J. Lopez, “On the features and challenges of security and privacy in distributed internet of things,” Computer
Networks, vol. 57, no. 10, pp. 2266–2279, 2013.
[4] N. Van Saberhagen, “Cryptonote v 2.0,” 2013.
[5] S. Goldwasser, S. Micali, and C. Rackoff, “The knowledge complexity of interactive proof systems,” SIAM J. Comput., vol. 18, no. 1,
pp. 186–208, 1989.
[6] M. Chen and S. Chen, “An efficient anonymous authentication protocol for RFID systems using dynamic tokens,” in 35th IEEE
International Conference on Distributed Computing Systems, ICDCS 2015, Columbus, OH, USA, June 29 - July 2, 2015. IEEE Computer
Society, 2015, pp. 756–757.
[7] J.-L. Tsai and N.-W. Lo, “A privacy-aware authentication scheme for distributed mobile cloud computing services,” IEEE systems journal,
vol. 9, no. 3, pp. 805–815, 2015.
[8] D. He, S. Zeadally, N. Kumar, and J.-H. Lee, “Anonymous authentication for wireless body area networks with provable security,” IEEE
Systems Journal, vol. 11, no. 4, pp. 2590–2601, 2017.
[9] G. J. Simmons, “Authentication theory/coding theory,” in Workshop on the Theory and Application of Cryptographic Techniques. Springer,
1984, pp. 411–431.
[10] L. Lai, H. El Gamal, and H. V. Poor, “Authentication over noisy channels,” IEEE Transactions on Information Theory, vol. 55, no. 2,
pp. 906–916, 2009.
[11] U. M. Maurer, “Authentication theory and hypothesis testing,” IEEE Transactions on Information Theory, vol. 46, no. 4, pp. 1350–1356,
2000.
[12] L. Xiao, L. J. Greenstein, N. B. Mandayam, and W. Trappe, “Using the physical layer for wireless authentication in time-variant channels,”
IEEE Transactions on Wireless Communications, vol. 7, no. 7, 2008.
[13] W. Tu and L. Lai, “Keyless authentication and authenticated capacity,” IEEE Transactions on Information Theory, vol. 64, no. 5, pp.
3696–3714, 2018.
[14] H. Sun and S. A. Jafar, “The capacity of private information retrieval,” IEEE Transactions on Information Theory, vol. 63, no. 7, pp.
4075–4088, 2017.
[15] L. Sankar, S. R. Rajagopalan, and H. V. Poor, “Utility-privacy tradeoffs in databases: An information-theoretic approach,” IEEE
Transactions on Information Forensics and Security, vol. 8, no. 6, pp. 838–852, 2013.
[16] L. Lai, S.-W. Ho, and H. V. Poor, “Privacy-security tradeoffs in biometric security systems,” in Communication, Control, and Computing,
2008 46th Annual Allerton Conference on. IEEE, 2008, pp. 268–273.
[17] T. Ignatenko and F. M. Willems, “Biometric systems: Privacy and secrecy aspects,” IEEE Transactions on Information Forensics and
security, vol. 4, no. 4, p. 956, 2009.
[18] A. Shamir, “How to share a secret,” Communications of the ACM, vol. 22, no. 11, pp. 612–613, 1979.
[19] A. D. Wyner and J. Ziv, “The rate-distortion function for source coding with side information at the decoder,” IEEE Trans. Inf. Theory,
vol. 22, no. 1, pp. 1–10, 1976.
[20] H. Sun and S. A. Jafar, “The capacity of symmetric private information retrieval,” IEEE Trans. Information Theory, vol. 65, no. 1, pp.
322–329, 2019.
[21] M. Fujiwara, A. Waseda, R. Nojima, S. Moriai, W. Ogata, and M. Sasaki, “Unbreakable distributed storage with quantum key distribution
network and password-authenticated secret sharing,” Scientific reports, vol. 6, p. 28988, 2016.

32
[22] A. El Gamal and Y.-H. Kim, Network information theory. Cambridge university press, 2011.
[23] Q. Wang and M. Skoglund, “Secure symmetric private information retrieval from colluding databases with adversaries,” in 55th Annual
Allerton Conference on Communication, Control, and Computing, Allerton 2017, Monticello, IL, USA, October 3-6, 2017. IEEE, 2017,
pp. 1083–1090.
[24] D. R. Stinson, “An explication of secret sharing schemes,” Designs, Codes and Cryptography, vol. 2, no. 4, pp. 357–390, 1992.















![A Game-Theoretic Framework for Multi-Period-Multi-Company ... · Using the framework of game theory, load adaptive pricing has been introduced decades ago [10].In this paper, we use](https://img.pdfslide.us/doc/110x75/5f92126fbd78906db6221b4f/a-game-theoretic-framework-for-multi-period-multi-company-using-the-framework.jpg)













