Embed Size (px)
Citation preview

How many scientific
papers should be retracted?
Murat Çokol, Ivan Iossifov, Raul Rodriguez-Esteban, Andrey Rzhetsky
Columbia UniversityCenter for Computational Biology and Bioinformatics
EMBO Reports. 2007 May; 8(5):422

Data:
• Journal impact factors (IF) are computed and reported by Institute of Scientific Information. (www.isinet.com)
• PubMed records more than 9 million articles on life sciences that are published in a journal with a known IF. (www.pubmed.com)
• 596 articles were retracted out of this 9 million articles.
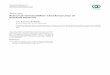
Important Observation: • Most retracted articles were published in high-impact journals. (see Figure 1)
1.

Figure 1: Each sphere represents the set of articles within the same IF range, sphere’s volume is proportional to the set size and its color represents the IF value. The expected number of retractions is computed under the assumption that all retractions are uniformly distributed among articles and journals.
2.

max
IFr
IF
Impact-independent quality
Impact-dependent quality
= Impact-independent scrutiny
Impact-dependent scrutiny
Analysis:
• This observation suggests that either the higher-impact journals are more prone to publishing flawed manuscripts, or they are much more rigorously scrutinized.
• To differentiate between these possibilities, we create the following generative model.
para
met
ers
3.

Analysis:
• We find that for all values analyzed, - impact-dependent quality () is very close to 0 (indicating that quality is independent of IF).- impact-dependent scrutiny () is 1 (indicating that scrutiny of articles is linearly dependent on IF or visibility).
Posterior mode of is ~0.
Posterior mode of is ~1.
4.

Results:
• Our model allows us to estimate the number of papers that should have been retracted.
• We estimate the number of articles (published between 1950 and 2004) that ought to be retracted to be over 100,000 under the more pessimistic scenario ( = 0.1, sum of red distributions in Figure 2), and greater than 10,000 under the most optimistic scenario ( = 1, sum of green distributions in Figure 2).
• Bad news: Although high-impact journals tend to have fewer retractable-undetected articles, even the most vigilant journals potentially host undetected flawed papers.
• Good news: The positive relationship between visibility of research and post-publication scrutiny suggests that the technical and sociological progress in information dissemination inadvertently improves self-correction of science by making scientific publications more visible and accessible.
5.

Figure 2. Posterior distributions of estimated number of retractable articles: red- and green-colored distributions correspond to = 0.1 (a pessimistic scenario) and = 1 (most optimistic scenario), respectively; horizontal black solid lines indicate the actual number of retracted articles for individual IF bins and journals. The contour distributions represent individual journals, while the solid distributions correspond to the whole PubMed corpus binned by the IF value.
6.

A Recipe for High Impact
Murat Çokol,Raul Rodriguez-Esteban, Andrey Rzhetsky
Columbia UniversityCenter for Computational Biology and Bioinformatics
Genome Biol. 2007 May; 8(5):406

• Every research article attacks a scientific problem (topic) and uses a technique (method). Here, we quantify the contribution of these elements to an article’s impact.
• PubMed lists MeSH terms and chemicals for most articles. We use the MeSH terms to reflect the topics and chemicals to reflect the methods of an article. Article’s impact is determined by the impact factor of the journal it was published.
• We estimate two parameters for each journal, separately for topic and method:
- Novelty: How likely is the journal to publish ‘new’ concepts(high novelty indicates tendency to publish more novel items).
- Temperature: How popular are the concepts in the journal (high temperature indicates tendency to publish popular items).
1.

For 1757 journals with known impact factor, we compute Topic temperature, Topic novelty, Method temperature and Method novelty. Above, all significant correlations between these measures that reflect content of journals and impact factor are shown.
2.

Interestingly, when a 5-way linear regression is done, we find that both topic and method novelty are unimportant for predicting the impact factor, while coefficient of topic temperature is positive and method temperature is negative, which is reflected in the plot below (high-impact journals are in lower right quadrant)
Therefore, the recipe for high-impact is: Study highly popular topics using unpopular methods. Inventing new topics and methods does not pay off.
, , , ,i topic i topic i method i method iIF A B C D E error
temperature novelty
>0 <0=0 =0
Impa
ct fa
ctor
3.

We repeat the same temperature and novelty calculation separately for topics and methods for different publication types.
Observations:
• Our model captures the expected information flow through publication type niches.
- For example, “colder” chemicals are published first in the journal articles, some of them later make it to warmer and less novel space of clinical trials phase I, yet a subset of drugs makes it to the significantly warmer area of clinical trials phase II.
• The content of retracted and corrected articles is curiously different from the rest of publication types!
4.

5.

6.